Лекция
Привет, сегодня поговорим про фиксация, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое фиксация, обработка статистических результатов , настоятельно рекомендую прочитать все из категории Моделирование и Моделирование систем.
В лекции 21 мы подробно познакомились со схемой статистического компьютерного эксперимента. В лекциях 21—26 мы рассмотрели практическую реализацию всех основных блоков (см. рис. 21.3) этой схемы. Сейчас важно научиться организовывать работу последних двух блоков — блок вычисления статистических характеристик (БВСХ) и блок оценки достоверности статистических результатов (БОД).
Итак, рассмотрим, как следует фиксировать статистические величины в результате эксперимента, чтобы получить надежную информацию о свойствах моделируемого объекта. Напомним, что обобщенными характеристиками случайного процесса или явления являются средние величины.
Вычисление средних величин во время эксперимента, который многократно повторяется, а результат его усредняется, может быть организовано несколькими способами:
Способ 1. Вычисление всей статистики в конце. Для этого в процессе эксперимента значенияXi выходной (изучаемой) случайной величины X накапливается в массиве данных. После окончания эксперимента подсчитывается математическое ожидание (среднее) X и дисперсия D (характерный разброс величин относительно этого математического ожидания).
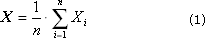
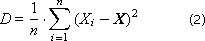
Часто используют среднеквадратичное отклонение σ = sqrt(D).
Заметим, что недостатком метода является неэффективное использование памяти, так как приходится накапливать и сохранять большое количество значений выходной величины в течение всего эксперимента, который может быть весьма продолжительным.
Второй минус заключается в том, что приходится дважды считывать массив Xi, так как воспользоваться формулой (2) в том виде, как она здесь записана, мы можем, только просчитав формулу (1) (от 1 до n), а потом еще раз прогнав для формулы (2) массив Xi.
Положительным моментом является сохранение всего массива данных, что дает возможность более подробного его изучения в дальнейшем при необходимости расследования тех или иных эффектов и результатов.
Способ 2. Вычисление всей статистики в процессе вычисления (по рекурсивным соотношениям). Этот способ предусматривает возможность хранить только текущее значение математического ожидания Xi и дисперсии Di, подправляемое на каждой итерации. Это избавляет нас от необходимости постоянного хранения всего массива экспериментальных данных. Каждое новое данное Xi учитывается в сумме с весовым коэффициентом — чем более слагаемых i накоплено в суммеXi, тем более ее значение важно по отношению к очередной поправке Xi, поэтому соотношение весовых коэффициентов i/(i + 1) : 1/(i + 1).
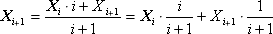

где Xi — очередное значение экспериментальной выходной величины.
Способ 3. Вычисление всей статистики в классовых интервалах. Этот способ предполагает, что в массив будут накапливать не все значения Xi, а только по значимым интервалам, в которых распределена случайная выходная величина Xi. Общий интервал изменения Xi разбивается на mподинтервалов, в каждом из которых фиксируется количество ni, которое показывает, сколько раз Xiприняло значение из i-го интервала. При небольшом количестве интервалов (m ≈ 1) мы получаем способ 1, при количестве интервалов m = n мы получаем способ 2. В случае 1 < m < n получаем среднее решение — компромисс между занимаемой памятью и информативностью массива выходных данных.
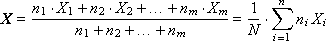
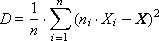
Еще более информативным является вычисление геометрии распределения случайной величины. Оно необходимо для того, чтобы представить себе более точно характер распределения. Известно, что по значению статистического момента можно приблизительно судить о геометрическом виде распределения.
Первый момент (или среднее арифметическое) вычисляется так:
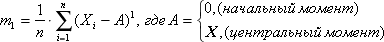
Если A принимает значение 0, то первый момент называется начальным моментом, если Aпринимает значение X, то первый момент называется центральным. (В принципе A может быть любым числом, задаваемым исследователем.)
На практике принято использовать не сам первый момент, а нормированную его величинуR1 = m1/σ1.
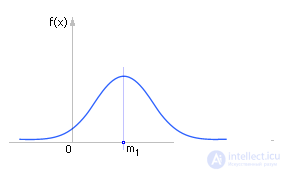
Первый момент указывает на центр тяжести в геометрии распределения, см. рис. 34.1.
|
|
| Рис. 34.1. Характерное положение первого момента на графике распределения статистической величины |
Второй момент (или дисперсия, разброс) вычисляется так:

Вы знакомы с понятием среднеквадратичного отклонения, связанным со вторым моментом:
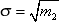
На практике принято использовать не сам второй момент, а нормированную его величинуR2 = m2/σ2.
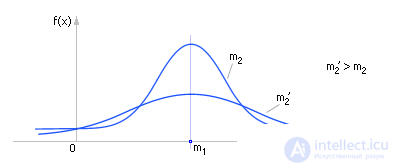
Дисперсия характеризует величину разброса экспериментальных данных относительно центра тяжести m1. Таким образом, по величине m2 можно судить о втором параметре геометрии распределения (см. рис. 34.2).
|
|
| Рис. 34.2. Характерное изменение вида распределения статистической величины в зависимости от величины второго момента |
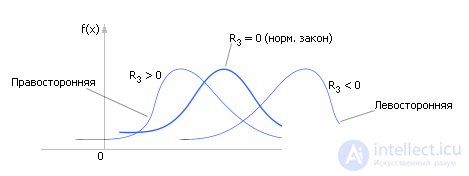
Третий момент характеризует асимметрию (или скошенность) (см. рис. 34.3) вычисляется так:

На практике принято использовать не сам второй момент, а нормированную его величинуR3 = m3/σ3.
|
|
| Рис. 34.3. Характерное изменение вида распределения статистической величины в зависимости от величины третьего момента |
Определяя знак R3, можно определить, есть ли асимметрия у распределения (см. рис. 34.3), а если есть (R3 ≠ 0), то в какую сторону.
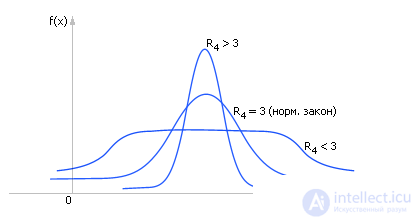
Четвертый момент (см. рис. 34.4) характеризует эксцесс (или островершинность) и вычисляется так:
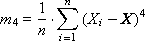
Нормированный момент равен: R4 = m4/σ4.
|
|
| Рис. 34.4. Характерное изменение вида распределения статистической величины в зависимости от величины четвертого момента |
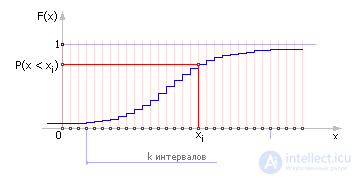
Очень важным является выяснение того, на какое распределение более всего походит полученное экспериментальное распределение случайной величины. Оценка степени совпадения эмпирического закона распределения с теоретическим проводится в два этапа: определяют параметры экспериментального распределения и далее производят оценку по Колмогорову соответствия экспериментального распределения выбранному теоретическому.
|
|
| Рис. 34.5. Интегральный закон эмпирического распределения, дискретный вариант (пример) |
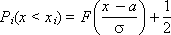
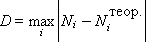
|
|
| Рис. 34.6. Сравнение теоретического и эмпирического интегральных распределений случайной величины (дискретный вариант) |
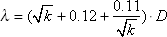
Далее, используя табл. 34.1 Колмогорова, следует принять или отвергнуть гипотезу о том, является ли эмпирическое распределение с заданной нами вероятностью Q теоретическим или нет. Для принятия гипотезы должно быть: λ < λтабл..
| Таблица 34.1. Таблица критерия Колмогорова |
||||||||||
|
Примечание. Критерий Колмогорова не единственный возможный к применению при оценивании; можно использовать критерий Хи-квадрат, критерий Андерсона-Дарлинга и другие.
Крайне важным является вопрос, сколько экспериментов следует сделать, чтобы можно было доверять снятым характеристикам. Если экспериментов не достаточно, то характеристика недостоверна. Обычно исследователь задает доверительную вероятность, то есть вероятность, с которой он готов доверять снятым характеристикам. Чем больше будет задана доверительная вероятность, тем больше экспериментов потребуется сделать. Ранее мы пользовались и другими способами оценки требуемого количества экспериментов (см. лекцию 21, пример с монетой).
Итак, сейчас наша оценка будет основываться на центральной предельной теореме (см. лекцию 25, утверждающей, что сумма (или среднее) случайных величин есть величина неслучайная. ЦПТ утверждает, что значения вычисленной нами статистической характеристики будут распределены по нормальному закону, ni — число i-ых исходов значения статистической характеристики в nэкспериментах, pi = ni/n — частота i-го исхода.
Если n –> ∞, то p –> P (частота p стремится к теоретической вероятности P) и эмпирические характеристики будут стремиться к теоретическим (см. рис. 34.7). Итак, согласно ЦПТ p будет распределена по нормальному закону c математическим ожиданием m и среднеквадратичным отклонением σ.
При этом m = P, σ =sqrt(p · (1 – p)/n).
Обозначим как Q доверительную вероятность, то есть вероятность того, что частота pотличается от вероятности P не более, чем на ε. Тогда по теореме Бернулли:
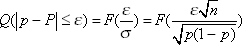
Величина ε называется доверительным интервалом. Смысл ε состоит в том, что в серии (каждая выборкой n) в среднем ε · 100% доверительных интервалов содержат истинное значение статистической характеристики p. Как и ранее (см. лекцию 25), F — интеграл от функции нормального закона распределения, интегральная функция Лапласа.
|
|
| Рис. 34.7. Иллюстрация к вычислению количества экспериментов по величине доверительного интервала согласно центральной предельной теореме |
Отсюда можно выразить требуемое для доверительной вероятности количество экспериментов (F–1 — обратная функция Лапласа):

Пример. При моделировании выпускаемой продукции предприятием в результате имитации его работы в течение 50 дней были получены следующие выходные данные (см. табл. 34.2).
| Таблица 34.2. Экспериментальные статистические данные моделирования |
|||||||||||||||
|
То есть всего было проведено: 15 + 10 + 5 + 20 = 50 экспериментов (n = 50). Из таблицы экспериментов следует ответ задачи, что частость (вероятность) выпуска изделий 1 сорта равна 15/50, частость (вероятность) выпуска изделий 2 сорта равна 10/50, частость (вероятность) выпуска изделий 3 сорта равна 5/50, частость (вероятность) выпуска изделий 4 сорта равна 20/50.
Зададимся доверительной вероятностью к ответам модели Q = 0.9 и доверительным интерваломε = 0.05.
Теперь надо ответить на вопрос: можно ли доверять с вероятностью Q вычисленному ответу?
Будем оценивать результат статистических экспериментов по наихудшей вероятности, таковой в нашей задаче является p = 0.4, так как вероятность, например, 0.1 определена намного лучше.
Очень важное примечание. Вообще вероятности (частости) близкие к 0 или 1 весьма привлекательны в качестве ответа, так как вполне определяют решение. Вероятности близкие к 0.5 говорят о том, что ответ весьма неопределен, событие случится «50 на 50». Такой ответ удовлетворительным назвать сложно, он мало информативен.
Формула
после подстановки значений F–1(0.9) = 1.65 (см. таблицу Лапласа), далее (F–1(0.9))2 = 2.7, p = 0.4,ε = 0.05 дает N = 0.4 · 0.6 · 2.7/0.052 или окончательно N = 250.
То есть наш эксперимент и его ответ недостоверен относительно заданных Q и ε: 50 экспериментов недостаточно для ответа, требуется 250. То есть надо продолжать эксперименты и еще провести 200 экспериментов, чтобы достичь требуемой точности.
Очень важное примечание. Формула использует себя рекуррентно. Сразу вычислить с ее помощью количество экспериментов n не удается. Чтобы вычислить n, надо провести пробную серию экспериментов, оценить значение искомой статистической характеристики p, подставить это значение в формулу и определить необходимой число экспериментов.
Для уверенности данную процедуру следует провести несколько раз при разных получаемых последовательно значениях n.
Итак, в блоке оценки достоверности (БОД) (см. лекцию 21) анализируют степень достоверности статистических экспериментальных данных, снятых с модели (принимая во внимание точность результата Q и ε, заданные пользователем) и определяют необходимое для этого количество статистических испытаний n.
При большом количестве опытов n частота появления события p, полученная экспериментальным путем, стремится к значению теоретической вероятности появления события P. Если колебания значений частоты появления событий относительно теоретической вероятности меньше заданной точности, то экспериментальную частоту принимают в качестве ответа, иначе генерацию случайных входных воздействий продолжают, и процесс моделирования повторяется. При малом числе испытаний результат может оказаться недостоверным. Но чем более испытаний, тем точнее ответ, согласно центральной предельной теореме. Количество требуемых экспериментов nданы для сравнения в табл. 34.3 и табл. 34.4 при различных комбинациях p и ε.
| Таблица 34.3. Количество экспериментов n, необходимых для вычисления достоверного ответа с доверительной вероятностью Q = 0.95, (F–1(0.95))2 = 3.84, p = 0.1 |
||||||||||||
|
| Таблица 34.4. Количество экспериментов n, необходимых для вычисления достоверного ответа с доверительной вероятностью Q = 0.95, (F–1(0.95))2 = 3.84, p = 0.5 |
||||||||||||
|
На рис. 34.8 отображен график зависимости n(ε) при Q = 0.95 и p = 0.5.
|
|
| Рис. 34.8. Зависимость количества требуемых экспериментов от величины доверительной вероятности ε и доверительного интервала Q для случая частости выпадения случайного события p = 0.5 |
Важно: оценивание ведут по худшей из частот. Это обеспечивает достоверный результат сразу по всем снимаемым характеристикам модели.
Примечание. Следует иметь в виду, что данная оценка количества экспериментов по ЦПТ не единственная из существующих. Известны аналогичные близкие по смыслу оценки Бернулли, Муавра-Лапласа, Чебышева.
Как объяснить, почему так странно ведет себя кривая снятой экспериментально статистической характеристики (см. рис. 34.7 и рис. 34.8)? При большом n кривая крайне медленно подходит к истинному значению, хотя сначала (при малых n) процесс идет с большой скоростью — мы быстро входим в область приближенного ответа (большие ε), но медленно приближаемся к точному ответу (малые ε).
Например, допустим, что мы провели N испытаний. Выпадений события в этих испытаниях составило число N1. Пусть вероятность выпадения события близка к N1/N = 0.5 или N = N1 · 2.
Допустим, что мы хотим провести еще одно испытание (N + 1)-е. Взяв ответ (частость N1/N) приN за 100%, оценим, насколько процентов изменится ответ после следующего опыта? Составим пропорцию:
N1/N — 100%
(N1 + 1)/(N + 1) — X%
Отсюда имеем: X = (N1 + 1) · 100 · N/(N1 · (N + 1)), при N1 = N/2 (вероятность 0.5) получаем, чтоX = 100 · (N + 2)/(N + 1).
И величина X образует ряд: 150%, 133%, 125%, 120%, …, 100.1%, …, … –> 100%. Значит, сначала улучшение ответа на один дополнительный эксперимент составило 50%, на 2 — 33%, на 3 — 25%, на 4 — 20%, …, на 100-м — всего на 0,1%.
Видно, что улучшение точности на каждый новый эксперимент (значения X) сначала очень хорошее, а затем — незначительное, после 100 экспериментов эта величина меняется всего на доли процента в расчете на один дополнительный эксперимент! Итог: изменение оценки, основанной на сумме, после серии опытов перестает сильно меняться!!!
Итоги. Важно.
Надеюсь, эта статья об увлекательном мире фиксация, была вам интересна и не так сложна для восприятия как могло показаться. Желаю вам бесконечной удачи в ваших начинаниях, будьте свободными от ограничений восприятия и позвольте себе делать больше активности в изученном направлени . Надеюсь, что теперь ты понял что такое фиксация, обработка статистических результатов и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Моделирование и Моделирование систем



Комментарии
Оставить комментарий
Моделирование и Моделирование систем
Термины: Моделирование и Моделирование систем