Лекция
Привет, Вы узнаете о том , что такое big data, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое big data, большие данные , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
большие данные (англ. big data, [ˈbɪɡ ˈdeɪtə]) в информационных технологиях — совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объемов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence В данную серию включают средства массово-параллельной обработки неопределенно структурированных данных, прежде всего, решениями категории NoSQL, алгоритмами MapReduce, программными каркасами и библиотеками проекта Hadoop.
В качестве определяющих характеристик для больших данных отмечают «три V»: объем (англ. volume, в смысле величины физического объема), скорость (англ. velocity в смыслах как скорости прироста, так и необходимости высокоскоростной обработки и получения результатов), многообразие (англ. variety, в смысле возможности одновременной обработки различных типов структурированных и полуструктурированных данных).
Большие данные (Big Data) – совокупность непрерывно увеличивающихся объемов информации одного контекста, но разных форматов представления, а также методов и средств для эффективной и быстрой обработки.
Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала Nature, подготовившему к 3 сентября 2008 года специальный выпуск с темой «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объемами данных?», в котором были собраны материалы о феномене взрывного роста объемов и многообразия обрабатываемых данных и технологических перспективах в парадигме вероятного скачка «от количества к качеству»; термин был предложен по аналогии с расхожими в деловой англоязычной среде метафорами «большая нефть», «большая руда»
Несмотря на то, что термин вводился в академической среде и прежде всего разбиралась проблема роста и многообразия научных данных, начиная с 2009 года термин широко распространился в деловой прессе, а к 2010 году относят появление первых продуктов и решений, относящихся исключительно и непосредственно к проблеме обработки больших данных. К 2011 году большинство крупнейших поставщиков информационных технологий для организаций в своих деловых стратегиях используют понятие о больших данных, в том числе IBM , Oracle , Microsoft , Hewlett-Packard , EMC а основные аналитики рынка информационных технологий посвящают концепции выделенные исследования
В 2011 году Gartner отмечает большие данные как тренд номер два в информационно-технологической инфраструктуре (после виртуализации и как более существенный, чем энергосбережение и мониторинг) . Прогнозируется, что внедрение технологий больших данных наибольшее влияние окажет на информационные технологии в производстве, здравоохранении, торговле, государственном управлении, а также в сферах и отраслях, где регистрируются индивидуальные перемещения ресурсов
С 2013 года большие данные как академический предмет изучаются в появившихся вузовских программах по науке о данных и вычислительным наукам и инженерии.
В качестве примеров источников возникновения больших данных приводятся непрерывно поступающие данные с измерительных устройств, события от радиочастотных идентификаторов, потоки сообщений из социальных сетей, метеорологические данные, данные дистанционного зондирования Земли, потоки данных о местонахождении абонентов сетей сотовой связи, устройств аудио- и видеорегистрации. Ожидается, что развитие и начало широкого использования этих источников инициирует проникновение технологий больших данных как в научно-исследовательскую деятельность, так и в коммерческий сектор и сферу государственного управления.
Благодаря экспоненциальному росту возможностей вычислительной техники, описанному в законе Мура , объем данных не может являться точным критерием того, являются ли они большими. Об этом говорит сайт https://intellect.icu . Например, сегодня большие данные измеряются в терабайтах, а завтра – в петабайтах. Поэтому главной характеристикой Big Data является степень их структурированности и вариантов представления.
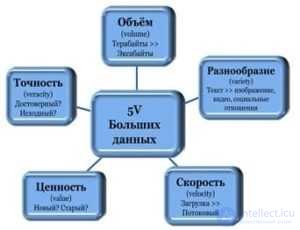
5V — главные характеристики Big Data
Яркая иллюстрация больших данных – это непрерывно поступающая информация с датчиков или устройств аудио- и видеорегистрации, потоки сообщений из соцсетей, метеорологические данные, координаты геолокации абонентов сотовой связи и т.п. . Например, вот здесь мы рассказывали, как ПАО «Газпромнефть» собирал и анализировал более 200 миллионов разновариантных записей с контроллеров систем управления на нефтяных скважинах, записи рестартов напряжения из аварийных журналов, особенности эксплуатации насосов и характеристики скважинных условий для формирования и проверки гипотез о причинах сбоев и выявления ранее неизвестных взаимосвязей в работе насосного оборудования .
Таким образом, источниками больших данных могут быть :
К основным методам сбора и анализа больших данных относят следующие:
Разнородность больших данных обусловливает специфические технологии работы с ними
Программно-аппаратные средства работы с Big Data предусматривают масштабируемость, параллельные вычисления и распределенность, т.к. непрерывное увеличение объема – это одна из главных характеристик больших данных. К основным технологиям относят нереляционные базы данных (NoSQL), модель обработки информации MapReduce, компоненты кластерной экосистемы Hadoop, языки программирования R и Python, а также специализированные продукты Apache (Spark, AirFlow, Kafka, HBase и др.) . Все это и многое другое мы рассматриваем на наших практических курсах для аналитиков, инженеров и администраторов по работе с большими данными.
Наиболее часто указывают в качестве базового принципа обработки больших данных в SN-архитектуру (англ. Shared nothing architecture), обеспечивающую массивно-параллельную обработку, масштабируемую без деградации на сотни и тысячи узлов обработки[источник не указан 1908 дней]. При этом, McKinsey, кроме рассматриваемых большинством аналитиков технологий NoSQL, MapReduce, Hadoop, R, включает в контекст применимости для обработки больших данных также технологии Business Intelligence и реляционные системы управления базами данных с поддержкой языка SQL[24].
Существует ряд аппаратно-программных комплексов, предоставляющих предконфигурированные решения для обработки больших данных: Aster MapReduce appliance (корпорации Teradata), Oracle Big Data appliance, Greenplum appliance (корпорации EMC, на основе решений поглощенной компании Greenplum). Эти комплексы поставляются как готовые к установке в центры обработки данных телекоммуникационные шкафы, содержащие кластер серверов и управляющее программное обеспечение для массово-параллельной обработки.
Аппаратные решения для аналитической обработки в оперативной памяти, в частности, предлагаемой аппаратно-программными комплексами Hana (предконфигурированное аппаратно-программное решение компании SAP) и Exalytics (комплекс компании Oracle на основе реляционной системы Timesten (англ.) и многомерной Essbase), также иногда относят к решениям из области больших данных , несмотря на то, что такая обработка изначально не является массово-параллельной, а объемы оперативной памяти одного узла ограничиваются несколькими терабайтами.
Кроме того иногда к решениям для больших данных относят и аппаратно-программные комплексы на основе традиционных реляционных систем управления базами данных — Netezza, Teradata, Exadata, как способные эффективно обрабатывать терабайты и эксабайты структурированной информации, решая задачи быстрой поисковой и аналитической обработки огромных объемов структурированных данных. Отмечается, что первыми массово-параллельными аппаратно-программными решениями для обработки сверхбольших объемов данных были машины компаний Britton Lee (англ.), впервые выпущенные в 1983 году, и Teradata (начали выпускаться в 1984 году, притом в 1990 году Teradata поглотила Britton Lee).
Аппаратные решения DAS — систем хранения данных, напрямую присоединенных к узлам — в условиях независимости узлов обработки в SN-архитектуре также иногда относят к технологиям больших данных. Именно с появлением концепции больших данных связывают всплеск интереса к DAS-решениям в начале 2010-х годов, после вытеснения их в 2000-е годы сетевыми решениями классов NAS и SAN
Чтобы получить рабочую гипотезу о причинах возникновения конкретных ситуаций, в частности, как связаны отказы оборудования с условиями подачи напряжения, или спрогнозировать будущее, например, вероятность своевременного возврата кредита частным заемщиком, анализ больших объемов структурированной и неструктурированной информации выполняется в несколько этапов :
Прочтение данной статьи про big data позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое big data, большие данные и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL