Лекция
Привет, Вы узнаете о том , что такое решения задач таксономии статистическими методами, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое решения задач таксономии статистическими методами , настоятельно рекомендую прочитать все из категории Распознавание образов.
|
Статистических методов решения задач таксономии существует достаточно много. Мы из-за ограниченности времени, выделенного на курс распознавания образов (классификации), остановимся только на одном, не умаляя значения или эффективности других методов. Он непосредственно связан с аппроксимационным методом распознавания. Действительно, восстановление неизвестного распределения по выборке в виде смеси базовых распределений является, по существу, решением задачи таксономии с определенными требованиями (ограничениями), предъявляемыми к описанию каждого из таксонов.
Рис. 25. Объединение компонент смеси в таксоны Эти требования состоят в том, что значения признаков объектов, входящих в один таксон, имеют распределения вероятностей заданного вида. В рассматриваемом нами случае это нормальные или биномиальные распределения. В ряде случаев это ограничение можно обойти. В частности, если задано число таксонов Естественно, объединять в один таксон следует те компоненты смеси, которые наименее разнесены в признаковом пространстве. Мерой разнесенности компонент может служить, например, мера Кульбака
Следует отметить, что эта мера применима лишь в том случае, если подмножество значений Если говорить о связи изложенного статистического подхода к таксономии с ранее рассмотренными детерминистскими методами, то можно заметить следующее. Алгоритм ФОРЭЛЬ близок по своей сути к аппроксимации распределения смесью нормальных плотностей вероятностей значений признаков, причем матрицы ковариаций компонент смеси диагональны, элементы этих матриц равны между собой, распределения компонент отличаются друг от друга только векторами средних значений. Однако на одинаковый результат таксономии даже в этом случае можно рассчитывать лишь при большой разнесенности компонент смеси. Объединение нескольких смесей в один таксон по методике близко к эмпирическому алгоритму KRAB 2. Эти два подхода взаимно дополняют друг друга. Когда выборка мала и статистические методы неприменимы или малоэффективны, целесообразно использовать алгоритм KRAB, FOREL, KRAB 2. При большом объеме выборки эффективнее становятся статистические методы, в том числе объединение компонент смеси в таксоны. |
| Оценка информативности признаков |
|
Оценка информативности признаков необходима для их отбора при решении задач распознавания. Сама процедура отбора практически не зависит от способа измерения информативности. Важно лишь, чтобы этот способ был одинаков для всех признаков (групп признаков), входящих в исходное их множество и участвующих в процедуре отбора. Поскольку процедуры отбора были рассмотрены в разделе, посвященном детерминистским методам распознавания, здесь мы на них останавливаться не будем, а обсудим только статистические методы оценки информативности. При решении задач распознавания решающим критерием является риск потерь и как частный случай – вероятность ошибок распознавания. Об этом говорит сайт https://intellect.icu . Для использования этого критерия необходимо для каждого признака (группы признаков) провести обучение и контроль, что является достаточно громоздким процессом, особенно при больших объемах выборок. Именно это и характерно для статистических методов. Хорошо, если обучение состоит в построении распределений значений признаков для каждого образа Если имеются обучающая и контрольная выборки, то первая из них используется для построения Можно пойти другим путем, а именно: всю выборку использовать для обучения (построения В связи с этим представляют интерес другие меры информативности признаков, вычисляемые с меньшими затратами вычислительных ресурсов, чем оценка вероятности ошибок распознавания. Такие меры могут быть не связаны взаимооднозначно с вероятностями ошибок, но для выбора наиболее информативной подсистемы признаков это не столь существенно, так как в данном случае важно не абсолютное значение риска потерь, а сравнительная ценность различных признаков (групп признаков). Смысл критериев классификационной информативности, как и при детерминистском подходе, состоит в количественной мере "разнесенности" распределений значений признаков различных образов. В частности, в математической статистике используются оценки верхней ошибки классификации Чернова (для двух классов), связанные с ней расстояния Бхатачария, Махаланобиса. Для иллюстрации приведем выражение расстояния Махаланобиса для двух нормальных распределений, отличающихся только векторами средних
где
-1 – обращение матрицы. В одномерном случае Несколько подробнее рассмотрим информационную меру Кульбака применительно к непрерывной шкале значений признаков. Определим следующим образом среднюю информацию в пространстве
При этом предполагается, что нет областей, где Аналогично Назовем расхождением величину
Чем расхождение больше, тем выше классификационная информативность признаков. Очевидно, что при Легко убедиться, что если признаки (признаковые пространства) В качестве примера вычислим расхождение двух нормальных одномерных распределений с одинаковыми дисперсиями и различными средними:
Оказывается, что в этом конкретном случае расхождение равно расстоянию Махаланобиса Промежуточные выкладки предлагается сделать самостоятельно. |
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области решения задач таксономии статистическими методами имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое решения задач таксономии статистическими методами и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
Из статьи мы узнали кратко, но содержательно про решения задач таксономии статистическими методами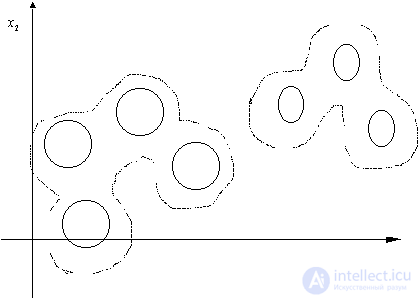
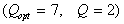
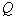 , а
, а  , то некоторые таксоны следует объединить в один, который будет иметь уже отличающееся от нормального или биномиального распределение значений признаков (рис. 25).
, то некоторые таксоны следует объединить в один, который будет иметь уже отличающееся от нормального или биномиального распределение значений признаков (рис. 25).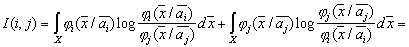

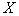 , на котором
, на котором 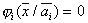 , а
, а 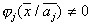 и наоборот, пусто. В частности, это требование выполняется для нормально распределенных значений признаков компонент смеси.
и наоборот, пусто. В частности, это требование выполняется для нормально распределенных значений признаков компонент смеси. . Тогда, если нам удалось построить
. Тогда, если нам удалось построить 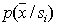 в исходном признаковом пространстве, распределение по какому-либо признаку (группе признаков) получается как проекция
в исходном признаковом пространстве, распределение по какому-либо признаку (группе признаков) получается как проекция  на соответствующую ось (в соответствующее подпространство) исходного признакового пространства (маргинальные распределения). В этом случае повторных обучений проводить не нужно, следует лишь оценить вероятность ошибок распознавания. Это можно осуществить различными способами. Рассмотрим некоторые из них.
на соответствующую ось (в соответствующее подпространство) исходного признакового пространства (маргинальные распределения). В этом случае повторных обучений проводить не нужно, следует лишь оценить вероятность ошибок распознавания. Это можно осуществить различными способами. Рассмотрим некоторые из них.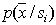 , а вторая – для оценки вероятности ошибок распознавания. Недостатками этого подхода являются громоздкость расчетов, поскольку приходится большое число раз осуществлять распознавание объектов, и необходимость в наличии двух выборок: обучающей и контрольной, к каждой из которых предъявляются жесткие требования по их объему. Сформировать на практике выборку большого объема является, как правило, сложной задачей, а две независимые выборки – тем более.
, а вторая – для оценки вероятности ошибок распознавания. Недостатками этого подхода являются громоздкость расчетов, поскольку приходится большое число раз осуществлять распознавание объектов, и необходимость в наличии двух выборок: обучающей и контрольной, к каждой из которых предъявляются жесткие требования по их объему. Сформировать на практике выборку большого объема является, как правило, сложной задачей, а две независимые выборки – тем более. ), а контрольную выборку генерировать датчиком случайных векторов в соответствии с
), а контрольную выборку генерировать датчиком случайных векторов в соответствии с  . Такой подход улучшает точность построения
. Такой подход улучшает точность построения 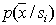 по сравнению с предыдущим вариантом, но обладает другими недостатками. В частности, помимо большого числа актов распознавания требуется сгенерировать соответствующее число требуемых для этого псевдообъектов, что само по себе связано с определенными затратами вычислительных ресурсов, особенно если распределения
по сравнению с предыдущим вариантом, но обладает другими недостатками. В частности, помимо большого числа актов распознавания требуется сгенерировать соответствующее число требуемых для этого псевдообъектов, что само по себе связано с определенными затратами вычислительных ресурсов, особенно если распределения 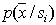 имеют сложный вид.
имеют сложный вид. и
и  :
:
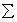 – матрица ковариаций,
– матрица ковариаций, – транспонирование матрицы,
– транспонирование матрицы,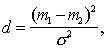 откуда видно, что
откуда видно, что 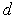 тем больше, чем удаленнее друг от друга
тем больше, чем удаленнее друг от друга 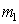 и
и 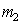 и компактнее распределения (меньше
и компактнее распределения (меньше  ).
).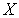 для различения в пользу
для различения в пользу 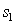 против
против 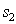 :
: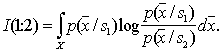
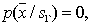 а
а 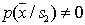 , и наоборот.
, и наоборот.
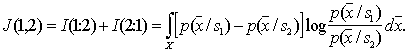

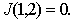 В других случаях
В других случаях  Действительно, если
Действительно, если 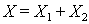 , где в области
, где в области справедливо
справедливо  , а в
, а в  –
– 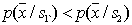 , то
, то 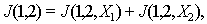 причем
причем 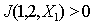 и
и  .
.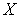 и
и  независимы, то
независимы, то 
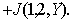
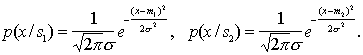
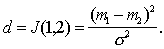

Комментарии