Лекция
Привет, Вы узнаете о том , что такое инвертированный индекс, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое инвертированный индекс, расстояние левенштейна, расстояние редактирования, редакционным расстоянием, soundex, metaphone, стемминг, stemming, лемматизация, субстантивация, анализ данных, индексирование данных, обработка запроса , поиск текста, обработка текста, частота термина , документная частота, обратная документная частота , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
анализ данных , индексирование данных и обработка запроса
Перед индексацией необходимо выполнить - через Индексатор - Кэширование,Нормализацию, оработку Сниппетов, Поиск, обработку Недоступных страниц
Индексирование можно выонить с использованием
N-грамма
Алгоритм Nagao 94 для текстов на японском
Алгоритм Лемпеля — Зива — Велча
Суффиксный массив
Суффиксное дерево
инвертированный индекс
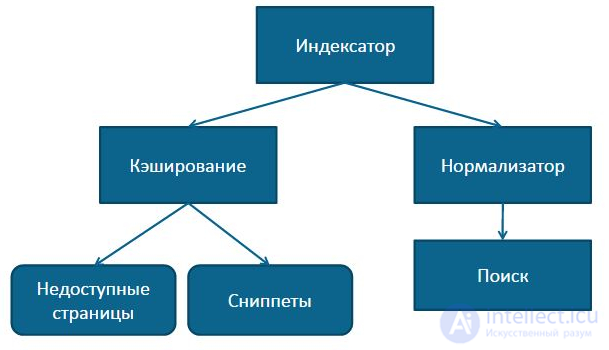
Нормализатор – часть индексатора, преобразующая документ в вид удобный для последующего поиска
Задача нормализатора: перевести неструктурированную информацию в структурированную
Удобный вид Нужно узнать, в каких документах встречается запрашиваемое слово
Варианты решения:
Инвертированный индекс (англ. inverted index) — структура данных, в которой для каждого слова коллекции документов в соответствующем списке перечислены все документы в коллекции, в которых оно встретилось. Инвертированный индекс используется для поиска по текстам.
Есть два варианта инвертированного индекса:
В списке вхождений слова в документы, помимо id документов, обычно также указываются факторы (TF-IDF, бинарный фактор: «попало слово в заголовок или не попало», другие факторы), которые используются при ранжировании. Индекс может строиться не по всем словоформам, а по леммам (по каноническим формам слов). Стоп-слова можно исключить и не строить для них индекс, считая, что каждое из них встречается почти во всех документах корпуса. Для ускорения вычисления пересечений используют эвристику skip-pointer-ов. При обработке запросов, содержащих много слов, используют функцию кворума, которая пропускает на следующую стадию ранжирования часть документов, в которых встретились не все слова из запроса.
Пример Инвертированного индекса, запроса и резуьтата
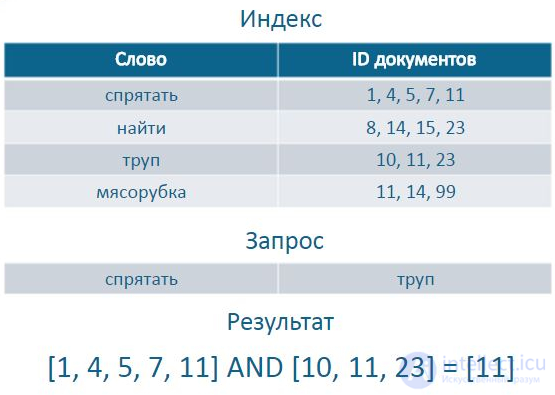
Часто важно, чтобы искомые слова шли подряд.
Нужно учитывать позиции слов.
Пример: «Варенье лучше прятать от солнечного света… … … … … Банка была холодная как труп.»
