Лекция
Привет, Вы узнаете о том , что такое оптимизация сайта, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое оптимизация сайта, производительность сайта , настоятельно рекомендую прочитать все из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы.
Современные веб приложения обычно состоят из нескольких уровней: клиентская логика, веб-фреймворк, бизнес-логика, технология ORM и база данных. Например, конкретный стек может включать в себя Vue.js, ASP.NET WebAPI, C#, Entity Framework, MSSQL либо React.js, ASP.NET Core, NHibernate, C#, PostgreSQL. Если приложение во время своей работы подтормаживает, то проблемы с производительностью могут быть скрыты на одном конкретном уровне или одновременно на нескольких.
Представим, загрузка страницы с большим количеством отчетов занимает 5 секунд. Подобная задержка может быть вызвана таким набором просчетов: на таблице в базе MS SQL отсутствует необходимый индекс; Entity Framework загружает в память все записи из таблицы базы данных с отчетами, так как используется интерфейс IEnumerable; бизнес-логика, выполняя дополнительные преобразования данных, бездумно аллоцирует тонны объектов (например, в следствие активной модификации строк или частых resize’ов List’ов), а мегабайтные .js и .css файлы отсылаются клиенту не минифицированными. Исправление только одного из перечисленных пунктов не будет достаточным для достижения максимального быстродействия приложения в целом. Диагностика проблем с производительностью, их устранение и профилактика требуют комплексной работы.
Исследования уважаемых компаний показывают, что лишние 100 мс задержки ощутимо просаживают продуктовые метрики — и отрицательный эффект со временем становится все заметнее.
По данным Amazon:
10 лет назад с каждыми 100 мс задержки конверсия падала на 1%;
5 лет назад с каждыми 100 мс задержки продажи падали уже на 7%.
Google говорит:
15 лет назад лишние 400 мс задержки уменьшали трафик на 20%;
5 лет назад, если Largest Contentful Paint (LCP) уменьшалось на 300 мс, то это давало +12% к вовлеченности и +9% к просмотрам.
Deloitte заявляет, что ускорение времени загрузки страницы на 100 мс может увеличить конверсию на 8%.
Всего одна десятая секунды — и такие результаты. Но давайте посмотрим, что такое эти 100 мс с когнитивной точки зрения:
за 13 мс человеческий мозг способен уловить изображение, то есть при FPS меньше 77 можно заметить «эффект 25-го кадра»;
за 100 мс — разобрать, что изображение означает;
за 150 мс (в среднем) обработать изображение и как-то среагировать;
за 17–50 мс мозг способен сформировать эстетическую реакцию на веб-страницу, говорят исследователи UX YouTube.
В этой статье условимся, что «быстро» — это меньше 100 мс.
В рекомендациях по созданию веб-сайтов 100 мс — это хорошее значение для показателя интерактивности. Но некоторые другие величины все еще измеряются в секундах, то есть в реальном мире контент грузится целые секунды. Мы все далеки от идеала в 100 мс, и у нас впереди еще много работы.
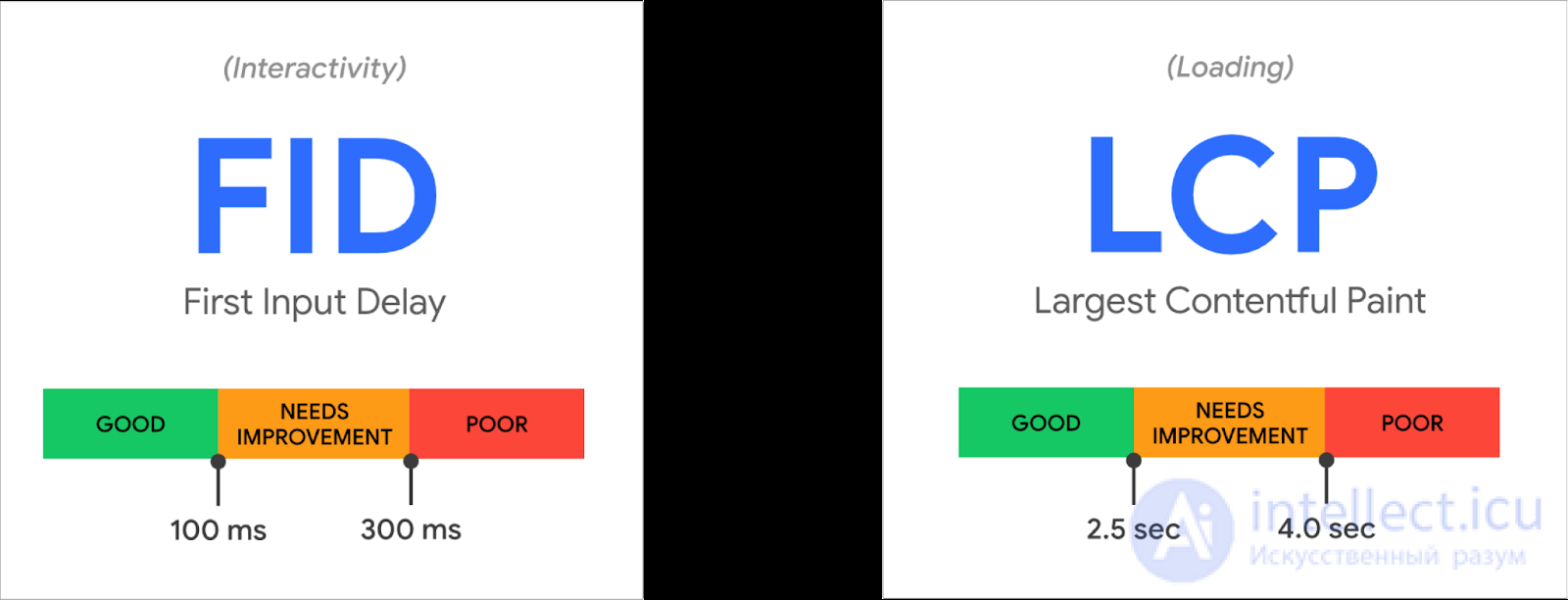
https://web.dev/vitals/
Конечно, и мы ВКонтакте боремся за каждые 100 мс отдачи контента, отрисовки страниц, старта приложений и других операций.
Чтобы понять, где можно добиться максимального эффекта, вспомним, как устроены почти все интернет-сервисы. Базово их можно описать примерно так:

На уровне логики и клиентов интернет-сервис может работать очень быстро, если вы хорошо написали код, — поэтому на схеме блоки выделены зеленым. Скорость обращения к оперативной памяти или SSD напрямую зависит от качества кода: она в вашей власти, ее можно оптимизировать понятными способами.
Работа с данными обычно чуть медленнее, но базы данных и системы хранения все эффективнее в обращении к дискам, кешировании и прочем. Так что блок оранжевый: при должных разумных усилиях latency здесь порядка 10–30 мс и неплохо предсказуема.
Самый медленный и самый сложный для оптимизации уровень — сетевой. Разработчики редко до него добираются: чтобы что-то оптимизировать на сетевом уровне, нужно оптимизировать и бэкенд, и клиент — и выкатывать это одновременно.

При этом в «Latency numbers every programmer should know» на сеть отводится гораздо больше, чем на все остальные операции, вместе взятые, — 150 мс. 150 мс — это каждый round-trip на другой континент. Если ваши пользователи и серверы находятся на разных континентах, то latency всего вашего сервиса точно больше 150 мс. Это, как мы выяснили, уже создает ощущение, будто что-то тормозит.
Мы помним, что «преждевременная оптимизация — корень всех бед». Перед тем как оптимизировать, нужно остановиться и подумать: зачем что-то ускорять, если за последние 20 лет пропускная способность интернет-сети стала больше в 1 000 раз.
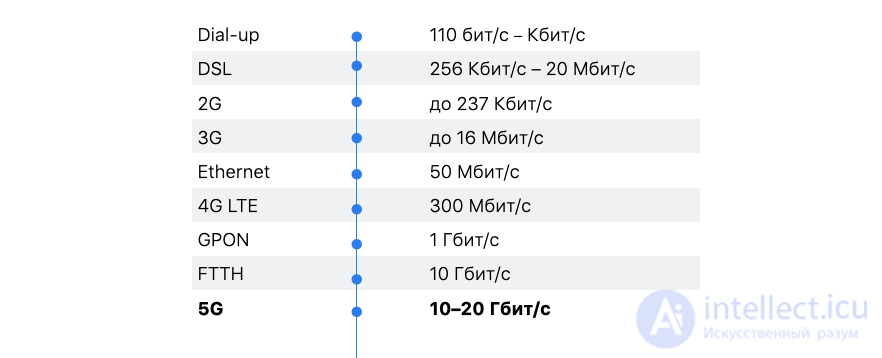
Это все так. Но давайте посмотрим, как в последнее время изменились другие характеристики сети, в частности round-trip time (RTT).
На изображении ниже показаны основные способы борьбы с проседанием производительности на каждом из слоев приложения. Большинство изложенных рекомендаций не относятся к конкретной технологии или ее версии.
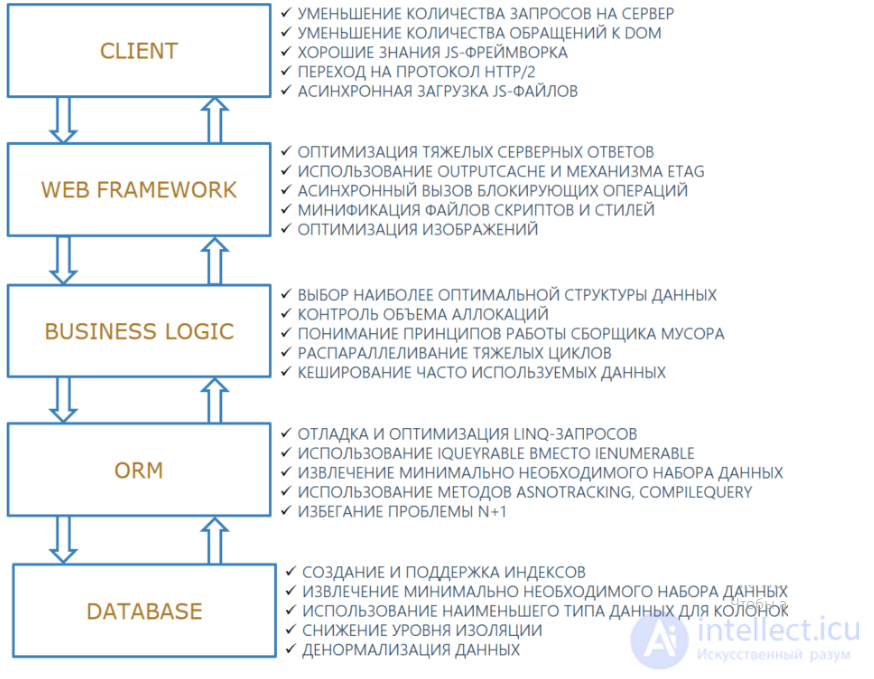
Уменьшение количества запросов на сервер. Если для отображения некоторой страницы выполняется большое количество запросов на сервер и общее время загрузки долгое, то можно предпринять несколько действий. Во-первых, ответы отдельных запросов могут быть кешированы. Во-вторых, список выполняемых запросов в пределах страницы может быть пересмотрен. Некоторые запросы могут быть уже не актуальны, т. е. клиент выполняет запрос, но не обрабатывает ответ. Также запросы могут дублироваться. Такие сюрпризы нередко можно встретить в больших системах, которые разрабатываются большой распределенной командой и часто меняются требования от заказчика, в результате чего в коде остается мусор. В-третьих, страница не всегда должна ожидать завершения выполнения всех без исключения запросов для того, чтобы пользователь мог начать с ней работу. Достаточно дождаться выполнения запросов, которые возвращают основной контент или подготавливают ключевой функционал, а остальное подгрузить асинхронно.
Для диагностики вышеизложенных проблем обычно достаточно Network вкладки в Chrome DevTools, в которой можно изучать количество выполненных запросов, их время, содержимое, объем и тд.
Уменьшение количества обращений к DOM. JavaScript и DOM являются двумя отдельными технологиями. JavaScript работает с DOM через API, что влечет за собой дополнительные накладные расходы. Модификации объектов DOM-модели влекут за собой выполнение тяжелой браузерной операции Reflow, время выполнения которой растет с увеличением количества тегов на странице, уровня вложенности тегов и количества CSS-стилей.
Если появляется необходимость работать с DOM напрямую, в обход JS-фреймворка, то ссылки на DOM-объекты могут быть закешированы и использованы повторно. Также большое количество обновлений DOM-объекта можно выполнить в «отсоединенном» режиме (в копии реального DOM-объекта в оперативной памяти, изменения которого не влияют на UI), после чего все внесенные изменения единожды применяются к UI.
Диагностировать проблему частой манипуляции DOM можно при помощи профайлера, который находится в Chrome DevTools во вкладке Performance.
Хорошие знания JS-фреймворка. Cинхронизация JS-моделей и DOM является основной обязанностью JS-фреймворков, которую они выполняют достаточно быстро. Однако по мере увеличения объема данных, скорость синхронизации DOM и JS-модели при внесении изменений в последнюю может замедлится до неприемлемой. Для исправления такой проблемы, поверхностных знаний JS-фреймворка на уровне «как прибиндить модель к UI» уже недостаточно.
В документации каждого JS-фреймворка можно найти способы оптимизировать его производительность. Например, в React.js для избежания ненужного рендеринга используется shouldComponentUpdate(), в Knockout.js метод valueHasMutated() позволяет избежать проблем с быстродействием при частой модификации модели привязанной к UI и тд.
Переход на протокол HTTP/2. Простой переход с протокола HTTP/1.1 на HTTP/2.0 может увеличить скорость работы сайта, так как новая версия протокола поддерживает возможность совершать несколько запросов на сервер в рамках одного TCP соединения, использует механизм сжатия для HTTP-заголовков, приоритизирует запросы, доставляя клиенту более важный контент быстрее.
HTTP/2 поддерживается большинством современных браузеров, не требуется никаких настроек со стороны клиента. Со стороны веб-серверов IIS или Kestrel конфигурирование выполняется вручную. В Network вкладке в Chrome DevTools можно проверить, по какому протоколу общаются клиент и сервер.
Асинхронная загрузка JS-файлов. Браузер рендерит страницу, читая HTML-код. Если браузер встречает тег script, рендеринг страницы приостанавливается до момента полной загрузки JS-файла со всеми его возможными зависимостями и выполнениями запросов на сервер. Атрибут async в теге script заставит браузер не приостанавливать рендеринг страницы, она будет быстрее показана пользователю намного быстрее.
При правильном проектировании, рендеринг страницы блокируется только до момента полной загрузки ключевого контента или функционала, с которым пользователь вероятнее всего будет работать сразу и без которого страница не имеет смысла. Загрузка вспомагательных частей страницы выполняются асинхронно.
Использование Асинхронной обработки изображения decoding
sync: Декодировать изображение синхронно для отображения одновременно с другим содержимым.async: Декодировать содержимое асинхронно для уменьшения задержки в отображении другого содержимого.auto: Режим по умолчанию, который не отдает предпочтения ни одному режиму декодирования, предоставляя браузеру решать, какой режим для пользователя оптимальнее
Использование адаптивных версий изображений
HTML-элемент picture служит контейнером для одного или более элементов  и одного элемента img для обеспечения оптимальной версии изображения для различных размеров экрана. Браузер рассмотрит каждый из дочерних элементов
и одного элемента img для обеспечения оптимальной версии изображения для различных размеров экрана. Браузер рассмотрит каждый из дочерних элементов
и выберет один, соответствующий лучшему совпадению; если совпадений среди элементов
найдено не будет, то будет выбран файл, указанный атрибутом src элемента img . Затем выбранное изображение отображается в пространстве, занятом элементом img .
Оптимизация тяжелых серверных ответов. Серверные ответы по сотни килобайт требуют заметного времени на загрузку браузером. Такие ответы могут быть сжаты стандартным gzip’ом, что может быть достигнуто добавлением аттрибута над декларацией GET-запроса. На стороне клиента никакого кода писать не требуется, так как браузеры сами умеют выполнять распаковку сжатых данных.
Диагностировать деградацию перформанса по причине тяжелых ответов в Chrome можно в Network вкладке в DevTools. При клике на конкретные веб-запрос появится информация о его размере и о времени, которое браузер потратил на загрузку ответа (свойство Content Download).
Использования OutputCache и механизма ETag. Если сервер возвращает тяжелые и редко изменяющиеся данные, то он может попросить браузер их закешировать, путем установки специальных HTTP-заголовков. Для кеширования статического контента обычно применяются аттрибуты OutputCache или ResponseCache с указанием времени, в течение которого браузер будет брать данные из своего кеша. Если нужно закешировать контент с возможностью немедленного обновления кеша при изменении данных на сервере, применяют механизм ETag.
Асинхронный вызов блокирующих операций. Синхронный вызов блокирующих операций, таких как обращение к стороннему сервису, чтение/запись данных c жесткого диска или базы данных, ведет к блокированию потока, который инициировал такую операцию. Об этом говорит сайт https://intellect.icu . Поток будет ожидать завершения блокирующей операции и не сможет заниматься другой работой, такой как обработка входящих запросов на веб-сервер. В результате можно получить проблему, при которой сервер не сможет выделить новый поток на обработку входящего запроса, так как все имеющиеся в распоряжении потоки будут ожидать завершения синхронно вызванных ими блокирующих операций. Когда поток вызывает блокирующую операцию асинхронно, то он возвращается в пул потоков, в результате чего сервер может использовать минимальное число потоков для обработки входящих запросов.
Другим примером использования асинхронности есть вызов нескольких блокирующих операций подряд, например, для агрегирования набора данных из разных источников. При синхронном вызове нескольких блокирующих операций общее время работы будет равно сумме времени выполнения всех операций, а при асинхронном — снизится до времени выполнения одной самой долгой блокирующей операции.
Для диагностики проблем нерационального использования потоков можно через класс ThreadPool и пространство имен System.Diagnostics, где можно получить информацию о количестве занятых потоков в конкретный момент времени, об их максимально доступном количестве и тд.
Минификация файлов скриптов и стилей. Минификация — это процесс оптимизации при котором уменьшается размер .js и .css файлов путем удаления лишних пробелов, отступов, комментариев, в результате чего увеличивается время загрузки страницы. JS-библиотеки обычно поставляются с минифицированными версиями файлов. При необходимости минифицировать собственные файлы можно использовать какой-нибудь javascript-minifier. Другая техника оптимизации Bundling позволяет объединять несколько .js или .css файлов в один. Bundling и Minification включают для продакшена, но для тестовой среды минифицированные файлы не используются, чтобы не затруднять процесс отладки.
Оптимизация изображений. Уменьшения размера изображений снижает время загрузки страницы. Изображения могут быть оптимизированы вручную при помощи большого количества онлайн-сервисов или расширений как например Visual Studio Image Optimizer. Также изображения могут быть оптимизированы автоматически при запуске билда или развертывании аппликации с использованием gulp-imagemin, Azure Image Optimizer и других.
Выбор наиболее оптимальной структуры данных. Каждая структура данных (Stack, List, Dictionary, HashSet и другие) оптимизирована под конкретные операции с ней и должна выбираться программистом исходя из условий решаемой задачи. Например, обычный массив отлично подойдет для хранения объектов в определенном порядке, но расширение массива будет происходить медленно, так как его нужно будет постоянно пересоздавать и поиск элемента будет самым медленным — линейным. HashSet подойдет для быстрого поиска объекта, но в пределах коллекции они должны быть уникальными. Если на выбранной структуре данных часто используются операции для которых она не оптимизирована и в ней хранятся десятки тысяч объектов, имеем проблемы с перформансом.
Засорение памяти ненужными объектами или долгое время выполнения фрагмента кода являются симптомами неправильного выбора структуры данных, соответственно для диагностики данной проблемы подойдут memory и CPU профайлеры, такие, как Visual Studio Memory Profiler, JetBrains dotTrace, ANTS Memory Profiler.
Контроль количества аллокаций. Лишняя аллокация имеет два недостатка: сам процесс аллокации занимает некоторое время и появляется дополнительная работа для сборщика мусора. Существует много возможностей получить аллокацию неявно, среди них механизм упаковки, работа с LINQ, работа с неизменяемыми объектами, замыкания, переполнение коллекций и тд. Для контроля объемов занимаемой оперативной памяти можно использовать профайлеры из предыдущего пункта. В статическом анализе кода на предмет неявных аллокаций полезны Heap Allocations Viewer или Roslyn Clr Heap Allocation Analyzer.
Понимание принципов работы сборщика мусора. Чем меньше аллокаций, тем меньше нагрузка на сборщик мусора и тем меньше он тормозит приложение. Помимо этого правила полезно понимать как GC работает с кучей больших объектов, слабыми ссылками и какие существуют режимы сборки мусора, чтобы добиться максимального быстродействия за относительно короткий промежуток времени. Также полезно понимать причины по которым происходят утечки памяти в управляемом коде, и знать когда применять шаблон Dispose.
Сборщик мусора имеет различные события (GCStart, GCEnd, GCAllocationTick и тд), на которые можно подписаться для сбора информации о времени и причинах запуска GC, объеме освобожденной памяти и тд. Также детальную статистику по работе GC и объему используемой памяти предоставляют performance counter’ы (Time in GC, Total committed Bytes, Large Object Heap size и тд), которые можно получить при помощи легковесной программы Performance Monitor. Для более продвинутого анализа памяти можно использовать Windows Debugger (WinDbg). Для изучения деталей работы GC и устройства памяти в .NET есть прекрасная книга Under the Hood of .NET Memory Management.
Распараллеливание тяжелых циклов. Если foreach или for выполняют десятки тысяч итераций, что тормозит приложение, то имеет смысл использовать класс Parallel, если только порядок выполнения итераций не имеет значения. Если логика класса Parallel решит, что обработка данных несколькими потоками или процессорами имеет смысл в конкретных условиях, то коллекция будет разделена на части, каждая из которых будет отправлена на обработку отдельному потоку, после чего, результаты будут смержены обратно в единую коллекцию.
Кеширование часто используемых данных. Речь идет не о кешировании данных из базы с использованием Cache-Aside шаблона либо в статических свойствах, а о максимальном повторном использовании вычисляемых данных. Когда-то я исследовал проблему с производительностью при генерации репортов. Помимо ряда ненужных обращений к базе данных, профайлер указал, что 20% времени тратилось на работу с типом DateTime. Оказалось, что код генерации репортов постоянно обращался в циклах к свойству DateTime.Now. Вынесение его за пределы циклов улучшило скорость генерации репортов на те же 20%.
Хорошими кандидатами для участия в кешировании являются чистые функции. Если такая функция вызывается много раз и замедляет работу приложения, то из ее входящих параметров можно составить ключ и закешировать по нему возвращаемое значение функции.
Использование IQueyrable вместо IEnumerable. Оба интерфейса позволяют отфильтровать коллекцию данных по переданному предикату. Однако IEnumerable выполняет фильтрацию на стороне .NET, предварительно выгружая все записи из базы. IQueyrable фильтрует данные на стороне SQL-сервера, возвращая только то количество записей, которое реально необходимо.
Отладка и оптимизация LINQ запросов. Программист пишет LINQ-запрос, ORM трансформирует его в SQL и передает SQL-серверу на выполнение. Не всегда сгенерированные запросы являются самыми оптимальными. Необходимо контролировать все, что ORM отправляет SQL-серверу и при необходимости переписывать исходный LINQ с целью улучшить SQL-код. Если переписывание LINQ не дает результата, от него можно отказаться в пользу написания SQL-запроса в C# коде, либо использовать хранимые процедуры.
Начиная с Entity Framework 6.0, SQL-запросы можно легко отслеживать при помощи свойства context.Database.Log. Также можно пользоваться SQL-профайлером, Entity Framework профайлером и простым вызовом IQueryable.ToString().
Извлечение минимально необходимого набора данных. Извлекать данных из базы нужно не больше, чем требуется для успешного выполнения веб-запроса. Больше извлекаем — хуже перформанс. Избыточные данные можно получить когда:
Использование методов AsNoTracking, CompileQuery. Использование метода AsNoTracking в Entity Framework помогает в улучшении перформанса в случаях, когда из базы извлекается большая коллекция объектов только для чтения. Entity Framework не кеширует такие объекты в DbContext’е, перестает отслеживать изменения в них изменения. В Entity Framework Core появилась возможность заставить весь DbContext работать в read-only режиме, установив свойство QueryTrackingBehavior.
Методы CompileQuery и CompileQueryAsync помогают улучшить производительность в случаях, когда некоторый LINQ-запрос вызывается многократно. Вместо постоянной компиляции LINQ-запроса в SQL перед своим выполнением, он компилируется единожды в пределах жизненного цикла веб-запроса либо целого приложения. Более того, скомпилированный запрос не нуждается в перекомпиляции при изменении входящих параметров.
Избегание проблемы N+1. Для хорошего перформанса, количество запросов к SQL-серверу должно быть минимально, но проблема N+1 наоборот способствует их увеличению. Например, имеется коллекция объектов List, класс Country содержит в себе свойство List, для которого включена ленивая загрузка. При итерировании List и обращении к свойству List в цикле, получим по одному запросу в базу на каждой итерации.
Отследить проблему N+1 можно через SQL-профайлер. Обычно в нем будут один за другим идти одинаковые SQL-запросы, с отличающимися параметрами. В Entity Framework Проблема решается предварительной загрузкой данных методом Include (Eager Loading).
Создание и поддержка индексов. Индексы создаются для одной или нескольких колонок таблицы, по которым наиболее часто происходит выборка данных. Скорость выполнения запроса, например, SELECT * FROM Info i WHERE i.SomeID = 10, на таблице с сотней тысяч записей будет отличаться в разы в зависимости от наличия или отсутствия индекса для колонки SomeID. Однако, наличие большого количества индексов на таблице замедлит производительность, так как индексы необходимо перестраивать при обновлении данных в таблице + требуется дополнительное место в памяти для их хранения.
Понять используются ли индексы запросами поможет анализ результатов SQL Server Query Execution Plan’а. Статистику по использованию индексов дает MS SQL функция sys.dm_db_index_operational_stats.
Извлечение минимально необходимого набора данных. Для минимизации извлекаемых данных нужно следить за количеством указанных столбцов в операторе SELECT, использовать SET NOCOUNT ON в хранимых процедурах, использовать ‘SELECT 1 …’ вместо ‘SELECT * …’ для проверки наличия или отсутствия записей в таблице, использовать наиболее «узкие» предикаты в WHERE (которые не возвращают лишние строки, только необходимые).
Использование наименьшего типа данных для колонок. Используемая SQL-сервером память может быть значительно сэкономлена, если при проектировании таблиц выбирать наименьшие типы данных для колонок. Перед выбором типа данных для колонки недостаточно понять, будет ли в ней храниться строка или число. Нужно подумать о диапазоне допустимых значений. Например, для хранения возраста человека нет смысла использовать bigint или int. Подойдет tinyint с диапазоном значений от 0 до 255. При оптимизации размера таблиц, помимо экономии памяти, увеличится скорость работы JOIN’ов и вырастет скорость сканирования индексов.
Снижение уровня изоляции. В следствии одновременного обращения несколькими транзакциями к таблицам MS SQL могут возникать блокировки, которые снижают ожидаемое время выполнения запросов. В первую очередь проблемы блокировок решаются оптимизацией SELECT’ов, что помогает блокировать меньшее количество данных и на меньшее время. В других случаях можно рассматривать понижение уровней изоляций транзакций вплоть до READ UNCOMMITTED либо использование уровня SNAPSHOT ISOLATION, который решает проблемы одновременного доступа не блокированием, а версионностью. Также можно использовать опцию WITH (NOLOCK), которая работает аналогично уровню READ UNCOMMITTED, но применяется не на уровне транзакции, а для отдельного SELECT’а .
Диагностировать проблемы блокировок в MS SQL можно при помощи утилиты Activity monitor.
Денормализация редко изменяемых данных. Нормализованные данные оптимизированы для их быстрого и удобного обновления, денормализованные — для чтения. Цена нормализации — плохая скорость чтения по причине частых JOIN’ов и вызовах агрегатных функций, денормализации — высокая сложность обновления данных, поддержка их в согласованном состоянии.
Если данные в некоторой таблице редко изменяются и одновременно с этим она часто участвует в JOIN’ах, имеет смысл объединить такую таблицу с другими. Если постепенно вся база превращается в денормализованную и сложность поддержки данных в согласованном состоянии начинает зашкаливать, то можно рассмотреть подход CQRS на уровне баз данных, при котором для записи данных используется полностью нормализованная база, для чтения — максимально денормализованая.
Применениие жестко денормальзованных баз данных типа NoSQL
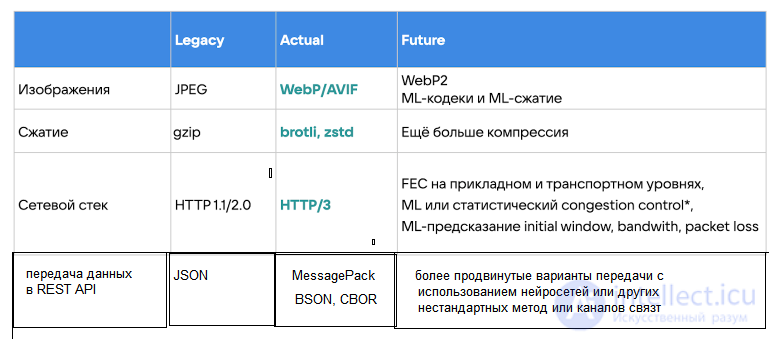
передача данных в REST API JSON/XML MessagePack более продвинутые варианты передачи с использованием нейросетей или других нестандартных метод или каналов связт
JSON, конечно, очень удобный и human-readable, но есть более современные решения, например: BSON, CBOR, MessagePack.
Мы установили следующие требования к новому формату представления данных:
бинарный;
быстрый (с поддержкой Zero-copy);
без схемы;
поддерживаются существующие в JSON типы для конвертации.
MessagePack, ускорились на 50% относительно JSON,
FastCGI Cache — это система кэширования данных реализованая на уровне HTTP-сервера Nginx.
Преимущество FastCGI Cache заключается в том, что Nginx вернет закешированный ответ пользователю сразу, как только получит запрос, при этом слой приложения не будет вовсе обрабатывать поступивший HTTP-запрос, если он имеется в кэше Nginx.
Использование FastCGI Cache — отличный способ снизить нагрузку на вашу систему.
Если на вашем сайте есть страницы, которые изменяются редко или задержка обновления информации на некоторое время не критична, то FastCGI Cache именно то, что нужно.
Если на сервер Nginx пришел HTTP-запрос и некоторое время назад ответ на такой же запрос был помещен в кэш, то Nginx не станет передавать данный запрос на выполнение PHP-FPM, в место этого Nginx вернет результат из кэша.

Кэширование объектов может серьезно улучшить производительность вашего сайта WordPress за счет оптимизации процесса запросов к базе данных, но при обслуживании запроса страницы по-прежнему возникают большие накладные расходы, поскольку сервер необходим для обработки PHP.
Эти накладные расходы вызваны тем, что WordPress и PHP должны создавать запрошенную HTML-страницу при каждой загрузке страницы. Мы можем уменьшить эту утечку ресурсов сервера, кэшируя HTML-версию запрошенной страницы после ее создания, а затем при следующем запросе этой страницы мы просто обслуживаем кешированную HTML-страницу и можем полностью избежать попадания в WordPress или PHP.
Этот тип статического кэширования страниц особенно полезен на сайтах, где содержимое каждой страницы обновляется редко.
Однако существуют различные варианты кэширования статической страницы, поэтому сначала давайте рассмотрим наши варианты.
Varnish Cache - это хорошо зарекомендовавший себя ускоритель веб-приложений, также известный как кэширующий обратный HTTP-прокси. По сути, вы устанавливаете его перед любым сервером (в нашем случае NGINX), который поддерживает HTTP, и он будет кэшировать возвращаемое содержимое любых запросов страницы.
Это действительно очень быстро.
Причина, по которой я решил использовать кэширование NGINX FastCGI вместо кэширования Varnish в этой серии, заключается в том, что Varnish не поддерживает протокол HTTPS, а кэширование NGINX FastCGI работает примерно так же быстро.
Наш сайт WordPress был настроен на использование Let's Encrypt SSL, чтобы воспользоваться преимуществами HTTP2, которые доступны только через HTTPS. Следовательно, чтобы использовать кеш Varnish, нам понадобится терминатор HTTP, сидящий перед ним, чтобы перехватывать и расшифровывать запросы HTTPS-страницы на порту 443 перед их передачей в кеш Varnish. Мы могли бы использовать NGINX для этой цели, но мы должны спросить, стоит ли такая повышенная сложность.
Вот две диаграммы, которые ясно иллюстрируют, почему я решил отказаться от кэширования Varnish для кэширования NGINX FastCGI:
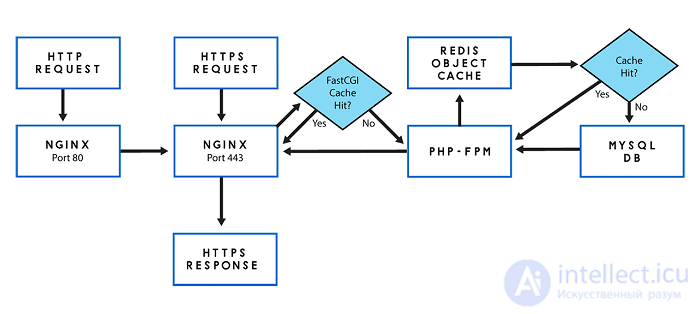
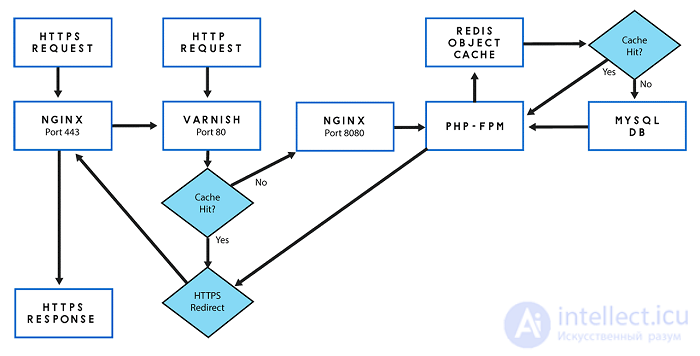
Отчетливо видна возросшая сложность. Добавление еще одного компонента в наш стек представляет еще одну возможную точку отказа и увеличивает нагрузку на администрирование и настройку.
Другой альтернативой кэшированию NGINX FastCGI является использование одного из многих плагинов статического кеширования WordPress.
Самый известный из них, WP Super Cache , создается самой Automattic. Этот плагин будет генерировать статические html-файлы с вашего динамического сайта WordPress и кэшировать их в каталоге WordPress. Когда посетитель посещает ваш сайт, ваш сервер будет обслуживать этот файл вместо обработки сравнительно более тяжелых и более дорогих скриптов WordPress PHP.
Такие плагины имеют множество настроек. При более продвинутой настройке они могут предлагать аналогичные улучшения, полностью обходя PHP. Однако эта расширенная конфигурация полагается на модуль Apache, поскольку наш стек использует более производительный веб-сервер NGINX, который нам понадобится для использования нестандартных конфигураций, которые труднее отлаживать.
Более простая конфигурация, рекомендованная плагином, фактически обслуживает статические файлы HTML с помощью PHP, чего мы хотим избежать.
Кроме того, эти плагины требуют, чтобы PHP и WordPress были запущены для обслуживания любых страниц. Одним из преимуществ кэширования NGINX FastCGI является то, что его можно настроить для продолжения обслуживания страниц даже в случае сбоя PHP (и, следовательно, WordPress).
По указанным выше причинам я решил использовать кэширование NGINX FastCGI.
Теперь, когда у нас включено кэширование объектов Redis и статическое кэширование страниц NGINX FastCGI, пора вернуться к нагрузочному тестированию и мониторингу серверов.
Войдите в свою панель управления New Relic Infrastructure и в Loader.io, чтобы начать нагрузочное тестирование и мониторинг.
1000 пользователей в минуту с включенным кешированием
Поскольку мы знаем, что без кэширования ЦП нашего сервера действительно начал испытывать нагрузку на 1000 пользователей в минуту, давайте начнем нагрузочное тестирование с этой настройки.

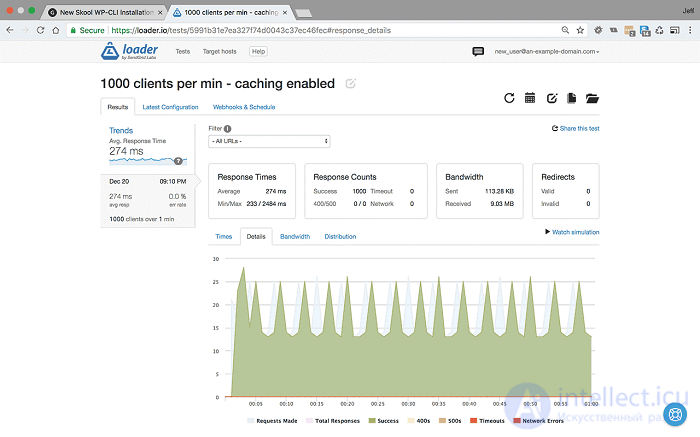
<1000 пользователей в минуту в течение 1 минуты с включенным кешированием - Настройки и результаты>
Как мы видим, при 1000 пользователей в минуту мы уменьшили время отклика с 338 мс до 274 мс, это отличное начало, но давайте посмотрим на использование ЦП в New Relic:
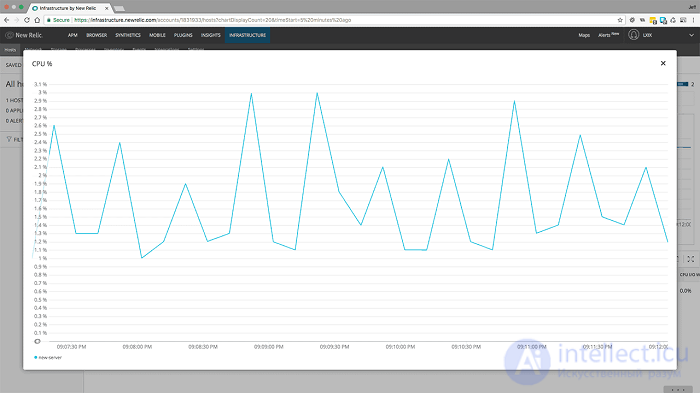
<1000 пользователей в минуту в течение 1 минуты с включенным кешированием - загрузка ЦП>
Здесь мы видим реальную пользу кеширования. Без кеширования загрузка ЦП увеличилась до 24%, но теперь у нас включено кеширование, и вы можете видеть, что загрузка ЦП остается стабильной на уровне 2-3%. Это невероятная разница.
5000 пользователей в минуту с включенным кешированием.
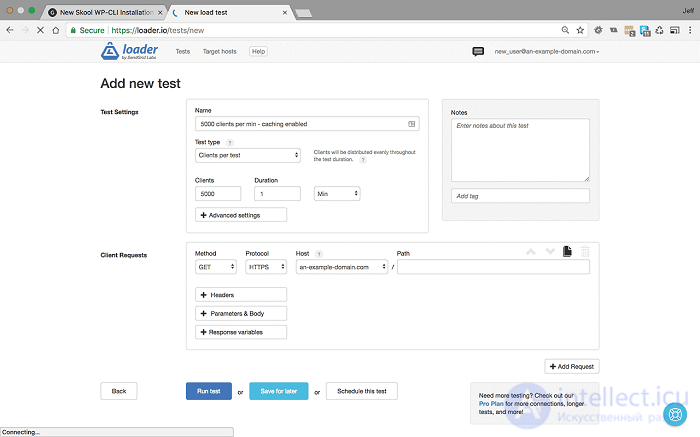
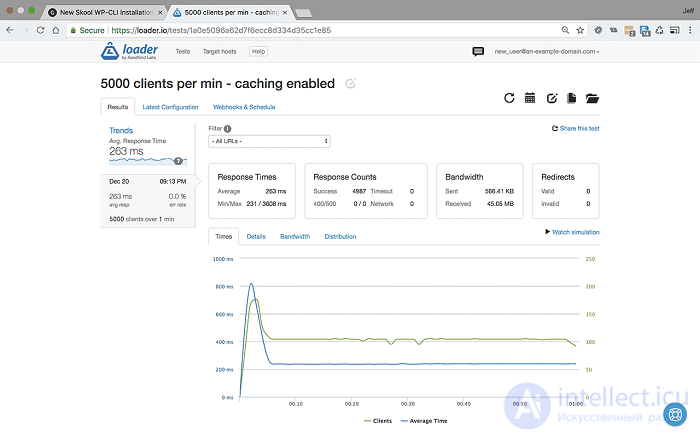
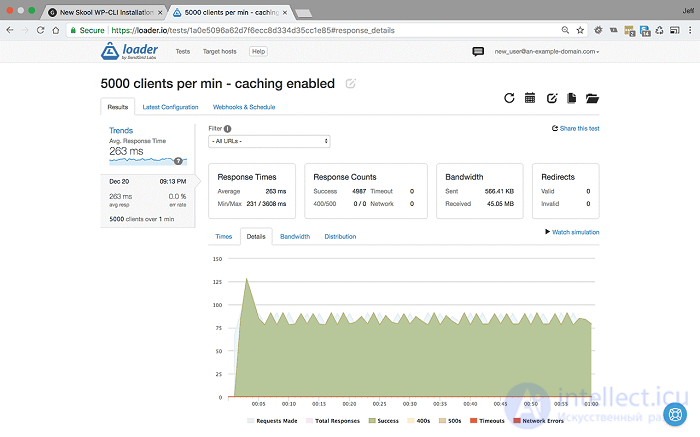
<5000 пользователей в минуту в течение 1 минуты с включенным кешированием - Настройки и результаты>
При 5000 пользователей в минуту без кеширования время отклика упало до 1715 мс, и мы начали показывать ошибки http 500. Но, как вы можете видеть, при кешировании среднее время отклика остается стабильным, в этом тесте оно фактически уменьшилось до 263 мс, и мы по-прежнему обслуживаем 100% ответов.
Посмотрим, какую картину рисует загрузка процессора
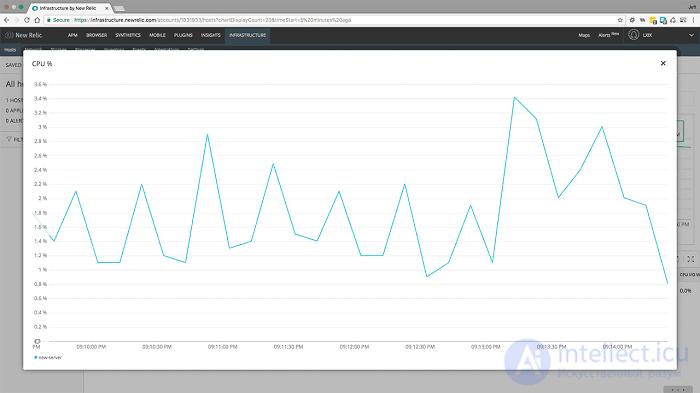
<5000 пользователей в минуту в течение 1 минуты с включенным кешированием - загрузка ЦП>
Та же история и здесь. Использование ЦП от 1000 до 5000 практически не изменилось. Он показывает небольшое увеличение примерно до 3,5%.
Помните, что без кеширования наш сервер раньше работал на 100%.
Ранее мы оценивали скорость 7500 пользователей в минуту, но давайте немного поторопимся с сервером и посмотрим, что произойдет ...
10000 пользователей в минуту с включенным кешированием.
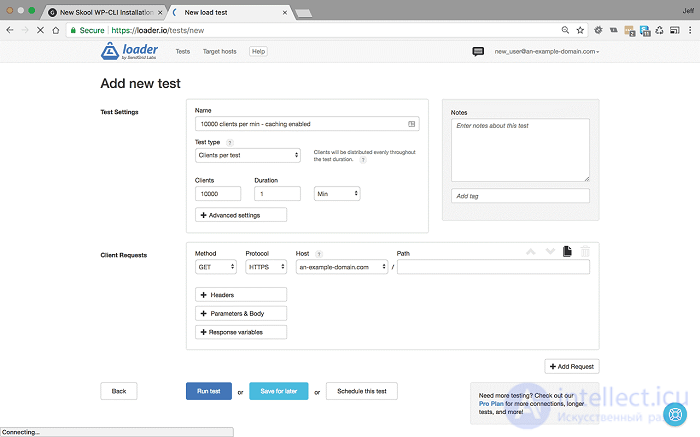
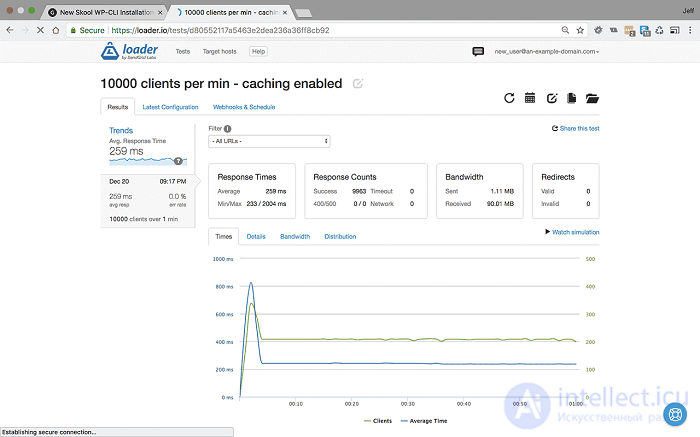
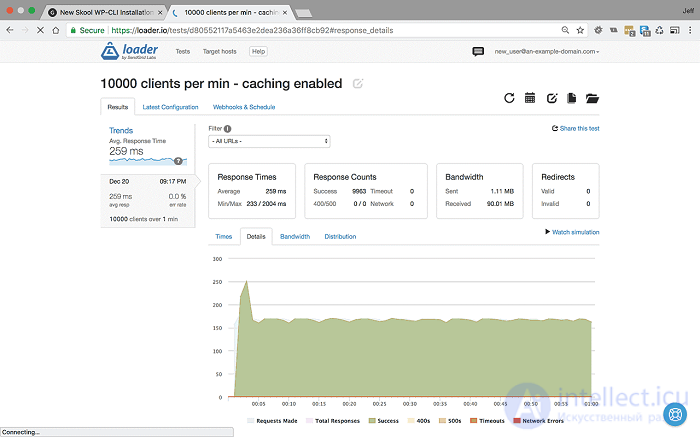
<10000 пользователей в минуту в течение 1 минуты с включенным кешированием - Настройки и результаты>
Именно при таких высоких нагрузках наш сервер раньше отказывался от кеширования, возвращая частоту ошибок 35%. Теперь, когда кэширование включено, вы можете видеть, что даже при 10000 пользователей в минуту наш сервер не ломает голову, среднее время отклика составляет 259 мсек, а частота ошибок 0%.
Что касается использования ЦП:
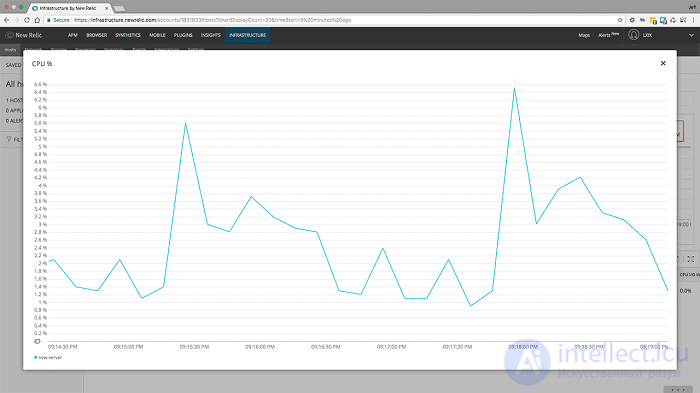
<10000 пользователей в минуту в течение 1 минуты с включенным кешированием - загрузка ЦП>
Использование ЦП сейчас выросло примерно до 6%, что по-прежнему находится в пределах оптимальной производительности.
Если мы хотим увеличить нагрузку на сервер, нам нужно переходить на количество пользователей в секунду.
500 пользователей в секунду в течение одной минуты с включенным кешированием
Это составляет 30000 посетителей в минуту, или 1,8 миллиона посетителей в час - на сервере .
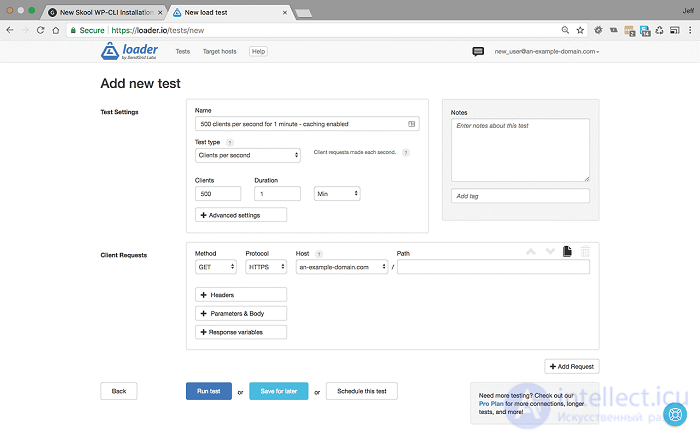
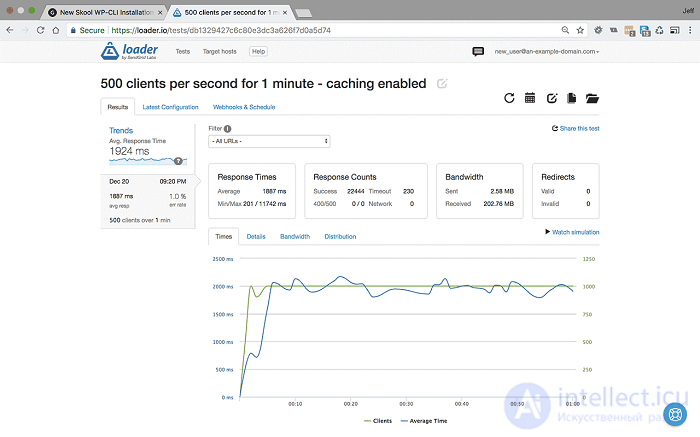

<500 пользователей в секунду в течение 1 минуты с включенным кешированием - Настройки и результаты>
Мы видим, что при скорости 500 пользователей в секунду в течение одной минуты сайт начинает тормозить. Среднее время ответа сократилось до 1887 мс, и это показывает 1% ошибок, в основном из-за тайм-аутов, что предполагает, что узким местом является ввод-вывод, а не производительность сервера.
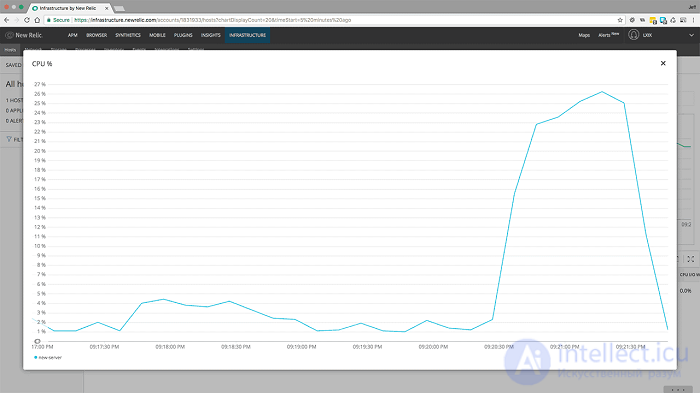
<500 пользователей в секунду в течение 1 минуты с включенным кешированием - загрузка ЦП>
Здесь мы видим, что загрузка ЦП достигла пика около 27%. Это все еще находится в пределах допустимого диапазона, что добавляет веса ошибкам, связанным с вводом-выводом.
Мы зашли так далеко, так что можем подтолкнуть лодку еще немного, пока мы здесь ...
1000 пользователей в секунду за одну минуту при включенном кешировании
(60000 посетителей в минуту, или 3,6 миллиона посетителей в час!)

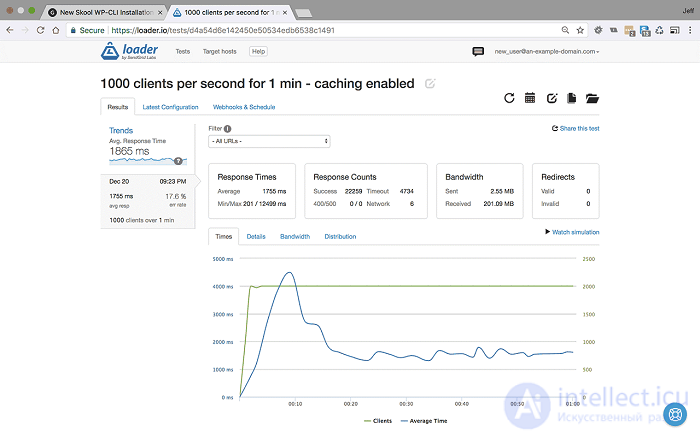
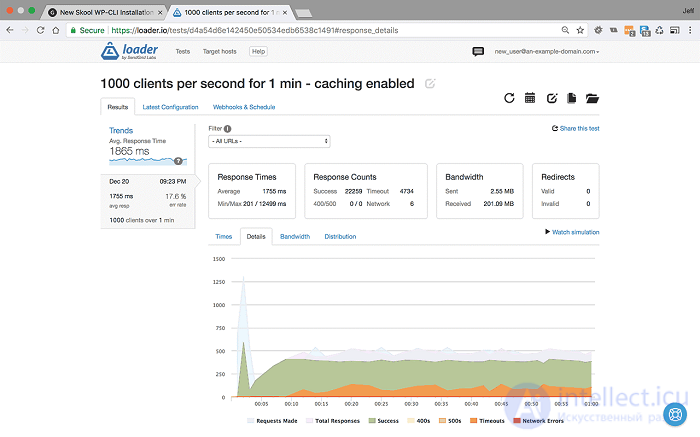
<1000 пользователей в секунду в течение 1 минуты с включенным кешированием - Настройки и результаты>
Мы видим, что среднее время отклика на самом деле остается стабильным и составляет около 1755 мс, но наша частота ошибок увеличилась до 17,6%, в основном из-за тайм-аутов.

<1000 пользователей в секунду ЦП - кеширование включено>
Интересно, что использование нашего процессора резко возрастает примерно до 36%, а затем снова падает и выходит на плато при аналогичном использовании до 500 пользователей в минуту.
Давайте посмотрим на использование ЦП нашего сервера, показывая результаты для сервера без кеширования и с включенным кешированием:
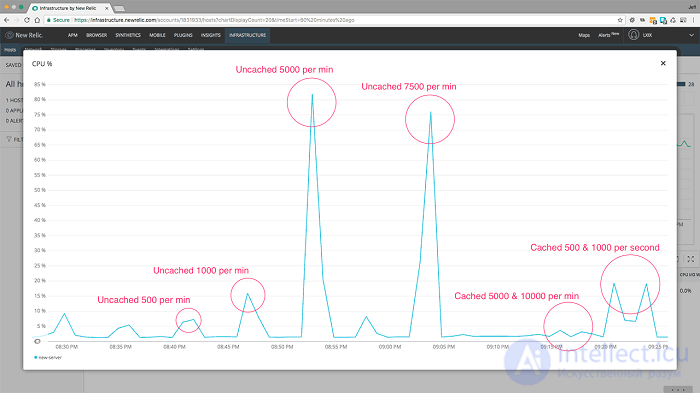
Использование ЦП показывает оба результата для сравнения.
Исследование, описанное в статье про оптимизация сайта, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое оптимизация сайта, производительность сайта и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы

Комментарии
Оставить комментарий
Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы
Термины: Высоконагруженные проекты.Паралельные вычисления. Суперкомпьютеры. Распределенные системы