Лекция
Привет, Вы узнаете о том , что такое алгоритмы исправления опечаток, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
Итак, нам пришел опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
Эта постановка — самая элементарная — предполагает, что если нам пришел запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать P(w|s). Первый вопрос считается простым. В 1990 году словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!
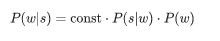
Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные: P(s|w) — вероятность того, что при наборе слова w можно опечататься и получить s, и P(w) — в принципе вероятность использования пользователем слова w.
Как оценить P(s|w)? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумленного канала; в нашем случае зашумленный канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model —
модель ошибок . Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учет как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова — P(w) — можно по-разному. Самый простой вариант — взять за нее частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — еще одна модель. Эта модель называется language model,
модель языка .
Мы предоставляем два типа конвейеров для исправления орфографии: levenshtein_corrector использует простое расстояние Дамерау-Левенштейна для поиска кандидатов на исправление, а brillmoore использует для него статистическую модель ошибок. В обоих случаях кандидаты на исправление выбираются на основе контекста с помощью языковой модели кенлм .
Сравнение автоматической коррекции орфографии для русского языка с использованием разлиных алгоритмов:
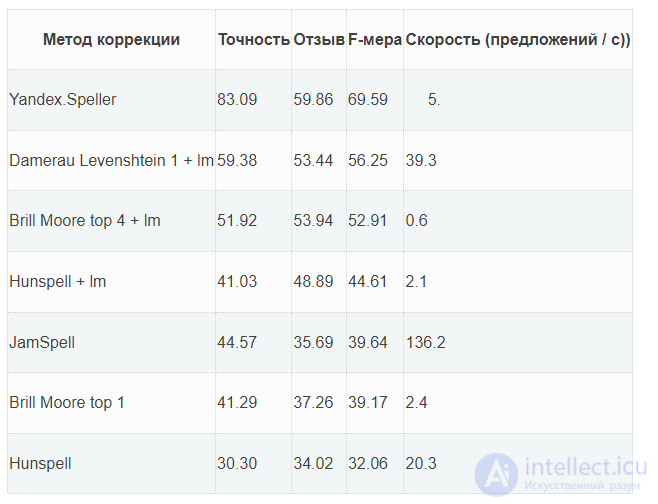
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в нее встраивают механизмы исправления ошибок.
Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления :
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трех. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики . Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше , несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов . Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).
Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.
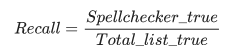
Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.
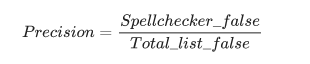
Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье , в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура , либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Первые модели ошибок считали P(s|w), подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее . Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром и многократно использованной впоследствии (например, специалистами Google ). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим P(тся→ться) — это параметр нашей модели. Если для всех возможных фрагментов α,β мы можем посчитать P(α→β), то искомую вероятность P(s|w) набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины P(s|w):

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:
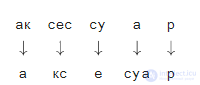
Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины P(ак→а) и P(р→р) еще не так плохи, то P(су→е) и P(а→суа), скорее всего, сделают итоговый «счет» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь все сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной 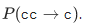 .
.
Несмотря на то, что возможных разбиений для двух слов имеется порядка 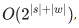 , с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за
, с помощью динамического программирования алгоритм вычисления P(s|w) можно сделать довольно быстрым — за 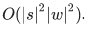 . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведем прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы ее вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие P(α→β). Например, если у нас заполнена таблица
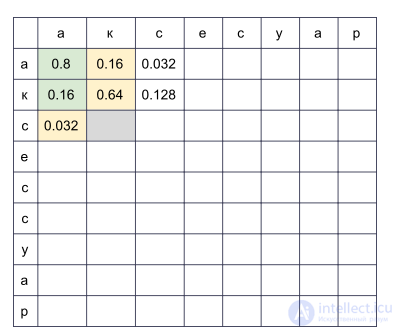
, то для заполнения ячейки в четвертой строке и третьем столбце (серая) нужно взять максимум из величин 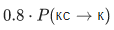 и
и 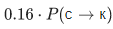 . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зеленым. Если также рассматривать модификации вида пустаястрока P(α→пустая строка) и пустаястрока P(пустая строка→β), то придется пробежаться и по ячейкам, подсвеченным желтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет 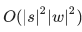 : мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до
: мы заполняем таблицу |s|×|w|, и для заполнения ячейки (i, j) нужно O(i⋅j) операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины L (например, не больше двух букв, как в ), сложность уменьшится до 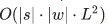 . Для русского языка в своих экспериментах я брал L=3.
