Лекция
Привет, сегодня поговорим про рекурсия, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое рекурсия, стек , настоятельно рекомендую прочитать все из категории Выполнение скриптов на стороне клиента JavaScript, jqvery, JS фреймворки (Frontend).
Есть пара весомых поводов не использовать рекурсию, но это не повод не использовать рекурсию вообще. Программы, во-первых, создаются программистами для программистов, и лишь во-вторых — программистами для компьютеров. В итоге, некоторыми годными программами могут пользоваться неподготовленные люди. рекурсия имеет одно безусловное преимущество перед итерацией — читабельность. Когда программист создает программы для себе подобных, рекурсия имеет право на существование до тех пор, пока не докажет обратного (т.е. — не будет запущена на компьютере и не поперхнется реальными данными).
Вернемся к функциям и изучим их более подробно.
Нашей первой темой будет рекурсия.
Если вы не новичок в программировании, то, возможно, уже знакомы с рекурсией и можете пропустить эту главу.
Рекурсия – это прием программирования, полезный в ситуациях, когда задача может быть естественно разделена на несколько аналогичных, но более простых задач. Или когда задача может быть упрощена до несложных действий плюс простой вариант той же задачи. Или, как мы скоро увидим, для работы с определенными структурами данных.
В процессе выполнения задачи в теле функции могут быть вызваны другие функции для выполнения подзадач. Частный случай подвызова – когда функция вызывает сама себя. Это как раз и называется рекурсией.
В качестве первого примера напишем функцию pow(x, n), которая возводит x в натуральную степень n. Иначе говоря, умножает x на само себя n раз.
pow(2, 2) = 4 pow(2, 3) = 8 pow(2, 4) = 16
Рассмотрим два способа ее реализации.
Итеративный способ: цикл for:
function pow(x, n) {
let result = 1;
// умножаем result на x n раз в цикле
for (let i = 0; i < n; i++) {
result *= x;
}
return result;
}
alert( pow(2, 3) ); // 8
Рекурсивный способ: упрощение задачи и вызов функцией самой себя:
function pow(x, n) {
if (n == 1) {
return x;
} else {
return x * pow(x, n - 1);
}
}
alert( pow(2, 3) ); // 8
Обратите внимание, что рекурсивный вариант отличается принципиально.
Когда функция pow(x, n) вызывается, исполнение делится на две ветви:
if n==1 = x
/
pow(x, n) =
\
else = x * pow(x, n - 1)
Говорят, что функция pow рекурсивно вызывает саму себя до n == 1.
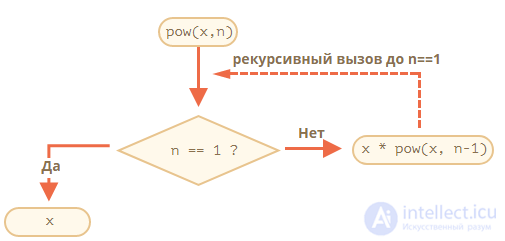
Например, рекурсивный вариант вычисления pow(2, 4) состоит из шагов:
Итак, рекурсию используют, когда вычисление функции можно свести к ее более простому вызову, а его – к еще более простому и так далее, пока значение не станет очевидно.
Рекурсивное решение обычно короче
Рекурсивное решение задачи обычно короче, чем итеративное.
Используя условный оператор ? вместо if, мы можем переписать pow(x, n), делая код функции более лаконичным, но все еще легко читаемым:
function pow(x, n) {
return (n == 1) ? x : (x * pow(x, n - 1));
}
Общее количество вложенных вызовов (включая первый) называют глубиной рекурсии. В нашем случае она будет равна ровно n.
Максимальная глубина рекурсии ограничена движком JavaScript. Точно можно рассчитывать на 10000 вложенных вызовов, некоторые интерпретаторы допускают и больше, но для большинства из них 100000 вызовов – за пределами возможностей. Существуют автоматические оптимизации, помогающие избежать переполнения стек а вызовов («оптимизация хвостовой рекурсии»), но они еще не поддерживаются везде и работают только для простых случаев.
Это ограничивает применение рекурсии, но она все равно широко распространена: для решения большого числа задач рекурсивный способ решения дает более простой код, который легче поддерживать.
Теперь мы посмотрим, как работают рекурсивные вызовы. Для этого заглянем «под капот» функций.
Информация о процессе выполнения запущенной функции хранится в ее контексте выполнения (execution context).
Контекст выполнения – специальная внутренняя структура данных, которая содержит информацию о вызове функции. Она включает в себя конкретное место в коде, на котором находится интерпретатор, локальные переменные функции, значение this (мы не используем его в данном примере) и прочую служебную информацию.
Один вызов функции имеет ровно один контекст выполнения, связанный с ним.
Когда функция производит вложенный вызов, происходит следующее:
Разберемся с контекстами более подробно на примере вызова функции pow(2, 3).
В начале вызова pow(2, 3) контекст выполнения будет хранить переменные: x = 2, n = 3, выполнение находится на первой строке функции.
Можно схематически изобразить это так:
Это только начало выполнения функции. Условие n == 1 ложно, поэтому выполнение идет во вторую ветку if:
function pow(x, n) {
if (n == 1) {
return x;
} else {
return x * pow(x, n - 1);
}
}
alert( pow(2, 3) );
Значения переменных те же самые, но выполнение функции перешло к другой строке, актуальный контекст:
Чтобы вычислить выражение x * pow(x, n - 1), требуется произвести запуск pow с новыми аргументами pow(2, 2).
Для выполнения вложенного вызова JavaScript запоминает текущий контекст выполнения в стеке контекстов выполнения.
Здесь мы вызываем ту же функцию pow, однако это абсолютно неважно. Для любых функций процесс одинаков:
Вид контекста в начале выполнения вложенного вызова pow(2, 2):
Новый контекст выполнения находится на вершине стека (и выделен жирным), а предыдущие запомненные контексты – под ним.
Когда выполнение подвызова закончится, можно будет легко вернуться назад, потому что контекст сохраняет как переменные, так и точное место кода, в котором он остановился. Слово «строка» на рисунках условно, на самом деле запоминается более точное место в цепочке команд.
Процесс повторяется: производится новый вызов в строке 5, теперь с аргументами x=2, n=1.
Создается новый контекст выполнения, предыдущий контекст добавляется в стек:
Теперь в стеке два старых контекста и один текущий для pow(2, 1).
При выполнении pow(2, 1), в отличие от предыдущих запусков, условие n == 1 истинно, поэтому выполняется первая ветка условия if:
function pow(x, n) {
if (n == 1) {
return x;
} else {
return x * pow(x, n - 1);
}
}
Вложенных вызовов больше нет, поэтому функция завершается, возвращая 2.
Когда функция заканчивается, контекст ее выполнения больше не нужен, поэтому он удаляется из памяти, а из стека восстанавливается предыдущий:
Возобновляется обработка вызова pow(2, 2). Имея результат pow(2, 1), он может закончить свою работу x * pow(x, n - 1), вернув 4.
Восстанавливается контекст предыдущего вызова:
Самый внешний вызов заканчивает свою работу, его результат: pow(2, 3) = 8.
Глубина рекурсии в данном случае составила 3.
Как видно из иллюстраций выше, глубина рекурсии равна максимальному числу контекстов, одновременно хранимых в стеке.
Обратим внимание на требования к памяти. Рекурсия приводит к хранению всех данных для неоконченных внешних вызовов в стеке, и в данном случае это приводит к тому, что возведение в степень n хранит в памяти n различных контекстов.
Реализация возведения в степень через цикл гораздо более экономна:
function pow(x, n) {
let result = 1;
for (let i = 0; i < n; i++) {
result *= x;
}
return result;
}
Итеративный вариант функции pow использует один контекст, в котором будут последовательно меняться значения i и result. При этом объем затрачиваемой памяти небольшой, фиксированный и не зависит от n.
Любая рекурсия может быть переделана в цикл. Как правило, вариант с циклом будет эффективнее.
Но переделка рекурсии в цикл может быть нетривиальной, особенно когда в функции в зависимости от условий используются различные рекурсивные подвызовы, результаты которых объединяются, или когда ветвление более сложное. Оптимизация может быть ненужной и совершенно не стоящей усилий.
Часто код с использованием рекурсии более короткий, легкий для понимания и поддержки. Оптимизация требуется не везде, как правило, нам важен хороший код, поэтому она и используется.
Другим отличным применением рекурсии является рекурсивный обход.
Представьте, у нас есть компания. Об этом говорит сайт https://intellect.icu . Структура персонала может быть представлена как объект:
let company = {
sales: [{
name: 'John',
salary: 1000
}, {
name: 'Alice',
salary: 600
}],
development: {
sites: [{
name: 'Peter',
salary: 2000
}, {
name: 'Alex',
salary: 1800
}],
internals: [{
name: 'Jack',
salary: 1300
}]
}
};
Другими словами, в компании есть отделы.
Отдел может состоять из массива работников. Например, в отделе sales работают 2 сотрудника: Джон и Алиса.
Или отдел может быть разделен на подотделы, например, отдел development состоит из подотделов: sites и internals. В каждом подотделе есть свой персонал.
Также возможно, что при росте подотдела он делится на подразделения (или команды).
Например, подотдел sites в будущем может быть разделен на команды siteA и siteB. И потенциально они могут быть разделены еще. Этого нет на картинке, просто нужно иметь это в виду.
Теперь, допустим, нам нужна функция для получения суммы всех зарплат. Как мы можем это сделать?
Итеративный подход не прост, потому что структура довольно сложная. Первая идея заключается в том, чтобы сделать цикл for поверх объекта company с вложенным циклом над отделами 1-го уровня вложенности. Но затем нам нужно больше вложенных циклов для итераций над сотрудниками отделов второго уровня, таких как sites… А затем еще один цикл по отделам 3-го уровня, которые могут появиться в будущем? Если мы поместим в код 3-4 вложенных цикла для обхода одного объекта, то это будет довольно некрасиво.
Давайте попробуем рекурсию.
Как мы видим, когда наша функция получает отдел для подсчета суммы зарплат, есть два возможных случая:
Случай (1), когда мы получили массив, является базой рекурсии, тривиальным случаем.
Случай (2), при получении объекта, является шагом рекурсии. Сложная задача разделяется на подзадачи для подотделов. Они могут, в свою очередь, снова разделиться на подотделы, но рано или поздно это разделение закончится, и решение сведется к случаю (1).
Алгоритм даже проще читается в виде кода:
let company = { // тот же самый объект, сжатый для краткости
sales: [{name: 'John', salary: 1000}, {name: 'Alice', salary: 600 }],
development: {
sites: [{name: 'Peter', salary: 2000}, {name: 'Alex', salary: 1800 }],
internals: [{name: 'Jack', salary: 1300}]
}
};
// Функция для подсчета суммы зарплат
function sumSalaries(department) {
if (Array.isArray(department)) { // случай (1)
return department.reduce((prev, current) => prev + current.salary, 0); // сумма элементов массива
} else { // случай (2)
let sum = 0;
for (let subdep of Object.values(department)) {
sum += sumSalaries(subdep); // рекурсивно вызывается для подотделов, суммируя результаты
}
return sum;
}
}
alert(sumSalaries(company)); // 6700
Код краток и прост для понимания (надеюсь?). В этом сила рекурсии. Она работает на любом уровне вложенности отделов.
Схема вызовов:
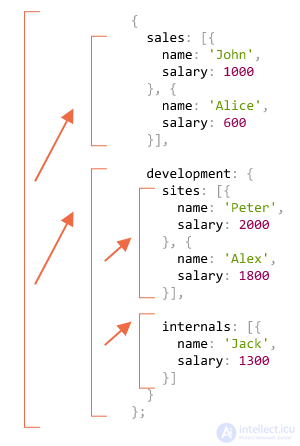
Принцип прост: для объекта {...} используются рекурсивные вызовы, а массивы [...] являются «листьями» дерева рекурсии, они сразу дают результат.
Обратите внимание, что в коде используются возможности, о которых мы говорили ранее:
Рекурсивная (рекурсивно определяемая) структура данных – это структура, которая повторяет саму себя в своих частях.
Мы только что видели это на примере структуры компании выше.
Отдел компании – это:
Для веб-разработчиков существуют гораздо более известные примеры: HTML- и XML-документы.
В HTML-документе HTML-тег может содержать:
Это снова рекурсивное определение.
Для лучшего понимания мы рассмотрим еще одну рекурсивную структуру под названием «связанный список», которая в некоторых случаях может использоваться в качестве альтернативы массиву.
Представьте себе, что мы хотим хранить упорядоченный список объектов.
Естественным выбором будет массив:
let arr = [obj1, obj2, obj3];
…Но у массивов есть недостатки. Операции «удалить элемент» и «вставить элемент» являются дорогостоящими. Например, операция arr.unshift(obj) должна переиндексировать все элементы, чтобы освободить место для нового obj, и, если массив большой, на это потребуется время. То же самое с arr.shift().
Единственные структурные изменения, не требующие массовой переиндексации – это изменения, которые выполняются с конца массива: arr.push/pop. Таким образом, массив может быть довольно медленным для больших очередей, когда нам приходится работать с его началом.
Или же, если нам действительно нужны быстрые вставка/удаление, мы можем выбрать другую структуру данных, называемую связанный список.
Элемент связанного списка определяется рекурсивно как объект с:
Пример:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
Графическое представление списка:

Альтернативный код для создания:
let list = { value: 1 };
list.next = { value: 2 };
list.next.next = { value: 3 };
list.next.next.next = { value: 4 };
Здесь мы можем еще лучше увидеть, что есть несколько объектов, каждый из которых имеет value и next, указывающий на соседа. Переменная list является первым объектом в цепочке, поэтому, следуя по указателям next из нее, мы можем попасть в любой элемент.
Список можно легко разделить на несколько частей и впоследствии объединить обратно:
let secondList = list.next.next; list.next.next = null;

Для объединения:
list.next.next = secondList;
И, конечно, мы можем вставить или удалить элементы из любого места.
Например, для добавления нового элемента нам нужно обновить первый элемент списка:
let list = { value: 1 };
list.next = { value: 2 };
list.next.next = { value: 3 };
list.next.next.next = { value: 4 };
// добавление нового элемента в список
list = { value: "new item", next: list };

Чтобы удалить элемент из середины списка, нужно изменить значение next предыдущего элемента:
list.next = list.next.next;

list.next перепрыгнуло с 1 на значение 2. Значение 1 теперь исключено из цепочки. Если оно не хранится где-нибудь еще, оно будет автоматически удалено из памяти.
В отличие от массивов, нет перенумерации, элементы легко переставляются.
Естественно, списки не всегда лучше массивов. В противном случае все пользовались бы только списками.
Главным недостатком является то, что мы не можем легко получить доступ к элементу по его индексу. В простом массиве: arr[n] является прямой ссылкой. Но в списке мы должны начать с первого элемента и перейти в next N раз, чтобы получить N-й элемент.
…Но нам не всегда нужны такие операции. Например, нам может быть нужна очередь или даже двухсторонняя очередь – это упорядоченная структура, которая позволяет очень быстро добавлять/удалять элементы с обоих концов, но там не нужен доступ в середину.
Списки могут быть улучшены:
Термины:
Рекурсия – это термин в программировании, означающий вызов функцией самой себя. Рекурсивные функции могут быть использованы для элегантного решения определенных задач.
Когда функция вызывает саму себя, это называется шагом рекурсии. База рекурсии – это такие аргументы функции, которые делают задачу настолько простой, что решение не требует дальнейших вложенных вызовов.
Рекурсивно определяемая структура данных – это структура данных, которая может быть определена с использованием самой себя.
Например, связанный список может быть определен как структура данных, состоящая из объекта, содержащего ссылку на список (или null).
list = { value, next -> list }
Деревья, такие как дерево HTML-элементов или дерево отделов из этой главы, также являются рекурсивными: они разветвляются, и каждая ветвь может содержать другие ветви.
Как мы видели в примере sumSalary, рекурсивные функции могут быть использованы для прохода по ним.
Любая рекурсивная функция может быть переписана в итеративную. И это иногда требуется для оптимизации работы. Но для многих задач рекурсивное решение достаточно быстрое и простое в написании и поддержке.
Любая рекурсия может быть переделана в цикл. Как правило, вариант с циклом будет эффективнее.
…Но зачем тогда нужна рекурсия? Да просто затем, что рекурсивный код может быть гораздо проще и понятнее! Переделка в цикл может быть нетривиальной, особенно когда в функции, в зависимости от условий, используются разные рекурсивные подвызовы.
В программировании мы в первую очередь стремимся сделать сложное простым, а повышенная производительность нужна… Лишь там, где она действительно нужна. Поэтому красивое рекурсивное решение во многих случаях лучше.
Недостатки и преимущества рекурсии:
Требования к памяти.
Ограничена максимальная глубина стека.
Краткость и простота кода.
Существуют много областей применения рекурсивных вызовов, в частности — работа со структурами данных, такими как дерево документа.
Вложенные категории или комментарии, обход дерева
Напишите функцию sumTo(n), которая вычисляет сумму чисел 1 + 2 + ... + n.
Например:
sumTo(1) = 1 sumTo(2) = 2 + 1 = 3 sumTo(3) = 3 + 2 + 1 = 6 sumTo(4) = 4 + 3 + 2 + 1 = 10 ... sumTo(100) = 100 + 99 + ... + 2 + 1 = 5050
Сделайте три варианта решения:
Пример работы вашей функции:
function sumTo(n) { /*... ваш код ... */ }
alert( sumTo(100) ); // 5050
P.S. Какой вариант решения самый быстрый? Самый медленный? Почему?
P.P.S. Можно ли при помощи рекурсии посчитать sumTo(100000)?
решение
Решение с помощью цикла:
function sumTo(n) {
let sum = 0;
for (let i = 1; i <= n; i++) {
sum += i;
}
return sum;
}
alert( sumTo(100) );
Решение через рекурсию:
function sumTo(n) {
if (n == 1) return 1;
return n + sumTo(n - 1);
}
alert( sumTo(100) );
Решение по формуле: sumTo(n) = n*(n+1)/2:
function sumTo(n) {
return n * (n + 1) / 2;
}
alert( sumTo(100) );
P.S. Надо ли говорить, что решение по формуле работает быстрее всех? Это очевидно. Оно использует всего три операции для любого n, а цикл и рекурсия требуют как минимум n операций сложения.
Вариант с циклом – второй по скорости. Он быстрее рекурсии, так как операций сложения столько же, но нет дополнительных вычислительных затрат на организацию вложенных вызовов. Поэтому рекурсия в данном случае работает медленнее всех.
P.P.S. Некоторые движки поддерживают оптимизацию «хвостового вызова»: если рекурсивный вызов является самым последним в функции (как в sumTo выше), то внешней функции не нужно будет возобновлять выполнение и не нужно запоминать контекст его выполнения. В итоге требования к памяти снижаются, и сумма sumTo(100000) будет успешно вычислена. Но если JavaScript-движок не поддерживает это (большинство не поддерживают), будет ошибка: максимальный размер стека превышен, так как обычно существует ограничение на максимальный размер стека.
Факториал натурального числа – это число, умноженное на "себя минус один", затем на "себя минус два", и так далее до 1. Факториал n обозначается как n!
Определение факториала можно записать как:
n! = n * (n - 1) * (n - 2) * ...*1
Примеры значений для разных n:
1! = 1 2! = 2 * 1 = 2 3! = 3 * 2 * 1 = 6 4! = 4 * 3 * 2 * 1 = 24 5! = 5 * 4 * 3 * 2 * 1 = 120
Задача – написать функцию factorial(n), которая возвращает n!, используя рекурсию.
alert( factorial(5) ); // 120
P.S. Подсказка: n! можно записать как n * (n-1)! Например: 3! = 3*2! = 3*2*1! = 6
решение
По определению факториал n! можно записать как n * (n-1)!.
Другими словами, factorial(n) можно получить как n умноженное на результат factorial(n-1). И результат для n-1, в свою очередь, может быть вычислен рекурсивно и так далее до 1.
function factorial(n) {
return (n != 1) ? n * factorial(n - 1) : 1;
}
alert( factorial(5) ); // 120
Базисом рекурсии является значение 1. А можно было бы сделать базисом и 0, однако это добавило рекурсии дополнительный шаг:
function factorial(n) {
return n ? n * factorial(n - 1) : 1;
}
alert( factorial(5) ); // 120
Последовательность чисел Фибоначчи определяется формулой Fn = Fn-1 + Fn-2. То есть, следующее число получается как сумма двух предыдущих.
Первые два числа равны 1, затем 2(1+1), затем 3(1+2), 5(2+3) и так далее: 1, 1, 2, 3, 5, 8, 13, 21....
Числа Фибоначчи тесно связаны с золотым сечением и множеством природных явлений вокруг нас.
Напишите функцию fib(n) которая возвращает n-е число Фибоначчи.
Пример работы:
function fib(n) { /* ваш код */ }
alert(fib(3)); // 2
alert(fib(7)); // 13
alert(fib(77)); // 5527939700884757
P.S. Все запуски функций из примера выше должны работать быстро. Вызов fib(77) должен занимать не более доли секунды.
решение
Сначала решим через рекурсию.
Числа Фибоначчи рекурсивны по определению:
function fib(n) {
return n <= 1 ? n : fib(n - 1) + fib(n - 2);
}
alert( fib(3) ); // 2
alert( fib(7) ); // 13
// fib(77); // вычисляется очень долго
При больших значениях n такое решение будет работать очень долго. Например, fib(77) может повесить браузер на некоторое время, съев все ресурсы процессора.
Это потому, что функция порождает обширное дерево вложенных вызовов. При этом ряд значений вычисляется много раз снова и снова.
Например, посмотрим на отрывок вычислений для fib(5):
... fib(5) = fib(4) + fib(3) fib(4) = fib(3) + fib(2) ...
Здесь видно, что значение fib(3) нужно одновременно и для fib(5) и для fib(4). В коде оно будет вычислено два раза, совершенно независимо.
Полное дерево рекурсии:
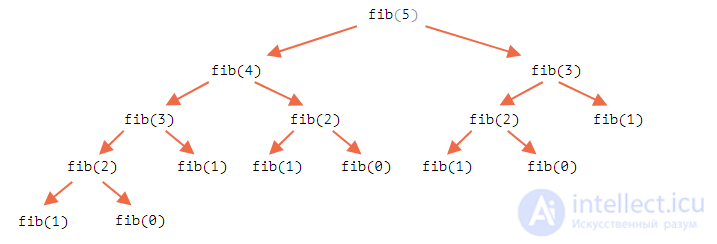
Можно заметить, что fib(3) вычисляется дважды, а fib(2) – трижды. Общее количество вычислений растет намного быстрее, чем n, что делает его огромным даже для n=77.
Можно это оптимизировать, запоминая уже вычисленные значения: если значение, скажем, fib(3) вычислено однажды, затем мы просто переиспользуем это значение для последующих вычислений.
Другим вариантом было бы отказаться от рекурсии и использовать совершенно другой алгоритм на основе цикла.
Вместо того, чтобы начинать с n и вычислять необходимые предыдущие значения, можно написать цикл, который начнет с 1 и 2, затем из них получит fib(3) как их сумму, затем fib(4)как сумму предыдущих значений, затем fib(5) и так далее, до финального результата. На каждом шаге нам нужно помнить только значения двух предыдущих чисел последовательности.
Вот детальные шаги нового алгоритма.
Начало:
// a = fib(1), b = fib(2), эти значения по определению равны 1 let a = 1, b = 1; // получим c = fib(3) как их сумму let c = a + b; /* теперь у нас есть fib(1), fib(2), fib(3) a b c 1, 1, 2 */
Теперь мы хотим получить fib(4) = fib(2) + fib(3).
Переставим переменные: a,b, присвоим значения fib(2),fib(3), тогда c можно получить как их сумму:
a = b; // теперь a = fib(2) b = c; // теперь b = fib(3) c = a + b; // c = fib(4) /* имеем последовательность: a b c 1, 1, 2, 3 */
Следующий шаг дает новое число последовательности:
a = b; // now a = fib(3)
b = c; // now b = fib(4)
c = a + b; // c = fib(5)
/* последовательность теперь (на одно число больше):
a b c
1, 1, 2, 3, 5
*/
…И так далее, пока не получим искомое значение. Это намного быстрее рекурсии и не требует повторных вычислений.
Полный код:
function fib(n) {
let a = 1;
let b = 1;
for (let i = 3; i <= n; i++) {
let c = a + b;
a = b;
b = c;
}
return b;
}
alert( fib(3) ); // 2
alert( fib(7) ); // 13
alert( fib(77) ); // 5527939700884757
Цикл начинается с i=3, потому что первое и второе значения последовательности заданы a=1, b=1.
Такой способ называется динамическое программирование снизу вверх.
важность: 5
Допустим, у нас есть односвязный список (как описано в главе Рекурсия и стек):
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
Напишите функцию printList(list), которая выводит элементы списка по одному.
Сделайте два варианта решения: используя цикл и через рекурсию.
Как лучше: с рекурсией или без?
решение
Решение с использованием цикла
Решение с использованием цикла:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
function printList(list) {
let tmp = list;
while (tmp) {
alert(tmp.value);
tmp = tmp.next;
}
}
printList(list);
Обратите внимание, что мы используем временную переменную tmp для перемещения по списку. Технически, мы могли бы использовать параметр функции list вместо нее:
function printList(list) {
while(list) {
alert(list.value);
list = list.next;
}
}
…Но это было бы неблагоразумно. В будущем нам может понадобиться расширить функцию, сделать что-нибудь еще со списком. Если мы меняем list, то теряем такую возможность.
Говоря о хороших именах для переменных, list здесь – это сам список, его первый элемент. Так и должно быть, это просто и понятно.
С другой стороны, tmp используется исключительно для обхода списка, как i в цикле for.
Решение через рекурсию
Рекурсивный вариант printList(list) следует простой логике: для вывода списка мы должны вывести текущий list, затем сделать то же самое для list.next:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
function printList(list) {
alert(list.value); // выводим текущий элемент
if (list.next) {
printList(list.next); // делаем то же самое для остальной части списка
}
}
printList(list);
Какой способ лучше?
Технически, способ с циклом более эффективный. В обеих реализациях делается то же самое, но для цикла не тратятся ресурсы для вложенных вызовов.
С другой стороны, рекурсивный вариант более короткий и, возможно, более простой для понимания.
Выведите односвязный список из предыдущего задания Вывод односвязного списка в обратном порядке.
Сделайте два решения: с использованием цикла и через рекурсию.
решение
С использованием рекурсии
Рекурсивная логика в этом случае немного сложнее.
Сначала надо вывести оставшуюся часть списка, а затем текущий элемент:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
function printReverseList(list) {
if (list.next) {
printReverseList(list.next);
}
alert(list.value);
}
printReverseList(list);
С использованием цикла
Вариант с использованием цикла сложнее, чем в предыдущей задаче.
Нет способа сразу получить последнее значение в списке list. Мы также не можем «вернуться назад», к предыдущему элементу списка.
Поэтому мы можем сначала перебрать элементы в прямом порядке и запомнить их в массиве, а затем вывести то, что мы запомнили, в обратном порядке:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};
function printReverseList(list) {
let arr = [];
let tmp = list;
while (tmp) {
arr.push(tmp.value);
tmp = tmp.next;
}
for (let i = arr.length - 1; i >= 0; i--) {
alert( arr[i] );
}
}
printReverseList(list);
Обратите внимание, что рекурсивное решение на самом деле делает то же самое: проходит список, запоминает элементы в цепочке вложенных вызовов (в контексте выполнения), а затем выводит их.
Тестирование — это, по сути, создание программ для программ, позволяющее программистам отодвигать порог непреодолимой сложности в разрабатываемых приложениях. Столкнувшись на днях с необходимостью написать юнит-тест для рекурсивного метода я был неприятно удивлен необходимостью мокировать сам тестируемый метод. Альтернатива — создавать такие входные данные, которые бы позволяли протестировать все ветки рекурсии в одном тестовом методе. В перспективе вырисовывалось не снижение сложности, а наоборот — ее увеличение. как же тестировать рекурсивный мето?
Решив, что подготовить тестовые данные для трех проходов по коду — не такая уж непреодолимая сложность, отложил эту задачу до утра. Под катом решение, пришедшее в голову за ночь, позволяющее разбивать тестирование рекурсивных методов на части.
public function foo($arg1, $arg2)
{
//...
$out = $this->foo($in1, $in2);
//...
}
Создаем обертку для метода и делаем так, чтобы сам метод вызывал только обертку, а обертка вызывала метод:
public function foo($arg1, $arg2)
{
//...
$out = $this->fooRecursive($in1, $in2);
//...
}
public function fooRecursive($arg1, $arg2)
{
return $this->foo($arg1, $arg2);
}
public function test_foo()
{
/* create mock for wrapper 'fooRecursive'*/
$obj = \Mockery::mock(\FooClass::class . '[fooRecursive]');
$obj->shouldReceive('fooRecursive')->once()
->andReturn('out');
/* call recursive method 'foo' */
$res = $obj->foo('arg1', 'arg2');
}
Да, решение весьма незамысловатое, но, может кому-нибудь пригодится, и ему удастся потратить свою ночь на что-то более полезное.
К сожалению, в одной статье не просто дать все знания про рекурсия. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое рекурсия, стек и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Выполнение скриптов на стороне клиента JavaScript, jqvery, JS фреймворки (Frontend)

тесты функциональные или модульные?
вообще что модульные что функциональные нужно
1. проверка сознания родительского комментария,
2. проверка удаление родителя (при том определиться что будет с дочерними - удалять рекурсивно)
3. проверка создания дочернего (до какого то уровня)
4. проверка обновления дочернего(на разных уровнях)
и еще что то проверить. причем проверки должны быть как на правильные данные как и на неправильные данные
1) только если это модульные тесты - то тестируется класс
2) если это функциональный текст то тестируется или апи или контроллер
3)если то поведенческие тесты то тестируется прямо нажатие кнопок добавления удаления прямо в браузере автотестами
вот реальный пример модульных тестов для проверки рекурсивных категорий или коментов
https://github.com/lazychaser/laravel-nestedset/tree/v5/tests
это уже готовый вендор для вложенных категории или Комментов (но в папке автотесты есть реальные юниттесты) посмотри что проверяли. там вроде 2 файла с несколькими метода, не идеал.. но вендор очень часто используемый

Комментарии