Пример индексов словопозиций
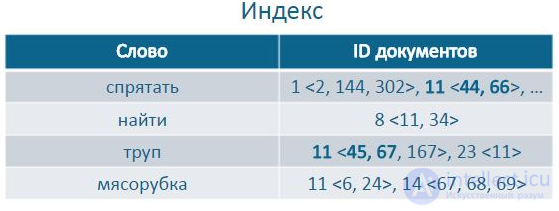
Чем ближе слова друг к другу, тем релевантнее в итоге документ
Разбиение страницы на зоны
O`Neill
aren`t
Некоторые «слова» выглядят необычно
Разбираются по отдельным правилам, паттернам
Некоторые слова нужно правильно разделить
Решение: составление статистики устойчивости употребления слов
Термин – класс эквивалентных слов, имеющих несущественные отличия (в окончаниях, префиксах и т.д.)
[прячу, спрятанный, припрятал] = спрятать
некторые разные слова могут иметь одно и тоже понятие или близкое, но написание их асолютно разное
для этого используется синонимический индекс
стемминг (stemming) – последовательное удаление незначащих частей слов
лемматизация – морфологический разбор слова, приведение к нормальной форме
Стеммер Портера
5 шагов, на каждом применяется правило удаления окончания
Первый шаг:

Плюс: быстрое получение термина
Минус: для многих языков термин плохо воспринимается человеком
Стемминг (stemming)- отсечение от слова окончаний и суффиксов, чтобы оставшаяся часть, называемая stem, была одинаковой для всех грамматических форм слова. Разумеется в таком виде стеммер может работать только с языками, которые реализуют словоизменение через аффиксы. Примерами таких языков являются русский и английский.
Обычно стеммером пользуются для поиска текста с имитацией учета морфологии. Под имитацией подразумевается неустранимо большое количество ошибок и нерелевантных результатов, которые возникают, если применять только стеммер. В русском языке источником ошибок при стемминге являются всевозможные изменения корня слова - беглые гласные, к примеру. Наглядно проблемы, связанные с использованием стеммера, можно продемонстрировать для русского существительного кошка. Родительный падеж множественного числа имеет форму кошек. Таким образом, самый длинный общий префикс всех форм существительного кошка - это кош. Если выполнить поиск текста по этому префиксу, то в результатах с большой вероятностью будут такие слова, как кошмар. Замечу, что обычно реализации стеммера идут немного другим путем и допускают ошибку иного рода - они возвращают при стемминге префикс кошк и таким образом из результатов поиска исчезают фрагменты текста с формой кошек.
В качестве решения проблемы плохих результатов поиска со стеммером для русского языка можно использовать два дополнительных модуля грамматического словаря - лемматизатор и флексер (склонение и спряжение). С помощью лемматизатора можно приводить слова к базовой форме, поэтому после сопоставления слова со стемом можно уточнить результат с помощью лемматизации. Второй модуль - флексер, который умеет выдавать все грамматические формы слова на основе базовой. Это позволяет уточнять результаты поиска, проверяя найденные фрагменты по набору форм ключевого слова.
Допускаемые при стемминге ошибки можно классифицировать следующим образом.
Ошибки стемминга 1го рода - стем дает слишком большое обобщение и поэтому сопоставляется с грамматическими формами более чем одной словарной статьи. Это самая многочисленная группа ошибок стемминга. К примеру, если при стемминг вами даст вам, то в дальнейшем поиск текста даст совпадение с вампир. В русском языке мжет быть весьма трудно полностью устранить данные ошибки, к примеру глагол пасть при спряжении дает формы пади и пал, в результате стемминг дает па, и это очень большое расширение при поиске. Впрочем, ошибки такого типа могут рассматриваться и как способ включить в поиск однокрненные слова - в примере с кошкой это могут быть формы прилагательного кошачий. Компенсация ошибок первого рода успешно выполняется либо введением списка стоп-слов, либо более качественно - лемматизатором или флексером.
Ошибки стемминга 2го рода - усечение формы дает слишком длинный стем, которые не сопоставляется с некоторыми грамматическими формами этого же слова. Об этом говорит сайт https://intellect.icu . К таким ошибкам приводит стремление разработчика стеммера найти компромисс с ошибками 1го рода в случае, когда при словоизменении меняется основа слова. Такие слова есть даже в крайне регулярном в плане словоизменения английском языке, например - группа неправильных глаголов. В русском случаи изменения основы даже не являются основанием для отнесения слова к группе неправильных, настолько часто это явление. В качестве примера, на котором обычно спотыкаются многие реализации стеммера, можно взять слова кошка и пачка, которые имеют формы кошек и пачек. Обычно стеммеры выполняют в этих случаях усечение до кошк и птичк, которые несопоставимы с формами родительного и винительного падежа множественного числа.
