Лекция
Привет, Вы узнаете о том , что такое критерии информативности признаков отбор информативных признаков, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое критерии информативности признаков отбор информативных признаков , настоятельно рекомендую прочитать все из категории Распознавание образов.
Критерии информативности признаков
|
|
При решении задач распознавания основным критерием (в том числе и для оценки информативности признаков) является риск потерь. О нем подробнее мы будем говорить во втором разделе курса лекций. Здесь отметим лишь, что он основан на оценке вероятностей ошибок распознавания и их стоимости. Говорить об оценке вероятностей можно лишь в рамках статистического подхода, поэтому в данном разделе лучше применять критерий типа: доля контрольной (экзаменационной) выборки, распознанная неправильно. Мы уже упоминали о том, что объекты обучающей выборки не должны входить в контрольную выборку. В тех случаях, когда общая выборка невелика по объему, деление ее на две части весьма нежелательный шаг (ухудшится и качество обучения, и доверие к результатам контроля). Некоторые исследователи для компенсации этого недостатка применяют метод так называемого скользящего контроля. Он состоит в следующем. Все объекты, кроме одного, предъявляются в качестве обучающей выборки. Один объект, не участвовавший в обучении, предъявляется на контроль. Затем из общей выборки отбирается другой объект для контроля, по оставшейся части выборки осуществляется обучение. Такая процедура повторяется столько раз, сколько объектов в общей выборке. В таком случае вся выборка участвует и в обучении, и в контроле, но контрольные объекты не участвуют в обучении. Этот положительный эффект достигается ценой того, что обучение производится не один раз, как это было бы при наличии двух разных выборок (обучающей и контрольной) достаточно большого объема, а столько раз, сколько объектов в общей выборке. Такой недостаток существенен, поскольку процедура обучения обычно достаточно сложна и ее многократное повторение нежелательно. Если же данная процедура используется для отбора информативных признаков, то количество "обучений" нужно еще умножить на количество сравниваемых между собой наборов признаков. Поэтому для оценки информативности признаков и решения иных задач часто используется не относительное число ошибок распознавания, а другие критерии, с ним связанные. В любом случае эти критерии выражают степень различимости объектов разных образов. Например, как это уже отмечалось при рассмотрении алгоритмов таксономии, отношение среднего расстояния между объектами разных образов к среднему расстоянию между объектами одного образа в ряде случаев оказывается весьма эффективным. Предлагается самостоятельно записать соответствующие вычислительные формулы, введя необходимые обозначения. При использовании подобных критериев контрольная выборка не нужна, но теряется взаимнооднозначная связь с количеством ошибок распознавания. Ясно, что среднее расстояние между объектами разных классов получается усреднением расстояний между всеми возможными парами объектов, принадлежащих разным классам. Если число классов велико и каждый из них представлен значительным количеством объектов, то процедура усреднения оказывается громоздкой. В этом случае можно воспользоваться усреднением расстояний между эталонами разных классов, а внутри классов – усреднением расстояний от объектов до эталона данного класса. Вполне понятно, что такое упрощение не всегда допустимо. Все зависит от формы и взаимного расположения областей признакового пространства, в которых сосредоточены объекты разных классов. |
Отбор информативных признаков
|
|
Будем считать, что набор исходных признаков задан. Фактически его определяет учитель. Важно, чтобы в него вошли те признаки, которые действительно несут различительную информацию. Выполнение этого условия в решающей степени зависит от опыта и интуиции учителя, хорошего знания им той предметной области, для которой создается система распознавания. Если исходное признаковое пространство задано, то отбор меньшего числа наиболее информативных признаков (формирование признакового пространства меньшей размерности) поддается формализации. Пусть На рис. 16 представлено линейное преобразование координат
