Лекция
SQL-антипаттерн — это типичная ошибка проектирования базы данных или написания запросов, которая сначала кажется удобной, но позже приводит к проблемам: медленным запросам, сложной поддержке, ошибкам данных, дублированию логики и плохой масштабируемости.
| Категория | Примеры |
|---|---|
| Ошибки запросов | SELECT *, ORDER BY RAND(), глубокий OFFSET, функции в WHERE |
| Ошибки индексации | нет индексов, слишком много индексов, неправильный составной индекс |
| Ошибки модели данных | списки в колонке, EAV, JSON вместо связей, God Table |
| Ошибки связей | нет FK, полиморфные связи без контроля, дублирование данных |
| Ошибки производительности | N+1, тяжелые JOIN, неверный порядок табиц в JSON, отчеты на production DB |
| Ошибки безопасности | SQL Injection, склейка SQL строками |
| Ошибки поддержки | God Query, магические числа, плохие имена, нет миграций |
Если выбрать самые критичные, я бы выделил:

Смотри EXPLAIN.
Признаки проблемы:
type = ALL
key = NULL
rows = очень много
Using temporary
Using filesort
Using join buffer
Особенно плохо, если большая таблица читается первой без индекса.
Например:
logs: rows = 10 000 000, type = ALL
А потом только после JOIN применяется сильный фильтр.
Практическое правило выбора порядка JOIN
Обычно хорошо начинать с таблицы, которая:
1. наиболее точно соответствует бизнес-вопросу;
2. имеет самые сильные фильтры WHERE;
3. быстро ограничивает количество строк;
4. имеет подходящий индекс;
5. не размножает строки слишком рано.
Например:
Краткая памятка
| Ошибка | Почему плохо | Лучше |
|---|---|---|
| Начинать с огромной таблицы без фильтра | много лишних строк | начинать с селективной таблицы |
LEFT JOIN + фильтр в WHERE |
превращает LEFT в INNER | фильтр правой таблицы в ON |
| JOIN нескольких коллекций | размножение строк | отдельные запросы или агрегация до JOIN |
| JOIN вместо EXISTS | дубли и DISTINCT |
использовать EXISTS |
| Неполное условие JOIN | неверные суммы и дубли | указывать все ключи связи |
| Неверная ведущая таблица | плохой план выполнения | начинать с главной сущности запроса |
| Поздняя агрегация | большой промежуточный набор | агрегировать раньше |
Главная мысль
Неверный порядок JOIN — это не только про “какую таблицу написать первой”.
Это про то, чтобы база как можно раньше уменьшала количество строк.
Хороший порядок JOIN:
Переработка сгенерированных SQL значений PK.
Использование множества слолбцов в одной бог-таблице. Ничто не говорит «органично», как 100 столбцов битовых флагов, больших строк и целых чисел.
Шаблон «Я скучаю по INI-файлам» : хранение CSV, серриализированных и json строк с разделителями каналов или других необходимых данных для анализа в больших текстовых полях.
(Изменить: для предотвращения путаницы: это правило производственного кода. Оно не применяется к одноразовым сценариям анализа - если я не автор.)
SELECT * Insert Into blah SELECT *
должно быть
SELECT field1, otherfield Insert Into blah (fieldlist) SELECT fieldlist
проблемы:
Очень частый антипаттерн в ORM и backend-коде.
Плохо
Сначала получаем заказы:
SELECT * FROM orders;
Потом для каждого заказа отдельно получаем пользователя:
SELECT * FROM users WHERE id = 1;
SELECT * FROM users WHERE id = 2;
SELECT * FROM users WHERE id = 3;
Если заказов 1000, будет 1001 запрос.
Лучше
SELECT
orders.id,
orders.total,
users.name
FROM orders
JOIN users ON users.id = orders.user_id;
Или использовать eager loading в ORM.
DECLARE @LoopVar int
SET @LoopVar = (SELECT MIN(TheKey) FROM TheTable)
WHILE @LoopVar is not null
BEGIN
-- Do Stuff with current value of @LoopVar
...
--Ok, done, now get the next value
SET @LoopVar = (SELECT MIN(TheKey) FROM TheTable
WHERE @LoopVar < TheKey)
END
А для MS SQL server использование курсоров вообще . Есть лучший способ сделать любую заданную задачу курсора.
--Trim the time Convert(Convert(theDate, varchar(10), 121), datetime)
Должно быть
--Trim the time DateAdd(dd, DateDiff(dd, 0, theDate), 0)
Я видел недавний всплеск «Один запрос лучше, чем два, верно?»
SELECT * FROM blah WHERE (blah.Name = @name OR @name is null) AND (blah.Purpose = @Purpose OR @Purpose is null)
Этот запрос требует двух или трех разных планов выполнения в зависимости от значений параметров. Только один план выполнения генерируется и помещается в кеш для этого текста SQL. Этот план будет использоваться независимо от значения параметров. Это приводит к периодической низкой производительности. Гораздо лучше написать два запроса (по одному на каждый план выполнения)
SELECT
FirstName + ' ' + LastName as "Full Name",
case UserRole
when 2 then "Admin"
when 1 then "Moderator"
else "User"
end as "User's Role",
case SignedIn
when 0 then "Logged in"
else "Logged out"
end as "User signed in?",
Convert(varchar(10), LastSignOn, 101) as "Last Sign On",
DateDiff('d', LastSignOn, getDate()) as "Days since last sign on",
AddrLine1 + ' ' + AddrLine2 + ' ' + AddrLine3 + ' ' +
City + ', ' + State + ' ' + Zip as "Address",
'XXX-XX-' + Substring(
Convert(varchar(9), SSN), 6, 4) as "Social Security #"
FROM Users
Обычно программисты делают это, потому что они намерены привязать свой набор данных непосредственно к сетке, и просто удобно иметь формат SQL Server на стороне сервера, а не форматировать на клиенте.
Запросы, подобные показанному выше, чрезвычайно хрупкие, поскольку они тесно связывают уровень данных с уровнем пользовательского интерфейса. Кроме того, этот стиль программирования полностью предотвращает повторное использование хранимых процедур.
Плохо
SELECT *
FROM orders
WHERE user_id = 15;
Если user_id не индексирован, база может делать полный просмотр таблицы.
Лучше
CREATE INDEX idx_orders_user_id ON orders(user_id);
Особенно индексы нужны для полей, которые часто используются в:
WHERE
JOIN
ORDER BY
GROUP BY
Обратная проблема: разработчик добавляет индекс “на всякий случай”.
Почему плохо
Каждый индекс ускоряет чтение, но замедляет запись:
INSERT
UPDATE
DELETE
Потому что базе нужно обновлять не только таблицу, но и все индексы.
Признак антипаттерна
CREATE INDEX idx_users_name ON users(name);
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_users_status ON users(status);
CREATE INDEX idx_users_created_at ON users(created_at);
CREATE INDEX idx_users_name_email_status ON users(name, email, status);
Не каждый индекс реально полезен.
Лучше
Создавать индексы под конкретные запросы и проверять через:
EXPLAIN
Периодически у разработчика возникает необходимость передать в запрос набор параметров или даже целую выборку «на вход». Иногда попадаются очень странные решения этой задачи.

Пойдем «от обратного» и посмотрим, как делать не стоит, почему, и как можно сделать лучше.
Выглядит обычно примерно так:
query = "SELECT * FROM tbl WHERE id = " + value
… или так:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)
Про этот способ сказано, написано и даже нарисовано предостаточно:
Почти всегда это — прямой путь к SQL-инъекциям и лишней нагрузке на бизнес-логику, которая вынуждена «клеить» строку вашего запроса.
Частично оправдан такой подход может быть только в случае необходимости использования секционирования в версиях PostgreSQL 10 и ниже для получения более эффективного плана. В этих версиях перечень сканируемых секций определяется еще без учета передаваемых параметров, только на основании тела запроса.
Использование плейсхолдеров параметров — это хорошо, оно позволяет использовать PREPARED STATEMENTS, снижая нагрузку как на бизнес-логику (строка запроса формируется и передается только один раз), так и на сервер БД (не требуется повторный разбор и планирование для каждого экземпляра запроса).
Переменное количество аргументов
Проблемы будут ждать нас, когда мы захотим передать заранее неизвестное количество аргументов:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...
Если оставить запрос в таком виде, то это хоть и убережет нас от потенциальных инъекций, но все равно приведет к необходимости склейки/разбора запроса для каждого варианта от количества аргументов. Уже лучше, чем делать это каждый раз, но можно обойтись и без этого.
Достаточно передать всего один параметр, содержащий сериализованное представление массива:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'
Единственное отличие — необходимость явно преобразовывать аргумент в нужный тип массива. Но это не вызывает проблем, поскольку мы и так заранее знаем, куда адресуемся.
Передача выборки (матрицы)
Обычно это всякие варианты передачи наборов данных для вставки в базу «за один запрос»:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...
Помимо описанных выше проблем с «переклейкой» запроса, это нас может привести еще и к out of memory и падению сервера. Причина проста — под аргументы PG резервирует дополнительную память, а количество записей в наборе ограничивается только прикладными хотелками бизнес-логики. В особо клинических случаях приходилось видеть «номерные» аргументы больше $9000 — не надо так.
Перепишем запрос, применив уже «двухуровневую» сериализацию:
INSERT INTO tbl
SELECT
unnest ::text k
, unnest ::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Да, в случае «сложных» значений внутри массива, их требуется обрамлять кавычками.
Понятно, что таким способом можно «развернуть» выборку с произвольным количеством полей.
unnest, unnest, ...
Периодически встречаются варианты передачи вместо «массива массивов» нескольких «массивов столбцов», про которые я упоминал в прошлой статье:
SELECT unnest($1::text[]) k , unnest($2::integer[]) v;
При таком способе, ошибившись при генерации списков значений для разных столбцов, очень просто получить совсем неожиданные результаты, зависящие еще и от версии сервера:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |
Начиная еще с версии 9.3 в PostgreSQL появились полноценные функции для работы с типом json. Поэтому, если определение входных параметров у вас происходит в браузере, вы можете прямо там и формировать json-объект для SQL-запроса:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'
Для предыдущих версий такой же способ можно использовать для each(hstore), но корректная «свертка» с экранированием сложных объектов в hstore может вызвать проблемы.
json_populate_recordset
Если вы заранее знаете, что данные из «входного» json-массива пойдут для заполнения какой-то таблицы, можно сильно сэкономить в «разыменовании» полей и приведении к нужным типам, воспользовавшись функцией json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);
json_to_recordset
А эта функция просто «развернет» переданный массив объектов в выборку, не опираясь на формат таблицы:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2
Плохо
users
-------------------------
id | name | role_ids
1 | Bob | 1,2,5
Потом появляются запросы:
SELECT *
FROM users
WHERE FIND_IN_SET(2, role_ids);
Почему плохо
Лучше
Создать промежуточную таблицу:
users
id | name
roles
id | name
user_roles
user_id | role_id
Запрос:
SELECT users.*
FROM users
JOIN user_roles ON user_roles.user_id = users.id
WHERE user_roles.role_id = 2;
Но если объем данных в передаваемой выборке очень велик, то закинуть его в один сериализованный параметр — тяжело, а иногда и невозможно, поскольку требует разового выделения большого объема памяти. Например, вам необходимо долго-долго собирать большой пакет данных по событиям из внешней системы, а потом хотите разово его обработать на стороне БД.
В этом случае лучшим решением станет использование временных таблиц:
CREATE TEMPORARY TABLE tbl(k text, v integer); ... INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз ... -- тут делаем что-то полезное со всей этой таблицей целиком
Способ хорош именно для редкой передачи больших объемов данных.
С точки зрения описания структуры своих данных временная таблица отличается от «обычной» только лишь одним признаком в системной таблице pg_class, а в pg_type, pg_depend, pg_attribute, pg_attrdef, ... — так и вовсе ничем.
Поэтому в web-системах с большим количеством короткоживущих подключений для каждого из них такая таблица будет порождать новые системные записи каждый раз, которые удаляются с закрытием соединения с БД. В итоге, неконтролируемое использование TEMP TABLE приводит к «распуханию» таблиц в pg_catalog и замедлению многих операций, использующих их.
Конечно, с этим можно бороться с помощью периодического прохода VACUUM FULL по таблицам системного каталога.
Предположим, обработка данных из предыдущего случая достаточно сложна для одного SQL-запроса, но делать ее хочется достаточно часто. То есть мы хотим использовать процедурную обработку в DO-блоке, но использовать передачу данных через временные таблицы будет слишком накладно.
Использовать $n-параметры для передачи в анонимный блок мы тоже не сможем. Выйти из положения нам помогут переменные сессии и функция current_setting.
До версии 9.2 необходимо было предварительно сконфигурировать специальное пространство имен custom_variable_classes для «своих» переменных сессии. На актуальных же версиях можно писать примерно так:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3
На других поддерживаемых процедурных языках можно найти и другие решения.
Сегодня не будет никаких сложных кейсов и мудреных алгоритмов на SQL. Все будет очень просто, на уровне Капитана Очевидность — делаем просмотр реестра событий с сортировкой по времени.
То есть вот лежит в базе табличка events, а у нее поле ts — ровно то самое время, по которому мы хотим эти записи упорядоченно показывать:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);
Понятно, что записей у нас там будет не десяток, поэтому нам потребуется в каком-то виде постраничная навигация.
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
Даже почти не шутка — редко, но встречается в дикой природе. Иногда после работы с ORM бывает тяжело перестроиться на «прямую» работу с SQL.
Но давайте перейдем к более распространенным и менее очевидным проблемам.
SELECT ... FROM events ORDER BY ts DESC LIMIT 26 OFFSET $1; -- 26 - записей на странице, $1 - начало страницы
Откуда тут взялось число 26? Это примерное количество записей для заполнения одного экрана. Точнее, 25 отображаемых записей, плюс 1, сигнализирующая, что дальше в выборке хоть что-то еще есть и имеет смысл двигаться дальше.
Конечно, это значение можно не «вшивать» в тело запроса, а передавать через параметр. Но в этом случае планировщик PostgreSQL не сможет опереться на знание, что записей должно оказаться относительно немного, — и запросто выберет неэффективный план.
И пока в интерфейсе приложения просмотр реестра реализован как переключение между визуальными «страницами», никто долго не замечает ничего подозрительного. Ровно до момента, когда в борьбе за удобство UI/UX не решают переделать интерфейс на «бесконечный скролл» — то есть все записи реестра рисуются единым списком, который пользователь может крутить вверх-вниз.
И вот, при очередном тестировании вас ловят на дублировании записей в реестре. Почему, ведь на таблице есть нормальный индекс (ts), на который опирается ваш запрос?
Ровно потому, что вы не учли, что ts не является уникальным ключом в этой таблице. Собственно, и значения у него не уникальны, как у любого «времени» в реальных условиях — поэтому одна и та же запись в двух соседних запросах легко «перескакивает» со страницы на страницу за счет другого конечного порядка в рамках сортировки одинакового значения ключа.
На самом деле, тут скрыта еще и вторая проблема, которую заметить много сложнее — некоторые записи не будут показаны вовсе! Ведь «сдублировавшиеся» записи заняли чье-то место. Подробное объяснение с красивыми картинками можно прочитать тут.
Расширяем индекс
Хитрый разработчик понимает — надо сделать ключ индекса уникальным, а самый простой способ — расширить его заведомо уникальным полем в качестве которого отлично подойдет PK:
CREATE UNIQUE INDEX ON events(ts DESC, id DESC);
А запрос мутирует:
SELECT ... ORDER BY ts DESC, id DESC LIMIT 26 OFFSET $1;
Некоторое время спустя к вам приходит DBA и «радует», что ваши запросы адски грузят сервер своими конскими OFFSET, и вообще, пора бы перейти на навигацию от последнего показанного значения. Ваш запрос мутирует снова:
SELECT ... WHERE (ts, id) < ($1, $2) -- последние полученные на предыдущем шаге значения ORDER BY ts DESC, id DESC LIMIT 26;
Вы облегченно вздохнули, пока не наступила…
Потому что однажды ваш DBA прочитал статью про поиск неэффективных индексов и понял, что «непоследний» timestamp — это нехорошо. И снова пришел к вам — теперь с мыслью, что вот тот индекс должен все-таки превратиться обратно в (ts DESC).
Но что же делать с первоначальной проблемой «скакания» записей между страницами?.. А все просто — надо выбирать блоки с нефиксированным количеством записей!
Вообще, кто нам запрещает читать не «ровно 26», а «не менее 26»? Например, так, чтобы в следующем блоке оказались записи с заведомо другими значениями ts — тогда ведь и проблемы с «перепрыгиванием» записей между блоками не будет!
Вот как этого добиться:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;
Что здесь вообще происходит?
Или то же самое картинкой:
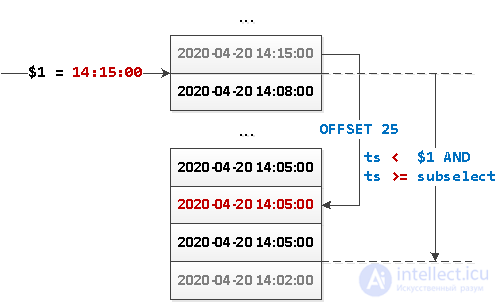
Поскольку теперь у нас выборка не имеет какого-то определенного «начала», то нам ничто не мешает «развернуть» этот запрос в обратную сторону и реализовать динамическую подгрузку блоков данных от «опорной точки» в обе стороны — как вниз, так и вверх.
Замечание
WHERE)
SQL — это не C++, и не JavaScript. Поэтому вычисление логических выражений происходит иначе, и вот это — совсем не одно и то же:
WHERE fncondX() AND fncondY()
= fncondX() && fncondY()
В процессе оптимизации плана исполнения запроса PostgreSQL может произвольным образом «переставлять» эквивалентные условия, не вычислять какие-то из них для отдельных записей, относить к условию применяемого индекса… Короче, проще всего считать, что вы заранее не можете управлять тем, в каком порядке будут (и будут ли вообще) вычисляться равноправные условия.
Поэтому если управлять приоритетом все-таки хочется, надо структурно сделать эти условия неравными с помощью условных выражений и операторов.
Данные и работа с ними — основа нашего комплекса СБИС, поэтому нам очень важно, чтобы операции над ними выполнялись не только корректно, но и эффективно. Давайте посмотрим на конкретных примерах, где могут быть допущены ошибки вычисления выражений, а где стоит улучшить их эффективность.
Плохо
SELECT *
FROM orders
WHERE DATE(created_at) = '2026-05-02';
Проблема: если на created_at есть индекс, он может не использоваться эффективно, потому что к колонке применяется функция DATE().
Лучше
SELECT *
FROM orders
WHERE created_at >= '2026-05-02 00:00:00'
AND created_at < '2026-05-03 00:00:00';
Так база может использовать индекс по created_at.
Стартовый пример из документации:
Когда порядок вычисления важен, его можно зафиксировать с помощью конструкции CASE. Например, такой способ избежать деления на ноль в предложении WHERE ненадежен:SELECT ... WHERE x > 0 AND y/x > 1.5;
Безопасный вариант:SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;
Применяемая так конструкция CASE защищает выражение от оптимизации, поэтому использовать ее нужно только при необходимости.
BEGIN
IF cond(NEW.fld) AND EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
Вроде все выглядит хорошо, но… Никто не обещает, что вложенный SELECT не будет выполняться при ложности первого условия. Поправим с помощью вложенных IF:
BEGIN
IF cond(NEW.fld) THEN
IF EXISTS(SELECT ...) THEN
...
END IF;
END IF;
RETURN NEW;
END;
Теперь посмотрим внимательно — все тело триггерной функции оказалось «завернуто» в IF. А это значит, что нам ничто не мешает вынести это условие из процедуры с помощью WHEN-условия:
BEGIN
IF EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
...
CREATE TRIGGER ...
WHEN cond(NEW.fld);
Такой подход позволяет гарантированно сэкономить ресурсы сервера при ложности условия.
SELECT ... WHERE EXISTS(... A) OR EXISTS(... B)
В неприятном случае можно получить, что оба EXISTS будут «истинными», но оба и выполнятся.
Но если мы точно знаем, что один из них бывает «истинным» много чаще (или «ложным» — для AND-цепочки) — нельзя ли как-то «повысить его приоритет», чтобы второй не выполнялся лишний раз?
Оказывается, можно — алгоритмически подход близок к теме статьи PostgreSQL Antipatterns: редкая запись долетит до середины JOIN.
Давайте просто «засунем под CASE» оба эти условия:
SELECT ...
WHERE
CASE
WHEN EXISTS(... A) THEN TRUE
WHEN EXISTS(... B) THEN TRUE
END
В данном случае мы не определяли ELSE-значение, то есть в случае ложности обоих условий CASE вернет NULL, что трактуется как FALSE в WHERE-условии.
Данный пример можно скомбинировать и иначе — на вкус и цвет:
SELECT ...
WHERE
CASE
WHEN NOT EXISTS(... A) THEN EXISTS(... B)
ELSE TRUE
END
На разбор причин «странной» сработки этого триггера мы потратили два дня — давайте посмотрим, почему.
Исходник:
IF( NEW."Документ_" is null or NEW."Документ_" = (select '"Комплект"'::regclass::oid) or NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
AND ( OLD."ДокументНашаОрганизация" <> NEW."ДокументНашаОрганизация"
OR OLD."Удален" <> NEW."Удален"
OR OLD."Дата" <> NEW."Дата"
OR OLD."Время" <> NEW."Время"
OR OLD."ЛицоСоздал" <> NEW."ЛицоСоздал" ) ) THEN ...
Проблема №1: неравенство не учитывает NULL
Представим, что все OLD-поля имели значение NULL. Что получится?
SELECT NULL <> 1 OR NULL <> 2; -- NULL
А с точки зрения отработки условия NULL эквивалентен FALSE, как было упомянуто выше.
Решение: используйте оператор IS DISTINCT FROM от ROW-оператора, сравнивая сразу целые записи:
SELECT (NULL, NULL) IS DISTINCT FROM (1, 2); -- TRUE
Проблема №2: разная реализация одинакового функционала
Сравним:
NEW."Документ_" = (select '"Комплект"'::regclass::oid)
NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
Зачем тут лишние вложенные SELECT? А функция to_regclass? А по-разному-то почему?..
Исправим:
NEW."Документ_" = '"Комплект"'::regclass::oid NEW."Документ_" = '"ДокументПоЗарплате"'::regclass::oid
Проблема №3: приоритет bool-операций
Отформатируем исходник:
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате} AND
( {... неравенства} )
Упс… По факту, получилось, что в случае истинности любого из двух первых условий, все условие целиком обращается в TRUE, без учета неравенств. А это совсем не то, чего мы хотели.
Исправим:
(
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате}
) AND
( {... неравенства} )
Проблема №4 (маленькая): сложное OR-условие для одного поля
Собственно, проблемы в №3 у нас возникли ровно потому, что условий было три. Но вместо них можно обойтись одним, с помощью механизма coalesce ... IN:
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"')
Так мы и NULL «поймаем», и сложных OR со скобками городить не придется.
Итого
Зафиксируем то, что у нас получилось:
IF (
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"') AND
(
OLD."ДокументНашаОрганизация"
, OLD."Удален"
, OLD."Дата"
, OLD."Время"
, OLD."ЛицоСоздал"
) IS DISTINCT FROM (
NEW."ДокументНашаОрганизация"
, NEW."Удален"
, NEW."Дата"
, NEW."Время"
, NEW."ЛицоСоздал"
)
) THEN ...
А если учесть, что эта триггерная функция может применяться только в UPDATE-триггере из-за наличия OLD/NEW в условии верхнего уровня, то это условие можно вообще вынести в WHEN-условие, как было показано в #1…
EAV — Entity-Attribute-Value.
Пример
product_attributes
--------------------------------
product_id | attribute | value
1 | color | black
1 | size | XL
1 | weight | 2.5
Когда это плохо
Если почти все данные можно было бы хранить обычными колонками:
products
id | color | size | weight
Проблемы EAV
Когда EAV допустим
Когда набор атрибутов действительно динамический, например:
Но даже тогда часто лучше использовать гибрид:
products
id | name | price | category_id | attributes_json
Плохо
orders
---------------------------------
id | items_json
1 | [{"product_id":5,"qty":2}]
Почему плохо
Если нужно часто искать, фильтровать, агрегировать или связывать данные, JSON становится проблемой.
Например:
найти все заказы, где product_id = 5
будет сложнее и медленнее, чем при нормальной структуре.
Лучше
orders
id | user_id | total
order_items
id | order_id | product_id | qty | price
JSON полезен для дополнительной редко используемой информации, но не как замена нормальной модели данных.
Пример
comments
-------------------------------------
id | entity_type | entity_id | text
1 | post | 10 | ...
2 | product | 55 | ...
3 | order | 77 | ...
Почему опасно
База не может нормально проверить внешний ключ, потому что entity_id может ссылаться на разные таблицы.
Проблемы
Лучше
Иногда лучше сделать отдельные таблицы:
post_comments
product_comments
order_comments
Или использовать общую таблицу сущностей:
entities
id | type
comments
id | entity_id | text
Плохо
orders
id | user_id
Но нет ограничения:
FOREIGN KEY (user_id) REFERENCES users(id)
Проблема
Можно создать заказ для несуществующего пользователя:
INSERT INTO orders(user_id) VALUES (999999);
Лучше
ALTER TABLE orders
ADD CONSTRAINT fk_orders_user
FOREIGN KEY (user_id) REFERENCES users(id);
Внешние ключи защищают целостность данных.
NULL без пониманияПример проблемы
SELECT *
FROM users
WHERE deleted_at != '2026-01-01';
Если deleted_at равен NULL, строка может не попасть в результат так, как ожидается.
Правильно
WHERE deleted_at IS NULL
или
WHERE deleted_at IS NOT NULL
Важно помнить: NULL — это не значение, а отсутствие значения.
LEFT JOINПлохо
SELECT *
FROM users
LEFT JOIN orders ON orders.user_id = users.id
WHERE orders.status = 'paid';
Хотели получить всех пользователей и их оплаченные заказы, но условие в WHERE превращает LEFT JOIN почти в INNER JOIN.
Лучше
SELECT *
FROM users
LEFT JOIN orders
ON orders.user_id = users.id
AND orders.status = 'paid';
Условие по правой таблице лучше перенести в ON, если нужно сохранить строки из левой таблицы.
Плохо
orders
--------------------------------
id | user_id | user_name | user_email
Если имя пользователя изменится в таблице users, в заказах останется старое значение.
Но есть нюанс
Иногда дублирование допустимо. Например, в заказе можно хранить snapshot:
customer_name_at_order_time
customer_email_at_order_time
Потому что заказ должен сохранять данные на момент покупки.
Антипаттерн возникает тогда, когда дублирование случайное, а не осознанное.
Плохо
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
Если второй запрос упадет, деньги спишутся, но не зачислятся.
Лучше
START TRANSACTION;
UPDATE accounts
SET balance = balance - 100
WHERE id = 1;
UPDATE accounts
SET balance = balance + 100
WHERE id = 2;
COMMIT;
При ошибке:
ROLLBACK;
Транзакции нужны для операций, где несколько изменений должны выполниться вместе.
Пример
Слишком сложные запросы на сотни строк:
SELECT ...
CASE ...
IF ...
SUBQUERY ...
GROUP_CONCAT ...
HAVING ...
Почему плохо
Лучше
Баланс:
Обратный антипаттерн.
Плохо
$orders = SELECT * FROM orders;
foreach ($orders as $order) {
if ($order['status'] === 'paid') {
...
}
}
Лучше
SELECT *
FROM orders
WHERE status = 'paid';
База данных должна делать то, что она умеет хорошо:
ORDER BY RAND()Плохо
SELECT *
FROM products
ORDER BY RAND()
LIMIT 10;
Проблема: база генерирует случайное значение для множества строк и сортирует их. На больших таблицах это очень медленно.
Лучше
Варианты:
SELECT *
FROM products
WHERE id >= FLOOR(RAND() * (SELECT MAX(id) FROM products))
LIMIT 10;
Или хранить случайный ключ:
random_score
И выбирать по нему.
OFFSETПлохо
SELECT *
FROM orders
ORDER BY id
LIMIT 20 OFFSET 100000;
База должна пройти большое количество строк, чтобы пропустить первые 100000.
Лучше: keyset pagination
SELECT *
FROM orders
WHERE id > 100000
ORDER BY id
LIMIT 20;
Или по дате:
SELECT *
FROM orders
WHERE created_at < '2026-05-01 12:00:00'
ORDER BY created_at DESC
LIMIT 20;
Плохо
SELECT *
FROM users
WHERE phone = 123456789;
Если phone — строка, база может приводить типы и хуже использовать индекс.
Лучше
SELECT *
FROM users
WHERE phone = '123456789';
Тип значения в запросе должен соответствовать типу колонки.
Плохо
created_at VARCHAR(255)
Со значениями:
02-05-2026
Проблемы
Лучше
created_at DATETIME
или
created_at TIMESTAMP
Плохо
status VARCHAR(255)
И туда можно записать что угодно:
paid
payed
done
success
finished
Лучше
Использовать ограничения:
CHECK (status IN ('new', 'paid', 'cancelled'))
Или отдельную таблицу статусов:
statuses
id | code | name
Плохо
SELECT *
FROM orders
WHERE status = 3;
Что такое 3? Оплачен? Отменен? Завершен?
Лучше
SELECT *
FROM orders
WHERE status = 'paid';
Или хотя бы использовать понятные константы в коде:
OrderStatus::PAID
Плохо
SELECT *
FROM users
WHERE id IN (
SELECT user_id
FROM orders
WHERE status = 'paid'
);
Это не всегда плохо, но иногда JOIN читается и оптимизируется лучше.
Альтернатива
SELECT DISTINCT users.*
FROM users
JOIN orders ON orders.user_id = users.id
WHERE orders.status = 'paid';
Но важно: IN, EXISTS и JOIN не всегда взаимозаменяемы. Нужно смотреть смысл запроса и EXPLAIN.
NOT IN с NULLПлохо
SELECT *
FROM users
WHERE id NOT IN (
SELECT user_id FROM orders
);
Если в orders.user_id есть NULL, результат может быть неожиданным.
Лучше
SELECT *
FROM users u
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.user_id = u.id
);
NOT EXISTS часто безопаснее и понятнее.
Пример
Есть индекс:
CREATE INDEX idx_orders_status_created_at
ON orders(status, created_at);
Он хорошо подходит для:
WHERE status = 'paid'
ORDER BY created_at
Но может хуже подходить для:
WHERE created_at >= '2026-05-01'
Порядок колонок в составном индексе важен.
Обычно сначала ставят:
поля с точным равенством
потом поля диапазона
потом поля сортировки
Например:
WHERE user_id = 10
AND status = 'paid'
AND created_at >= '2026-05-01'
ORDER BY created_at
Индекс:
(user_id, status, created_at)
Плохо
SELECT *
FROM orders
WHERE status = 'paid'
ORDER BY created_at DESC
LIMIT 20;
Если нет подходящего индекса, база может делать дорогую сортировку.
Лучше
CREATE INDEX idx_orders_status_created_at
ON orders(status, created_at);
OR ломает использование индексовПлохо
SELECT *
FROM users
WHERE email = 'a@test.com'
OR phone = '123';
Иногда такой запрос хуже использует индексы.
Вариант
SELECT *
FROM users
WHERE email = 'a@test.com'
UNION
SELECT *
FROM users
WHERE phone = '123';
Это не всегда обязательно, но иногда UNION помогает оптимизатору использовать разные индексы.
HAVING вместо WHEREПлохо
SELECT user_id, COUNT(*) as orders_count
FROM orders
GROUP BY user_id
HAVING status = 'paid';
Лучше
SELECT user_id, COUNT(*) as orders_count
FROM orders
WHERE status = 'paid'
GROUP BY user_id;
WHERE фильтрует строки до группировки, HAVING — после группировки.
FLOATПлохо
price FLOAT
FLOAT может давать ошибки округления.
Лучше
price DECIMAL(10,2)
Или хранить в минимальных единицах:
price_cents INT
Например:
1999 = 19.99 USD
LIMITПлохо
SELECT *
FROM logs
ORDER BY created_at DESC;
Если таблица большая, можно случайно вытащить миллионы строк.
Лучше
SELECT *
FROM logs
ORDER BY created_at DESC
LIMIT 100;
Пример
WHERE deleted_at IS NULL
Если почти все запросы используют soft delete, нужно учитывать это в индексах.
Часто полезно
CREATE INDEX idx_orders_deleted_created
ON orders(deleted_at, created_at);
Особенно если есть запросы:
WHERE deleted_at IS NULL
ORDER BY created_at DESC
Проблема
На production-базе выполняют тяжелые отчеты:
SELECT
user_id,
SUM(total),
COUNT(*)
FROM orders
GROUP BY user_id;
по миллионам строк.
Почему плохо
Это может тормозить основное приложение.
Лучше
Использовать:
Плохо
table1
data
value
type
status2
flag
Почему плохо
Через месяц никто не понимает, что значит flag.
Лучше
orders
payment_status
is_hidden
created_at
completed_at
service_checkout_id
Имена должны объяснять смысл данных.
Таблица, в которую складывают все подряд.
Пример
users
------------------------------------------------
id
name
email
password
last_order_id
cart_total
profile_image
billing_address
shipping_address
subscription_status
last_payment_id
admin_notes
game_settings
notification_config
...
Почему плохо
NULL;Лучше
Разделить по смыслу:
users
user_profiles
user_settings
user_addresses
user_subscriptions
Один гигантский SQL-запрос, который делает все.
Признаки
CASE;Лучше
Иногда разбить на:
$sql = "SELECT * FROM users WHERE email = '" . $_GET['email'] . "'";
Это SQL Injection.
Лучше
$stmt = $pdo->prepare(
'SELECT * FROM users WHERE email = :email'
);
$stmt->execute([
'email' => $_GET['email']
]);
Всегда использовать параметры.
EXPLAINПлохо
Разработчик “на глаз” считает, что запрос быстрый.
Лучше
Проверять:
EXPLAIN SELECT ...
Смотреть:
type
key
rows
Extra
Using index
Using where
Using temporary
Using filesort
Особенно важно смотреть:
rows
filtered
possible_keys
key
Плохо
Изменения в БД делаются вручную:
“Я добавил колонку на проде через phpMyAdmin”
Почему плохо
Лучше
Использовать миграции:
php artisan make:migration add_status_to_orders_table
Плохо
Таблица логов растет бесконечно:
logs
events
notifications
audit_trails
Проблемы
Лучше
Заранее продумать:
JOIN — SQL-антипаттернНеверный порядок JOIN — это ситуация, когда таблицы соединяются так, что база данных вынуждена сначала обрабатывать слишком много строк, а уже потом отфильтровывать результат.
Главная проблема: запрос вроде бы логически правильный, но физически выполняется дорого.
Допустим, есть таблицы:
users
orders
order_items
products
Если сначала соединить огромные таблицы, а фильтр применить позже, получится много лишней работы.
Плохо:
SELECT *
FROM users u
JOIN orders o ON o.user_id = u.id
JOIN order_items oi ON oi.order_id = o.id
JOIN products p ON p.id = oi.product_id
WHERE p.category_id = 5;
Если products.category_id = 5 оставляет только маленькую часть товаров, лучше сначала ограничить товары.
Вариант лучше:
SELECT *
FROM products p
JOIN order_items oi ON oi.product_id = p.id
JOIN orders o ON o.id = oi.order_id
JOIN users u ON u.id = o.user_id
WHERE p.category_id = 5;
Но важный нюанс: современные СУБД часто сами переставляют INNER JOIN в более выгодном порядке. Однако это не всегда возможно или не всегда получается идеально.
очень часто вместо какого-нибудь category_id такая проблема возникает с дата(время) полем, когда нужен лишь небольшой интервал данных за определенный момент времени и такая таблица не стоит на первом места в выборке с джоин
LEFT JOINДля INNER JOIN оптимизатор часто может менять порядок таблиц.
А вот с LEFT JOIN порядок имеет логический смысл.
SELECT *
FROM users u
LEFT JOIN orders o ON o.user_id = u.id;
Это значит:
взять всех пользователей, даже если у них нет заказов.
Если поменять порядок:
SELECT *
FROM orders o
LEFT JOIN users u ON u.id = o.user_id;
Смысл уже другой:
взять все заказы, даже если пользователь не найден.
Это не одно и то же.
LEFT JOINОчень частая ошибка.
Плохо:
SELECT *
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
WHERE o.status = 'paid';
Формально написан LEFT JOIN, но условие:
WHERE o.status = 'paid'
убирает строки, где заказов нет. В итоге запрос начинает вести себя почти как INNER JOIN.
Лучше, если нужно сохранить всех пользователей:
SELECT *
FROM users u
LEFT JOIN orders o
ON o.user_id = u.id
AND o.status = 'paid';
Так пользователи без оплаченных заказов останутся в результате.
Один из главных рисков — multiplication of rows, то есть размножение строк.
Пример:
users
1 user -> 10 orders
1 order -> 20 order_items
После JOIN получится:
1 пользователь × 10 заказов × 20 позиций = 200 строк
Если потом добавить еще одну таблицу с несколькими строками на пользователя, результат может раздуться еще сильнее.
Плохо:
SELECT u.id, u.name, o.id, oi.id, n.id
FROM users u
JOIN orders o ON o.user_id = u.id
JOIN order_items oi ON oi.order_id = o.id
JOIN notifications n ON n.user_id = u.id;
Если у пользователя:
10 заказов
200 позиций заказа
50 уведомлений
то можно случайно получить:
200 × 50 = 10 000 строк
для одного пользователя.
Опасный случай — когда к одной сущности присоединяют несколько независимых коллекций.
Например:
user -> orders
user -> roles
user -> notifications
Плохо:
SELECT *
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
LEFT JOIN user_roles ur ON ur.user_id = u.id
LEFT JOIN notifications n ON n.user_id = u.id;
Если у пользователя:
5 заказов
3 роли
20 уведомлений
результат:
5 × 3 × 20 = 300 строк
Хотя реально данных не 300 сущностей, а только 28 связанных записей.
Лучше
Разделять такие данные:
SELECT *
FROM users
WHERE id = 10;
Отдельно:
SELECT *
FROM orders
WHERE user_id = 10;
Отдельно:
SELECT *
FROM user_roles
WHERE user_id = 10;
Или агрегировать до JOIN:
SELECT
u.id,
u.name,
oc.orders_count,
rc.roles_count
FROM users u
LEFT JOIN (
SELECT user_id, COUNT(*) AS orders_count
FROM orders
GROUP BY user_id
) oc ON oc.user_id = u.id
LEFT JOIN (
SELECT user_id, COUNT(*) AS roles_count
FROM user_roles
GROUP BY user_id
) rc ON rc.user_id = u.id;
Плохо:
SELECT *
FROM logs l
JOIN users u ON u.id = l.user_id
WHERE u.status = 'active';
Если logs огромная, а активных пользователей мало, может быть выгоднее сначала отобрать активных пользователей.
Лучше по смыслу:
SELECT *
FROM users u
JOIN logs l ON l.user_id = u.id
WHERE u.status = 'active';
Но опять же: оптимизатор может сам поменять порядок для INNER JOIN.
Более явно можно использовать derived table:
SELECT *
FROM (
SELECT id
FROM users
WHERE status = 'active'
) u
JOIN logs l ON l.user_id = u.id;
Но не стоит делать так всегда. Иногда derived table может, наоборот, помешать оптимизации. Нужно смотреть EXPLAIN.
Иногда проблема не в самом порядке JOIN, а в том, где расположен фильтр.
Плохо
SELECT *
FROM orders o
LEFT JOIN payments p ON p.order_id = o.id
WHERE p.status = 'captured';
Так заказы без платежа исчезнут.
Лучше
Если нужны все заказы, но только captured-платежи:
SELECT *
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.id
AND p.status = 'captured';
Если нужны только заказы с captured-платежом:
SELECT *
FROM orders o
JOIN payments p
ON p.order_id = o.id
AND p.status = 'captured';
То есть сначала нужно понять бизнес-смысл:
нужны все левые строки?
или только строки, у которых есть совпадение справа?
Ведущая таблица — это таблица, с которой логически начинается выборка.
Например, нужно найти последние 20 оплаченных заказов.
Плохо:
SELECT *
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 20;
Логически выборка не про пользователей, а про заказы.
Лучше:
SELECT *
FROM orders o
JOIN users u ON u.id = o.user_id
WHERE o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 20;
И индекс:
CREATE INDEX idx_orders_status_created_user
ON orders(status, created_at, user_id);
Плохо:
SELECT
u.id,
COUNT(oi.id) AS items_count
FROM users u
JOIN orders o ON o.user_id = u.id
JOIN order_items oi ON oi.order_id = o.id
GROUP BY u.id;
Если таблицы большие, запрос может сначала создать огромный промежуточный набор, а потом группировать.
Иногда лучше агрегировать раньше:
SELECT
o.user_id,
SUM(oi_count.items_count) AS total_items
FROM orders o
JOIN (
SELECT order_id, COUNT(*) AS items_count
FROM order_items
GROUP BY order_id
) oi_count ON oi_count.order_id = o.id
GROUP BY o.user_id;
Или еще проще, если order_items уже содержит связь до пользователя через заказ, зависит от схемы.
JOIN вместо EXISTS, когда нужны только признаки существованияПлохо:
SELECT DISTINCT u.*
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE o.status = 'paid';
Если нужно только найти пользователей, у которых есть оплаченный заказ, JOIN может размножать пользователей и потом требует DISTINCT.
Лучше:
SELECT u.*
FROM users u
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.user_id = u.id
AND o.status = 'paid'
);
EXISTS лучше выражает смысл:
есть ли хотя бы одна подходящая строка?
JOIN без полного условияОчень опасный антипаттерн.
Плохо:
SELECT *
FROM order_items oi
JOIN prices p ON p.product_id = oi.product_id;
Если цены зависят еще от валюты, региона или периода действия, результат будет неправильным.
Лучше:
SELECT *
FROM order_items oi
JOIN prices p
ON p.product_id = oi.product_id
AND p.currency = oi.currency
AND oi.created_at >= p.valid_from
AND oi.created_at < p.valid_to;
Неполное условие JOIN часто приводит к дублированию строк и неправильным суммам.
JOIN в твоем стиле запросовНапример, если есть:
warnings
LEFT JOIN checkouts
LEFT JOIN services
LEFT JOIN games
LEFT JOIN assigned_services
Важно понять, какая таблица главная.
Если ты выбираешь предупреждения, то логично:
FROM services_checkouts_warnings warnings
JOIN/LEFT JOIN services_checkouts checkouts
ON checkouts.id = warnings.service_checkout_id
Но если фильтры в основном по checkouts, например:
checkouts.services_uid
checkouts.pay_date
checkouts.services_id
checkouts.game_id
иногда логически и физически выгоднее начинать с checkouts, а уже потом присоединять warnings.
Например:
SELECT ...
FROM services_checkouts checkouts
JOIN services_checkouts_warnings warnings
ON warnings.service_checkout_id = checkouts.id
LEFT JOIN services s
ON s.id = checkouts.services_id
LEFT JOIN games g
ON g.id = checkouts.game_id
WHERE warnings.reached_at IS NOT NULL;
Но если главный фильтр такой:
WHERE warnings.reached_at IS NOT NULL
и предупреждений мало, то начинать с warnings может быть нормально.
Это ситуация, когда разработчик продолжает “докручивать” один и тот же SQL-запрос:
но реальная проблема уже не в синтаксисе запроса, а в объеме, структуре и жизненном цикле данных.
То есть запрос стал медленным не потому, что он “плохо написан”, а потому что данные организованы так, что быстро ответить на вопрос уже невозможно без более радикального подхода.
Плохой подход:
“Давайте еще чуть-чуть оптимизируем этот SELECT”.
Правильный подход:
“Давайте изменим способ хранения, подготовки, агрегации или движения данных”.
Есть запрос:
SELECT
user_id,
COUNT(*) AS orders_count,
SUM(total) AS total_sum
FROM orders
WHERE created_at >= '2026-01-01'
GROUP BY user_id
ORDER BY total_sum DESC
LIMIT 100;
На маленьких данных он работает быстро.
Потом таблица orders выросла до сотен миллионов строк.
Разработчик начинает:
Но запрос все равно тяжелый, потому что он должен прочитать, сгруппировать и отсортировать слишком много строк.
Этот антипаттерн — пытаться получить мгновенный ответ из “сырой” огромной таблицы, когда вопрос по своей природе требует предварительной подготовки данных.
Например:
В таких случаях SQL-запрос уже не должен быть единственным местом оптимизации.
Вместо того чтобы каждый раз считать:
SELECT user_id, COUNT(*), SUM(total)
FROM orders
GROUP BY user_id;
создать таблицу агрегатов:
user_order_stats
--------------------------------
user_id
orders_count
orders_total_sum
last_order_at
И читать уже готовый результат:
SELECT *
FROM user_order_stats
ORDER BY orders_total_sum DESC
LIMIT 100;
Это особенно полезно для:
дашбордов,
рейтингов,
отчетов,
статистики,
финансовых сводок.
Нормализация хороша для целостности данных, но иногда для чтения нужна отдельная read-модель.
Например, вместо сложного запроса:
orders
JOIN users
JOIN payments
JOIN order_items
JOIN products
JOIN services
JOIN games
можно создать read table:
checkout_warning_view_data
--------------------------------
warning_id
checkout_id
user_name
service_name
game_name
payment_status
last_message_at
warning_reached_at
Тогда экран приложения читает простую подготовленную структуру.
Важно: это не хаотичное дублирование данных, а осознанная денормализация под конкретный сценарий чтения.
Если СУБД поддерживает materialized view, можно заранее сохранять результат сложного запроса.
Идея:
Подходит для:
В MySQL часто делают аналог вручную через отдельную таблицу и cron/job.
Если production-база обслуживает заказы, платежи, пользователей и одновременно на ней строят тяжелые отчеты — это часто проблема.
OLTP — рабочая операционная база:
OLAP — аналитическая база:
Правильное решение:
операционные запросы — в основной БД,
аналитика — в реплике, DWH, ClickHouse, BigQuery, Redshift и т. п.
Иногда запрос медленный не потому, что он сложный, а потому что таблица содержит все за все годы.
Например:
logs
events
notifications
audit_trails
orders_history
Если 90% запросов работают только с последними 30 днями, старые данные можно вынести:
logs_current
logs_archive
или использовать партиционирование по дате.
Если таблица огромная и почти всегда фильтруется по дате, региону, tenant_id или другой крупной группе, можно использовать партиционирование.
Например:
orders_2026_01
orders_2026_02
orders_2026_03
или партиции внутри одной таблицы.
Польза: база может читать не всю таблицу, а только нужные партиции.
Но партиционирование — не магия. Оно полезно, когда запросы действительно хорошо отсекают ненужные партиции.
Иногда запрос медленный, потому что модель данных не соответствует тому, как система реально используется.
Например, каждый раз нужно найти “последний статус заказа”:
SELECT *
FROM order_status_history
WHERE order_id = 123
ORDER BY created_at DESC
LIMIT 1;
Если это делается постоянно, можно хранить текущий статус прямо в orders:
orders.current_status
orders.current_status_changed_at
А историю оставить отдельно:
order_status_history
Это уже не “плохая денормализация”, а нормальная оптимизация модели под частый сценарий.
Если данные тяжело посчитать в момент запроса пользователя, их лучше готовить заранее.
Например:
пользователь сделал заказ
событие попало в очередь
воркер обновил агрегаты
дашборд читает готовую статистику
Вместо:
пользователь открыл страницу
страница ждет огромный GROUP BY
Если данные не обязаны быть абсолютно свежими каждую секунду, можно использовать кэш:
Redis,
Memcached,
application cache,
HTTP cache.
Например:
топ товаров за день,
счетчики,
дашборд,
список популярных игр,
статистика по сервисам.
Но кэш не должен скрывать плохую модель данных навсегда. Он полезен, когда понятно:
что кэшируем,
на сколько,
когда инвалидируем.
Если запрос по сути является поиском:
WHERE title LIKE '%text%'
OR description LIKE '%text%'
то бесконечно оптимизировать SQL может быть бессмысленно.
Правильнее вынести поиск в:
Elasticsearch,
OpenSearch,
Meilisearch,
Sphinx,
Solr.
SQL-база остается источником истины, а поисковый индекс — инструментом быстрого поиска.
Признаки, что запрос уже “не надо оптимизировать запросом”
| Признак | Что это значит |
|---|---|
EXPLAIN уже использует хорошие индексы |
Проблема может быть в объеме данных |
| Запрос все равно читает миллионы строк | Нужна агрегация, партиционирование или архив |
Много GROUP BY/ORDER BY по большому набору |
Нужна предрасчитанная read-модель |
| Данные нужны для отчета | Лучше OLAP/реплика/materialized view |
| Экран открывается часто, данные почти одинаковые | Нужен кэш или витрина |
| Таблица содержит историю за годы | Нужны архив/партиции/TTL |
| Запрос обслуживает UI-список со сложными связями | Нужна денормализованная таблица для чтения |
| Оптимизация дает 5%, а нужно ускорение в 10 раз | Нужен другой подход к данным |
Хороший SQL — это не только “запрос работает”.
Хороший SQL должен быть:
Антипаттерн часто выглядит удобно на маленьких данных, но становится проблемой, когда таблицы растут, появляются сложные связи, отчеты, нагрузка и новые разработчики.

Комментарии