Лекция
Привет, Вы узнаете о том , что такое машинный перевод, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое машинный перевод, гибридный перевод, нейронный перевод, статистический перевод, синхронный перевод , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
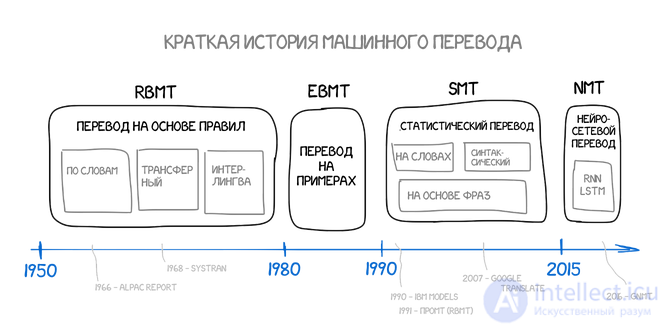
машинный перевод — процесс перевода текстов (письменных, а в идеале и устных) с одного естественного языка на другой с помощью специальной компьютерной программы. Так же называется направление научных исследований, связанных с построением подобных систем.
Мысль использовать ЭВМ для перевода была высказана в 1947 году в США, сразу после появления первых ЭВМ. Первая публичная демонстрация машинного перевода (так называемый Джорджтаунский эксперимент) состоялась в 1954 году. Несмотря на примитивность той системы (словарь в 250 слов, грамматика из 6 правил, перевод нескольких простых фраз), этот эксперимент получил широкий резонанс: начались исследования в Англии, Болгарии, ГДР, Италии, Китае, Франции, ФРГ, Японии и других странах; в том же 1954 году и в СССР.
К середине 1960-х в США для практического использования были предоставлены две системы русско-английского перевода:
Однако созданная для оценки подобных систем комиссия ALPAC[en] пришла к выводу, что в силу низкого качества машинно переведенных текстов эта деятельность в условиях США нерентабельна. Хотя комиссия рекомендовала продолжать и углублять теоретические разработки, в целом ее выводы привели к росту пессимизма, снижению финансирования, часто к полному прекращению работ по этой тематике.
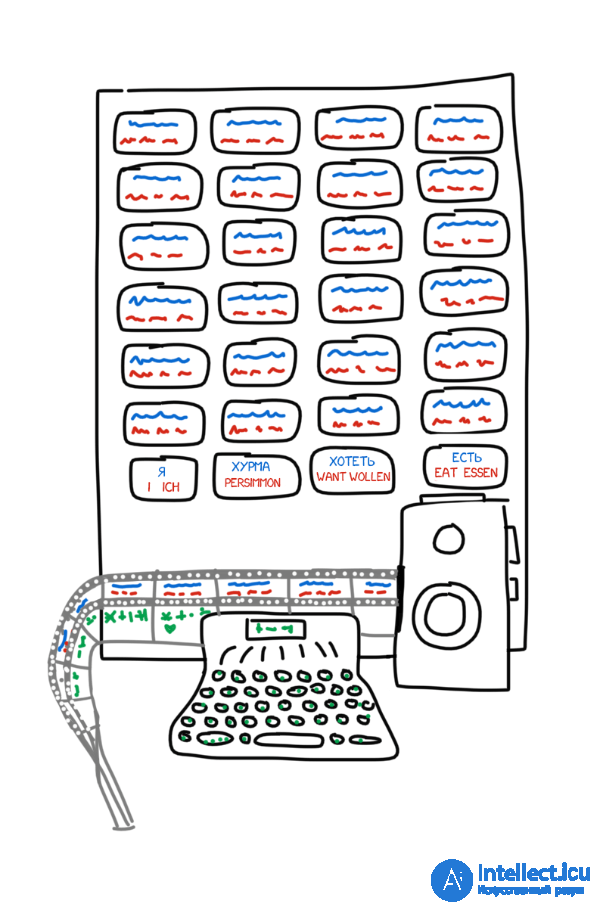
Машина Троянского (Иллюстрация по описаниям. )
«машиной для подбора и печатания слов при переводе с одного языка на другой». Машина была крайне проста: большой стол, печатная машинка с лентой и пленочный фотоаппарат. На столе лежали карточки со словами и их переводами на четырех языках.
Оператор брал первое слово из текста, находил с ним карточку, фотографировал ее, а на печатной машинке набирал его морфологическую информацию — «существительное, множественное число, родительный падеж». Ее клавиши были модифицированы для удобства, каждая однозначно кодировала одно из свойств. Лента печатной машинки и пленка камеры подавались параллельно, на выходе формируя набор кадров со словами и их морфологией:
Полученная лента отдавалась знающим конкретные языки лингвистам, которые превращали набор фотографий в связный литературный текст. Получается, чтобы переводить тексты как оператору, так и лингвистам требовалось знать только свой родной язык. Машина Троянского впервые на практике реализовала тот самый «промежуточный язык» (interlingua), о создании которого мечтали еще Лейбниц и Декарт.
Тем не менее, в ряде стран исследования продолжались, чему способствовал постоянный прогресс вычислительной техники. Особенно существенным фактором стало появление мини- и персональных компьютеров, а с ними все более сложных словарных, поисковых и т. п. систем, ориентированных на работу с естественно-языковыми данными. Росла и необходимость в переводе как таковом ввиду роста международных связей. Все это привело к новому подъему этой области, наступившему примерно с середины 1970-х. В 1980-е наступило время широкого практического использования переводческих систем, сложился рынок коммерческих разработок по этой теме.
Впрочем, мечты, с которыми человечество полвека назад взялось за задачу машинного перевода, в значительной мере остаются мечтами: высококачественный перевод текстов широкой тематики по-прежнему недостижим. Однако несомненным является ускорение работы переводчика при использовании систем машинного перевода: по оценкам конца 1980-х, до пяти раз.
В настоящее время существует множество коммерческих проектов машинного перевода. Одним из пионеров в области машинного перевода была компания SYSTRAN[en]. В России большой вклад в развитие машинного перевода внесла группа под руководством проф. Р. Г. Пиотровского (Российский государственный педагогический университет имени А. И. Герцена, Санкт-Петербург).
В 1960-х годах Станислав Лем обобщал высказывания о проблеме машинного перевода и связи с пониманием текста самой машиной (что связано, например, с обсуждением сформулированной в 1980 году концепции «китайской комнаты»):
| ... мы настаиваем на наделении машин-переводчиков «полнотой внутренней жизни» человека; однако мы просто не знаем, в какой мере можно «недодать личность» машине, которая призвана хорошо переводить. Мы не знаем, можно ли «понимать», не обладая «личностью» хотя бы в зачатке. <…> Не представляется возможным эффективно использовать операциональный язык до конца в качестве орудия перевода в сфере языков дискурсивных — мыслительных. Либо машины будут действовать «понимающе», либо по-настоящему эффективных машин-переводчиков не будет вовсе . |  |
Качество перевода зависит от тематики и стиля исходного текста, а также грамматической, синтаксической и лексической родственности языков, между которыми производится перевод. Машинный перевод художественных текстов практически всегда оказывается неудовлетворительного качества. Тем не менее для технических документов при наличии специализированных машинных словарей и некоторой настройке системы на особенности того или иного типа текстов возможно получение перевода приемлемого качества, который нуждается лишь в небольшой редакторской корректировке. Чем более формализован стиль исходного документа, тем большего качества перевода можно ожидать. Самых лучших результатов при использовании машинного перевода можно достичь для текстов, написанных в техническом (различные описания и руководства) и официально-деловом стиле.
Применение машинного перевода без настройки на тематику (или с намеренно неверной настройкой) служит предметом многочисленных бытующих в Интернете шуток. Из старых и наиболее популярных примеров таких шуток наиболее известен текст перевода документации к драйверу мыши, известный как «Гуртовщики Мыши», заявленный как «перевод компьютерной документации системой машинного перевода Poliglossum на основе медицинского, коммерческого и юридического словарей»[комм. 1]. Из кратких — фраза «Our cat gave birth to three kittens — two whites and one black», которую онлайн-переводчик «ПРОМТ» (версия 7.0, 2007) превращал в «Наш кот родил трех котят — двух белых и одного афроамериканца». Если «афроамериканца» еще можно было сделать «черным», написав «black kitten», то «коту» так и не получалось сменить пол: например, female cat переводился как «самка кот».
Чаще всего подобные шутки связаны с тем, что программа не распознает контекст фразы и переводит термины дословно, к тому же не отличая собственных имен от обычных слов. Тот же переводчик ПРОМТ превращал «Лев Толстой» в «Lion Thick» («толстый лев»), «bra-ket notation» в «примечание Кети лифчика», «Lie algebra» — в «алгебру Лжи», «eccentricity vector» — в «вектор оригинальности», «Shawnee Smith» в «индеец племени шони Смит» и т. п. Переводчик Google, наоборот, слово «rice» часто принимал за фамилию госсекретаря США.
Таким образом существуют следущие виды переводов с использованием компьютеров
Вместо «машинный» иногда употребляется слово автоматический, что не влияет на смысл. Однако термин автоматизированный перевод имеет совсем другое значение — при нем программа просто помогает человеку переводить тексты.
Автоматизированный перевод предполагает такие формы взаимодействия:
В англоязычной терминологии также различаются термины англ. machine translation, MT (полностью автоматический перевод) и англ. machine-aided или англ. machine-assisted translation (MAT) (автоматизированный); если же надо обозначить и то, и другое, пишут M(A)T.
Существуют несколько принципиально разных подходов к построению алгоритмов машинного перевода: основанный на правилах (rule-based), статистический, или основанный на статистике (statistical-based), нейронный машинный перевод (neural machine translation, NMT). Первый подход является традиционным и используется большинством разработчиков систем машинного перевода (ПРОМТ в России, SYSTRAN во Франции, Linguatec в Германии и др.) Ко второму типу относится популярный сервис Яндекс.Переводчик, Переводчик Google, а также новый сервис от ABBYY . Сейчас большинство систем являются гибридными — сочетая правила, статистику и нейронные сети.
Статистический машинный перевод — это разновидность машинного перевода текста, основанная на сравнении больших объемов языковых пар. Языковые пары — тексты, содержащие предложения на одном языке и соответствующие им предложения на втором, могут быть как вариантами написания двух предложений человеком — носителем двух языков, так и набором предложений и их переводов, выполненных человеком. Таким образом статистический машинный перевод обладает свойством «самообучения». Чем больше в распоряжении имеется языковых пар и чем точнее они соответствуют друг другу, тем лучше результат статистического машинного перевода. Под понятием «статистического машинного перевода» подразумевается общий подход к решению проблемы перевода, который основан на поиске наиболее вероятного перевода предложения с использованием данных, полученных из двуязычной совокупности текстов. В качестве примера двуязычной совокупности текстов можно назвать парламентские отчеты, которые представляют собой протоколы дебатов в парламенте. Двуязычные парламентские отчеты издаются в Канаде, Гонконге и других странах; официальные документы Европейского экономического сообщества издаются на 11 языках; а Организация объединенных наций публикует документы на нескольких языках. Как оказалось, эти материалы представляют собой бесценные ресурсы для статистического машинного перевода.
Нейронный машинный перевод (англ. Neural Machine Translation, NMT) — это подход к машинному переводу, в котором используется большая искусственная нейронная сеть. Он отличается от методов машинного перевода, основанных на статистике фраз, которые используют отдельно разработанные подкомпоненты .
