Лекция
Привет, Вы узнаете о том , что такое ромип-2006, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое ромип-2006, алгоритм ранжирования, функция ранжирования, ромип , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
На ромип -2006 представители Яндекса несколько приоткрыли завесу тайны по используемым текстовым факторам ранжирования:
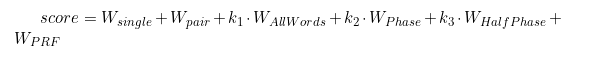
Где:
При подсчете количества вхождений слова в документ мы проводим предварительную лемматизацию слов запроса и слов документа. Использование в качестве меры длины документа максимальной TF среди всех лемм документа ухудшает результат.
Помимо учета количества слов в документе можно учитывать html-форматирование и позицию слова в документе. Мы учитываем это в виде отдельного слагаемого. Учитывается наличие слова в первом предложении, во втором предложении, внутри выделяющих html тегов.
Пара учитывается, когда слова запроса встречаются в тексте подряд (+1), через слово (+0.5) или в обратном порядке (+0.5). Плюс еще специальный случай, когда слова, идущие в запросе через одно, в тексте встречаются подряд (+0.1).
На 2010 год, по словам Дена Расковалова, в Яндексе учитывалось более 420 факторов ранжирования, а приведенные выше – это только малая часть из них.
алгоритм ранжирования проводит лемматизацию слов документа и запроса, поэтому не имеет значения в какой форме будет использоваться слово или его синонимы (разные формы будут считаться за одну и туже лемму). Для запроса была использована строка: «купить айофн с доставкой Бирюлево» (здесь и далее кавычки для того чтоб отделить слова от текста, при запросе их не было). Рассмотрим как будет работать формула для нашего примера и какие параметры будут у первых 4-х сайтов из выдачи Yandex.
Расчет релевантности документа к запросу производится по формуле:
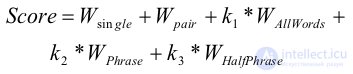
В оригинальной статье использовалось еще дополнительное слагаемое Wprf — за похожесть документа на документы из вершины выдачи, но мы его пока не будем учитывать. В наших расчетах коэффициенты k1, k2, k3 — нам также не известны поэтому предположим, что они равны 1.
1. Об этом говорит сайт https://intellect.icu . Учет отдельных слов:
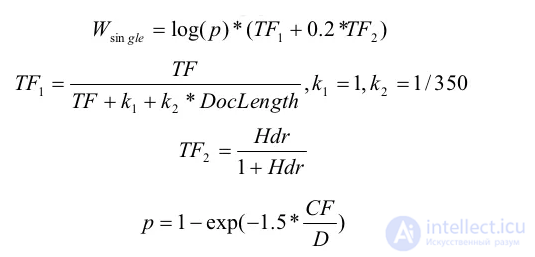
TF — частота вхождения слова в документ ( = число_вхождений_слова / длину_документа). Значения частот для слов из запроса, для каждого из мест в топ выдаче:
DocLength — длина документа в словах;
Hdr — сумма весов слова за форматирование. Согласно авторам статьи:
Учитывается наличие слова в первом предложении, во втором предложении, внутри выделяющих html тегов.
Но какие конкретно числа используются авторы не уточнили (в наших расчетах будем считать этот параметр равным 0).
D — число документов в коллекции. Для получения конкретного значения можно воспользоваться поиском фразы "intellect.icu" с помощью yandex. Полученное при этом количество документов и будем считать за число документов в коллекции. В нашем случае в выдачу попало 2325 млн. документов.
CF — число вхождений слова в коллекцию документов (число документов, в которых слово встретилось хотя-бы раз). Конкретные числа для слов из нашего запроса получились следующими:
Wsingle мы рассчитывали для каждого слова и в Score добавляли их сумму.
2. Учет пар слов:
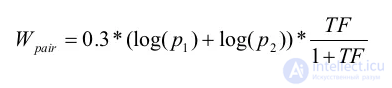
p1, p2 — рассчитываются так-же как и для Wsingle; TF — количество вхождений пары слов, с учетом весов. Пара учитывается, когда слова запроса встречаются в тексте подряд (+1), через слово (+0.5) или в обратном порядке (+0.5). Плюс еще специальный случай, когда слова, идущие в запросе через одно, в тексте встречаются подряд (+0.1).
Остальные пары в документах не встречались.
Учет встречаемости трех и более слов запроса в документе уличшений в наших экспериментах не дал
3. Учет всех слов:
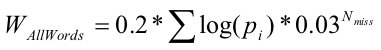
Nmiss — число слов которые не встретились в документе. Для рассматриваемых сайтов это число оказалось одинаковым.
