Лекция
Привет, Вы узнаете о том , что такое метод ближайших соседей для статического распознавания образов, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое метод ближайших соседей для статического распознавания образов , настоятельно рекомендую прочитать все из категории Распознавание образов.
Метод ближайших соседей — это простейший метрический классификатор, основанный на оценивании сходства объектов. Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты обучающей выборки. Анализ ближайшего сходства представляет собой метод классификации наблюдений на основе сходства наблюдений. Этот метод машинного обучения был разработан в качестве способа распознавания структуры данных при неточном соответствии имеющих структур или наблюдений. Подобные наблюдения близки друг к другу, а непохожие наблюдения, наоборот, удалены друг от друга. Таким образом, дистанция между двумя наблюдениями является критерием их различия. Близкие друг к другу наблюдения называются “соседи”. Когда представляется новое наблюдение, обозначенное знаком вопроса, вычисляется его расстояние от всех других наблюдений в модели. Определяется классификация наиболее похожих наблюдений (ближайшее сходство) и новое наблюдение помещается в категорию, в которой содержится наибольшее количество ближайшего сходства.Пользователь может указать количество анализируемых ближайших соседей; это значение обозначается k. Анализ ближайшего сходства также может использоваться для вычисления значений для непрерывного целевого объекта. В этой ситуации среднее целевое значение ближайшего сходства используется для получения предсказанного значения для нового наблюдения.
При статичекском распознаваниии образов идея состоит в том, что вокруг распознаваемого объекта 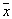 строится ячейка объема
строится ячейка объема 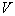 . При этом неизвестный объект относится к тому образу, число обучающих представителей которого в построенной ячейке оказалось большинство. Если использовать статистическую терминологию, то число объектов образа
. При этом неизвестный объект относится к тому образу, число обучающих представителей которого в построенной ячейке оказалось большинство. Если использовать статистическую терминологию, то число объектов образа 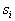 , попавших в данную ячейку, характеризует оценку усредненной по объему
, попавших в данную ячейку, характеризует оценку усредненной по объему 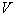 плотности вероятности
плотности вероятности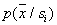 .
.
Для оценки усредненных 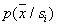 нужно решить вопрос о соотношении между объемом
нужно решить вопрос о соотношении между объемом 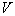 ячейки и количеством попавших в эту ячейку объектов того или иного класса (образа). Вполне разумно считать, что чем меньше
ячейки и количеством попавших в эту ячейку объектов того или иного класса (образа). Вполне разумно считать, что чем меньше 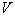 , тем более тонко будет охарактеризована
, тем более тонко будет охарактеризована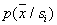 . Но при этом тем меньше объектов попадет в интересующую нас ячейку, а следовательно, тем меньше достоверность оценки
. Но при этом тем меньше объектов попадет в интересующую нас ячейку, а следовательно, тем меньше достоверность оценки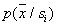 . При чрезмерном увеличении
. При чрезмерном увеличении  возрастает достоверность оценки
возрастает достоверность оценки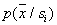 , но теряются тонкости ее описания из-за усреднения по слишком большому объему, что может привести к негативным последствиям (увеличению вероятности ошибок распознавания). Об этом говорит сайт https://intellect.icu . При небольшом объеме обучающей выборки
, но теряются тонкости ее описания из-за усреднения по слишком большому объему, что может привести к негативным последствиям (увеличению вероятности ошибок распознавания). Об этом говорит сайт https://intellect.icu . При небольшом объеме обучающей выборки 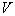 целесообразно брать предельно большим, но обеспечить при этом, чтобы внутри ячейки плотности
целесообразно брать предельно большим, но обеспечить при этом, чтобы внутри ячейки плотности 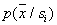 мало изменялись. Тогда их усреднение по большому объему не очень опасно. Таким образом, вполне может случиться, что объем ячейки, уместный для одного значения
мало изменялись. Тогда их усреднение по большому объему не очень опасно. Таким образом, вполне может случиться, что объем ячейки, уместный для одного значения 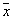 , может совершенно не годиться для других случаев.
, может совершенно не годиться для других случаев.
Предлагается следующий порядок действий (пока что принадлежность объекта тому или иному образу учитывать не будем).
Для того чтобы оценить 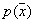 на основании обучающей выборки, содержащей
на основании обучающей выборки, содержащей 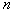 объектов, центрируем ячейку вокруг
объектов, центрируем ячейку вокруг  и увеличиваем ее объем до тех пор, пока она не вместит
и увеличиваем ее объем до тех пор, пока она не вместит 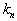 объектов, где
объектов, где 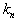 есть некоторая функция от
есть некоторая функция от 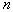 . Эти
. Эти 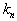 объектов будут ближайшими соседями
объектов будут ближайшими соседями 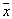 . Вероятность
. Вероятность 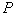 попадания вектора
попадания вектора 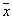 в область
в область 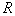 определяется выражением
определяется выражением 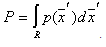 .
.
Это сглаженный (усредненный) вариант плотности распределения 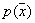 . Если взять выборку из
. Если взять выборку из 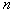 объектов (простым случайным выбором из генеральной совокупности), то
объектов (простым случайным выбором из генеральной совокупности), то 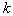 из них окажется внутри области
из них окажется внутри области 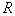 . Вероятность попадания
. Вероятность попадания 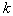 из
из 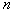 объектов в
объектов в 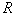 описывается биномиальным законом, имеющим резко выраженный максимум около среднего значения
описывается биномиальным законом, имеющим резко выраженный максимум около среднего значения 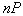 . При этом
. При этом 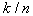 является неплохой оценкой для
является неплохой оценкой для 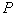 .
.
Если теперь допустить, что 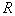 настолько мала, что
настолько мала, что 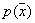 внутри нее меняется незначительно, то
внутри нее меняется незначительно, то
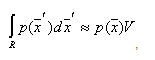 ,
,
где 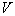 – объем области
– объем области 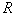 ,
, 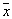 – точка внутри
– точка внутри 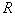 .
.
Тогда 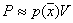 . Но
. Но 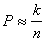 , следовательно,
, следовательно, 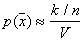 .
.
Итак, оценкой 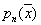 плотности
плотности 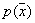 является величина
является величина
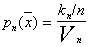 . (*)
. (*)
Без доказательства приведем утверждение, что условия
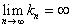 и
и 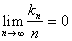 (**)
(**)
являются необходимыми и достаточными для сходимости 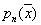 к
к 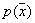 по вероятности во всех точках, где плотность
по вероятности во всех точках, где плотность 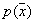 непрерывна.
непрерывна.
Этому условию удовлетворяет, например, 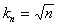 .
.
Теперь будем учитывать принадлежность объектов к тому или иному образу и попытаемся оценить апостериорные вероятности образов 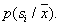
Предположим, что мы размещаем ячейку объема 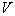 вокруг
вокруг 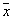 и захватываем выборку с количеством объектов
и захватываем выборку с количеством объектов 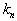 ,
, 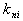 из которых принадлежат образу
из которых принадлежат образу  . Тогда в соответствии с формулой
. Тогда в соответствии с формулой  оценкой совместной вероятности
оценкой совместной вероятности 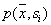 будет величина
будет величина
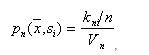 ,
,
а
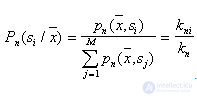 .
.
Таким образом, апостериорная вероятность 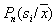 оценивается как доля выборки в ячейке, относящаяся к
оценивается как доля выборки в ячейке, относящаяся к 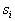 . Чтобы свести уровень ошибки к минимуму, нужно объект с координатами
. Чтобы свести уровень ошибки к минимуму, нужно объект с координатами 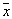 отнести к классу (образу), количество объектов обучающей выборки которого в ячейке максимально. При
отнести к классу (образу), количество объектов обучающей выборки которого в ячейке максимально. При 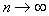 такое правило является байесовским, то есть обеспечивает теоретический минимум вероятности ошибок распознавания (разумеется, при этом должны выполняться условия
такое правило является байесовским, то есть обеспечивает теоретический минимум вероятности ошибок распознавания (разумеется, при этом должны выполняться условия  ).
).
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области метод ближайших соседей для статического распознавания образов имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое метод ближайших соседей для статического распознавания образов и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
Из статьи мы узнали кратко, но содержательно про метод ближайших соседей для статического распознавания образов
Комментарии