Лекция
Привет, Вы узнаете о том , что такое поиск по зашифрованному тексту, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое поиск по зашифрованному тексту, searchable encryption, peks, sse , настоятельно рекомендую прочитать все из категории Информационная безопасность, Шифры в криптографии.
Шифрование с возможностью поиска (англ. Searchable Encryption или SE) — класс криптографических алгоритмов шифрования, в которых существует возможность осуществлять поиск по зашифрованным данным (файлам, записям базы данных и т. д.). Областью применения является предоставление приватности данных, хранимых на недоверенном удаленном ресурсе .
В общем случае, в основе такого шифрования могут лежать как симметричные, так и асимметричные шифры. Однако, так как практические задачи предполагают шифрование большого количества данных, чаще встречается использование симметричного шифрования с поиском (соответственно, англ. Searchable Symmetric Encryption или сокращенно SSE). Большинство асимметричных подходов основаны на шифровании по открытому ключу с поиском по ключевым словам (англ. Public Key Encryption with Keyword Search, сокращенно PEKS)
Шифрование (англ. encryption) — обратимое преобразование информации в целях сокрытия от неавторизованных лиц, с предоставлением, в это же время, авторизованным пользователям доступа к ней. Главным образом, шифрование служит задачей соблюдения конфиденциальности передаваемой информации. Важной особенностью любого алгоритма шифрования является использование ключа, который утверждает выбор конкретного преобразования из совокупности возможных для данного алгоритма. В рамках данной статьи будут рассматриваться данные, полученные в результате шифрования.
Гомоморфное шифрование — форма шифрования, позволяющая производить определенные математические действия с зашифрованным текстом и получать зашифрованный результат, который соответствует результату операций, выполняемых с открытым текстом.
Частично гомоморфные криптосистемы — это такие криптосистемы, которые гомоморфны относительно только одной операции (или сложения, или умножения). Полностью гомомморфные криптосистемы гомоморфны относительно нескольких операций.
Поиск данных — раздел информатики, изучающий алгоритмы для поиска и обработки информации как в структурированных (см. напр. базы данных) так и неструктурированных (напр., текстовый документ) данных. В общем случае, поиск означает исследование чего-либо с целью нахождения неочевидной, утерянной или спрятанной части. Поиск данных обычно связан с обработкой некоторого хранилища данных, прочесть или осознать которые последовательно не представляется возможным, с целью найти интересующее постановщика задачи подмножество этих данных (или установить их отсутствие). Алгоритмы эффективного поиска существовали задолго до появления компьютеров и применялись, к примеру, для нахождения книг в библиотеках. Существует неинформированный поиск данных, когда алгоритмы могут обрабатывать любые данные независимо от их сути, например, побитовый поиск.
Актуальность задачи поиска вхождений в зашифрованных данных обусловлена быстрым развитием рынка облачного хранения данных, тогда как на сегодняшний день не существует протоколов безопасной обработки данных на стороне облачного сервера, так как при обработке данных в зашифрованном виде либо необходимо передать серверу секретный ключ, либо каждый раз выкачивать всю базу данных. Решение задачи поиска вхождений над зашифрованными данными позволит безопасно хранить данные за пределами доверенной зоны.
Идея поиска по шифротексту стала актуальна на фоне введения облачных хранилищ данных. Данные пользователей хранятся на удаленных ресурсах, которые могут быть недоверенными (или «полудоверенными», англ. semitrusted ). Для обеспечения приватности в этом случае, к данным применяется шифрование . Однако, при обычном шифровании для выполнения поиска по этим данным пользователь должен был либо выкачать весь набор данных и расшифровать его, либо же предоставить серверу средства для расшифровки, что противоречит изначальной цели шифрования .
Первыми попытками обеспечить приватность пользователя при работе с сервером можно считать работы 1990-х годов по oRAM, когда от сервера скрывался паттерн доступа к памяти при обработке запроса пользователя .
Первая работа в направлении поиска по шифрованным данным была изложена в 2000-м году Dawn Xiaodong Song, David Wagner и Adrian Perrig. Их алгоритм предполагал поиск по шифротексту с точным совпадением .
В то время, как алгоритм SWP00 строил метод шифрования, где поиск производится по самому шифротексту, большинство дальнейших реализаций предполагают построение зашифрованного индекса , поиск по которому занимает меньше времени , позволяет обновлять данные на сервере (dynamic SSE) , или использовать расширенный поиск [10]. Платой за это является увеличение размера шифрованных данных и повышение риска утечек.
В статье Eu-Jin Goh 2003-го года впервые был предложен поиск по шифрованному индексу, который предполагал поиск точного совпадения. А в 2009-ом в статье Emily Shen, Elaine Shi и Brent Waters — приватный предикативный поиск[10].
В направлении PEKS первый результат представлен в статье 2004-го за авторством Dan Boneh, Giovanni Di Crescenzo, Rafail Ostrovsky и Giuseppe Persiano .
Изначально, при проверке новых алгоритмов на защищенность, проверялись только общие требования к криптографическим системам. Определения криптостойкости для SE, учитывающие особенности возможных новых видов утечек, были даны в статье 2006-го года от Reza Curtmola, Juan Garay, Seny Kamara и Rafail Ostrovsky .
Возможность поиска предполагает возможное наличие утечек информации с каждым поисковым запросом[11]. Они могут быть связаны с детерминированностью этапов шифрования, ограничениями входных данных и т. д. В качестве возможного решения рассматривалось использование oRAM для скрытия работы сервера и уменьшения утечек[11], но этот метод также и критиковался[12].
Для удовлетворения потребности в поиске, первым был предложен алгоритм Сонг-Вагнера-Перрига, при котором пользователь делает поисковые запросы на файловый сервер с зашифрованными данными, но при этом не раскрывает ему ни содержимого файлов, ни самого поискового запроса. Шифрование заключается в выполнении обратимой операции (например, XOR) с псевдослучайной последовательностью, а ключом, соответственно, является зерно ГПСП. Такая схема выполняет поиск за линейное от размера шифротекста время, а ее надежность зависит от качества псевдослучайной последовательности и прешифрования .
Кроме методов с основой из симметричного шифрования, свое место имеют алгоритмы с использованием открытого ключа. Например, электронные письма могут шифроваться для адресата его открытым ключом. Адресат может пожелать хранить их на удаленном почтовом сервере, но сохранить возможность поиска. Либо, схема может быть рассчитана на то, что из зашифрованного сообщения почтовый сервер сможет понять, что в нем, например, содержится ключевое слово («важно») и составит маршрут или установит приоритет пересылки письма соответствующим образом, но не узнает ничего кроме этого слова [13].
SE основана на наличии клиент-серверной архитектуры. Как следствие, различные подходы к созданию алгоритмов могут различаться по количеству клиентов, имеющих доступ к данным. Могут быть один или несколько клиентов с правом размещать данные на сервере (записывающие), и один или несколько клиентов с правом производить поиск (читающие). Таким образом, выделяются 4 класса алгоритмов :
К классу S/S относятся, в большей степени, алгоритмы симметричного шифрования, так как хозяин информации будет хранить у себя единственный ключ. Алгоритмы класса M/S предполагают наличие множества клиентов, шифрующих данные для единственного получателя. Так, например, устроена система шифрованной электронной почты. Стоит отметить, что алгоритмы этого класса можно тривиальным образом превратить в S/S алгоритмы, если читающий клиент не будет распространять открытый ключ .
В обзорной статье 2016-го года приводятся статистика наличия исследований в различных классах SE:
| Архитектура | S/S | S/M | M/S | M/M |
|---|---|---|---|---|
| точное совпадение | ✓ | ✓ | ✓ | ✓ |
| конъюнкция | ✓ | - | ✓ | ✓ |
| сравнение | - | - | ✓ | - |
| поднабор | (✓) | - | ✓ | - |
| диапазон | (✓) | - | ✓ | - |
| wildcard | - | - | ✓ | - |
| fuzzy | ✓ | - | - | - |
| Количество схем | 28 | 2 | 19 | 9 |
| Количество реализаций | 6 | 1 | 0 | 2 |
| Временной промежуток | 2000-2013 | 2009-2011 | 2004-2011 | 2007-2008 |
Алгоритм Song-Wagner-Perrig был предложен в статье 2000-го года и является разновидностью симметричного шифрования с поиском . Он работает за линейное от размеров шифруемых данных время и использует фундаментальные криптографические примитивы, что делает его удобным для рассмотрения .
Основную идею можно рассмотреть на следующем примере, где обеспечивается только возможность поиска в ущерб некоторой приватности.
Пусть пользователь Алиса хочет зашифровать документ из слов  . Ее цель — произвести обратимую операцию XOR над каждым из слов с каким-то секретным значением .
. Ее цель — произвести обратимую операцию XOR над каждым из слов с каким-то секретным значением .
Для этого ей понадобятся :
 , необходимая для расширения элементов последовательности S до длины слов (возвращает m-битные значения)
, необходимая для расширения элементов последовательности S до длины слов (возвращает m-битные значения) , для генерации ключей
, для генерации ключей  , для прешифрования
, для прешифрованияАлгоритм шифрования :
 .
. длины n бит, расположенное на позиции i, генерируется
длины n бит, расположенное на позиции i, генерируется  длины n-m бит.
длины n-m бит. как конкатенация и
как конкатенация и 
 .
. .
.При этом последовательность ключей может быть выбрана разными способами (например, использовать один и тот же ключ или какой-то набор ключей) .
Так построенная схема позволяет проводить поиск по шифротексту следующим образом :
Пусть зашифрованный документ Алисы хранится у Боба. Об этом говорит сайт https://intellect.icu . Алиса хочет отыскать слово W, поэтому отправляет его вместе с набором ключей к таким позициям i, где может находиться W. Тогда Боб проверяет, представима ли сумма по модулю очередного шифрослова с образцом в виде :

Если такое условие выполняется, то Алисе возвращается подтверждение совпадения и позиция i. Если же для какой-то из позиций ключ не передавался, то Боб ничего не узнает об этом слове .
Такой алгоритм поиска имеет линейную сложность. Недостатками базовой схемы является то, что Боб знает содержимое запроса, и при успешном поиске узнает содержимое как самого документа, так и ключей, использованных при шифровании .
Чтобы повысить гибкость поиска и приватность шифрованных данных можно использовать дополнительный генератор для ключей с отдельным ключом для него. Тогда  для каждого слова, и вместо раскрытия группы ключей, Алиса будет прикладывать к поисковому запросу только необходимый .
для каждого слова, и вместо раскрытия группы ключей, Алиса будет прикладывать к поисковому запросу только необходимый .
Чтобы Боб не получал доступ к открытым данным, их следует предварительно шифровать. То есть предварительно следует получить прешифрованный документ из  , где
, где  . Стоит отметить, что шифрование E не должно зависеть от позиции слова (одинаковые слова в разных частях документа породят одинаковый шифротекст) .
. Стоит отметить, что шифрование E не должно зависеть от позиции слова (одинаковые слова в разных частях документа породят одинаковый шифротекст) .
Для поиска, Алиса отправляет Бобу зашифрованное слово  и ключ к нему
и ключ к нему  . Боб сможет осуществить поиск, не имея доступа к открытому тексту .
. Боб сможет осуществить поиск, не имея доступа к открытому тексту .
Однако в этой схеме проявляется новый недостаток. Из одного только шифротекста Алиса не сможет получить исходный текст, если она не знает, что там было. То есть ей необходимо знать  (или, хотя бы, последние m бит) чтобы из
(или, хотя бы, последние m бит) чтобы из  восстановить .
восстановить .
Конечная форма алгоритма Сонг-Вагнера-Перрига выглядит следующим образом :
выполняется пре-шифрация: . делится на две части —
делится на две части —  длины n-m бит и
длины n-m бит и  длины m бит. генерируется ключ
длины m бит. генерируется ключ  .. расширяется до n-битного .
.. расширяется до n-битного . .
.Поиск на стороне Боба происходит как описано ранее, используя  .
.
В этой схеме Алиса (или кто-либо еще) может расшифровать данные, имея ключи  и
и  и зная положение слова i. Для этого :
и зная положение слова i. Для этого :
. считается сложением по модулю 2 старших n-m бит c .. .
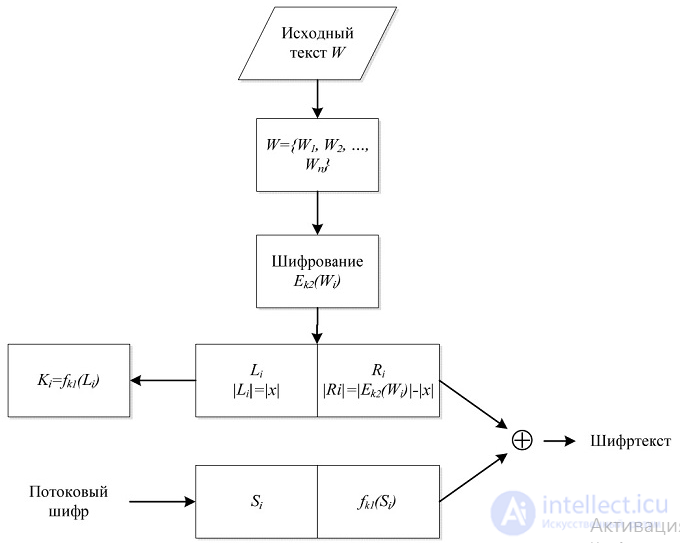
.В 2000 г. была опубликована статья Сонга «Practical Techniques for Searches on Encrypted Data» , в которой авторы представили набор алгоритмов, позволяющих производить поиск в зашифрованных данных. Сложность поиска представленных алгоритмов была линейной О(n) для каждого зашифрованного документа .
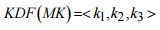 используемых в разных частях алгоритма и не позволяющих серверу расшифровать данные.
используемых в разных частях алгоритма и не позволяющих серверу расшифровать данные. , разбивается на две неравные части
, разбивается на две неравные части 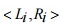 (зависит от пользовательского параметра длины левой части зашифрованного сообщения x ,
(зависит от пользовательского параметра длины левой части зашифрованного сообщения x , 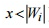 ), дополнительно обрабатываются
), дополнительно обрабатываются 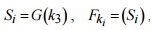 , где
, где 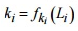 и полученные значения кладываются между собой (выполняется операция, исключаю щая или), образуя тем самым шифртекст ,
и полученные значения кладываются между собой (выполняется операция, исключаю щая или), образуя тем самым шифртекст , 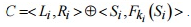 .
.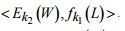 .
. , получая на выходе пару значений
, получая на выходе пару значений 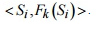 .
.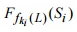 с оставшимися битами
с оставшимися битами 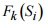 .
.Вычислительная сложность приведенного алгоритма детерминированного поиска ключевого слова в зашифрованных данных экспоненциально растет с увеличением входных данных, что объясняет его неприменимость на практике.
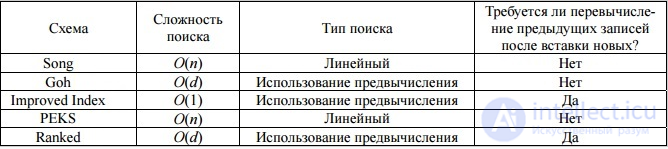
Подробного описания остальных присутствующих в сравнении разработанных схем поиска в зашифрованных данных не приводится, поскольку ни одна из них не находит вхождения в зашифрованных данных, а выполняет только поиск ключевых слов при полном совпадении .
Специалисты исследовательского подразделения Fujitsu разработали метод поиска подстроки по зашифрованному тексту, не требующий его расшифровки и предварительного составления словаря ключевых слов .
Этот метод основан на использовании гомоморфного шифрования, благодаря этому поиск совпадения с ключевой строкой ведется непосредственно по зашифрованным данным и нет необходимости для предварительного включения ключевых слов в словарь. Предшествующие методы позволяли искать вхождение лишь одной строки в один момент времени. В методе, разработанном Fujitsu Laboratories, используется пакетный метод поиска, вследствие чего значительно увеличивается скорость обработки данных.
Исследователи из Массачусетского технологического института в 2011 году представили проект CryptDB, в рамках которого предпринята попытка решения проблемы безопасного хранения данных в БД, обслуживаемых в облачных сервисах и других неподконтрольных системах. Основная проблема при хранении важной информации в неподконтрольных СУБД связана с возможностью утечки данных в процессе взлома сервиса или в результате неправомерных действий администраторов. Для решения этой проблемы в CryptDB обеспечена поддержка шифрования, при которой данные на стороне СУБД никогда не фигурируют в открытом виде, а все передаваемые в CУБД запросы содержат только зашифрованные данные, в том числе в условных блоках.
При использовании CryptDB, в процессе выполнения SQL-запросов все действия производятся только с зашифрованными данными, т.е. пользователь может отправить SQL-запрос к СУБД и получить результат без расшифровки информации на стороне сервера (данные будут расшифрованы на оборудовании клиента). Для обеспечения сохранения конфиденциальности информации используется многоуровневая система шифрования, при которой разные данные размещаются на разных вложенных криптографических уровнях, каждый из уровней имеет свой ключ и поддерживает ограниченный набор простейших операций над зашифрованными данными. Для скрытия данных на каждом уровне используются свои методы гомоморфного шифрования, при которых данные необратимо искажаются, но сохраняется возможность совершения определенных математических операций, которые дадут аналогичные результаты, что и операции над исходными данными (можно использовать зашифрованные данные для сравнения, сортировки, сложения и т.д. без предварительной расшифровки, например, выполняется условие decrypt(crypt(A) + crypt(B)) = A + B).
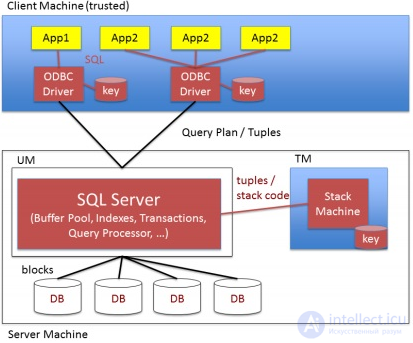
Cipherbase — реляционная база данных, которая использует новейшее специально настроенное оборудование для хранения и обработки данных в зашифрованном виде. Cipherbase является дополнением Microsoft SQL Server, разработанная специально для организаций, предоставляющих услуги баз данных и озабоченных проблемой безопасности данных, в том числе и от нечестных администраторов БД .
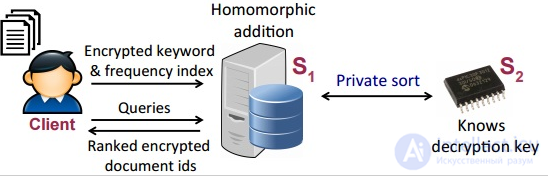
MRSE — система поиска по зашифрованным данным, которая эффективно обрабатывает множество запросов одновременно, не расшифровывая при этом данные и сохраняя их конфиденциальность. В основе системы лежит частично гомоморфное шифрование .
До закрытия Google Desktop предполагалось, что он будет ярким примером использования SSE .
Однако на текущий момент реализации алгоритмов (например, открытая реализация OpenSSE) имеют скорее исследовательский, а не практический характер
Данная статья про поиск по зашифрованному тексту подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое поиск по зашифрованному тексту, searchable encryption, peks, sse и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Информационная безопасность, Шифры в криптографии




Комментарии