Лекция
Это продолжение увлекательной статьи про методы распознавания образов.
...
данной грамматикой). В противном случае, объект либо отклоняется, либо подвергается анализу с помощью других грамматик, описывающих другие классы объектов. Известны бесконтекстные, автоматные и другие типы грамматик. Однако задача восстановления (определения) грамматик по некоторому множеству высказываний (предложений - описаний объектов), порождающих данный язык, является трудно формализуемой. В литературе приводится описание эвристических правил автоматического восстановления грамматик для конструирования и применения лингвистических алгоритмов распознавания образов.
В методах данной группы, в отличие от интенсионального направления, каждому изучаемому объекту в большей или меньшей мере придается самостоятельное диагностическое значение. По своей сути эти методы близки к клиническому подходу, который рассматривает людей не как проранжированную по тому или иному показателю цепочку объектов, а как целостные системы, каждая из которых индивидуальна и имеет особенную диагностическую ценность [46]. Такое бережное отношение к объектам исследования не позволяет исключать или утрачивать информацию о каждом отдельном объекте, что происходит при применении методов интенсионального направления, использующих объекты только для обнаружения и фиксации закономерностей поведения их атрибутов.
Основными операциями в распознавании образов с помощью обсуждаемых методов являются операции определения сходства и различия объектов. Объекты в указанной группе методов играют роль диагностических прецедентов. При этом в зависимости от условий конкретной задачи роль отдельного прецедента может меняться в самых широких пределах от главной до весьма косвенного участия в процессе распознавания. В свою очередь, условия задачи могут требовать для успешного решения участия различного количества диагностических прецедентов от одного в каждом распознаваемом классе до полного объема выборки, а также разных способов вычисления мер сходства и различия объектов. Этими требованиями объясняется дальнейшее разделение экстенсиональных методов на подклассы.
Это наиболее простой экстенсиональный метод распознавания. Он применяется, например, тогда, когда распознаваемые классы отображаются в пространстве признаков компактными геометрическими группировками. В таком случае обычно в качестве точки - прототипа выбирается центр геометрической группировки класса (или ближайший к центру объект). Для классификации неизвестного объекта находится ближайший к нему прототип, и объект относится к тому же классу, что и этот прототип. Очевидно, никаких обобщенных образов классов в данном методе не формируется.
В качестве меры близости могут применяться различные типы расстояний. Часто для дихотомических признаков используется расстояние Хэмминга, которое в данном случае равно квадрату евклидова расстояния. При этом решающее правило классификации объектов эквивалентно линейной решающей функции.
Указанный факт следует особо отметить. Он наглядно демонстрирует связь прототипной и признаковой репрезентации информации о структуре данных. Пользуясь приведенным представлением, можно, например, любую традиционную измерительную шкалу, являющуюся линейной функцией от значений дихотомических признаков, рассматривать как гипотетический диагностический прототип. В свою очередь, если анализ пространственной структуры распознаваемых классов позволяет сделать вывод об их геометрической компактности, то каждый из этих классов достаточно заменить одним прототипом который, фактически эквивалентен линейной диагностической модели.
На практике, конечно, ситуация часто бывает отличной от описанного идеализированного примера. Перед исследователем, намеревающимся применить метод распознавания, основанный на сравнении с прототипами диагностических классов, встают непростые проблемы. Это, в первую очередь, выбор меры близости (метрики), от которого может существенно измениться пространственная конфигурация распределения объектов. И, во-вторых, самостоятельной проблемой является анализ многомерных структур экспериментальных данных. Обе эти проблемы особенно остро встают перед исследователем в условиях высокой размерности пространства признаков, характерной для реальных задач.
Метод k-ближайших соседей для решения задач дискриминантного анализа был впервые предложен еще в 1952 году. Он заключается в следующем. При классификации неизвестного объекта находится заданное число (k) геометрически ближайших к нему в пространстве признаков других объектов (ближайших соседей) с уже известной принадлежностью к распознаваемым классам. Решение об отнесении неизвестного объекта к тому или иному диагностическому классу принимается путем анализа информации об этой известной принадлежности его ближайших соседей, например, с помощью простого подсчета голосов.
Первоначально метод k-ближайших соседей рассматривался как непараметрический метод оценивания отношения правдоподобия. Для этого метода получены теоретические оценки его эффективности в сравнении с оптимальным байесовским классификатором. Доказано, что асимптотические вероятности ошибки для метода k-ближайших соседей превышают ошибки правила Байеса не более чем в два раза.
Как отмечалось выше, в реальных задачах часто приходится оперировать объектами, которые описываются большим количеством качественных (дихотомических) признаков. При этом размерность пространства признаков соизмерима или превышает объем исследуемой выборки. В таких условиях удобно интерпретировать каждый объект обучающей выборки, как отдельный линейный классификатор. Тогда тот или иной диагностический класс представляется не одним прототипом, а набором линейных классификаторов. Совокупное взаимодействие линейных классификаторов дает в итоге кусочно-линейную поверхность, разделяющую в пространстве признаков распознаваемые классы. Вид разделяющей поверхности, состоящей из кусков гиперплоскостей, может быть разнообразным и зависит от взаимного расположения классифицируемых совокупностей.
Также можно использовать другую интерпретацию механизмов классификации по правилу k-ближайших соседей. В ее основе лежит представление о существовании некоторых латентных переменных, абстрактных или связанных каким-либо преобразованием с исходным пространством признаков. Если в пространстве латентных переменных попарные расстояния между объектами такие же, как и в пространстве исходных признаков, и количество этих переменных значительно меньше числа объектов, то интерпретация метода k-ближайших соседей может рассматриваться под углом зрения сравнения непараметрических оценок плотностей распределения условных вероятностей. Приведенное здесь представление о латентных переменных близко по своей сути к представлению об истинной размерности и другим представлениям, используемым в различных методах снижения размерности.
При использовании метода k-ближайших соседей для распознавания образов исследователю приходится решать сложную проблему выбора метрики для определения близости диагностируемых объектов. Эта проблема в условиях высокой размерности пространства признаков чрезвычайно обостряется вследствие достаточной трудоемкости данного метода, которая становится значимой даже для высокопроизводительных компьютеров. Поэтому здесь так же, как и в методе сравнения с прототипом, необходимо решать творческую задачу анализа многомерной структуры экспериментальных данных для минимизации числа объектов, представляющих диагностические классы.
По мнению авторов необходимость уменьшения числа объектов в обучающей выборке (диагностических прецедентов)является недостатком данного метода, т.к. уменьшает представительность обучающей выборки.
Принцип действия алгоритмов вычисления оценок (АВО) состоит в вычислении приоритете (оценок сходства), характеризующих “близость” распознаваемого и эталонных объектов по системе ансамблей признаков, представляющей собой систему подмножеств заданного множества признаков.
В отличие от всех ранее рассмотренных методов алгоритмы вычисления оценок принципиально по-новому оперируют описаниями объектов. Для этих алгоритмов объекты существуют одновременно в самых разных подпространствах пространства признаков. Класс АВО доводит идею использования признаков до логического конца: поскольку не всегда известно, какие сочетания признаков наиболее информативны, то в АВО степень сходства объектов вычисляется при сопоставлении всех возможных или определенных сочетаний признаков, входящих в описания объектов [46].
Используемые сочетания признаков (подпространства) авторы называют опорными множествами или множествами частичных описаний объектов. Вводится понятие обобщенной близости между распознаваемым объектом и объектами обучающей выборки (с известной классификацией), которые называют эталонными объектами. Эта близость представляется комбинацией близостей распознаваемого объекта с эталонными объектами, вычисленных на множествах частичных описаний. Таким образом, АВО является расширением метода k-ближайших соседей, в котором близость объектов рассматривается только в одном заданном пространстве признаков.
Еще одним расширением АВО является то, что в данных алгоритмах задача определения сходства и различия объектов формулируется как параметрическая и выделен этап настройки АВО по обучающей выборке, на котором подбираются оптимальные значения введенных параметров. Критерием качества служит ошибка распознавания, а параметризуется буквально все:
Параметры АВО задаются в виде значений порогов и (или) как веса указанных составляющих. Теоретические возможности АВО превышают или, по крайней мере, не ниже возможностей любого другого алгоритма распознавания образов, так как с помощью АВО могут быть реализованы все мыслимые операции с исследуемыми объектами. Но, как это обычно бывает, расширение потенциальных возможностей наталкивается на большие трудности их практического воплощения, особенно на этапе построения (настройки) алгоритмов данного типа. Отдельные трудности отмечались ранее при обсуждении метода k-ближайших соседей, который можно было интерпретировать как усеченный вариант АВО. Его тоже можно рассматривать в параметрическом виде и свести задачу к поиску взвешенной метрики выбранного типа. В то же время уже здесь для высокоразмерных задач возникают сложные теоретические вопросы и проблемы, связанные с организацией эффективного вычислительном процесса. Для АВО, если попытаться использовать потенциальные возможности данных алгоритмов в полном объеме, указанные трудности возрастают многократно.
Отмеченные проблемы объясняют то, что на практике применение АВО для решения высокоразмерных задач сопровождается введением каких-либо эвристических ограничений и допущений. В частности, известен пример использования АВО в психодиагностике, в котором апробирована разновидность АВО, фактически эквивалентная методу k-ближайших соседей.
Заканчивая обзор методов распознавания образов, остановимся еще на одном подходе. Это так называемые коллективы решающих правил.
Так как различные алгоритмы распознавания проявляют себя по-разному на одной и той же выборке объектов, то закономерно встает вопрос о синтетическом решающем правиле, адаптивно использующем сильные стороны этих алгоритмов. В синтетическом решающем правиле применяется двухуровневая схема распознавания. На первом уровне работают частные алгоритмы распознавания, результаты которых объединяются на втором уровне в блоке синтеза. Наиболее распространенные способы такого объединения основаны на выделении областей компетентности того или иного частного алгоритма. Простейший способ нахождения областей компетентности заключается в априорном разбиении пространства признаков исходя из профессиональных соображений конкретной науки (например, расслоение выборки по некоторому признаку). Тогда для каждой из выделенных областей строится собственный распознающий алгоритм. Другой способ базируется на применении формального анализа для определения локальных областей пространства признаков как окрестностей распознаваемых объектов, для которых доказана успешность работы какого-либо частного алгоритма распознавания.
Самый общий подход к построению блока синтеза рассматривает результирующие показатели частных алгоритмов как исходные признаки для построения нового обобщенного решающего правила. В этом случае могут использоваться все перечисленные выше методы интенсионального и экстенсионального направлений в распознавании образов. Эффективными для решения задачи создания коллектива решающих правил являются логические алгоритмы типа “Кора” и алгоритмы вычисления оценок (АВО), положенные в основу так называемого алгебраического подхода, обеспечивающего исследование и конструктивное описание алгоритмов распознавания, в рамки которого укладываются все существующие типы алгоритмов [46].
Приведенные характеристики различных методов распознавания образов были бы неполными без обсуждения вопроса о критериях качества алгоритмов и о способах оценки этих критериев. Показателями качества обычно являются либо собственно ошибка классификации, либо связанные с ней некоторые функции потерь. При этом различают условную вероятность ошибочной классификации, ожидаемую ошибку алгоритма классификации на выборке заданного объема и асимптотическую ожидаемую ошибку классификации. Функции потерь также разделяют на функцию средних потерь, функцию ожидаемых потерь и эмпирическую функцию средних потерь.
Для оценки выбранного показателя качества того или иного алгоритма распознавания образов применяется три основных экспериментальных способа.
Первый способ дает завышенную оценку качества распознавания по сравнению с той же оценкой качества по независимым от обучения данным. Второй способ является самым простым и убедительным. Им широко пользуются, если экспериментальных данных достаточно. В то же время третий способ, называемый также методом скользящего экзамена является наиболее предпочтительным, так как дает меньшую дисперсию оценки вероятности ошибки. Однако этот метод является и самым трудоемким, так как требует многократного построения правила распознавания.
Применительно к рассмотренным методам распознавания образов эта трудоемкость наиболее существенна для многих методов интенсионального направления, для которых необходимо на каждом шаге скользящего экзамена производить коррекцию используемых характеристик признаков и их связей (например, средних значений и ковариаций). Но для экстенсиональных методов, оперирующих объектами, достаточно просто не включать контрольный объект в исследуемое правило распознавания. Поэтому данные методы (k-ближайших соседей, АВО) как бы приспособлены для реализации метода скользящего экзамена, который позволяет избегать расточительного обращения с экспериментальным материалом и одновременно получать наиболее эффективные оценки качества распознающих алгоритмов.
Сравнение описанных выше методов распознавания образов приводит к следующим выводам. Для решения реальных задач из группы методов интенсионального направления практическую ценность представляют параметрические методы и методы, основанные на предложениях о виде решающих функций. Параметрические методы составляют основу традиционной методологии конструирования показателей. Применение этих методов в реальных задачах связано с наложением сильных ограничений на структуру данных, которые приводят к линейным диагностическим моделям с очень приблизительными оценками их параметров. При использовании методов, основанных на предположениях о виде решающих функций, исследователь также вынужден обращаться к линейным моделям. Это обусловлено высокой размерностью пространства признаков, характерной для реальных задач, которая при повышении степени полиноминальной решающей функции дает огромный рост числа ее членов при проблематичном сопутствующем повышении качества распознавания. Таким образом, спроецировав область потенциального применения интенсиональных методов распознавания на реальную проблематику, получим картину, соответствующую хорошо отработанной традиционной методологии линейных диагностических моделей.
Как отмечалось ранее, свойства линейных диагностических моделей, в которых диагностический показатель представлен взвешенной суммой исходных признаков, хорошо изучены. Результаты этих моделей (при соответствующем нормировании) интерпретируются как расстояния от исследуемых объектов до некоторой гиперплоскости в пространстве признаков или, что эквивалентно, как проекции объектов на некоторую прямую линию в данном пространстве. Поэтому линейные модели адекватны только простым геометрическим конфигурациям областей пространства признаков, в которые отображаются объекты разных диагностических классов. При более сложных распределениях эти модели принципиально не могут отражать многие особенности структуры экспериментальных данных. В то же время такие особенности способны нести ценную диагностическую информацию.
Вместе с тем, появление в какой-либо реальной задаче простых многомерных структур (в частности, многомерных нормальных распределений) следует скорее расценивать как исключение, чем как правило. Часто диагностические классы формируются на основании сложносоставных внешних критериев, что автоматически влечет за собой геометрическую неоднородность данных классов в пространстве признаков. Это особенно касается “жизненных”, наиболее часто практически встречающихся критериев. В таких условиях применение линейных моделей фиксирует только самые “грубые” закономерности экспериментальной информации.
Применение экстенсиональных методов не связано каким-либо предположениями о структуре экспериментальной информации кроме того, что внутри распознаваемых классов должны существовать одна или несколько групп чем-то похожих объектов, а объекты разных классов должны чем-то отличаться друг от друга. Очевидно при любой конечной размерности обучающей выборки (а другой она быть и не может) это требование выполняется всегда просто по той причине, что существуют случайные различия между объектами. В качестве мер сходства применяются различные меры близости (расстояния) объектов в пространстве признаков. Поэтому эффективное использование экстенсиональных методов распознавания образов зависит от того, насколько удачно определены указанные меры близости, а также от того, какие объекты обучающей выборки (объекты с известной классификацией) выполняют роль диагностических прецедентов. Успешное решение данных задач дает результат, приближающийся к теоретически достижимым пределам эффективности распознавания.
Достоинствам экстенсиональных методов распознавания образов противопоставлена, в первую очередь, высокая техническая сложность их практического воплощения. Для высокоразмерных пространств признаков внешне простая задача нахождения пар ближайших точек превращается в серьезную проблему. Также многие авторы отмечают в качестве проблемы необходимость запоминания достаточно большого количества объектов, представляющих распознаваемые классы.
По мнению авторов, само по себе это не является проблемой, однако воспринимается как проблема (например, в методе k-ближайших соседей) по той причине, что при распознавании каждого объекта происходит полный перебор всех объектов обучающей выборки.
Теоретические проблемы применения экстенсиональных методов распознавания связаны с проблемами поиска информативных групп признаков, нахождения оптимальных метрик для измерения сходства и различия объектов и анализа структуры экспериментальной информации. В то же время успешное решение перечисленных проблем позволяет не только конструировать эффективные распознающие алгоритмы, но и осуществлять переход от экстенсионального знания эмпирических фактов к интенсиональному знанию о закономерностях их структуры.
