Лекция
Привет, сегодня поговорим про numa, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое numa, ccnuma, недостатки компьютеров с общей и распределенной памятью , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Для компьютеров с общей памятью проще создавать параллельные программы, но их максимальная производительность сильно ограничивается небольшим числом процессоров. Для компьютеров с распределенной памятью все наоборот. Одним из возможных направлений объединения достоинств этих двух классов является проектирование компьютеров с архитектурой NUMA (Non Uniform Memory Access).
NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется ее расположением по отношению к процессору.
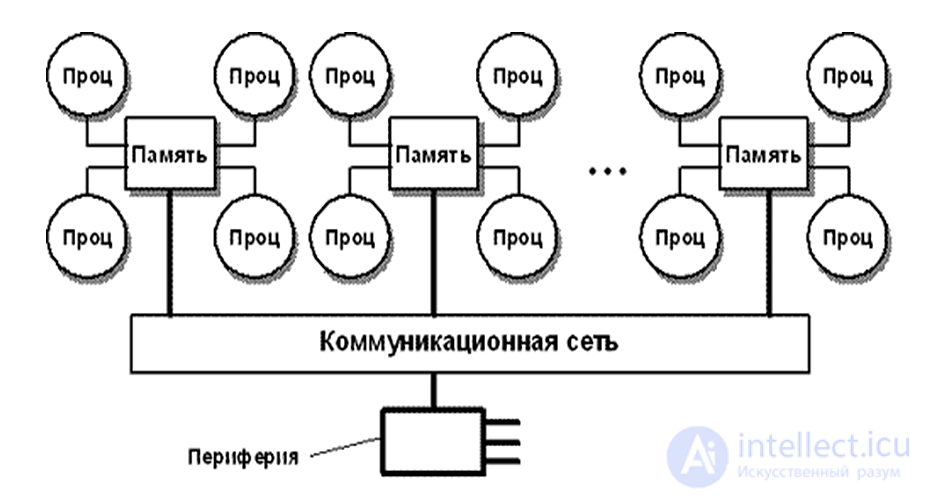
Данный компьютер состоит из набора кластеров, соединенных друг с другом через межкластерную шину. Каждый кластер объединяет процессор, контроллер памяти, модуль памяти и иногда некоторые устройства ввода/вывода, соединенные между собой посредством локальной шины. Когда процессору нужно выполнить операции чтения или записи, он посылает запрос с нужным адресом своему контроллеру памяти. Контроллер анализирует старшие разряды адреса, по которым и определяет, в каком модуле хранятся нужные данные. Если адрес локальный, то запрос выставляется на локальную шину, в противном случае запрос для удаленного кластера отправляется через межкластерную шину. В таком режиме программа, хранящаяся в одном модуле памяти, может выполняться любым процессором системы. Единственное различие заключается в скорости выполнения. Все локальные ссылки отрабатываются намного быстрее, чем удаленные. Поэтому и процессор того кластера, где хранится программа, выполнит ее на порядок быстрее, чем любой другой.
NUMA - архитектура / Проблема неоднородности доступа
Простая конфигурация с архитектурой NUMA
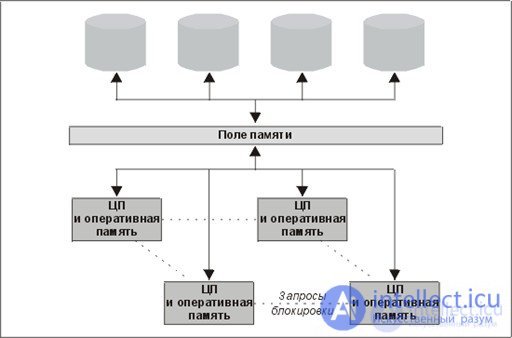
NUMA - архитектура
NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной кэш-памяти у каждого процессорного элемента Кэш-память для многопроцессорных систем оказывается узким местом
Объяснение: Если процессор Р1 сохранил значение X в ячейке q, а затем процессор Р2 хочет прочитать содержимое той же ячейки q . Об этом говорит сайт https://intellect.icu . Об этом говорит сайт https://intellect.icu . Процессор Р2 получит результат отличный от X, так как X попало в кэш процессора Р1. Эта проблема носит название проблемы согласования содержимого кэш-памяти
Решение: Архитектура ccNUMA
проблема неоднородности доступа
Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями), что в свою очередь требует от пользователя понимания неоднородности архитектуры. Если обращение к памяти другого узла требует на 5-10% больше времени, чем обращение к своей памяти, то это может и не вызвать никаких вопросов. Большинство пользователей будут относиться к такой системе, как к UMA (SMP), и практически все разработанные для SMP программы будут работать достаточно хорошо. Однако для современных NUMA систем это не так, и разница времени локального и удаленного доступа лежит в промежутке 200-700%.
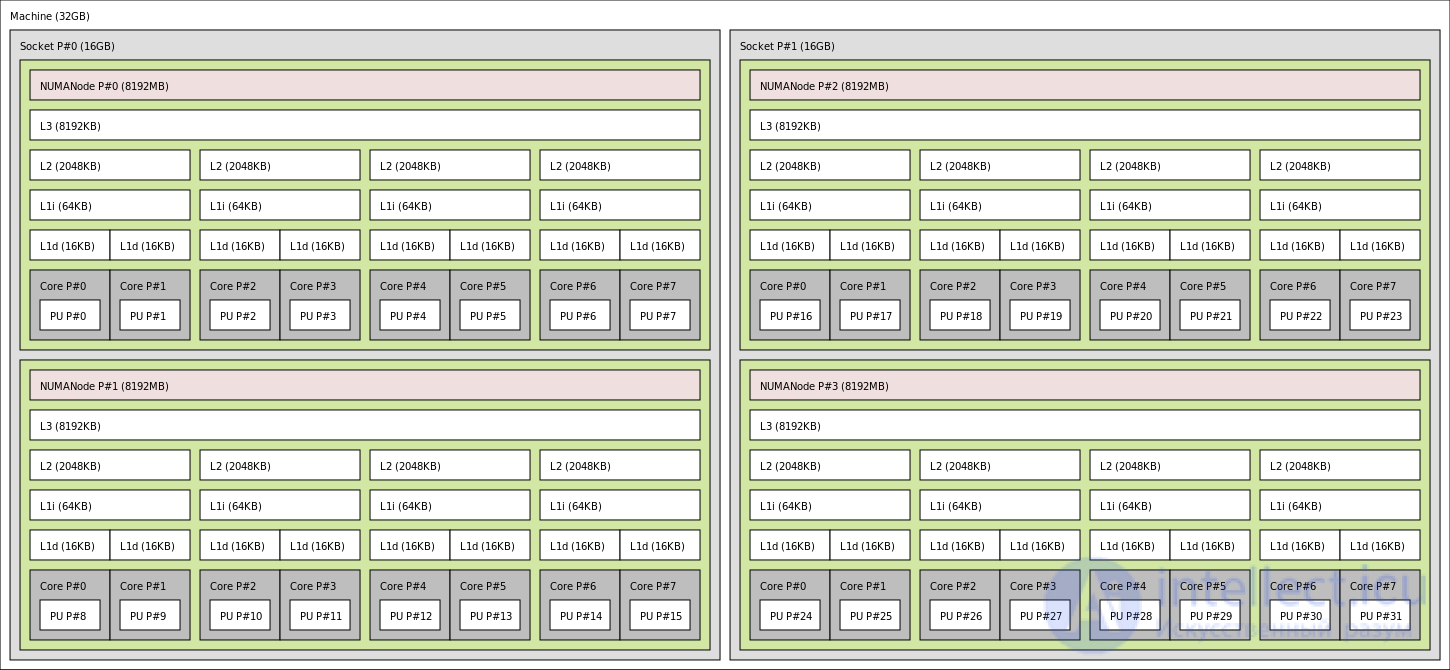
Почти все архитектуры ЦП используют небольшой объем очень быстрой не разделяемой памяти, известной как кеш, чтобы использовать локальность ссылок при доступе к памяти. При использовании NUMA поддержание согласованности кэша в общей памяти связано со значительными накладными расходами. Несмотря на то, что их проще спроектировать и построить, некогерентные системы NUMA становятся чрезмерно сложными для программирования в стандартной модели программирования архитектуры фон Неймана .
Как правило, ccNUMA использует межпроцессорную связь между контроллерами кеш-памяти, чтобы поддерживать согласованный образ памяти, когда более одного кеша хранят одно и то же место в памяти. По этой причине ccNUMA может плохо работать, когда несколько процессоров пытаются получить доступ к одной и той же области памяти в быстрой последовательности. Поддержка NUMA в операционных системах пытается снизить частоту такого рода доступа, выделяя процессоры и память удобными для NUMA способами и избегая алгоритмов планирования и блокировки, которые делают необходимым доступ, недружественный к NUMA.
В качестве альтернативы, протоколы когерентности кэша, такие как протокол MESIF, пытаются уменьшить обмен данными, необходимыми для поддержания когерентности кеша. Масштабируемый когерентный интерфейс (SCI) - это стандарт IEEE, определяющий протокол согласованности кэша на основе каталогов, чтобы избежать ограничений масштабируемости, обнаруженных в более ранних многопроцессорных системах. Например, SCI используется в качестве основы для технологии NumaConnect.
По состоянию на 2011 год системы ccNUMA представляют собой многопроцессорные системы на базе процессора AMD Opteron , который может быть реализован без внешней логики, и процессора Intel Itanium, для которого требуется, чтобы набор микросхем поддерживал NUMA. Примерами наборов микросхем с поддержкой ccNUMA являются SGI Shub (Super hub), Intel E8870, HP sx2000 (используется в серверах Integrity и Superdome) и те, которые используются в системах NEC на базе Itanium. Более ранние системы ccNUMA, такие как системы Silicon Graphics, были основаны на процессорах MIPS и процессоре DEC Alpha 21364 (EV7).
Можно рассматривать NUMA как сильно связанную форму кластерных вычислений . Добавление подкачки виртуальной памяти к архитектуре кластера может позволить реализовать NUMA полностью программно. Однако межузловая задержка программной NUMA остается на несколько порядков больше (медленнее), чем у аппаратной NUMA.
основные классы современных параллельных компьютеров системы с неоднородным доступом к памяти numa ,
В общем, мой друг ты одолел чтение этой статьи об numa. Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое numa, ccnuma, недостатки компьютеров с общей и распределенной памятью и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Из статьи мы узнали кратко, но содержательно про numa
Комментарии