Лекция
Привет, мой друг, тебе интересно узнать все про технологии социальных сетей, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое технологии социальных сетей , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Фильм "Социальная сеть" хорошо иллюстрирует феномен развития Facebook’а, сумевшего за рекордный срок собрать баснословную, немыслимую ранее аудиторию.
Однако за кадром осталась еще одна составляющая проекта — то, как он работает изнутри. Его техническое устройство.
Что такое Facebook сейчас? Лучше всего это демонстрируют сухие цифры:

Как же все это работает?
Можно по-разному относиться к социальным сетям вообще и к Facebook’у в частности, но с точки зрения технологичности это один из самых интересныхпроектов. Особенно приятно, что разработчики никогда не отказывались делиться опытом создания ресурса, выдерживающего подобные нагрузки. В этом есть большаяпрак тическая польза. Ведь в основе системы лежат общедоступные компоненты, которые можешь использовать ты, могу использовать я — они доступны каждому. Более того, многие из тех технологий, которые разрабатывались внутри Facebook’а, сейчас опубликованы с открытыми исходниками. И использовать их, опять же, может любой желающий. Разработчики социальной сети по возможности использовали лишь открытые технологии и философию Unix: каждый компонент системы должен быть максимально простым и производительным, при этом решение задач достигается путемих комбинирования. Все усилия инженеров направлены на масштабируемость, минимизацию количества точек отказа и, что самое важное, простоту. Чтобы не быть голословным, укажу основные технологии, которые сейчас используются внутри
Facebook:
Балансировщик нагрузки выбирает php-сервер для обработки каждого запроса, где HTML генерируется на основе различных источников (таких как MySQL, memcached) и специализированных сервисов. Таким образом, архитектура Facebook имеет традиционный трехуровневый вид:
Полагаю, что наиболее интересно будет услышать, как в проекте удалось использовать самые привычные технологии. И тут действительно есть немало
нюансов.
Что обычно происходит за 20 минут на Facebook?
- Люди публикуют 1 000 000 ссылок;
- Отмечают друзей на 1 323 000 фотографий;
- Приглашают 1 484 000 знакомых на мероприятия;
- Отправляют 1 587 000 сообщений на стену;
- Пишут 1 851 000 новых статусов;
- 2 000 000 пар людей становятся друзьями;
- Загружается 2 700 000 фотографий;
- Появляется 10 200 000 комментариев;
- Отправляется 4 632 000 личных сообщений.
Напрашивается вопрос: почему именно PHP? Во многом – просто "исторически сложилось". Он хорошо подходит для веб-разработки, легок в изучении и работе, для программистов доступен огромный ассортимент библиотек. К тому же существует огромное международное сообщество. Из негативных сторон можно назвать высокий расход оперативной памяти и вычислительных ресурсов. Когда объем кода стал слишком велик, к этому списку добавились слабая типизация, линейный ростизде ржек при подключении дополнительных файлов, ограниченные возможности для статичного анализа и оптимизации. Все это стало создавать большие трудности. По этой причине в Facebook была реализована масса доработок к PHP, в том числе оптимизация байт-кода, улучшения в APC (ленивая загрузка, оптимизация блокировок, "подогрев" кэша) и ряд собственных расширений (клиент memcache, формат сериализации, логи, статистика, мониторинг, механизм асинхронной
обработки событий).
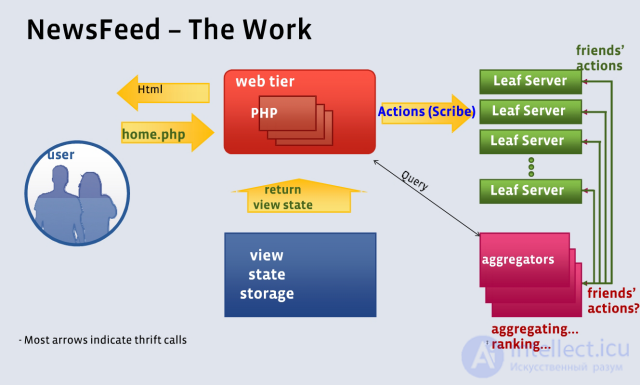
Схема формирования новостной ленты
Особого внимания заслуживает проект HipHop – это трансформатор исходного кода из PHP в оптимизированный C++. Принцип простой: разработчики пишут на PHP, который конвертируется в оптимизированный C++. В надстройке реализованы статический анализ кода, определение типов данных, генерация кода и многое другое. Также HipHop облегчает разработку расширений, существенно сокращает расходы оперативной памяти и вычислительных ресурсов. У команды из трех программистов ушло полтора года на разработку этой технологии, в частности была переписана большая часть интерпретатора и многие расширения языка PHP. Сейчас
коды HipHop опубликованы под opensource лицензией, пользуйся на здоровье.
Культура разработки Facebook
- Двигаться быстро и не бояться ломать некоторые вещи;
- большое влияние маленьких команд;
- быть откровенным и инновационным;
- возвращать инновации в opensource сообщество.
Теперь о базе данных. В отличие от подавляющего большинства сайтов, MySQL в Facebook используется как простое хранилище пар "ключ-значение". Большое количество логических баз данных распределено по физическим серверам, но репликация используется только между датацентрами. Балансировка нагрузки осуществляется перераспределением баз данных по машинам. Так как данные распределены практически случайным образом, никакие операции типа JOIN, объединяющие данные из нескольких таблиц, в коде не используются. В этом есть смысл. Ведь наращивать вычислительные мощности намного проще на веб-серверах,
чем на серверах баз данных.
В Facebook используется практически не модифицированный исходный код MySQL, но с собственными схемами партиционирования по глобально-уникальным идентификаторам и архивирования, основанного на частоте доступа к данным. Принцип очень эффективен, поскольку большинство запросов касаются самой свежей информации. Доступ к новым данным максимально оптимизирован, а старые записи автоматически архивируются. Помимо этого используются свои библиотеки для доступа к данным на основе графа, где объекты (вершины графа) могут иметь лишь ограниченный набор типов данных (целое число, строка ограниченной длины, текст),
а связи (ребра графа) автоматически реплицируются, образуя аналог распределенных внешних ключей.
Как известно, memcached — высокопроизводительная распределенная хэш-таблица. Facebook хранит в ней "горячие" данные из MySQL, что существенно снижает нагрузку на уровне баз данных. Используется более 25 Тб (только вдумайся в цифру) оперативной памяти на нескольких тысячах серверов при среднем времени отклика менее 250 мкс. Кэшируются сериализованные структуры данных PHP, причем из-за отсутствия автоматического механизма проверки консистенции данных между memcach d и MySQL приходится делать это на уровне программного кода. Основным способом использования memcache является множество multi-get запросов,используемых для получения данных на другом конце ребер графа.
Facebook очень активно занимаются доработкой проекта по вопросам производительности. Большинство из описанных ниже доработок были включены в opensource версию memcached: порт на 64-битную архитектуру, сериализация, многопоточность, компрессия, доступ к memcache через UDP (уменьшает расход памяти благодаря отсутствию тысяч буферов TCP-соединений). В дополнение были внесены некоторые изменения в ядро Linux для оптимизации работы memcache. Насколько это действенно? После вышеперечисленных модификаций memcached способен выполнять до 250 000 операций в секунду по сравнению со стандартными 30 000 — 40
000 в оригинальной версии.
Еще одной инновационной разработкой Facebook является проект Thrift. По сути, это механизм построения приложений с использованием нескольких языковпрограммирования. Основная цель — предоставить технологию прозрачного взаимодействия между разными технологиями программирования. Thrift предлагает разработчикам специальный язык описания интерфейсов, статический генератор кода, а также поддерживает множество языков, в том числе C++, PHP, Python, Java, Ruby, Erlang, Perl, Haskell. Возможен выбор транспорта (сокеты, файлы, буферы в памяти) и стандарта сериализации (бинарный, JSON). Поддерживаются различные типы серверов: неблокирующие, асинхронные, как однопоточные, так и многопоточные. Альтернативными технологиями являются SOAP, CORBA, COM, Pillar, Protocol Buffers, но у всех есть свои существенные недостатки, и это вынудило Facebook разработать свою собственную. Важное преимущество Thrift’а заключается в производительности. Он очень и очень быстрый, но даже это не главный его плюс. С появлением Thrift на разработку сетевых интерфейсов и протоколов уходит куда меньше времени. В Facebook технология входит в общий инструментарий, который знаком любому программисту. В частности, благодаря этому, удалось ввести четкое разделение труда: работа над высокопроизводительными серверами теперь ведется отдельно от работы над приложениями. Thrift, как и многие другие разработки Facebook, сейчас
находится в открытом доступе.