Сервисы перевода компаний Google, Яндекс, Microsoft и PROMT уже используют нейронный перевод . Google использует нейронный машинный перевод Google (GNMT) вместо ранее используемых статистических методов. Майкрософт использует похожую технологию для перевода речи (в том числе в Майкрософт Переводчике и Skype Переводчике). Гарвардской группой по обработке естественного языка была выпущена OpenNMT, система нейронного машинного перевода с открытым исходным кодом . Яндекс.Переводчик имеет гибридную модель: свой вариант перевода предлагает и статистическая модель, и нейросеть. После этого технология CatBoost, в основе которой лежит машинное обучение, будет выбирать лучший из полученных результатов .
Модели NMT используют глубинное обучение и обучение признакам. Для их работы требуется лишь малая часть памяти по сравнению с традиционными системами статистического машинного перевода (SMT). Кроме того, в отличие от традиционных систем перевода, все части модели нейронного перевода обучаются совместно (от начала до конца), чтобы максимизировать эффективность перевода .
Двунаправленная рекуррентная нейронная сеть (RNN), также известная как кодировщик, используется нейронной сетью для кодирования исходного предложения для второй рекуррентной сети, также известной как декодировщик, которая используется для предсказания слов в конечном языке
Машинный перевод на основе правил (Rule-Based Machine Translation) — общий термин, который обозначает системы машинного перевода на основе лингвистической информации об исходном и переводном языках . Они состоят из двуязычных словарей и грамматик, охватывающих основные семантические, морфологические, синтаксические закономерности каждого языка. Такой подход к машинному переводу еще называют классическим. На основе этих данных исходный текст последовательно, по предложениям, преобразуется в текст перевода. Эти системы противопоставляют системам машинного перевода, которые основаны на примерах. Принцип работы таких систем — связь структуры входного и выходного предложения.
RBMT системы делятся на три группы:
Основным достоинством систем на основе трансфера является высокая полнота охвата текстов при приемлемом уровне качества перевода, а также низкий уровень затрат на первичную разработку и модернизацию.
Компоненты типичной RBMT:
Особенности RBMT систем:
Машинный перевод на основе примеров (англ. Example-based machine translation, EBMT) — это метод машинного перевода, который часто характеризуется использованием двуязычного корпуса с параллельными текстами в качестве основной базы знаний во время выполнения перевода. По сути, это перевод по аналогии, который может рассматриваться как применение метода рассуждений на основе прецедентов к машинному обучению.
В основе машинного перевода на примерах лежит идея перевода по аналогии. Применительно к процессу перевода человеком, мысль о том, что перевод выполняется по аналогии, является отказом от идеи, что люди переводят предложения, делая глубокий лингвистический анализ. Вместо этого, данная мысль основана на убеждении, что люди переводят, сначала разбирая предложения на определенные фразы, затем переводят эти фразы, и, наконец, правильно составляют эти фрагменты в одно длинное предложение. Переводы по фразам выполняются по аналогии с предыдущими переводами. Принцип перевода по аналогии кодируется в машинном переводе на основе примеров посредством примеров переводов, которые используются для обучения такой системы. Другие подходы к машинному переводу, включая статистический машинный перевод, также используют двуязычные корпуса для изучения процесса перевода.
Машинный перевод на основе примеров был впервые предложен Макото Нагао в 1984 году . Нагао указывал на то, что данный вид перевода специально адаптирован для перевода, если это касается двух совершенно разных языков, таких как английский и японский. В этом случае одно предложение может быть переведено на несколько хорошо структурированных предложений на другом языке, поэтому нет смысла делать глубокий лингвистический анализ, характерный для машинного перевода на основе правил.
В общем, система EBMT состоит из трех компонентов: поиска соответствий, рекомбинации и выравнивания .
Пример двуязычного корпуса
| Английский | Японский |
|---|---|
| How much is that red umbrella? | Ano akai kasa wa ikuradesuka. |
| How much is that small camera? | Ano chiisai kamera wa ikura desu ka. |
Системы машинного перевода на основе примеров состоят из двуязычных параллельных корпусов, содержащих пары предложений, как пример, приведенный в таблице выше. Пары предложений содержат предложения на одном языке с их переводом на другой. В данном примере показан пример минимальной пары, что означает, что предложения отличаются лишь одним элементом. Эти предложения упрощают запоминание переводов частей предложения. Например, система машинного перевода на основе примеров запомнит три единицы перевода из приведенного выше примера:
Составление этих единиц может использоваться для создания новых переводов в будущем. Например, если бы нас обучали, используя текст, содержащий предложения: President Kennedy was shot dead during the parade и The convict escaped on July 15th, мы могли бы перевести предложение The convict was shot dead during the parade, заменив соответствующие части предложений.
Машинный перевод на основе примеров лучше всего подходит для таких явлений подъязыка, как фразовые глаголы. Фразовые глаголы имеют весьма контекстно-зависимые значения. Они распространены в английском языке и состоят из глагола, за которым следует наречие и/или предлог, который называется частицей в составе глагола. Фразовые глаголы образуют специализированные контекстно-специфические значения, которые не могут быть извлечены из смысла составляющих. При их пословном переводе с исходного языка на целевой почти всегда возникает неоднозначность . В качестве примера рассмотрим фразовый глагол «put on» и его значение на хинди—урду. Он может использоваться любым из следующих способов:
Статистический машинный перевод (англ. Statistical machine translation — SMT) — разновидность машинного перевода, где перевод генерируется на основе статистических моделей, параметры которых являются производными от анализа двуязычных корпусов текста (text corpora).
Статистический машинный перевод противопоставляют системам машинного перевода, основанным на правилах Rule-Based Machine Translation (RBMT) и на примерах Example-Based MT (EBMT).
Первые идеи статистического машинного перевода были опубликованы Уорреном Уивером (Warren Weaver), в 1949 году. «Вторая волна» — начало 1990-х, IBM. «Третья волна» — Google, Microsoft, Language Weaver, Яндекс …
Разработчики систем машинного перевода для улучшения качества вводят некоторые «сквозные» правила, тем самым превращая чисто статистические системы в Гибридный машинный перевод. Добавление некоторых правил, то есть создание гибридных систем, несколько улучшает качество переводов, особенно при недостаточном объеме входных данных, используемых при построении индекса машинного переводчика.
В качестве языковой модели в системах статистического перевода используются преимущественно различные модификации n-граммной модели, утверждающей, что «грамматичность» выбора очередного слова при формировании текста определяется только тем, какие (n-1) слов идут перед ним .
Машинный перевод на основе трансформации является разновидностью машинного перевода (MП). В настоящее время это один из наиболее распространенных методов машинного перевода. В отличие от более простой модели прямого MП, MП на основе трансформации разделяет процесс перевод на три этапа: анализ текста на исходном языке для определения его грамматической структуры, перевод результирующей структуры в структуру, подходящую для производства текста на языке перевода, и генерацию текста. Таким образом, системы МП на основе трансформации способны использовать знания исходного языка и языка перевода .
В основе перевода на основе трансформации и межъязыкового машинного перевода лежит одна и та же идея, согласно которой для того чтобы осуществить перевод, необходимо получить промежуточное представление. С его помощью можно зафиксировать смысл первоначального предложения, чтобы затем построить правильный перевод. В межъязыковом МП такое промежуточное представление должно быть независимым и от исходного языка, и от языка перевода, в то время как в случае с MП, основанном на переносе, имеет место определенная степень зависимости от конкретной пары языков. Способы работы систем МП на основе трансформации существенным образом различаются, однако в целом они следуют одной и той же схеме: применяют наборы лингвистических правил, определяемых соответствиями между структурой исходного языка и языка перевода. Первый этап включает анализ входного текста с точки зрения морфологии и синтаксиса (иногда также семантики) для создания промежуточного представления. Из полученного представления с использованием двуязычных словарей и правил грамматического построения формируется перевод. Данная стратегия позволяет получить достаточно качественный перевод с точностью соответствия оригиналу порядка 90% (впрочем, точность в большой степени зависит от конкретной языковой пары и определяется степенью близости двух конкретных языков).
В системе МП на основе правил исходный текст сначала анализируется с точки зрения морфологии и синтаксиса с целью получения синтаксического представления. Данное представление в дальнейшем может быть изменено в сторону меньшей конкретизации, в связи с необходимостью уделять повышенное внимание наиболее существенным для перевода фрагментам, игнорируя при этом другие виды информации. В процессе трансформации окончательное представление (все еще существующее на исходном языке) преобразуется в представление того же уровня конкретизации на языке перевода. Эти два представления носят название промежуточных представлений. Процесс трансформации представления на языке перевода в готовый текст состоит из аналогичных этапов, произведенных в обратном порядке.
До того момента как будет получен финальный результат, возможно обращение к различным методам анализа и трансформации. Наряду со статистическими подходами может быть увеличено число генерирующих гибридных систем. Выбираемые методы и приоритеты в значительной мере зависят от устройства самой системы. Тем не менее, большинство существующих систем включает как минимум следующие этапы:
Одной из основных особенностей систем МП на основе трансформации является стадия, на которой происходит перевод промежуточного представление текста на исходном языке в промежуточное представление текста на языке перевода. Этот процесс может происходить на одном из уровней лингвистического анализа или в промежутке между ними. Уровни представлены ниже:
Привожу английские названия потому что именно эти аббревиатуры повсеместно используются в текстах и разговорах. Как HTTP или RSA, например.
Идеи машинного перевода на основе правил начали появляться еще в 1970-х годах. Ученые подсматривали за работой лингвистов-переводчиков и пытались запрограммировать свои большие и медленные компуктеры повторять за ними. Их системы состояли из:
В общем-то все. По желанию они дополнялись хаками типа списков имен, корректорами орфографии и транслитераторами.
ПРОМТ и Systran — самые известные примеры RBMT-систем. «Охладите траханье, углепластик, я рассматриваю ее пользу», — золотое время же. Алиэкспресс вон до сих пор так переводит.
Но даже у них были свои нюансы и подвиды.
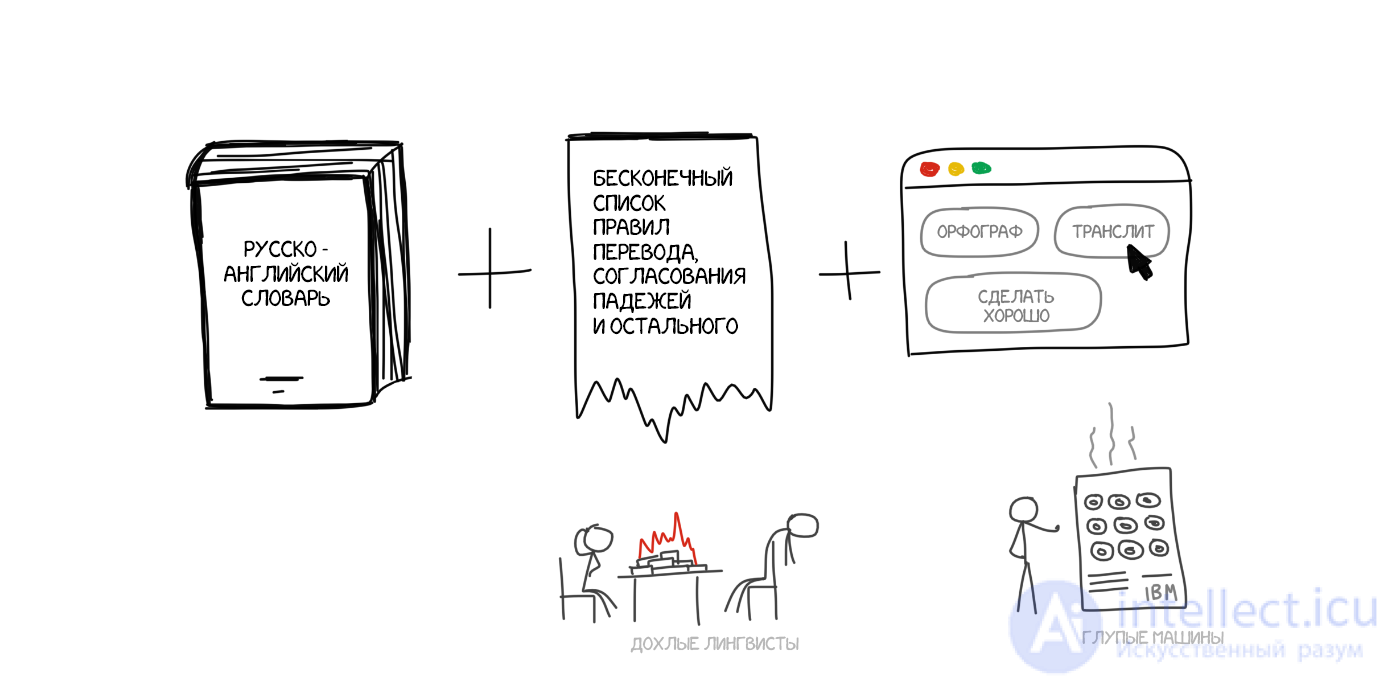
Самый простой способ машинного перевода, понятный любому пятикласснику. Делим текст по словам, переводим каждое, немножко правим морфологию, чтобы звучало не криво, согласуем падежи, окончания и остальной синтаксис. Специально обученные лингвисты по ночам пишут правила под каждое слово.
На выходе получаем что-то переведенное. Чаще всего полное говно. Только лингвистов зря попортили.
В современных системах подход не используется вообще, рассказываю чисто поржать.
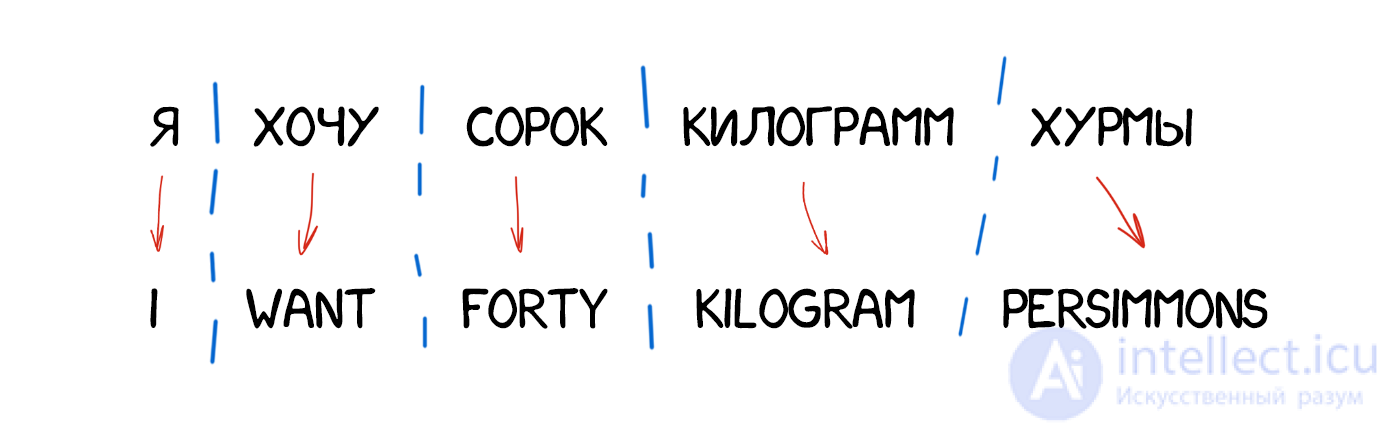
В них мы не кидаемся сразу переводить по словарю, а немного готовимся. Разбираем текст на подлежащее, сказуемое, ищем определения и все остальное как учили в школе. Взрослые дядьки говорят «выделяем синтаксические конструкции». После этого в систему мы уже не закладываем правила перевода каждого слова, а манипулируем целыми конструкциями. В теории даже можем добиться более-менее неплохой конвертации порядка слов в языках.
На практике все еще тяжело, лингвисты по-прежнему гибнут от физического истощения, а перевод получается фактически дословный. С одной стороны проще: можно задать общие правила согласования по роду и падежу. С другой сложнее: сочетаний слов намного больше, чем самих слов. Каждый вариант не учтешь руками.
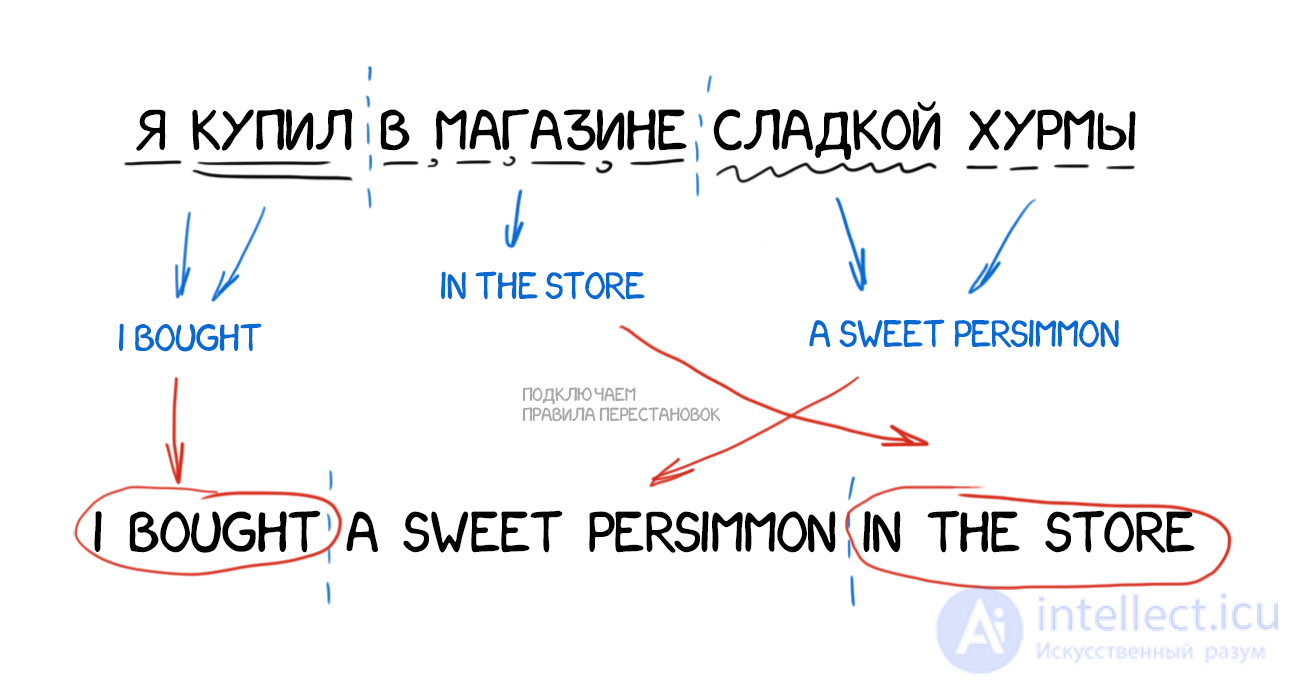
Полностью конвертируем исходное предложение в некое промежуточное представление, единое для всех языков мира (interlingua). В ту самую интерлингву, которой грезил сам Декарт. Специальный метаязык, правила которого едины и покрывают все языки мира, тем самым превращая перевод в техническую задачу перегона туда-сюда. Специальные парсеры затем конвертируют эту интерлингву в нужный язык и вот она сингулярность.
Часто интерлингву путают с трансферными системами, ведь там тоже есть конвертация. Однако в трансферных системах правила конвертации пишутся под два конкретных языка, а в интерлингвистической между каждым языком и интерлингвой. Добавив в интерлингвистическую систему третий язык, мы сможем переводить между всеми тремя, а в трансферной нет.
В реальной жизни все оказалось не так сладко. Создать универсальную интерлингву вручную оказалось крайне сложно. Некоторые ученые жизни свои положили на это. Ничего не получилось, однако благодаря им у нас появились методы морфологического, синтаксического и даже иногда семантического анализа. Одна только модель Смысл <-> Текст чего стоит.
Но сама идея промежуточного языка еще вернется к нам позже. Надо будет всего 30 лет подождать.
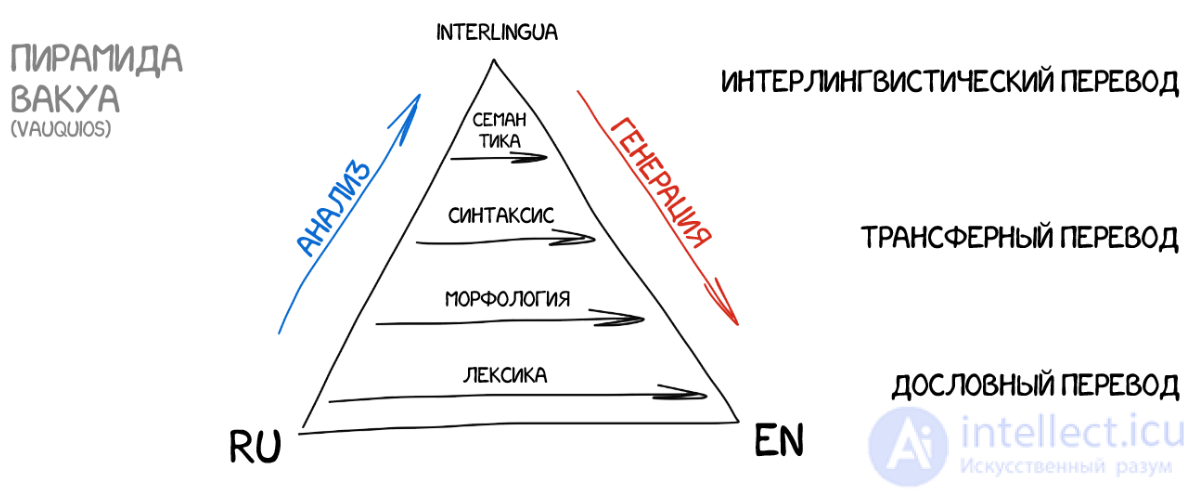
рис пирамида вакуа
Как можно заметить, все RBMT тупы, ужасны, потому сейчас редко используются. Разве что в специфических местах типа перевода метеосводок. Среди плюсов RBMT отмечают морфологическую точность (не путает слова), воспроизводимость (все переводчики получат одинаковый результат) и возможность затюнить под предметную область (обучить специальным терминам экономистов или программистов).
Даже если представить, что ученым и удалось бы создать идеальную RBMT, а лингвистам заложить в нее все правила правописания, за дверью их уже поджидало веселье — исключения. Неправильные глаголы в английском, плавающие приставки в немецком, суффиксы в русском, да и просто ситуации, когда «у нас так не говорят, надо вот так». Попытка учесть все нюансы оборачивается миллионами потраченных зря человекочасов.
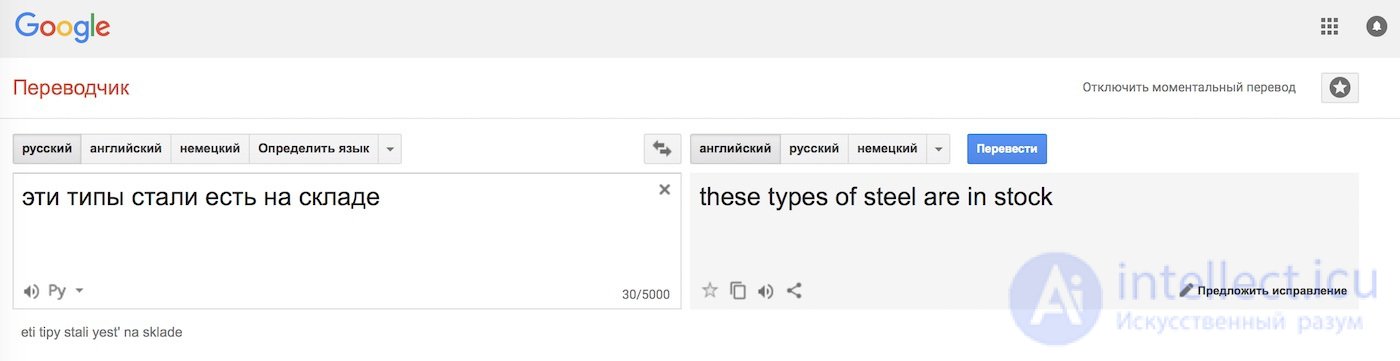
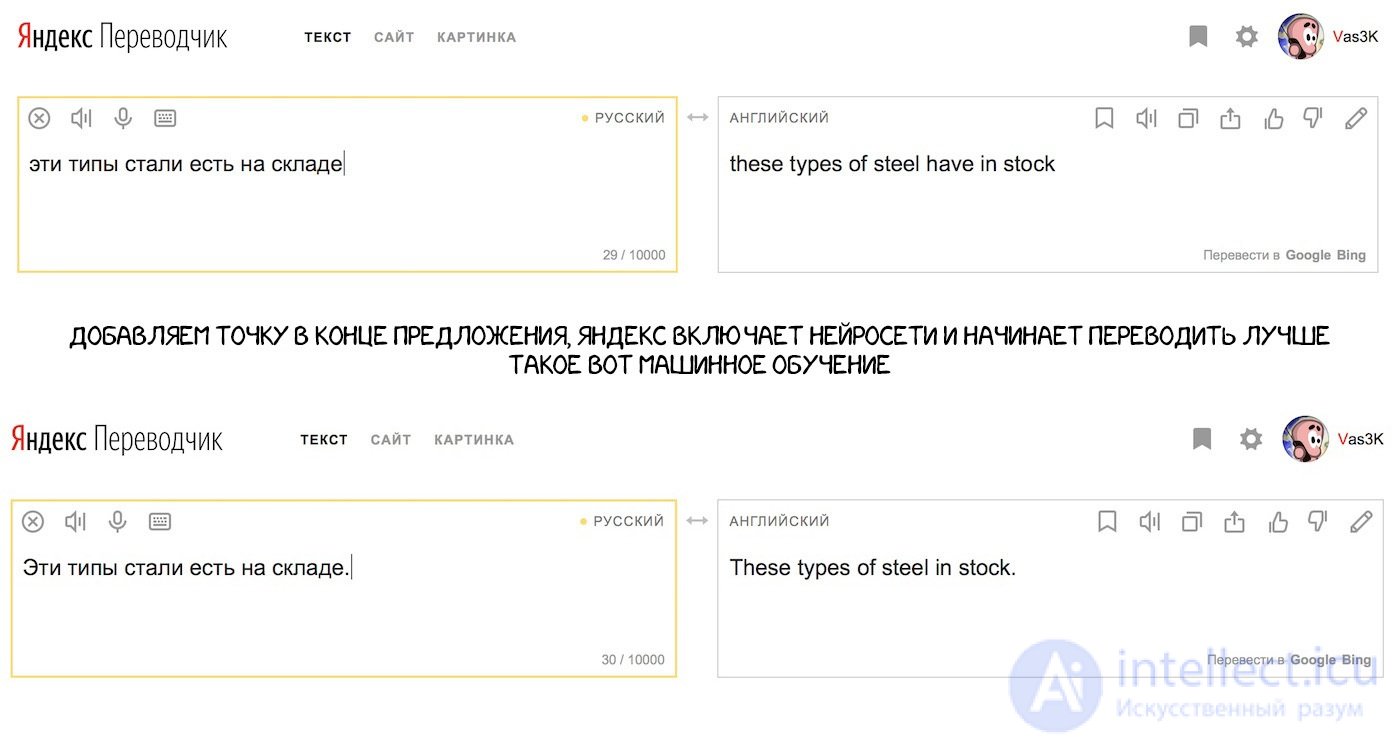
Куча правил все равно не решает главной проблемы — омонимия. Одно и то же слово может иметь разный смысл зависимости от контекста, а значит отличается и его перевод. Вспоминается пример с одной из старых лекций Сегаловича: «Эти типы стали есть на складе». Он говорил, что может найти четыре разных варианта прочтения этого предложения. А вы?
Наши языки развивались отнюдь не на основе грамматик и правил, о которых любят рассуждать лингвисты. Они больше зависят от того, кто на кого напал и завоевал за последние триста лет. Вот как мне теперь обучить этому машину?
За сорок лет холодной войны ученые так и не смогли найти внятного решения. RBMT сдох.
В битве за машинный перевод в те годы была особенно заинтересована Япония. Там не было холодной войны, но были свои причины: крайне мало кто в стране знал английский. Это сулило большие трудности на вечеринке наступающей глобализации, из-за чего японцы были крайне мотивированы найти рабочий метод машинного перевода.
Англо-японский перевод на основе одних только правил крайне сложен, строение языков отличается, почти все слова приходится переставлять и добавлять новые. В 1984 году ученому университета Киото по имени Макото Нагао приходит идея. А что если не пытаться каждый раз переводить заново, а использовать уже готовые фразы?
Предположим нам надо перевести предложение «я иду в магазин». Где-то в заначке у нас уже есть перевод похожей фразы «я иду в театр» и словарь с переводом слова «магазин». Мы ведь можем как-то попытаться вычислить разницу и перевести только одно слово в имеющемся примере, не похерив остальные конструкции. И чем больше у нас примеров — тем лучше перевод.
Я же тоже так строю фразы на незнакомых языках!
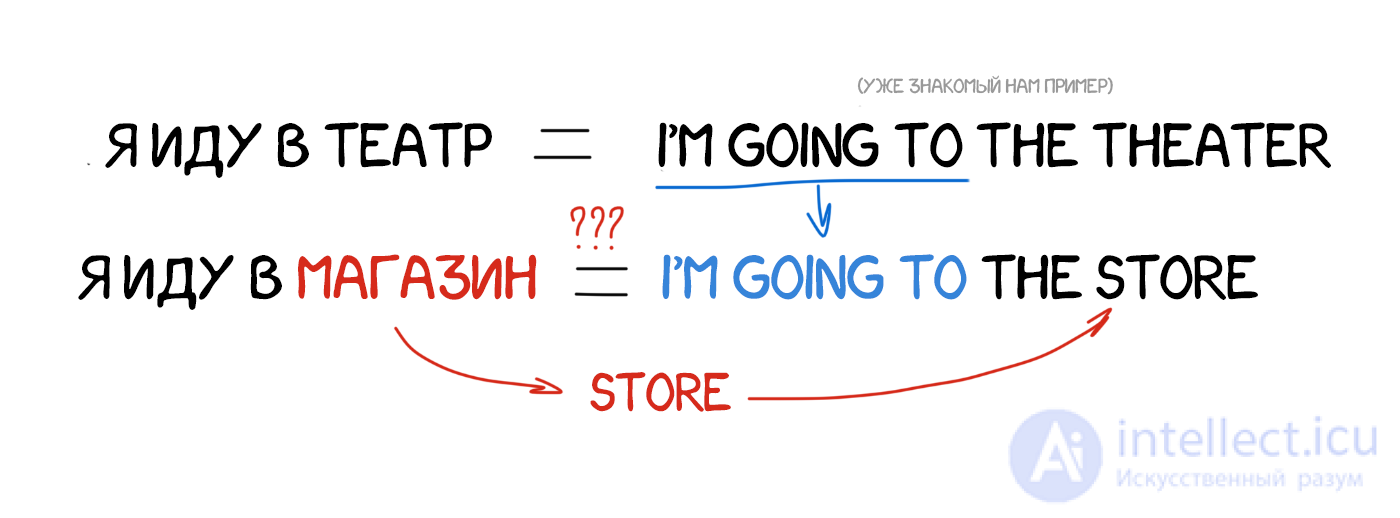
Историческая важность метода была в том, что ученые всего мира впервые прозрели: можно не тратить годы на создание правил и исключений, а просто взять кучу уже имеющихся переводов и скормить их машине. Это была еще не революция, но шаг туда. До революции и изобретения статистического перевода оставалось пять лет.
На рубеже 1990 года в исследовательском центре IBM впервые показали систему машинного перевода, которая ничего не знала о правилах и лингвистике. Ученые показали бездушному компьютеру очень много одинаковых текстов на двух языках, и заставили его разбираться в закономерностях самому.
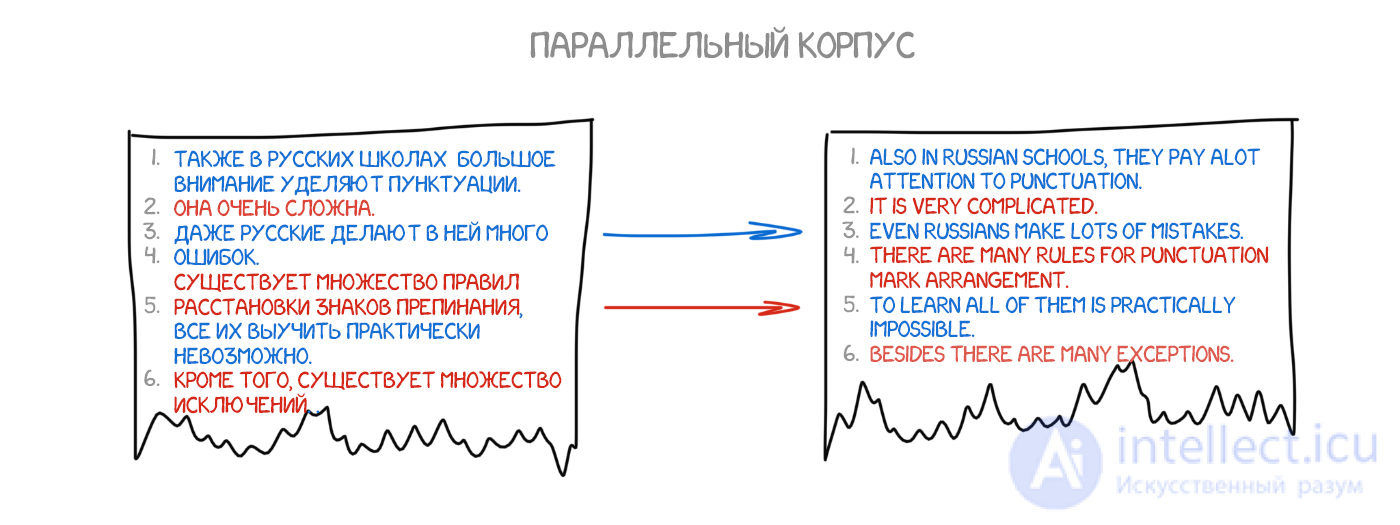
Идея была проста и одновременно красива: берем одно предложение на двух языках, разбиваем его по словам и пытаемся сопоставить каждое слово с его с переводом. Повторяем эту операцию где-то 500 млн раз, а машина считает сколько раз у нас слово das Haus переводилось как house, building, construction, итд. Наверное чаще всего это был house, его и будем использовать. Заметьте, мы не задали ни правил, ни словарей. Машина сама все нашла, руководствуясь чистой статистикой и логикой «люди переводят вот так, значит и я буду». Так родился статистический перевод .
