Лекция
Привет, сегодня поговорим про развитие архитектуры эвм, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое развитие архитектуры эвм , настоятельно рекомендую прочитать все из категории Компьютерная схемотехника и архитектура компьютеров.
Ранее отмечалось, что в процессе эволюции классическая структура ЭВМ претерпела некоторые изменения, в частности, изменилось устройство памяти, организация которого стала иерархической. Однако это далеко не все изменения, которые произошли с классической пятиблочной структурой ЭВМ и ее основными принципами функционирования, сформулированными фон Нейманом.
Ниже очень коротко рассматриваются некоторые элементы архитектуры современных ЭВМ четвертого поколения, которые выходят за рамки классических структур и принципов функционирования первых ЭВМ различных классов. Материал раздела, по возможности, иллюстрируется примерами построения упрощенных элементов вычислительных устройств на базе процессора I80386, структуры которых достаточно прозрачны.
Одним из эффективных средств совершенствования архитектуры современных ЭВМ является теговая организация памяти, при которой каждое хранящееся в памяти или регистре слово снабжается тегом. Тег определяет тип данных – целое число, ЧПЗ, десятичное число, адрес, строку символов, дескриптор и т.д. В поле тега обычно указывают не только тип, но и длину (формат) и некоторые другие его параметры. Теги формируются компилятором. Формат данных, хранимых в памяти, при этом имеет вид, изображенный на рис. 22.1.

Рис.22.1. Теговая организация памяти
Наличие тегов придает хранящимся в машине данным свойство самоопределяемости. Это принципиальная особенность в функционировании ЭВМ.
Следует отметить, что ЭВМ с теговой памятью выходят за рамки модели вычислительной машины фон Неймана именно в результате самоопределяемости данных. Классическая модель фон Неймана исходит из того, что тип (характер) данного, хранящегося в памяти, определяется только в контексте выполнения программы, а точнее, команды, использующей данное в качестве операнда. В обычных ЭВМ, соответствующих классической модели фон Неймана, тип данных-операндов и их формат задаются кодом операции команды, а в ряде случаев размер (формат) операндов определяется специальными полями команды.
Например, в IBM-360/370 команда десятичное сложение самим своим кодом операции определяла, что адресуемые ею операнды являются десятичными числами. Специальные четырехразрядные поля в этой команде задавали число десятичных цифр в 1-м и 2-м операндах. Таким образом, в IBM-360/370 имелось 256 кодов только одной командыдесятичное сложение.
Теговая организация памяти позволяет достигнуть инвариантности команд относительно типов и форматов операндов, что приводит к значительному сокращению набора команд машины. Это упрощает и делает более регулярной структуру процессора. Кроме того, такая организация памяти дает еще ряд преимуществ, а именно:
- облегчает работу программиста, в том числе при отладке программ;
- сокращает затраты времени на компиляцию (отпадает необходимость выбора типа команды в зависимости от типа данных);
- облегчает обнаружение ошибок, связанных с некорректным заданием типа данных (например, при попытке сложить адрес с ЧПЗ).
Теговая организация памяти способствует реализации принципа независимости программ от данных.
И, наконец, нечто неожиданное. Использование тегов приводит к экономии памяти, несмотря на удлинение формата данных. Это объясняется тем, что в программах обычных машин имеется большая информационная избыточность на задание типов и размеров операндов при их использовании несколькими командами.
К недостаткам такой организации памяти можно отнести некоторое замедление работы процессора из-за того, что установление соответствия типа команды типу данных в обычных ЭВМ выполняется на этапе компиляции, а при использовании тегов переносится на этап выполнения программы.
В архитектуре современных ЭВМ широко используются также дескрипторы – служебные слова, содержащие описания массивов данных и команд. Дескрипторы могут употребляться как в машинах с теговой организацией памяти (например, ЭВМ "Эльбрус"), так и без тегов (например, компьютеры фирмы IBM на процессорах I80286 и старше). В последнем случае достигается ограниченная самоопределяемость данных.
Дескриптор содержит сведения о размере массива данных, его местоположении (в ОП или ВП), адресе начала массива, типе данных, режиме защиты данных (например, запрет записи в ячейки массива) и некоторых других параметрах данных, которые позволяют упростить работу с массивами. Так, задание в дескрипторе размера массива позволяет контролировать выход за его границу при индексации его элементов.
В качестве примера рассмотрим один из видов дескрипторов – дескриптор данных в машине B6700 фирмы Burroughs (рис. 22.2).
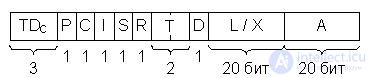
Рис.22.2. Дескриптор данных ЭВМ B6700 Burroughs, TDc – тег дескриптора
Дескриптор содержит специфический тег TDc, указывающий, что данное слово является дескриптором определенного вида, группу указателей и два поля A и L/X. Поле A указывает адрес начала массива данных. В зависимости от значения указателя I дескриптор описывает массив данных (I = 0)– и в соответствующее поле помещается длина массива L, или описывает элемент массива (I = 1)– и тогда в поле находится индекс X. Этот индекс указывает смещение элемента относительно начала массива. Указатель P определяет, находится массив в оперативной памяти или ВП, т.е. его можно назвать "Указатель присутствия". В последнем случае (нахождение в ВП) поле A указывает местоположение массива во внешней памяти. Остальные указатели имеют следующий смысл:
D – одинарная или двойная точность представления данных;
T – описывается слово или строка;
R = 1 – данные можно только читать;
S – указывает на непрерывное или фрагментарное расположение массива в памяти;
C – определяет, является ли дескриптор копией другого дескриптора.
Процессоры фирмы Intel, начиная с модели I80386, снабжены средствами, позволяющими реализовать механизм разделения логического адресного пространства памяти на страницы (4 Кбайт) и сегменты разного размера (сегменты программ, данных, системные сегменты и т.д.). Более подробно этот вопрос обсуждается в п. 16.4. Все сегменты рассматриваются как массивы, и для их описания и адресации используются дескрипторы. Каждая задача может иметь системное и индивидуальное логическое адресное пространство. Эти пространства описываются соответственно глобальной (GDT) и локальной (LDT) таблицами дескрипторов сегментов, каждая из которых может содержать максимум 8192 дескриптора. На рис. 22.3 представлен формат дескрипторов сегмента программ и сегмента данных процессора I80386.
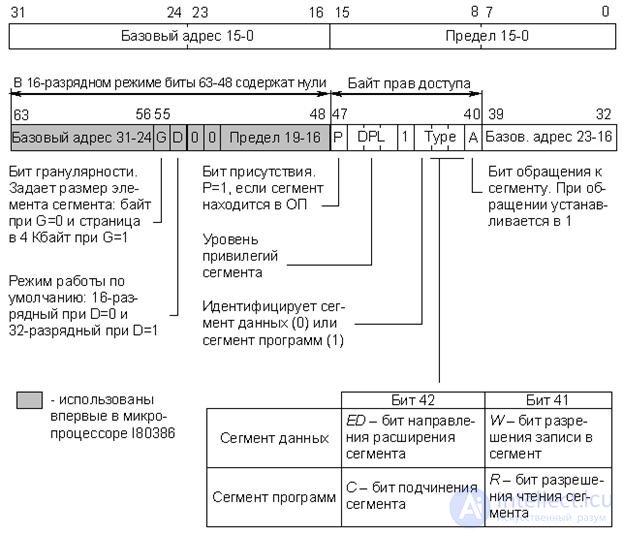
Рис.22.3. Формат дескрипторов сегментов программ и данных процессора I80386
Назначение полей дескриптора приведено на рис. 22.3, однако необходимо сделать некоторые пояснения:
- "16-разрядный режим" – это режим полной эмуляции процессора I80286.
- "Базовый адрес" – 32-битное поле (из трех фрагментов), определяющее положение сегмента в адресном пространстве 4 Гбайт.
- "Предел" – 20-битное поле (из двух фрагментов), определяющее размер сегмента. В зависимости от значения бита гранулярности G предел вычисляется либо в байтах (G = 0), либо в страницах по 4 Кбайта (G = 1). В первом случае размер сегмента не превышает 1 Мбайт, во втором – может достигать 4 Гбайт.
Использование в архитектуре ЭВМ дескрипторов подразумевает, что обращение к информации в памяти производится через дескрипторы, которые при этом можно рассматривать как дальнейшее развитие аппарата косвенной адресации. Адресация информации в памяти может осуществляться с помощью цепочки дескрипторов. При этом реализуется многоступенчатая косвенная адресация. Более того, сложные многомерные массивы данных (таблицы и т.п.) эффективно описываются древовидными структурами дескрипторов. Это можно проиллюстрировать упрощенной схемой на рис. 22.4.

Рис.22.4. Описание двумерного массива данных древовидной структурой дескрипторов
Термины "тег" и "дескриптор" достаточно широко используются в технической литературе при обсуждении вопросов организации ЭВМ и вычислительных процессов. Однако трактовка этих терминов во многих случаях достаточно неоднозначна, особенно в технических описаниях конкретных процессоров и ЭВМ различных производителей, поэтому необходимо всегда учитывать контекст, в котором используются указанные термины.
Вначале очень коротко рассмотрим причины, вынуждающие инженеров непрерывно совершенствовать аппаратную и идеологическую основы процессов обмена данными между процессором и памятью.
Как уже отмечалось, память современных ЭВМ имеет иерархическую, многоуровневую структуру. Чем выше уровень, тем выше быстродействие и тем меньше емкость. К верхнему уровню относятся ЗУ, с которыми процессор непосредственно взаимодействует в процессе выполнения программы. Это, прежде всего, основная или оперативная память (ОП), а также сверхоперативная внутренняя память процессора. Последняя имеет очень малую емкость и во внимание приниматься не будет, т.е. речь пойдет только об обмене процессор – ОП. К нижнему уровню памяти относятся внешние ЗУ, обладающие большой емкостью и малым быстродействием. Во всех современных ЭВМ вычислительный процесс строится так, чтобы число обращений к ВП было минимальным. В отличие от ВП современные ОП имеют достаточно высокое быстродействие (цикл обращения составляет десятки наносекунд и менее). Однако при организации взаимодействия процессор – ОП возникает много проблем, связанных с несоответствием пропускной способности процессора и памяти.
Непрерывный рост производительности (скорости работы) ЭВМ, вызываемый потребностями их применения, проявляется, в первую очередь, в повышении скорости работы процессоров. Это достигается использованием более быстродействующих электронных схем, а также специальных архитектурных решений (конвейерная и векторная обработка данных и др.). Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора. Это происходит прежде всего потому, что одновременно идет опережающий рост ее емкости, что делает более трудным уменьшение времени цикла работы памяти.
Результаты, к которым приводит такой разрыв в быстродействии процессора и ОП, можно проиллюстрировать на простейшем примере. Рассмотрим типичный цикл обращения микропроцессора к ОП, состоящий из ряда тактов Т1 Т2 ... Т5, например МП КР580. В такте Т1 МП выставляет на ША адрес ячейки памяти, к которой будет произведено обращение. В такте Т2 МП ожидает приход сигнала READY от модуля памяти. Количество тактов Т2 в общем случае не ограничено. Такт Т3 наступает только после поступления сигнала READY. Из этого примера становится понятным, почему увеличение тактовой частоты не всегда приводит к увеличению скорости выполнения программ, так как МП просто "топчется на месте" в ожидании ответа ОП.
Из всего сказанного следует, что существует, по крайней мере, два направления оптимизации процессов обмена процессора и ОП.
Первое направление – это совершенствование их аппаратной базы. Но, как оказалось, на этом направлении есть ряд серьезных препятствий как технологических, так и принципиальных. Одно из них связано со скоростью распространения электрического сигнала в проводнике. При низкой скорости обмена явление запаздывания сигнала не заметно. Однако оно становится заметным при повышении этих скоростей до величин, пропорциональных
109 обр./с. При дальнейшем увеличении частоты обращений становится невозможным гарантировать правильность работы ОП, так как время получения данных будет существенно зависеть от места их расположения в ОП.
Второе направление – это оптимизирующие алгоритмы взаимодействия процессора и ОП, которые, естественно, также требуют аппаратной поддержки. Ниже, очень коротко, рассматриваются наиболее распространенные методы этого направления, используемые при создании современных ЭВМ.
Рассмотрим основные принципы конвейеризации процедур цикла выполнения команды (рабочего цикла машины).
Ранее, при рассмотрении принципов функционирования УУ процессоров, уже упоминалось о конвейерном способе выполнения микрокоманд, когда процедура выполнения i-й микрокоманды в АЛУ совмещалась по времени с процедурой вызова из управляющей памяти i+1 микрокоманды. Этот принцип распространяется и на выполнение команд машины. Еще в 1956 г. академик Лебедев С.А. предложил повышать производительность машин, используя принцип совмещения во времени отдельных этапов рабочего цикла, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды.
В современных ЭВМ очень широко используются различные варианты конвейерного способа выполнения операций, что существенно повышает их производительность. Не вдаваясь в подробности, рассмотрим простейший пример конвейерного способа выполнения микропроцессором операции сложения двух операндов, находящихся в ОП. Для этого необходимо выполнить две команды: 1-я – вызов первого операнда в аккумулятор; 2-я – вызов второго операнда и сложение. В процессе выполнения 1-й команды можно использовать ресурсы МП во время ожидания ответа ОП (например, в МП КР580 это такт Т2 каждого машинного цикла). Для этого необходимо, чтобы вместо пассивного режима ожидания МП инициировал новый цикл обмена с ОП для вызова 2-й команды. По соответствующим сигналам готовности ОП последовательно заканчиваются 1-й и 2-й циклы обращения к памяти и выполняется операция сложения. При этом время каждого обращения к ОП не уменьшается, но суммарное время выполнения двух команд оказывается меньше за счет их перекрытия во времени. Практика показала, что использование конвейера в той или иной форме существенно повышает в среднемскорость обмена процессор – ОП. При этом, естественно, усложняется программное и аппаратное обеспечение ЭВМ в целом (а не только одного МП).
В общем случае конвейерный принцип позволяет процессору параллельно выполнять множество команд. Однако в этом случае как единое устройство процессор функционировать уже не может. Последовательность выполнения каждой команды разделяется в процессоре на основные операции. Для выполнения операций каждого типа служат специализированные исполнительные устройства.
Наиболее общий прием конвейеризации заключается в том, что во время выполнения предыдущей команды с упреждением производится выборка из памяти очередной команды. Тем самым достигается рациональное использование времени работы шины, которое при обычной архитектуре процессора затрачивалось впустую, и сокращается длительность выполнения программы, хотя длительность цикла выполнения отдельных команд может даже несколько увеличиться.
Совмещение во времени этапов цикла выполнения команды давно и широко используется в процессорах, которые в этом случае представляют собой совокупность специализированных исполнительных блоков, управляемых одним УУ. Так, например, в МП фирмы Zilog Z80000 использован шестиступенчатый конвейер, а цикл выполнения команды состоит соответственно из шести этапов:
- выборки команды;
- декодирования команды;
- вычисления адреса операнда;
- выборки операнда;
- собственно выполнения операции;
- запоминания результата.
Когда в конвейере заканчивается выполнение определенного этапа предыдущей команды, высвобождается соответствующий исполнительный блок и может быть начато выполнение аналогичного этапа следующей команды. В идеальной ситуации очередная команда должна поступать на конвейер в тот момент, когда предыдущая команда с него сходит. Это соответствует шестикратному повышению производительности. Однако при исполнении реальных программ максимальная производительность никогда не достигается по ряду причин. Это, прежде всего:
- различные продолжительности этапов выполнения команды, что вынуждает выбирать такт работы конвейера соответствующим продолжительности выполнения самого "медленного" этапа. Это приводит к некоторому увеличению длительности цикла выполнения отдельной команды (времени прохождения команды через конвейер) по сравнению с потенциально возможной;
- использование не в каждой команде всех исполнительных блоков, что требует дополнительных временных затрат на работу специальных переключающих схем;
- нарушение последовательности выполнения команд программы, которое имеет место при наличии команд передачи управления или прерываниях.
Нарушение строго последовательного выполнения команд программы вызывает необходимость очистки конвейера от команд, выполнение которых началось после команды, нарушившей эту последовательность (торможение конвейера), и повторного заполнения конвейера командами с новой точки программы (разгон конвейера). Доля команд, на которых естественная последовательность выполнения программы нарушается, обычно составляет 15-30% от общего количества команд. При этом вызываемое процентное снижение производительности превышает вероятность их появления в программе.
Наличие команд передачи управления и, в частности, команд условных переходов оказывает самое существенное влияние на производительность конвейера команд, поэтому разработчики идут на существенное усложнение архитектуры процессоров в целях уменьшения этого влияния. Основные пути уменьшения влияния команд условных переходов на производительность конвейера команд состоят в следующем:
- прогнозировании направления перехода по косвенным признакам;
- одновременной обработке команд по обоим направлениям перехода (в более простом случае – создание очередей команд);
- выборе направления перехода на основании анализа статистики ранее совершенных аналогичных переходов в теле цикла;
- выборе случайного направления перехода;
- методе "отложенных переходов", при котором на этапе компиляции после команды условного перехода размещаются команды, не связанные с направлением перехода (число таких команд равно числу ступеней конвейера).
Для уменьшения влияния различной продолжительности этапов цикла выполнения команды на производительность разработчики искусственно увеличивают число ступеней конвейера, разбивая этапы на подэтапы, продолжительность выполнения которых примерно одинакова. Об этом говорит сайт https://intellect.icu . Однако увеличение числа ступеней конвейера ведет к увеличению времени разгона, которое может существенно понизить общую производительность конвейера при обработке программ с короткими линейными участками. Виду этого число ступеней конвейера команд должно быть оптимальным.
Опыт построения конвейеров команд показывает, что полностью исключить влияние перечисленных выше факторов на производительность конвейера команд не удается. Максимальная производительность возможна только при обработке программ, имеющих длинные линейные участки, с использованием всех ступеней конвейера.
При рассмотрении метода конвейеризации обмена был проигнорирован тот факт, что реальные устройства ОП не допускают одновременного обращения к нескольким ячейкам (имеются в виду реальные БИСы памяти, охваченные общим полем адресов). Выйти из этого положения позволяет следующий метод.
Известны два основных метода расслоения памяти. Суть этих методов состоит в том, что память строится на основе нескольких модулей. Но в одном случае модули памяти имеютраздельные адресные пространства (независимая адресация), а в другом – модули охвачены общим полем адресов и образуют единое адресное пространство. Оба метода предложены достаточно давно, но широко используются и в современных ЭВМ, причем в ряде случаев совместно. Рассмотрим их очень коротко.
Метод 1
Метод разделения памяти на два модуля с независимой адресацией был предложен и опробован еще в конце 50-х гг. лабораториями Гарвардского университета. Один модуль памяти использовался для хранения команд программы, другой – данных. Оба модуля имели собственные контроллеры памяти и раздельные магистрали доступа. Такой принцип построения ОП оказался во многих случаях очень эффективным и был успешно использован при разработке компьютеров различного назначения. Возник даже термин "Гарвардская архитектура".
Этот принцип сохранен и в современных вариантах ЭВМ (процессорах) Гарвардской архитектуры. Он позволяет совместить во времени циклы обмена с обоими модулями памяти и оказывается эффективным при обработке любых типов программ. В настоящее время Гарвардская архитектура широко используется при построении кэш-памятей мощных процессоров.
Метод 2
В простейшем случае используют два модуля с "веерной" (чередующейся) адресацией, при которой смежные адреса информационных единиц, соответствующих ширине выборки (слово, двойное слово и т.д.), принадлежат разным модулям (т.е. четные адреса принадлежат одному модулю, а нечетные – другому). Это позволяет процессору инициировать второй цикл обмена до завершения первого, поскольку адреса лежат в разных модулях, либо обращаться одновременно двум устройствам к разным модулям памяти. В результате за счет перекрытия во времени обращений к разным модулям пропускная способность ОП в среднем повышается.
Следует отметить, что веерная адресация, как и конвейер команд, оказывается эффективной только при наличии в программе достаточно длинных участков с последовательным выбором команд, т.е. когда вероятность появления команд передачи управления мала. Выигрыш в быстродействии оказывается максимальным, когда необходимо осуществить множество последовательных обращений к ОП в ходе пакетных пересылок в режиме ПДП. В этом режиме в качестве параметров пересылки блока данных указывается начальный адрес и количество слов, подлежащих пересылке.
Двунаправленное расслоение ОП не может предотвратить появления циклов ожидания поэтому были разработаны системы с 4- и более кратным расслоением ОП, в которых контроллер памяти обеспечивает распределение последовательно вырабатываемых адресов между несколькими модулями памяти.
Проблема повышения пропускной способности характерна для всех уровней иерархии внутренней памяти ЭВМ. Наиболее остро эта проблема стоит перед разработчиками динамических ОП, которые благодаря максимальной информационной емкости и низкой стоимости занимают ведущее место в составе внутренней памяти компьютера. В последнее время предложен ряд вариантов ОП повышенного быстродействия. Это FPM, MDRAM, EDORAM, SDRAM, BEDORAM, RDRAM и многие другие типы памятей.
Методы повышения быстродействия таких памятей основаны на предположении о "кучности" адресов обращения к ОП, т.е. на предположении о том, что адреса последующих обращений к ОП, вероятнее всего, расположены рядом с адресом текущего обращения. Внутренние механизмы реализации этих методов схожи с механизмами конвейеризации процесса выполнения команд в процессоре, расслоения памяти, кэширования только на уровне отдельных БИСов и модулей памяти.
Суть этого метода состоит в том, что между процессором и ОП включаются дополнительные блоки буферных памятей относительно небольшой емкости, но имеющие быстродействие существенно выше, чем ОП. При обращении к таким памятям у процессора не возникает проблем с запаздыванием сигналов и уменьшением из-за этого скорости обмена. Как уже отмечалось, повышение быстродействия БИСов памяти сопровождается резким повышением их стоимости, поэтому доля буферной памяти в общем объеме небольшая, порядка 16-256 Кбайт на 4-8 Мбайт основной памяти. Сверхоперативная память, упоминавшаяся ранее, также является буферной, однако ее емкость очень незначительна (десятки слов) и в данном случае не учитывается.
В общем случае буферная память состоит из двух модулей: буферной памяти команд и буферной памяти операндов. Структура памяти в этом случае имеет вид, показанный на рис. 22.5. Такая схема буферизации ОП использовалась еще в мэйнфреймах 60-х гг.
Представленные буферные памяти в современных ЭВМ скрыты от программиста в том смысле, что он не может их адресовать и может даже не знать об их существовании, поэтому они получили название кэш-памятей (cache – тайник). Некоторые ЭВМ содержат объединенную кэш-память операндов и команд. Наличие кэш в общем случае не исключает присутствия в процессоре небольшой сверхоперативной памяти.

Рис.22.5. Схема подключения буферной памяти
Таким образом, кэш-память представляет собой быстродействующее ЗУ, размещенное в одном кристалле с процессором или же внешнее по отношению к кристаллу, но размещенное на той же плате. При обращении процессора к ОП для считывания в кэш пересылается блок информации, содержащий нужное слово. При этом происходит опережающая выборка, так как высока вероятность того, что ближайшие обращения будут происходить к словам блока, уже находящегося в кэш. Это приводит к значительному уменьшению среднего времени, затрачиваемого на выборку данных и команд.
Для обращения к кэш, размещенному вне кристалла процессора, но на одной с ним плате, может потребоваться несколько тактов, тогда как при обращении к кэш, размещенному внутри кристалла процессора, может оказаться достаточно одного такта. Однако даже размещение кэш на одной плате с процессором позволяет избежать большого числа циклов ожидания, которые неизбежны при работе с ОП, расположенной на отдельной плате и взаимодействующей с процессором через системную шину. Кроме того, выборка содержимого кэш-памяти может производиться произвольным образом, и, следовательно, в адресном пространстве кэш можно разместить командные циклы с входящими в них командами переходов (передачи управления).
Все это позволяет не только ускорить операции обмена процессор - память, но также снизить загрузку системной магистрали. Последнее стало особенно актуально с возникновением многопроцессорных систем, в которых процессорные элементы располагаются на общей магистрали и имеют общий модуль ОП. Уже отмечалось, что обмен между устройствами ЭВМ по общей магистрали возможен только в неперекрывающиеся моменты времени (т.е. в каждый момент времени с ОП может общаться только один процессор). Поэтому кэш-память оказалась очень удобным инструментом для сокращения числа обращений каждого процессора к ОП, а следовательно, и загрузки системной магистрали ЭВМ.
Таким образом, снижение загрузки системной магистрали является еще одной причиной (помимо ускорения операций обмена процессор – ОП) включения в структуру современных ЭВМ модулей кэш. Кроме того, наличие кэш-памяти достаточного объема позволяет не прерывать работу процессора даже при захвате магистрали каким-либо устройством, т.е. при осуществлении обмена в режиме ПДП.
Производительность кэш-памяти определяется временем доступа к ней и вероятностью удачных обращений, которая зависит от объема кэш и количества слов в блоке (строке), переносимых в кэш при каждом обращении к ОП. С увеличением длины блока возрастает вероятность того, что следующее обращение будет удачным, т.е. необходимая информация окажется в кэш-памяти. Однако эта зависимость нелинейная и имеет свой оптимум в координатах "производительность - стоимость", который обусловлен тем, что увеличение размера блока свыше некоторого оптимального приводит лишь к незначительному увеличению вероятности удачных обращений к кэш.
Полная производительность памяти ЭВМ (при наличии кэш) является функцией времени доступа к кэш, вероятности удачных обращений к кэш и времени обращения к ОП, которое происходит при неудачном обращении к кэш. Численная оценка полной производительности памяти оказывается в этом случае очень сложной задачей, особенно при учете увеличения быстродействия ОП за счет расслоения, и решается только статистическими методами.
При проектировании аппаратного и алгоритмического обеспечения кэш-памяти приходится учитывать большое число различных факторов и, часто взаимоисключающих, требований, поэтому конкретное исполнение кэш-памяти в различных ЭВМ отличается большим разнообразием. В частности, одной из проблем является взаимодействие кэш и ОП при изменении в процессе выполнения программы находящейся в кэш информации. В настоящее время эта задача решается, в основном, двумя путями, каждый из которых определяет тип кэш:
· Запоминание новой информации происходит одновременно в кэш и ОП (write through –сквозная запись). При этом в ОП всегда есть последняя копия хранящейся в кэш информации. Это удобно, но длинный цикл ОП снижает производительность процессора.
· Запоминание новой информации происходит только в кэш. Копирование ее в ОП происходит только при передаче в другие устройства ЭВМ или при вытеснении из кэш в результате вызова новой информации из ОП (write back – обратная запись).
Задача выбора алгоритма перемещения блоков информации из кэш-памяти в ОП при вызове из ОП новых блоков также не имеет однозначного решения. В большинстве случаев из кэш-памяти удаляется блок информации, который используется наиболее редко либо не использовался дольше других. Возможны и другие алгоритмы замещения. В частности, в кэш с прямым отображением, в котором за каждой ячейкой кэш закреплена определенная группа ячеек ОП, замена информации в ячейках кэш происходит по мере обращения процессора к соответствующей группе ячеек ОП (более подробно этот вопрос рассматривается ниже).
Следует отметить, что наличие кэш-памяти усложняет работу вычислительной системы и требует дополнительного программно- аппаратного обеспечения. В частности, требуется специальный контроллер кэш-памяти, который перехватывает обращения процессора к ОП и обрабатывает их непосредственно сам, без передачи запросов шине.
В качестве примера рассмотрим организацию кэш-памяти в вычислительных системах, построенных на базе 32-разрядного процессора I80386. В архитектуре микропроцессора I80386 за ячейку памяти на аппаратном уровне принята последовательность из восьми смежных бит, т.е. 1 байт. Несмотря на то, что МП I80386 является 32 - разрядным, наибольшая эффективность достигается в нем при обработке 16-разрядных данных, поэтому в качестве машинного слова в данном МП выбраны два объединенных байта.
В вычислительных системах, построенных на базе I80386, управление кэш-памятью осуществляется высокопроизводительным контроллером кэш-памяти I82385. Для инициализации контроллера I82385 не требуется специального программного обеспечения, а сам контроллер программно невидим (прозрачен), поэтому он может быть легко применен в системах с уже существующим программным обеспечением, а разработка нового программного продукта не потребует специфических условий, связанных с этим контроллером. Контроллер обеспечивает прозрачность на шине с помощью наблюдения за шиной ("подслушивание" шины). Наблюдение за шиной реализуется контроллером через интерфейс, аналогичный интерфейсу шины процессора I80386. Благодаря своей прозрачности контроллер кэш-памяти I82385 может быть включен в состав микропроцессорных систем на базе I80386 для работы в конвейерном и неконвейерном режиме и адресации пространства ОП до 4 Гбайт. Обновление ОП выполняется на каждом цикле записи методом "сквозной записи". При этом производительность повышается вследствие выдачи запросов на операции записи через некоторый буфер, позволяющий процессору продолжать работу с кэш-памятью, пока идет обращение к ОП. Если содержимое ячеек ОП, копии которых находятся в кэш, в процессе выполнения программы изменилось, контроллер автоматически обновляет содержимое соответствующих ячеек кэш-памяти.
Очень упрощенная структура кэш вычислительной системы на базе I80386 и I82385 (да в принципе и любой другой) изображена на рис. 22.6. Причем в вычислительных системах на базе I80386 и I82385 используется объединенный кэш команд и данных.
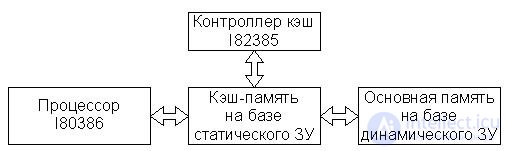
Рис.22.6. Организация кэш-памяти
Как уже отмечалось, пересылка информации из ОП в кэш-память и обратно осуществляется целыми блоками. Для этого ОП также разделяют на блоки от 2 до 16 байт. Если запрашиваемая процессором информация не находится в кэш, то контроллер кэш-памяти обновляет содержимое кэш целым блоком. Размер блока является очень важным параметром, определяющим эффективность работы кэш-памяти. В 32 - разрядных системах контроллер в качестве блока пересылает совокупность данных размером 2-4 слова (4-16 байт). Даже если запрашивается одиночное слово, то все равно осуществляется блочная пересылка. С увеличением блока замедляется модификация кэш, но увеличивается коэффициент попадания. Так, увеличение блока с 4 байт до 8 увеличивает коэффициент попадания на несколько процентов. Однако при этом в кэш размещается меньшее число блоков. А с уменьшением числа блоков растет вероятность операций пересылки блоков между кэш и ОП, поэтому приходится выбирать оптимум (что уже отмечалось). Обычно в вычислительных системах на базе I80386, I82385 работа кэш-памяти организована так, что вероятность удачных обращений достигает 0,95.
При обработке различных классов задач наибольшую эффективность системы кэш-памяти достигают при использовании различных структур, а именно: полностью ассоциативных кэш, кэш с прямым отображением и множественный ассоциативный кэш. Каждая из этих структур имеет свои преимущества и недостатки. В принципе, все эти структуры поддерживаются контроллером кэш I82385 с некоторыми ограничениями. Рассмотрим эти структуры подробнее, полагая, что емкость ОП вычислительной системы составляет 16 Мбайт.
· Полностью ассоциативный кэш (рис. 22.7)
Концепция полностью ассоциативного кэш основана на том предположении, что процессор обращается к адресам, лежащим в разных частях ОП, поэтому для обеспечения общей эффективности работы механизм кэш должен поддерживать множественные несвязанные блоки данных. Поскольку между блоками нет в этом случае каких-либо определенных взаимосвязей, в кэш должны записываться полный адрес каждого блока и непосредственно сам блок. При обращении к памяти контроллер кэш-памяти сравнивает полученный адрес с адресами, отображенными на кэш.
Существенным недостатком полностью ассоциативных кэш является то, что всякий раз при обращении к памяти затрачивается время на сравнение адресов в кэш. Следует отметить, что в стандартной конфигурации вычислительных систем на базе процессора I80386 и контроллера кэш-памяти I82385 структура полностью ассоциативного кэш не используется.
Происходит последовательное сравнение ячеек кэш с 22-разрядным полем признака (адресом) без вызова их в контроллер. Такой последовательный процесс сравнения и увеличивает время поиска.
Известно также, что в ряде устройств ассоциативной памяти контроль ассоциации осуществляется последовательно по битам ассоциативного признака. Применительно к данному кэш это означает, что происходит параллельное сравнение 128 бит в i-м разряде адреса, т.е. необходимо выполнить последовательно 22 сравнения, чтобы проанализировать все поле признака (адреса). В специализированных блоках ассоциативной памяти контроль ассоциации осуществляется параллельно по всем ячейкам памяти.


Рис.22.7. Организация полностью ассоциативного кэш
· Кэш с прямым отображением (рис. 22.8)
При использовании кэш такого типа ОП условно делится на 256 страниц по
64 Кбайт каждая. Каждая страница имеет свой базовый адрес, задаваемый 8 битами поля признака (старшие разряды адреса ячейки ОП). Объем кэш (банк данных) соответствует объему одной страницы (64 Кбайт). Поле индекса в адресе занимает 16 бит. Из них 14 используются для выбора одного из 16 Кбайт 4 байтовых блоков (ячеек) кэш или ОП (на странице с соответствующим признаком), а два бита определяют один из 4 байтов в блоке, т.е. индекс является ничем иным, как смещением относительно базового адреса(признака).

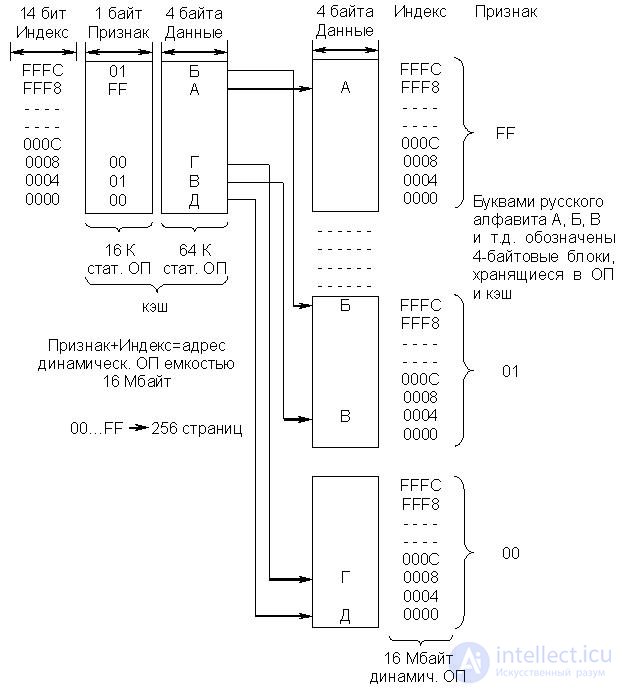
Рис.22.8. Организация кэш с прямым отображением
Копии блоков с одинаковыми адресами на всех страницах ОП помещаются в одну и ту же ячейку кэш с аналогичным адресом. Таким образом, на один адрес кэш отображаются256 адресов ОП (256*64 Кбайта = 16 Мбайт). Сам кэш имеет два уровня. Первый уровень образован банком признаков и содержит адресную информацию. В данном случае это базовые адреса страниц ОП (признаки). В некоторых источниках вместо термина признакупотребляют тег. Второй уровень состоит из банка данных, в котором содержатся 4 байтовые копии (блоки) ячеек ОП.
Упрощенный алгоритм обращения процессора к памяти состоит в следующем:
- 14-битный индекс сообщает контроллеру кэш, какую из 16 Кбайт однобайтовых ячеек в банке признаков следует проверить:
- 8-битный признак, находящийся в указанной ячейке банка признаков, сообщает, какой из 256 возможных 4-байтовых блоков находится по этому адресу (индексу) в ячейке банка данных;
- если запрошенный процессором признак совпадает с признаком в банке признаков, возникло совпадение. Если нет, происходит обращение к ОП и осуществляется замена признака и данных в кэш на данные, полученные из ОП.
Рассмотренная структура кэш отличается от предыдущей (полностью ассоциативной) тем, что здесь нет неопределенности в размещении блока данных. Адрес (индекс) указывается непосредственно в запросе процессора, и сравнивать приходится только признак. Это ускоряет процесс обмена.
Недостатком такого типа кэш является то, что на одну ячейку кэш отображается 256 адресов ОП, т.е. одинаковые адреса со всех страниц ОП, поэтому при циклическом обращении процессора к одинаковым адресам хотя бы на двух разных страницах возникает "пробуксовка" кэш. В этом случае при каждом обращении происходит обновление содержимого соответствующей ячейки кэш.
Этой проблемы можно избежать, разрешив любой ячейке в ОП направляться по мере необходимости не в одну, а в две или более ячеек кэш. При этом увеличивается коэффициент попаданий, но и усложняется алгоритм обращения к памяти.
· Двухвходовый множественныйассоциативный кэш (рис. 22.9)
Множественный ассоциативный кэш занимает промежуточное положение между полностью ассоциативным кэш и кэш с прямым отображением. Из приведенной структурной схемы следует, что банк признаков и банк данных, используемые в кэш с прямым отображением, в данном случае разбиваются на два блока, в каждом из которых есть свой банк признаков и банк данных емкостью 32 Кбайт.
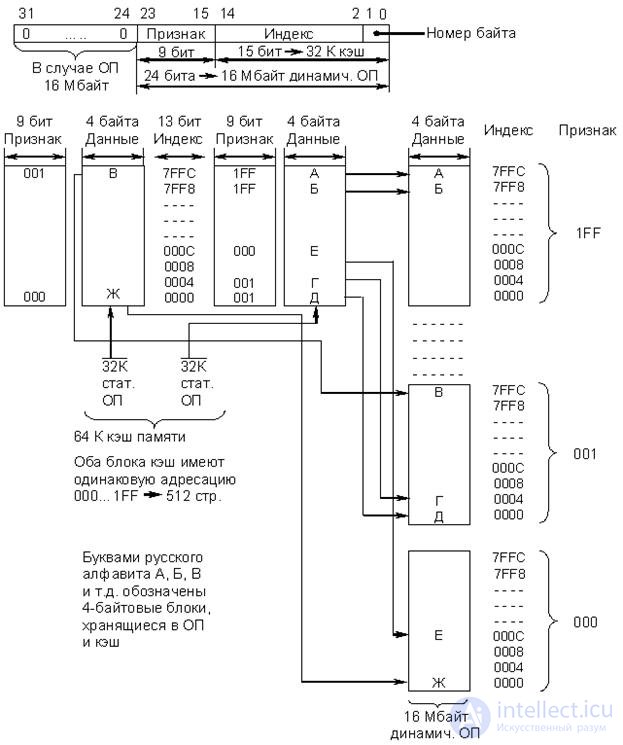
Рис.22.9. Организация двухвходового множественного ассоциативного кэш
Оба блока кэш имеют одинаковую адресацию, т.е. индекс изменяется от 0000 до 7FFC. При использовании кэш такого типа ОП делится уже не на 256 страниц, а на 512, каждая из которых имеет свой 9-разрядный признак (базовый адрес) от 000 до 1FF (32 Кбайт). Данные из ОП могут быть помещены в любую из двух ячеек с соответствующим индексом (смещением) банков данных, относящимся к разным блокам кэш. В соответствии с принятым алгоритмом контроллер кэш I82385 помещает новый блок данных из ОП в ту из двух ячеек, содержимое которой наиболее долго не использовалось.
Алгоритм обращения к памяти полностью аналогичен описанному ранее для кэш с прямым отображением, за исключением того, что в данном случае контроллеру приходится одновременно проверять две ячейки с одинаковыми индексами (смещением) в обоих блоках кэш. Изменился также формат адресных полей.
Производительность для двухвходового ассоциативного кэш примерно на 1% выше, чем у кэш с прямым отображением. Возможно построение четырехвходовых и более множественных ассоциативных кэш, состоящих из четырех и более блоков с одинаковой адресацией. При этом увеличивается производительность, но и усложняется алгоритм обращения к памяти.
В заключение следует отметить, что в вычислительных системах на базе процессора I80386 в стандартной конфигурации контроллер кэш I82385 поддерживает работу двухвходового множественного ассоциативного кэш и кэш с прямым отображением.
В современных ЭВМ, построенных на базе мощных процессоров, происходит дальнейшее расслоение внутренней памяти и, прежде всего, расслоение кэш. Быстродействующий внутрикристальный кэш первого уровня и более "медленный" внешний кэш второго уровня являются обязательными компонентами всех современных IBM PC. Взаимодействие кэш обоих уровней строится по принципам, аналогичным принципам взаимодействия остальных иерархических слоев памяти – минимизация числа обращений более быстродействующего слоя к менее быстродействующему. Дальнейшее увеличение производительности процессоров неизбежно повлечет за собой и дальнейшее расслоение кэш-памяти ЭВМ.
Во многих случаях большие исполняемые программы и структуры данных не удается полностью разместить в ОП, поскольку емкости существующих ОП ограничены. Особенно остро эта проблема стоит в мультипрограммных, многопользовательских системах, выполняющих, грубо говоря, несколько программ одновременно. Естественно, в каждый момент времени ЭВМ выполняет команду какой-то одной программы. Однако всякий раз, когда выполнение процессором некоторой программы приостанавливается из-за необходимости произвести, например, операцию ВВ, процессор переходит к обработке другой, готовой для выполнения программы. При этом предполагается, что одновременно в ОП присутствует несколько программ, которые могут находиться в активном состоянии, состоянии готовности или ожидания. Однако нет принципиальной необходимости в том, чтобы все программы целиком (или одна большая программа) находились в ОП, так как в любой момент времени работа программы концентрируется на определенных, сравнительно небольших участках. Таким образом, в ОП следует хранить только используемые в данный период части программ, а неиспользуемые части (программ или программы) могут храниться во внешней памяти ЭВМ (ВП).
Вводя в ЭВМ свою программу, пользователь не знает, в комбинации с какими программами будет выполняться его программа, какое место в памяти отведет ей операционная система, поэтому при подготовке программ используются условные адреса (подготовка – имеется в виду операция компиляции программы). Позднее, в процессе выполнения программы, операционная система выделяет активным частям программы место в памяти, и условные адреса переводятся в исполнительные. Эта процедура получила название динамического распределения памяти.
Осуществление динамического распределения чисто программным путем привело бы к значительным потерям машинного времени, поэтому для этой цели используются также аппаратные средства.
Наиболее распространенный способ динамического распределения памяти основан на использовании базовых регистров. Операционная система каждой пользовательской программе ставит в соответствие свой базовый адрес. Базовые адреса обрабатываемых программ находятся в общих регистрах процессора. При выполнении программы физический адрес образуется суммированием базового и относительного адресов. При динамическом распределении памяти с помощью базовых регистров программа (или, по крайней мере, та часть ее, адреса которой преобразуются с помощью одного и того же базового адреса) должна располагаться в последовательных ячейках и вводиться в ОП целиком, хотя в ближайшем цикле активности может потребоваться лишь небольшой фрагмент программы.
При рассмотренном способе динамического распределения памяти свободная памятьможет состоять из несвязных областей (фрагментация памяти) и для ввода нужной программы может понадобиться сдвиг содержимого памяти. Это можно проиллюстрировать примером на
рис. 22.10.
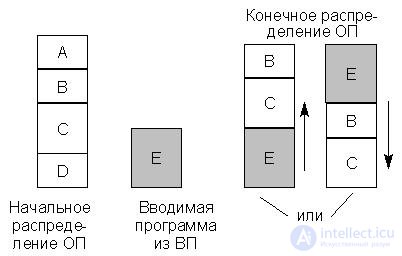
Рис.22.10. Пример распределения памяти
Первоначально ОП распределяется между программами A, B, C, D. Программы A и D в данный момент наименее активны и могут рассматриваться как кандидаты на удаление во внешнюю память. Если вновь вводимая программа E больше любой из программ A и D, то для ее размещения в памяти необходимо сдвинуть программы B и C "вверх" или "вниз". Это перемещение связано с потерей времени. Более того, в ряде прежних операционных систем такое перемещение требовало выполнения заново операции редактирования связей в программе и новой загрузки программы.
Отмеченные недостатки в распределении ОП отсутствуют в виртуальной памяти со страничной организацией.
Принцип виртуальной памяти предполагает, что пользователь при подготовке своей программы имеет дело не с физической ОП, действительно работающей в составе ЭВМ и имеющей некоторую фиксированную емкость, а с виртуальной (т.е. кажущейся) одноуровневой памятью, емкость которой равна всему адресному пространству, определяемому размером адресных полей в форматах команд и базовых регистров. Так, например, процессор I80386 может управлять виртуальной памятью до 64 Тбайт (терабайт). Это потенциально возможный объем виртуальной памяти, которой может управлять процессор с 32-разрядной ША. Между тем объем виртуальной памяти реальных компьютеров существенно меньше потенциального. Он определяется объемом ВП (жесткого диска), а точнее той ее части, которая выделяется операционной системой для реализации механизма виртуальной памяти. Объем ОП в данном случае не учитывается, поскольку он существенно меньше выделенного объема дисковой памяти (ВП).
Пользователь имеет в своем распоряжении все адресное пространство ЭВМ независимо от объема ее физической памяти (ОП) и объемов памятей, необходимых для других программ, участвующих в мультипрограммной обработке. При этом достигается гибкое динамическое распределение памяти, устраняется ее фрагментация и создаются значительные удобства для работы программиста. В современных ЭВМ все это достигается без заметного снижения производительности компьютера, ценой усложнения аппаратуры, операционной системы и процессов их функционирования.
На всех этапах подготовки программы, включая загрузку в ОП, программа представляется в виртуальных адресах, и лишь при самом исполнении машинной команды производится преобразование виртуальных адресов в реальные адреса физической памяти ЭВМ (их называют еще физическими адресами или исполнительными).
Преобразование виртуальных адресов в физические упрощается, а также устраняется фрагментация памяти, если физическую и виртуальную память разбить на блоки небольшого размера, содержащие одно и то же число байт. Такие блоки называютсястраницами. Страницам виртуальной и физической памяти присваивают номера, называемые номерами соответственно виртуальных и физических страниц. Каждая физическая страница способна хранить одну из виртуальных страниц. Нумерация байт в виртуальной и физической страницах сохраняется одной и той же.
Вновь загружаемая в ОП программа может быть направлена в любые свободные в данный момент физические страницы, независимо от того, расположены они подряд или нет. Не требуется перемещения информации в остальной части памяти. Страничная организация позволяет более рационально осуществлять обмен информацией между ВП и ОП, так как страница программы не должна загружаться до тех пор, пока она действительно не понадобится (имеется в виду, что обмен небольшими блоками информации между ВП и ОП можно осуществить без заметного снижения производительности процессора). Сначала в ОП загружается начальная страница программы, и ей передается управление. Если в процессе обработки программы делается попытка выборки слов из другой страницы, то производится автоматическое обращение к операционной системе, которая осуществляет загрузку требуемой страницы. Так происходит в процессе выполнения всей программы, при этом ненужные модифицированные страницы программы перемещаются из ОП в ВП. Операция замены (замещения) страниц в ОП называется свопингом (swapping), а часть диска, выделенная на нужды виртуальной памяти, – файлом подкачки (swap file). Размер этого файла, а следовательно, и максимальный объем виртуальной памяти конкретной ЭВМ зависят от общего объема жесткого диска и типа установленной операционной системы.
Соответствие между виртуальными и физическими памятями устанавливается страничной таблицей, причем физические страницы могут содержаться в текущий момент времени как в ОП, так и в ВП.
Упрощенная схема страничной организации памяти изображена на
рис. 22.11.

Рис.22.11. Упрощенная схема страничной организации памяти
Страничная таблица для каждой программы формируется операционной системой в процессе распределения памяти и перерабатывается ею каждый раз, когда в распределении памяти производятся изменения. Процедура обращения к памяти состоит в том, что номер виртуальной страницы извлекается из адреса и используется для входа в страничную таблицу, которая указывает номер соответствующей физической страницы. Этот номер вместе с номером байта, взятым непосредственно из виртуального адреса, представляет собой физический адрес, по которому происходит обращение к ОП. Процесс формирования физического адреса можно изобразить схемой, представленной на рис. 16.12, причем под номером физической страницы понимается ее базовый адрес.
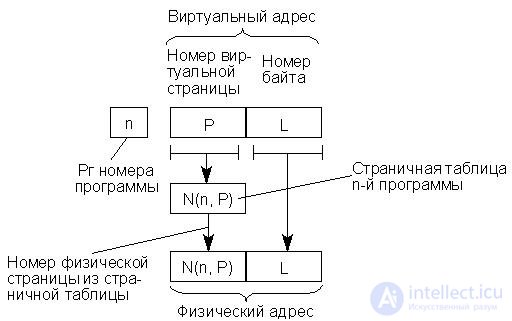
Рис.22.12. Формирование физического адреса
Если страничная таблица указывает на размещение требуемой информации во внешней памяти (ВП), то обращение к ОП не может состояться немедленно, так как операционная система должна организовывать загрузку в ОП из ВП нужной страницы.
Для каждой из программ, обрабатываемых в мультипрограммном режиме, организуется своя виртуальная память и создается своя страничная таблица, при этом все программы делят между собой одну физическую память (ОП и ВП).
Страничные таблицы программ хранятся в ОП, и обращение к нужной строке активной страничной таблицы в ОП происходит по адресу, который определяется номером активной программы и номером виртуальной страницы.
Следует иметь в виду, что механизм организации страничной адресации в реальных вычислительных системах, даже на процессорах поколения I80386, существенно сложнее описанного выше. В частности, для обращения к страничной таблице соответствующей программы операционная система должна первоначально обратиться к каталогу, в котором хранятся базовые адреса страничных таблиц соответствующих программ. Перемещение модифицированных страниц из ОП в ВП в большинстве случаев осуществляется не напрямую, а через кэшированную область ОП (дисковый кэш), поскольку велика вероятность обращения к недавно удаленной странице. Такой механизм позволяет ускорить процесс подкачки страницы при повторном обращении.
Для ускорения преобразования адресов обычно используется небольшая сверхоперативная память, куда передается из ОП страничная таблица активной программы. Кроме того, во внутренней памяти процессора обычно формируется сводная таблица, содержащая сведения о номерах виртуальных и соответствующих физических страниц для нескольких недавно использовавшихся страниц, в том числе принадлежащих разным программам. Так, внутрикристальный кэш процессора I80386 содержит информацию, необходимую для доступа к 32 страницам памяти, к которым недавно выполнялось обращение. В этом варианте сверхоперативная память, используемая при преобразовании адресов, строится как ассоциативная. Обращение к ней идет не по адресу, а по содержанию хранимой в ячейке информации – номеру программы и номеру виртуальной страницы.
До сих пор предполагалось, что виртуальная память, которой располагает программист, представляет собой непрерывный массив с единой нумерацией байтов. Такое логическое адресное пространство называют еще плоским или линейным. Между тем программа обычно состоит из нескольких массивов-подпрограмм, одной или нескольких секций данных. При программировании длина таких массивов (программных модулей) получается произвольной (различной), поэтому удобно, чтобы каждый массив имел свою собственную нумерацию байтов, начинающуюся с нуля. Желательно также, чтобы составленная таким образом программа могла работать при динамическом распределении памяти, не требуя от программиста усилий по объединению различных ее частей в единый массив. В современных вычислительных системах эта задача решается путем использования особого метода преобразования виртуальных адресов в физические, называемого сегментно-страничной организацией памяти.
Виртуальная память каждой программы делится на части, называемые сегментами, с независимой адресацией байтов внутри каждой части. При этом к виртуальному адресу добавляются дополнительные разряды левее номера страницы. Эти разряды определят номер сегмента.
Возникает определенная иерархия в организации программ, состоящая из четырех ступеней: программа-сегмент-страница-байт. Этой иерархии программ соответствует иерархия таблиц, служащих для перевода виртуальных адресов в физические. Программная таблица для каждой программы, загруженной в систему, указывает начальный адрес соответствующей сегментной таблицы. Сегментная таблица перечисляет сегменты данной программы с указанием начального адреса страничной таблицы, относящейся к данному сегменту. Страничная таблица определяет расположение каждой из страниц сегмента в памяти. Страницы сегмента могут располагаться не подряд – часть страниц данного сегмента может находиться в ОП, остальные во внешней памяти.
Следует отметить, что страничная организация памяти, сегментация памяти и разнообразные их комбинации и сочетания возникли в ранних универсальных вычислительных машинах, таких как IBM 360/370. В РС механизм сегментно-страничной адресации появился существенно позднее. Первыми процессорами фирмы Intel, имеющими аппаратную поддержку механизма сегментации памяти, являлись процессоры I80286. Однако наиболее широко защищенный режим (многозадачность, виртуальная память) стал использоваться с появлением 32-разрядных процессоров, в частности процессоров I80386, имеющих аппаратную поддержку механизма сегментно-страничной организации памяти. Такая поддержка позволила разработчикам системного программного обеспечения строить логическое адресное пространство памяти в соответствии с потребностями, определяемыми функциональным назначением ЭВМ. Процессор I80386 может работать как в реальном, так и защищенном режимах и поддерживает следующие варианты логической организации памяти:
- плоское (линейное) логическое адресное пространство, представляющее собой массив байтов со сплошной нумерацией;
- сегментированное логическое адресное пространство, состоящее из некоторого числа сегментов, каждый из которых содержит переменное число байтов;
- страничное логическое адресное пространство, состоящее из большого числа страниц, каждая из которых включает фиксированное число байтов;
- сегментно-страничное адресное пространство, состоящее из некоторого числа сегментов, которые, в свою очередь, состоят из целого числа страниц.
Процессор I80386 поддерживает 16000 сегментов различного объема. Размер каждого сегмента может достигать 4 Гбайт, что позволяет реализовывать управление виртуальной памятью емкостью до 64 Тбайт (в многозадачном режиме 16000 сегментов – для каждой новой задачи).
Перечисленные возможности позволяют программисту, в случае необходимости, использовать защищенный режим и разбить виртуальную память ЭВМ на сегменты. При этом каждому модулю программных кодов можно присвоить свой собственный логический сегмент памяти. Пользуясь моделью сегментной адресации, программист может разделить логическое адресное пространство, например, на сегменты данных, кодов программ, стека и несколько дополнительных сегментов. Это будет способствовать достаточно простой реализации механизмов, обеспечивающих защиту отдельных модулей, разделение информации между сегментами, а также совместную или раздельную их обработку.
Виртуальную память можно поделить также на страницы. В отличие от сегментов, для которых допускаются переменные размеры и размещение в ОП, наиболее приемлемые для программных модулей страницы имеют фиксированный размер 4 Кбайт и жесткую привязку к адресам памяти. Страничная организация памяти придает алгоритмам перекачки данных в процедурах размещения, запоминания и поиска более рациональную форму благодаря равномерности распределения блоков памяти в адресном пространстве. В любой программе можно объединить основные принципы каждого из рассмотренных способов управления памятью, если, допустим, логическое адресное пространство разделить на сегменты, а для управления физической памятью применить методы страничной организации. Размер страницы 4 Кбайт хорошо подходит для функционирования операционных систем и для подсистем ВВ дисков, а также обеспечивает хороший коэффициент удачных обращений для внутрикристального кэш страниц. Следует отметить, что с появлением процессоров Pentium возникла возможность поддержки страниц размером 4 Мбайт. Однако при дальнейшем изложении материала размер страницы подразумевается 4 Кбайт.
Следует, однако, иметь в виду, что виртуальной памяти как физического объекта не существует (в отличие от кэш-памяти), хотя она и имеет определенную аппаратную поддержку. Виртуальная память является "порождением" операционной системы, поэтому и законы ее функционирования зависят от конкретного типа операционной системы.
Кроме того, фирмы-изготовители в процессе совершенствования аппаратной части стремятся сохранить преемственность поколений процессоров. Это позволяет использовать в новых моделях программное обеспечение, уже написанное для вычислительных систем, построенных на базе более ранних моделей процессоров, но делает алгоритмы обращения к памяти более консервативными. Такая преемственность достигается в основном двумя путями:
- Созданием новых моделей процессоров, расширенные системы команд которых "накрывают" системы команд прежних моделей. Так, все процессоры фирмы Intel семейства I80х86, в том числе 32-разрядные (I80386, I80486, Pentium, Pentium Pro), включают в себя как подмножество системы команд и архитектуры нижестоящих моделей, начиная с базовой модели I8088;
- Созданием новых операционных систем, поддерживающих возможность эмуляции прежних структур логического адресного пространства памяти. Так, все версии операционной системы MS-DOS, включая последние (например,MS DOS 6.22), поддерживали реальный режим, эмулирующий фактически адресное пространство PC/XT.
1. Теговая организация памяти.
2. Использование дескрипторов.
3. Описание двумерного массива данных древовидной структурой дескрипторов.
4. Методы оптимизации обмена процессор-память.
5. Основные принципы конвейеризации процедур цикла выполнения команды.
6. Использование расслоения памяти.
7. Буферизация памяти. Схема подключения буферной памяти.
8. Взаимодействие кэш и ОП. Сквозная и обратная запись.
9. Организация полностью ассоциативного кэш.
10. Организация кэш с прямым отображением.
11. Организация двухвходового множественного ассоциативного кэш.
12. Динамическое распределение памяти. Виртуальная память.
13. Упрощенная схема страничной организации памяти.
14. Формирование физического адреса.
15. Сегментно-страничная организация памяти.
Надеюсь, эта статья про развитие архитектуры эвм, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое развитие архитектуры эвм и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Компьютерная схемотехника и архитектура компьютеров
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии