Лекция
Привет, Вы узнаете о том , что такое mpp, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое mpp, smp, numa, pvp, кластеры, классы современных параллельных компьютеров, классификация параллельных вычислительных систем , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Основным параметром классификации паралелльных компьютеров является наличие общей (SMP) или распределенной памяти (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры, где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP-системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
При организациях распределенных вычислений в глобальных сетях (Интернет) говорят о мета-компьютерах, которые, строго говоря, не представляют из себя параллельных архитектур.
Более подробно особенности всех перечисленных архитектур будут рассмотрены далее на этой странице, а также в описаниях конкретных компьютеров - представителей этих классов. Для каждого класса приводится следующая информация:
| Одиночный поток команд (single instruction) |
Множество потоков команд (multiple instruction) |
|
|---|---|---|
| Одиночный поток данных (single data) |
SISD
|
MISD |
| Множество потоков данных (multiple data) |
SIMD
|
MIMD
|
Общая классификация архитектур ЭВМ по признакам наличия параллелизма в потоках команд и данных была предложена Майклом Флинном в 1966 году и расширена в 1972 году . Все разнообразие архитектур ЭВМ в этой таксономии сводится к четырем классам:
Типичными представителями SIMD являются векторные архитектуры. К классу MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует. Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных.
Отношение конкретных машин к конкретному классу сильно зависит от точки зрения исследователя. Так, конвейерные машины могут быть отнесены и к классу SISD (конвейер — единый процессор), и к классу SIMD (векторный поток данных с конвейерным процессором) и к классу MISD (множество процессоров конвейера обрабатывают один поток данных последовательно), и к классу MIMD — как выполнение последовательности различных команд (операций ступеней конвейера) на множественным скалярным потоком данных (вектором).
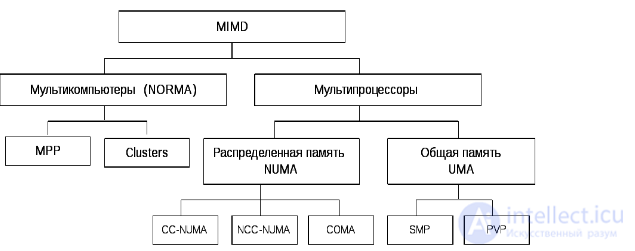
Рисунок . Структура класса многопроцессорных вычислительных систем.
Существуют два типа машин (процессоров), выполняющих несколько команд за один машинный такт:
Суперскалярные машины могут выполнять за каждый машинный такт переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств.
Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд (англ. OoO, Out of Order execution), прогнозирование переходов (англ. Branch prediction), кэши целевых адресов переходов и условное (по предположению) выполнение команд.
В отличие от суперскалярных машин, VLIW-машина выполняет за один машинный такт фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором. В типичной суперскалярной машине аппаратура может выдавать на выполнение от одной до восьми команд в один такт. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждый такт не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в выполняемом потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах переменна. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор (и следовательно программист-разработчик компилятора), а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Использование VLIW приводит в большинстве случаев к быстрому заполнению небольшого объема внутрикристальной памяти командами NOP (no operation), которые предназначены для тех устройств, которые не будут задействованы в текущем цикле. В существующих VLIW-архитектурах был найден большой недостаток, который был устранен делением длинных слов на более мелкие, параллельно поступающие к каждому устройству. Обработка множества команд независимыми устройствами одновременно является главной особенностью суперскалярной процессорной архитектуры.
Классификация машин MIMD-архитектуры:
В класс конвейерных архитектур (по Хокни) попадают машины с одним конвейерным устройством обработки, работающим в режиме разделения времени для отдельных потоков. Машины, в которых каждый поток обрабатывается своим собственным устройством, Хокни назвал переключаемыми. В класс переключаемых машин попадают машины, в которых возможна связь каждого процессора с каждым, реализуемая с помощью переключателей — машины с распределенной памятью. Если же память есть разделяемый ресурс, машина называется с общей памятью. При рассмотрении машин с сетевой структурой Хокни считал, что все они имеют распределенную память. Дальнейшую классификацию он проводил в соответствии с топологией сети.
В 1972 году Фенг (T. Feng) предложил классифицировать вычислительные системы на основе двух простых характеристик. Первая — число n бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной ВС. Немного изменив терминологию, функционирование ВС можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Каждую вычислительную систему можно описать парой чисел (n, m). Произведение P = n x m определяет интегральную характеристику потенциала параллельности архитектуры, которую Фенг назвал максимальной степенью параллелизма ВС.