Ошибки стемминга 3го рода - стем построить невозможно из-за изменения в корне слова, которое оставляет единственную букву в стеме. Либо модель словоизменения подразумевает использование приставок. Пример для первого случая - глагол впиться, имеющий форму вопьемся. Второй случай возникает в рамках грамматического словаря для сравнительной степени прилагательных и наречий в русском языке - например покрасивее как форма прилагательного красивый, или помедленнее как форма наречия медленно.
Лемматизатор - Разбор слова по составу: (как в школе по частям слова(приставка,корень,суффикс, окончание), только автоматически)
Крупнейший лемматизатор русского языка: AOT.ru (py_morphy, PHPMorphy, …)
Плюсы: получение термина в нормально форме, воспринимаемой человеком
Минусы: долго работает
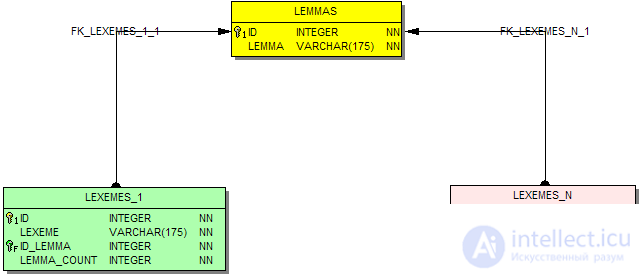
В составе схемы SQL словаря есть отдельные таблицы, разработанные исключительно для выполнения лемматизации:
LEXEMES_1 пары слово-лемма, а также дополнительное поле - количество альтернативных нормальных форм.
LEXEMES_N пары слово-лемма, в отличие от предыдущей таблицы может быть несколько записей для каждого слова.
LEMMAS - вспомогательная таблица, список нормальных форм, на которые ссылаются LEXEMES_1 и LEXEMES_N.
С помощью такого запроса к базе данных
SELECT lemma_COUNT, COUNT(*) FROM lexemes_1 GROUP BY lemma_COUNT
можно определить, насколько велик в естественном языке процент слов, которые дают неоднозначную лемматизацию, например для русского языка:
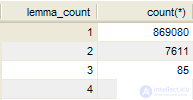
Таким образом, примерно 1% слов русского языка могут доставить некоторые трудности при приведении к нормальной грамматической форме. Следует учесть, что данное распределение не берет в расчет частоту употребления соответствующих слов.
К примеру, такой запрос к базе данных словаря
SELECT lexeme, lemma FROM lexemes_n, lemmas WHERE lemmas.id=id_lemma AND lexemes_n.lexeme='РОЙ'
даст такие варианты лемматизации:
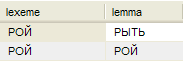
Вполне ожидаемый результат - повелительная форма глагола рыть и две падежные формы существительного рой текстуально совпадают.
Выбор между быстрой, но иногда неполной лемматизацией, и медленной и исчерпывающей, зависит от решаемой задачи.
Например, в поисковой системе скорость индексирования играет решающую роль, так как лемматизация миллионов лексем становится основным занятием процессора. Поэтому индексатор с командой -index wordforms использует упрощенную лемматизацию - берет первую нормальную форму, игнорируя остальные варианты.
С другой стороны машинный переводчик должен максимально аккуратно учитывать все возможные нормальные формы переводимых слов, поэтому скорость лемматизации приносится в жертву точности.
В API есть несколько вызовов, которые позволяют прямо или с дополнительными шагами выполнять приведение слова к базовой форме - лемматизацию. Большинство из них одинаково успешно работают с любым из поддерживаемых в проекте языков, разумеется при наличии соответствующего словаря.
Два основных вызова, разработанных именно как лемматизаторы:
sol_TranslateToBase
Упрощенный, но самый быстрый вариант. Ищет единственную нормальную форму слова. Если слово может быть приведено к нескольким базовым формам, например для мою могут быть варианты мыть и мой, то используется одна любая из альтернатив на усмотрение лемматизатора.
sol_TranslateToBases
Более сложный и медленный вариант предыдущей процедуры. Если поданное на вход слово можно лемматизировать более чем единственным способом, то возвращает все варианты.
Пример использования обеих процедур можно найти в исходных текстах демо-программы ...\demo\ai\solarix\Grammar_Engine\Lemmatizer_Russian.
Далее описаны другие процедуры API, которые решают эту же или близкую задачу.
sol_SeekWord
Это быстрый поиск id словарной статьи по любой грамматической форме. Как и sol_TranslateToBase, берется первый вариант базовой формы, если есть альтернативы. Возвращается целое число - ключ словарной статьи, которое можно использовать для таким операций, как получение названия статьи, склонения и спряжения, определения грамматических свойств слова.
sol_FindWord
Медленный вариант поиск словарной статьи по любой грамматической форме.
sol_ProjectWord
Поиск всех возможных словарных статей, чьей грамматической формой является слово. Процедура вернет список, элементы которого позволяют получить целочисленный id подходящих словарных статей. Особенность данной процедуры в том, что ее алгоритм может для неизвестного слова попытаться подобрать статью и приставку-суффикс, чтобы найти статью-оригинал. Например, для суперкот будет найдена словарная статья кот, так как продуктивная приставка супер- включена в число проверяемых.
sol_ProjectMisspelledWord
Расширенный вариант предыдущей процедуры, позволяет искать словарные статьи по форме с возможными опечатками - пропусками букв, заменами, лишними буквами.
В некоторых приложениях бывает полезно не просто лемматизировать слово, а получать по возможности существительное, от которого получено слово, например страшный - страх. В составе API есть соответствующий вызов:
sol_TranslateToNoun
В схеме SQL словаря есть несколько таблиц, которые можно создавать и использовать автономно, позволяющих выполнять поиск базовых форм слов.
Для русского языка, как уже отмечалось в описании процедуры лемматизации через API грамматического словаря, главная проблема - наличие неоднозначностей.
С помощью несложного запроса можно увидеть, что всего в русском лексиконе имеется чуть больше 400 пар существительное-глагол, у которых хотя бы одна грамматическая форма омонимична.
Этот запрос к базе данных словаря:
SELECT DISTINCT E1.name AS "сущ", E2.name AS "глаг", F2.name AS "форма"
FROM sg_form F1, sg_form F2, sg_entry E1, sg_entry E2
WHERE E1.id_class=8 AND -- русские существительные
F1.id_entry=E1.id AND -- их грамматические формы
F2.name=F1.name AND -- формы совпадают
E2.id=F2.id_entry AND E2.id_class IN (13,14) -- русские глаголы и инфинитивы
дает примерно такую таблицу (показано несколько записей):
| сущ | глаг | форма |
|---|---|---|
| явь | явить | яви |
| штурман | штурмануть | штурману |
| шлем | слать | шлем |
| шило | шить | шило |
| шило | шить | шила |
| шило | шить | шил |
| шея | шить | шей |
| шаль | шалить | шали |
| чертенок | чертить | чертят |
Теперь рассмотрим, как получить базовую форму слова по любой грамматической.
Запрос к базе словаря очень простой:
SELECT DISTINCT Lower(sg_class.name), sg_entry.name
FROM sg_form, sg_entry, sg_class
WHERE sg_form.name='пни' AND
sg_entry.id=sg_form.id_entry AND
sg_class.id=sg_entry.id_class -- покажем часть речи
Обратите внимание, что мы никак не фиксируем язык обрабатываемых слов.
Результат вышеприведенного запроса, в котором ищутся базовые формы для слова пни, такой:

Стеммер - это упрощенный алгоритм морфологического разбора слова, оптимизированный под максимально быстрое нахождение префикса, общего для всех грамматических форм заданного слова. Обычно получамая при стемминге основа включает в себя морфологический корень, вместе с приставкой. У стеммера всегда есть некоторый процент ошибок, проистекающих из особенностей словоизменения естественного языка и невозможности согласовать примитивную идею отсечения "окончаний" со русским словоизменением, а тем более с такими языковыми явлениями, как беглые гласные. В русском лексиконе примерно 1.7% словоформ имеют такую особенность, например мешок-мешки, взять-возьму. Даже такой регулярный язык, как английский, имеет обширный набор исключений из регулярных правил - неправильные глаголы исуществительные, склоняющиеся не по общему правилу.
Несомненный плюс стеммера - возможность реализации без использования внешней базы данных. К примеру, программная реализация алгоритма стемминга для платформы .NET компилируется как единственная dll без дополнительных зависимостей и файлов данных. Для ее использования достаточно включить сборку StemmerFX.dll в проект - смотрите online пример.
С другой стороны, словарный лемматизатор, имеющийся в грамматическом словаре, позволяет с намного более высокой точностью находить базовую форму слова из любой грамматической. Из общих соображений понятно, что если сравнивать результат лемматизации искомого ключевого слова и слов, читаемых из текста, то мы получим как раз поиск текста с учетом морфологии. Однако операция лемматизации выполняется медленее, чем стемминг, поэтому возникает идея объединить оба этих алгоритма для быстрого и релевантного поиска ключевых слов. Такой подход реализован в библиотеке StringLib для платформы .NET. Она позволяет выполнять поиск ключевого слова, находя все вхождения любой его грамматической формы.
Как уже отмечалось выше, база данных правил лемматизации генерируется автоматически компилятором словаря на основе загруженных в лексикон словарных статей и их грамматических форм. Генератор построен с максимально широкими допущениями на лексический состав словаря, поэтому вполне реально получить модуль, возвращающий лемму и для русских, и для английских слов.
Наличие тезауруса, ориентированного на машинную обработку текста, позволяет реализовывать более сложные преобразования слов. К примеру, вместо простой лемматизации можно одним запросом возвращать базовую форму существительного, к которому приводится словарная статья. Например, прилагательное кошачий является деривативом от существительного кошка. Можно приводить не только к форме существительного, но и к форме инфинитива, например причастие бегающий приводится к инфинитиву бегать. Более того, инфинитив бегать связан с существительным бег. Все эти связи, образующие сложную семантическую сеть, доступны для SQL запросов, пример одного из которых показан далее.
Итак, мы имеем несколько слов, принадлежащих к разным частям речи. Нам нужно для каждого из них выполнить лемматизацию, а затем по возможности найти форму существительного. Обратите внимание, что результат лемматизации может не допускать приведения к существительному - в этом случае мы вернем простую лемматизацию.
В справочнике типов связей можно найти числовой код нужного нам типа в_сущ=39.
Составляем запрос к базе словаря:
SELECT DISTINCT COALESCE( E2.name, E1.name )
FROM sg_form, sg_entry E1 LEFT JOIN sg_link ON id_entry1=E1.id
AND istate=39 -- тип связи <в_сущ>
LEFT JOIN sg_entry E2 ON E2.id=id_entry2
WHERE sg_form.name IN ( 'сияющими', 'звенело', 'по-кошачьи' )
AND E1.id=sg_form.id_entry
Результат его исполнения:

Лемматизатор может использоваться как автономно, так и загружаться в составе грамматического словаря. Параметры подключения и работы лемматизатора в этих случаях задаются в файле конфигурации словаряв отдельном XML-узле - см. здесь.
Кроме специализированного лемматизатора, описанного выше, нормализация текста может быть выполнена другими способами. Отметим из них два самых интересных.
Морфологический анализатор неявно дает на выходе информацию о леммах, так как он распознает для каждого исходного слова принадлежность к определенной словарной статье. У словарной статьи можно получить начальную форму слова, и таким образом решить задачу. Побочным эффектом такого алгоритма будет учет контекста слова и отбрасывание альтернативных вариантов распознавания.
Можно пойти дальше, и учесть информацию из тезауруса. Взяв результаты морфологического анализа предложения, можно для каждого слова проверить, не является ли оно уменьшительной (котик) или усилительной (котище) формой слова, и привести к нейтральной (кот). Более того, можно воспользоваться информацией о дериватах, к примеру выполнить приведение глаголов, деепричастий и причастий к форме абстрактного существительного движения или действия: изменять-изменение.
Далее представлено наглядное сравнение всех имеющихся видов лемматизации текста для одного и того же предложения.
Простая лемматизация:

Приведение к леммам как результат морфологического разбора предложения:

Глубокая нормализация текста с приведением к существительным с помощью тезауруса:

Стоп-слово – слово, которое встречается во многих текстах, но никак текст не характеризует
Примеры: союзы, междометия
Запрос: «что делать с трупом он плохо пахнет»

Во время нормализации можно пытаться определить не только термины документа, но и их значимость для него
Примеры:
Документная частота – сколько документов содержат данный термин.
Определяет насколько термин важен вообще.
Отношение количества документов с термином ко всему количеству документов:
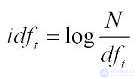
Как ведет себя эта функция?
Что может происходить с ростом N?
Частота термина в документе (term frequency) – отношение количества вхождений термина ко всем терминам.
Определяет, насколько важен термин для данного документа
Что делать с документом, в котором 20 повторений термина из 100 слов?
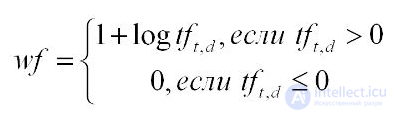
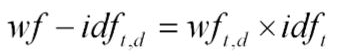
Поведение:
Итоговый вид нормализованного документа
Векторная модель документа (VSM) – каждый термин является вектором,
направление вектора – термин
длина вектора - вес

Запрос нужно привести к тому же виду, что и проиндексированные страницы (перевести в термины)
Так как запрос значительно меньше текстов документа, можно и нужно применять более сложный анализ
расстояние редактирования ( редакционным расстоянием ) – для случая, когда палец попал на неправильную кнопку или есть 1-2 орфографических ошибок
Фонетические исправления – для случая, когда человек не знает, как пишется слово, но знает, как оно звучит (пример: фр. oiseaux) (soundex,metaphone)
Аналогом функции soundex() является функция metaphone(). Считается, что функция metaphone() дает более точные результаты.
Расстояние редактирования – количество простых операций для превращения одной строки в другую
Простые операции:
Кодируем слово в индекс Soundex(metaphone). Созвучные слова имеют одинаковый индекс.
Пример Soundex индекса: R163: Rupert, Robert
Для русского языка Soundex не доработан. Можно переводить слово в транслит и пользоваться английским
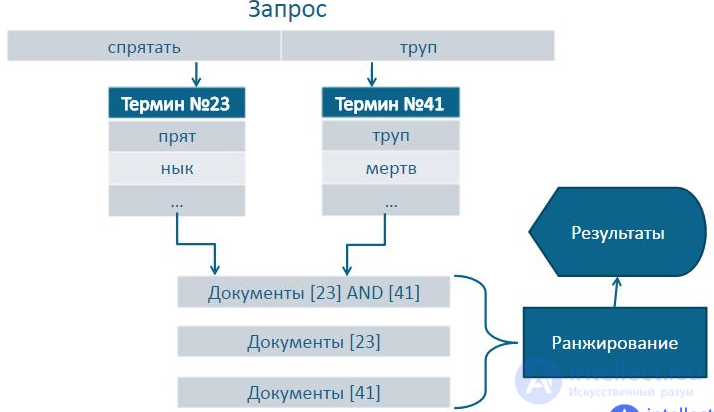
soundex
metaphone
поисковая система
N-грамма
Алгоритм Nagao 94 для текстов на японском
Алгоритм Лемпеля — Зива — Велча
Суффиксный массив
Выводы из данной статьи про инвертированный индекс указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое инвертированный индекс, расстояние левенштейна, расстояние редактирования, редакционным расстоянием, soundex, metaphone, стемминг, stemming, лемматизация, субстантивация, анализ данных, индексирование данных, обработка запроса , поиск текста, обработка текста, частота термина , документная частота, обратная документная частота и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка

Комментарии