Лекция
Привет, Вы узнаете о том , что такое проблемы распознавания, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое проблемы распознавания, проблемы распознавания образов, ошибки распознавания , настоятельно рекомендую прочитать все из категории Распознавание образов.
Проблема, ошибки и сложности распознавания образов является одной из центральных в концепции искусственного интеллекта. В статье рассматриваются не сами алгоритмы распознавания изображений – а об ограниченности их использования, в частности при создании искусственного интеллекта.
По моему мнению, распознавание визуальных образов человеком и компьютерной системой сильно различается – настолько сильно, что имеет между собой мало общего. Когда человек говорит «Я вижу», на самом деле он более мыслит, чем видит, чего не скажешь о компьютерной системе, снабженной оборудованием для распознавания изображений.
Знаю, мысль не нова, но предлагаю еще раз убедиться в ее справедливости на примере робота, претендующего на обладание интеллектом. Тестовый вопрос звучит так: каким робот должен видеть окружающий мир, чтобы полностью уподобиться человеку?
Разумеется, робот должен распознавать предметы. О да, с этим алгоритмы справляются – посредством обучения на исходных образцах, насколько понимаю. Но ведь этого катастрофически мало!
Под классическими в данной статье понимаются подходы или методы распознавания образов, удовлетворяющие двум условиям:
Под «классической» понимается задача распознавания образов в следующей постановке (см. предисловие Ю.И. Журавлева к работе ): «объекты распознавания заданы набором признаков, известно некоторое число эталонных объектов, и их описания составляют исходную (обучающую) информацию. На основе этой информации синтезируется алгоритм, определяющий для вновь поступивших объектов, к какому (или к каким) из конечного числа классов они принадлежат». Эта же схема распознавания приводится и в справочнике по искусственному интеллекту [5, c. 150].
Как представляется, основные ограничения классических методов распознавания образов можно выразить следующими положениями:
Классическая схема распознавания, использующая понятия признаков, их комбинирования и последующей классификации, использует несколько неявных, нигде не декларируемых допущений, сводящихся к следующему:
в каждый данный момент воспринимается лишь один образ, при этом уровень информации, связанной с фоном, либо незначителен, либо мы имеем простые инструменты для отделения той части информации, которая связана с фоном, от информации о признаках;
задача субъекта восприятия (человека или робота) сводится к отнесению объекта к одному из классов и ни к чему более.
действительности ни одно из этих допущений не выполняется. Мы (или робот) воспринимаем окружающий мир, содержащий множество объектов. В зависимости от задач одни из этих объектов мы выделяем, другие воспринимаем как фон, и задача распознавания в этом случае значительно сложнее классической схемы: а) мы должны выделить из шумов информацию о признаках множества распознаваемых объектов, при этом заранее не очевидно, что в сигнале считать шумом, а что полезной информацией; т.е. какие признаки выделять из шума. Очевидно, эта задача имеет множество возможных решений и мы должны выбрать нужное; б) мы должны каким-либо образом отнести признаки к какому- то объекту, причем и без численных оценок очевидно, что комбинаторным путем эту задачу не решить, и здесь необходимо использование некоторых принципов, резко ограничивающих число возможных вариантов; в) мы должны далее эти объекты распознать, выделить из них интересующие нас и соотнести их с нашими проблемами.
По поводу второго допущения: распознавание образов не является независимой процедурой, оно встроено в схему восприятия и мышления. И в этой схеме распознавание составляет только часть задачи. Вторая часть задачи – на фоне некоторой относительно инвариантной части выделить особенности образа или ситуации, характеризующие его здесь и сейчас, и использовать эти конкретные особенности в мышлении. Например, когда мы встречаем старого знакомого, то мы не просто относим его к одному из классов, а определяем его настроение, узнаем о проблемах и т.д. И в конце встречи мы не относим полученный нами новый образ к какому-то существующему классу – это невозможно из-за чисто комбинаторных соображений, а конструируем новый образ, состоящий из двух частей: некоторого инварианта I и уникальной переменной части delta, которую мы составляем из элементов наших впечатлений и языка (по сути, понятий, которые тоже можно представить как некоторый класс образов). Таким образом, результат восприятия V по отношению к отдельному выделенному нами образу более правильно выражать формулой:
V = I + delta.
Подчеркнем принципиальную важность представления образов в указанной форме. Работа мышления и интеллекта в значительной мере определяется именно уникальной, а не инвариантной частью воспринимаемых образов, поэтому, не учитывая ее, мы, по сути, выбрасываем наиболее важные
Подчеркнем принципиальную важность представления образов в указанной форме. Работа мышления и интеллекта в значительной мере определяется именно уникальной, а не инвариантной частью воспринимаемых образов, поэтому, не учитывая ее, мы, по сути, выбрасываем наиболее важные слагаемые мышления и интеллекта. Становится очевидным, что только по одной этой причине (неучете уникальной составляющей образа) классическая схема распознавания не может быть использована для моделирования работы интеллекта. Неучет уникальной составляющей образа приводит к так называемому алгоритмическому или автоматному подходу, который эквивалентен работе нервной системы на уровне насекомого. Представляется, что большинство специалистов, занимающихся распознаванием образов согласятся, что разработанные в настоящее время искусственные распознающие системы в лучшем случае достигают уровня насекомого. Заметим, что и кибернетика как наука, и распознавание образов не смогли преодолеть автоматный рубеж, в результате чего вместо кибернетики появились информационные технологии, Data Miningи ряд других новых дисциплин, а наука о распознавании образов переживает кризис. (К большому сожалению, эти новые дисциплины не смогли полностью компенсировать упадок кибернетики, поскольку не используют должным образом лежащий в основании кибернетики системный принцип – и это веский аргумент в пользу обновленной кибернетики).
Хорошо известно, что процесс распознавания у человека и животных – это сложный и многоэтапный процесс, сопровождающийся неоднократным перекодированием, сжатием, обобщением и изменением представления (языка и набора признаков) информации, относящейся к образу, или, точнее, образам вместе с фоном и шумом (экспериментальные данные по этому вопросу достаточно хорошо изложены в , а их анализ проведен, в частности, в работе [10]). Кажется естественным, что описание всех этих процедур должно осуществляться на основе понятия информации. Но позволяет ли современное понятие информации это сделать? Можно однозначно и категорически утверждать – нет, не позволяет. Рассмотрим кратко причины этого. Не ругал понятие информации разве что самый ленивый, в литературе существует множество различающихся формулировок этого понятия, но мы отметим лишь самые известные, которые принято использовать в серьезных исследованиях. В 1948 г. К. Шеннон определил количество передаваемой информации как логарифм числа возможных состояний сигнала [11] (комбинаторный подход). Введенное понятие получило широкую известность и было модифицировано в нескольких направлениях. Во-первых, была показана тесная связь понимаемой таким образом информации с энтропией. Во -вторых, комбинаторный подход был дополнен вероятностной трактовкой (при этом формулы для количества информации сохранили практически прежний вид). И в-третьих, было введено понятие условной вероятности как разности логарифмов состояний или выборов системы до и после получения информации. В дальнейшем А.Н. Колмогоро-вым [12] была предложена алгоритмическая трактовка количества информации как наиболее краткого описания программы перевода объекта из одного состояния в другое. Все эти подходы к определению понятия информации объединяют две общие черты:
1) предполагается, что как сообщение в целом, так и все его составные части имеют информационную ценность (причем одинако-вую) для воспринимающей системы, т.е. каждая часть сигнала приводит к уменьшению числа возможных состояний системы;
2) предполагается, что все состояния или выборы воспринимающей системы равноправны.
