Лекция
Это окончание невероятной информации про оптимизация программ .
...
во времени доступа между оперативной памятью и диском колоссальный. Диск медленнее оперативной памяти в десятки тысяч раз, и медленнее кэша первого уровня в миллионы раз. Выгоднее обратиться несколько тысяч раз к оперативной памяти, чем один раз к диску. На это знание опираются такие структуры данных , как B- деревья , которые стараются разместить больше информации в оперативной памяти, пытаясь избежать обращения к диску любой ценой.
Локальный диск сам может рассматриваться как кэш для данных, расположенных на удаленных серверах. Когда вы посещаете веб- сайт , ваш браузер сохраняет изображения с веб-страницы на диске, чтобы при повторном посещении их не нужно было качать. Существуют и более низкие иерархии памяти. Крупные датацентры, типа Google, сохраняют большие объемы данных на ленточных носителях, которые хранятся где-то на складах, и когда понадобятся, должны быть присоеденены вручную или роботом.
Современная система имеет примерно такие характеристики:
| Тип кэша | Время доступа (тактов) | Размер кэша |
|---|---|---|
| Регистры | 0 | десятки штук |
| L1 кэш | 4 | 32 KB |
| L2 кэш | 10 | 256 KB |
| L3 кэш | 50 | 8 MB |
| Оперативная память | 200 | 8 GB |
| Буфер диска | 100'000 | 64 MB |
| Локальный диск | 10'000'000 | 1000 GB |
| Удаленные сервера | 1'000'000'000 | ∞ |
Быстрая память стоит очень дорого, а медленная очень дешево. Это великая идея архитекторов систем совместить большие размеры медленной и дешевой памяти с маленькими размерами быстрой и дорогой. Таким образом система может работать на скорости быстрой памяти и иметь стоимость медленной. Давайте разберемся как это удается.
Допустим, ваш компьютер имеет 8 ГБ оперативной памяти и диск размером 1000 ГБ. Но подумайте, что вы не работаете со всеми данными на диске в один момент. Вы загружаете операционную систему, открываете веб-браузер, текстовый редактор, пару-тройку других приложений и работаете с ними несколько часов. Все эти приложения помещаются в оперативной памяти, поэтому вашей системе не нужно обращаться к диску. Потом, конечно, вы закрываете одно приложение и открываете другое, которое приходится загрузить с диска в оперативную память. Но это занимает пару секунд, после чего вы несколько часов работаете с этим приложением, не обращаясь к диску. Вы не особо замечаете медленный диск, потому что в один момент вы работаете только с небольшим бъемом данных, которые кэшируются в оперативной памяти. Вам нет смысла тратить огромные деньги на установку 1024 ГБ оперативной памяти, в которую можно было бы загрузить содержимое всего диска. Если бы вы это сделали, вы бы почти не заметили никакой разницы в работе, это было бы « деньги на ветер».
Так же дело обстоит и с маленькими кэшами процессора. Допустим вам нужно выполнить вычисления над массивом, который содержит 1000 элементов типа int. Такой массив занимает 4 КБ и полностью помещается в кэше первого уровня размером 32 КБ. Система понимает, что вы начали работу с определенным куском оперативной памяти. Она копирует этот кусок в кэш, и процессор быстро выполняет действия над этим массивом, наслаждаясь скоростью кэша. Потом измененный массив из кэша копируется назад в оперативную память. Увеличение скорости оперативной памяти до скорости кэша не дало бы ощутимого прироста в производительности, но увеличило бы стоимость системы в сотни и тысячи раз. Но все это верно только если программы имеют хорошую локальность.
Локальность — основная концепция этой статьи. Как правило, программы с хорошей локальностью выполняются быстрее, чем программы с плохой локальностью. Локальность бывает двух типов. Когда мы обращаемся к одному и тому же месту в памяти много раз, это временнáя локальность. Когда мы обращаемся к данным, а потом обращаемся к другим данным, которые расположены в памяти рядом с первоначальными, это пространственная локальность.
Рассмотрим, программу, которая суммирует элементы массива:
int sum(int size, int A[])
{
int i, sum = 0;
for (i = 0; i < size; i++)
sum += A[i];
return sum;
}
В этой программе обращение к переменным sum и i происходит на каждой итерации цикла. Они имеют хорошую временную локальность и будут расположены в быстрых регистрах процессора. Элементы массива A имеют плохую временную локальность, потому что к каждому элементу мы обращаемся только по разу. Но зато они имеют хорошую пространственную локальность — тронув один элемент, мы затем трогаем элементы рядом с ним. Все данные в этой программе имеют или хорошую временную локальность или хорошую пространственную локальность, поэтому мы говорим что программа в общем имеет хорошую локальность.
Когда процессор читает данные из памяти, он их копирует в свой кэш, удаляя при этом из кэша другие данные. Какие данные он выбирает для удаления тема сложная. Но результат в том, что если к каким-то данным обращаться часто, они имеют больше шансов оставаться в кэше. В этом выгода от временной локальности. Программе лучше работать с меньшим количеством переменных и обращаться к ним чаще.
Перемещение данных между уровнями иерархии осуществляется блоками определенного размера. К примеру, процессор Core i7 Haswell перемещает данные между своими кэшами блоками размером в 64 байта. Рассмотрим конкретный пример. Мы выполняем программу на машине с вышеупомянутым процессором. У нас есть массив v, содержащий 8-байтовые элементы типа long. И мы последовательно обходим элементы этого массива в цикле. Когда мы читаем v , его нет в кэше, процессор считывает его из оперативной памяти в кэш блоком размером 64 байта. То есть в кэш отправляются элементы v –v . Далее мы обходим элементы v , v , ..., v . Все они будут в кэше и доступ к ним мы получим быстро. Потом мы читаем элемент v , которого в кэше нет. Процессор копирует элементы v –v[15] в кэш. Мы быстро обходим эти элементы, но не находим в кэше элемента v[16]. И так далее.
Поэтому если вы читаете какие-то байты из памяти, а потом читаете байты рядом с ними, они наверняка будут в кэше. В этом выгода от пространственной локальности. Нужно стремиться на каждом этапе вычисления работать с данными, которые расположены в памяти рядом.
Желательно обходить массив последовательно, читая его элементы один за другим. Если нужно обойти элементы матрицы, то лучше обходить матрицу построчно, а не по столбцам. Это дает хорошую пространственную локальность. Теперь вы можете понять, почему функция matrixsum2работала медленнее функции matrixsum1. Двумерный массив расположен в памяти построчно: сначала расположена первая строка, сразу за ней идет вторая и так далее. Первая функция читала элементы матрицы построчно и двигалась по памяти последовательно, будто обходила один большой одномерный массив. Эта функция в основном читала данные из кэша. Вторая функция переходила от строки к строке, читая по одному элементу. Она как бы прыгала по памяти слева-направо, потом возвращалась в начало и опять начинала прыгать слева-направо. В конце каждой итерации она забивала кэш последними строками, так что в начале следующей итерации первых строк кэше не находила. Эта функция в основном читала данные из оперативной памяти.
Как программисты вы должны стараться писать код, который, как говорят, дружелюбный к кэшу (cache-friendly). Как правило, основной объем вычислений производится лишь в нескольких местах программы. Обычно это несколько ключевых функций и циклов. Если есть вложенные циклы, то внимание нужно сосредоточить на самом внутреннем из циклов, потому что код там выполняется чаще всего. Эти места программы и нужно оптимизировать, стараясь улучшить их локальность.
Вычисления над матрицами очень важны в приложениях анализа сигналов и научных вычислениях. Если перед программистами встанет задача написать функцию перемножения матриц, то 99.9% из них напишут ее примерно так:
void matrixmult1(int size, double A[][size], double B[][size], double C[][size])
{
double sum;
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++) {
sum = 0.0;
for (int k = 0; k < size; k++)
sum += A[i][k]*B[k][j];
C[i][j] = sum;
}
}
Этом код дословно повторяет математическое определение перемножения матриц. Мы обходим все элементы окончательной матрицы построчно, вычисляя каждый из них один за другим. В коде есть одна неэффективность, это выражение B[k][j] в самом внутреннем цикле. Мы обходим матрицу B по стобцам. Казалось бы, ничего с этим не поделаешь и придется смириться. Но выход есть. Можно переписать то же вычисление по другому:
void matrixmult2(int size, double A[][size], double B[][size], double C[][size])
{
double r;
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++) {
r = A[i][k];
for (int j = 0; j < size; j++)
C[i][j] += r*B[k][j];
}
}
Теперь функция выглядит очень странно. Но она делает абсолютно то же самое. Только мы не вычисляем каждый элемент окончательной матрицы за раз, мы как бы вычисляем элементы частично на каждой итерации. Но ключевое свойство этого кода в том, что во внутреннем цикле мы обходим обе матрицы построчно. На машине с Core i7 Haswell вторая функция работает в 12 раз быстрее для больших матриц. Нужно быть действительно мудрым программистом, чтобы организовать код таким образом.
Существует техника, которая называется блокинг. Допустим вам надо выполнить вычисление над большим объемом данных, которые все не помещаются в кэше высокого уровня. Вы разбиваете эти данные на блоки меньшего размера, каждый из которых помещается в кэше. Выполняете вычисления над этими блоками по отдельности и потом объединяете результат.
Можно продемонстрировать это на примере. Допустим у вас есть ориентированный граф, представленный в виде матрицы смежности . Это такая квадратная матрица из нулей и единиц, так что если элемент матрицы с индексом (i, j) равен единице, то существует грань от вершины графа i к вершине j. Вы хотите превратить этот ориентированный граф в неориентированный. То есть, если есть грань (i, j), то должна появиться противоположная грань (j, i). Обратите внимание, что если представить матрицу визуально, то элементы (i, j) и (j, i) являются симметричными относительно диагонали. Эту трансформацию нетрудно осуществить в коде:
void convert1(int size, int G[][size])
{
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++)
G[i][j] = G[i][j] | G[j][i];
}
Блокинг появляется естественным образом. Представьте перед собой большую квадратную матрицу. Теперь иссеките эту матрицу горизонтальными и вертикальными линиями, чтобы разбить ее, скажем, на 16 равных блока (четыре строки и четыре столбца). Выберите два любых симметричных блока. Обратите внимание, что все элементы в одном блоке имеют свои симметричные элементы в другом блоке. Это наводит на мысль , что ту же операцию можно совершать над этими блоками поочередно. В этом случае на каждом этапе мы будем работать только с двумя блоками. Если блоки сделать достаточно маленького размера, то они поместятся в кэше высокого уровня. Выразим эту идею в коде:
void convert2(int size, int G[][size])
{
int block_size = size / 12; // разбить на 12*12 блоков
// представим, что делится без остатка
for (int ii = 0; ii < size; ii += block_size) {
for (int jj = 0; jj < size; jj += block_size) {
int i_start = ii; // индекс i для блока принимает значения [ii, ii + block_size)
int i_end = ii + block_size;
int j_start = jj; // индекс j для блока принимает значения [jj, jj + block_size)
int j_end = jj + block_size;
// обходим блок
for (int i = i_start; i < i_end; i++)
for (int j = j_start; j < j_end; j++)
G[i][j] = G[i][j] | G[j][i];
}
}
}
Нужно заметить, что блокинг не улучшает производительность на системах с мощными процессорами, которые хорошо делают предвыборку. На системах, которые не делают предвыборки, блокинг может сильно увеличить производительность.
На машине с процессором Core i7 Haswell вторая функция не выполняется быстрее. На машине с более простым процессором Pentium 2117U вторая функция выполняется в 2 раза быстрее. На машинах, которые не выполняют предвыборку, производительность улучшилась бы еще сильнее.
Все знают из курсов по алгоритмам, что нужно выбирать хорошие алгоритмы с наименьшей сложностью и избегать плохих алгоритмов с высокой сложностью. Но эти сложности оценивают выполнение алгоритма на теоретической машине, созданной нашей мыслью. На реальных машинах теоретически плохой алгоритм может выполнятся быстрее теоретически хорошего. Вспомните, что получить данные из оперативной памяти занимает 200 тактов, а из кэша первого уровня 4 такта — это в 50 раз быстрее. Если хороший алгоритм часто трогает память , а плохой алгоритм размещает свои данные в кэше, хороший алгоритм может выполняться медленнее плохого. Также хороший алгоритм может выполняться на процессоре хуже, чем плохой. К примеру, хороший алгоритм вносит зависимость данных и не может загрузить конвеер процессора. А плохой алгоритм лишен этой проблемы и на каждом такте отправляет в конвеер новую инструкцию. Иными словами, сложность алгоритма это еще не все. Как алгоритм будем выполняться на конкретной машине с конкретными данными имеет значение.
Представим, что вам нужно реализовать очередь целых чисел, и новые элементы могут добавляться в любую позицию очереди. Вы выбираете между двумя реализациями: массив и связный список. Чтобы добавить элемент в середину массива, нужно сдвинуть вправо половину массива, что занимает линейное время. Чтобы добавить элемент в середину списка, нужно дойти по списку до середины, что также занимает линейное время. Вы думаете, что раз сложности у них одинаковые, то лучше выбрать список. Тем более у списка есть одно хорошее свойство . Список может расти без ограничения, а массив придется расширять, когда он заполнится.
Допустим, очередь длиной 1000 элементов мы реализовали обоими способами. И нам нужно вставить элемент в середину очереди. Элементы списка хаотично разбросаны по памяти, поэтому чтобы обойти 500 элементов, нам понадобится 500*200=100'000 тактов. Массив расположен в памяти последовательно, что позволит нам наслаждаться скоростью кэша первого уровня. Используя несколько оптимизаций, мы можем двигать элементы массива, тратя 1-4 такта на элемент. Мы сдвинем половину массива максимум за 500*4=2000 тактов. То есть быстрее в 50 раз.
Если в предыдущем примере все добавления были бы в начало очереди, реализация со связным списком была бы более эффективной. Если какая-то доля добавлений была бы куда-то в середину очереди , реализация в виде массива могла бы стать лучшим выбором. Мы бы тратили такты на одних операциях и экономили такты на других. И в итоге могли бы остаться в выигрыше.
Система памяти организована в виде иерархии устройств хранения с маленькими и быстрыми устройствами вверху иерархии и большими и медленными устройствами внизу. Программы с хорошей локальностью работают с данными из кэшей процессора. Программы с плохой локальностью работают с данными из относительно медленной оперативной памяти.
Программисты, которые понимают природу иерархии памяти, могут структурируют свои программы так, чтобы данные располагались как можно выше в иерархии и процессор получал их быстрее.
В частности, рекомендуются следующие техники:
сколько времени получить информацию из кеша первого уровня? 1 наносек
примерно за это же время выпролняется команда поступающая в процессор ....
Давайте посмотрим все варианты задержек, которые нужно учитвать при проектировании и эксплуатации программых комплексов.
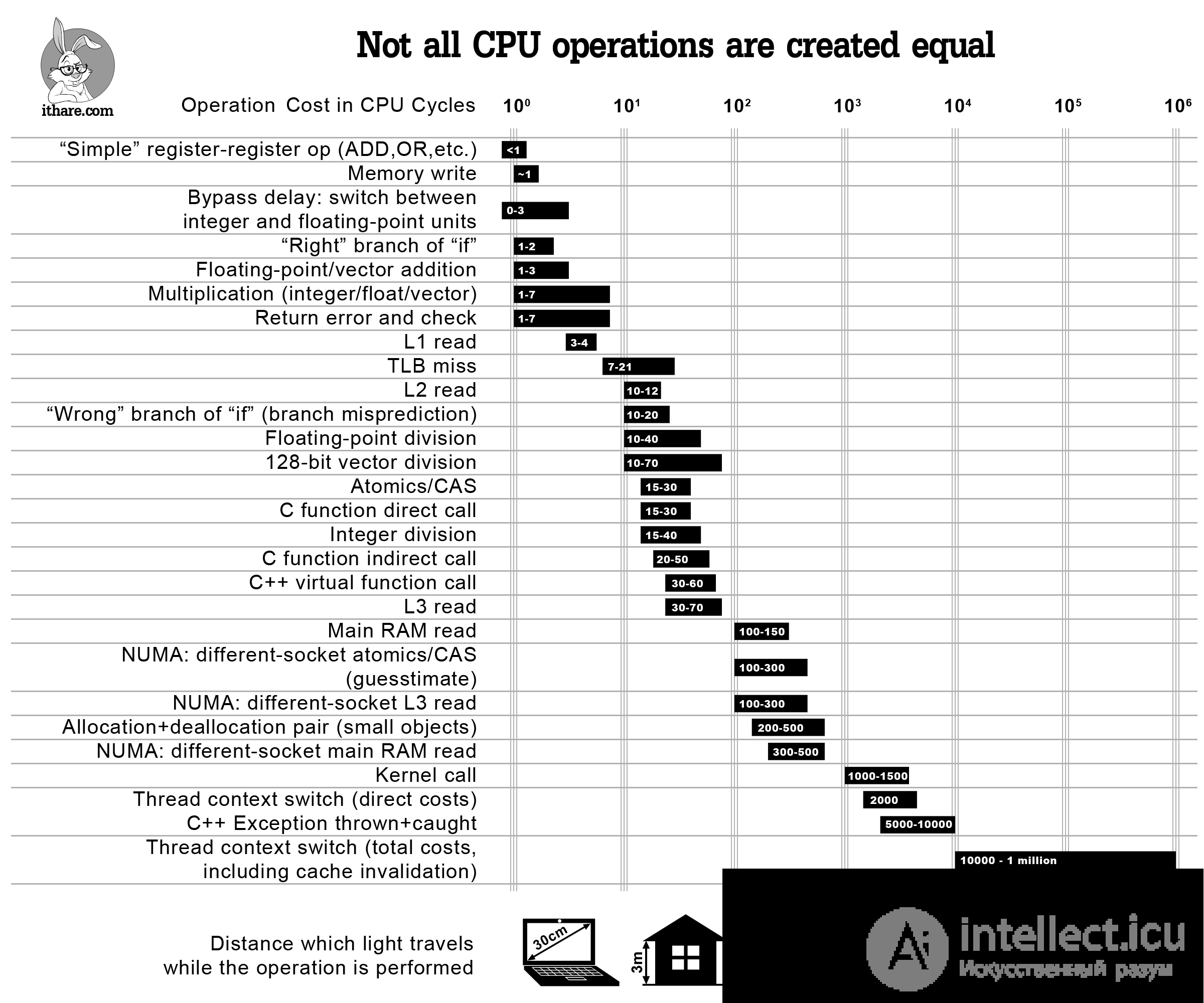
NB: масштаб логарифмический!
Преждевременная пессимизация Легко на себя, легко по коду: при прочих равных условиях, особенно в отношении сложности кода и удобочитаемости, некоторые эффективные шаблоны проектирования и идиомы кодирования должны просто естественным образом вытекать из ваших кончиков пальцев и писать их сложнее, чем пессимизированные альтернативы. Это не преждевременная оптимизация ; он избегает безнадежной пессимизации.- Херб Саттер, Андрей Александреску.Всякий раз, когда нам нужно оптимизировать код, мы должны профилировать его, просто и просто. Тем не менее, иногда имеет смысл просто знать номера шаров для относительных затрат на некоторые популярные операции, поэтому вы не будете делать крайне неэффективные вещи с самого начала (и, надеюсь, позже не понадобится профилировать программу ).
Итак, здесь идет речь - инфографика, которая должна помочь оценить затраты на определенные операции в цикле тактовых импульсов ЦП и отвечать на такие вопросы, как «эй, сколько обычно читается L2?». Хотя ответы на все эти вопросы более или менее известны, я не знаю ни одного места, где все они перечислены и представлены в перспективе. Также отметим, что, хотя перечисленные номера, строго говоря, применяются только к современным процессорам x86 / x64, ожидается, что аналогичные модели относительных эксплуатационных затрат будут наблюдаться на других современных процессорах с большими многоуровневыми кэшами (такими как ARM Cortex A или SPARC); с другой стороны, MCU (включая ARM Cortex M) различны, поэтому некоторые из шаблонов могут быть разными.
И последнее, но не менее важное: слово осторожности: все оценки здесь являются лишь показаниями на порядок; однако, учитывая масштаб различий между различными операциями, эти показания могут по-прежнему использоваться (по крайней мере, следует иметь в виду избегать «преждевременной пессимизации»).
С другой стороны, я все еще уверен, что такая диаграмма полезна, чтобы не говорить о том, что «эй, вызовы виртуальных функций ничего не стоят» - что может быть или не быть истинным в зависимости от того, как часто вы их называете. Вместо этого, используя инфографику выше, вы сможете увидеть, что
если вы вызываете свою виртуальную функцию 100K раз в секунду на процессоре 3GHz - это, вероятно, не будет стоить вам более 0,2% от общего объема вашего процессора; однако, если вы вызываете одну и ту же виртуальную функцию 10M раз в секунду, это легко означает, что виртуализация поглощает двузначные проценты вашего ядра процессора.
Другой способ приблизиться к одному и тому же вопросу - сказать, что «эй, я вызываю виртуальную функцию один раз за кусок кода, который составляет 10000 циклов, поэтому виртуализация не будет потреблять более 1% от времени программы», - но вы все равно нужен какой-то способ увидеть порядок величины связанных затрат - и приведенная выше диаграмма по-прежнему будет полезна .
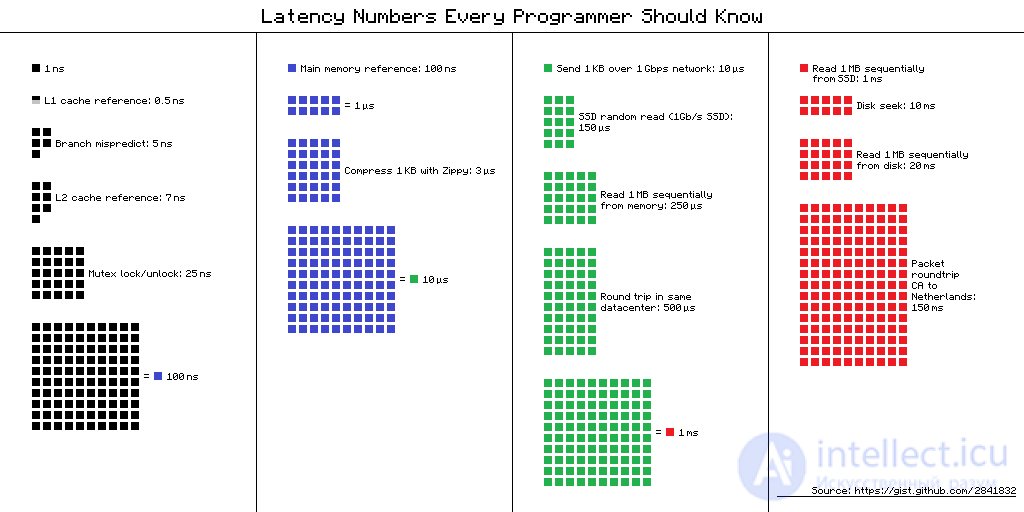
latency numbers every programmer should know
L1 cache reference ......................... 0.5 ns Branch mispredict ............................ 5 ns L2 cache reference ........................... 7 ns Mutex lock/unlock ........................... 25 ns Main memory reference ...................... 100 ns Compress 1K bytes with Zippy ............. 3,000 ns = 3 µs Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs SSD random read ........................ 150,000 ns = 150 µs Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs Round trip within same datacenter ...... 500,000 ns = 0.5 ms Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms Disk seek ........................... 10,000,000 ns = 10 ms Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
Assuming ~1GB/sec SSD
Выводы из данной статьи про оптимизация программ указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое оптимизация программ , latency numbers every programmer should know, задержки в передаче данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Часть 1 Методы оптимизации программ. Сравнение времен задержки на различных уровнях архитектуры
Часть 2 Вау!! 😲 Ты еще не читал? Это зря! - Методы оптимизации программ. Сравнение времен задержки на
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Термины: Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы