Лекция
Привет, Вы узнаете о том , что такое методы распознавания образов, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое методы распознавания образов, объект, свойство, признак, шкала измерений, шкала свойств, образ , материал обучения, материал экзамена, решающее правило, таблица объекты-свойства, тос, мера сходства, метрика , настоятельно рекомендую прочитать все из категории Распознавание образов.
Курс лекций по распознаванию образ ов закономерно входит в систему подготовки специалистов по информатике, компьютерным системам и сетям. Не развивая арсенал возможностей искусственного интеллекта (в том числе методов распознавания), трудно рассчитывать на гармоничное совершенствование информационных технологий, расширение круга решаемых на их основе задач.
Человеческое восприятие индивидуально, поэтому одни и те же образы будут иметь разные и зачастую нечеткие границы у разных людей

Осуществление автоматического перевода с одного языка на другой, автоматическое стенографирование невозможно без распознавания печатных и рукописных текстов и знаков, устной речи.
Реализация методов распознавания необходима в автоматизированных системах, предназначенных для использования в криминалистике, медицине, военном деле. Такие применения теории распознавания, как кластерный анализ (таксономия), выявление закономерностей в множестве экспериментальных данных, прогнозирование различных процессов или явлений широко используются в научных исследованиях. Большую роль методы распознавания (классификации) играют в активно развивающихся геоинформационных системах.
Показательным в этом отношении является выдержка из монографии А.М. Берлянта «Геоиконика»: «...использование карт, дешифрирование снимков, анализ экранных видеоизображений – это всегда распознавание и анализ графических образов, их измерение, преобразование, сопоставление и т.п. Отсюда следует, что распознавание графических образов, то есть создание системы решающих правил для их идентификации, классификации и интерпретации – это одна из главных задач геоиконики".
Исторически сложилось так, что теория распознавания образов развивалась по двум направлениям: детерминистскому и статистическому, хотя чаще всего строго различить их не удается. Детерминистский подход включает различные методы: эмпирические, эвристические, в основе которых лежат здравый смысл, более или менее удачное моделирование действий, осуществляемых мозгом человека; математически формализованные, например, основанные на модели порождения объект ов (реализаций) того или иного образа. При этом используется различный математический аппарат (математическая логика, теория графов, топология, математическая лингвистика, математическое программирование и др.).
Статистический подход опирается на фундаментальные результаты математической статистики (теория оценок, последовательный анализ, стохастическая аппроксимация, теория информации).
Многие методы распознавания, появившиеся как детерминистские, получили в дальнейшем статистическое обоснование. Примеры подобного рода рассматриваются в предлагаемом курсе лекций.
В процессе развития теории распознавания различные подходы и применяемый математический аппарат переплелись столь причудливым образом, что классификация различных алгоритмов по используемым методам является условной и неоднозначной. Тем не менее в данном курсе выделены два раздела: детерминистские методы и статистические методы. Это сделано в основном из педагогических соображений. Детерминистские методы (особенно эмпирические) достаточно наглядны, легче воспринимаются, чем статистические, поэтому методически целесообразно начинать изложение материала с них.
Распознавание – это отнесение конкретного объекта (реализации), представленного значениями его свойств ( признак ов), к одному из фиксированного перечня образов (классов) по определенному решающему правилу в соответствии с поставленной целью.
Отсюда следует, что распознавание может осуществляться любой системой (живой или неживой), выполняющей следующие функции: измерение значений признаков, производство вычислений, реализующих решающее правило . При этом перечень образов, информативных признаков и решающие правила либо задаются распознающей системе извне, либо формируются самой системой. Вспомогательная, но важная функция распознающих систем – оценка риска потерь. Без этой функции невозможно, например, построить оптимальные решающие правила, выбрать наиболее информативную систему признаков, которые используются при распознавании, и др.
Введем следующие обозначения:
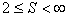 – множество распознаваемых образов (классов), называемое иногда алфавитом;
– множество распознаваемых образов (классов), называемое иногда алфавитом; – признаковое (выборочное) пространство;
– признаковое (выборочное) пространство;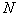 – размерность признакового пространства (количество признаков, характеризующих распознаваемые объекты);
– размерность признакового пространства (количество признаков, характеризующих распознаваемые объекты);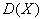 – множество решающих правил, по которым осуществляется отнесение распознаваемого объекта (реализации) к тому или иному образу;
– множество решающих правил, по которым осуществляется отнесение распознаваемого объекта (реализации) к тому или иному образу;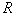 – риск потерь при распознавании.
– риск потерь при распознавании.Количество распознаваемых образов 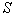 всегда конечно и не может быть меньше двух. Гипотетически, конечно, можно рассматривать случай
всегда конечно и не может быть меньше двух. Гипотетически, конечно, можно рассматривать случай 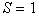 , но он является вырожденным, т.к. все реализации относят к одному и тому же образу. Для этого не нужно измерять значения каких бы то ни было признаков, решающее правило тривиально, а практический смысл решения подобного рода задачи распознавания вряд ли можно усмотреть.
, но он является вырожденным, т.к. все реализации относят к одному и тому же образу. Для этого не нужно измерять значения каких бы то ни было признаков, решающее правило тривиально, а практический смысл решения подобного рода задачи распознавания вряд ли можно усмотреть.
Перечень образов, как уже упоминалось, может задаваться распознающей системе извне (учителем). Например, если система предназначена для автоматического стенографирования, то распознаваемыми образами являются фонемы – элементы устной речи.
Во многих случаях распознающая система сама формирует перечень распознаваемых образов. В литературе этот процесс называют обучением без учителя, самообучением, кластерным анализом (таксономией). Эта функция реализуется чаще всего в исследовательском процессе: естественно-научная классификация, анализ данных, выявление закономерностей и т.п.
Размерность признакового пространства 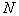 обычно стремятся сделать как можно меньше, поскольку при этом сокращается количество требуемых измерений, упрощаются вычисления, формирующие и реализующие решающие правила, повышается статистическая устойчивость результатов распознавания. Вместе с тем уменьшение
обычно стремятся сделать как можно меньше, поскольку при этом сокращается количество требуемых измерений, упрощаются вычисления, формирующие и реализующие решающие правила, повышается статистическая устойчивость результатов распознавания. Вместе с тем уменьшение , вообще говоря, ведет к росту риска потерь. Поэтому формирование признакового пространства является компромиссной задачей, которую можно разделить на две части: формирование исходного признакового пространства и минимизация размерности этого пространства. В части, касающейся минимизации размерности, существуют формальные методы, алгоритмы и программы. Что же касается исходного пространства, то его формирование пока что основано на опыте, интуиции, а то и везении. Теоретически обоснованные подходы к решению этой задачи в литературе не встречаются.
, вообще говоря, ведет к росту риска потерь. Поэтому формирование признакового пространства является компромиссной задачей, которую можно разделить на две части: формирование исходного признакового пространства и минимизация размерности этого пространства. В части, касающейся минимизации размерности, существуют формальные методы, алгоритмы и программы. Что же касается исходного пространства, то его формирование пока что основано на опыте, интуиции, а то и везении. Теоретически обоснованные подходы к решению этой задачи в литературе не встречаются.
Построение решающих правил, пожалуй, наиболее богатая в отношении разработанных подходов и методов решения компонента задач распознавания. Основная цель, которая при этом преследуется, – минимизация риска потерь.
На основе фундаментальных способов представления знаний можно предложить следующую классификацию методов распознавания (см. рисунок 1):
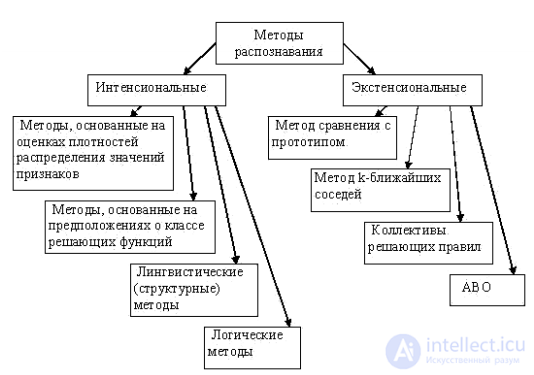
Рис 1 Классификация методов распознавания образов на снимках
Риск потерь 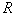 фактически является критерием, по которому формируется наиболее информативное признаковое пространство и наиболее эффективные решающие правила. И алфавит, и признаки, и решающие правила должны быть такими, чтобы по возможности минимизировать риск потерь. Этот критерий (характеристика распознающей системы) является составным. В него в общем случае входят потери (штрафы) за ошибки распознавания и затраты на измерения признаков распознаваемых объектов. В частном наиболее широко используемом случае в качестве риска потерь фигурирует средняя вероятность ошибки распознавания или максимальная компонента матрицы вероятностей ошибок. На практике, конечно, речь идет не о вероятностях, а об их выборочных оценках.
фактически является критерием, по которому формируется наиболее информативное признаковое пространство и наиболее эффективные решающие правила. И алфавит, и признаки, и решающие правила должны быть такими, чтобы по возможности минимизировать риск потерь. Этот критерий (характеристика распознающей системы) является составным. В него в общем случае входят потери (штрафы) за ошибки распознавания и затраты на измерения признаков распознаваемых объектов. В частном наиболее широко используемом случае в качестве риска потерь фигурирует средняя вероятность ошибки распознавания или максимальная компонента матрицы вероятностей ошибок. На практике, конечно, речь идет не о вероятностях, а об их выборочных оценках.
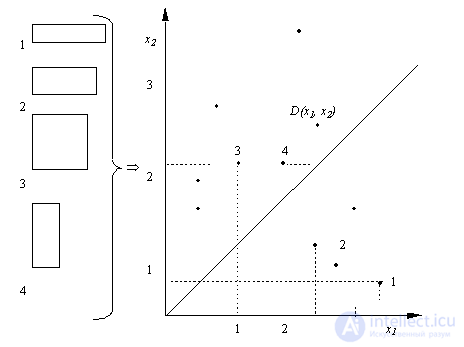
Рис. 2. Множество прямоугольников и их представление в признаковом пространстве
Итак,  можно представить как некоторое пространство размерности
можно представить как некоторое пространство размерности 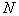 с определенной в этом пространстве метрикой. Любой объект (реализация) представляется в виде точки (вектора) в этом пространстве. Проекция этой точки на
с определенной в этом пространстве метрикой. Любой объект (реализация) представляется в виде точки (вектора) в этом пространстве. Проекция этой точки на 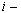 ю ось координат соответствует значению
ю ось координат соответствует значению 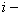 го признака. Например, множество прямоугольников со сторонами, параллельными осям координат, можно представить множеством точек в двухмерном признаковом пространстве (см. рис. 2) с евклидовой метрикой, где
го признака. Например, множество прямоугольников со сторонами, параллельными осям координат, можно представить множеством точек в двухмерном признаковом пространстве (см. рис. 2) с евклидовой метрикой, где 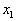 – длина горизонтальной стороны,
– длина горизонтальной стороны,  – длина вертикальной стороны. Если нам нужно распознавать два образа – вертикально и горизонтально вытянутые прямоугольники, то решающее правило в виде биссектрисы угла в начале координат
– длина вертикальной стороны. Если нам нужно распознавать два образа – вертикально и горизонтально вытянутые прямоугольники, то решающее правило в виде биссектрисы угла в начале координат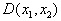 эту задачу выполняет. Все точки (объекты), лежащие выше – левее
эту задачу выполняет. Все точки (объекты), лежащие выше – левее 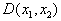 , относятся к образу "вертикально вытянутые прямоугольники", ниже – правее – "горизонтально вытянутые прямоугольники".
, относятся к образу "вертикально вытянутые прямоугольники", ниже – правее – "горизонтально вытянутые прямоугольники".
Приблизимся еще ближе к теме распознавания текста. Следует заметить, что под распознаванием текста обычно понимают три главных метода.
