Лекция
Это окончание невероятной информации про risk.
...
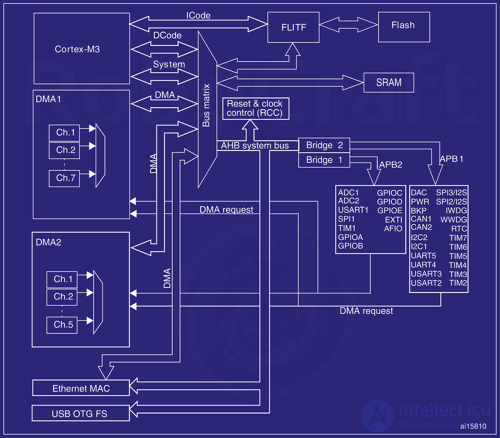
style="font-family:verdana,sans-serif; font-size:14px">Сегодня шины стали сложнее их число увеличилось на порядок. Раздельные шины дают возможность работать с несколькими устройствами одновременно, причем на разных скоростях: у каждой шины может быть своя скорость. Можно гибко управлять энергопотреблением, отключая неиспользуемые устройства и целые шины. Для управления всей этой оравой шин понадобилось вводить специальный контроллер, управляющий обменом данными между шинами и процессором.
Шинная матрица — это развитие идеи простого контроллера шины: здесь шины соединены так, что устройства могут взаимодействовать напрямую, не через ядро. Также она управляет доступом к не-выровненным данным (адреса которых не кратны 4, как принято в 32-битных архитектурах) и атомарным доступом к отдельным битам в специально выделенном диапазоне (технология bit-banding)
Архитектурой Cortex-M3 предусмотрены 4 шины, подключенных к матрице:
AHB — это относительно новая спецификация для более производительных шин, так что шины этого типа используют, в основном, для связи высокоскоростных внутренних компонентов, а APB, как более медленную — для периферии типа GPIO, UART и пр.
/* Включаем тактирование порта C */
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE);
Так вот, в названии функции видны теперь уже знакомые нам RCC и APB2, и ее смысл становится понятен: «RCC, включи тактирование на шине APB2 для периферии GPIOC».
Кроме того, RCC позволяет прямо в процессе работы МК переключаться между источниками тактирования — внешним кварцем или керамическим резонатором и встроенной откалиброванной RC-цепочкой, а также запрашивать у NVIC немаскируемое прерывание при сбое внешнего источника и переключаться на внутренний, увеличивая надежность системы.
Интерфейс SDIO (в Performance line), а также Ethernet и USB OTG FS (в Connectivity line) подключены к шине AHB напрямую.
Direct Memory Access — это технология, позволяющая устройствам обмениваться данными друг с другом без участия ядра. Делается это так: контроллер DMA программируется так, чтобы осуществлять копирование данных из одной области памяти в другую, после чего требуется лишь запустить процесс — и контроллер сам начнет копировать данные, а ядро МК в это время может выполнять другой код. При этом, копирование байта в регистр данных интерфейса SPI приводит к передаче этого байта по SPI, и таким образом можно готовить данные в виде пакетов по N байт, а потом скармливать их контроллеру DMA.
Работает это за счет того, что контроллер подключен напрямую к шинной матрице по собственной шине и имеет прямой доступ ко всей памяти, включая память, на которую отображены управляющие регистры периферии. Контроллер в некотором смысле независим от ядра, и может сильно разгрузить последнее в том случае, если нужно обработать большое количество поступающей информации по нескольким интерфейсам. А для того, чтобы узнать о завершении передачи, контроллер может генерировать прерывания начала/конца передачи.
Вы уже знаете, что Cortex-M3 — полностью 32-битная архитектура. Это значит, что все шины 32-битные и все регистры процессорного ядра тоже. Что это дает? Во-первых, большинство чисел, с которыми реально приходится работать программисту и программе, в большинстве случаев не превышают максимального значения 32-битного беззнакового числа — 4294967295. С другой стороны, эти числа часто бывают больше 255 — максимального значения 8-битного беззнакового числа. Таким образом, большинство вычислений даже с довольно большими числами даются 32-битному процессору легче, чем 8-битному, т.к. последнему приходится разбивать операцию с числами на несколько операций с меньшими их «кусками» размером по 8 бит. На сайте компании ARM Ltd. есть прикольный пример, показывающий преимущества 32-битного вычислительного ядра:

Суть такова: в ядрах Cortex-M умножение двух 16-битных чисел делается одной командой, ядра меньшей разрядности нервно курят вычисляют в сторонке. Конечно, пример специально выбран такой, чтобы опустить конкурентов пониже, но это на самом деле правда — ядра большей разрядности рулят (:
Рулеж тут еще и в том, что с такой разрядностью можно адресовать 4 ГБ памяти — не нужно никаких ухищрений типа банков памяти и сегментной адресации, чтобы адресовать встроенную Flash-память, SRAM, периферию и еще внешнюю память на отдельной микросхеме. А память в Cortex-M3 разделена на заранее оговоренные области, которые можно посмотреть в этой таблице:
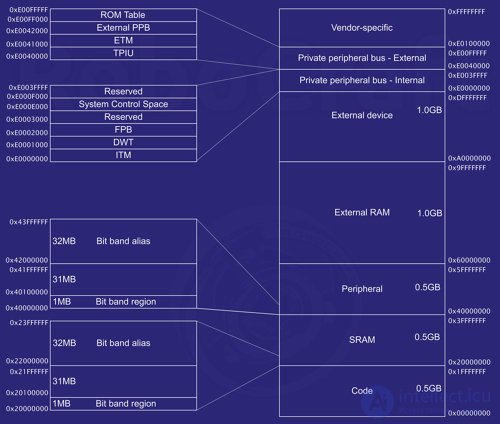
Доступ к пямяти можно осуществлять 32-битными словами, полусловами и байтами. Есть ограничения на некоторые регистры периферии, и об этом всегда пишут в Reference manual. Но это важно, по большому счету, больше для пишущих на ассемблере.
Напоследок немного об ассемблере и инструкциях. Как обычно, доступны все те же обычные инструкции типа копирования из памяти в регистры обратно, ветвлений и логических и арифметических операций. Но есть и некоторые уникальные особенности: например, большинство инструкций может быть выполнено условно. Нет, не только привычным способом:
cmp r2,r3 ; x == y
beq after
muls r0, r1, r0
add r0, r0, r2
after:
...
cmp r2,r3 ; x == y
itt eq
mulseq r0, r1, r0
addeq r0, r0, r2
...
Инструкция вида ITxxx делает от одной до 4х последующих инструкций условными, избавляя от необходимости в условных переходах, которые выполняются дольше. И подобных интересных инструкций еще довольно много, включая инструкции для извлечения/установки битовых полей. Короче, рай для ассебмлерщика.
Thumb (Большой палец/Тумба)
Для улучшения компилируемой плотности кода, процессоры, начиная с ARM7TDMI, снабжены режимом тумбы (в оригинале обыграны слова arm--рука и thumb--большой палец). В этом режиме процессор выполняет 16-разрядные команды. Большинство из этих 16-разрядных команд тумбы переводятся в нормальные команды ARM. Экономия пространства происходит за счет сокрытия некоторых операндов и ограничения возможностей по сравнению с режимом полного набора команд ARM.
В режиме тумбы меньшие коды операций обладают меньшей функциональностью. Например, только ветвления могут быть условными, и многие коды операций имеют ограничение на доступ только к половине главных регистров процессора. Более короткие коды операций в целом дают большую плотность кода, хотя некоторые операции требуют дополнительных команд. В ситуациях, когда порт памяти или ширина шины ограничены 32мя битами, более короткие коды операций режима тумбы становятся гораздо производительнее по сравнению с обычным 32-битным ARM кодом, так как меньший программный код придется загружать в процессор при ограниченной пропускной способности памяти.
Thumb-2
Thumb-2 — технология, стартовавшая с ARM1156 core, анонсированного в 2003 году. Он расширяет ограниченный 16-битный набор команд Thumb дополнительными 32-битными командами, чтобы задать набору команд дополнительную ширину. Цель Thumb-2 — достичь плотности кода как у Thumb, и производительности как у набора команд ARM на 32 битах. Можно сказать, что в ARMv7 эта цель была достигнута.
Thumb-2 расширяет как команды ARM, так и команды Thumb еще большим количеством команд, включая управление битовым полем, табличное ветвление, условное исполнение. Новый язык «Unified Assembly Language» (UAL) поддерживает создание команд как для ARM, так и для Thumb из одного и того же исходного кода.
Jazelle
Jazelle — это метод, который позволяет байткоду Java исполняться прямо в архитектуре ARM в качестве 3го состояния исполнения (и набора команд) наряду с обычными командами ARM и режимом бегунка. Поддержка этого свойства обозначается буквой «J» в названии процессора — например, ARMv5TEJ. Необходимость такой поддержки появляется начиная с процессоров ARMv6, хотя новые ядра лишь содержат тривиальные реализации, которые не поддерживают аппаратного ускорения.
Усовершенствованный SIMD(NEON)
Расширение усовершенствованного SIMD, также называемое технологией NEON — это комбинированный 64- и 128-битный набор команд SIMD (single instruction multiple data), который обеспечивает стандартизованное ускорение для медиа приложений и приложений обработки сигнала. NEON может выполнять декодирование аудио формата mp3 на частоте процессора в 10Мгц, и может работать с речевым кодеком GSM AMR (adaptive multi-rate) на частоте более чем 13Мгц. Он обладает внушительным набором команд, отдельными файлами регистра, и независимой системой исполнения на аппаратном уровне. NEON поддерживает 8-,16-,32-,64-битную информацию целого типа, одинарной точности и с плавающей точкой, и работает в операциях SIMD по обработке аудио и видео (графика и игры). В NEON SIMD поддерживает до 16 операций единовременно.
VFP
Другие сопроцессоры с плавающей точкой и/или SIMD, находящиеся в ARM процессорах включают в себя FPA, FPE, iwMMXt. Они обеспечивают ту же функциональность, что и VFP, но не совместимы с ним на уровне опкода.
Расширения безопасности
Отладка
Все современные процессоры ARM включают аппаратные средства отладки, так как без них отладчики ПО не смогли бы выполнить самые базовые операции типа остановки, отступа, установка контрольных точек после перезагрузки.
Архитектура ARMv7 определяет базовые средства отладки на архитектурном уровне. К ним относятся точки останова, точки просмотра и выполнение команд в режиме отладки. Такие средства были также доступны с модулем отладки EmbeddedICE. Поддерживаются оба режима — остановки и обзора. Реальный транспортный механизм, который используется для доступа к средствам отладки, не специфицирован архитектурно, но реализация, как правило, включает поддержку JTAG.
Архитектура ядра ARM7TDMI приведена на рис.24.2.
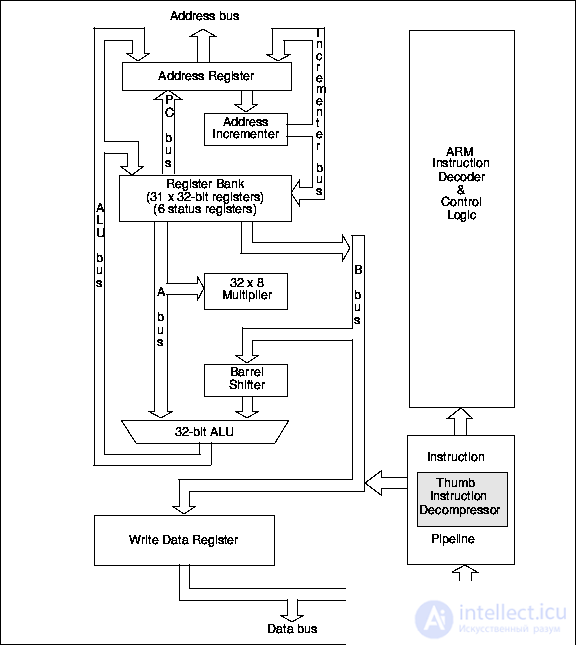
Рис.24.2. Упрощенная архитектура ядра ARM7TDMI
Ядро ARM7TDMI стало первым Thumb-ориентированным ядром. Это ядро семейства ARM7 располагающее:
– встроенной макроячейкой EmbeddedICE™, поддерживающей отладку встроенного ядра ,
– 32-разрядным аппаратным умножителем ,
– декомпрессором Thumb,
– 32-разрядной производительностью в 8- и 16-разрядных управляющих применениях .
Ядро ARM7TDMI пополнило стандартный ряд 32-разрядных ядер ARM, обеспечив возможность выхода на рынок встраиваемого управления, привнося 32-разрядную производительность в 8 и 16-разрядные применения управления. Первый Thumb-ориентированный прибор в кремнии был выпущен во второй половине 1995.
Ядро ARM7TDMI используется как лицензионная макроячейка ARM, предназначенная использования при создании стандартных приборов специального назначения .
И ARM7 и ARM7T ядра в одном тактовом цикле, используют 3-уровневый конвейер с фазами выборки, декодирования и выполнения
( рис.24.3). Поток команд через каждый уровень конвейера управляется высокими и низкими фазами тактового сигнала. В ядре ARM7TDMI неиспользуемая фаза тактового сигнала используется для декомпрессирования команд Thumb в каскаде декодирования. Следовательно, в одном тактовом цикле производится и декодирование и выполнение команды, не требуется никаких дополнительных непроизводительных затрат синхронизации.

Рис.24.3. Thumb декодирование и декомпрессия
Команды ARM, поступающие из каскада выборки конвейера, проходят через декодер ARM и активируют сигналы управления старшими и младшими битами операционного кода. Старшие биты опкода описывают тип выполняемой команды, тогда как младшие биты определяют детали команды типа определения регистров или операнда.
В Thumb состоянии мультиплексоры направляют Thumb команды через логику декомпрессии Thumb, разворачивающую команду Thumb в ее эквивалент ARM команды . Затем команда ARM выполняется в нормальном режиме.
Блок-схема ядра ARM1020T семейства ARM10 приведена на рис.24.4.
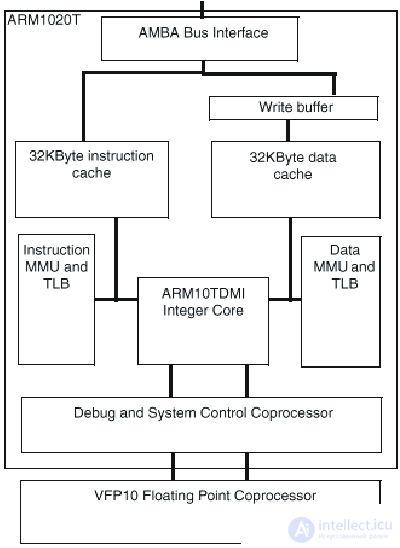
Рис.24.4. Блок-схема ядра ARM1020T
Главной особенностью семейства ARM10 является наличие векторного сопроцессора вычислений с плавающей точкой, явного свидетельства современной тенденции к объединению в одном приборе управляющих целочисленных процессоров и процессоров цифровой обработки сигналов..
В основе процессоров семейства ARM10 Thumb целочисленное ядро ARM10TDMI(TM), использующее ARM® 32-разрядную RISC систему команд, сжатую 16-разрядную систему команд Thumb и расширенные Multi-ICE средства отладки программного обеспечения. Ядро процессора ARM10TDMI - первая реализация ARMV5T Архитектуры Системы команд (Instruction Set Architecture - ISA). Архитектура ARMV5T - некоторая комбинация архитектуры ARMV4 ISA, используемой StrongARM процессорами, и ARMV4T ISA используемой процессорами семейств ARM7 Thumb и ARM9 Thumb.
Ядро ARM10TDMI оснащено пятиуровневым конвейером, реализует параллельное выполнение команд, предсказание переходов и способно продолжать работу при неудачном обращении к кэш, обеспечивая высокую производительность в реальных применениях.
Уровни конвейера целочисленного процессора ARM10TDMI.
| F: | Выборка команды и предсказание перехода |
| D: | Декодирование команды и чтение регистра |
| E: | Выполнение (Сдвиг и ALU), вычисление адреса и умножение |
| M: | Обращение к памяти и умножение |
| W: | Запись в регистры |
Процессор ARM10T обеспечивает производительность 400 MIPS
( миллионов операций в секунду) на частоте 300 МГц, а векторное устройство операций с плавающей точкой, обеспечивает производительность 600 MFLOPS (миллионов операций с плавающей точкой в секунду). Такие уровни целочисленной и с плавающей точкой производительности необходимы для применений, оснащенных сложными интерфейсами с 2- и 3-мерной графикой, типа игровых видео плееров и высокопроизводительных принтеров, при сохранении доступных потребительских цен.
В настоящее время в семейство входит ARM1020T™ - кэшированное макроядро процессора, сформированное на основе ядра ARM10TDMI и оснащенное встроенными кэш команд и данных емкостью по 32 Кбайт, MMU, поддерживающим виртуальную память с подкачкой страниц по требованию, буфером записи, и широкополосным шинным интерфейсом AMBA, класса "система на кристалле".
Сопроцессор векторных вычислений с плавающей точкой VFP10 (Vector Floating Point - VFP) интегрируется на тот же кристалл что и процессор ARM1020T в тех применениях, для которых он необходим. Сопроцессор VFP10 - первая реализация новой архитектуры VFPV1 процессоров вычислений с плавающей точкой фирмы ARM. Сопроцессор VFP10 обеспечивает высокопроизводительные IEEE вычисления с плавающей точкой одиночной и двойной точности, занимая на кристалле площадь малого размера и при его реализации был использован RISC подход, заключающийся в том, что простые, наиболее часто используемые операции реализуются в кремнии (аппаратно) а для обработки редких исключительных случаев используются программные решения. Векторные операции хорошо использовать для обеспечения потребностей целевых применений и они обеспечивают существенный параллелизм при простой схемотехнике.
В конвейере вычислений с плавающей точкой VFP10 используется два конвейера - пятиуровневый конвейер команд загрузки и памяти и семиуровневый конвейер арифметических команд. Эти конвейеры совместно используют два первых уровня, что ограничивает количество выполняемых команд одной командой, но из-за векторного характера архитектуры VFP в параллель могут быть выполнены команда векторной арифметики и векторной загрузки или команда сохранения.
Конвейером отслеживаются пять уровней загрузки и хранения. В случае выполнения множественных пересылок уровень памяти конвейера используется многократно для каждого элемента данных. За каждый цикл могут быть перемещены два значения одиночной точности или одно значение двойной точности.
В семиуровневом арифметическом конвейере первые 3 уровня соответствуют конвейеру ARM, в которых команды принимаются от ARM (выборка, декодирование и выполнение). Команды загрузки и сохранения и команды пересылки данных, остаются зафиксированными в ARM на два следующих цикла, с тем, чтобы передать данные на соответствующем уровне памяти ARM, и записи данных на пятом уровне.
Специалисты фирмы ARM так излагают основные идеи заложенные в семействе процессоров ARM10: чтобы отслеживать характер работы и, в зависимости от этого, снижать потребление, разработчики отказались от сложности и дороговизны полностью суперскалярной машины. Необходимый уровень производительности был достигнут за счет использования уникальных особенностей архитектуры ARM, обеспечивающих высокую степень внутреннего параллелизма в единожды созданной машине. Система команд векторных операций с плавающей точкой полностью новая, так что разработчики, проанализировав алгоритмы, необходимые для основных применений, имели возможность создать устройство очень быстрое, применяя возможные кремниевые решения для наиболее часто используемых операций, оставляя на долю программных решений действительно уникальные операции.
1. Характерные особенности RISC-архитектуры .
2. Назначение механизма перекрывающихся регистровых окон .
3. Характерные особенности архитектура ARM.
4. Назначение предиката в ARM.
5. Дополнительные технологии в ARM.
6. Технологии Thumb и Thumb2.
7. Технология Jazelle.
8. Технология NEON.
9. Технология VFP.
10. Система безопасности TrustZone Technology.
11. Упрощенная архитектура ядра ARM7TDMI.
12. Thumb декодирование и декомпрессия.
13. Блок-схема ядра ARM1020T.
Часть 1 Тема 17. RISK и ARM– процессоры
Часть 2 Аппаратная модель STM32 - Тема 17. RISK и ARM– процессоры
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии
Оставить комментарий
Компьютерная схемотехника и архитектура компьютеров
Термины: Компьютерная схемотехника и архитектура компьютеров