Лекция
Сразу хочу сказать, что здесь никакой воды про корпусная лингвистика, и только нужная информация. Для того чтобы лучше понимать что такое корпусная лингвистика, корпус , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
корпус ная лингвистика — раздел языкознания, занимающийся разработкой, созданием и использованием текстовых корпусов (англ. Text corpus). Термин введен в употребление в 1960-е годы в связи с развитием практики создания корпусов, которому начиная с 1980-х способствовало развитие вычислительной техники.
Лингвистическим корпусом называют совокупность текстов, собранных в соответствии с определенными принципами, размеченных по определенному стандарту и обеспеченных специализированной поисковой системой. Иногда корпусом («корпус первого порядка») называют просто любое собрание текстов, объединенных каким-то общим признаком (языком, жанром, автором, периодом создания текстов).
Целесообразность создания текстовых корпусов объясняется:
Первым большим компьютерным корпусом считается Брауновский корпус (БК, англ. Brown Corpus, BC), который был создан в 1960-е годы в Университете Брауна и содержал 500 фрагментов текстов по 2 тысячи слов в каждом, которые были опубликованы на английском языке в США в 1961 году. В результате он задал стандарт в 1 млн словоупотреблений для создания представительных корпусов на других языках. По модели близкой к БК в 1970-е годы был создан частотный словарь русского языка Засориной, построенный на основе корпуса текстов объемом также в 1 миллион слов и включавший примерно в равной пропорции общественно-политические тексты, художественную литературу, научные и научно-популярные тексты из разных областей и драматургию. По аналогичной модели был построен и русский корпус, созданный в 1980-е годы в Университете Уппсалы, Швеция.
Размер в один миллион слов достаточен для лексикографического описания только самых частотных слов, поскольку слова и грамматические конструкции средней частоты встречаются по несколько раз на миллион слов (со статистической точки зрения язык является большим набором редких событий). Так, каждое из таких обыденных слов, как англ. polite (вежливый) или англ. sunshine (солнечный свет) встречается в БК всего 7 раз, выражение англ. polite letter лишь один раз, а такие устойчивые выражения как англ. polite conversation, smile, request ни разу.
По этим причинам, а также в связи с ростом компьютерных мощностей, способных работать с большими объемами текстов, в 1980-е годы в мире было предпринято несколько попыток создать корпуса большего размера. Об этом говорит сайт https://intellect.icu . В Великобритании такими проектами были Банк Английского (Bank of English) в Бирмингемском Университете иБританский Национальный Корпус (British National Corpus, BNC). В СССР таким проектом был Машинный фонд русского языка, создававшийся по инициативеА. П. Ершова.
Наличие большого количества текстов в электронной форме существенно облегчило задачу создания больших представительных корпусов размером в десятки и сотни миллионов слов, но не ликвидировало проблем: сбор тысяч текстов, снятие проблем с авторскими правами, приведение всех текстов в единую форму, балансировка корпуса по темам и жанрам отнимают много времени. Представительные корпуса существуют (или разрабатываются) для немецкого, польского, чешского, словенского, финского, новогреческого, армянского, китайского, японского, болгарского и других языков.
Национальный корпус русского языка, создаваемый при РАН, содержит на сегодняшний день более 300 млн словоупотреблений .
Наряду с представительными корпусами, которые охватывают большой набор жанров и функциональных стилей, в лингвистических исследованиях часто используются и оппортунистические коллекции текстов, например, газеты (часто Wall Street Journal и New York Times), новостные ленты (Рейтер), коллекции художественной литературы (Библиотека Мошкова или Проект Гутенберг).
Корпус состоит из конечного числа текстов, но он призван адекватно отражать лексикограмматические феномены, типичные для всего объема текстов в соответствующем языке (или подъязыке). Для представительности важен как размер, так и структура корпуса. Представительный размер зависит от задачи, поскольку он определяется тем, как много примеров может быть найдено для исследуемых феноменов. В связи с тем, что со статистической точки зрения язык содержит большое число относительно редких слов (Закон Ципфа), для исследования первых пяти тысяч наиболее частотных слов (например, убыток, извиняться) требуется корпус размером около 10-20 миллионов словоупотреблений, в то время как для описания первых двадцати тысяч слов (незатейливый, сердцебиение, роиться) уже требуется корпус свыше ста миллионов словоупотреблений.
К первичной разметке текстов относятся этапы, обязательные для каждого корпуса:
В больших корпусах возникает проблема, которая ранее была неактуальной: поиск по запросу может выдавать сотни и даже тысячи результатов (контекстов употребления), которые просто физически невозможно просмотреть в ограниченное время. Для решения этой проблемы разрабатываются системы, позволяющие группировать результаты поиска и автоматически разбивать их на подмножества (кластеризация результатов поиска), либо выдающие наиболее устойчивыесловосочетания (коллокации) со статистической оценкой их значимости.
В качестве корпуса может использоваться множество текстов, доступных в интернете (то есть миллиарды словоупотреблений для основных мировых языков). Для лингвистов самым распространенным способом работы с Интернетом остается составление запросов к поисковой машине и интерпретация результатов либо по числу найденных страниц, либо по первым возвращенным ссылкам. В английском языке такая методология получила название англ. Googleology , для русского более подходящим названием может стать Яндексология. Необходимо отметить, что такой подход годится для решения ограниченного класса задач, так как средства разметки текстов, используемые в вебе, не описывают ряд лингвистических особенностей текста (указание ударений, грамматических классов, границ словосочетанийи т. д.). Кроме того дело осложняется малой распространенностью семантической верстки.
На практике ограниченность такого подхода приводит к тому, что проверить, например, сочетаемость двух слов проще всего через запрос вида «слово1 слово2». По полученным результатам можно судить, насколько распространено такое сочетание и в каких текстах оно чаще встречается. Вау!! 😲 Ты еще не читал? Это зря! статистика запросов.
Второй способ заключается в автоматическом извлечении большого количества страниц из Интернета и их дальнейшем использовании в качестве обычного корпуса, что дает возможность провести его разметку и использовать лингвистические параметры в запросах. Этот способ позволяет быстро создать представительный корпус для любого языка в достаточной степени представленного в Интернете, но его жанровое и тематическое разнообразие будет отражать интересы пользователей Интернета .
Все большую популярность в научной среде получает использование Википедии — как корпуса текстов .
В 2006 году появился сайт Татоэба (Tatoeba), позволяющий на свободной основе добавлять новые и изменять существующие предложения на различных языках, связанные между собой по смыслу. В его основу лег лишь англо-японский корпус, а уже сейчас число языков превышает 80, а число предложений — 600000 . Любой желающий может добавлять новые предложения и их переводы, а при необходимости — бесплатно скачать целиком или частично все языковые корпуса.

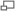
Интерфейс системы разметки Открытого корпуса русского языка
Интерес представляет проект открытого корпуса русского языка, который не только использует опубликованные под свободными лицензиями тексты, но и позволяет любому желающему принять участие в лингвистической разметке корпуса. Такая форма краудсорсинга стала возможной благодаря разбиению задачи разметки на небольшие задания, с большинством из которых может справиться человек без специальной лингвистической подготовки . Корпус постоянно пополняется, все тексты и программное обеспечение , связанные с ним доступны под лицензиями GNU GPL v2 и CC-BY-SA.
А как ты думаешь, при улучшении корпусная лингвистика, будет лучше нам? Надеюсь, что теперь ты понял что такое корпусная лингвистика, корпус и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Из статьи мы узнали кратко, но содержательно про корпусная лингвистика
Комментарии
Оставить комментарий
Обработка естественного языка
Термины: Обработка естественного языка