В основу классификации В. Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
Подобная схема выделения уровней предполагает, что вычислительная система включает какое-то число процессоров каждый со своим устройством управления. Если на какое-то время не рассматривать возможность конвейеризации, то число устройств управления k, число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данной вычислительной системы C: t(C) = (k, d, w).
В 1988 году Шнайдер (L.Snyder) предложил новый подход к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных.
Классификация Скилликорна (1989) была очередным расширением классификации Флинна. Архитектура любого компьютера в классификации Скилликорна рассматривается в виде комбинации четырех абстрактных компонентов: процессоров команд (Instruction Processor — интерпретатор команд, может отсутствовать в системе), процессоров данных (Data Processor — преобразователь данных), иерархии памяти (Instruction Memory, Data Memory — память программ и данных), переключателей (связывающих процессоры и память). Переключатели бывают четырех типов — «1-1» (связывают пару устройств), «n-n» (связывает каждое устройство из одного множества устройств с соответствующим ему устройством из другого множества, то есть фиксирует попарную связь), «1-n» (переключатель соединяет одно выделенное устройство со всеми функциональными устройствами из некоторого набора), «n x n» (связь любого устройства одного множества с любым устройством другого множества). Классификация Скилликорна основывается на следующих восьми характеристиках:
Рассматримнаиболее типичные классы архитектур современных параллельных компьютеров и супер-компьютер.
| Архитектура |
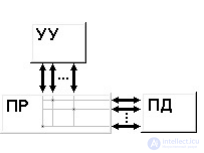
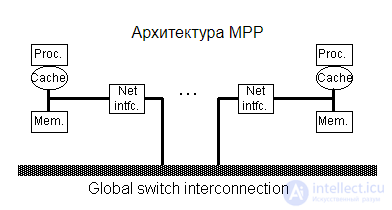
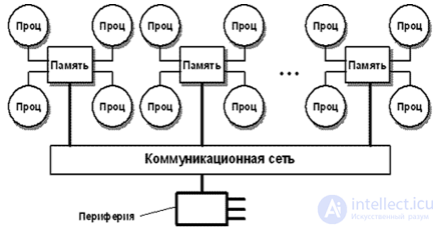
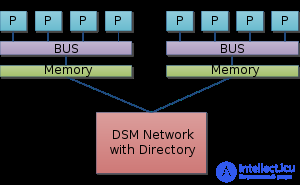
Система состоит из однородных вычислительных узлов, включающих:
К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.п.)
Рисунок – Схематический вид архитектуры с раздельной памятью |
|---|---|
| Примеры | IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec. |
| Масштабируемость | Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain). |
| Операционная система |
Существуют два основных варианта:
|
| Модель программирования | Программирование в рамках модели передачи сообщений ( MPI, PVM, BSPlib) |
Преимущества |
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Об этом говорит сайт https://intellect.icu . Практически все рекорды по производительности в 1990-е годы установлены на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific). |
Недостатки |
|
| Архитектура |
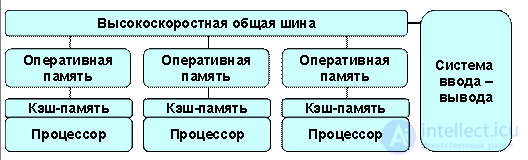
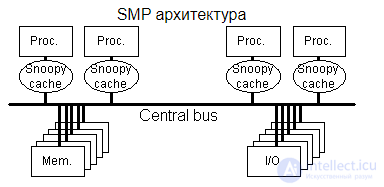
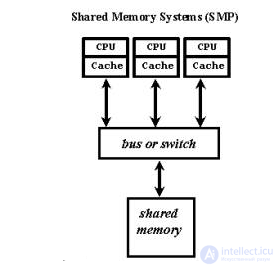
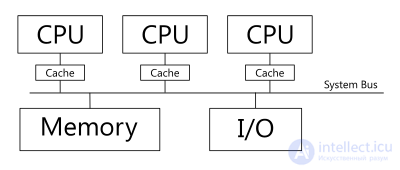
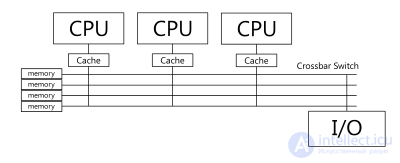
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей.
Рис. 1.1. Архитектура симметричных мультипроцессорных систем.
Диаграмма устройства системы с симметричной мультипроцессорностью. Процессоры обращаются к общей памяти по общей шине
|
|
|---|---|---|
| Примеры | HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). | |
| Масштабируемость | Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. | |
| Операционная система | Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. | |
| Модель программирования | Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. | |
| преимущества |
SMP — самый простой и экономически выгодный способ масштабирования вычислительной системы: путем наращивания числа процессоров. Также просто и программирование: с помощью потоков и сопутствующих механизмов обмена данными между ними через общие переменные в памяти. SMP часто применяется в науке, промышленности, бизнесе, где программное обеспечение специально разрабатывается для многопоточного выполнения. В то же время большинство потребительских продуктов, таких как текстовые редакторы и компьютерные игры, написаны так, что они не могут использовать сильные стороны SMP-систем. В случае игр это зачастую связано с тем, что оптимизация программы под SMP-системы приведет к потере производительности при работе на однопроцессорных системах, которые еще недавно занимали большую часть рынка ПК. (Современные многоядерные процессоры — лишь еще одна аппаратная реализация SMP.) В силу природы разных методов программирования для максимальной производительности потребуются отдельные проекты для поддержки одного одноядерного процессора и SMP-систем. И все же программы, запущенные на SMP-системах, получают незначительный прирост производительности, даже если они были написаны для однопроцессорных систем. Это связано с тем, что аппаратные прерывания, обычно приостанавливающие выполнение программы для их обработки ядром, могут обрабатываться на свободном процессоре (процессорном ядре). Эффект в большинстве приложений проявляется не столько в приросте производительности, сколько в ощущении, что программа выполняется более плавно. В некоторых прикладных программах (в частности: программных компиляторах и некоторых проектах распределенных вычислений) повышение производительности будет почти прямо пропорционально числу дополнительных процессоров. |
|
| недостатки |
Выход из строя одного процессора приводит к некорректной работе всей системы и требует перезагрузки всей системы для отключения неисправного процессора. Выход же из строя одного процессорного ядра нередко оборачивается выходом из строя всего многоядерного процессора, если многоядерный процессор не оснащен встроенной защитой, отключающей неисправное процессорное ядро и через это позволяющей исправным процессорным ядрам продолжать работать штатно. Ограничение на количество процессоровПри увеличении числа процессоров заметно увеличивается требование к пропускной возможности шины памяти. Это налагает ограничение на количество процессоров в SMP архитектуре. Современные SMP-системы позволяют эффективно работать при 16 процессорах. Проблема когерентности кэш-памятиКаждый современный процессор оборудован многоуровневой кэш-памятью для более быстрой выборки данных и машинных команд из основной памяти, которая работает медленнее, чем процессор. В многопроцессорной системе наличие кэш-памяти у процессоров снижает нагрузку на общую шину или на коммутируемое соединение, что весьма благоприятно сказывается на общей производительности системы. Но так как каждый процессор оборудован своей индивидуальной кэш-памятью, то возникает опасность, что в кэш-память одного процессора попадет значение переменной, отличное от того, что хранится в основной памяти и в кэш-памяти другого процессора. Представим, что процессор изменяет значение переменной в своем кэше, а другой процессор запрашивает эту переменную из основной памяти, — и он (второй процессор) получит уже недействительное значение переменной. Или, например, подсистема ввода-вывода записывает в основную память новое значение переменной, а в кэш-памяти процессора все еще остается устаревшее. Разрешение этой проблемы возложено на протокол согласования кэшей (cache coherence protocol), который призван обеспечить согласованность («когерентность») кэшей всех процессоров и основной памяти без потери общей производительности . Поддержка операционной системойПоддержка SMP должна быть встроена в операционную систему, иначе дополнительные процессоры будут бездействовать, и система будет работать как однопроцессорная. (Собственно эта проблема актуальна и для однопроцессорных систем с многоядерным процессором.) Большинство современных операционных систем поддерживает симметричную мультипроцессорность, но в разной степени. Поддержка многопроцессорности в ОС Linux была добавлена в версии ядра 2.0 и усовершенствована в версии 2.6. Линейка ОС Windows NT изначально создавалась с поддержкой многопроцессорности. (Windows 9x SMP не поддерживали.) |
| Архитектура |
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. По сути своей NUMA представляет собой большую SMP, разбитую на набор более мелких и простых SMP. Аппаратура позволяет работать со всеми отдельными устройствами основной памяти составных частей системы (называемых обычно узлами) как с единой гигантской памятью. Этот подход порождает ряд следствий. Во-первых, в системе имеется одно адресное пространство, распространяемое на все узлы. Реальный (не виртуальный) адрес 0 для каждого процессора в любом узле соответствует адресу 0 в частной памяти узла 0; реальный адрес 1 для всей машины - это адрес 1 в узле 0 и т.д., пока не будет использована вся память узла 0. Затем происходит переход к памяти узла 1, затем узла 2 и т.д. Для реализации этого единого адресного пространства каждый узел NUMA включает специальную аппаратуру (Dir), которая решает проблему когерентности кэшей, обеспечивая получение актуальной информации от других узлов. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA)
|
|---|---|
| Примеры | HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600. |
| Масштабируемость | Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). |
| Операционная система | Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). |
| Модель программирования | Аналогично SMP. |
| достонства | |
| недостатки |
NUMA-компьютеры обладают серьезным недостатком, который выражается в наличии отдельной кэш-памяти у каждого процессорного элемента Кэш-память для многопроцессорных систем оказывается узким местом Объяснение: Если процессор Р1 сохранил значение X в ячейке q, а затем процессор Р2 хочет прочитать содержимое той же ячейки q . Об этом говорит сайт https://intellect.icu . Процессор Р2 получит результат отличный от X, так как X попало в кэш процессора Р1. Эта проблема носит название проблемы согласования содержимого кэш-памяти Решение: Архитектура ccNUMA проблема неоднородности доступа Архитектура NUMA имеет неоднородную память (распределенность памяти между модулями), что в свою очередь требует от пользователя понимания неоднородности архитектуры. Если обращение к памяти другого узла требует на 5-10% больше времени, чем обращение к своей памяти, то это может и не вызвать никаких вопросов. Большинство пользователей будут относиться к такой системе, как к UMA (SMP), и практически все разработанные для SMP программы будут работать достаточно хорошо. Однако для современных NUMA систем это не так, и разница времени локального и удаленного доступа лежит в промежутке 200-700%. |
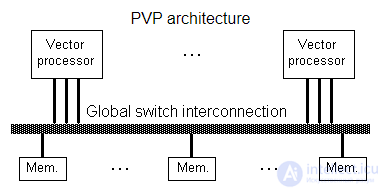
| Архитектура | Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).
|
|---|---|
| Примеры | NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, CRAY X1, серия Fujitsu VPP. |
| Модель программирования | Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением). |
| достоинства | |
| недостатки |
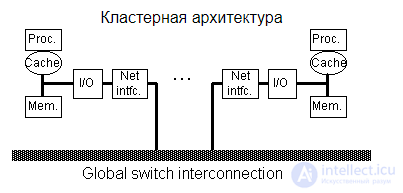
| Архитектура | Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора.
При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку.
|
|---|---|
| Примеры | NT-кластер в NCSA, Beowulf- кластеры . |
| Операционная система | Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. |
| Модель программирования | Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. |
Grid (вычислительная сеть). Grid – это объединение многих разнородных вычислительных ресурсов в сетях, в частности, в глобальных сетях (Интернет). Grid осуществляет распределенные вычисления. Свое название распределенная вычислительная сеть получила по аналогии с электрической сетью.
Графические процессоры (GPU – Graphics Processing Unit). GPU (видеокарты) – миниатюрные суперкомпьютеры в корпусе обычного персонального компьютера. Графические процессоры являются универсальными вычислительными модулями, обеспечивающими многопотоковое параллельное программирование. Чип GPU включает в себя некоторое множество вычислительных блоков, называемых потоковыми мультипроцессорами; каждый вычислительный блок содержит некоторое множество потоковых (универсальных) процессоров. Мультипроцессоры обмениваются информацией посредством оперативной памяти, называемой глобальной памятью. Потоковые процессоры взаимодействуют посредством быстрой разделяемой между этими процессорами памяти. Универсальные вычисления на GPUs компании NVIDIA обеспечивает технология программирования CUDA (Compute Unified Device Architecture). Считается, что использование CUDA для графических процессоров сложнее, чем использование OpenMP для многоядерных компьютеров
Данный компьютер считается первой коммерчески доступной вычислительной системой с множественным потоком команд. В своей полной конфигурации Denelcor HEP содержит 16 процессорных модулей (Process Execution Module - PEM), через многокаскадный переключатель связанных со 128 модулями памяти данных (Data Memory Module - DMM). Все процессорные модули могут работать независимо друг от друга со своими потоками команд. В свою очередь каждый процессорный модуль может поддерживать до 50 потоков команд пользователей. На уровне процессорного модуля множественность потоков команд обеспечивается одним восьмиуровневым конвейерным устройством для обработки команд. На каждой ступени конвейера должны находиться команды из разных потоков. Следовательно, скорость вычислений увеличивается с увеличением количества потоков команд, пока конвейер не будет заполнен. После заполнения конвейера эта величина остается постоянной.
Содержит до 16 машин типа DEC PDP-11, связанных с 16 модулями памяти через перекрестный переключатель размерности 16x16.
Содержит до N=2n процессорных элементов, каждый из которых содержит свое устройство обработки данных и модуль памяти из двух блоков. Все процессорные элементы между собой связываются через многокаскадный переключатель. Отличительной особенностью этой архитектуры является возможность динамически менять свою конфигурацию в зависимости от прикладных задач. Система может быть сконфигурирована либо как SIMD, либо как MIMD компьютер. Кроме локальной памяти, каждый процессорный элемент имеет доступ к общей памяти.
Это вычислительная система типа MIMD с распределенной памятью, состоящая из 64 процессорных элементов (ПЭ). Каждый ПЭ содержит 8-разряд\-ный микропроцессор Intel 8031 с 32--разрядным сопроцессором Intel 8231 и локальную память объемом 2 Кбайта. В качестве контроллера используется 16-разрядный микропроцессор Intel 8086. Связь процессорных элементов осуществляется через общую шину.
Данная система состоит из нескольких машин FPS 164, которые контролируются одной управляющей машиной. В демонстрационных образцах было использовано семь FPS 164, каждая из которых имела по 4 Мбайта основной памяти. Управляющей машиной служила IBM 4381.
Основной компонентой этой системы является "вычислительный модуль", состоящий из микропроцессора DEC LSI-11 с 64Мбайтами dynamic MOS memory. Данный модуль может работать как отдельный компьютер. В то же время до 14 таких модулей могут быть подключены к шине (intracluster bus), формируя таким образом сильносвязанную систему (кластер - tightly-coupled cluster). Внутри этого кластера передача данных происходит путем прямого доступа к памяти. Построенные таким образом кластеры можно связать в более сложную систему через две соединяющие кластеры шины (intercluster buses). При этом получается слабо связанная сеть (loosely-coupled network), в которой обмен данными происходит путем коммутации пакетов (packet switching techniques).
В состав системы входит шестнадцать кластеров по восемь процессорных элементов (ПЭ) в каждом. Кластеры связаны через расширенную сеть типа Omega (extended Omega global switching network) с 256 модулями глобальной памяти. Каждый модуль памяти имеет объем от 4 до 16 мегаслов. Процессорные элементы, составляющие кластер, имеют по 16 мегаслов локальной памяти. Все процессорные элементы конвейерного типа и связаны между собой через локальную коммутационную сеть (local switching network).
В ее состав входят четыре матричных модуля, управляемых последовательной машиной PDP-11. Каждый модуль содержит 256 ПЭ и общую память емкостью от 64 Кбит до 64 Мбит. Связь между ПЭ и памятью осуществляется через гибкую коммутационную сеть.
Это система из 288 ПЭ с низкой степенью связности. Каждый процессорный элемент содержит по три процессора (каждый процессор предназначался для выполнения определенной функции, связанной с задачей радиолокации), управляемых в синхронном режиме тремя устройствами управления (по одному на каждый тип процессора в ПЭ). Эти три устройства управления подключались к трем стандартным каналам ввода-вывода машины CDC 7600, которая была главной для всей системы. Связь между ПЭ осуществлялась через блоки памяти устройств управления.
Система состоит из пяти процессоров. Каждый процессор через матричный коммутатор имеет доступ к блокам памяти (количество блоков варьируется от одного и более). Через сеть внешнего доступа процессоры соединяются с памятью на внешних носителях и устройствами ввода--вывода. В каждый момент времени некоторый процессор с памятью работает как управляющий процессор (монитор), регулируя активность остальных рабочих процессоров.
3 Какая из перечисленных систем имеет PVP-архитектуру:
Многопроцессорность
Параллельные вычислительные системы
Симметричная мультипроцессорность
Компьютеры пятого поколения
основные классы современных параллельных компьютеров массивно-параллельные системы mpp ,
основные классы современных параллельных компьютеров симметричное мультипроцессирование smp ,
основные классы современных параллельных компьютеров симметричное мультипроцессирование smp ,
основные классы современных параллельных компьютеров системы с неоднородным доступом к памяти numa ,
основные классы современных параллельных компьютеров параллельные векторные системы pvp ,
основные классы современных параллельных компьютеров кластерные системы ,
Исследование, описанное в статье про mpp, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое mpp, smp, numa, pvp, кластеры, классы современных параллельных компьютеров, классификация параллельных вычислительных систем и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы

Комментарии