Распознаванием образов называются задачи построения и применения формальных операций над числовыми или символьными отображениями объектов реального или идеального мира, результаты решения которых отражают отношения эквивалентности между этими объектами. Отношения эквивалентности выражают принадлежность оцениваемых объектов к каким-либо классам, рассматриваемым как самостоятельные семантические единицы.
При построении алгоритмов распознавания классы эквивалентности могут задаваться исследователем, который пользуется собственными содержательными представлениями или использует внешнюю дополнительную информацию о сходстве и различии объектов в контексте решаемой задачи. Тогда говорят о “распознавании с учителем” [145]. В противном случае, т.е. когда автоматизированная система решает задачу классификации без привлечения внешней обучающей информации, говорят об автоматической классификации или “распознавании без учителя”. Большинство алгоритмов распознавания образов требует привлечения весьма значительных вычислительных мощностей, которые могут быть обеспечены только высокопроизводительной компьютерной техникой.
Различные авторы (Барабаш Ю.Л. [15], Васильев В.И. [26], Горелик А.Л., Скрипкин В.А. [37], Дуда Р., Харт П. [45], Кузин Л.Т. [60], Перегудов Ф.И., Тарасенко Ф.П. [99], Темников Ф.Е. [121], Ту Дж., Гонсалес Р. [145], Уинстон П. [126], Фу К. [130], Цыпкин Я.З. [133] и др.) дают различную типологию методов распознавания образов. Одни авторы различают параметрические, непараметрические и эвристические методы, другие - выделяют группы методов, исходя из исторически сложившихся школ и направлений в данной области. Например, в работе [46], в которой дан прекрасный обзор методов распознавания, используется следующая типология методов распознавания образов:
Подобная типология методов распознавания с той или иной степенью детализации встречается во многих работах по распознаванию. В то же время известные типологии не учитывают одну очень существенную характеристику, которая отражает специфику способа представления знаний о предметной области с помощью какого-либо формального алгоритма распознавания образов. Д.А.Поспелов (1990) выделяет два основных способа представления знаний:
Интенсиональное представление фиксируют закономерности и связи, которыми объясняется структура данных. Применительно к диагностическим задачам такая фиксация заключается в определении операций над атрибутами (признаками) объектов, приводящих к требуемому диагностическому результату. Интенсиональные представления реализуются посредством операций над значениями атрибутов и не предполагают произведения операций над конкретными информационными фактами (объектами).
В свою очередь, экстенсиональные представления знаний связаны с описанием и фиксацией конкретных объектов из предметной области и реализуются в операциях, элементами которых служат объекты как целостные системы.
Можно провести аналогию между интенсиональными и экстенсиональными представлениями знаний и механизмами, лежащими в основе деятельности левого и правого полушарий головного мозга человека. Если для правого полушария характерна целостная прототипная репрезентация окружающего мира, то левое полушарие оперирует закономерностями, отражающими связи атрибутов этого мира.
Описанные выше два фундаментальных способа представления знаний позволяют предложить следующую классификацию методов распознавания образов:
Интенсиональные - методы, основанные на операциях с признаками. Экстенсиональные методы распознавания образов - методы, основанные на операциях с объектами. Необходимо особо подчеркнуть, что с по мнению авторов существование именно этих двух и только двух групп методов распознавания (оперирующих с признаками, и оперирующих с объектами) глубоко закономерно и отражает фундаментальные характеристики взаимодействия Реальности и Сознания. С этой точки зрения ни один из этих методов, взятый отдельно от другого, не позволяет сформировать адекватное отражение Реальности. Стало быть между этими методами существует отношение дополнительности в смысле Н.Бора [19] и перспективные системы распознавания должны обеспечивать реализацию обоих этих методов, а не только какого-либо одного из них.
В приводимой ниже классификации основное внимание уделено формальным методам распознавания образов и поэтому опущено рассмотрение эвристического подхода к распознаванию, получившего полное и адекватное развитие в экспертных системах. По поводу этого подхода ограничимся лишь несколькими замечаниями.
Эвристический подход основывается на трудно формализуемых знаниях и интуиции исследователя. В этом подходе исследователь сам определяет, какую информацию и каким образом нужно использовать для достижения требуемого эффекта распознавания.
Отличительной особенностью интенсиональных методов является то, что в качестве элементов операций при построении и применении алгоритмов распознавания образов они используют различные характеристики признаков и их связей. Такими элементами могут быть отдельные значения или интервалы значений признаков, средние величины и дисперсии, матрицы связи признаков и т. п., над которыми производятся действия, выражаемые в аналитической или конструктивной форме. При этом объекты в данных методах не рассматриваются как целостные информационные единицы, а выступают в роли индикаторов для оценки взаимодействия и поведения своих атрибутов.
Группа интенсиональных методов распознавания образов обширна, и ее деление на подклассы носит в определенной мере условный характер.
Эти методы распознавания образов заимствованы из классической теории статистических решений, в которой объекты исследования рассматриваются как реализации многомерной случайной величины, распределенной в пространстве признаков по какому-либо закону [37]. Они базируются на байесовской схеме принятия решений, апеллирующей к априорным вероятностям принадлежности объектов к тому или иному распознаваемому классу и условным плотностям распределения значений вектора признаков. Данные методы сводятся к определению отношения правдоподобия в различных областях многомерного пространства признаков.
Группа методов, основанных на оценке плотностей распределения значений признаков имеет прямое отношение к методам дискриминантного анализа. Байесовский подход к принятию решений и относится к наиболее разработанным в современной статистике так называемым параметрическим методам, для которых считается известным аналитическое выражение закона распределения (в данном случае нормальный закон) и требуется оценить лишь небольшое количество параметров (векторы средних значений и ковариационные матрицы).
К этой группе относится и метод вычисления отношения правдоподобия для независимых признаков. Этот метод, за исключением предположения о независимости признаков (которое в действительности практически никогда не выполняется), не предполагает знания функционального вида закона распределения. Поэтому его можно отнести к непараметрическим [46].
Другие непараметрические методы, применяемые тогда, когда вид кривой плотности распределения неизвестен и нельзя сделать вообще никаких предположений о ее характере, занимают особое положение. К ним относятся известные метод многомерных гистограмм, метод “k-ближайших соседей, метод евклидова расстояния, метод потенциальных функций и др., обобщением которых является метод, получивший название “оценки Парзена” [46]. Эти методы формально оперируют объектами как целостными структурами, но в зависимости от типа задачи распознавания могут выступать и в интенсиональной и в экстенсиональной ипостасях.
Непараметрические методы анализируют относительные количества объектов, попадающих в заданные многомерные объемы, и используют различные функции расстояния между объектами обучающей выборки и распознаваемыми объектами [46]. Для количественных признаков, когда их число много меньше объема выборки, операции с объектами играют промежуточную роль в оценке локальных плотностей распределения условных вероятностей и объекты не несут смысловой нагрузки самостоятельных информационных единиц. В то же время, когда количество признаков соизмеримо или больше числа исследуемых объектов, а признаки носят качественный или дихотомический характер, то ни о каких локальных оценках плотностей распределения вероятностей не может идти речи. В этом случае объекты в указанных непараметрических методах рассматриваются как самостоятельные информационные единицы (целостные эмпирические факты) и данные методы приобретают смысл оценок сходства и различия изучаемых объектов.
Таким образом, одни и те же технологические операции непараметрических методов в зависимости от условий задачи имеют смысл либо локальных оценок плотностей распределения вероятностей значений признаков, либо оценок сходства и различия объектов.
В контексте интенсионального представления знаний здесь рассматривается первая сторона непараметрических методов, как оценок плотностей распределения вероятностей. Многие авторы отмечают, что на практике непараметрические методы типа оценок Парзена работают хорошо [46]. Основными трудностями применения указанных методов считаются необходимость запоминания всей обучающей выборки для вычисления оценок локальных плотностей распределения вероятностей и высокая чувствительность к непредставительности обучающей выборки.
В данной группе методов считается известным общий вид решающей функции и задан функционал ее качества. На основании этого функционала по обучающей последовательности ищется наилучшее приближение решающей функции [124]. Самыми распространенными являются представления решающих функций в виде линейных и обобщенных нелинейных полиномов. Функционал качества решающего правила обычно связывают с ошибкой классификации.
Основным достоинством методов, основанных на предположениях о классе решающих функций, является ясность математической постановки задачи распознавания, как задачи поиска экстремума [124]. Решение этой задачи нередко достигается с помощью каких-либо градиентных алгоритмов. Многообразие методов этой группы объясняется широким спектром используемых функционалов качества решающего правила и алгоритмов поиска экстремума. Обобщением рассматриваемых алгоритмов, к которым относятся, в частности, алгоритм Ньютона, алгоритмы перцептронного типа и др., является метод стохастической аппроксимации. В отличие от параметрических методов распознавания успешность применения данной группы методов не так сильно зависит от рассогласования теоретических представлений о законах распределения объектов в пространстве признаков с эмпирической реальностью. Все операции подчинены одной главной цели - нахождению экстремума функционала качества решающего правила. В то же время результаты параметрических и рассматриваемых методов могут быть похожими. Как показано выше, параметрические методы для случая нормальных распределений объектов в различных классах с равными ковариационными матрицами приводят к линейным решающим функциям. Отметим также, что алгоритмы отбора информативных признаков в линейных диагностических моделях, можно интерпретировать как частные варианты градиентных алгоритмов поиска экстремума.
Возможности градиентных алгоритмов поиска экстремума, особенно в группе линейных решающих правил, достаточно хорошо изучены. Сходимость этих алгоритмов доказана только для случая, когда распознаваемые классы объектов отображаются в пространстве признаков компактными геометрическими структурами. Однако стремление добиться достаточного качества решающего правила нередко может быть удовлетворено с помощью алгоритмов, не имеющих строгого математического доказательства сходимости решения к глобальному экстремуму [46].
К таким алгоритмам относится большая группа процедур эвристического программирования, представляющих направление эволюционного моделирования. Эволюционное моделирование является бионическим методом, заимствованным у природы. Оно основано на использовании известных механизмов эволюции с целью замены процесса содержательного моделирования сложного объекта феноменологическим моделированием его эволюции.
Известным представителем эволюционного моделирования в распознавании образов является метод группового учета аргументов (МГУА) [46]. В основу МГУА положен принцип самоорганизации, и алгоритмы МГУА воспроизводят схему массовой селекции. В алгоритмах МГУА особым образом синтезируются и отбираются члены обобщенного полинома, который часто называют полиномом Колмогорова-Габора. Этот синтез и отбор производится с нарастающим усложнением, и заранее нельзя предугадать, какой окончательный вид будет иметь обобщенный полином. Сначала обычно рассматривают простые попарные комбинации исходных признаков, из которых составляются уравнения решающих функций, как правило, не выше второго порядка. Каждое уравнение анализируется как самостоятельная решающая функция, и по обучающей выборке тем или иным способом находятся значения параметров составленных уравнений. Затем из полученного набора решающих функций отбирается часть в некотором смысле лучших. Проверка качества отдельных решающих функций осуществляется на контрольной (проверочной) выборке, что иногда называют принципом внешнего дополнения. Отобранные частные решающие функции рассматриваются далее как промежуточные переменные, служащие исходными аргументами для аналогичного синтеза новых решающих функций и т. Об этом говорит сайт https://intellect.icu . д. Процесс такого иерархического синтеза продолжается до тех пор, пока не будет достигнут экстремум критерия качества решающей функции, что на практике проявляется в ухудшении этого качества при попытках дальнейшего увеличения порядка членов полинома относительно исходных признаков.
Принцип самоорганизации, положенный в основу МГУА, называют эвристической самоорганизацией, так как весь процесс основывается на введении внешних дополнений, выбираемых эвристически. Результат решения может существенно зависеть от этих эвристик. От того, как разделены объекты на обучающую и проверочную выборки, как определяется критерий качества распознавания, какое количество переменных пропускается в следующий ряд селекции и т. д., зависит результирующая диагностическая модель.
Указанные особенности алгоритмов МГУА свойственны и другим подходам к эволюционному моделированию. Но отметим здесь еще одну сторону рассматриваемых методов. Это - их содержательная сущность. С помощью методов, основанных на предположениях о классе решающих функций (эволюционных и градиентных), можно строить диагностические модели высокой сложности и получать практически приемлемые результаты. В то же время достижению практических целей в данном случае не сопутствует извлечение новых знаний о природе распознаваемых объектов. Возможность извлечения этих знаний, в частности знаний о механизмах взаимодействия атрибутов (признаков), здесь принципиально ограничена заданной структурой такого взаимодействия, зафиксированной в выбранной форме решающих функций. Поэтому максимально, что можно сказать после построения той или иной диагностической модели - это перечислить комбинации признаков и сами признаки, вошедшие в результирующую модель. Но смысл комбинаций, отражающих природу и структуру распределений исследуемых объектов, в рамках данного подхода часто остается нераскрытым.
Логические методы распознавания образов базируются на аппарате алгебры логики и позволяют оперировать информацией, заключенной не только в отдельных признаках, но и в сочетаниях значений признаков. В этих методах значения какого-либо признака рассматриваются как элементарные события [46].
В самом общем виде логические методы можно охарактеризовать как разновидность поиска по обучающей выборке логических закономерностей и формирование некоторой системы логических решающих правил (например, в виде конъюнкций элементарных событий), каждое из которых имеет собственный вес. Группа логических методов разнообразна и включает методы различной сложности и глубины анализа. Для дихотомических (булевых) признаков популярными являются так называемые древообразные классификаторы, метод тупиковых тестов, алгоритм “Кора” и другие. Более сложные методы основываются на формализации индуктивных методов Д.С.Милля. Формализация осуществляется путем построения квазиаксиоматической теории и базируется на многосортной многозначной логике с кванторами по кортежам переменной длины [46].
Алгоритм “Кора”, как и другие логические методы распознавания образов, является достаточно трудоемким, поскольку при отборе конъюнкций необходим полный перебор. Поэтому при применении логических методов предъявляются высокие требования к эффективной организации вычислительного процесса, и эти методы хорошо работают при сравнительно небольших размерностях пространства признаков и только на мощных компьютерах.
Лингвистические методы распознавания образов основаны на использовании специальных грамматик порождающих языки, с помощью которых может описываться совокупность свойств распознаваемых объектов [130].
Для различных классов объектов выделяются непроизводные (атомарные) элементы (подобразы, признаки) и возможные отношения между ними. Грамматикой называют правила построения объектов из этих непроизводных элементов [130]. Таким образом, каждый объект представляется совокупностью непроизводных элементов, “соединенных” между собой теми или иными способами или, другими словами, “предложением” некоторого “языка”. Авторы хотели бы особо подчеркнуть очень значительную на их взгляд мировоззренческую ценность этой мысли. Путем синтаксического анализа (грамматического разбора) “предложения” устанавливается его синтаксическая “правильность” или, что эквивалентно, - может ли некоторая фиксированная грамматика (описывающая класс) породить имеющееся описание объекта. Грамматический разбор производится так называемым “синтаксическим анализатором”, который представляет полное синтаксическое описание объекта в виде дерева грамматического разбора, если объект является синтаксически правильным (принадлежит классу, описываемому данной
продолжение следует...
Часть 1 Методы распознавания образов, классификация и основные понятия
Часть 2 ЭКСТЕНСИОНАЛЬНЫЕ МЕТОДЫ - Методы распознавания образов, классификация и основные понятия
Часть 3 АНАЛИЗ ПЕРСПЕКТИВНЫХ НАПРАВЛЕНИЙ РАЗВИТИЯ МЕТОДОВ РАСПОЗНАВАНИЯ - Методы распознавания образов,
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области методы распознавания образов имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое методы распознавания образов, объект, свойство, признак, шкала измерений, шкала свойств, образ , материал обучения, материал экзамена, решающее правило, таблица объекты-свойства, тос, мера сходства, метрика и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов

Комментарии