Возвращение инноваций
Возвращение инноваций общественности — важный аспект разработки в
Facebook. Компанией были опубликованы свои проекты:
Thrift,
Scribe,
Tornado,
Cassandra,
Varnish,
Hive,
xhprof.
Помимо этого были сделаны доработки для PHP, MySQL, memcached.Информация о взаимодействии Facebook с opensource-сообществом этих и
других проектов расположена на
странице, посвященной opensource.
Закончив на этом рассказывать об используемых технологиях, хочу привести подробности решения интересной задачки внутри социальной сети, а именно — организации хранения фотографий. Многих фотографий. Громадного количества фотографий. Это довольно интересная история. Сначала фотоальбомы пользователей были организованы по самому тривиальному сценарию:
Такой простой подход был необходим, чтобы сначала проверить, что продукт востребован пользователями, и они действительно будут активно загружать фотографии. Новая фича, как известно, "поперла". Но на практике оказалось, что файловые системы непригодны для работы с большим количеством небольших файлов. Метаданные не помещаются в оперативную память, что приводит к дополнительным обращениям к дисковой подсистеме. Ограничивающим фактором является ввод-вывод, а не плотность хранения. Первым шагом по оптимизации стало кэширование. Наиболее часто используемые миниатюры изображений кэшировались в памяти на оригинальных серверах для масштабируемости и производительности, а также распределялись по CDN (географически распределенной сетевой инфраструктуре) для уменьшения сетевых задержек. Это дало результат. Позже оказалось, что можно сделать еще лучше. Изображения стали хранить в больших бинарных файлах (blob), предоставляя приложению информацию о том, в каком файле и с каким отступом (по сути, идентификатором) от начала расположена каждая фотография. Такой сервис в Facebook получил название Haystack и оказался в десять раз эффективнее "простого" подхода и в три раза эффективнее "оптимизированного". Как говорится, все гениальное просто!
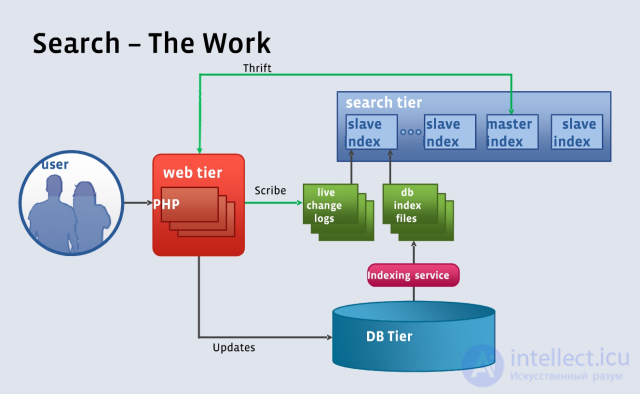
Принцип работы поиска в Facebook
Каждый хоть раз слышал о Google благодаря их всеобъемлющему, «умному» и быстрому поисковому сервису, но ни для кого не секрет, что они не ограничиваются только им. Их платформа для построения масштабируемых приложений позволяет выпускать множество удивительно конкурентноспособных интернет-приложений, работающих на уровне всего Интернета вцелом. Они ставят перед собой цель постоянно строить все более и более производительную и масштабируемую архитектуру для поддержки своих продуктов. Как же им это удается?
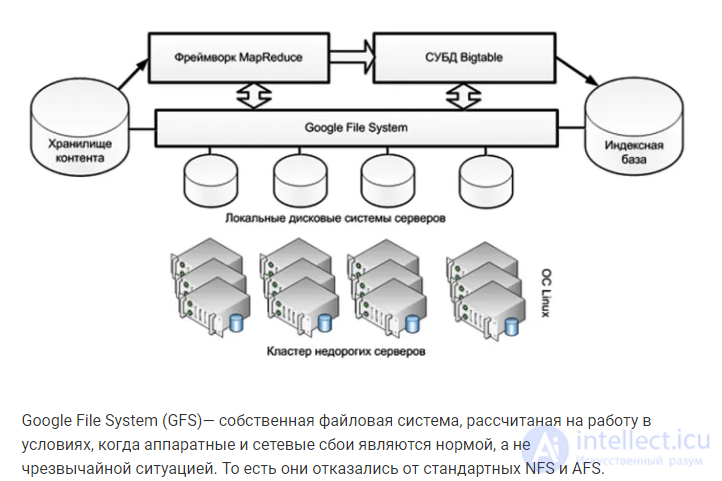
Google File System (GFS)— собственная файловая система, рассчитаная на работу в условиях, когда аппаратные и сетевые сбои являются нормой, а не чрезвычайной ситуацией. То есть они отказались от стандартных NFS и AFS.
Сразу хочу сказать, что эта запись является переводом с английского, автороригинальной версии — Todd Hoff. Оригинал написан приблизительно в середине 2007 года, но по-моему до сих пор очень даже актуально.
Далее следует перечисление источников информации из оригинала:
// Цифры не первой свежести конечно, но тоже неплохо.
Google визуализирует свою инфраструктуру в виде трехслойного стека:
– высокую надежность дата центров
– масштабируемость до тысяч сетевых узлов
– высокую пропускную способность операций чтения и записи
– поддержку больших блоков данных, размер которых может измеряться в гигабайтах
– эффективное распределение операций между датацентрами для избежания возникновения «узких мест» в системе
– Мастер-сервера хранят метаданные для всех файлов. Об этом говорит сайт https://intellect.icu . Сами данные хранятся блоками по 64 мегабайта на остальных серверах. Клиенты могут выполнять операции с метаданными на мастер-серверах, чтобы узнать на каком именно сервере расположены необходимые данные.
– Для обеспечения надежности один и тот же блок данных хранится в трех экземплярах на разных серверах, что обеспечивает избыточность на случай сбоев в работе какого-либо сервера.
– Новые приложения могут пользоваться как существующими кластерами, так и новыми, созданными специально для них.
– Ключ успеха заключается в том, чтобы быть уверенными в том, что у людей есть достаточно вариантов выбора для реализации их приложений. GFS может быть настроена для удовлетворения нужд любого конкретного приложения.
– Отличный способ распределения задач между множеством компьютеров
– Обработка сбоев в работе
– Работа с различными типами смежных приложений, таких как поиск или реклама. Возможно предварительное вычисление и обработка данных, подсчет количества слов, сортировка терабайт данных и так далее
– Вычисления автоматически приближаются к источнику ввода-вывода
– Master: назначают задания остальным типам серверов, а также следят за процессом их выполнения
– Map: принимают входные данные от пользователей и обрабатывают их, результаты записываются в промежуточные файлы
– Reduce: принимают промежуточные файлы от Map-серверов и сокращают их указанным выше способом
– Последовательность выполняемых действий выглядела бы следующим образом: GFS → Map → перемешивание → Reduce → запись результатов обратно в GFS
– Технология MapReduce состоит из двух компонентов: соответственно map и reduce. Map отображает один набор данных в другой, создавая тем самым пары ключ/значение, которпыми в нашем случае являются слова и их количества.
– В процессе перемешивания происходит аггрегирование типов ключей.
– Reduction в нашем случае просто суммирует все результаты и возвращает финальный результат.
– Master: распределяют таблицы по Tablet-серверам, а также следят за расположением таблиц и перераспределяют задания в случае необходимости.
– Tablet: обрабатывают запросы чтения/записи для таблиц. Они раделяют таблицы, когда те превышают лимит размера (обычно 100-200 мегабайт). Когда такой сервер прекращает функционирование по каким-либо причинам, 100 других серверов берут на себя по одной таблице и система продолжает работать как-будто ничего не произошло.
– Lock: формируют распределенный сервис ограничения одновременного доступа. Операции открытия таблицы для записи, анализа Master-сервером или проверки доступа должны быть взаимноисключающими.
Архитектура Google была одной из первых статьей на Insight IT. Именно она дала толчок развитию проекта: после ее публикации посещаемость блога увеличилась в десятки раз и появились первые сотни подписчиков. Прошли годы, информация устаревает стремительно, так что пришло время взглянуть на Google еще раз, теперь уже с позиции конца 2011 года. Что мы увидим нового в архитектуре интернет-гиганта?