Переход от экстенсионального знания к интенсиональному происходит на той стадии, когда формальный алгоритм распознавания уже сконструирован и продемонстрировал свою эффективность. Тогда производится изучение механизмов, за счет которых достигается полученная эффективность. Такое изучение, связанное с анализом геометрической структуры данных, может, например, привести к выводу, что достаточно заменить объекты, представляющие тот или иной диагностический класс, одним типичным представителем (прототипом). Это эквивалентно, как отмечалось выше, заданию традиционной линейной диагностической шкалы. Также возможно, что каждый диагностический класс достаточно заменить несколькими объектами, осмысленными как типичные представители некоторых подклассов, что эквивалентно построению веера линейных шкал. Возможны и другие варианты, которые будут рассмотрены ниже.
Таким образом обзор методов распознавания показывает, что в настоящее время теоретически разработан целый ряд различных методов распознавания образов. В литературе приводится развернутая их классификация. Однако для большинства этих методов их программная реализация отсутствует, и это глубоко закономерно, можно даже сказать “предопределено” характеристиками самих методов распознавания. Об этом можно судить потому, что такие системы мало упоминаются в специальной литературе, других общедоступных источниках информации.
Следовательно остается недостаточно разработанным вопрос о практической применимости тех или иных теоретических методов распознавания для решения практических задач при реальных (т.е. довольно значительных) размерностях данных и на реальных современных компьютерах.
Вышеупомянутое обстоятельство может быть понято, если напомнить, что сложность математической модели экспоненциально увеличивает трудоемкость программной реализации системы и в такой же степени уменьшает шансы на то, что эта система будет практически работать. Это означает, что реально на рынке можно реализовать только такие программные системы, в основе которых лежат достаточно простые и “прозрачные” математические модели. Поэтому разработчик, заинтересованный в тиражировании своего программного продукта, подходит к вопросу о выборе математической модели не с чисто научной точки зрения, а как прагматик, с учетом возможностей программной реализации. Он считает, что модель должна быть как можно проще, а значит реализоваться с меньшими затратами и более качественно, а также должна обязательно работать (быть практически эффективной).
В этой связи особенно актуальной представляется задача реализации в системах распознавания механизма обобщения описаний объектов, относящихся к одному классу, т.е. механизм формирования компактных обобщенных образов. Очевидно, что такой механизм обобщения позволит “сжать” любую по размерности обучающую выборку к заранее известной по размерности базе обобщенных образов.
В заключение краткого обзора методов распознавания представим суть вышеизложенного в сводной таблице, а также в форме в виде диаграмы:
1. классификация методов распознавания;
2. области применения методов распознавания;
3. классификация ограничений методов распознавания.
|
Классификация
методов распознавани |
Область
применения |
Ограничения
(недостатки) |
||
|
Методы распознавания
|
Интенсиальные методы
|
Методы, основанные на оценках плотностей распределения значений признаков (или сходства и различия объектов)
|
Задачи с известным распределением, как правило нормальным, необходимость набора большой статистики.
|
Отсутствие обобщения. Необходимость перебора всей обучающей выборки при распознавании, высокая чувствительность к непредставительности обучающей выборки и артефактам.
|
|
Методы, основанные на предположениях о классе решающих функций
|
Классы должны быть хорошо разделяемыми, система признаков - ортонормированной.
|
Отсутствие обобщения. Должен быть заранее известен вид решающей функции. Невозможность учета новых знаний о корреляциях между признаками.
|
||
|
Логические методы
|
Задачи небольшой размерности пространства признаков.
|
Отсутствие обобщения. При отборе логических решающих правил (коньюнкций) необходим полный перебор. Высокая вычислительная трудоемкость.
|
||
|
Лингвистические (структурные) методы
|
Задачи небольшой размерности пространства признаков.
|
Отсутствие обобщения. Задача восстановления (определения) грамматики по некоторому множеству высказываний (описаний объектов), является трудно формализуемой. Нерешенность теоретических проблем.
|
||
|
Экстенсиальные методы
|
Метод сравнения с прототипом
|
Задачи небольшой размерности пространства признаков.
|
Отсутствие обобщения. Высокая зависимость результатов классификации от меры расстояния (метрики).
|
|
|
Метод k-ближайших соседей
|
Задачи небольшой размерности по количеству классов и признаков.
|
Отсутствие обобщения. Высокая зависимость результатов классификации от меры расстояния (метрики). Необходимость полного перебора обучающей выборки при распознавании. Вычислительная трудоемкость.
|
||
|
Алгоритмы вычисления оценок
(голосования) АВО |
Задачи небольшой размерности по количеству классов и признаков.
|
Отсутствие обобщения. Зависимость результатов классификации от меры расстояния (метрики). Необходимость полного перебора обучающей выборки при распознавании. Высокая техническая сложность метода.
|
||
|
Коллективы решающих правил
|
Задачи небольшой размерности по количеству классов и признаков.
|
Отсутствие обобщения. Очень высокая техническая сложность метода, нерешенность ряда теоретических проблем, как при определении областей компетенции частных методов, так и в самих частных методах.
|
||
Процессу распознавания всегда предшествует процесс обучения, т. е. процесс, во время которого мы знакомимся с некоторым количеством объектов или явлений, зная наперед об их принадлежности определенному образу. По такому принципу дети обучаются распознавать объекты окружающего мира и называть их образ. (карандаш, яблоко, собака и т.д.) Когда вы сталкиваетесь с каким либо неизвестным вам предметом или явлением, то не можете сразу его определить , т.к. вам не с чем его сравнивать. Пример (экзотические фрукты, экзотические растения или животные и т.п.)

Все эти буквы «а» написанные разными шрифтами относятся к одному образу, несмотря на существенное различие.
Проблема распознавания
1. Человеческий мозг подсознательно разбивает объекты окружающего мира на классы, но механизм этого процесса неизвестен.
2. Процессу распознавания(классификации) предшествует процесс обучения, кроме случаев распознавания без учителя.
3. Благодаря априорному свойству схожести объектов внутри образа необязательно изучать все объекты образа, достаточно сделать представительную выборку.
4. Из-за расплывча тос ти образов, различных погрешностей (выборки, измерения и выбора свойств) невозможно гарантировать безошибочное распознавание.
Если мы можем точно (в виде конкретных признаков) сформулировать то общее, что объединяет объекты в класс, то задача распознаваниясводится к сравнению признаков предъявляемых объектов с заранее известными. Этот принцип используется в контрольно-сортирующих устройствах для распознавания бракованных деталей.
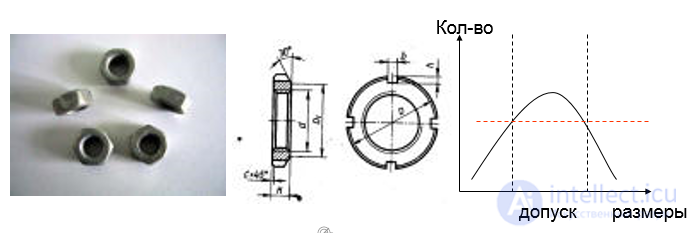
Нас будет интересовать тот случай, когда общность свойств объектов каждого класса заранее установить невозможно или неудобно. В этом случае нужно классифицировать объекты.
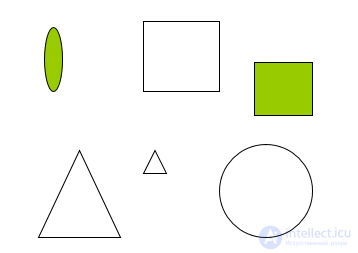
Существует ли «объективная», «естественная» классификация или она всегда «субъективна»?
Объекты на рисунке можно классифицировать по разному, например так:
По цвету - 2 образа : прозрачные и закрашенные фигуры.
По числу углов - 3 образа : фигуры с 3-мя, 4-мя и без углов.
По площади – 2 образа: большие и малые или 3 образа: большие, средние, малые.
Вывод: все реальные объекты имеют бесконечное число
продолжение следует...
Часть 1 Методы распознавания образов, классификация и основные понятия
Часть 2 ЭКСТЕНСИОНАЛЬНЫЕ МЕТОДЫ - Методы распознавания образов, классификация и основные понятия
Часть 3 АНАЛИЗ ПЕРСПЕКТИВНЫХ НАПРАВЛЕНИЙ РАЗВИТИЯ МЕТОДОВ РАСПОЗНАВАНИЯ - Методы распознавания образов,
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области методы распознавания образов имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое методы распознавания образов, объект, свойство, признак, шкала измерений, шкала свойств, образ , материал обучения, материал экзамена, решающее правило, таблица объекты-свойства, тос, мера сходства, метрика и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Распознавание образов
Термины: Распознавание образов