. Для русского языка в своих экспериментах я брал L=3.
Мы научились находить P(s|w) за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всем словаре. Причем наилучшие не по P(s|w), а по P(w|s)! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по P(s|w), который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить ее для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмем словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд . А кэширование результатов сделает процесс еще быстрее.
Вычисление P(α→β) для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть ее качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдем много пар (si,wi), где wi — правильное слово из словаря, а si — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмем составляющие ее w и s и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:
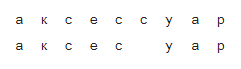
Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее. Об этом говорит сайт https://intellect.icu . Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причем каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам (si,wi) за вероятность P(α→β) принимается количество замен α → β, встретившихся в наших парах (с учетом встречаемости соответствующих слов), деленное на количество повторений фрагмента α.
Как найти пары (si,wi)? В предлагается такой подход. Возьмем большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмем за w, менее популярное — за s. Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В предлагается только фильтр по встречаемости (w в десять раз популярнее, чем s), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом w, найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчетов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трех слов).
Итак, теперь для заданного словарного слова w нам нужно вычислить P(w) — вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчета встречаемости слов в нем. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления P(w1w2…wk), где одно из wi — слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем P(w), а остальные wi — слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу еще раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут все зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы w1w2…wk ее вероятность вычисляется по формуле
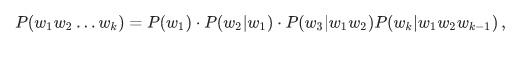
где P(w1) — непосредственно частота слова, а P(w3|w1w2) — вероятность слова w3 при условии, что перед ним идут w1w2 — не что иное, как отношение частоты триграммы w1w2w3 к частоте биграммы w1w2. (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить мамамыларамуP(мама мыла раму), обозначив частоту произвольной n-граммы за f, мы получим формулу
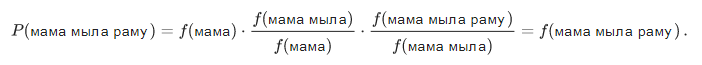
Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввел впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что
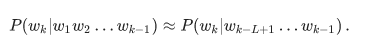
Положив L=3, для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трех. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввел совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить f=0, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьезных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в . Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчет первого из них придется, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова si в нашей фразе найдем с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из NK получившихся фраз, где K — количество слов в исходной фразе, посчитаем честно величину
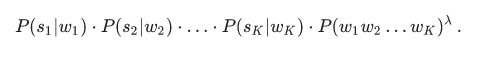
Здесь si — слова, введенные пользователем, wi — подобранные для них исправления (которые мы сейчас перебираем), а λ — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в . Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и еще домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор NK фраз?
К счастью, за счет того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для P(w1w2…wK) так, что она стала зависеть только от частот n-грамм длины не выше трех:
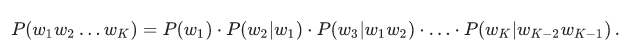
Если мы домножим эту величину на  и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
и попытаемся максимизировать по wK, мы увидим, что достаточно перебрать всевозможные wK−2 и wK−1 и решить задачу для них — то есть для фраз w1w2…wK−2wK−1. Итого задача решается динамическим программированием за O(KN3).
Сразу оговорюсь: данных в моем распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трех символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r"^[a-z0-9]{2}$" — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчете биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадет в словарь...).
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
короткие правки вида сс → с (под спойлером).
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчета
# расстояния восстановить оптимальное расположение букв, будем
#
продолжение следует...
Часть 1 Алгоритмы исправления опечаток с и без учёта контекста
Часть 2 Результаты - Алгоритмы исправления опечаток с и без учёта контекста
Исследование, описанное в статье про алгоритмы исправления опечаток, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Комментарии
Оставить комментарий
Обработка естественного языка
Термины: Обработка естественного языка