рис гиперинформационнная эпока вызванная развитием социальных сетей
Google — огромная интернет-компания, неоспоримый лидер на рынке поиска в Интернет и владелец большого количества продуктов, многие из которых также добились определенного успеха в своей нише.
В отличии от большинства интернет-компаний, которые занимаются лишь одним продуктом (проектом), архитектура Google не может быть представлена как единое конкретное техническое решение. Сегодня мы скорее будем рассматривать общую стратегию технической реализации интернет-проектов в Google, возможно слегка затрагивая и другие аспекты ведения бизнеса в Интернет.
Все продукты Google основываются на постоянно развивающейся программной платформе, которая спроектирована с учетом работы на миллионах серверов, находящихся в разных датацентрах по всему миру.
Обеспечение работы миллиона серверов и расширение их парка — одна из ключевых статей расходов Google. Для минимизации этих издержек очень большое внимание уделяется эффективности используемого серверного, сетевого и инфраструктурного оборудования.
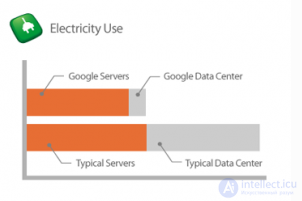
В традиционных датацентрах потребление электричества серверами примерно равно его потреблению остальной инфраструктурой, Google же удалось снизить процент использования дополнительной электроэнергии до 14%. Таким образом суммарное энергопотребление датацентром Google сравнимо с потреблением только серверов в типичном датацентре и вдвое меньше его общего энергопотребления. Основные концепции, которые используются для достижения этого результата:
В Google активно пропагандируют максимальное использование возобновляемой энергии. Для этого заключаются долгосрочные соглашения с ее поставщиками (на 20 и более лет), что позволяет отрасли активно развиваться и наращивать мощности. Проекты по генерации возобновляемой энергии, спонсируемые Google, имеют суммарную мощность более 1.7 гигаватт, что существенно больше, чем используется для работы Google. Этой мощности хватило бы для обеспечения электричеством 350 тысяч домов.
Если говорить о жизненном цикле оборудования, то используются следующие принципы:
Google известны за свои эксперименты и необычные решения в области серверного оборудования и инфраструктуры. Некоторые запатентованы; какие-то прижились, какие-то — нет. Подробно останавливаться на них не буду, лишь вкратце о некоторых:
В заключении этого раздела хотелось бы взглянуть правде в глаза: идеального оборудования не бывает. У любого современного устройства, будь то сервер, коммутатор или маршрутизатор, есть шанс прийти в негодность из-за производственного брака, случайного стечения обстоятельств или других внешних факторов. Если умножить этот, казалось бы, небольшой шанс на количество оборудования, которое используется в Google, то окажется, что чуть ли не каждую минуту из строя выходит одно, или несколько, устройств в системе. На оборудование полагаться нельзя, по-этому вопрос отказоустойчивости переносится на плечи программной платформы, которую мы сейчас и рассмотрим.
В Google очень рано столкнулись с проблемами ненадежности оборудования и работы с огромными массивами данных. Программная платформа, спроектированная для работы на многих недорогих серверах, позволила им абстрагироваться от сбоев и ограничений одного сервера.
Основными задачами в ранние годы была минимизация точек отказа и обработка больших объемов слабоструктурированных данных. Решением этих задач стали три основных слоя платформы Google, работающие один поверх другого:
Такая комбинация, дополненная другими технологиями, довольно долгое время позволяла справляться с индексацией Интернета, пока… скорость появления информации в Интернете не начала расти огромными темпами из-за «бума социальных сетей». Информация, добавленная в индекс даже через полчаса, уже зачастую становилась устаревшей. В дополнение к этому в рамках самого Google стало появляться все больше продуктов, предназначенных для работы в реальном времени.
Спроектированные с учетом совершенно других требований Интернета пятилетней давности компоненты, составляющие ядро платформы Google, потребовали фундаментальной смены архитектуры индексации и поиска, который около года назад был представлен публике под кодовым названием Google Caffeine. Новые, переработанные, версии старых «слоев» также окрестили броскими именами, но резонанса у технической публики они вызвали намного меньше, чем новый поисковый алгоритм в SEO-индустрии.
Новая архитектура GFS была спроектирована для минимизации задержек при доступе к данным (что критично для приложений вроде GMail и YouTube), не в ущерб основным свойствам старой версии: отказоустойчивости и прозрачной масштабируемости.
В оригинальной же реализации упор был сделан на повышение общей пропускной способности: операции объединялись в очереди и выполнялись разом, при таком подходе можно было прождать пару секунд еще до того, как первая операция в очереди начнет выполняться. Помимо этого в старой версии было большое слабое место в виде единственно мастер-сервера с метаданными, сбой в котором грозил недоступностью всей файловой системы в течении небольшого промежутка времени (пока другой сервер не подхватит его функции, изначально это занимало около 5 минут, в последних версиях порядка 10 секунд) — это также было вполне допустимо при отсутствии требования работы в реальном времени, но для приложений, напрямую взаимодействующих с пользователями, это было неприемлемо с точки зрения возможных задержек.
Основным нововведением в Colossus стали распределенные мастер-сервера, что позволило избавиться не только от единственной точки отказа, но и существенно уменьшить размер одного блока с данными (с 64 до 1 мегабайта), что в целом очень положительно сказалось на работе с небольшими объемами данных. В качестве бонуса исчез теоретический предел количества файлов в одной системе.
Детали распределения ответственности между мастер-серверами, сценариев реакции на сбои, а также сравнение по задержкам и пропускной способности обоих версий, к сожалению, по-прежнему конфиденциальны. Могу предположить, что используется вариация на тему хэш-кольца с репликацией метаданных на ~3 мастер-серверах, с созданием дополнительной копии на следующем по кругу сервере в случае в случае сбоев, но это лишь догадки. Если у кого-то есть относительно официальная информация на этот счет — буду рад увидеть в комментариях.
По прогнозам Google текущий вариант реализации распределенной файловой системы «уйдет на пенсию» в 2014 году из-за популяризации твердотельных накопителей и существенного скачка в области вычислительных технологий (процессоров).
MapReduce отлично справлялся с задачей полной перестройки поискового индекса, но не предусматривал небольшие изменения, затрагивающие лишь часть страниц. Из-за потоковой, последовательной природы MapReduce для внесения изменений в небольшую часть документов все равно пришлось бы обновлять весь индекс, так как новые страницы непременно будут каким-то образом связаны со старыми. Таким образом задержка между появлением страницы в Интернете и в поисковом индексе при использовании MapReduce была пропорциональна общему размеру индекса (а значит и Интернета, который постоянно растет), а не размеру набора измененных документов.
Ключевые архитектурные решения, лежащие в основе MapReduce, не позволяли повлиять на эту особенность и в итоге система индексации была построена заново с нуля, а MapReduce продолжает использоваться в других проектах Google для аналитики и прочих задач, по прежнему не связанных с реальным временем.
Новая система получила довольно своеобразное название Percolator, попытки узнать что оно значит приводит к различным устройствам по фильтрации дыма, кофеваркам и непойми чему еще. Но наиболее адекватное объяснение мне пришло в голову, когда я прочитал его по слогам: per col — по колонкам.
Percolator представляет собой надстройку над BigTable, позволяющую выполнять комплексные вычисления на основе имеющихся данных, затрагивающие много строк и даже таблиц одновременно (в стандартном API BigTable это не предусмотрено).
Веб-документы или любые другие данные изменяются/добавляются в систему посредством модифицированного API BigTable, а дальнейшие изменения в остальной базе осуществляются посредством механизма »обозревателей». Если говорить в терминах реляционных СУБД, то обозреватели — что-то среднее между триггерами и хранимыми процедурами. Обозреватели представляют собой подключаемый к базе данных код (наC++), который исполняется в случае возникновении изменений в определенных колонкахBigTable (откуда, видимо, и пошло название). Все используемые системой метаданные также хранятся в специальных колонках BigTable. При использовании Percolator все изменения происходят в транзакциях, удовлетворяющих принципу ACID, каждая из которых затрагивает именно те сервера в кластере, на которых необходимо внести изменения. Механизм транзакций на основе BigTable разрабатывался в рамках отдельного проекта под названием Google Megastore.
Таким образом, при добавлении нового документа (или его версии) в поисковый индекс, вызывается цепная реакция изменений в старых документах, скорее всего ограниченная по своей рекурсивности. Эта система при осуществлении случайного доступа поддерживает индекс в актуальном состоянии.
