Лекция
Привет, Вы узнаете о том , что такое системные вызовы , Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое системные вызовы , диспетчеризация , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Возьмем сначала системные вызовы, которые можно описать так:
Ваша программа (в так называемом пользовательском пространстве) должна просить ядро операционной системы выполнить операцию ввода/вывода от имени вашей программы.
Системные вызовы — это способ, с помощью которого программа просит ядро что-то сделать. Специфика их реализаций зависит от ОС, но базовый принцип везде один и тот же. Должна быть какая-то конкретная инструкция для передачи управления из вашей программы через ядро (как вызов функции, только со специальной «добавкой» для работы в такой ситуации). В целом системные вызовы блокирующие, т. е. программа ждет, пока ядро не вернется к вашему коду.
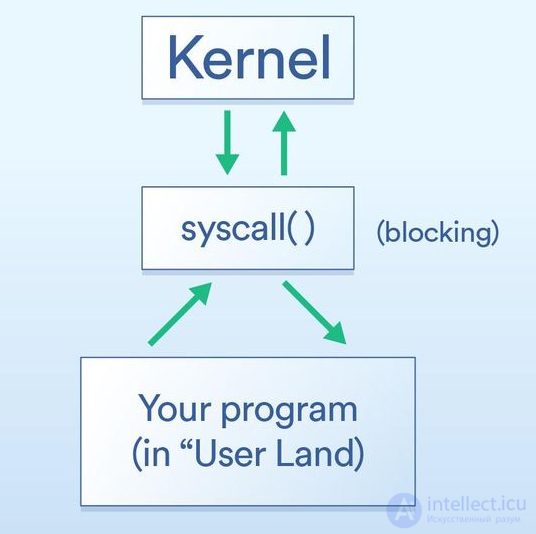
Выше говорилось, что системные вызовы — блокирующие, и в целом это так. Однако некоторые вызовы можно охарактеризовать как неблокирующие. Это означает, что ядро принимает ваш запрос, кладет его в очередь или какой-то буфер, а затем безо всякого ожидания немедленно возвращается к выполняемому в данный момент вводу/выводу. Так что «блокирование» происходит лишь на очень небольшой период времени, достаточный для постановки вашего запроса в очередь.
Чтобы было понятнее, вот некоторые примеры (системных вызовов Linux):
read() — блокирующий вызов: вы передаете ему дескриптор (handle), говорящий, какой файл взять и в какой буфер доставить считываемые данные; вызов возвращается, когда данные окажутся в месте назначения. Об этом говорит сайт https://intellect.icu . Все просто и понятно.epoll_create(), epoll_ctl() и epoll_wait() — вызовы, которые, соответственно, позволяют создавать группу дескрипторов для прослушивания; добавлять дескрипторы в группу / удалять их из нее; блокировать до тех пор, пока не появится активность. Это позволяет эффективно управлять большим количеством операций ввода/вывода с помощью одного потока выполнения. Хорошо, что есть такая функциональность, но ее довольно сложно использовать.
Важно понимать различия в тайминге. Если ядро процессора работает на частоте 3 ГГц, без каких-либо оптимизаций, то оно выполняет 3 миллиарда тактов в секунду (3 такта в наносекунду). Для неблокирующего системного вызова могут потребоваться десятки тактов, то есть несколько наносекунд. Вызов, блокирующий получение информации по сети, может выполняться гораздо дольше: например, 200 миллисекунд (1/5 секунды). То есть если неблокирующий вызов длится 20 наносекунд, то блокирующий — 200 миллионов наносекунд. Процесс ждет выполнения блокирующего вызова в 10 миллионов раз дольше.

Ядро предоставляет средства для выполнения как блокирующих («считай данные из сетевого подключения и дай их мне»), так и неблокирующих («скажи мне, когда в этих сетевых подключениях появятся новые данные») вводов/выводов. И в зависимости от выбранного механизма длительность блокировки вызывающего процесса будет разительно отличаться.
Диспетчеризация также крайне важна, если у вас есть много потоков выполнения или процессов, которые начинают блокировать.
Для нашей задачи разница между процессом и потоком выполнения невелика. В реальной жизни самое главное отличие между ними с точки зрения производительности заключается в том, что поток выполнения использует одну и ту же область памяти, а процессы получают собственные области. Поэтому отдельные процессы требуют гораздо больше памяти. Но если мы говорим о диспетчеризации, то все сводится к тому, сколько потокам и процессам нужно времени выполнения на доступных ядрах процессора. Если у вас есть 300 потоков и восемь ядер, то придется поделить время так, чтобы каждый поток получил свою долю: каждое ядро недолго выполняет один поток, а затем переходит к следующему. Это делается с помощью переключения контекста, когда процессор переключается с одного выполняемого потока/процесса на другой.
Но с этими переключениями контекста связаны определенные затраты — они занимают какое-то время. Иногда это может происходить меньше, чем за 100 наносекунд, но нередко переключение занимает 1000 наносекунд и больше, в зависимости от особенностей реализации, скорости/архитектуры процессора, его кеша и т. д.
И чем больше потоков выполнения (или процессов), тем больше переключений контекста. Если речь идет о тысячах потоков, когда на переключения с каждого из них уходят сотни наносекунд, то все выполняется очень неторопливо.
Однако неблокирующие вызовы по существу говорят ядру: «Вызови меня только тогда, когда появятся новые данные или событие в одном из этих подключений». Эти вызовы созданы для эффективной обработки большой нагрузки по вводу/выводу и уменьшения количества переключений контекста.
Исследование, описанное в статье про системные вызовы , подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое системные вызовы , диспетчеризация и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Из статьи мы узнали кратко, но содержательно про системные вызовы
Комментарии
Оставить комментарий
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Термины: Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы