Лекция
Привет, Вы узнаете о том , что такое нечеткий поиск дубликатов, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое нечеткий поиск дубликатов, алгоритм шинглов , сравнение текстов, сравнение строк, шинглинг, w-shingling, shingling , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
w-shingling - алгоритм шинглов (от англ. shingles — чешуйки) — алгоритм, разработанный для поиска копий и дубликатов рассматриваемого текста в веб-документе. Инструмент для выявления плагиата.
В естественном языке обработка в алгоритм шинглова представляет собой набор уникальной черепицы (поэтому н-грамм ) , каждый из которых состоит из смежных подпоследовательностей из маркеров в пределах документа , которые затем могут быть использованы для установления подобия между документами . Символ w обозначает количество токенов в каждом выбранном или решенном шингле.
Таким образом, документ "a rose is a rose is a rose" можно максимально токенизировать следующим образом:
(a,rose,is,a,rose,is,a,rose)
Множество всех смежных последовательностей 4 маркеров (таким образом 4 = п , таким образом 4- г ) является
{ (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose) }
Которая затем может быть уменьшена или максимально покрыта черепицей в данном конкретном случае до
{ (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is) }.
Уди Манбер . в 1994 г. первым в мире выразил идею поиска дубликатов, а в 1997 г. Андрей Бродер оптимизировал и довел ее до логического завершения, дав имя данной системе — «алгоритм шинглов».
рассморим реализацию алгоритма, описанную Зеленковым Ю. Г. и Сегаловичем И.В. в публикации «Сравнительный анализ методов определения нечетких дубликатов для Web-документов».
Опишим доступным языком принцип алгоритмов шинглов, супершинглов и мегашинглов для сравнение веб-документов.
В публикации об алгоритмах поиска почти дубликатов предлагается версия алгоритма шинглов, использующая случайную выборку 84х случайных шинглов.
Почему именно 84? Использование 84х случайно выбранных значений контрольных сумм позволит легко модифицировать алгоритм до алгоритма супершинглов и мегашинглов, которые гораздо менее ресурсоемки.
Для данного размера черепицы степень, в которой два документа A и B похожи друг на друга, может быть выражена как отношение величин пересечения и объединения их черепицы , или

где | A | - это размер набора A. Сходство - это число в диапазоне [0,1], где 1 означает, что два документа идентичны. Это определение идентично коэффициенту Жаккара, описывающему сходство и разнообразие выборок.
Рекомендую вооружиться ручкой и листком бумаги и фигурально представлять в виде рисунка каждый из этапов, описанных ниже.
Итак, алгоритм шинглов для веб-документов
Разберем, через какие этапы проходит текст, подвергшийся сравнению:
Канонизация текста приводит оригинальный текст к единой нормальной форме. Текст очищается от предлогов, союзов, знаков препинания, HTML тегов, и прочего ненужного «мусора», который не должен участвовать в сравнении. В большинстве случаев также предлагается удалять из текста прилагательные, так как они не несут смысловой нагрузки.
Также на этапе канонизации текста можно приводить существительные к именительному падежу, единственному числу, либо оставлять от них только корни
Текст очищается от предлогов, союзов, знаков препинания, HTML тегов, и прочего не нужного «мусора», который не должен участвовать в сравнении. В большинстве случаев так же предлагается удалять из текста прилагательные, так как они не несут смысловой нагрузки.
Так же на этапе канонизации текста можно приводить существительные к именительному падежу, единственному числу, либо оставлять от них только корни.
С канонизацию текста можно экспериментировать и экспериментировать, простор для действий тут широк.
На выходе имеем текст, очищенный от «мусора», и готовый для сравнения.
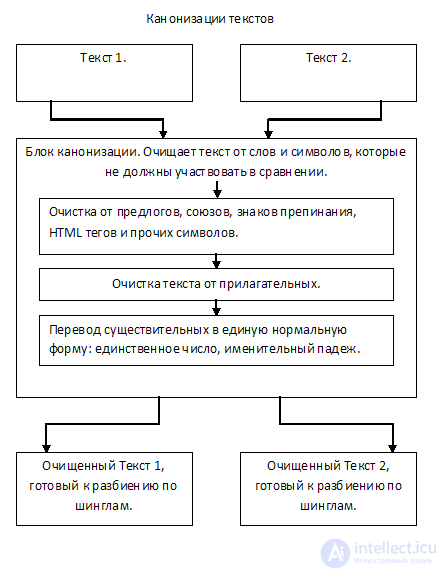
Шинглы — это чешуйки, выделенные из статьи подпоследовательности слов.
Необходимо из сравниваемых текстов выделить подпоследовательности слов, идущих друг за другом по 10 штук (длина шингла). Выборка происходит внахлест, а не встык.
Таким образом, разбивая текст на подпоследовательности, мы получим набор шинглов в количестве равному количеству слов минус длина шингла плюс один (кол_во_слов — длина_шингла + 1).
Напоминаю, что действия по каждому из пунктов выполняются для каждого из сравниваемых текстов.
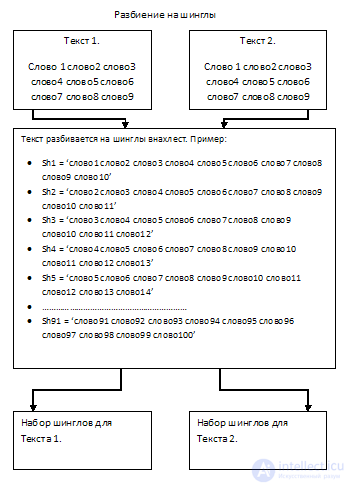
Вот этот этап самый интересный. Принцип алгоритма шинглов заключается в сравнении случайной выборки контрольных сумм шинглов (подпоследовательностей) двух текстов между собой.
Проблема алгоритма заключается в количестве сравнений, ведь это напрямую отражается на производительности. Увеличение количества шинглов для сравнения характеризуется экспоненциальным ростом операций, кто критически отразится на производительности.
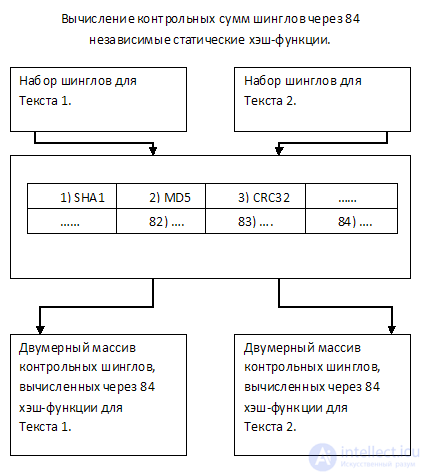
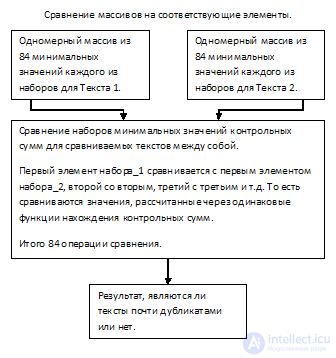
Предлагается представить текст в виде набора контрольных сумм, рассчитанных через 84х уникальные между собой статические хэш функции.
Поясню: для каждого шингла рассчитывается 84 значения контрольной суммы через разные функции (например SHA1, MD5, CRC32 и т.д., всего 84 функции). Итак каждый из текстов будет представлен, можно сказать, в виде двумерного массива из 84х строк, где каждая строка характеризует соответствующую из 84х функций контрольных сумм.
Из полученных наборов будут случайным образом отобраны 84 значения для каждого из текстов и сравнены между собой в соответствии функции контрольной суммы, через которую каждый из них был рассчитан. Об этом говорит сайт https://intellect.icu . Таким образом, для сравнения будет необходимо выполнить всего 84 операции.
Как я описывал выше, сравнивать элементы каждого из 84х массивов между собой — ресурсоемко. Для увеличения производительности выполним случайную выборку контрольных сумм для каждой из 84х строк двумерного массива, для обоих текстов. Например, будем выбирать самое минимальное значение из каждой строки.
Итак, на выходе имеем набор из минимальных значений контрольных сумм шинглов для каждой из хэш функций.
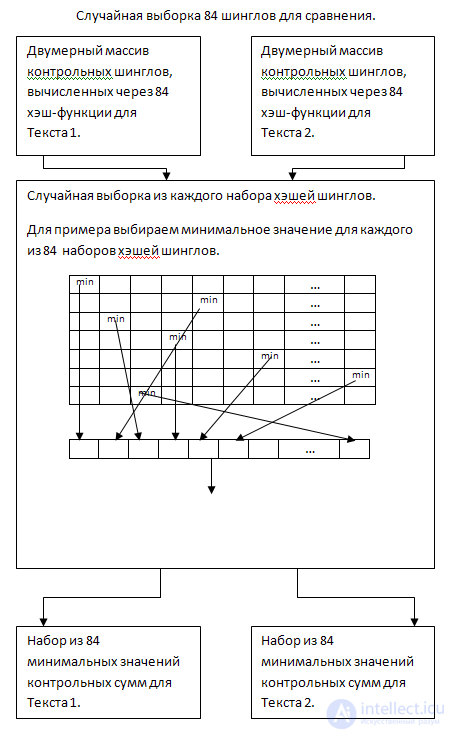
И последний этап — сравнение. Сравниваем между собой 84 элемента первого массива с соответствующими 84ю элементами второго массива, считаем отношение одинаковых значений, из этого получаем результат.
Алгоритм шинглов используется для поиска “похожих документов” и определения степени похожести двух текстов. Например, у вас есть сотня текстов (допустим это статьи или новости) и вам нужно найти рерайты. Т.е. тексты, которые не абсолютно идентичны между собой, но в какой-то степени похожи. Алгоритм шинглов можно использовать, чтобы найти “перепечатки” текстов или, например, чтобы сгруппировать новости по сюжетам (привет сервису Яндекс.Новости). Несмотря на то, что в своем базовом исполнении алгоритм довольно простой, существует множество способов сделать его сложным и множество разных вариаций – супершинглы, мегашинглы… Мы реализуем базовый вариант этого алгоритма без особых заморочек на PHP.
Итак, у нас есть два текста. Нам нужно определить являются ли они похожими. Что мы делаем?
Давайте посмотрим как работает алгоритм на небольшом примере. Допустим у нас есть два каких-то текста.
Чтобы иметь стройную фигуру, вы должны заниматься спортом и правильно питаться. Приходите в спортивный зал “Огонек” — будьте здоровыми и красивыми!
Девушки! Приходите в спортивный клуб “Бабочка”. У нас много тренажеров и опытные инструктора, которые подскажут вам как заниматься спортом и правильно питаться, чтобы иметь стройную фигуру и бодрый дух.
На лицо рерайт. Тексты не одинаковые, но похожие. Возьмем первые текст и очистим его, получится следующее:
чтобы иметь стройную фигуру вы должны заниматься спортом правильно питаться приходите спортивный зал огонек будьте здоровыми здоровыми
девушки приходите спортивный клуб бабочка нас много тренажеров опытные инструктора которые подскажут вам заниматься спортом правильно питаться чтобы иметь стройную фигуру бодрый дух
Составляем шинглы (последовательности слов). Пускай один шингл у нас будет состоять из 3 слов. Тогда для первого текста мы получим следующие последовательности:
|
1 2 3 4 5 6 7 8 9 |
Array ( => чтобы иметь стройную => иметь стройную фигуру => стройную фигуру вы => фигуру вы должны => вы должны заниматься // и так далее... ) |
Обратите внимание, что шинглы у меня идут “внахлест”, а не “в стык”. Размер шинглов (т.е. сколько слов в последовательности), “в стык” или “внахлест”, если последнее, то сколько слов сконца будет входить в начало следующего шингла — все это вопросы индивидуальной настройки алгоритма под ваши задачи. А теперь найдем контрольные суммы, для этих шинглов. Воспользуемся функций crc32() и получим следующее:
|
1 2 3 4 5 6 7 8 9 |
Array ( => 281830324 => 1184612177 => -30086073 => -811305747 => -308857406 // и так далее... ) |
Тоже самое проделывается со вторым текстом, после чего мы ищем одинаковые контрольные суммы. В нашем случае одинаковыми последовательностями, которые присутствуют в обоих текстах, будут:
|
1 2 3 4 5 6 |
Array ( [13] => заниматься спортом правильно // 964071158 [14] => спортом правильно питаться // 2144093920 [18] => иметь стройную фигуру // 1184612177 ) |
Таким образом, если мы разделим кол-во одинаковых шинглов на их общее кол-во и умножим на 100, получим процент одинаковых шинглов. В примере это 13.04%. Обратите внимание, что это процент одинаковых шинглов, а не процент похожести текстов. Есть разница. Саму эту границу “похожести” вы определяете самостоятельно. Я применяю этот алгоритм, немного доработанный, в системе мониторинга новостей для группировки новостей по сюжетам. В моем случае, оказываться что если процент более 10%, то новости об одном событии.
Итак, сперва нам нужна функция канонизации, т.е. очистки текста от всякого мусора. Вот она:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function canonize($text) { $words = explode(' ', $text) ;
$result = array() ; foreach($words as $k=>$w) { $w = strtolower($w) ; $w = preg_replace(self::$filter, '', $w) ;
if(!empty($w)) { $result[] = trim($w); ; } }
return $result ; } |
И так, после прогона текста по этой функции мы имеем текст очищенный от всякого мусора. Теперь надо разбить его на шинглы и найти контрольные суммы для них. Это все в одной функции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function shinglesGen(array $words) { $wordsLen = count($words) ; $shinglesCount = $wordsLen - (3 - 1) ;
$shingles = array() ; for($i=0; $i < $shinglesCount; $i++) { $sh = array() ; for($k=$i; $k < $i + 3; $k++) { $sh[] = $words[$k] ; } $shingles[] = crc32( implode(' ', $sh) ) ; } return $shingles ; } |
Ну вот, теперь у нас есть массив контрольных сумм. Нам нужно найти пересечение двух таких массивов (от двух текстов), чтобы найти общие последовательности.
|
1 |
$intersection = array_intersect($shingles1, $shingles2) ; |
В переменной $intersection у нас теперь массив с общими для двух текстов последовательностями слов. Мы можем найти процент общих последовательностей от их общего количества и выдать процент “общего”. Если этот процент достаточно большой (границу вы определяете сами) — то смело называем такие тексты похожими. Вот и все. Напоследок даю полный вариант всего кода оформленного в виде класса.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
class Shingles {
const SHINGLES_LEN = 3 ;
public static function analyze ($source1, $source2) { $words1 = self::canonize($source1) ; $shingles1 = self::shinglesGen($words1) ;
$words2 = self::canonize($source2) ; $shingles2 = self::shinglesGen($words2) ;
$intersection = array_intersect($shingles1, $shingles2) ;
$intersectionPercent = (count($intersection) / count($words1)) * 100 ;
return $intersectionPercent ; }
private static function canonize($text) { $words = explode(' ', $text) ;
$result = array() ; foreach($words as $k=>$w) { $w = strtolower($w) ; $w = preg_replace(self::$filter, '', $w) ;
if(!empty($w)) { $result[] = trim($w); ; } }
return $result ; }
private static function shinglesGen($words) { $wordsLen = count($words) ; $shinglesCount = $wordsLen - (self::SHINGLES_LEN - 1) ;
$shingles = array() ;
for($i=0; $i < $shinglesCount; $i++) { $sh = array() ; for($k=$i; $k < $i + self::SHINGLES_LEN; $k++) { $sh[] = $words[$k] ; }
$shingles[] = crc32( implode(' ', $sh) ) ; }
return $shingles ; }
private static $filter = array( '/,/', '/\./', '/\!/', '/\?/', '/\(/', '/\)/', '/-/', '/—/', '/:/', '/;/', '/"/',
'/^это$/', '/^как$/', '/^так$/', '/^в$/', '/^на$/', '/^над$/', '/^к$/', '/^ко$/', '/^до$/', '/^за$/', '/^то$/', '/^с$/', '/^со$/', '/^для$/', '/^о$/', '/^ну$/', '/^же$/', '/^ж$/', '/^что$/', '/^он$/', '/^она$/', '/^б$/', '/^бы$/', '/^ли$/', '/^и$/', '/^у$/' ) ;
} |
|
1 2 3 4 5 6 |
require_once "shingles.php" ;
$text = "Текст для сравнения номер один" ; $text2 = "Текст для сравнения номер два" ;
echo Shingles::analyze($text2, $text) ; // выведет 25 (25% общих последовательностей) |
Вот и все. Даже в таком простом исполнении все отлично работает.
Если этого мало, на этапе канонизации можно не только удалять предлоги, знаки препинания, но и переводить слова в нормальную форму – т.е. в именительный падеж, единственное число. Глаголы — в инфинитив.
Алгоритм довольно ресурсоемкий. Если вам нужно сравнить не два текста, а выделить группу похожих текстов из 100 или 1000. Позабодьтесь о том, чтобы не находить шинглы повторно, если для данного текста вы их уже делали. Сохраняйте в БД, например.
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области нечеткий поиск дубликатов имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое нечеткий поиск дубликатов, алгоритм шинглов , сравнение текстов, сравнение строк, шинглинг, w-shingling, shingling и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии