Привет, сегодня поговорим про cистемы с распределенной памятью, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое
cистемы с распределенной памятью, mpi , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
. Об этом говорит сайт https://intellect.icu
Для систем с распределенной памятью широкоприменяется интерфейс MPI—Message Passing Interface.
- Используютсяи другие:PMV(Parallel Virtual Machine) или SHMEM.
- MPI основан на механизме передачии приемки сообщений.
- MPI является распространенной средой для создания и выполнения параллельных программ.
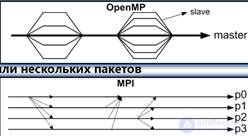
Message Passing
- Метод передачи данных из памяти одногопроцессора в память другого
- Данные пересылаются в виде пакетов
- Сообщение может состоять из одного илинескольких пакетов
- Пакеты обычно содержат информацию роутингаи управления
Process:
- Набор исполняемых команд (программа)
- На процессоре может выполняться один или несколько процессов
- Процессы обмениваются информацией только с помощью сообщений
- Для повышения производительности желательно каждый процесс запускать на отдельном процессоре
- На многоядерной ПЭВМ процессы могут выполняться на отдельных ядрах
Message PassingLibrary
- Коллекция функций, используемых программой
- Предназначены для передачи, приема и обработки сообщений
- Среда выполнения параллельных программ

Send / Receive
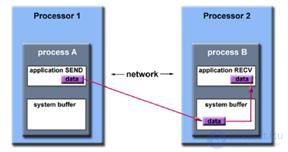
- При передаче данных требуется взаимодействие двух процессоров -передатчика и приемника
- Передатчик определяет положение данных, размер, тип, получателя
- Приемник должен соответствовать передаваемым данным

Synchronous/ Asynchronous
- Синхронная передача завершается только послеподтверждения приемника о получениисообщения.
- Асинхронная передача выполняется безквитирования (менее надежно)
ApplicationBuffer
- Адресное пространство, содержащее данные, подлежащие передаче или приему (например,область памяти данных, хранящая некоторуюпеременную)
SystemBuffer
- Системная область памяти для хранения сообщений
- В зависимости от типа сообщения данные из ApplicationBufferмогут копироваться в SystemBufferи наоборот
BlockingCommunication
- Функция завершается только после некоторого события
Non-blockingCommunication
- Функция завершается без ожидания каких-либо коммуникационных событий
- Использование системного буфера после выполнения неблокирующей операции передачи ОПАСНО!
CommunicatorsandGroups
- Специальные объекты, определяющие, какие процессы могут обмениваться данными.
- Процесс может входить в группу
- Группа обменивается данными с помощью коммуникатора
- В пределах группы процесс получает уникальный номер (идентификаторы)
- Процесс может входить в несколько групп (разные идентификаторы!)
- Сообщения, отправленные в разных коммуникаторах, не мешают друг другу
Поддерживает 2 стиля программирования:
MIMD -MultipleInstructionsMultipleData
- •Процессы выполняют разный программный код
- •Очень сложно писать и отлаживать
- •Сложно синхронизировать и управлять взаимодействием процессов
SPMD -SingleProgramMultipleData
- •Самый распространенный вариант
- •Все процессы выполняют одинаковый программный код


MPI представляет собой как набор библиотек, так и среду выполнения
- Компиляция и компоновка с помощью скрипта mpicc
mpiccMPI_Hello.c-o MPI_Hello
- Запуск программы на исполнение с использованием 5 процессов
mpiexec-n 5 MPI_Helloс
- Добавление адресов узлов делается параметрами “-hosts”, “-nodes”, “-hostfile”:
mpiexec–hosts 10.2.12.5 10.2.12.6
Набор функций MPIдля обмена данными между группами процессов
Особенности:
- в режиме приема-передачи работают все процессы
- коллективная функция работает одновременно и на прием, и на передачу
- значения всех параметров во всех процессах (кроме адреса буфера) должны совпадать
Включают:
- MPI_Bcast()–широковещательная рассылка сообщения
- MPI_SCATTER() –раздача данных разным процессам
- MPI_Gather()–сбор данных из всех процессов в один процесс
- MPI_Allgather()–сбор данных из всех процессов во все процессы
- intMPI_Barrier()–точка синхронизации
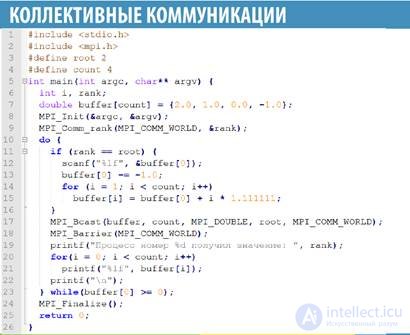
MPI_Bcast(*buffer,count,datatype,root,comm)
- buffer -буфер данных
- count -счетчик передаваемых данных
- datatype -тип данных
- root -процесс-источник данных
- comm-коммуникатор
MPI_Barrier(comm)
- Приостанавливает процесс до момента, когда всепроцессы группы не достигнут барьера (точкисинхронизации)
- Процессы ждут друг друга.
MPI_Scatter(*sendbuf,sendcnt,sendtype,*recvbuf,recvcnt,recvtype,root,comm)
Передает данные из массива процесса источника в накопители всех процессов
- sendbuf-буфер источник с массивом рассылаемых данных
- sendcnt-счетчик передаваемых данных
- sendtype-тип данных
- recvbuf-приемный буфер
- recvcnt-счетчик принятых данных
- recvtype-тип принятых данных
- root -номер процесса, рассылающего данные
- comm-коммуникатор
MPI_Gather(*sendbuf,sendcnt,sendtype,*recvbuf,recvcnt,recvtype,root,comm)
Собирает данные из буферов всех процессов вмассив-накопитель процесса-сборщика
- sendbuf-буфер источник рассылаемых данных
- sendcnt-счетчик передаваемых данных
- sendtype-тип данных
- recvbuf-приемный буфер для сбора данных
- recvcnt-счетчик принятых данных
- recvtype-тип принятых данных
- root -номер собирающего процесса
- comm-коммуникатор
набор функций MPI для обмена даннымимежду отдельными процессами
- одна ветвь вызывает функцию передачиданных, а другая -функцию приема
Суть:
- Задача 1 передает:
intbuf[10];
MPI_Send(buf, 5, MPI_INT, 1, 0, MPI_COMM_WORLD);
- Задача 2 принимает:
intbuf[10];
MPI_Statusstatus;
MPI_Recv(buf, 10, MPI_INT, 0, 0,
MPI_COMM_WORLD, &status);



- Создадим приложение из N процессов
- Создадим и заполним данными большой массив в процессе 0
- Передадим часть массива в каждый процесс
- В каждом процессе выполним сортировку локального массива в порядке возрастания
- В процессе 0 копируем локальный массив в выходной массив
- В процессе 0 по очереди принимаем локальные массивы от других процессов и сливаем с выходным массивом
Вспомогательные функции:
- •Создание буфера и заполнение числами
- •Сортировка по возрастанию указанного буфера
- •Печать элементов буфера в окне терминала
- •Слияние двух упорядоченных массивов по возрастанию
Прототипы функций
double *generate1(int);
double *processIt1(double *, int);
voidshowIt1(double *, int);
double *merge(double *arr1, double *arr2, intl1, intl2);



В общем, мой друг ты одолел чтение этой статьи об cистемы с распределенной памятью. Работы впереди у тебя будет много.
Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое cистемы с распределенной памятью, mpi
и для чего все это нужно, а если не понял, или есть замечания,
то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Из статьи мы узнали кратко, но содержательно про cистемы с распределенной памятью

Комментарии