В качестве бонуса в этой схеме удалось избежать еще двух недостатков MapReduce:
Но все это оказалось не бесплатно: при переходе на новую систему удалось достичь той же скорости индексации, но при этом использовалось вдвое больше вычислительных ресурсов. Производительность Percolator находится где-то между производительностью MapReduce и производительностью традиционных СУБД. Так как Percolator является распределенной системой, для обработки фиксированного небольшого количества данных ей приходится использовать существенно больше ресурсов, чем традиционной СУБД; такова цена масштабируемости. По сравнению с MapReduce также пришлось платить дополнительными потребляемыми вычислительными ресурсами за возможность случайного доступа с низкой задержкой.
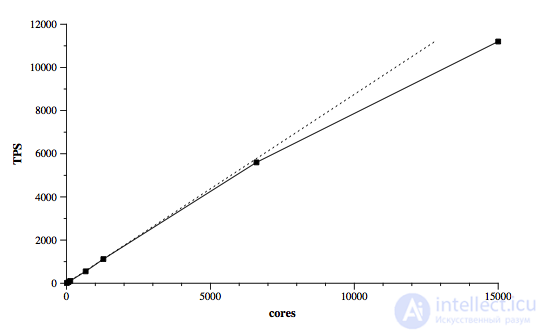
Тем не менее, при выбранной архитектуре Google удалось достичь практически линейного масштабирования при увеличении вычислительных мощностей на много порядков (см. график, основан на тесте TPC-E). Дополнительные накладные расходы, связанные с распределенной природой решения, в некоторых случаях до 30 раз превосходят аналогичный показатель традиционных СУБД, но у данной системы есть солидный простор для оптимизации в этом направлении, чем Google активно и занимается.
Spanner представляет собой единую систему автоматического управления ресурсамивсего парка серверов Google.
Основные особенности:
Проектировалась из расчета на:
Об этом проекте Google известно очень мало, официально он был представлен публике лишь однажды в 2009 году, с тех пор лишь местами упоминался сотрудниками без особой конкретики. Точно не известно развернута ли эта система на сегодняшний день и если да, то в какой части датацентров, а также каков статус реализации заявленного функционала.
Платформа Google в конечном итоге сводится к набору сетевых сервисов и библиотек для доступа к ним из различных языков программирования (в основном используются C/C++, Java, Python и Perl). Каждый продукт, разрабатываемый Google, в большинстве случаев использует эти библиотеки для осуществления доступа к данным, выполнения комплексных вычислений и других задач, вместо стандартных механизмов, предоставляемых операционной системой, языком программирования или opensource библиотеками.
Вышеизложенные проекты составляют лишь основу платформы Google, хотя она включает в себя куда больше готовых решений и библиотек, несколько примеров из публично доступных проектов:
Не гарантирую достоверность всех нижеизложенных источников информации, ставших основой для данной статьи, но ввиду конфиденциальности подобной информации на большее рассчитывать не приходится.
Поправки и уточнения приветствуются ![]()
Не секрет, что стек LAMP эффективен и пригоден для создания самых сложных систем, но при этом далеко не идеален. Конечно, PHP+MySQL+Memcache решают большинство задач, но далеко не все. Каждый крупный проект сталкивается с тем, что:
Facebook’у (да и любым другим крупным проектам) приходится разрабатывать собственные внутренние сервисы, чтобы компенсировать недостатки основных технологий, перенести исполняемый код ближе к данным, сделать ресурсоемкие части кода более эффективными, реализовать преимущества, которые доступны только в определенных языках программирования. Молниеносная обработка запросов от чудовищного количества пользователей достигается за счет комплексного подхода к распределению запросов по тысячам серверов и непрерывной работе над устранением узких мест в системе. В компании есть много небольших команд с полномочиями принимать важные решения, что в совокупности с короткими циклами разработки позволяет очень быстро двигаться вперед и оперативно решать все проблемы.
Результат проверить несложно. Открой facebook.com.
Для управления такой огромной системой в Facebook’е были созданы различные дополнительные сервисы. Всего их более пятидесяти, приведу несколько примеров:
Если я не полностью рассказал про технологии социальных сетей? Напиши в комментариях Надеюсь, что теперь ты понял что такое технологии социальных сетей и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Комментарии
Оставить комментарий
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Термины: Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы