Лекция
Это окончание невероятной информации про алгоритмы исправления опечаток.
...
хранить в таблице помимо расстояний указатели на предыдущие # ячейки: memo будет хранить соответствие # i -> j -> (distance, prev i, prev j). # Дальше немного непривычно страшного Python кода - вот что # бывает, когда язык используется не по назначению! m, n = len(intended_word), len(misspelled_word) memo = [[None] * (n+1) for _ in range(m+1)] memo[0] = [(j, (0 if j > 0 else -1), j-1) for j in range(n+1)] for i in range(m + 1): memo[i][0] = i, i-1, (0 if i > 0 else -1) for j in range(1, n + 1): for i in range(1, m + 1): if intended_word[i-1] == misspelled_word[j-1]: memo[i][j] = memo[i-1][j-1][0], i-1, j-1 else: best = min( (memo[i-1][j][0], i-1, j), (memo[i][j-1][0], i, j-1), (memo[i-1][j-1][0], i-1, j-1), ) # Отдельная обработка для перепутанных местами # соседних букв (распространенная ошибка при # печати). if (i > 1 and j > 1 and intended_word[i-1] == misspelled_word[j-2] and intended_word[i-2] == misspelled_word[j-1] ): best = min(best, (memo[i-2][j-2][0], i-2, j-2)) memo[i][j] = 1 + best[0], best[1], best[2] # К концу цикла расстояние по Левенштейну между исходными словами # хранится в memo[m][n] . # Теперь восстанавливаем оптимальное расположение букв. s, t = [], [] i, j = m, n while i >= 1 or j >= 1: _, pi, pj = memo[i][j] di, dj = i - pi, j - pj if di == dj == 1: s.append(intended_word[i-1]) t.append(misspelled_word[j-1]) if di == dj == 2: s.append(intended_word[i-1]) s.append(intended_word[i-2]) t.append(misspelled_word[j-1]) t.append(misspelled_word[j-2]) if 1 == di > dj == 0: s.append(intended_word[i-1]) t.append("") if 1 == dj > di == 0: s.append("") t.append(misspelled_word[j-1]) i, j = pi, pj s.reverse() t.reverse() # Генерируем модификации длины не выше заданной. for i, _ in enumerate(s): ss = ts = "" while len(ss) < max_l and i < len(s): ss += s[i] ts += t[i] yield ss, ts i += 1
Сам подсчет правок выглядит элементарно, хотя длиться может долго.
Эта часть реализована в виде микросервиса на Go, связанного с основным бэкендом через gRPC. Реализован алгоритм, описанный самими Бриллом и Муром , с небольшими оптимизациями. Работает он у меня в итоге примерно вдвое медленнее, чем заявляли авторы; не берусь судить, дело в Go или во мне. Но по ходу профилировки я узнал о Go немного нового.
math.Max, чтобы считать максимум. Это примерно в три раза медленнее, чем if a > b { b = a }! Только взгляните на реализацию этой функции:
// Max returns the larger of x or y.
//
// Special cases are:
// Max(x, +Inf) = Max(+Inf, x) = +Inf
// Max(x, NaN) = Max(NaN, x) = NaN
// Max(+0, ±0) = Max(±0, +0) = +0
// Max(-0, -0) = -0
func Max(x, y float64) float64
func max(x, y float64) float64 {
// special cases
switch {
case IsInf(x, 1) || IsInf(y, 1):
return Inf(1)
case IsNaN(x) || IsNaN(y):
return NaN()
case x == 0 && x == y:
if Signbit(x) {
return y
}
return x
}
if x > y {
return x
}
return y
}
math.Max.
Здесь без особых сюрпризов был реализован алгоритм динамического программирования, описанный в разделе выше. На этот компонент пришлось меньше всего работы — самой медленной частью остается применение модели ошибок. Поэтому между этими двумя слоями было дополнительно прикручено кэширование результатов модели ошибок в Redis.
По итогам этой работы (занявшей примерно человекомесяц) мы провели A/B тест опечаточника на наших пользователях. Вместо 10% пустых выдач среди всех поисковых запросов, которые мы имели до внедрения опечаточника, их стало 5%; в основном оставшиеся запросы приходятся на товары, которых просто нет у нас на платформе. Также увеличилось количество сессий без второго поискового запроса (и еще несколько метрик такого рода, связанных с UX). Метрики, связанные с деньгами, впрочем, значимо не изменились — это было неожиданно и сподвигло нас к тщательному анализу и перепроверке других метрик.
Рассмотрение готовых решений проводилось с уклоном на собственное использование, и приоритет отдавался автокорректорам, которые удовлетворяют трем критериям:
1) язык реализации,
2) тип лицензии,
3) обновляемость.
В продуктовой разработке язык Java считается одним из самых популярных, поэтому приоритет при поиске библиотек отдавался ему. Из лицензий актуальны: MIT, Public, Apache, BSD. Обновляемость — не более 2-х лет с последнего обновления. В ходе поиска фиксировалась дополнительная информация, например, о поддерживаемой платформе, требуемые дополнительные программы, особенности применения, возможные затруднения при первом использовании и т. д. Ссылки с основными и полезными ресурсами на источники приведены в конце статьи. В целом, если не ограничиваться вышеупомянутыми критериями, количество существующих решений велико. Давайте кратко рассмотрим основные, а более подробно уделим внимание лишь некоторым.
Исторически одним из самых старых автокорректоров является Ispell (International Spell), написан в 1971 на ассемблере, позднее перенесен на C и в качестве модели ошибок использует редакционное расстояние Дамерау-Левенштейна. Для него даже есть словарь на русском языке. В последующем ему на замену пришли два автокорректора HunSpell (ранее MySpell) и Aspell. Оба реализованы на на C++ и распространяются под GPL лицензиями. На HunSpell также распространяется GPL/MPL и его используют для исправления опечаток в OpenOffice, LibreOffice, Google Chrome и других инструментах.
Для Интернета и браузеров есть целое множество решений на JS (сюда можно отнести: nodehun-sentences, nspell, node-markdown-spellcheck, Proofreader, Spellcheck-API — группа решений, базирующаяся на автокорректоре Hunspell; grunt-spell — под NodeJS; yaspeller-ci — обертка для автокорректора Яндекс.Спеллер, распространяется под MIT; rousseau — Lightweight proofreader in JS — используется для проверки правописания).
В категорию платных решений входят: Spellex; Source Code Spell Checker — как десктопное приложение; для JS: nanospell; для Java: Keyoti RapidSpell Spellchecker, JSpell SDK, WinterTree (у WinterTree можно даже купить исходный код за $5000).
Широкой популярностью пользуется автокорректор Питера Норвига, программный код на Python которого находится в публичном доступе в статье «How to Write a Spelling Corrector» . На основе этого простого решения были построены автокорректоры на других языках, например: Norvig-spell-check, scala-norvig-spell-check (на Scala), toy-spelling-corrector — Golang Spellcheck (на GO), pyspellchecker (на Python). Разумеется, здесь никакой речи не идет о языковых моделях и контекстно-зависимом исправлении.
Для текстовых редакторов, в частности для VIM сделаны vim-dialect, vim-ditto — распространяются под публичной лицензией; для Notepad++ разработан DspellCheck на C++, лицензия GPL; для Emacs сделан инструмент автоматического определения языка при печати, называется guess-language, распространяется под публичной лицензией.
Есть отдельные сервисы от поисковых гигантов: Яндекс.Спеллер — от Яндекса, про обертку к нему было сказано выше, google-api-spelling-java (соответственно, от Google).
Бесплатные библиотеки для Java: languagetool (лицензируется под LGPL), интегрируется с библиотекой текстового поиска Lucene и допускает использование языковых моделей, для работы необходима 8 версия Java; Jazzy (аналог Aspell) распространяется под лицензией LGPLv2 и не обновлялась с 2005 года, а в 2013 была перенесена на GitHub. По подобию этого автокорректора сделано отдельное решение ; Jortho (Java Orthography) распространяется под GPL и разрешает бесплатное использование исключительно в некоммерческих целях, в коммерческих — за дополнительную плату; Jaspell (лицензируется под BSD и не обновлялся с 2005 года); Open Source Java Suggester — не обновлялся с 2013 года, распространяется SoftCorporation LLC и разрешает коммерческое применение; LuceneSpellChecker — автокорректор библиотеки Lucene, написана на Java и распространяется под лицензией Apache.
На протяжении длительного времени вопросом исправления опечаток занимался Wolf Garbe, им были предложены алгоритмы SymSpell (под MIT лицензией) и LinSpell (под LGPL) с реализациями на C# , которые используют расстояние Дамерау-Левенштейна для модели ошибок. Особенность их реализации в том, что на этапе формирования возможных ошибок для входного слова, используются только удаления, вместо всевозможных удалений, вставок, замен и перестановок. По сравнению с реализацией автокорректора Питера Норвига оба алгоритма за счет этого работают быстрее, при этом прирост в скорости существенно увеличивается, если расстояние по Дамерау-Левенштейну становится больше двух. Также за счет того, что используются только удаления, сокращается время формирования словаря. Отличие между двумя алгоритмами в том, что LinSpell более экономичен по памяти и медленнее по скорости поиска, SymSpell — наоборот. В более поздней версии SymSpell исправляет ошибки слитно-раздельного написания. Языковые модели не используются.
К числу наиболее свежих и перспективных для пользования автокорректоров, работающих с языковыми моделями и исправляющих контекстно-зависимые опечатки относятся Яндекс.Спеллер, JamSpell [10], DeepPavlov [11]. Последние 2 распространяются свободно: JamSpell (MIT), DeepPavlov (под Apache).
Яндекс.Спеллер использует алгоритм CatBoost, работает с несколькими языками и исправляет всевозможные разновидности ошибок даже с учетом контекста. Единственное из найденных решение, которое исправляет ошибки неверной раскладки и транслитерацию. Решение обладает универсальностью, что делает его популярным. Его недостатком является то, что это удаленный сервис, а про ограничения и условия пользования можно прочитать здесь [12]. Сервис работает с ограниченным количеством языков, нельзя самостоятельно добавлять слова и управлять процессом исправления. В соответствии с ресурсом по результатам соревнований RuSpellEval этот автокорректор показал самое высокое качество исправлений. JamSpell — самый быстрый из известных автокорректор (C++ реализация), здесь есть готовые биндинги под другие языки. Исправляет ошибки только в самих словах и работает с конкретным языком. Использовать решение на уровне униграмм и биграмм нельзя. Для получения приемлемого качества требуется большой обучающий текст.
Есть неплохие наработки у DeepPavlov, однако интеграция этих решений и последующая поддержка в собственном продукте может вызвать затруднения, т. к. при работе с ними требуется подключение виртуального окружения и использование более ранней версии Python 3.6. DeepPavlov предоставляет на выбор три готовых реализации автокорректоров, в двух из которых применены модели ошибок Бриля-Мура и в двух языковые модели. Исправляет только ошибки орфографии, а вариант с моделью ошибок на основе расстояния Дамерау-Левенштейна может исправлять ошибки слитного написания.
Упомяну еще про один из современных подходов к исправлению опечаток, который основан на применении векторных представлений слов (Word Embeddings). Достоинством его является то, что на нем можно построить автокорректор для исправления слов с учетом контекста. Более подробно про этот подход можно прочитать здесь [13]. Но чтобы его использовать для исправления опечаток поисковых запросов вам потребуется накопить большой лог запросов. Кроме того, сама модель может оказаться довольно емкой по потребляемой памяти, что отразится на сложности интеграцию в продукт.
Из готовых решений для Java был выбран автокорректор от Lucene (распространяется под лицензией от Apache). Позволяет исправлять опечатки в словах. Процесс обучения быстрый: например, формирование специальной структуры данных словаря – индекса для 3 млн. строк составило 30 секунд на процессоре Intel Core i5-8500 3.00GHz, 32 Gb RAM, Lucene 8.0.0. В более ранних версиях время может быть больше в 2 раза. Размер обучающего словаря – 3 млн. строк (~73 Mb txt-файл), структура индекса ~235 Mb. Для модели ошибок можно выбирать расстояние Джаро-Винклера, Левенштейна, Дамерау-Левенштейна, N-Gram, если нужно, то можно добавить свое. При необходимости есть возможность подключения языковой модели [14]. Модели известны с 2001 года, но их сравнение с известными современными решениями в открытом доступе не было обнаружено. Следующим этапом будет проверка их работы.
Полученное решение на основе Lucene исправляет только ошибки в самих словах. К любому подобному решению несложно добавить исправление искаженной раскладки клавиатуры путем соответствующей таблицы перевода, тем самым сократить возможность нерелевантной выдачи до 10% (в соответствии с опечаточной статистикой). Кроме того, несложно добавить раздельное написание слитых 2-х слов и транслитерацию.
В качестве основных недостатков решения можно выделить необходимость знания Java, отсутствие подробных кейсов использования и подробной документации, что отражается на снижении скорости разработки решения для Data-Science специалистов. Кроме того, не исправляются опечатки с расстоянием по Дамерау-Левенштейну более 2-х. Опять же, если отталкиваться от опечаточной статистики, более 2-х ошибок в слове возникает реже, чем в 5% случаев. Обоснована ли необходимость усложнения алгоритма, в частности, увеличение потребляемой памяти? Тут уже зависит от кейса заказчика. Если есть дополнительные ресурсы, то почему бы их не использовать?
Большинство открытых спелл-чекеров (к примеру hunspell) не учитывают контекст, а без него сложно получить хорошую точность. Я взял за основу спеллчекер Питера Норвига, прикрутил к нему языковую модель (на базе N-грамм), ускорил его (используя подход SymSpell), поборол сильное потребление памяти (через bloom filter и perfect hash) а затем оформил все это в виде библиотеки на C++ со swig биндингами для других языков.
Прежде чем писать непосредственно спеллчекер нужно было придумать способ измерить его качество. Норвиг для этих целей использовал готовую коллекцию опечаток, в которой дан список слов с ошибками вместе с правильным вариантом. Но в нашем случае этот способ не подходит по причине отсутствия в нем контекста. Вместо этого первым делом был написан простой генератор опечаток.
Генератор опечаток на вход принимает слово, на выходе дает слово с некоторым количеством ошибок. Ошибки бывают следующих типов: замена одной буквы на другую, вставка новой буквы, удаление существующей, а также перестановка двух букв местами. Вероятности каждого из типа ошибок настраиваются отдельно, так же настраивается общая вероятность совершить опечатку (в зависимости от длины слова) и вероятность совершить повторную опечатку.
Пока что все параметры выбраны интуитивно, вероятность ошибки составляет примерно 1 на 10 слов, вероятность самого простого типа ошибки (замена одной буквы на другую) в 7 раз выше чем других типов ошибок.
У данной модели много недостатков — она не основывается на реальной статистике опечаток, не учитывает раскладку клавиатуры а также не склеивает и не разделяет слова. Тем не менее, для начального варианта ее хватит. А в следующих версиях библиотеки модель будет улучшена.
Теперь, имея генератор опечаток, можно прогнать через него любой текст и получить аналогичный текст с ошибками. В качестве метрики качества спеллчекера можно использовать процент ошибок оставшихся в тексте после прогона его через этот спеллчекер. В дополнение к этой метрике использовались следующие:
Питер Норвиг описал простой вариант спеллчекера. Для каждого слова генерируются все возможные варианты изменений (удаления + вставки + замены + перестановки), рекурсивно с глубиной <= 2. Получившиеся слова проверяются на наличие в словаре (хеш-таблица), среди множества подошедших вариантов выбирается тот, который встречается чаще всего. Подробней про этот спеллчекер можно почитать в оригинальной статье.
Основные недостатки данного спеллчекера — долгое время работы (особенно на длинных словах), отсутствие учета контекста. Начнем с исправления последнего — добавим модель языка и вместо простой частоты встречаемости слов будем использовать оценку, возвращаемую языковой моделью.
| N-грамма — последовательность из n элементов. Например, последовательность звуков, слогов, слов или букв. |
Модель языка умеет отвечать на вопрос — с какой вероятностью данное предложение может встретится в языке. На сегодняшний день в основном используются два подхода: модели на основе N-грамм а также на основе нейросетей. Для первой версии библиотеки была выбрана N-граммная модель, так как она является более простой. Однако в будущем есть планы попробовать нейросетевую модель.
N-граммная модель работает следующим образом. По тексту, используемому для обучения модели проходим окном размером в N слов и подсчитываем количество раз которые встретилось каждое сочетание (n-грамма). При запросе к модели — аналогичным образом проходим окном по предложению и считаем произведение вероятностей всех n-грамм. Вероятность встретить n-грамму оцениваем по количеству таких n-грамм в обучающем тексте.
Вероятность P(w1,..., wm) встретить предложение (w1,..., wm) из m слов примерно равна произведению всех n-грамм размера n, из которых состоит это предложение:
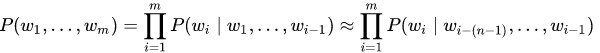
Вероятность каждой из n-граммы определяется через количество раз, которое встретилась эта n-грамма по отношению к количеству раз, которое встретилась такая же n-грамма но без последнего слова:
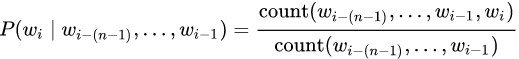
На практике в чистом виде такую модель не используют, так как у нее есть следующая проблема. Если какая-то n-грамма не встречалась в обучающем тексте — все предложение сразу же получит нулевую вероятность. Для решения этой проблемы используют один из вариантов сглаживания (smoothing). В простом виде это добавление единицы к частоте встречаемости всех n-грамм, в более сложном — использование n-грамм более низкого порядка при отсутствии n-граммы высокого порядка.
Самая популярная техника сглаживания — Kneser–Ney smoothing. Однако она требует для каждой n-граммы хранить дополнительную информацию, а выигрыш по сравнению с более простым сглаживанием получился не сильный (по крайней мере в экспериментах с небольшими моделями, до 50 миллионов n-грамм). Для простоты в качестве сглаживания будем считать вероятность каждой n-граммы как произведение n-грамм всех порядков, например для триграмм:

Теперь, имея модель языка, будем выбирать среди кандидатов на исправление опечаток того, для которого модель языка с учетом контекста будет выдавать наилучшую оценку. Кроме того, добавим к оценке небольшой штраф за изменение исходного слова, чтобы избежать большого числа ложных срабатываний. Изменение данного штрафа позволяет регулировать процент ложных срабатываний: например, в текстовом редакторе можно оставить процент ложных срабатываний выше, а для автоматического исправления текстов — ниже.
Следующая проблема спеллчекера Норвига — низкая скорость работы для случаев, когда кандидатов не нашлось. Так, на слове из 15 букв алгоритм работает около секунды, такой производительности вряд ли хватит для практического использования. Один из вариантов ускорения производительности — алгоритм SymSpell, который, по заверению авторов, работает в миллион раз быстрее. SymSpell работает по следующему принципу: для каждого слова из словаря в отдельный индекс добавляются удаления, а точнее — все слова, получившиеся из исходного путем удаления одной или нескольких букв (обычно 1 и 2), со ссылкой на оригинальное слово. В момент поиска кандидатов для слова делаются аналогичные удаления и проверяется их наличие в индексе. Такой алгоритм корректно обрабатывает все случаи ошибок — замены букв, перестановки, добавления и удаления.
Для примера рассмотрим замену (в примере будем учитывать только расстояние 1). Пусть в оригинальном словаре содержится слово "тест". А мы набрали слово “темт”. В индексе будут находится все удаления слова “тест”, а именно: ест, тст, тет, тес. Для слова “темт” удаления будут: емт, тмт, тет, емт. Удаление “тет” содержится в индексе, значит слову с опечаткой “темт” соответствует слово “тест”.
Следующая проблема — потребление памяти. Модель, обученная на тексте из двух миллионов предложений (миллион из википедии + миллион из новостных текстов) занимала 7 Гб оперативки. Примерно половину этого объема использовала языковая модель (n-граммы с частотой встречаемости) а другую половину — индекс для SymSpell. С таким потреблением памяти прикладное использование становилось не очень практичным.
Уменьшать размер словаря не хотелось, так как начинало заметно проседать качество. Как оказалось — это не новая проблема. В научных статьях предлагаются разные пути решения проблемы потребления памяти языковой моделью. Один из интересных подходов (описанный в статье Efficient Minimal Perfect Hash Language Models) — использовать perfect hash (а точнее, алгоритм CHD) для хранения информации об n-граммах. Perfect hash — это такой хеш, который не дает коллизий на фиксированном наборе данных. При отсутствии коллизий пропадает необходимость в хранении ключей, так как нет нужды их сравнивать. В результате, можно держать в памяти массив, равный количеству n-грамм, в котором хранить их частоту встречаемости. Это дает очень сильную экономию памяти, так как сами n-грамм-ы занимают сильно больше места чем их частоты встречаемости.
Но есть одна проблема. При использовании модели в нее будут приходить n-граммы, которые ни разу не встречались в обучающем тексте. Как следствие, perfect hash будет возвращать хеш какой-то другой, существующей n-граммы. Чтобы решить эту проблему, авторы статьи для каждой n-граммы предлагают дополнительно хранить другой хеш, по которому можно будет сравнить совпадают ли n-граммы или нет. В случае если хеш различается — данной n-граммы не существует и следует считать частоту встречаемости нулевой.
Например, у нас есть три n-граммы: n1, n2, n3, которые встретились 10, 15 и 3 раза, а также n-грамма n4 которая не встречалась в исходном тексте:

Мы завели массив, в котором храним частоты встречаемости, а также дополнительный хеш. Используем значение perfect-hash-а в качестве индекса массива:
| 15, 13 | 10, 42 | 3, 24 |
Предположим, нам встретилась n-грамма n1. Ее perfect-hash равен 1, а second-hash 42. Мы идем в массив по индексу 1, и сверяем хеш который там лежит. Он совпадает, значит частота n-граммы 10. Теперь рассмотрим n-грамму n4. Ее perfect-hash также равен 1, но second-hash равен 18. Это отличается от хеша который лежит по индексу 1, значит частота встречаемости 0.
На практике в качестве хеша был использован CityHash, размером в 16 бит. Конечно же хеш не исключает ложных срабатываний полностью, но сводит их частоту к такой, что на итоговых метриках качества это никак не отражается.
Сама частота встречаемости так же была закодирована более компактно, из 32-битных чисел в 16-битные, путем нелинейного квантования. Мелкие числа соответствовали как 1 к 1, более крупные как 1 к 2, 1 к 4, и т. д. На итоговых метриках квантование опять же никак не сказалось.
Скорее всего, можно запаковать и хеш, и частоты встречаемости еще сильней — но это уже в следующих версиях. В текущем варианте модель ужалась до 260 Мб — более чем в 10 раз, без какой либо просадки качества.
Кроме модели языка оставался еще индекс от алгоритма SymSpell, который также занимал кучу места. Над ним пришлось подумать немного дольше, так как готовых решений под это не существовало. В научных статьях про компактное представление языковой модели часто использовался bloom-фильтр. Казалось, что и в этой задаче он может помочь. Применить bloom-фильтр в лоб не удавалось — для каждого слова из индекса с удалениями нам нужны были ссылки на оригинальное слово, а bloom фильтр не позволяет хранить значения, только проверять факт наличия. С другой стороны — если bloom фильтр скажет что такое удаление есть в индексе — мы можем восстановить для него оригинальное слово выполняя вставки и проверяя их в индексе. Итоговая адаптация алгоритма SymSpell получилась следующей:
Будем хранить все удаления слов из оригинального словаря в bloom-фильтре. При поиске кандидатов будем вначале делать удаления от исходного слова на нужную глубину (аналогично SymSpell). Но, в отличии от SymSpell, следующим шагом для каждого удаления будем делать вставки, и проверять получившееся слово в оригинальном словаре. А индекс с удалениями, хранящийся в bloom-фильтре, будем использовать чтобы пропускать вставки для тех удалений, которые в нем отсутствуют. В этом случае ложные срабатывания нам не страшны — мы просто выполним немного лишней работы.
Производительность получившегося решения практически не замедлилась, а используемая память сократилась очень существенно — до 140 Мб (примерно в 25 раз). В итоге общий размер памяти сократился с 7 Гб до 400 Мб.
В таблице ниже приведены результаты для английского текста. Для обучения использовались 300К предложений из википедии и 300К предложений из новостных текстов (тексты взяты здесь). Исходная выборка была разбита на 2 части, 95% использовалось для обучения, 5% для оценки. Результаты:
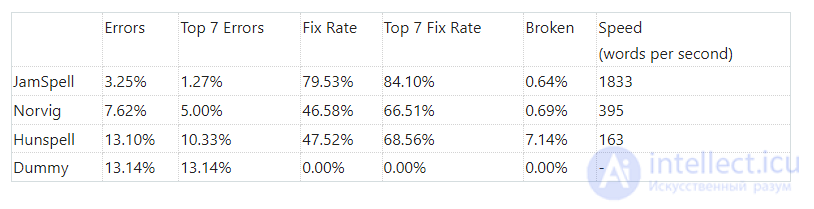
JamSpell — получившийся в итоге спелл-чекер. Dummy — корректор который ничего не делает, приведен для того чтобы было понятно какой процент ошибок в исходном тексте. Norvig — спелл-чекер Питера Норвига. Hunspell — один из самых популярных open-source спелл-чекеров. Для чистоты эксперимента — так же была проведена проверка на художественном тексте. Метрики по тексту "Приключения Шерлока Холмса":
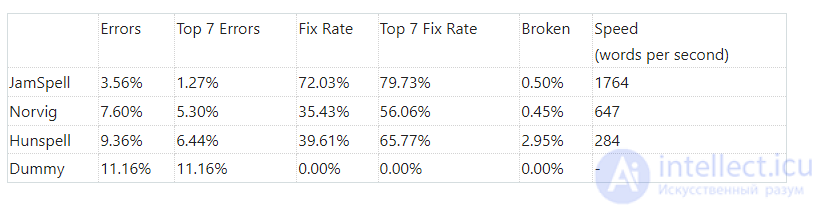
JamSpell показал лучшее качество и производительность по сравнению со спеллчекерами Hunspell и Норвига в обоих тестах, как в кейсе с одним кандидатом, так и в кейсе с лучшими 7 кандидатами.
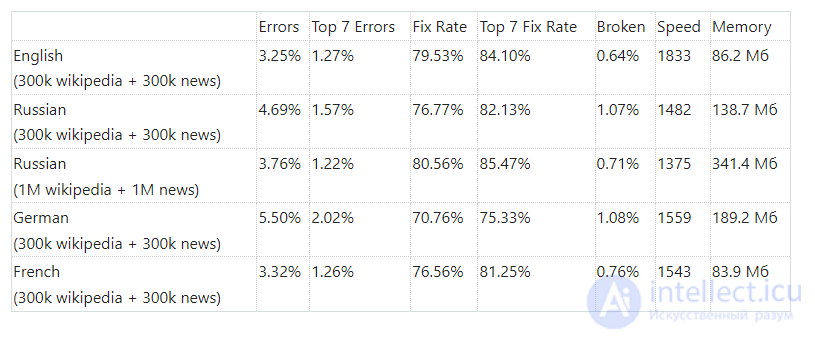
В следующей таблице приведены метрики для разных языков и для обучающей выборки разных размеров:
Исследование, описанное в статье про алгоритмы исправления опечаток, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое алгоритмы исправления опечаток, исправление опечаток с учётом контекста, исправление опечаток без учёта контекста, модель ошибок, модель языка и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Обработка естественного языка
Часть 1 Алгоритмы исправления опечаток с и без учёта контекста
Часть 2 Результаты - Алгоритмы исправления опечаток с и без учёта контекста
Комментарии
Оставить комментарий
Обработка естественного языка
Термины: Обработка естественного языка