4. Учет запроса целиком:
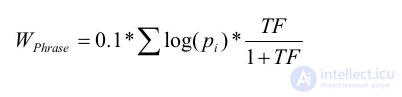
TF — число вхождений запроса целиком, деленное на длину документа. Для топа значение получилось 0 для всех сайтов.
5. Учет части запроса:
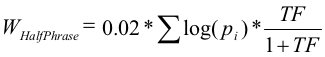
Это слагаемое учитывалось когда сумма idf слов запроса в предложении (в формуле — сумма логарифмов) больше половины суммы idf всех слов запроса. TF здесь – количество учитываемых предложений в тексте деленное на число предложений в документе. Для нашей 4-ки это опять получился 0, т.к. там таких предложений не оказалось. Для сравнения предположим что мы создали документ и хотим рассчитать его релевантность для запроса. Пусть числовые значения для него будут иметь вид:
Остальные значения пусть будут такими же как и топовой четверки. Окончательные числа соберем в таблицу и посмотрим, что получилось. Таблица полученных значений для нашего примера:
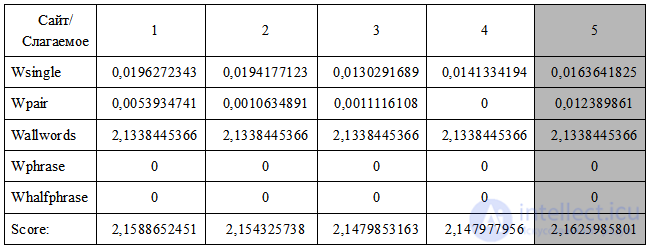
И так можно видеть, что показатель релевантности у созданной странички оказался даже лучше чем у первого места. Это можно объяснить следующими факторами:
I. Часто употребляемые слова слабо влияют на релевантность, или вообще игнорируются. Чем больше раз слово из запроса встречается в документах коллекции, тем менее оно информативно — тем меньше вклад этого слова в релевантность.
Если слово будет только в одном документе из всей коллекции, то вклад этого слова в релевантность будет наибольшим. Если слово встречается в каждом документе 1 или больше раз, то вклад такого слова в релевантность будет равен 0. При этом чем больше документов в коллекции, тем большее количество употреблений допустимо (употребление прямо пропорционально числу документов), при сохранении той же релевантности. Если число документов увеличится в 2 раза, то релевантность сохранится если и частота употребления также увеличится в 2 раза. Поэтому стоит акцентировать внимание лишь на те слова, которые имеют относительно малую частоту, и использовать одно и тоже слово как можно в меньшем числе документов. Ключевые слова стоит выделять с помощью форматирования. Используйте их как можно ближе к началу документа.
II. Одно и тоже ключевое слово не должно употребляться в тексте документа много раз. Важен сам факт его наличия. Зависимость релевантности от частоты слова носит не линейный характер. Общий принцип, что чем чаще встречается слово в документе, тем больше будет его релевантность — верен. Однако начиная с определенного значения увеличение частоты перестает влиять на релевантность. На графике приведено схематическое поведение влияния частоты вхождения слова на релевантность.
Горизонтальная ось — частота слова. Вертикальная — релевантность
Размер документа не должен быть слишком объемным или слишком коротким (желательно таким же как среднее значение остальных документов или меньше).
Частота отдельного слова не должна быть большой, важен сам факт наличия такого слова. Приоритет в количестве различных ключевых слов из тематики документа, их должно быть как можно больше, но из одной определенной тематики, чтобы увеличить шансы документа быть найденным.
III. Используйте ключевые слова в словосочетаниях. Ключевые слова по возможности должны образовывать все возможные парные словосочетания друг с другом. Повторения одинаковых пар стоит избегать. Т.е. как и в пункте II лучше много разных, чем много повторяющихся. На словосочетания длиной больше 3-х слов не стоит акцентировать внимание.
IV. Желательно чтоб слова из потенциальных запросов присутствовали в документе. Не помешает наличие разных ключевых слов по тематике документа. При этом количество одинаковых слов или форм одного и того же слова должно быть как можно меньше.
V. Половина слов в предложениях — тематические. Желательно чтобы каждое предложение содержало половину слов из потенциального запроса. Порядок следования слов стоит согласовать с пунктом III.
VI. Зная какой должна быть релевантность к конкретному запросу мы можем указать конкретные значения для числа вхождений каждого слова. Взяв в качестве значения релевантности запросу оценку для сайтов из топа выдачи можно оптимально подбирать количество вхождений каждого отдельного слова. Из минусов такого подхода — мы становимся зависимыми от конкретного запроса или набора запросов (но это если не учитывать что поисковики расширяют запросы)
Исследование, описанное в статье про ромип-2006, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое ромип-2006, алгоритм ранжирования, функция ранжирования, ромип и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка

Комментарии