Лекция
Сразу хочу сказать, что здесь никакой воды про bm15 , и только нужная информация. Для того чтобы лучше понимать что такое bm15 , bm11 , bm25 , bm25f, алгоритм ранжирования, функция ранжирования, тошнота документа по минычу , настоятельно рекомендую прочитать все из категории Обработка естественного языка.
Okapi bm25 — функция ранжирования , используемая поисковыми системами для упорядочивания документов по их релевантности данному поисковому запросу. Она основывается на вероятностной модели, разработанной в 1970-х и 1980-х годах Стивеном Робертсоном, Карен Спарк Джонс и другими.
Сама функция носит название BM25 (BM от англ. best match), но ее часто называют «Okapi BM25» по названию поисковой системы Okapi, созданной в Лондонском городском университете в 1980-х и 1990-х годах, в которой эта функция была впервые применена.
BM25 и его различные более поздние модификации (например, bm25f ) представляют собой современные TF-IDF-подобные функции ранжирования, широко используемые на практике в поисковых системах. В веб-поиске эти функции ранжирования часто входят как компоненты более сложной, часто машинно-обученной, функции ранжирования.
BM25 – функция расчета текстовой релевантности документов, разработанная британцами Стивеном Робертсоном и Карен Спарк Джоунс, опубликованная в 1994 году. Основана на эмпирических данных при попытке улучшить результаты работы критерия TF-IDF. Наилучшее соответствие между ожидаемым результатом и рассчитанным показал 25 алгоритм в списке, за что и получил свое название «Best matching», или BM25. Впервые был реализован в поисковой системе Okapi (Окапи), а в дальнейшем – положен в основу текстовых анализаторов современных поисковых машин.
BM25 — поисковая функция на неупорядоченном множестве термов («мешке слов») и множестве документов, которые она оценивает на основе встречаемости слов запроса в каждом документе, без учета взаимоотношений между ними (например, близости). Это не одна функция, а семейство функций с различными компонентами и параметрами. Одна из распространенных форм этой функции описана ниже.
Пусть дан запрос  , содержащий слова
, содержащий слова  , тогда функция BM25 дает следующую оценку релевантности документа
, тогда функция BM25 дает следующую оценку релевантности документа  запросу :
запросу :

где  есть частота слова (англ. term frequency, TF)
есть частота слова (англ. term frequency, TF)  в документе ,
в документе ,  есть длина документа (количество слов в нем), а
есть длина документа (количество слов в нем), а  — средняя длина документа в коллекции.
— средняя длина документа в коллекции.  и
и  — свободные коэффициенты, обычно их выбирают как
— свободные коэффициенты, обычно их выбирают как  и
и  .
.
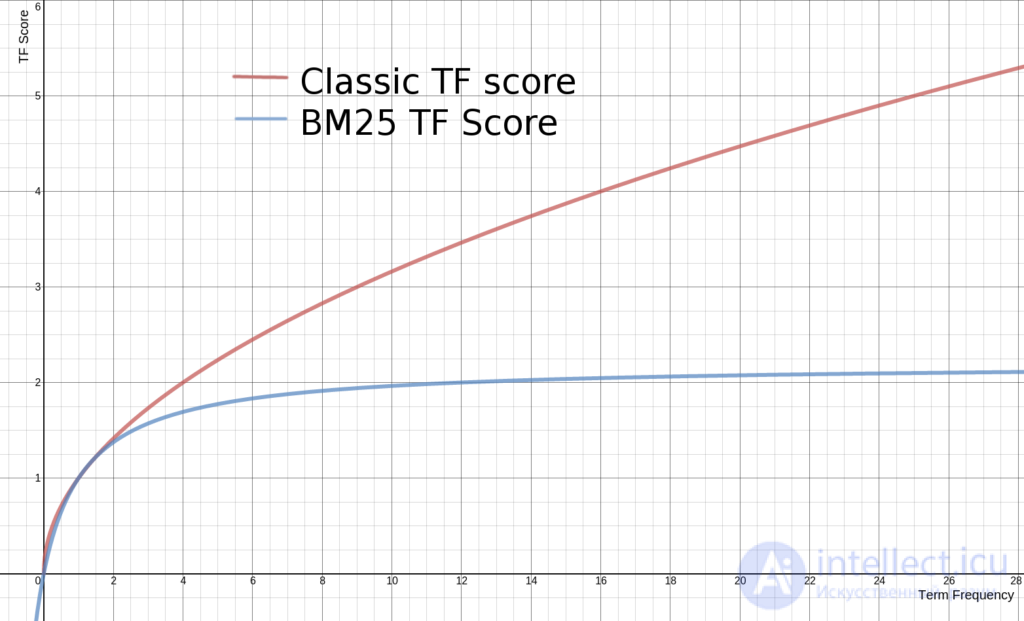
 есть обратная документная частота (англ. inverse document frequency, IDF) слова . Есть несколько толкований IDF и небольших вариации его формулы. Классически, она определяется как:
есть обратная документная частота (англ. inverse document frequency, IDF) слова . Есть несколько толкований IDF и небольших вариации его формулы. Классически, она определяется как:

где  есть общее количество документов в коллекции, а
есть общее количество документов в коллекции, а  — количество документов, содержащих . Но чаще применяются «сглаженные» варианты этой формулы, например:
— количество документов, содержащих . Но чаще применяются «сглаженные» варианты этой формулы, например:

Заметим, что вышеуказанная формула IDF имеет следующий недостаток. Для слов, входящих в более чем половину документов из коллекции, значение IDF отрицательно. Таким образом, при наличии любых двух почти идентичных документов, в одном из которых есть слово, а в другом — нет, второй может получить бо́льшую оценку.
Иными словами, часто встречающиеся слова испортят окончательную оценку документа. Это нежелательно, поэтому во многих приложениях вышеприведенная формула может быть скорректирована следующими способами:
 : если IDF меньше , то считать ее равной .
: если IDF меньше , то считать ее равной .Положим, что поисковое слово  встречается в
встречается в  документах. Тогда случайно выбранный документ содержит слово с вероятностью
документах. Тогда случайно выбранный документ содержит слово с вероятностью  (где есть мощность множества документов в коллекции). В таком случае информационная ценность фразы « содержит » будет такова:
(где есть мощность множества документов в коллекции). В таком случае информационная ценность фразы « содержит » будет такова:

Теперь положим, что имеется два поисковых слова  и
и  . Об этом говорит сайт https://intellect.icu . Если они входят в документ независимо друг от друга, то вероятность обнаружить их в случайно выбранном документе такова:
. Об этом говорит сайт https://intellect.icu . Если они входят в документ независимо друг от друга, то вероятность обнаружить их в случайно выбранном документе такова:

и содержание этого события

Это примерно то, что выражается компонентой IDF в BM25.
в функции BM25 получаются функции ранжирования, известные под названиями
bm11 (при  ) и
bm15 (при
) и
bm15 (при  ).
). Используемая модель «bag-of-words» (мешок слов) не учитывает:
Поэтому одна лишь формула BM25 в чистом виде для оценки релевантности документа не использовалась.
Робертсон хоть и утверждает, что для получения формулы использовалась вероятностная модель, но некоторые специалисты считают ее «подгонкой» под нужный результат. В функцию БМ25 внедрены свободные коэффициенты, которые могут принимать различные значения. Они подбираются так, чтобы «подогнать» результат работы поиска под заранее имеющиеся данные. Документы сначала оценивают асессоры, которые и говорят что плохо, а что хорошо. Затем на основании этих данных выбирают упомянутые коэффициенты, чтобы расположить документы так же, как это сделали асессоры – так называемый «принцип обезьянки». Оценка релевантности документа D по запросу Q , содержащего слова qi=q1,q2…qn по формуле BM25:
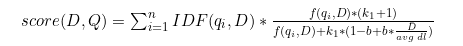
Где:
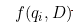 — частота употребления слова qi в документе;
— частота употребления слова qi в документе;
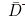 — общее количество слов в документе;
— общее количество слов в документе;
Для IDF используется сглаженная формула:
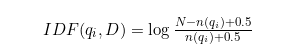
Где:
Формула для
TF
также изменилась:
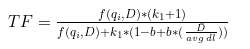
Релевантность по запросу Q равна сумме релевантностей по всем словам qi=q1,q2…qn из запроса. На первый взгляд, принцип работы такой же, как и TF-IDF:
Но есть и отличия:
| Число вхождений | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Рост Score в процентах | — | 50% | 20% | 11,1% | 7,1% | 5,0% | 3,7% | 2,9% | 2,3% | 1,9% |
а) отрицательные значения в сумме вообще игнорируются;
б) накладывается нижняя граница, при достижении которой значение IDF считается фиксированным числом;
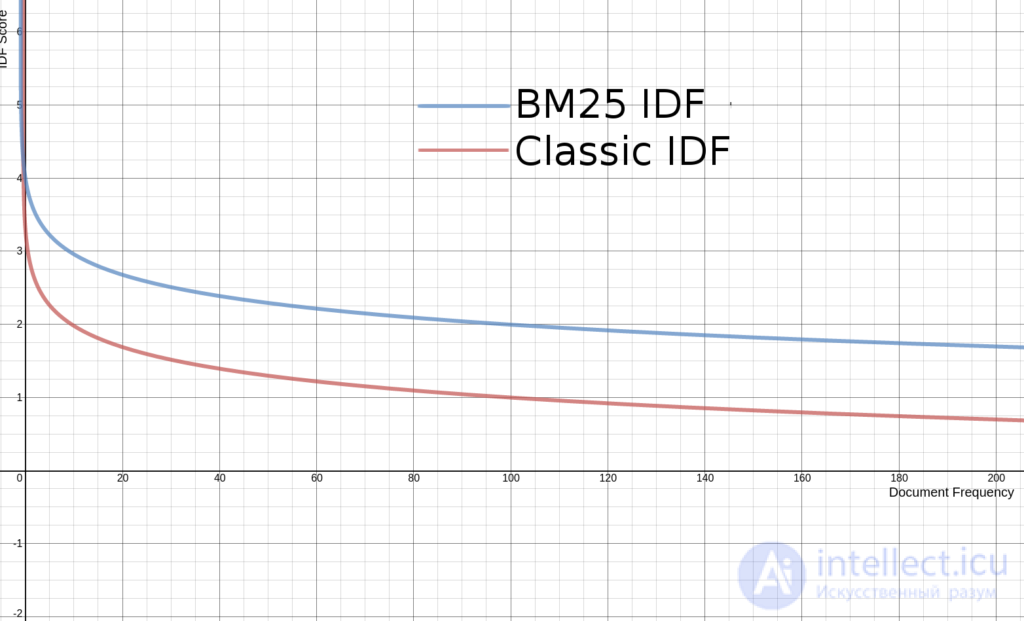
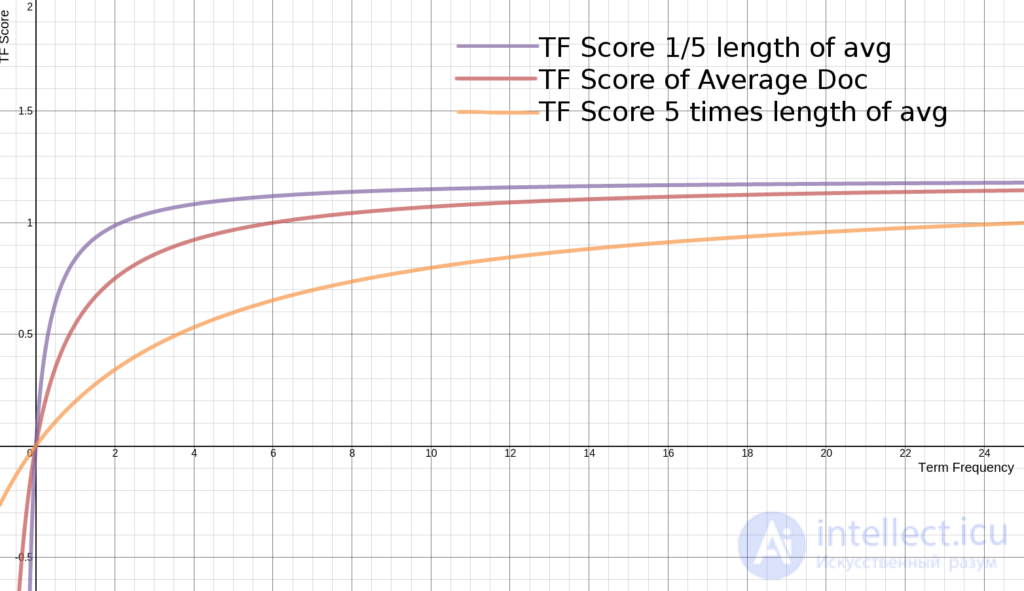
| Объем текста (слов) | 50 | 150 | 250 | 350 | 450 | 550 | 650 | 750 | 850 |
|---|---|---|---|---|---|---|---|---|---|
| Падение Score в процентах | — | -4,60% | -4,40% | -4,20% | -4,10% | -3,90% | -3,80% | -3,60% | -3,50% |
Немногие помнят «золотую эру SEO», когда вебмастера спамили ключевыми словами, достигали более высокой релевантности за счет их количества и, добавив ко всему этому тысячу сапо-ссылок, за пару недель выходили в ТОП.
Возьмем те же тексты и рассчитаем количество документов, содержащих слова из запроса, и среднюю длину документа.
| Текстовая | Релевантность | Документа | Поиске | ||
|---|---|---|---|---|---|
| Количество документов содержащих слово | 2 | 3 | 2 | 3 | |
| Док.1 | Док.2 | Док.3 | Док.4 | Средняя | |
| Длина документа | 25 | 22 | 26 | 17 | 22,5 |
Далее найдем IDF для каждого слова из запроса
| Слова из запроса | |||||
| Текстовая | Релевантность | Документа | Поиске | ||
| Док.1 | Частота слова | 0,080 | 0,080 | 0,000 | 0,000 |
| Док.2 | 0,045 | 0,045 | 0,000 | 0,045 | |
| Док.3 | 0,000 | 0,115 | 0,038 | 0,038 | |
| Док.4 | 0,000 | 0,000 | 0,059 | 0,059 | |
| IDF | 0 | -0,368 | 0 | -0,368 | |
В итоге получаем следующее значение TF и оценку Score по запросу «Текстовая релевантность документа в поиске»:
| Текстовая | Релевантность | Документа | Поиске | ||||
|---|---|---|---|---|---|---|---|
| Док.1 | TF | 0,107 | 0,107 | 0,000 | 0,000 | Score | 0,00107 |
| Док.2 | TF | 0,068 | 0,068 | 0,000 | 0,068 | Score | 0,00136 |
| Док.3 | TF | 0,000 | 0,147 | 0,051 | 0,051 | Score | 0,00198 |
| Док.4 | TF | 0,000 | 0,000 | 0,104 | 0,104 | Score | 0,00104 |
Наглядный пример, того как IDF может принимать отрицательные значения для слов, которые встречаются больше чем в половине документов. Вместо отрицательного значения IDF брали фиксированное IDF=0,01. Наибольшую оценку получил «документ 3», хотя в классической TF-IDF формуле – документ 1, который теперь имеет самую низкую оценку Score по BM25. Распределение оценок по различным запросам:
| BM25 | Запросы | |||
|---|---|---|---|---|
| № документа | Релевантность | Текстовая релевантность | Текстовая релевантность документа | Текстовая релевантность документа в поиске |
| Док.1 | ||||
| Док.2 | ||||
| Док.3 | ||||
| Док.4 | ||||
| BM25 | Запросы | |||
|---|---|---|---|---|
| № документа | Релевантность | Текстовая релевантность | Текстовая релевантность документа | Текстовая релевантность документа в поиске |
| Док.1 | ||||
| Док.2 | ||||
| Док.3 | ||||
| Док.4 | ||||
До этого мы рассматривали ограниченную выборку, в которой заранее известно, что документы околотематические. Для лучшего понимания формулы рассмотрим пример с нетематической коллекцией документов. Найдем Score в выборке из 20 000 документов.
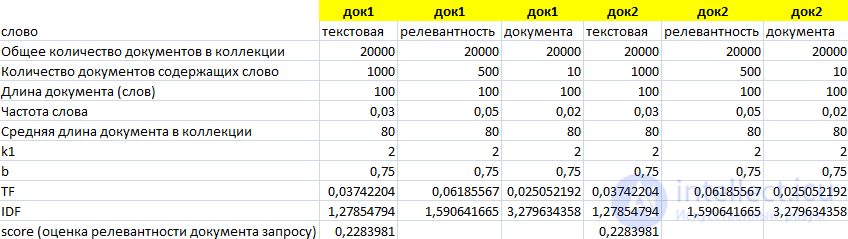
IDF для слова «документа» значительно больше, чем для слов «релевантность» и «текстовая». Теперь увеличим частоту слова «документа» в док2 с 2% до 5%.
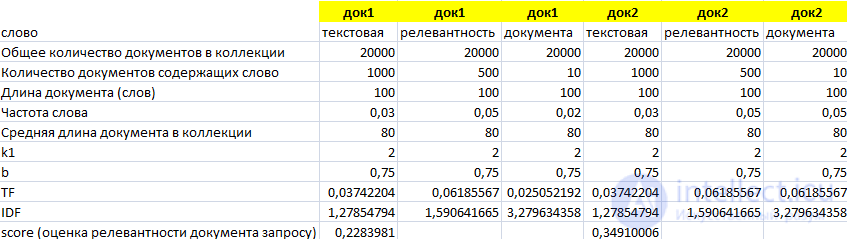
Видим значительный рост TF и Score при неизменном IDF. Увеличим частоту «текстовая» до 6% в док 1.
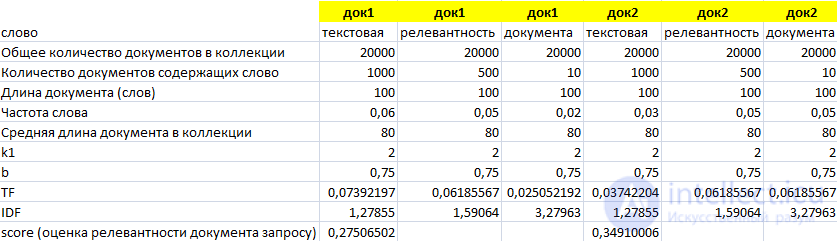
Сумма частот каждого слова из запроса в документе 1 и документе 2 одинаковая и составляет 13%, но термин «документа» меньше употребляется в коллекции. Из итоговой оценки и можно говорить, что значимость узкоспециализированных слов значительно выше, чем других терминов из запроса.
В 2006-2007 годах по методике пользователя под ником Миныч на форуме Searchengines решили, что в Яндексе при расчете релевантности использовались похожие формулы:
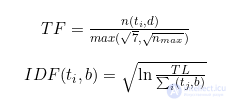
Где:
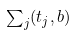 — количество вхождений слова ti в поисковую базу b;
— количество вхождений слова ti в поисковую базу b;
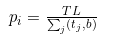 — вес термина.
— вес термина.
Видим, что по данной формуле максимальная релевантность достигается, когда продвигаемый запрос ti является самым частотным в документе n(ti,d)=nmax, а плотность ключевого слова вообще не влияет на оценку. Миныч – первый, кто ввел понятие «Тошнота». В его методике тошнота W=max(√7,√nmax) – квадратный корень от частоты самого употребляемого слова nmax в документе. Если nmax меньше 7, то W=√7. При превышении некоторого порога спамности для конкретного слова, например W>25, накладывалась пессимизация документа.
Статью про bm15 я написал специально для тебя. Если ты хотел бы внести свой вклад в развитие теории и практики, ты можешь написать коммент или статью отправив на мою почту в разделе контакты. Этим ты поможешь другим читателям, ведь ты хочешь это сделать? Надеюсь, что теперь ты понял что такое bm15 , bm11 , bm25 , bm25f, алгоритм ранжирования, функция ранжирования, тошнота документа по минычу и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка

Комментарии