Лекция
Привет, сегодня поговорим про обнаружение сайта, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое обнаружение сайта, ранжирование сайта, составляющие seo , настоятельно рекомендую прочитать все из категории Интернет маркетинг , SEO, SMO, монетизация , .
В эру поисковых машин, SEO может быть сведено к 3 основным элементам или функциям: время на обследование сайта(обнаружение), время на индексацию (куда также входит и фильтрация), и время на ранжирование (алгоритмы).
Сегодня первая часть из трех, мы поговорим про
обнаружение сайта поисковыми машинами.
Сведение SEO к этим основным элементам позволяет SEOшникам создать своего рода шаблон для работы над продвижением в поисковиках. Применяя этот шаблон можно не углубляться в специфику и тонкости действий в данном шаблоне.
И иногда это нам на руку, так как поисковые машины - это сверхсекретные монстры... роботы-монстры.
Этот тезис основан на следующих предположениях:
Поисковики исследуют, индексируют и ранжируют веб-страницы. Поэтому SEOшники должны основывать все свои тактики на этих шагах поисковиков. Вот те простые выводы, которые будут полезны SEOшникам, вне зависимости от конкуренции в нише:
Но конечно, Google как и все другие поисковики существуют с одной целью — развить бизнес, удовлетворяя потребности пользователей. Поэтому, мы должны постоянно помнить следующее:
И конечно же, так как по своей природе SEO — это соревнование, в котором для выхода в топ выдачи нужно победить своих конкурентов, мы должны заметить следующее:
Учитывая все вышесказанное, мы можем вывести несколько SEO тактик для каждой из фаз работы поисковика.
SEO начинается с исследования того, как поисковый бот обнаруживает страницы. Googlebot, например, исследуя наш сайт, видит все детали, которые записываются в логи. Эти несут следующую информацию:
Специальные скрипты (AudetteMedia's logfilt), которые помогают быстро разобрать множество таких логов, используются в разных ситуациях:
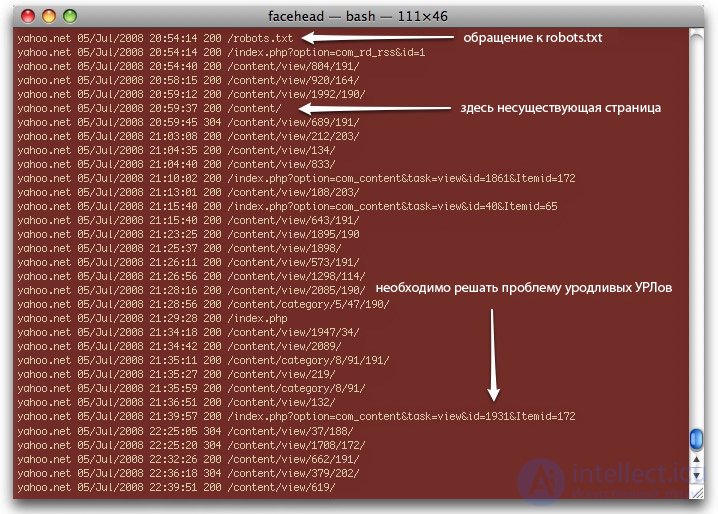
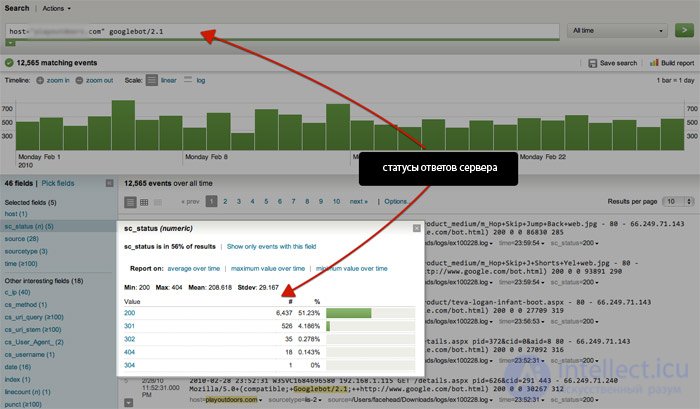
На уровне корпорации существует такой инструмент для анализа как http://www.splunk.com/, который может разобрать всю информацию по user-agent, сортируя ее по коду-статусу сервера, времени и дате:
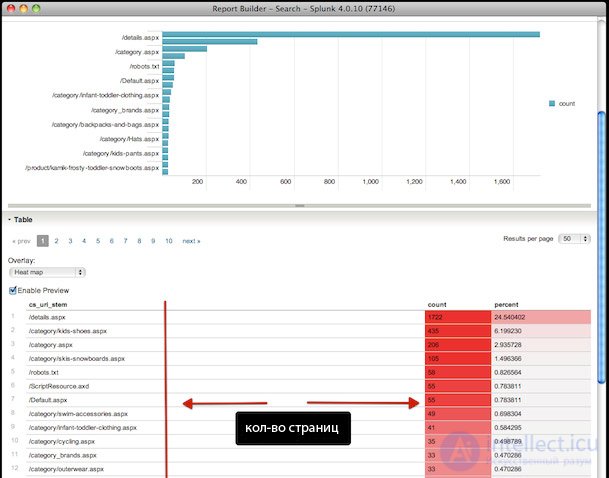
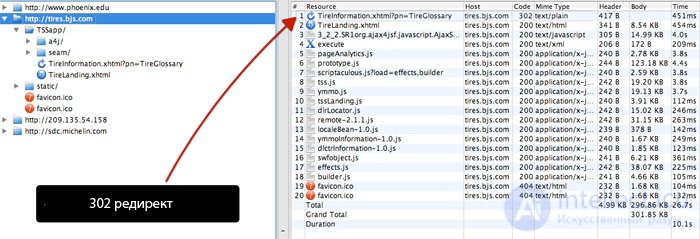
Xenu – это полноценное приложение, которое предоставляет полнейшую информацию о посещении сайта поисковым ботом. Приложение работает с более чем 10 000 страницами, поэтому его лучше использовать на корпоративном уровне. Вот несколько советов по работе с Xenu или подобными:
Эта быстрая и простая методика помогает найти такие коды как 302 и другие.
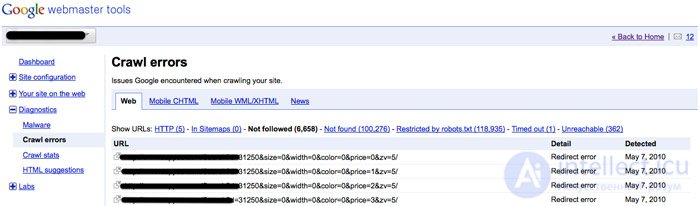
В Google Webmaster Tools также есть полезная для SEOшников информация по обнаружению страницы, дубликатам контента и частоте захождения бота на сайт:
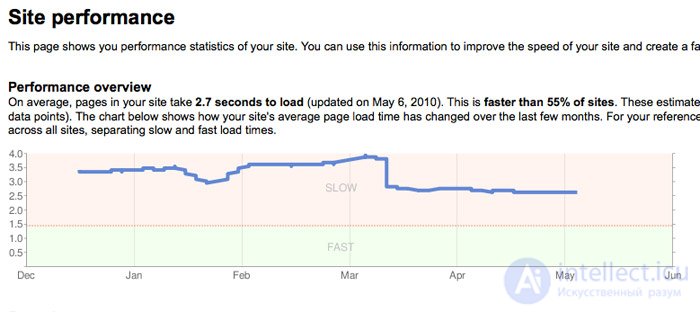
Существуют также и другие инструменты, с помощью которых вы можете посмотреть на страницы сайта глазами поискового бота (например Lynx и SEO Browser ).
Самое главное в SEO - это точная информация, но еще важнее то, что и как можно поделать с этой информацией. Об этом говорит сайт https://intellect.icu . Все дело в том, как вы интерпретируете данную информацию, а не то, как вы ее достанете.
Подвергая SEO работу систематизации, сообразительные SEOшники делают шаблон действий или методов, основываясь на теорию обнаружения, индексации и ранжирования, что впоследствии приводит их сайты прямиком в топы поисковой выдачи.
В прошлый раз в серии из трех статей мы познакомились с первой статьей, где рассмотрели первую стадию работы поисковика: обнаружение сайта. Также мы рассмотрели возможные методы работы SEOшника с каждой из стадий.
Перед тем как продолжить, я считаю, что будет целесообразным освежить в памяти о чем шла речь в первой статье:
Поисковик обнаруживает, индексирует и ранжирует веб-страницы. SEOшники должны основывать свои тактики продвижения на этих трех стадиях работы поисковика. Поэтому были сделаны следующие выводы:
Но конечно же, Google как и любой другой поисковик существуют с одной целью — построить и развить бизнес, удовлетворяя потребности пользователей. Поэтому мы должны постоянно помнить следующее:
Зная все вышесказанное, мы можем разработать несколько методов продвижения на каждую из фаз работы поисковика, что в конце может привести к единой SEO стратегии.
Индексация является следующим шагом после обнаружения страницы. Выявление дубликатов контента является главной функцией данного шага работы поисковика. Возможно не будет преувеличением, если я скажу, что все крупные сайты имеют не уникальный контент хотя и на международном уровне.
Интернет-магазины могут иметь одинаковый контент в виде одних и тех же товаров. Об этом мы с точностью можем заявить, имея большой опыт работы с такими продавцами как Zappos и Charming Shoppes.
Еще больше проблем с новостными порталами известных газетных изданий и публикаций. Маршалл Симондс и его команда, работая над The New York Times и другими изданиями, ежедневно сталкиваются с дубликатами контента, что является основной SEO работой.
К сайту никогда не будут специально применяться санкции, если на его страницах имеются дубликаты контента. Но существуют фильтры, которые способны отличать одинаковый или слегка измененный контент на множестве страниц. Эта проблема является одной из главных для SEO.
Дубликаты также повлияют на видимость сайта, поэтому нужно свести количество дубликатов к нулю. Различные версии одного и того же контента в индексе поисковика тоже не лучший результат оптимизации.
Мэтт Каттс, в своем интервью с Эриком Энгем, подтвердил существование "crawl cap" (колпак видимости сайта), который зависит от PR сайта (не тулбарного PR) и рассказал о том, какие проблемы могут появиться из-за дубликатов контента:
Полная версия интервью с Мэттом Каттсом включает полнейшую информацию для любого серьезного SEOшника по проблеме дубликатов контента. Хотя и большинство, что вы услышите там будет не новостью, но подтвердить некоторые догадки и решения, с которыми мы сталкиваемся ежедневно, будет не лишним.
Ссылки, особенно с сайтов с отличной структурой, с релевантных и высококачественных страниц не только улучшат индексирование сайта, но и улучшат его видимость.
Определение уровня "проникновения" поисковика в сайт, "колпака видимости сайта", количества дубликатов контента, а затем их устранение, улучшит как видимость сайта в глазах поисковика, так и индексацию сайта.
Существует несколько отличных способов узнать это:
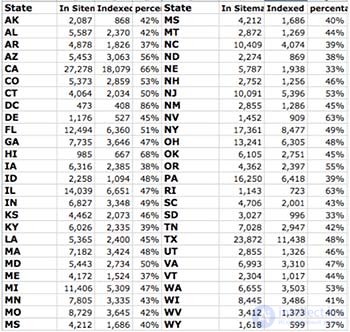
Проблема количества дубликатов для SEO очень сложна и требует отдельного рассмотрения. Если коротко, то проблему дубликатов можно решить использованием "rel=canonical" и стандартного "View All page" на страницах, которые служат главной.
Результаты поисковой выдачи — другая уникальная ситуация. Для управления этими результатами существует много способов.
Во время выявления проблем индексации сайта, любые "слабости" структуры URL страниц сайта всплывут наружу. Особенно это касается сайтов корпоративного уровня, где вы столкнетесь со всеми видами неожиданных результатов в индексе поисковика.
Эти проблемы возникают, когда у сайта появляется множество различных видов пользователей и членов администрации. Конечно же мы сами часто совершаем ошибки, SEO – не является решением всех проблем.
Индексация сайта является главным компонентом видимости сайта, индекса, ранжирования и обычно является главным объектом внимания SEOшников. Как следует почистите индекс вашего сайта и насладитесь эффективностью сканирования, скоростью индексации вашего сайта.
Оставайтесь с нами, так как будет еще и третья, заключительная статья из этой серии.
Данная статья направлена на рассмотрение ранжирования — последней из ступеней работы поисковика с веб-страницей. До этого мы рассмотрели две предыдущие стадии работы поисковика: обнаружение и индексацию веб-страницы.
По мнению не опытных SEOшников ранжирование является самой простой из трех частей работы поисковика. Однако это не так.
Вся сущность SEO сводится к поисковой выдаче. Если URL ваших конкурентов по поисковой выдаче вдруг стали выше ваших вам следует проанализировать и занести в таблицу следующее:
Вам нужно собрать данные по каждому URL и по каждому домену. Данные как по URL так и по домену в целом очень важны, но вам не следует рассматривать каждый фактор, который мог двигать страницу вверх в выдаче. Учтите самые важные из них, те, с которыми вы уже имели дело.
SEO Quake является отличным инструментом для быстрого получения основных SEO метрик прямо из поисковой выдачи. Более того, все данные могут быть легко экспортированы в Excel. Всю полученную информацию вы сможете представить различными способами.
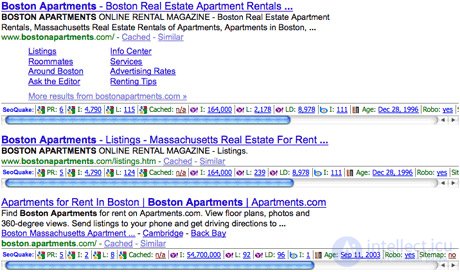
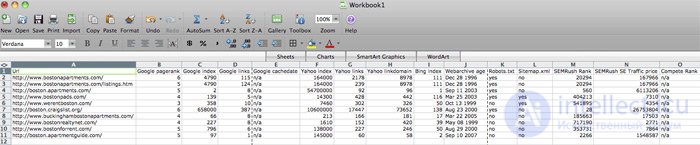
Итак, что осталось у вас после данного анализа? Полученная информация четко покажет вам то, что нужно сделать для того, чтобы обойти в поисковой выдаче ваших конкурентов и вообще где находится ваш сайт среди конкурентов.
Поставленная задача тут - это "выявить и победить" сайты конкурентов.
Подвергая систематическому SEO анализу трех составных стадий работы поисковика: обнаружение, индексация иранжирование, грамотные SEOшники составляют собственные методы улучшения ("прокачки") своих сайтов, что потом наградит их отличными результатами ранжирования в поисковой выдаче.
К сожалению, в одной статье не просто дать все знания про обнаружение сайта. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое обнаружение сайта, ранжирование сайта, составляющие seo и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интернет маркетинг , SEO, SMO, монетизация ,
Комментарии
Оставить комментарий
Интернет маркетинг , SEO, SMO, монетизация ,
Термины: Интернет маркетинг , SEO, SMO, монетизация ,