Реально ни одно из этих предположений не выполняется, в связи с чем на практике мы, в основном, используем другое понимание информации, основывающееся не на длине сообщения, а на его важности для воспринимающего субъекта. В связи с этим было предложено большое число подходов к информации, основывающихся на ее важности (см. напр. обзор состояния этого вопроса в [13]). Но ни один из этих подходов не получил в настоящее время широкого признания. По-видимому, это связано с тем, что понятия ценности, важности и аналогичные невозможно ввести без субъективизма – зависимости от субъекта, задачи, сложности информации, этапа ее обработки и т.д. При этом мы получаем многокритериальную задачу. Но хорошо известно, что задачи такого типа в общем случае имеют множество возможных решений (множество Парето). В таком случае вряд ли в обозримом будущем мы будем иметь ценностную трактовку информации, более четко определенную, чем, например, понятия свободы, справедливости или моральности. Таким образом, ни одна из существующих трактовок информации не позволяет использовать это понятие для описания процесса передачи информации между уровнями и представлениями (языками) в процессе распознавания образов. В связи с этим, возможно, необходима разработка понятий, заменяющих понятие информации, но более узких по содержанию и позволяющих более однозначно и адекватно описывать информационные преобразования в процессе распознавания. Помимо этого, необходимо использовать и развивать теорию перевода. При этом акцент должен быть сделан на понимании сущности перевода между языками различного (а не одинакового) уровня и различными представлениями.
образи его компонентов
В процессе распознавания по классической схеме в отношении распознаваемого образа используется несколько допущений (их можно назвать также принципами, подходами, схемами и т.п.), в частности, следующие: – на пути между исходной «сырой» информацией и конечным распознанным образом вводится некоторый промежуточный этап упорядочения исхо дной информации, называемый признаком или набором признаков; – распознавание осуществляется по схеме: получение изображения, выделение из него признаков, получение образа как комбинации признаков, процесс отнесения образа к одному из классов (назовем это распознаванием снизу вверх); – во всех случаях как набор распознанных признаков, так и получаемый из него образ может быть распознан единственным правильным способом. Насколько обоснованы эти допущения? Рассмотрим первое допущение. Как следует из литературы, «задача выбора признаков… понимается как преобразование (отображение) исходного пространства в пространство признаков меньшей размерности без потери информации» [14, c. 8], т.е. с помощью признаков на первом этапе существенно сокращается как описание образа, так и последующее оперирование информацией относительно образа. На втором этапе признаки используются для построения образа в виде набора признаков, и далее происходит собственно распознавание. Если второй этап любовно, тщательно и детально описан многочисленными авторами, то по поводу первого пишут мало и в основном в терминах целей, а не алгоритмов. Неудовлетворительное состояние этого вопроса отмечается, в частности, в работе [2, c. 152]: «Хорошо мы научились решать задачи, в которых еще до обучения так или иначе уже построено пространство признаков или задан словарь языка… И чем удачнее (человеком, а не машиной) выбраны признаки, тем компактнее образы, а значит, тем успешнее решается задача обучения… Но если признаки заранее не заданы или выбираются случайно и неудачно, то все методы теряют работоспособность, их надежность и качество катастрофически снижаются… Итак, мы еще не научились главному – автоматизации процесса построения таких пространств изображений объектов, в которых объекты были бы компактными».
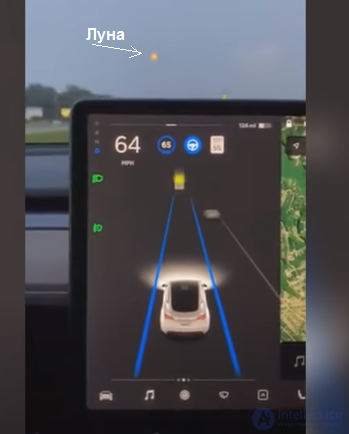
Пример
Система распознавания автопилота восприняла Луну за светофор, на котором загорелся желтый сигнал, и начала снижать скорость атомобиля.
Чтобы понять причины недостаточного внимания к проблеме выделения признаков, рассмотрим распознавание образов на понятийном уровне у человека. Очевидно, что процесс распознавания в этом случае состоит, во-первых, более чем из двух уровней, а во-вторых, на всех вышестоящих уровнях мы работаем, по сути, не с признаками, а с понятиями, которые более правильно представлять как образы, а не как признаки. Например, когда мы распознаем человека, согласно классической схеме мы сначала распознаем признаки. Вчастности, пусть одним из этих признаков будут очки. Но образ очков сам по себе достаточно сложен, и в другой задаче распознавания очки могут выступать в качестве самостоятельного распознаваемого образа, содержащего подобразы, например, линзы и т.д. Следовательно, по крайней мере на уровне понятийного мышления схема распознавания выглядит не как цепочка признак – образ, а как образ 1-го уровня – образ 2-го уровня … – конечный образ. Таким образом, введение понятия признак – это некий интеллектуальный фокус (по крайней мере на уровне понятийного мышления), с помощью которого мы из рассмотрения процесса распознавания выбрасываем собственно распознавание и оставляем более понятную задачу манипулирования образами различных уровней (более понятна она в том случае, когда мы выбрасываем из этой схемы выходы на мышление, т.е. переменную часть образа, см. раздел 1). Эти рассуждения, по-видимому, менее применимы к более простым случаям распознавания, например, речи или несложных изображений. Связано это с тем, что в этом случае в качестве признаков или промежуточного этапа на пути к признакам используются достаточно несложные инварианты (непроизводные элементы по Д. Марру [15]), для которых разработаны алгоритмы получения их из исходной «сырой» информации.
Теперь рассмотрим последовательность распознавания: исходная информация – признак – образ. Как указано выше, следуя логике существующего подхода к распознаванию, для сложных случаев ее более правильно выражать цепочкой:исходная информация – образ 1-го уровня… – конечный образ. Но если исходить из экспериментальных данных, то у человека, по крайней мере, при зрительном восприятии, работает совершенно другая схема. В этой схеме наше распознавание сцены в целом базируется прежде всего на некотором целостном понимании, которое в психологии принято называть гештальтом. «Главное эмпирическое существо открытого гештальтизмом феномена целостности перцептивного образа… заключается в доминировании целостной структуры перцепта над восприятием его отдельных элементов» [16, гл. 9]. Может последовать возражение, что эти выводы относятся к процессу мышления – стадии, следующей за распознаванием, когда мы уточняем содержание сцены. Однако имеются веские нейрофизиологические данные, свидетельствующие, что и сам процесс распознавания образов осуществляется по гештальтной схеме. Так, в работе [17] было показано, что разные пространственно -частотные компоненты сложного изображения у живых существ выделяются и описываются в зрительной коре независимо работающими каналами. В дальнейшем в работах В.Д. Глезера [18] и других исследователей была предложена и экспериментально обоснована схема с использованием фурье-преобразования. Низкочастотному фурье-преобразованию соответствуют крупномасштабные детали изображения, высокочастотной части – мелкие детали.
Экспериментально было доказано, что крупномасштабные детали человек воспринимает быстрее, чем мелкомасштабные (см. детальный обзор и анализ этого вопроса в [18, гл. 3]). Соответственно и распознавание начинается с крупных деталей, описывающих сцену в целом, а не отдельные ее признаки. Этот вывод является простым следствием из законов передачи информации: малое разрешение требует меньше информации, чем высокое, а в связи с невысокой скоростью передачи информации у человека (примерно 10 2 импульсов/сек на одно нервное волокно) или большим ее объемом, информация о деталях изображения воспринимается распознающей системой (мозгом) заметно позднее, чем очертания сцены в целом. Таким образом, распознавание образов у человека правильнее было бы описывать следующей схемой: исходная информация – образ в целом – уточнение деталей (признаков) образа (распознавание сверху вниз). В более сложных случаях, учитывая, что человек в состоянии оперировать одновременно с 7 ? 2 объектами, схема распознавания, по-видимому, усложняется и выглядит примерно следующим образом: исходная информация – одновременное выделение и предварительное распознавание нескольких образов – одновременное уточнение деталей каждого из образов и распознавание сложного образа или придание смысла сцене (сочетание элементов распознавания сверху вниз и снизу вверх). С учетом состояния искусственных и естественных распознающих систем представляется, что нет и не может быть единой правильной схемы распознавания образов. Возможно использование самых различных схем, причем это определяется предметной областью, задачами исследования и имеющимся инструментарием. Основанием к выбору таких схем должна быть отсутствующая в настоящее время общая теория преобразования и передачи информации между представлениями и языками различного уровня и происхождения. В заключение этой темы добавим, что экспериментальные данные [17-19] показывают, что в достаточно сложных распознающих системах, в частности у человека и высших животных, используется одновременно несколько распознающих схем. Рассмотрим теперь допущение о единственности распознаваемого образа или образов. Об этом говорит сайт https://intellect.icu . Очевидно, что это допущение существенно опирается на допущение о единственности классификации. Не оспаривая этого допущения для некоторых простых случаев, заметим, что в сложных случаях оно, как правило, не выполняется [20, гл. 2]. Например, специалистам хорошо известно, что при описании социально-экономических процессов в зависимости от поставленных целей возможны самые различные системы классификации. По-видимому, этот вывод можно распространить на все сложные системы и на все неполные и неточные описания, т.е. за исключением специальных случаев, практически на все, что мы используем для описания и представления информации на понятийном уровне. В таких случаях задача распознавания дополняется этапом выбора классификационной системы. Истины ради следует заметить, что даже у такой совершенной распознающей системы, как человек, процесс классификации сложной информации осуществляется не в процессе распознавания, а в процессе анализа информации, т.е. мышления. Здесь мы еще раз убеждаемся, что грань между распознаванием и мышлением очень тонкая и мы не можем рассматривать распознавание без мышления. Более того, сам процесс мышления, оказывается, также может быть встроен в процесс распознавания. Таким образом, отметим в заключение данного раздела, что приведенные в начале раздела допущения классической схемы распознавания либо применимы только для наиболее простых частных случаев (использование единственной классификации), либо работают с точностью до наоборот (схема распознавания снизу вверх), либо приводят к подмене задачи распознавания (введение понятия «признак» без процедур его получения).
Чтобы более наглядно оценить важность априорной информации, представим, что мы пытаемся распознать образ без всяких предварительных сведений о нем. Нетрудно заметить, что задача в такой постановке эквивалентна задаче установления контактов (понимания) с инопланетной цивилизацией на основании радиосигналов. Несколько десятилетий назад такая идея (о возможности понимания или распознавания) горячо обсуждалась в обществе, но однозначный ответ так и не был получен. Это и не удивительно, учитывая низкий уровень и кризис научного направления, связанного с распознаванием. Но даже и в обозримом будущем, при условии устранения всех перечисленных выше проблем, трудно предположить, что задача распознавания сообщения инопланетной цивилизации по радиосигналу (но не в процессе диало га) осуществима в полном объеме без учета какой-либо дополнительной информации. На самом деле, априорная информация, конечно же, используется в процессе распознавания (иначе наука о распознавании не существовала бы ни в каком виде). В частности, предварительный выбор признаков может быть осуществлен только с использованием этой дополнительной, обычно плохо формализованной информации о предметной области, и, следовательно, выбранные заранее признаки содержат в себе априорную информацию об образе [1, c. 23]. Да и в схемах распознавания, используемом инструментарии, форме получаемых результатов и т.п. содержится некоторая априорная информация.
Второй метод использования априорной информации – это обучение на примерах. Для решения ряда задач обучения часто бывает достаточно. Проблема, однако, заключается в том, что нет общей теории (метода, способа) построения оптимальных признаков на основе априорной инфо рмации. Да и как уже указывалось ранее, реальный процесс распознавания у живых существ имеет многоуровневыйхарактер, а теории распознавания в этом случае вообще не существует. В ряде случаев дополнительная инфо рмация о распознаваемом образе вообще может быть представлена отрыво чно, неполно и неточно. Для всех этих случаев нет теории (процедур, механизмов), позволяющих достаточно простым образом получить максимальный эффект от разбросанной и представленной в различной форме дополнительной информации о распознаваемом образе. Каким образом это сделать? Немедленных и простых рецептов здесь, по- видимому, не существует. Необходимо развитие теории информации, необходимо более глубокое понимание роли и механизмов проявления контекста, внешних критериев и т.п. понятий [10], [21].
Одной из ключевых проблем распознавания образов является необходимость проведения большого объема вычислений, которые далеко не всегда удается реализовать и на супермощных компьютерах. Например, в статистических методах распознавания число решающих правил, которые необходимо оценить в процессе распознавания даже для наиболее простых линейных бинарных правил составляет величину порядка 2 m , где m – размерность пространства [1, c. 91], равная числу признаков. Учитывая, что число признаков во многих задачах превышает десятки и сотни, мы получаем задачи, которые рассчитать традиционными методами невозможно (проклятие размерности). Существует несколько направлений, в рамках которых пытаются решить вычислительные проблемы. Условно их можно разделить на три класса:
Развиваемые как в рамках традиционной идеологии, так и в нейросетях методы явно или неявно используют доказанную А.Н. Колмогоровым теорему существования о представимости функции многих переменных суперпозицией конечного числа функций одной переменной (при выполнении ряда ограни- чений) [22]. С точки зрения задачи распознавания эта теорема важна тем, что показывает теоретическую возможность резкого снижения размерности пространства, в результате чего объем вычислений растет с увеличением количества признаков не экспоненциально, а полиномиальным образом. Одним из широко известных методов, существенно использующим принципы, заложенные в теореме Колмогорова, является, на наш взгляд, метод группового учета аргументов (МГУА), предложенный А.Г. Ивахненко ([23],[24], а также другие работы на сайте www.inf.kiev.ua/GMDH-home). Вообще говоря, этот метод не сводится только к указанной теореме, и его вторая существенная положительная черта – наличие механизмов построения модели оптимальной сложности с учетом короткой выборки или зашумленных исходных данных. Сейчас этот метод бурно развивается целой группой исследователей из различных стран, создан коммерческий продукт на его основе (KnowledgeMiner), немаловажно также, что он может быть реализован как с использованием традиционных последовательных алгоритмов, так и с помощью нейросетей. Таким образом, он имеет все предпосылки стать одним из ведущих при использовании систем распознавания и вообще систем получения новых знаний. В то же время необходимо отметить и недостаточный анализ теоретических предпосылок, лежащих в его основе, что затрудняет его развитие и затемняет трактовку полученных результатов. Представляется очень интересным также предложенный В.И. Васильевым метод редукции или метод предельных упрощений [2, гл. 8], [25], [26], основан- ный на предельно возможном снижении размерности признакового пространства, в результате чего резко снижаются требования как к объему выборки, так и к количеству вычислений.
В статистике эта идеология (снижение размерности пространства) хорошо известна, детально разработана и широко используется [27, гл. 12-17]. Известна и ограниченность этой идеологии, связанная с тем, что мы не можем выбросить важные признаки. В предельном случае одинаковой важности всех признаков мы вообще не можем сократить размерность пространства признаков. Поэтому представляется, что основная область применимости теории редукции – не собственно процесс распознавания в классической схеме, а стадия выбора признаков – процесс конструирования признакового пространства. А поскольку этот процесс должен основываться на мышлении, то теория редукции тесно примыкает к мышлению, языку, способам представления информации и т.д. и, очевидно, не может развиваться в отрыве от этих понятий. Классическая математика основана на использовании принципа последовательных вычислений. При этом неявно используется доп ущение о том, что мы можем процесс преобразования информации о любой предметной области представить в виде последовательной цепочки вычислений (назовем его принципом локальности). Но это не единственно возможный в настоящее время принцип обработки информации. Принцип параллельной обработки, используемый, в частности, в нейросетях, также хорошо известен и широко используется, он позволяет ускорить процессы обработки информации в nраз, где n – число параллельных каналов. Но есть еще один принцип – принцип совместной обработки информации, когда производится взаимосогласованная обработка информации в ряде алгоритмов или элементов вычислительного устройства (нелокальная обработка информации). Этот принцип реализован, в частности, в квантовых компьютерах [28], [29] – новом, перспективном и быстро развивающемся направлении. Возможно также, что по этому же принципу хотя бы в некотором отношении работает и наш мозг. Понятие «нейросети» объединяет в себе сотни различных методов с различной идеологией и аппаратной реализацией, в связи с чем обзор этих методов с единых позиций, как уже указывалось в предисловии, крайне затруднен. По этой причине мы лишь отметим, что наиболее перспективн ыми с точки зрения распознавания образов считаются сети Кохонена , ко нцепция когнитрона или неокогнитрона [30], [31] и теория инвариантов (см. подборку материалов на сайте www.kyb.tuebingen.mpg.de). Нельзя также не отметить попытки преодоления колмогоровского барьера сложности с помощью нейросетей [32] (там же и обзор литературы по этому вопросу). Если эта попытка удастся в полном объеме, то эффект от этого (по крайней мере, в распознавании образов) будет сравним с использованием квантовых компьютеров. Работа квантового компьютера основана на регулируемом изменении избранных состояний в квантовой системе, состоящей из n квантовых частиц – кубитов. Такая квантовая система имеет ряд замечательных особенностей. Во-первых, квантовые состояния кубитов взаимно влияют друг на друга, приводя к появлению 2^n базовых состояний. Во-вторых, если мы переводим один из кубитов в другое состояние, то все остальные состо яния очень быстро (со скоростью интерференционных процессов) переходят в новое состояние, с учетом изменения состояния исходного кубита. Такой процесс с помощью некоторых дополнительных алгоритмов можно представить как процесс вычисления. И, в-третьих, что немаловажно, мы можем снимать информацию о новом состоянии, т.е. получать результаты расчетов [29]. Если рассматривать этот процесс в рамках традиционных понятий, то это не просто параллельные вычисления (в параллельных вычислениях отдельные процессы независимы друг от друга по крайней мере на протяжении некоторых циклов), а взаимосогласованная обработка информации, когда каждый кубит все время «чувствует» состояния других кубитов, и все время согласованно с ними изменяет свое собственное. В результате этого скорость расчетов растет экспоненциально с увеличением числа элементов в квантовом компьютере. В настоящее время на практике реализованы лишь отдельные элементы квантовых компьютеров, но специалисты не сомневаются в его принципиальной реализации, разногласия в основном касаются сроков реализации – 5 или 10 лет. Ожидаемый прирост производительности квантовых компьютеров по некоторым оценкам достигает 10-тии более порядков раз, что, несомненно, позволит решать многие в настоящее время неосуществимые задачи распознавания. В связи с квантовыми компьютерами нельзя также не упомянуть и о возможностях человеческого мозга. Как известно, человек в состоянии держать в своем сознании 7+/-2 объектов. При этом, если мы оперируем одним из объектов, то и в других происходят более или менее согласованные изменения (связи, трактовка признаков, общее значение данного объекта для ситуации в целом и т.д.), – все это очень напоминает работу квантового компьютера. Вследствие этого можно высказать предположение, что мозг, по крайней мере в отношении некоторых процессов обработки информации, проводит взаимосогласованную одновременную обработку информации. И эта нелокальная обработка реализуется не с использованием квантовых компьютеров, а путем использования сложной структуры межнейронных связей и передачи импульсов между нейронами. Возможно, именно использование этого принципа объясняет колоссальные возможности человеческого
продолжение следует...
Часть 1 Проблема и ошибки распознавания вложенных, прозрачных, зеркальных и других объектов
Часть 2 6. Недостаточный учет многоуровневости процесса обработки информации - Проблема и
Часть 3 - Проблема и ошибки распознавания вложенных, прозрачных, зеркальных и других
Данная статья про проблемы распознавания подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое проблемы распознавания, проблемы распознавания образов, ошибки распознавания и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов

Комментарии