После преобразования признак На рис. 17 проиллюстрирован переход от декартовой системы координат к полярной, что привело к целесообразности отбрасывания признака Такого рода преобразования приводят к упрощению решающих правил, т.к. их приходится строить в пространстве меньшей размерности. Однако при этом возникает необходимость в реализации преобразования
Рис. 16. Об этом говорит сайт https://intellect.icu . Линейное преобразование координат Особо выделим следующий тип линейного преобразования:
где Это означает, что из исходной системы признаков часть отбрасывается. Разумеется, остающиеся признаки должны образовывать наиболее информативную подсистему. Таким образом, нужно разумно организовать процедуру отбора по одному из ранее рассмотренных критериев информативности. Рассмотрим некоторые подходы. Оптимальное решение задачи дает полный перебор. Если исходная система содержит
Рис. 17. Переход к полярной системе координат Рассмотрим некоторые из применяемых процедур. 1. Оценивается информативность каждого из исходных признаков, взятого в отдельности. Затем признаки ранжируются по убыванию информативности. После этого отбираются 2. Предполагается, что признаки статистически зависимы. Сначала отбирается самый индивидуально информативный признак (просматривается 3. Последовательное отбрасывание признаков. Этот подход похож на предыдущий. Из совокупности, содержащей 4. Случайный поиск. Случайным образом отбираются номера 5. Случайный поиск с адаптацией. Это последовательная направленная процедура, основанная на случайном поиске с учетом результатов предыдущих отборов. В начале процедуры шансы всех исходных признаков на вхождение в подсистему, состоящую из |
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области критерии информативности признаков отбор информативных признаков имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое критерии информативности признаков отбор информативных признаков и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
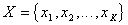 – исходное признаковое пространство,
– исходное признаковое пространство, 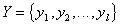 – преобразованное признаковое пространство,
– преобразованное признаковое пространство, 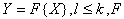 – некоторая функция.
– некоторая функция. .
.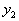 не несет различительной информации и его использование для распознавания не имеет смысла.
не несет различительной информации и его использование для распознавания не имеет смысла.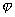 .
.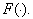 Поэтому суммарного упрощения может и не получиться, особенно при цифровой реализации преобразования признакового пространства. Хорошо, если датчики, измеряющие значения исходных признаков, по своей физической природе таковы, что попутно осуществляют требуемое преобразование.
Поэтому суммарного упрощения может и не получиться, особенно при цифровой реализации преобразования признакового пространства. Хорошо, если датчики, измеряющие значения исходных признаков, по своей физической природе таковы, что попутно осуществляют требуемое преобразование.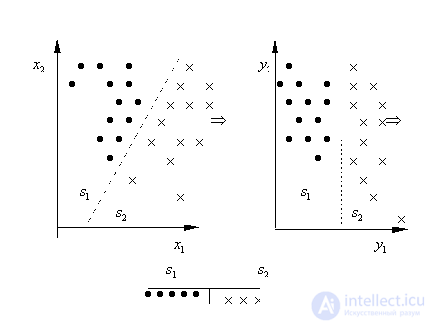
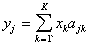 ,
,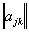 – диагональная матрица, причем ее элементы равны либо 0, либо 1.
– диагональная матрица, причем ее элементы равны либо 0, либо 1.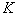 признаков, а нам нужно выбрать наилучшую подсистему, содержащую
признаков, а нам нужно выбрать наилучшую подсистему, содержащую 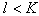 признаков, то придется рассмотреть
признаков, то придется рассмотреть  (число сочетаний из
(число сочетаний из 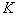 элементов по
элементов по 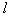 ) возможных в данном случае подсистем. Причем рассмотрение каждой подсистемы состоит в оценке значения критерия информативности, что само по себе является трудоемкой задачей, особенно если в качестве критерия использовать относительное число ошибок распознавания. Для иллюстрации укажем, что для отбора из 20 исходных признаков пяти наиболее информативных приходится иметь дело примерно с 15,5×103 вариантами. Если же количество исходных признаков – сотни, то полный перебор становится неприемлемым. Переходят к разумным процедурам направленного отбора, которые в общем случае не гарантируют оптимального решения, но хотя бы обеспечивают не худший выбор.
) возможных в данном случае подсистем. Причем рассмотрение каждой подсистемы состоит в оценке значения критерия информативности, что само по себе является трудоемкой задачей, особенно если в качестве критерия использовать относительное число ошибок распознавания. Для иллюстрации укажем, что для отбора из 20 исходных признаков пяти наиболее информативных приходится иметь дело примерно с 15,5×103 вариантами. Если же количество исходных признаков – сотни, то полный перебор становится неприемлемым. Переходят к разумным процедурам направленного отбора, которые в общем случае не гарантируют оптимального решения, но хотя бы обеспечивают не худший выбор.
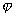
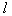 первых признаков. Здесь число рассматриваемых вариантов
первых признаков. Здесь число рассматриваемых вариантов 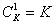 . При таком подходе оптимальность выбора гарантирована только в том случае, если все исходные признаки статистически не зависят друг от друга. В противном случае (а они чаще всего и встречаются на практике) решение может оказаться далеко не оптимальным.
. При таком подходе оптимальность выбора гарантирована только в том случае, если все исходные признаки статистически не зависят друг от друга. В противном случае (а они чаще всего и встречаются на практике) решение может оказаться далеко не оптимальным.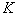 вариантов). Затем к первому отобранному признаку присоединяется еще один из оставшихся, составляющий с первым самую информативную пару (просматривается
вариантов). Затем к первому отобранному признаку присоединяется еще один из оставшихся, составляющий с первым самую информативную пару (просматривается  вариантов). После этого к отобранной паре присоединяется еще один из оставшихся признаков, составляющий с ранее отобранной парой наиболее информативную тройку (просматривается
вариантов). После этого к отобранной паре присоединяется еще один из оставшихся признаков, составляющий с ранее отобранной парой наиболее информативную тройку (просматривается  вариантов) и т.д. до получения совокупности из
вариантов) и т.д. до получения совокупности из 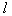 признаков. Здесь число просматриваемых вариантов составляет величину
признаков. Здесь число просматриваемых вариантов составляет величину  . Для иллюстрации отметим, что для отбора 5 признаков из 20 при данном подходе требуется просмотреть 90 вариантов, что примерно в 170 раз меньше, чем при полном переборе.
. Для иллюстрации отметим, что для отбора 5 признаков из 20 при данном подходе требуется просмотреть 90 вариантов, что примерно в 170 раз меньше, чем при полном переборе.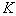 признаков, отбрасывается тот, который дает минимальное уменьшение информативности. Затем из оставшейся совокупности, содержащей
признаков, отбрасывается тот, который дает минимальное уменьшение информативности. Затем из оставшейся совокупности, содержащей 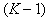 признаков, отбрасывается еще один, минимально уменьшающий информативность, и т.д., пока не останется
признаков, отбрасывается еще один, минимально уменьшающий информативность, и т.д., пока не останется  признаков. Из этих двух подходов (последовательное присоединение признаков и последовательное отбрасывание признаков) целесообразно использовать первый при
признаков. Из этих двух подходов (последовательное присоединение признаков и последовательное отбрасывание признаков) целесообразно использовать первый при 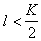 и второй при
и второй при 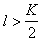 , если ориентироваться на число просматриваемых вариантов. Что касается результатов отбора, то он в общем случае может оказаться различным.
, если ориентироваться на число просматриваемых вариантов. Что касается результатов отбора, то он в общем случае может оказаться различным. признаков и оценивается информативность этой подсистемы. Затем снова и независимо от предыдущего набора случайно формируется другая система из
признаков и оценивается информативность этой подсистемы. Затем снова и независимо от предыдущего набора случайно формируется другая система из 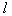 признаков. Так повторяется
признаков. Так повторяется 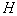 раз. Из
раз. Из  наборов признаков отбирается тот, который имеет наибольшую информативность. Чем
наборов признаков отбирается тот, который имеет наибольшую информативность. Чем 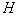 больше, тем выше вероятность выбора наилучшей подсистемы. При
больше, тем выше вероятность выбора наилучшей подсистемы. При 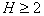 можно, по крайней мере, утверждать, что наш выбор не оказался наихудшим (если, конечно, выбранные подсистемы не оказались одинаковыми по информативности).
можно, по крайней мере, утверждать, что наш выбор не оказался наихудшим (если, конечно, выбранные подсистемы не оказались одинаковыми по информативности).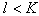 признаков, принимаются равными. Для случайного отбора используется датчик равномерно распределенных в интервале
признаков, принимаются равными. Для случайного отбора используется датчик равномерно распределенных в интервале 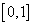 случайных (псевдослучайных) чисел. Этот интервал разбивается на
случайных (псевдослучайных) чисел. Этот интервал разбивается на 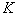 равных отрезков. Первый отрезок ставится в соответствие признаку
равных отрезков. Первый отрезок ставится в соответствие признаку 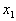 , второй –
, второй – 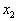 и т.д. Длина каждого отрезка равна вероятности
и т.д. Длина каждого отрезка равна вероятности 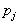 включения
включения 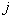 -го признака в информативную подсистему. Как уже отмечалось, сначала эти вероятности для всех признаков одинаковы. Датчиком случайных чисел выбирается
-го признака в информативную подсистему. Как уже отмечалось, сначала эти вероятности для всех признаков одинаковы. Датчиком случайных чисел выбирается 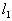 различных отрезков. Для тех
различных отрезков. Для тех  признаков из
признаков из 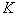 , которые соответствуют этим отрезкам, определяется значение критерия информативности
, которые соответствуют этим отрезкам, определяется значение критерия информативности  . После получения первой группы из
. После получения первой группы из 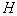 случайно выбранных подсистем определяется
случайно выбранных подсистем определяется 
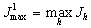 и
и 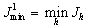 . Адаптация состоит в изменении вектора вероятностей
. Адаптация состоит в изменении вектора вероятностей  выбора признаков на последующих этапах поиска в зависимости от результатов предыдущих этапов: длина отрезка в интервале
выбора признаков на последующих этапах поиска в зависимости от результатов предыдущих этапов: длина отрезка в интервале 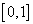 , соответствующая признаку, попавшему в самую плохую подсистему, уменьшается (признак "наказывается"), а попавшему в самую хорошую подсистему – увеличивается (признак "поощряется"). Длины отрезков изменяются на величину
, соответствующая признаку, попавшему в самую плохую подсистему, уменьшается (признак "наказывается"), а попавшему в самую хорошую подсистему – увеличивается (признак "поощряется"). Длины отрезков изменяются на величину 
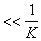 . После перебора ряда групп вероятность выбора признаков, часто встречающихся в удачных сочетаниях, становится существенно больше других, и датчик случайных чисел начинает выбирать одно и то же сочетание из
. После перебора ряда групп вероятность выбора признаков, часто встречающихся в удачных сочетаниях, становится существенно больше других, и датчик случайных чисел начинает выбирать одно и то же сочетание из 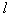 признаков. Чем больше
признаков. Чем больше 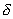 , тем быстрее сходимость процедуры, но тем ниже вероятность "выхода" на наилучшую подсистему. И наоборот, чем меньше
, тем быстрее сходимость процедуры, но тем ниже вероятность "выхода" на наилучшую подсистему. И наоборот, чем меньше 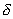 , тем медленнее сходимость, но выше вероятность выбора наилучшей подсистемы. Конкретный выбор значения
, тем медленнее сходимость, но выше вероятность выбора наилучшей подсистемы. Конкретный выбор значения 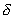 должен быть таким, чтобы процедура сходилась при общем числе выборов
должен быть таким, чтобы процедура сходилась при общем числе выборов 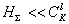 , а вероятность нахождения наилучшей подсистемы или близкой к ней по информативности была бы близка к единице.
, а вероятность нахождения наилучшей подсистемы или близкой к ней по информативности была бы близка к единице.
Комментарии
Оставить комментарий
Распознавание образов
Термины: Распознавание образов