Лекция
Привет, Вы узнаете о том , что такое n-граммы, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое n-граммы, триграмма, биграмма, коллокация , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
N-грамма — последовательность из n элементов . С семантической точки зрения, это может быть последовательность звуков, слогов, слов или букв. На практике чаще встречается N-грамма как ряд слов, устойчивые словосочетания называют коллокацией. Последовательность из двух последовательных элементов часто называют биграмма , последовательность из трех элементов называется триграмма . Не менее четырех и выше элементов обозначаются как N-грамма, N заменяется на количество последовательных элементов.
Биграмма - это комп. последовательность из двух элементов
Биграмма - это клингв. пара последовательных звуков, слогов, слов или букв
В современной компьютерной лингвистике биграммы, или в общем случае
n-граммы , являются важным статистическим инструментом. В статье мы расскажем с какими трудностями можно столкнуться при расчете биграмм на большом корпусе текстов и приведем алгоритм, который можно использовать на любом домашнем компьютере.Иногда в тексте мы позволим себе использовать термин двусочетание в качестве синонима к слову биграмма.
N-граммы в целом находят свое применение в широкой области наук. Они могут применяться, например, в области теоретической математики, биологии, картографии, а также в музыке. Наиболее часто использование N-грамм включает следующие области:
Также N-граммы широко применяются в обработке естественного языка.
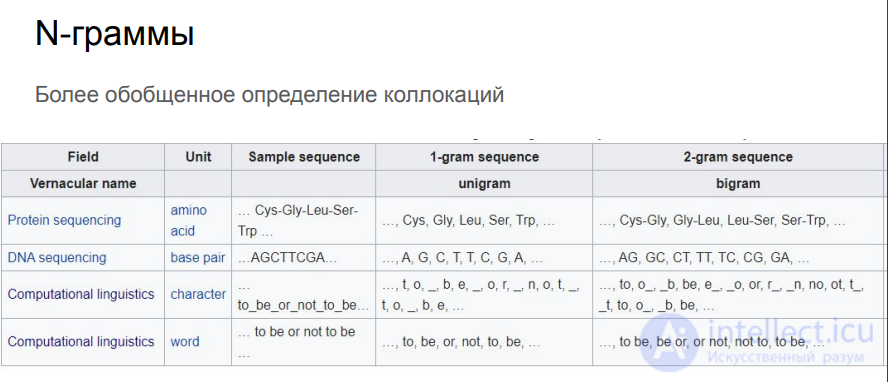
В области обработки естественного языка N-граммы используется в основном для предугадывания на основе вероятностных моделей. N-граммная модель рассчитывает вероятность последнего слова N-граммы, если известны все предыдущие. При использовании этого подхода для моделирования языка предполагается, что появление каждого слова зависит только от предыдущих слов .
Другим применением N-грамм является выявление плагиата. Если разделить текст на несколько небольших фрагментов, представленных N-граммами, их легко сравнить друг с другом и таким образом получить степень сходства анализируемых документов . N-граммы часто успешно используются для категоризации текста и языка. Кроме того, их можно использовать для создания функций, которые позволяют получать знания из текстовых данных. Используя N-граммы, можно эффективно найти кандидатов, чтобы заменить слова с ошибками правописания.
Целью построения N-граммных моделей является определение вероятности употребления заданной фразы. Эту вероятность можно задать формально как вероятность возникновения последовательности слов в неком корпусе (наборе текстов). К примеру, вероятность фразы «счастье есть удовольствие без раскаяния» можно вычислить как произведение вероятностей каждого из слов этой фразы:
P = P(счастье) * P(есть|счастье) * P(удовольствие|счастье есть) * P(без|счастье есть удовольствие) * P(раскаяния|счастье есть удовольствие без)
Чтобы определить P(счастье), нужно посчитать, сколько раз это слово встретилось в тексте, и поделить это значение на общее число слов. Рассчитать вероятность P(раскаяния|счастье есть удовольствие без) сложнее. Чтобы упростить эту задачу, примем, что вероятность слова в тексте зависит только от предыдущего слова. Об этом говорит сайт https://intellect.icu . Тогда наша формула для расчета фразы примет следующий вид:
P = P(счастье) * P(есть|счастье) * P(удовольствие|есть) * P(без|удовольствие) * P(раскаяния|без)
Рассчитать условную вероятность P(есть|счастье) несложно. Для этого считаем количество пар 'счастье есть', и делим на количество в тексте слова 'счастье'.
В результате, если мы посчитаем все пары слов в некотором тексте, мы сможем вычислить вероятность произвольной фразы. Этот набор рассчитанных вероятностей и будет биграммной моделью.
Исследовательские центры Google использовали N-граммные модели для широкого круга исследований и разработок. К ним относятся такие проекты, как статистический перевод с одного языка на другой, распознавание речи, исправление орфографических ошибок, извлечение информации и многое другое. Для целей этих проектов были использованы текстовые корпусы, содержащие несколько триллионов слов.
Google решила создать свой учебный корпус. Проект называется Google teracorpus и он содержит 1 * 10^12 слов, собранных с общедоступных веб-сайтов .
В связи с частым использованием N-грамм для решения различных задач необходим надежный и быстрый алгоритм для извлечения их из текста. Подходящий инструмент для извлечения N-грамм должен быть в состоянии работать с неограниченным размером текста, работать быстро и эффективно использовать имеющиеся ресурсы. Есть несколько методов извлечения N-грамм из текста. Эти методы основаны на разных принципах:
Синтаксические N-граммы — это N-граммы, определяемые путями в деревьях синтаксических зависимостей или деревьях составляющих, а не линейной структурой текста . Например, предложение: «Экономические новости оказывают незначительное влияние на финансовые рынки» может быть преобразовано в синтаксические N-граммы, следуя древовидной структуре его отношений зависимостей: новости-экономические, влияние-незначительное, влияние-на-рынки-финансовые и другие .
Синтаксические N-граммы отражают синтаксическую структуру в отличие от линейных N-грамм и могут использоваться в тех же приложениях, что и линейные N-граммы, в том числе в качестве признаков в векторной модели. Применение синтаксических N-грамм дает лучшие результаты при решении определенных задач, чем использование стандартных N-грамм, например, для определения авторства
Применение N грамов



Пример
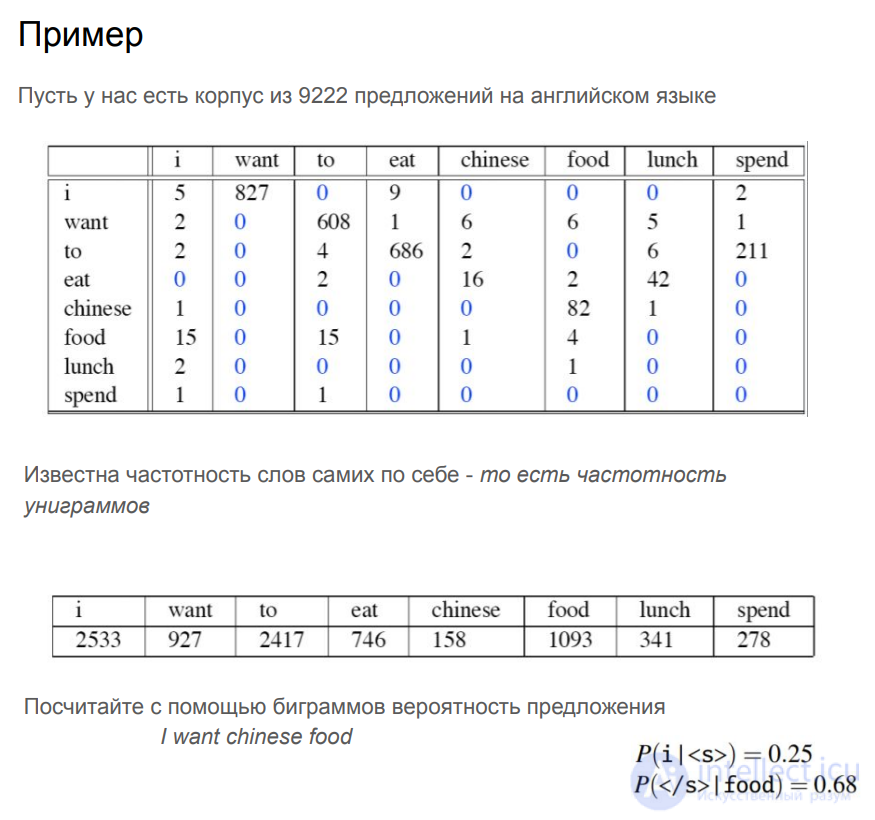
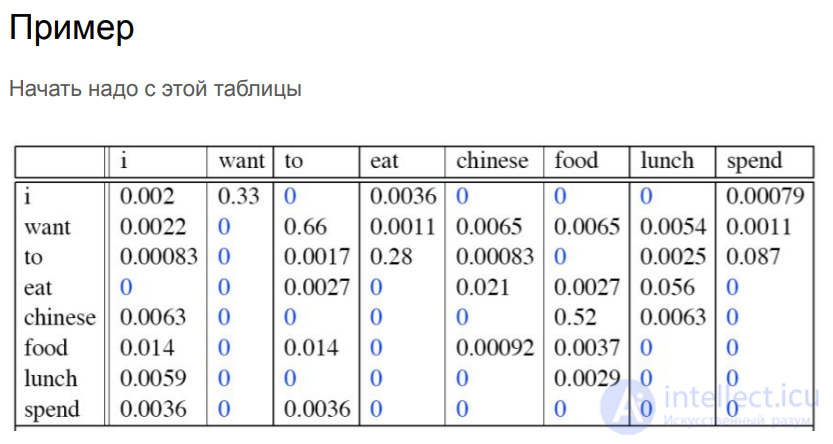

Коллокацией называется словосочетание, имеющее признаки синтаксически и семантически целостной единицы, в котором выбор одного из компонентов осуществляется по смыслу, а выбор второго зависит от выбора первого (например, ставить условия — выбор глагола ставить определяется традицией и зависит от существительного условия, при слове предложение будет другой глагол — вносить).
К коллокациям также обычно причисляют составные топонимы, антропонимы и другие часто совместно употребляемые именования (например, крейсер «Аврора», завод имени Кирова).
Другое наименование того же явления — устойчивые, или фразеологические словосочетания, N-граммы.
Статистический подход Коллокация – это привычное, традиционное сочетание слов в речи, звучащее правильно, естественно для носителей языка. Характерные, часто встречающиеся сочетания слов, появление которых рядом друг с другом основывается на регулярном характере взаимного ожидания. Показатель: частота совместной встречаемости
6 Меры ассоциации Показатели силы синтагматической связи между элементами словосочетаний. Исходные данные: частота совместной встречаемости, частоты слов или словоформ (node – ключевое слово, collocate – слово, встречающееся слева или справа от ключевого, коллокат). Меры ассоциации: MI (mutual information), t- score, z-score, log-likelihood, Odds, Dice, X 2 … (см. Корпуса как источники достоверных данных о частотах.


Примеры

В отличие от идиом (подложить свинью, темна вода в облацех и т. п.) коллокации широко распространены, без них невозможно говорить по-русски.
Слово, которое сохраняет свое значение, называется ключевым, или свободным компонентом: слово влияние в оказывать влияние, слово смысл в сочетании глубокий смысл. Свободный компонент порождается по обычным правилам порождения речи: подбирается по значению в зависимости от выражаемого смысла.
Слово, выбор которого определяется традицией, зависит от ключевого компонента и должен храниться в памяти (в словаре), называется несвободным компонентом. Для того, чтобы выбрать правильный глагол при слове влияние, необходимо не только представлять, какой смысл нужно выразить (смысл «делать»), но и помнить (или узнать из словаря), что это глагол оказывать, а не делать, не производить, не создавать.
Большая часть коллокаций выражает ограниченное количество стандартных смыслов, названных в модели «Смысл — Текст» лексическими функциями: оказывать влияние — это функция Oper, глубокое потрясение — Magn и т. п.
Коллокации по синтаксически главному слову делятся на:
Коллокации также могут классифицироваться в зависимости от функционального стиля, в котором они употребляются. Большинство коллокаций — книжные: научные (вести исследования), официально-деловые (выносить приговор), газетно-публицистические (энтузиазм охватил). Но есть и разговорные (нести ерунду, молоть чушь).
По лексическому составу коллокации делятся на :
У несоставных коллокаций смысл полностью отличается от ее составных частей. Это, как правило, идиомы и идиоматические выражения. Например, дать дуба, наставить рога и пр.
Незаменяемые коллокации не допускают синонимическую замену одного слова другим. В этот класс входят устойчивые обороты и метафоры. Например, белое вино нельзя заменить на прозрачное вино или желтое вино и пр.
Неизменяемые коллокации содержат жесткие связи между словами, не разрешающие их изменять с помощью дополнительной лексики или замены грамматической функции. Например, сердце в пятки не заменить на сердце в пятку, а (ходить) вокруг да около — на (ходить) вокруг дома да около.
Еще одна классификация коллокаций — на разрывные и неразрывные. В разрывные коллокации могут попадать второстепенные слова (жизнь кипит и жизнь его кипит, жизнь его постоянно кипит и пр.).
Коллокации выявляются при лексическом анализе текста. Статистические методы, отмечающие частоту совместного употребления, могут помочь их обнаружить в весьма малой степени. Некоторые статистические методы получения коллокаций:
Применение коллокации

Исследование, описанное в статье про n-граммы, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое n-граммы, триграмма, биграмма, коллокация и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Комментарии
Оставить комментарий
Обработка естественного языка
Термины: Обработка естественного языка