Лекция
Привет, Вы узнаете о том , что такое векторная модель, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое векторная модель, vector space model, косинусное сходство , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
векторная модель (англ. vector space model) — в информационном поиске представление коллекции документов векторами из одного общего для всей коллекции векторного пространства.
Векторная модель является основой для решения многих задач информационного поиска, как то: поиск документа по запросу, классификация документов, кластеризация документов.
Документ в векторной модели рассматривается как неупорядоченное множество термов. Термами в информационном поиске называют слова, из которых состоит текст, а также такие элементы текста, как, например, 2010, II-5 или Тянь-Шань.
Различными способами можно определить вес терма в документе — «важность» слова для идентификации данного текста. Например, можно просто подсчитать количество употреблений терма в документе, так называемую частоту терма, — чем чаще слово встречается в документе, тем больший у него будет вес. Если терм не встречается в документе, то его вес в этом документе равен нулю.
Все термы, которые встречаются в документах обрабатываемой коллекции, можно упорядочить. Если теперь для некоторого документа выписать по порядку веса́ всех термов, включая те, которых нет в этом документе, получится вектор, который и будет представлением данного документа в векторном пространстве. Размерность этого вектора, как и размерность пространства, равна количеству различных термов во всей коллекции, и является одинаковой для всех документов.
Более формально
dj = (w1j, w2j, …, wnj)
где dj — векторное представление j-го документа, wij — вес i-го терма в j-м документе, n — общее количество различных термов во всех документах коллекции.
Располагая таким представлением для всех документов, можно, например, находить расстояние между точками пространства и тем самым решать задачу подобия документов — чем ближе расположены точки, тем больше похожи соответствующие документы. В случае поиска документа по запросу, запрос тоже представляется как вектор того же пространства — и можно вычислять соответствие документов запросу.
Для полного определения векторной модели необходимо указать, каким именно образом будет отыскиваться вес терма в документе. Существует несколько стандартных способов задания функции взвешивания:
Косинусное сходство — это мера сходства между двумя векторами предгильбертового пространства, которая используется для измерения косинуса угла между ними.
Если даны два вектора признаков, A и B, то косинусное сходство, cos(θ), может быть представлено используя скалярное произведение и норму:

В случае информационного поиска, косинусное сходство двух документов изменяется в диапазоне от 0 до 1, поскольку частота терма (веса tf-idf) не может быть отрицательной. Угол между двумя векторами частоты терма не может быть больше, чем 90°.
Одна из причин популярности косинуснуго сходства состоит в том, что оно эффективно в качестве оценочной меры, особенно для разреженных векторов, так как необходимо учитывать только ненулевые измерения.
теории подобия документов , путем сравнения отклонения углов между каждым вектором документа и исходным вектором запроса, где запрос представлен как вектор с той же размерностью, что и векторы, которые представляют другие документы.
На практике проще вычислить косинус угла между векторами, чем сам угол:

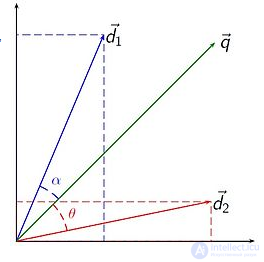
где  является пересечением (то есть скалярным произведением ) вектора документа (d 2 на рисунке справа) и вектора запроса (q на рисунке),
является пересечением (то есть скалярным произведением ) вектора документа (d 2 на рисунке справа) и вектора запроса (q на рисунке), - норма вектора d 2 , а
- норма вектора d 2 , а - норма вектора q. Об этом говорит сайт https://intellect.icu . Норма вектора вычисляется так:
- норма вектора q. Об этом говорит сайт https://intellect.icu . Норма вектора вычисляется так:

Используя косинус, сходство между документом d j и запросом q можно рассчитать как:

Поскольку все векторы, рассматриваемые в этой модели, являются неотрицательными по элементам, значение косинуса, равное нулю, означает, что вектор запроса и документа ортогональны и не имеют совпадений (т. Е. Термин запроса не существует в рассматриваемом документе). Смотрите косинусное подобие для получения дополнительной информации.
«Мягкая» косинусная мера — это «мягкая» мера сходства между двумя векторами, то есть мера, которая учитывает сходства между парами признаков. Традиционное косинусное сходство рассматривает признаки векторной модели как независимые или полностью обособленные, тогда как «мягкая» косинусная мера учитывает сходства признаков в векторной модели. Это позволяет обобщить идею косинусной меры, а также идею сходства объектов в векторном пространстве («мягкое» сходство).
Например, в области обработки естественного языка сходство между объектами весьма интуитивно. Такие признаки как слова, N-граммы или синтаксические N-граммы могут быть довольно схожи, хотя формально они считаются различными признаками в векторной модели. Например, слова «играть» и «игра» различны и, таким образом, отображаются в различных измерениях в векторной модели, хотя, очевидно, что они связаны семантически. В случае N-грамм или синтаксических N-грамм может быть применено расстояние Левенштейна (кроме того, расстояние Левенштейна может быть также применено и к словам).
Для расчета «мягкой» косинусной меры вводится матрица s сходства между признаками. Она может рассчитываться, используя расстояние Левенштейна или другие меры сходства, например, различные меры сходства в Wordnet. Затем производится умножение с применением данной матрицы.
Если даны два N-мерных вектора a и b, то мягкая косинусная мера рассчитывается следующим образом:

где sij = сходство(признакi, признакj).
При отсутствии сходства между признаками (sii = 1, sij = 0 для i ≠ j)), данное уравнение эквивалентно общепринятой формуле косинусного сходства.
Степень сложности этой меры является квадратичной, что делает ее вполне применимой к задачам реального мира. Степень сложности может быть также трансформирована в линейную.
В классической модели векторного пространства, предложенной Салтоном , Вонгом и Янгом , веса терминов в векторах документа являются произведениями локальных и глобальных параметров. Эта модель известна как частотно-обратная частотная модель документа . Вектор веса для документа d равен , где
, где

и
 частота термина t в документе d (локальный параметр)
частота термина t в документе d (локальный параметр) - обратная частота документа (глобальный параметр).
- обратная частота документа (глобальный параметр).  - общее количество документов в наборе документов;
- общее количество документов в наборе документов;  - количество документов, содержащих термин t .
- количество документов, содержащих термин t .Модель векторного пространства имеет следующие преимущества перед стандартной булевой моделью :
Большинство этих преимуществ является следствием разницы в плотности представления коллекции документов между логическим подходом и подходом, обратным частотности термина. При использовании логических весов любой документ лежит в вершине n-мерного гиперкуба . Следовательно, возможные представления документов: а максимальное евклидово расстояние между парами равно
а максимальное евклидово расстояние между парами равно  . По мере добавления документов в коллекцию документов область, определяемая вершинами гиперкуба, становится более населенной и, следовательно, более плотной. В отличие от логического значения, когда документ добавляется с использованием весов частот, обратных к частоте, обратные частоты терминов в новом документе уменьшаются, в то время как частота остальных терминов увеличивается. В среднем по мере добавления документов область расположения документов расширяется, регулируя плотность представления всей коллекции. Такое поведение моделирует исходную мотивацию Солтона и его коллег, согласно которой коллекция документов, представленная в области с низкой плотностью, может дать лучшие результаты поиска.
. По мере добавления документов в коллекцию документов область, определяемая вершинами гиперкуба, становится более населенной и, следовательно, более плотной. В отличие от логического значения, когда документ добавляется с использованием весов частот, обратных к частоте, обратные частоты терминов в новом документе уменьшаются, в то время как частота остальных терминов увеличивается. В среднем по мере добавления документов область расположения документов расширяется, регулируя плотность представления всей коллекции. Такое поведение моделирует исходную мотивацию Солтона и его коллег, согласно которой коллекция документов, представленная в области с низкой плотностью, может дать лучшие результаты поиска.
Модель векторного пространства имеет следующие ограничения:
Однако многие из этих трудностей можно преодолеть за счет интеграции различных инструментов, включая математические методы, такие как разложение по сингулярным числам, и лексические базы данных, такие как WordNet .
Модели, основанные на модели векторного пространства и расширяющие ее, включают:
Следующие ниже программные пакеты могут быть интересны тем, кто хочет поэкспериментировать с векторными моделями и реализовать на их основе поисковые сервисы.
Исследование, описанное в статье про векторная модель, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое векторная модель, vector space model, косинусное сходство и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Комментарии
Оставить комментарий
Обработка естественного языка
Термины: Обработка естественного языка