Точность таких переводчиков оказалась заметно выше всех предыдущих, а разработка не требовала никаких лингвистов. Находим больше текстов — улучшаем перевод.
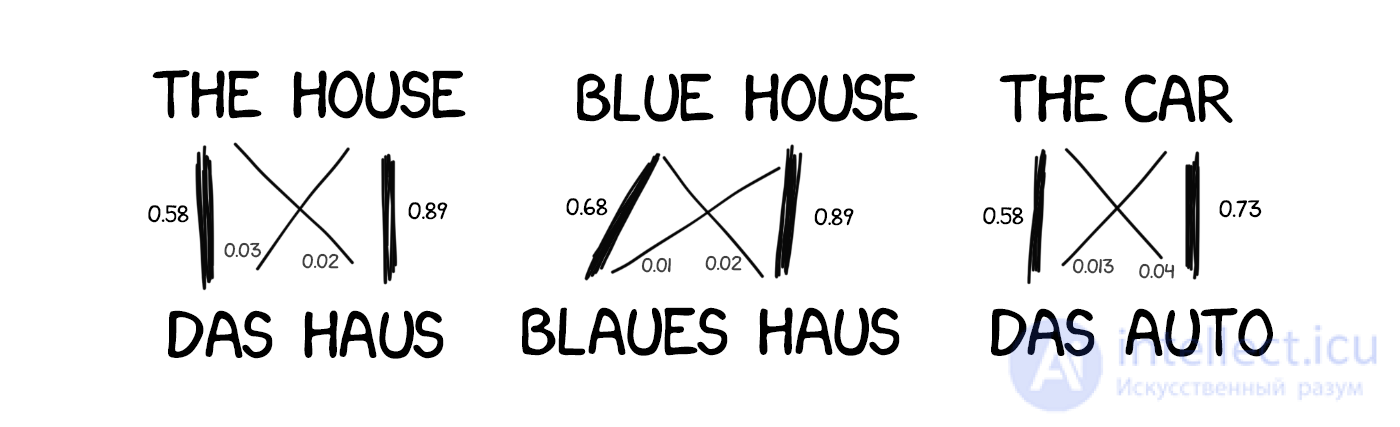
Одна проблема: как машина догадается, что для das Haus парой является именно house, а не любое другое слово из предложения? Порядок слов-то разный, откуда мы знаем как именно надо разбить и найти нужные слова?
Кишки статистического перевода в Google Translate. Гугл не только показывает вероятности, но и считает обратную статистику.
Ответ: никак. В начале работы машина с равной долей вероятности считает, что слово das Haus переводится как любое из слов имеющегося предложения. Когда она встречает das Haus в других предложениях, то количество переводов das Haus как house начинает увеличиваться с каждым разом. Это называется «алгоритмом выравнивания слов» (word aligment). Типична задача машинного обучения, такие решают в универах.
Машине нужны миллионы и миллионы предложений на двух языках, чтобы набрать статистику по каждому слову. И где столько взять? Так вон, в Европарламенте и совете ООН ведут конспекты заседаний на языках всех стран-членов, их и возьмем. Сейчас они даже открыли для скачивания: UN Corpora и Europarl Corpora.
Первые системы статистического перевода опять начали с деления по словам. Это казалось логично и просто. Первую изобретенную модель статистического перевода в IBM назвали IBM Model 1. Изящно, да. Догадайтесь как назвали вторую?
Классический подход — делим все на слова и считаем статистику. Никакого учета порядка или перестановок. Из хитростей Model 1 умела разве что переводить одно слово в несколько. Der Staubsauger (пылесос) легко превращался в Vacuum Cleaner, но обратно уже как повезет.
На питоне можно найти простенькие реализации: shawa/IBM-Model-1.
Отсутствие знаний о порядке слов в языках стало проблемой для Model 1. В некоторых он очень важен. Потому в Model 2 стали запоминать на каком месте появляется в переведенном предложении. Добавили промежуточный шаг — после перевода машина пыталась переставить слова местами так, как она думала будет звучать более естественно.
Стало лучше, но все еще хреново.
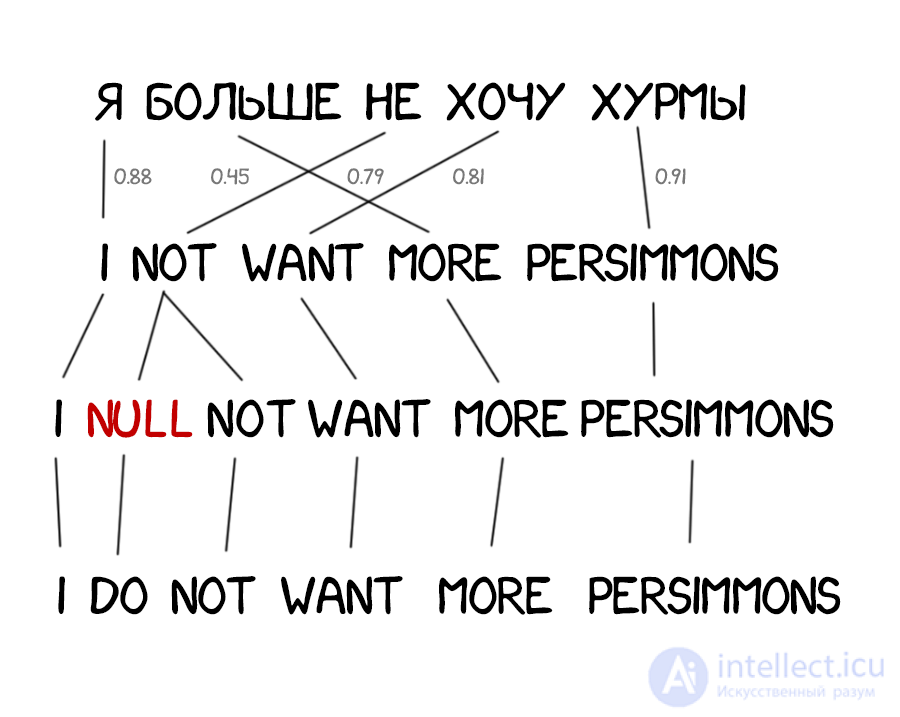
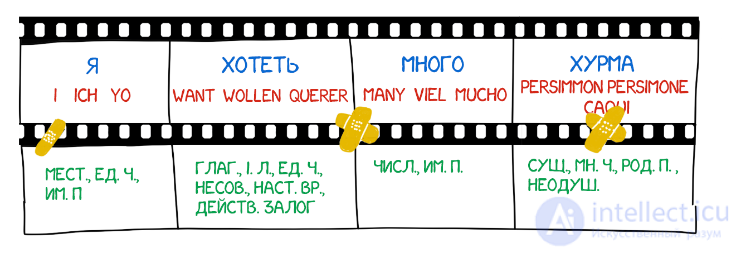
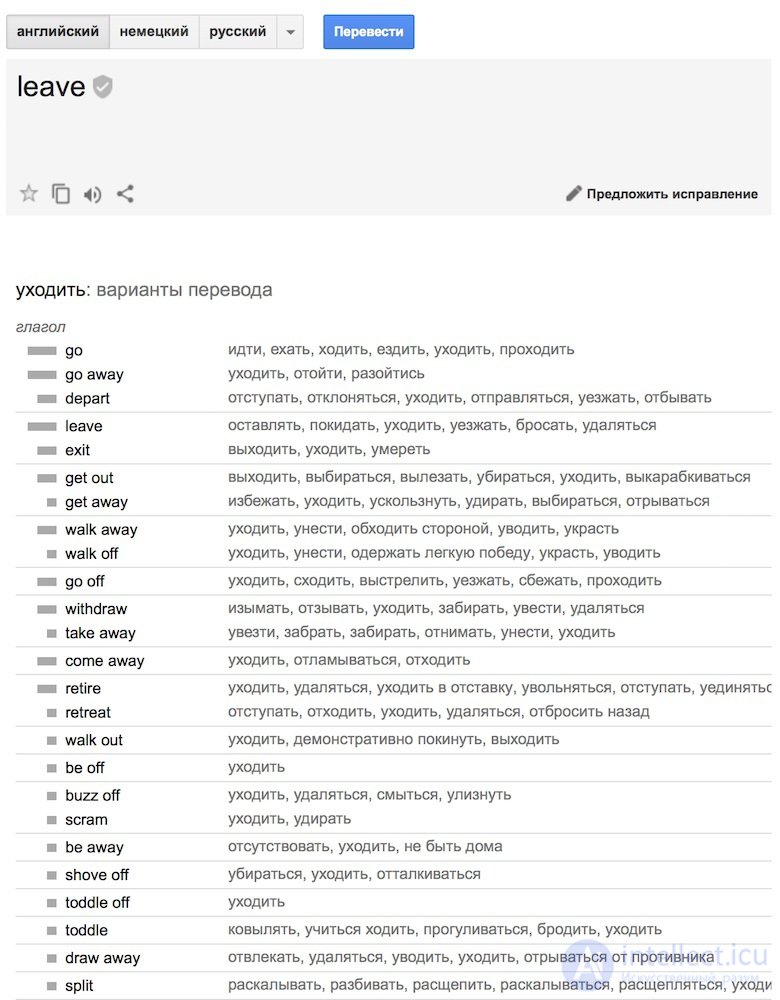
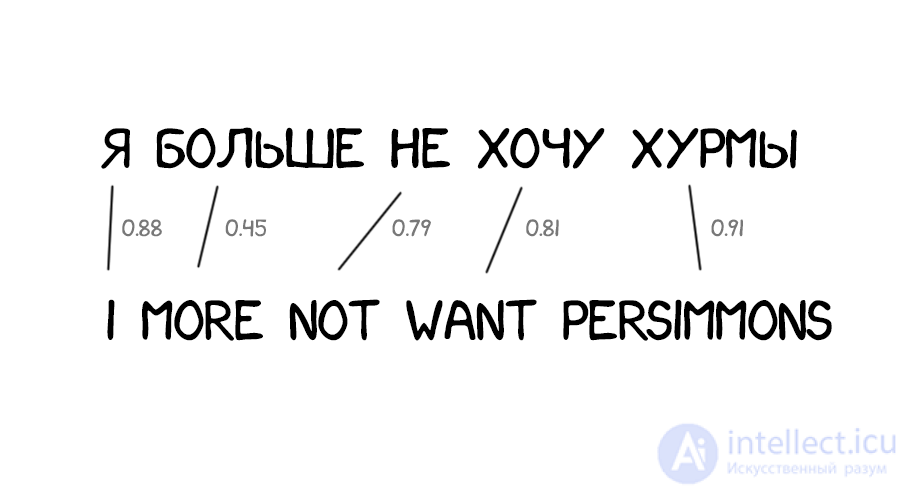
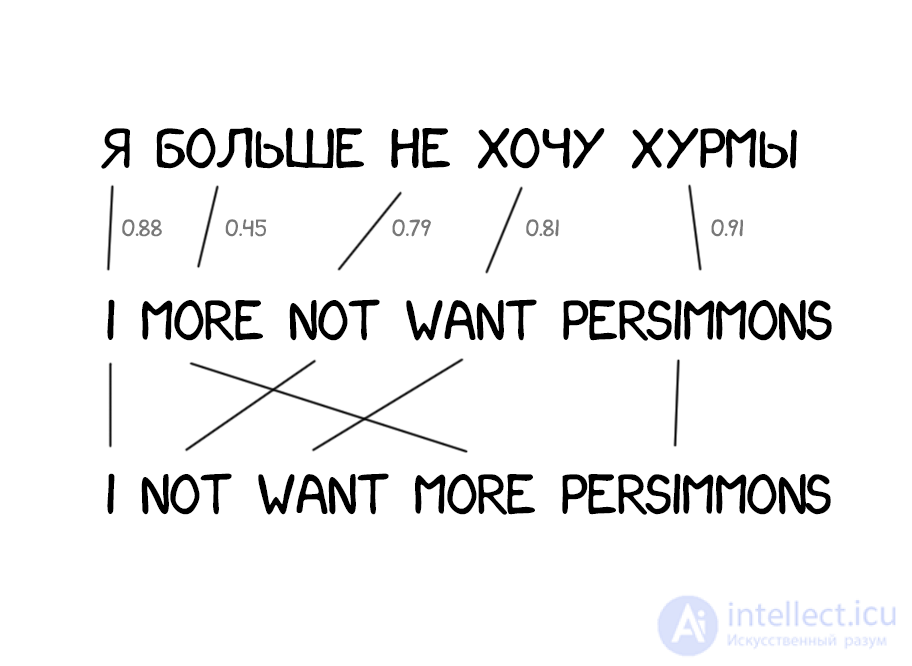
Часто при переводе появляются новые слова, которых не было в оригинальном тексте. В немецком языке внезапно вылезают артикли, в английском вставляют глагол do где не попадя. «Я не хочу хурмы» → «I do not want persimmons. Чтобы решить эту проблему в Model 3 добавили два промежуточных шага:
Model 2 хоть учитывала порядок слов в предложении, но ничего не знала про перестановки слов между собой. Часто при переводе надо, например, поменять существительное и прилагательное местами. Тут сколько ни запоминай их порядок по всему предложению — лучше не станет. Потому в Model 4 стали учитывать еще и так называемый «относительный порядок». Если при переводе два слова постоянно менялись друг с другом — модель это запоминала.
Особо ничего нового. В Model 5 добавили параметров для обучения и пофиксили проблемы, когда два слова конфликтовали за место в предложении.
Несмотря на всю революционность, Word-based системы по прежнему ничего не могли поделать с падежами, родом и омонимией. Каждое слово они переводили единственным, по их мнению, верным способом. Сейчас такие системы не используются, их заменил более продвинутый метод — перевод по фразам.
Про омонимию у меня есть любимая шутка:
— Это ваш Ягуар у подъезда стоит?
— Да
— Я допью?
Взял за основу все принципы перевода по словам: статистика, перестановки и лексические хаки. Но для обучения он разбивал текст не только на слова, но и на целые фразы. Точнее N-граммы или фраземы — пересекающиеся наборы из N слов подряд. Машина училась переводить устойчивые сочетания слов, что заметно улучшило точность.
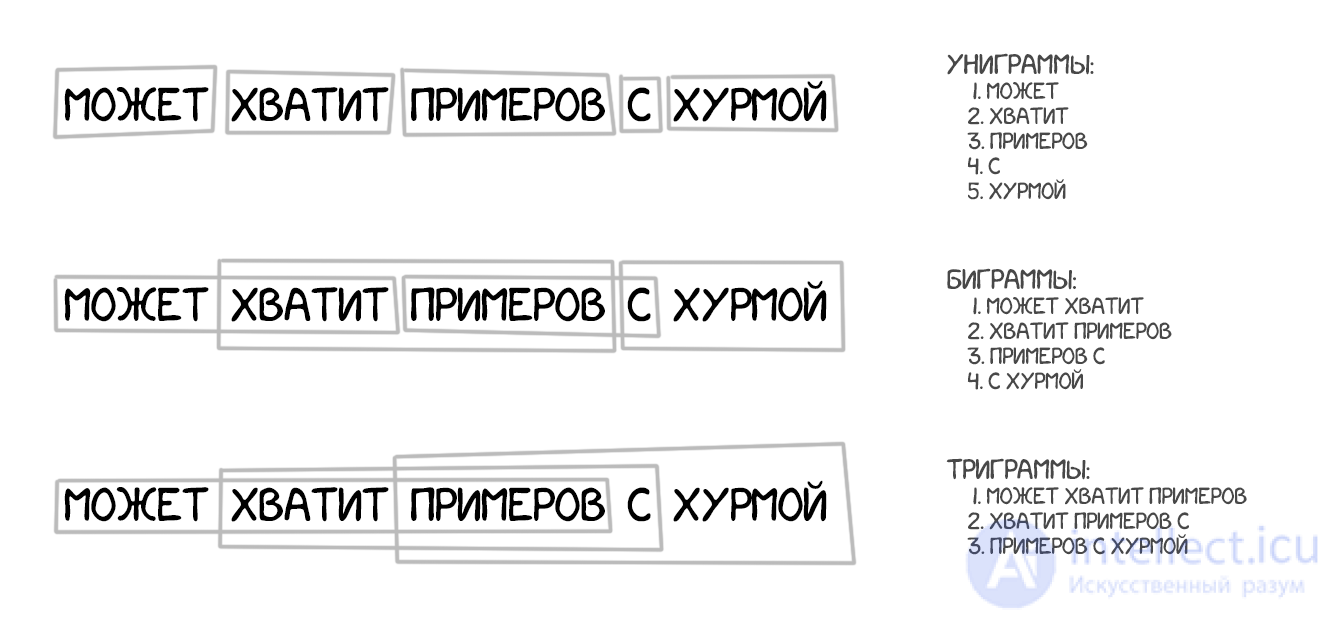
Хитрость метода заключалась в том, что «фразы» не всегда были понятными нам со школы синтаксическими конструкциями. Как только в перевод пытался вмешиваться человек, знающий про лингвистику и строение предложений, качество перевода резко падало. Пионер компьютерной лингвистики Фредерик Йелинек однажды пошутил по этому поводу: «Каждый раз, когда из команды уходит линвист, качество распознавания возрастает».
Помимо улучшения точности, перевод по фразам дал больше свободы в поиске двуязычных текстов для обучения. Для Word-based перевода было очень важно точное соответствие переводов, что исключало любые литературные или вольные переводы. Phrase-based прекрасно обучался даже на них. Многие даже начали парсить новостные сайты на разных языках и улучшать перевод этими текстами.
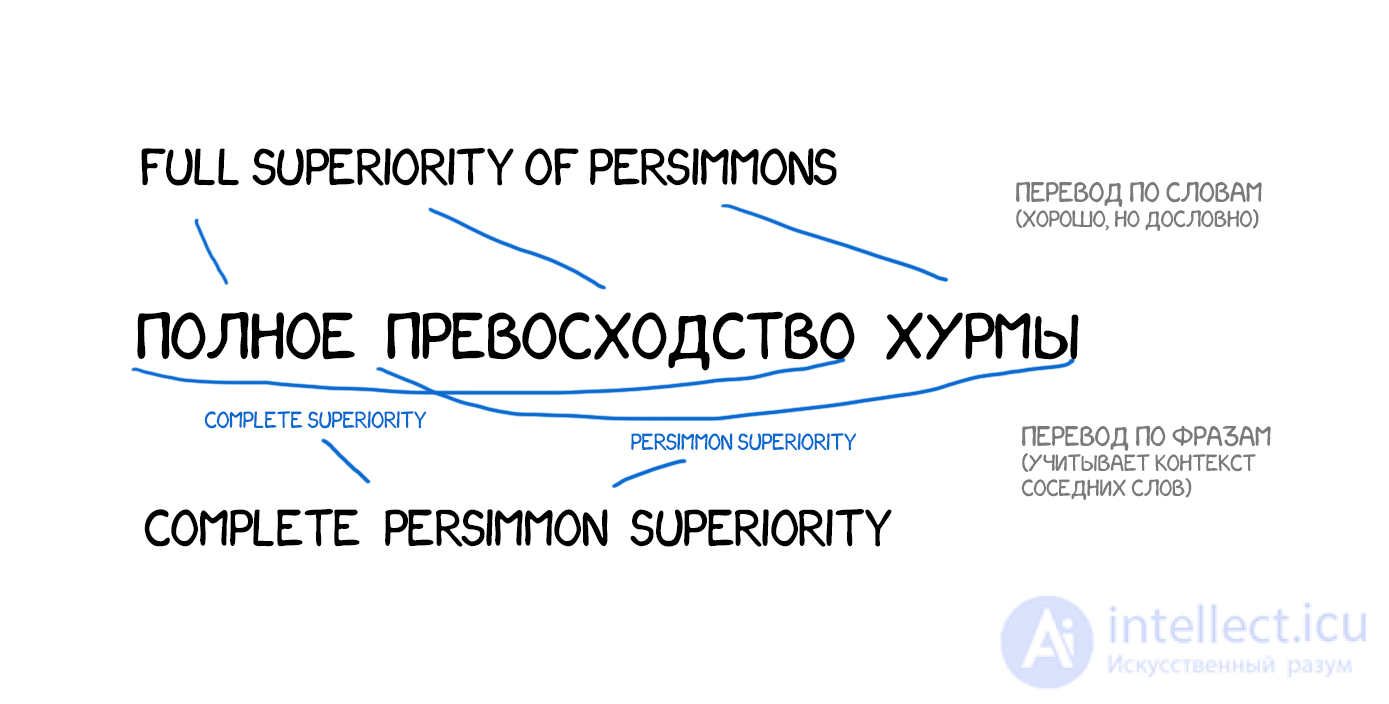
С 2006 года этот подход начали использовать все. Google Translate, Yandex, Bing и другие качественные онлайн-переводчики работали именно как Phrase-based аж до самого 2016-го. Каждый из вас может припомнить опыт, когда одно предложение Google переводил на отлично, литературно переставляя слова, а на другом начинал гнать полную околесицу. Такова особенность перевода по фразам.
Если старый добрый Rule-based подход стабильно давал предсказуемый, хоть и ужасный результат, то статистические методы бывало удивляли и озадачивали. Можно вспомнить десяток шуток про Google Translate, когда он переводил «three hundred» как «300» и даже не смущался. Этот косяк назвали статистическими аномалиями.
Phrase-based перевод стал настолько популярным, что когда вы слышите «статистический машинный перевод», скорее всего имеется в виду именно он. Вплоть до 2016 года во всех исследованиях Phrase-based перевод хвалебно называют the state-of-art. Тогда никто даже не подозревал, что в лабораториях Google уже завозят под это дело фуры с нейросетями, чтобы опять изменить наше представление о машинном переводе.
Стоит кратенько упомянуть и этот метод. До прихода нейросетей, про синтаксический перевод многие годы говорили как про «будущее переводчиков», но достичь успеха он так и не успел.
Адепты синтаксического перевода верили в объединение подходов SMT и старого трансферного перевода по правилам. Нужно научиться делать достаточно точный синтаксический разбор предложения — определять подлежащее, сказуемое, зависимые члены и вот это вот все, а затем построить дерево. Имея такое дерево, можно обучить машину правильно конвертировать фигуры одного языка в фигуры другого, выполняя остальной перевод по словам или фразам. Только делать это теперь не руками, а машинным обучением. В теории это решило бы проблему порядка слов навсегда.
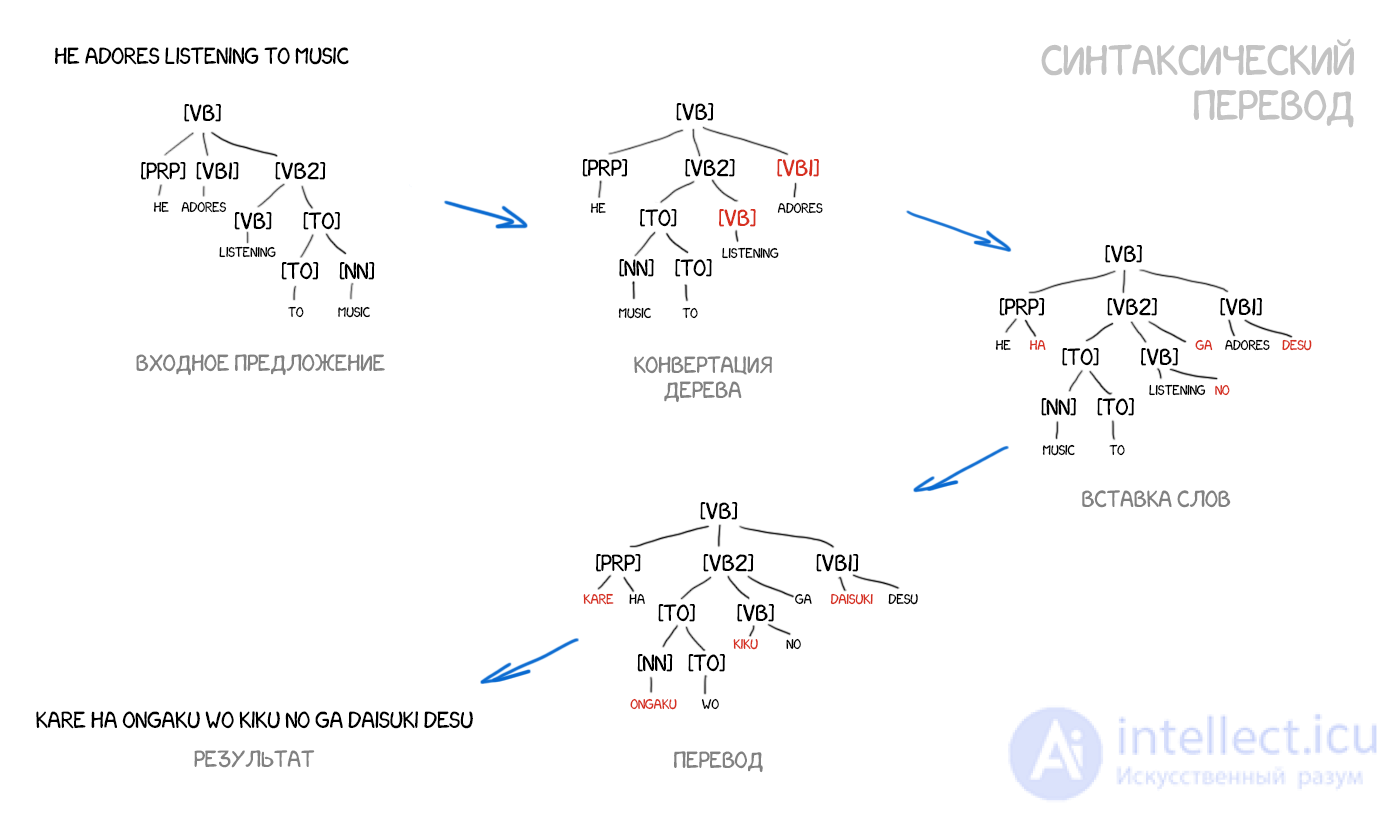
Пример взят из Yamada and Knight [2001] и вот этих отличных слайдов.
Проблема в том, что хоть человечество и считает проблему синтаксического разбора давно решенной (для многих языков есть готовые библиотеки), по факту он работает весьма говено. Я лично много раз пытался использовать синтаксические деревья для задач сложнее вычленения подлежащего и сказуемого, и каждый раз отказывался в пользу других методов.
Если у вас был хоть один успешный опыт с ними, расскажите в комментах.
В 2014 году выходит статья с кратким описанием идеи применения нейросетей глубокого обучения к машинному переводу. В верхнем интернете ее вообще никто не заметил, а вот в лабораториях Google начали активно копать. Спустя два года, в ноябре 2016, в блоге Google появляется анонс, который и перевернул игру.
Идея была похожа на перенос стиля между фотографиями. Помните приложения типа Prisma, которые обрабатывали фоточки в стиле известного художника? Там не было особой магии — нейросеть обучили распознавать картины художника, а потом «оторвали» последние слои, где она принимает решение. Получившиеся кишочки, по сути промежуточное представление сети, и было той самой стилизованной картинкой. Она так видит, а нам красиво.

Если с помощью нейросети мы можем перенести стиль на фото, то что если попытаться подобным образом наложить другой язык на наш текст? Представить язык текста как тот самый «стиль художника», попытавшись его перенести, сохранив суть изображения (то есть суть текста).
Представьте, что я на словах описываю вам как выглядит моя собака: средний размер, острый нос, большие уши, короткий хвост и гавкает постоянно. Я передаю вам набор характеристик собаки и, при достаточно точном описании, вы сможете даже нарисовать ее, хотя никогда вживую не встречали.
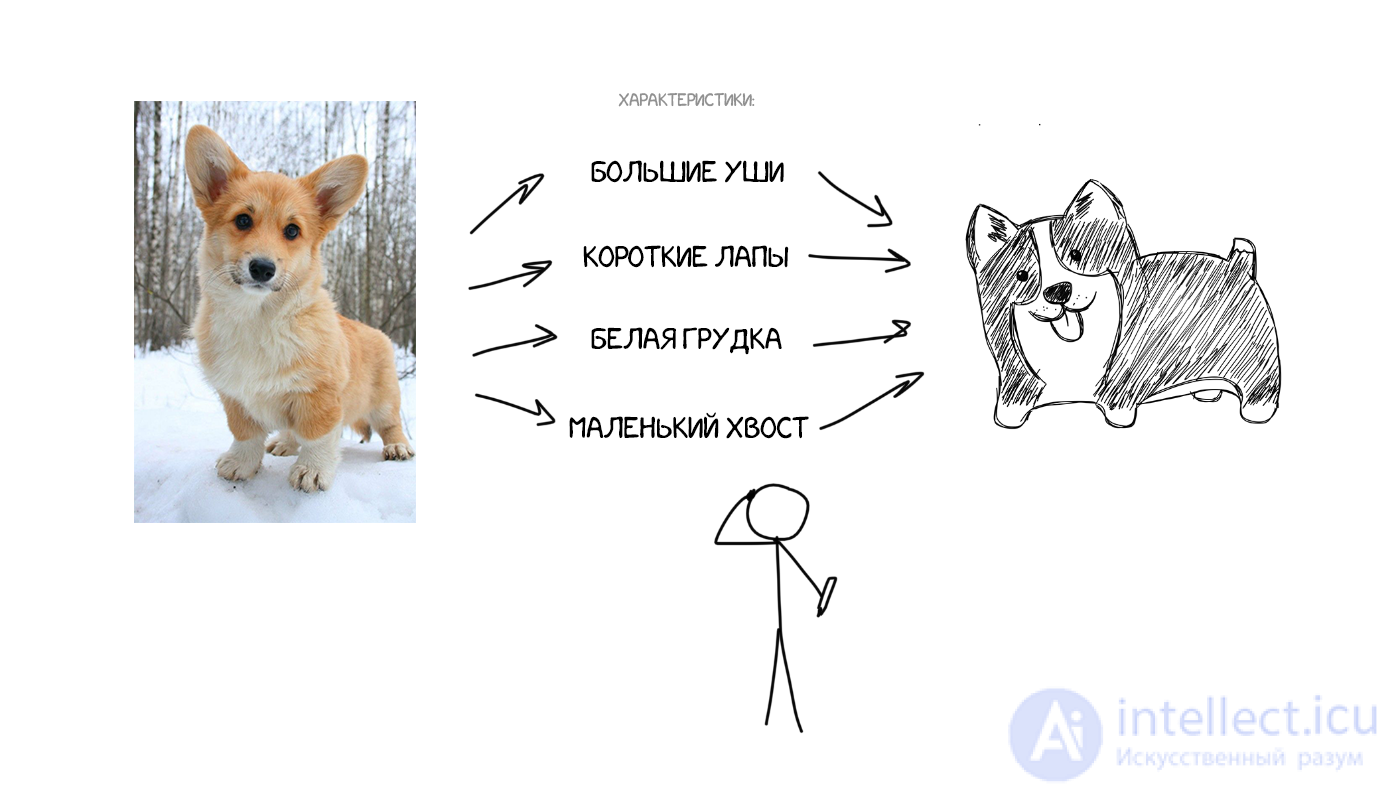
Теперь что если представить исходный текст как набор таких же характерных свойств? По сути закодировать его так, чтобы затем другая нейросеть — декодер, расшифровала их обратно в текст, но уже на другом языке. Мы специально обучим декодер знать только свой язык. Он и понятия не имеет откуда характеристики взялись, но умеет выразить их, скажем, на испанском. Продолжая аналогию: какая вам разница чем рисовать описанную мной собаку — карандашами, акварелью или пальцем по грязи. Рисуете как умеете.
Еще раз: первая нейросеть умеет только кодировать предложение в набор циферок-характеристик, а вторая только декодировать их обратно в текст. Обе понятия не имеют друг о друге, каждая знает только свой язык. Ничего не напоминает? К нам вернулась идея интерлингвы. Та-да.
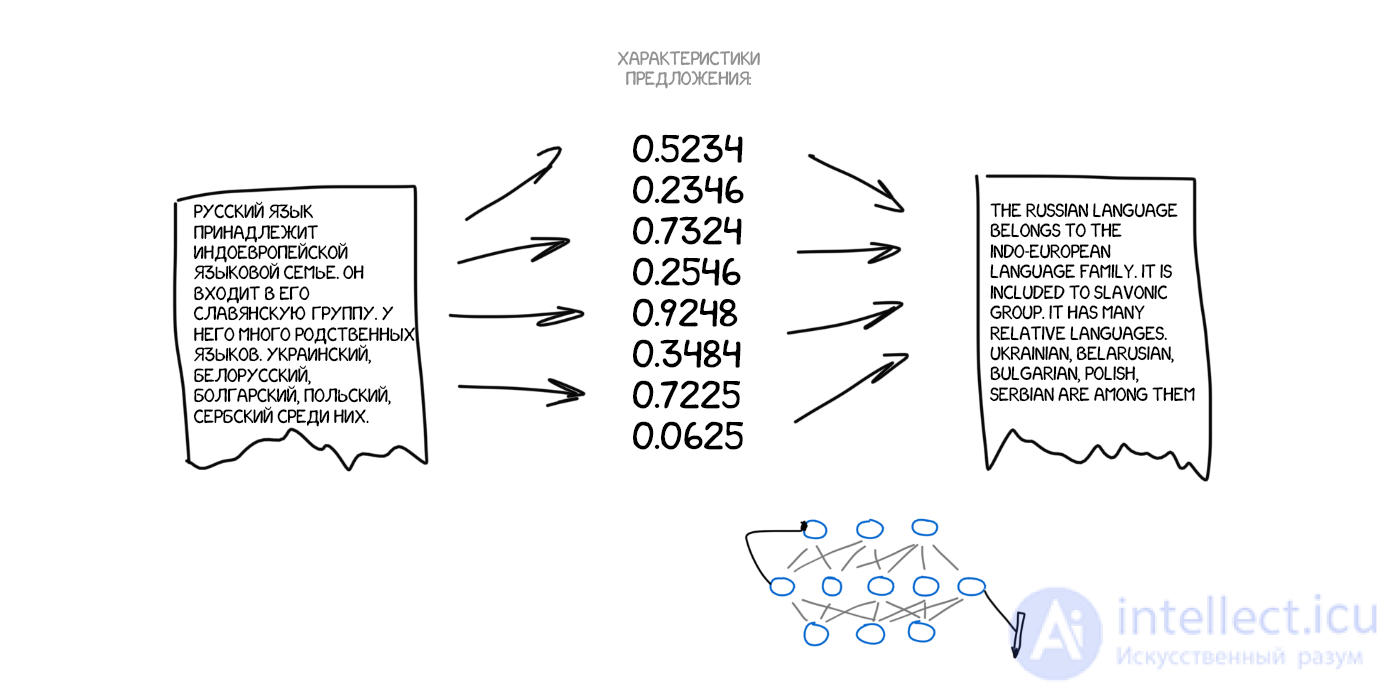
Но как найти эти характеристики? С собакой все понятно, у нее лапки и другие части тела, а с текстами как? Ученые 30 лет назад уже пытались скрафтить универсальный языковой код, это закончилось полным провалом.
Но у нас теперь есть диплернинг, который как раз этим и занимается! Главное отличие диплернинга от классических нейросетей как раз и было в том, что его сети обучаются находить характерные свойства объектов, не понимая их природы. При наличии достаточно большой нейросети и пары тысяч видеокарт в заначке, можно попытаться найти такие характеристики и в тексте!
Теоретически полученные нейросетями характеристики потом можно отдать лингвистам и они откроют для себя много нового. Яндекс об этом как-то рассказывал.
Вопрос только в том, какой вид нейросети использовать в кодере и декодере. Для картинок отлично подходят сверточные нейросети (CNN), потому что работают с независимыми блоками пикселей. Но в тексте не бывает независимых блоков, каждое следующее слово зависит от предыдущих и даже последующих. Текст, речь и музыка всегда последовательны. Для их обработки лучше подходят реккурентные нейросети (RNN), ведь они помнят предыдущий результат. В нашем случае это предыдущие слова в предложении.
RNN сейчас применяют много где: распознавание речи в Siri (парсим последовательность звуков, где каждый зависит от предыдущего), подсказки слов на клавиатуре (запоминаем предыдущие и угадываем следующее), генерация музыки, даже чатботы.
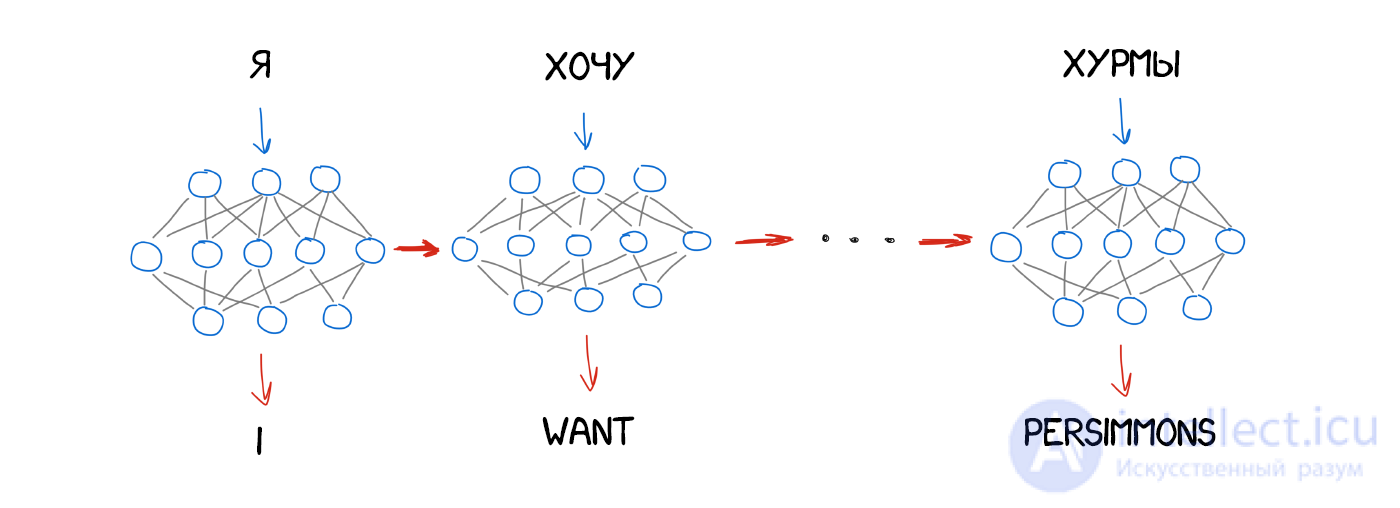
Для задротов типа меня: на самом деле, архитектуры нейронных переводчиков сильно разнятся. Сначала исследователи использовали обычные RNN, потом перешли на двунаправленные — переводчик учитывал не только слова до, но и после нужного слова. Так было куда эффективнее. Потом вообще пошли по-хардкору, используя многослойные RNN с LSTM-ячейками для долгого хранения контекста перевода.
За два года нейросети превзошли все, что было придумано в переводе за последние 20 лет. Нейронный перевод делал на 50% меньше ошибок в порядке слов, на 17% меньше лексических и на 19% грамматических ошибок. Нейросети даже научались сами согласовывать род и падежи в разных языках, никто их этому не учил.
Самые заметные улучшения были там, где никогда не существовало прямого перевода. Методы статистического перевода всегда работали через английский язык. Если вы переводили, например, с русского на немецкий, машина сначала перегоняла текст в английский, а только потом переводила на немецкий. Двойные потери. Нейронному переводу это не нужно — подключай любой декодер и погнали. Впервые стало возможно напрямую переводить между языками, у которых не было ни одного общего словаря.
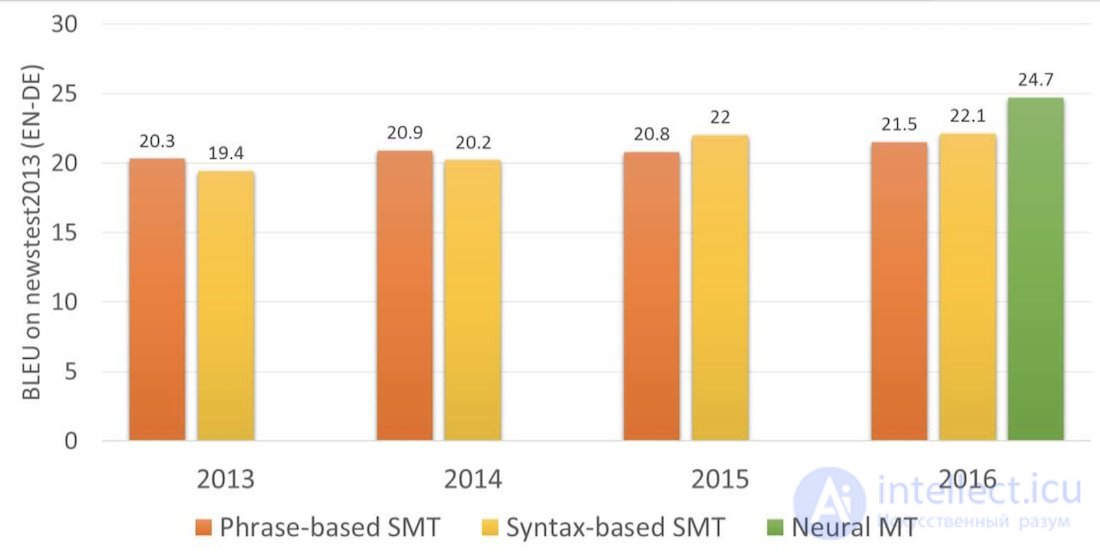
В 2016 году Google включил нейронный перевод девяти языков между собой, в 2017 был добавлен и русский. Google разработал собственную систему под нехитрым названием Google Neural Machine Translation (GNMT), состоявшую аж из 8-слойного RNN на входе и такого же на выходе и системы согласования контекста под названием Attention Model.
При обучении они не просто разбивали предложения по фразам и словам, они делили даже сами слова на части. Этим они пытались решить одну из главных проблем NMT — они беспомощны, когда слова нет в их словарном запасе. Например «Вастрик». Вряд ли кто-то обучал нейросеть переводить мой никнейм. В этом случае GMNT пытается разобрать его на части и склеить из них перевод. Хитро.
Hint: тот Google Translate, который переводит сайты в браузере, все еще использует старый Phrase-based алгоритм. Почему-то Google его не обновляет и на нем очень заметны отличия по сравнению с онлайн-версией.
В онлайн-версии Google Translate сделали еще и механизм краудсорсинга переводов. Сейчас пользователи могут выбрать наиболее правильную по их мнению версию перевода, и если так многим она понравится, Google будет всегда переводить эту фразу именно так, помечая специальным значком. Очень круто работает на коротких повседневных фразах типа «пойдем на обед» или «буду ждать внизу». Гугл знает разговорный английский лучше меня :(
Переводчик Bing от Microsoft работает как полная копия Google Translate. А вот Яндекс отличается.
Яндекс запустил свой нейросетевой перевод в 2017 году. Главным отличием они заявили гибридность. Переводчик Яндекса переводит предложение сразу двумя методами — статистическим и нейросетевым, а потом с помощью их любимого алгоритма CatBoost находит наиболее подходящий.
Дело в том, что нейронный перевод плохо справляется с короткими фразами. Когда вам надо перевести словосочетание типа «сиреневая бетономешалка», нейросети могут нафантазировать лишнего, а простой статистический перевод найдет оба слова тупо, быстро и без проблем.
Других подробностей Яндекс нам не рассказывает, отбиваясь нетехническими пресс-релизами. ШТОШ ЛАДНА.
Судя по всему Google тоже использует SMT для перевода слов и коротких словосочетаний. Они не упоминают это в статьях, но это очевидно по разнице между переводами коротких строк и длинных. Также SMT явно используется для показа статистики слова.
Гибридная технология перевода предполагает использование статистических методов для построения словарных баз автоматическим путем на основе параллельных корпусов, формирования нескольких возможных переводов как на лексическом уровне, так и на уровне синтаксической структуры предложения выходного языка, применения постредактирования в автоматическом режиме и выбор лучшего (наиболее вероятного) перевода из возможных на основе языковой модели, построенной по определенному корпусу выходного языка.
Hybrid (SMT + RBMT) System различаются: (п.2.4.3 )
Статистический МП стремится использовать лингвистические данные, а системы с «классическим» подходом, основанном на правилах, применяют статистические методы. Добавление некоторых "сквозных" правил, то есть создание гибридных систем, несколько[сколько?] улучшает качество переводов, особенно при недостаточном объеме входных данных, используемых при построении индексных файлов хранения лингвистической информации машинного переводчика, базирующегося на N-граммах.[10]
Объединение RBMT и статистического машинного перевода:
Этапы Гибридной технологии SMT и RBMT:
Всех по прежнему будоражит идея «Вавилонской Рыбки» — синхронного перевода речи на лету. Google делала шаг в этом направлении, когда анонсировала Pixel Buds, но на поверку все оказалось плохо. синхронный перевод на лету отличается от обычного, ведь нужно знать места, когда начать переводить, а когда сидеть и слушать. Подходов к решению этой задачи я еще не встречал.
upd: В комментариях отругали, что не вспомнил Skype с переводом на лету. Исправляюсь.
Вот еще одно непаханное поле на мой взгляд: все обучение по прежнему упирается в ограниченный набор параллельных корпусов с текстами. Хваленые глубоченные нейросети все равно обучаются именно на параллельных текстах. Мы не можем обучить нейросеть, не давая ей оригинала. Но человек-то может, начиная с определенного уровня знаний языка, пополнять словарный запас просто от чтения книг или статей, даже не переводя их на свой родной язык.
Если может человек, то и нейросеть, в теории, тоже.
Исследование, описанное в статье про машинный перевод, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое машинный перевод, гибридный перевод, нейронный перевод, статистический перевод, синхронный перевод и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка

Комментарии