Лекция
Привет, сегодня поговорим про системы с общей памятью на е openmp, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое системы с общей памятью на е openmp , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
при создании параллельных программ для SMPсистемиспользуют многопоточное программирование при помощи:
•нитей (потоков, threads)
•директивы OpenMP
директивы ОрепМР-специальныедирективы для компиляторов
•директивы используются для выделения участковкода, которые нужно распараллелить (фрагменты)
•в параллельных фрагментах код делится на потоки
•потоки выполняются отдельно
программа —набор из последовательныхи параллельныхучастков кода (вилочныйfork-join или пульсирующийпараллелизм).
OpenMPвходитвсоставкомпилятораgccначинаясверсии4.2,атакжевMSVisualStudioверсии2008ивыше.
ЕсликомпиляторвдругнеподдерживаетOpenMP,директивыигнорируютсяипрограммавыполняетсякакобычная(последовательная).
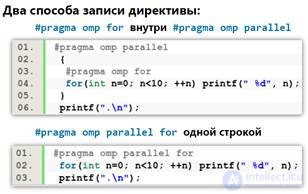
Используетспециальныедирективы#pragma,передучасткомкода,которыйнеобходимораспараллелить
Директивывнесколькострокразделяются«\»
#pragmaompparallelforshared(a)\
private(i,j,sum)\
schedule(dynamic,CHUNK)
директива parallel используется для выделения параллельных фрагментов
#pragmaompparallel
<блок_программы>
слово ompобязательно для всех директивOpenMP.
блок программы –statementили compoundstatement{…}.
правило для блока: один вход\один выход
порядок работы программы с директивой:
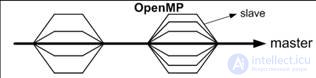
создается набор (team) из N потоков(исходный поток имеет номер 0 и называется master);
блок программы дублируется или разделяется между потоками для параллельного выполнения;
в конце происходит синхронизация –ожидается завершение всех потоков, после чего все потоки завершаются и дальше работает master.
Параметр num_threadsпозволяет указать количество создаваемых потоков.
Стандарт негарантируетсоздание указанного количества потоков (в случае указания очень больших значений).
Количество дополнительно создаваемых потоков –<указанное_значение>-1 (т.к. Об этом говорит сайт https://intellect.icu . есть master-поток).
если количество потоков не указано, то их будет создано столько, чтобы их общее количество =количеству вычислительных элементов(ядер или процессоров).
Каждый поток имеет свой стеки счетчиккоманд(поток может иметь локальные переменные).
Переменные –локальные (private) или общие (shared).
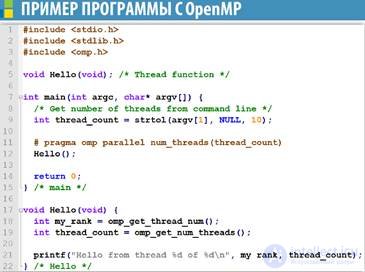
Стандартная функция OpenMP
•omp_get_thread_numвозвращает idпотока (от 0 до n-1);
•omp_get_num_threadsвозвращает количествопотоков.
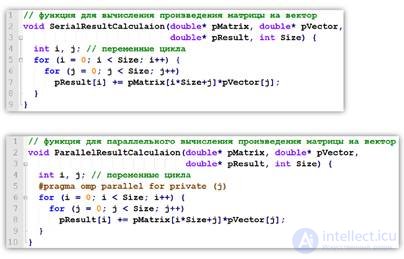
директива parallelforиспользуется для распараллеливания цикла for.
цикл forобязательнодолжен идти сразу за директивой.
КАЖДЫЙ ПОТОК ВЫПОЛНЯЕТ ЧАСТЬ ИТЕРАЦИЙ ЦИКЛА!
Каждый поток получает по ~1\n итераций цикла по порядку id(masterвыполнит первые 1\nитераций, поток с id=1 выполнит следующие 1\nитераций и т.д.
Счетчик цикла всегдалокальная переменная.

Распараллеливаются только циклы for(whileили do-whileне распараллеливаются).
Количество итерацийдолжно быть точноизвестнозаранее. Циклы типа
for ( ; ; ) { … }
или
for (i=0; i<n;i++) {
if (…) break;
…
}
распараллелить нельзя.
Распараллеливаются циклы только в канонической форме:
•счетчик цикла –intили указатель;
•начало, окончание и инкремент должны быть совместимыми типами (если счетчик –указатель, то инкремент –int).
•начало, окончание и инкремент не должны меняться в теле цикла.
•счетчик цикла не должен изменяться в теле цикла

Если результат вычислений в цикле зависит от результата одной или нескольких предыдущих итераций (рекурсия, динамическое программирование), то результат будет некорректным.
Программа для вычисления числа Фибоначчи выдаст некорректный и каждый раз новый результат.

OpenMPне проверяет зависимости между итерациями в цикле. Этим должнызаниматься программисты.
Цикл, в котором результаты одного или нескольких итераций зависят от других итераций, не могут корректно быть распараллелены с помощью OpenMP.
Ситуацию, когда вычисление fibo[6] зависит от вычисления fibo[5] называют зависимостью данных.
Зависимость данных может существовать внутри одной итерации, но не может внутри разных итераций.
привет программы OpenMP



В общем, мой друг ты одолел чтение этой статьи об системы с общей памятью на е openmp. Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое системы с общей памятью на е openmp и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Из статьи мы узнали кратко, но содержательно про системы с общей памятью на е openmp
Комментарии