Лекция
Привет, сегодня поговорим про многоядерные процессоры для встраиваемых приложений, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое многоядерные процессоры для встраиваемых приложений , настоятельно рекомендую прочитать все из категории Компьютерная схемотехника и архитектура компьютеров.
Процессоры Tile64 рассчитаны на применение в высокопроизводительном сетевом оборудовании, беспроводных телекоммуникационных системах, а также серверах для потоковой обработки видеоданных. Позволяют использовать во встраиваемых приложениях мощные вычислительные ресурсы при достаточно низких энергозатратах.
Круг целевых задач для данных процессоров следующий.
Процессоры способны работать в сетях с уровнем трафика порядка 10-20 Гб/с, обеспечивая поддержку следующих сервисов:
Мультимедиа-приложения, прежде всего включают цифровую обработку данных, легко замещая несколько цифровых сигнальных процессоров (ЦПС) или FPGA:
Применение в области беспроводных коммуникаций включает работу в существующих сетях GSM/CDMA и в сетях следующего поколения WiMAX & LTE. Прежде всего, это:
Процессор Tile64 может быть оптимизирован для выполнения определенных задач. Теоретически Tile64 будет обеспечивать десятикратный прирост производительности по сравнению с серверным процессором Intel Xeon при значительно меньшем энергопотреблении.
Tile64Pro является процессором общего назначения с MIMD-архитектурой. Каждое ядро может работать и под управлением собственной операционной системы, и под управлением многопроцессорной системы типа SMP Linux, соответственно, одновременно процессор может поддерживать различные приложения, к примеру, обработку видеокадров, шифрование данных и обработку стека сетевых протоколов.
Виртуальная память и технология Tilera's Multicore Hardwall позволяет осуществлять защиту данных на уровне ядра, как для общей памяти, так и для потоков и сообщений пользовательского уровня.
Процессор содержит 64 идентичных вычислительных ячейки (tile), организованных в двумерный массив 8х8 (рис.27.1, 27.2). Ячейка является базовым блоком процессора и состоит из комбинации коммутатора и RISC-ядра общего назначения. Каждое ядро представляет собой полноценный RISC-процессор, работающий на частотах от 600 МГц до 1 ГГц, и содержит кэши первого и второго уровней (L1, L2 cache).
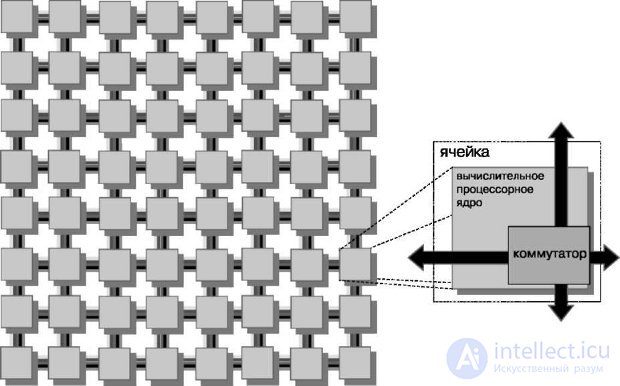
Рис.27.1. Ячейка процессора Tile64
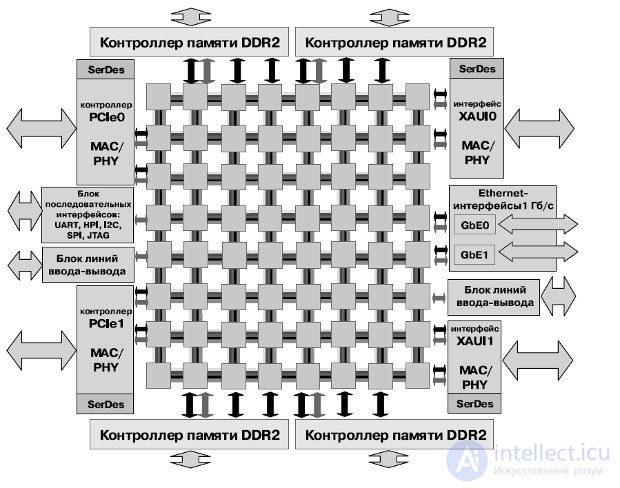
Рис.27.2. Структура процессора Tile64
Ядро имеет все основные возможности обычного процессора, такие как:
Каждое из ядер процессора Tile64 имеет собственную кэш-память первого и второго уровней (рис.27.3).
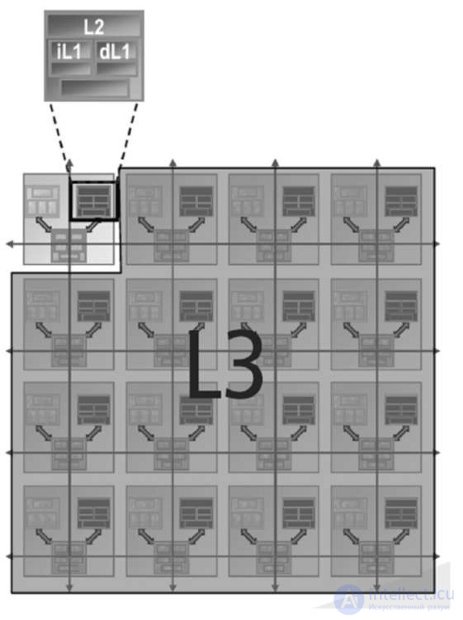
Рис.27.3. Организация кэш-памяти
Ядра оптимизированы для обеспечения наивысшей производительности при минимальном потреблении энергии. При работах на частотах между 500 и 1000 МГц энергопотребление составляет 170-300 мВт в расчете на ядро для типичных приложений. Соответственно, суммарное энергопотребление процессора составляет около 20 Вт.
Распределенный по ядрам когерентный кэш обеспечивает малое время задержки и большую емкость. Подсистема кэша состоит из высокопроизводительной двухуровневой неблокирующей иерархии кэшей. Двухуровневое решение изолирует кэш первого уровня (L1-инструкций и L1-данных) от лишних операций обращения к памяти, сохраняя решение быстрым и энергоэффективным. Аппаратная предварительная выборка инструкций для кэша инструкций L1-I уменьшает частоту промахов кэша. Программируемый блок прямого доступа в память позволяет осуществлять объемные передачи данных. Архитектура процессора разработана таким образом, что отдельному ядру доступен распределенный по другим ядрам кэш. Такая организация когерентного кэша предусматривает аппаратный контроль за доступом к общей распределенной памяти, это и позволяет ядру иметь доступ к набору локальных кэшей всех остальных ядер, работая как кэш третьего уровня.
Организованный данным образом кэш устраняет узкое место при доступе в глобальную внешнюю память — снижает частоту обращений.
Система когерентности кэшей позволяет получить доступ к странице памяти, кэшированной одним из ядер, и к остальным ядрам процессора при помощи операций чтения/записи (аналогично обращению к собственному кэшу ядра). Фактически ядро, кэшируя данные для себя, кэширует их для всех остальных ядер, независимо от их потребности в этих данных, что повышает производительность процессора в целом.
Технология Multicore Hardwall позволяет пользователю выделить одно или несколько ядер в относительно независимую процессорную группу, исключая коммуникации между выделенной группой и остальными ядрами, не включенными в группу. Если пакет данных пересекает установленную границу группы, вызывается прерывание и управление передается гипервизору — небольшой программе исполнительного уровня для отслеживания и управления системными ресурсами. Это обеспечивает защиту данных приложения в многозадачной среде. Технология Multicore Hardwall защищает множественные приложения и операционные системы от непредвиденных взаимодействий и случайных ошибок (рис.27.4).

Рис.27.4. Выделение независимых групп процессорных ядер
Сеть iMesh обеспечивает высокоскоростную передачу данных, необходимую для устранения узкого места системы и поддержки масштабирования приложений. iMesh состоит из пяти отдельных подсетей. Две подсети управляются полностью аппаратно и используются для передачи данных между ядрами и памятью при промахах кэша или при прямом доступе в память. Три оставшиеся подсети доступны для приложений, позволяют осуществлять взаимодействие между ядрами и между ядрами и устройствами ввода-вывода. Для доступа к аппаратуре используется некоторое количество абстракций, например, потоковые каналы, аналогичные сокетам, или интерфейс передачи сообщений. Сеть iMesh позволяет передавать данные без остановки приложений, выполняющихся на ядрах. Это позволяет осуществлять обмен данными между ядрами и осуществлять контроль и маршрутизацию для каждого сетевого соединения, включая буферизацию и контроль потока по всей сети (рис.27.5).

Рис.27.5. Коммутатор сети iMesh
Коммутатор, расположенный возле ядра, является неблокируемым и подключает ядро к внутрикристальной сети Tilera's iMesh™, которая позволяет каждому отдельному ядру взаимодействовать с находящимися поблизости ядрами. Скорость передачи данных по сети iMesh может достигать 27 Тбит/с.
Сеть реализована по топологии "толстого дерева" (Fat Tree).
Средства разработки включают в себя среду Tilera's Multicore Development Environment™ (MDE), имеющую в своем составе стандартные средства параллельного программирования для многоядерных систем.
Среда Tilera's MDE содержит:
Библиотека iLib предоставляет программные интерфейсы, которые позволяют разработчикам:
Архитектура процессора CSX700 была разработана для решения проблемы размеров, веса и потребляемой мощности (Size, Weight and Power (SWAP)), которая, как правило, доминирует во встраиваемых высокопроизводительных приложениях. Путем интегрирования процессоров, системных интерфейсов и встроенной памяти с коррекцией ошибок, CSX700 представляет собой экономичное, надежное и производительное решение, отвечающее требованиям современных приложений.
Процессор представляет собой архитектуру с массовым параллелизмом данных и высокой степенью эффективности и надежности. Архитектура нацелена на интеллектуальную обработку сигналов и обработку изображений во временной и частотной областях.
Кристалл CSX700 содержит 192 высокопроизводительных процессорных ядра, встроенную буферную память размером 256 Кбайт (два банка по 128 Кбайт), кэш данных и кэш команд, ECC защиту внутренней и внешней памяти, встроенный контроллер прямого доступа в память. Для обеспечения накристальной и межкристальной сети используется технология ClearConnect NoC (рис.27.6).
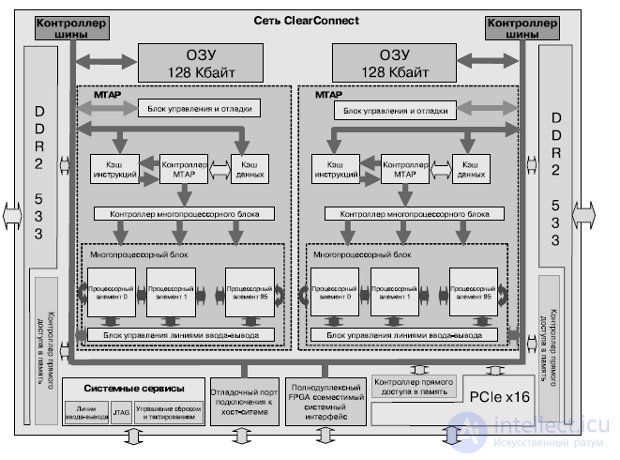
Рис.27.6. Структура процессора CSX700
Интерфейс внешней памяти имеет 72 бита для контроля и коррекции данных (Error Checking and Correction — ECC). Используется память 64-бит DDR2 SDRAM объемом до 4 Гбайт. Процессор имеет 64- разрядное адресное пространство, которое отображается в 48-разрядное физическое. Порты CCBR0 и CCBR1 предназначены для образования мультикристальных систем, а также могут служить для подключения ПЛИС.
Процессор состоит из двух относительно независимых модулей (ядер) MTAP, содержащих кэши инструкций, данных, блоки управления процессорными элементами, и набор из 96 вычислительных ядер — процессорных элементов (PE) (рис.27.8). Поддерживает одновременное выполнение восьми потоков.
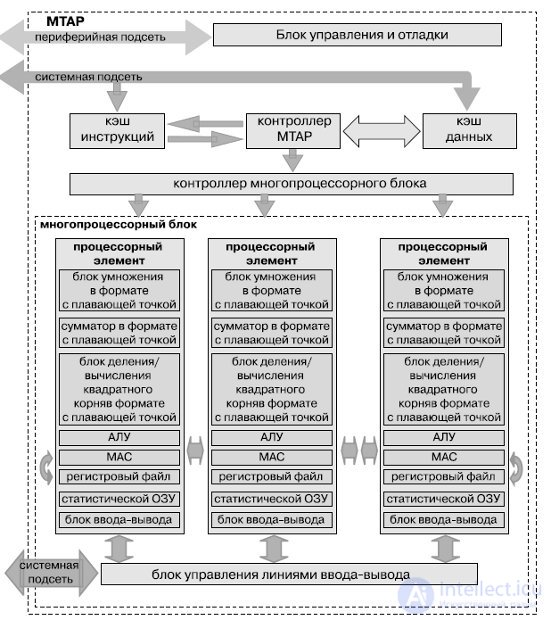
Рис.27.8. Структура MTAP-блока
На каждом такте процессор извлекает команду, декодирует ее и направляет в исполнительные блоки mono или poly либо на контроллер ввода-вывода. Набор команд традиционен для RISC-процессоров — это трехадресные команды. Кроме того, процессор выполняет команды перехода и управляет переключением потоков. Команды выполняются над операндами mono или poly, причем некоторые из них реализуются только в каком-то одном блоке (например, команды переходов — лишь в mono). Каждое ядро имеет двойной блок вычислений с плавающей точкой (сложение, умножение, деление, вычисление квадратного корня, поддерживаются числа одинарной и двойной точности), 6 Кбайт высокопроизводительной оперативной памяти, 128-байтный регистровый файл. Поддерживается 64-битное виртуальное адресное пространство и 48-битное реальное.
Технические характеристики процессора:
Внутрикристальная магистраль позволяет одновременно выполнять несколько обменов, например, обеспечивает доступ процессора к внутренней памяти. Кроме того, она дает возможность вести передачу данных из внешней памяти на порты CCBR0 или CCBR1 с использованием канала DMA.
Ядра синхронно исполняют один поток команд в режиме SIMD. Данные, которые должны обрабатываться параллельно, снабжены описателем poly.
Процессор поддерживает для каждого потока его контекст. Если PE- ядра выполняют длительный ввод-вывод, то процессор должен переключиться на другой поток. При этом потоки имеют приоритеты, и готовый поток с более высоким приоритетом прерывает выполнение потока с более низким. Потоки синхронизируются друг с другом и контроллерами ввода-вывода через аппаратные семафоры.
Семафоры представляют собой специальные регистры, значения которых увеличиваются или уменьшаются с помощью неделимых атомарных команд — соответственно, signal и wait. Если wait выполняется над семафором с нулевым значением, то выполнение команды приостанавливается до тех пор, пока не будет исполнена команда signal над этим семафором в другом треде или устройстве. Операции над семафорами способны выполнять и аппаратные блоки, например, контроллеры ввода-вывода.
Каждое ядро PE может выполнять или не выполнять команды в зависимости от значения разрешающих битов. Если все эти биты составляют "1", то команда выполняется. Если же хотя бы один из таких битов равен "0", большинство команд не выполняются (за исключением, например, команд изменения состояния разрешающих битов). Регистр разрешающих битов трактуется как стек: биты заходят в него через вершину.
Условное выполнение команд в PE поддерживается poly-командами перехода: if, else, endif и др. Они управляют значениями битов разрешения. Например, при выполнении команды if сравнения двух операндов во всех PE происходит следующее: в тех PE, где есть совпадение, в вершину стека будет помещена "1", а в тех, где обнаружено несовпадение, в вершину стека помещается "0". Соответственно, эти PE будут или не будут выполнять последующие команды — вплоть до команды endif, которая "вытолкнет" из стека значение, занесенное командой if. Стек имеет фиксированный размер, поэтому необходимо следить за его переполнением.
Команды чтения и записи из локальной памяти PE в регистры также могут выполняться или нет в зависимости от значения разрешающего бита. Для безусловного выполнения обмена между памятью и регистрами введены специальные команды forced load и forced store.
Канал ввода-вывода PE включает в себя контроллер и один или несколько каналов прямого доступа. Контроллер интерпретирует команды ввода-вывода и взаимодействует с тредами посредством семафоров. Обмен между локальной памятью PE и внешними устройствами выполняется путем программируемого ввода-вывода или с использованием каналов прямого доступа в локальную память. Каждый процессор может читать свою часть данных или выполнять общее чтение — с "нарезкой" одинаковых блоков для каждого процессора.
Процессорные элементы (PE) способны осуществлять обмен с "соседями" справа и слева. На каждом такте PE может выполнить передачу из своего регистра в регистр правого или левого "соседа" и получить одновременно справа и слева данные в свои регистры. Используются команды сдвига вправо и влево, а также передачи "соседу". Если PE имеет бит разрешения "0", то соседний процессор не может изменить состояние его регистров.
Разработанный для низкопотребляющих систем, данный процессор сочетает управление тактовой частотой, обычное для встраиваемых систем, с относительно низкой тактовой частотой. Управление частотой позволяет регулировать производительность приложений при работе в условиях определенного энергопотребления и теплового окружения.
CSX700 поддерживается профессиональной средой разработки (SDK) на основе технологии Eclipse с визуальными средствами отладки приложений, базирующейся на оптимизированном компиляторе ANSI C с расширениями для параллельного программирования. В дополнение к стандартной библиотеке С идет набор оптимизированных библиотек с такими функциями, как БПФ, BLAS, LAPACK и др.
167-ядерная вычислительная платформа (далее — процессор), разработанная в Калифорнийском университете в Дэвисе, реализована в кремнии фирмой STMicroelectronics по 65-нм технологическому циклу. Данный процессор предназначен прежде всего для цифровой обработки сигналов, коммуникационных функций, мультимедийных приложений. Процессор содержит 164 программируемых ядра с динамическим управлением напряжением питания и тактовой частотой, три специализированных процессора, три буфера разделяемой памяти по 16 Кбайт. Все компоненты процессора тактируются собственными независимыми генераторами и соединены специальной внутрикристальной сетью. Структурная схема процессора представлена нарис.27.9. Каждое из ядер имеет 16-разрядные шины данных, 40-битный аккумулятор, независимый тактовый генератор с возможностью останова.
Каждое ядро имеет память команд в 128 35-битных слов, 128 слов 16-разрядной памяти данных, два 16-разрядных FIFO-буфера по 64 слова, одновыходной шестиуровневый конвейер RISC. RISC-ядра поддерживают более 60 базовых инструкций, включая байтовое сложение/вычитание, вычисление минимума/максимума и абсолютных значений, переходы, возвраты из подпрограмм, инструкции условного выполнения, циклы, блок с плавающей точкой. Об этом говорит сайт https://intellect.icu . Задача вычисления квадратного корня (CORDIC) выполняется за 216 циклов .
Процессор БПФ может динамически переключаться между вычислением прямого и обратного преобразования Фурье с количеством отсчетов от 16 до 4096 путем вычисления комплексной 4- или 2-точечной "бабочки" за цикл.
Конфигурируемый Витерби-процессор содержит 8 ACS-модулей и может осуществлять декодирование кодов вплоть до длины 10.
Процессор детектора движения поддерживает несколько фиксированных и программируемых поисковых алгоритмов, отвечающих алгоритму H.264, выполняет более 14 миллиардов операций (SADs) в секунду на частоте 880 МГц.
Ядра процессора обмениваются данными посредством конфигурируемых связей между соседними процессорами и длинных связей. Связи являются циклически переключаемыми и статически конфигурируемыми, что хорошо согласуется с технологией локальной синхронизации, используемой в процессоре.
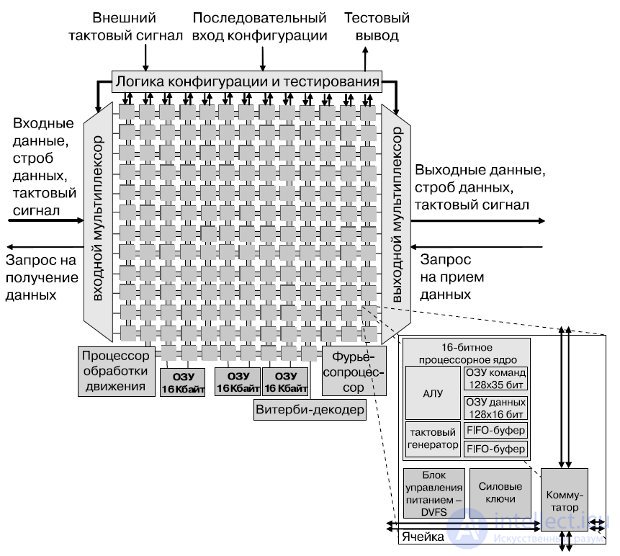
Рис.27.9. Структурная схема 167-ядерного вычислительного массива
Структура связей включает два входа вычислительного ядра и одиночный выход, который динамически подключается к восьми выходам ячейки. Каждая связь содержит 16-разрядную шину данных, сигнал синхронизации источника, разрешающий сигнал (стробирующий) и сигнал запроса на смену направления, используемый для контроля потока. Ограниченные только искажениями тактового сигнала, связи могут быть сконфигурированы для передачи данных сквозь процессор в выбранном выделенном канале без привлечения промежуточных процессоров и безотносительно их текущих напряжений питания и тактовых частот (рис.27.10). Данные могут быть помещены в конвейер в каждой ячейке для достижения полной скорости при передачи на длинные расстояния или передаваться напрямую, если дистанция мала или тактовая частота источника данных мала . Такие меры снижают общую задержку передачи данных.
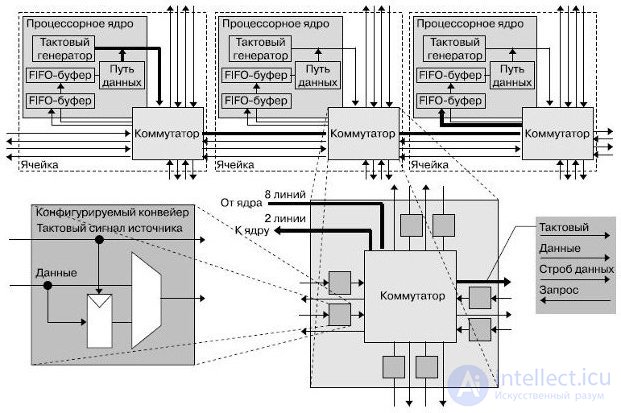
Рис.27.10. Пример межъядерных соединений
Для уменьшения рассеяния энергии, когда ядра не полностью загружены, ядра могут менять собственное напряжение питания и тактовую частоту. Ядра меняют напряжение питания, подключая свои питающие выводы (VddCore) к одной из двух глобальных шин питания. Также возможно отключение линий VddCore неиспользуемых процессоров от питающих глобальных шин (уменьшая таким образом потребление ядра более чем в 100 раз).
Энергопотребление отдельного ядра при полной загрузке на частоте 1,07 ГГц и питании 1,2 В составляет около 48,4 мВт. При напряжении питания 0.675В ядра работают на частоте 66 МГц и потребляют 0,61 мВт. Таким образом, в зависимости от режима энергопотребление процессора в целом составляет от 101 мВт до 7,93 Вт.
По результатам тестирования, 9-процессорный JPEG-кодер, работающий при напряжениях питания 1,3 В и 0,8 В, достигает примерно 8% экономии энергии по сравнению с тем же кодером, работающим исключительно при питании 1,3 В. Приемник, полностью совместимый со стандартом IEEE 802.11a/g, реализован с использованием 39 процессорных ядер (при этом задействованы только связи между соседними ячейками), плюс специализированные процессоры БПФ и Витерби. Применяя длинные связи, приемник можно реализовать на 27 ядрах — почти на треть меньше. При симуляции последняя версия приемника рассеивает примерно 75 мВт при работе на частоте 690 МГц и скорости данных 54 Мб/с в режиме реального времени (включая 2,7 мВт для БПФ-процессора и 5,5 мВт для Витерби).
Процессор Cell представляет собой мощную асимметричную многоядерную процессорную систему. Состоит из процессорного элемента Power, чаще всего выполняющего управляющие функции, и из восьми синергичных процессорных элементов, выполняющих основную вычислительную работу. Ядра объединены при помощи двунаправленной кольцевой шины.
Для борьбы с узким местом при доступе в основную память в процессоре Cell в процессорном элементе PPE применяется двухуровневый кэш и аппаратная поддержка двух потоков. В элементах SPE присутствует локальная оперативная память объемом 256 Кбайт и высокопрозводи-тельный блок прямого доступа в память.
Процессор Cell — совместная разработка компаний Sony, Toshiba и IBM, которые организовали альянс, известный как «STI». Разработка архитектуры и первые прототипы были созданы в STI Design Center за четырехлетний период с начала марта 2001 года.
Первое коммерческое применение процессора Cell — в игровой консоли Sony PlayStation 3. Toshiba использует Cell в своих домашних HDTV-кинотеатрах.
С 2006 года компания IBM выпускает блэйд-сервер QS20, оборудованный двумя процессорами Cell BE. Модули QS22, оборудованные двумя процессорами PowerXCell 8i (модифицированная версия Cell BE с аппаратной поддержкой вычислений двойной точности), используются в суперкомпьютере IBM Roadrunner .
Характеристики
В настоящее время выпускается процессор третьей ревизии PowerXCell 8i — изготовление идет по 45 нм техпроцессу. PowerXCell 8i по сравнению с предшественником обладает в пять раз более высоким быстродействием при выполнении операций с плавающей запятой с удвоенной точностью.
Cell представляет собой процессор с архитектурой CBEA (CBEA (Cell Broadband Engine Architecture) — архитектура, расширяющая 64-битную архитектуру), построенный на основе 64-битной архитектуры Power, которая направлена на распределенную обработку данных и выполнение приложений, предназначенных для обработки больших объемов мультимедиа-данных (рис.27.11).
Процессор состоит из набора модулей, объединенных при помощи высокоскоростной шины (EIB), которая представляет собой две пары колец (96 байт за такт), работающих на половине частоты процессора. Пропускная способность канала ввода данных — 35 Гб/с, канала вывода данных — 40 Гб/с, объединенная пропускная способность канала обмена данными с общей памятью — 25,6 Гб/с.
В состав процессора входит 8 одинаковых процессорных модулей (SPE), содержащих процессорное ядро (SPU), локальную память модуля (LS), один процессорный модуль (PPE), содержащий 64-битный процессор, кэши первого и второго уровней, два реконфигурируемых некогерентных интерфейса ввода-вывода (BIC), интерфейс памяти (MIC).
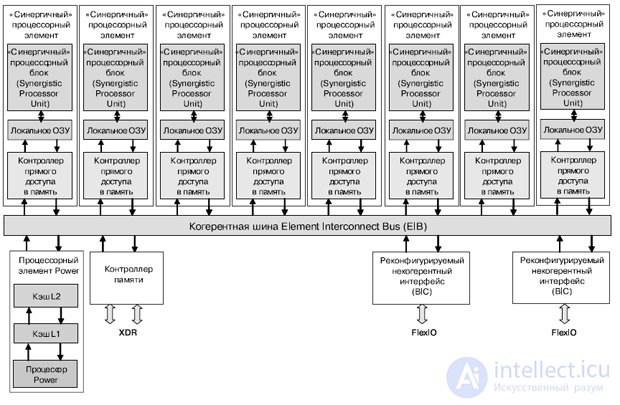
Рис.27.11. Блок-схема мультипроцессора Cell
Процессорный элемент Power (PPE) имеет 64-разрядную архитектуру, с упорядоченной выдачей двух инструкций одновременно (SMT), кэш данных и кэш инструкций первого уровня объемом 32 Кб, объединенный кэш второго уровня объемом 512 Кб.
Процессор обеспечивает два одновременных потока выполнения и может рассматриваться как двухпроцессорный мультипроцессор с общим потоком данных. Ядро чередует команды от двух вычислительных потоков, выполняющихся одновременно. Это позволяет программному обеспечению воспринимать его как два независимых процессора. Продублированы все видимые состояния, в том числе видимые регистры и регистры специального назначения (за исключением регистров, имеющих дело с ресурсами на уровне системы, такими как логические разделы, память и управление потоками). Такое решение позволяет оптимизировать применение слотов выдачи команд, сохранить максимальную эффективность процессора и уменьшить глубину конвейера. Невидимые для программиста ресурсы (типа кэшей и очередей) обычно используются обоими потоками совместно. Исключение составляют те случаи, когда ресурс невелик или может существенно повысить производительность многопоточных приложений.
Простые арифметические операции выполняются и отправляют далее свои результаты за два такта. Задействован режим отложенного выполнения на конвейере операций с фиксированной запятой, благодаря чему команды загрузки также завершаются и отправляют свои результаты за два такта. Команда двойной точности с плавающей запятой выполняется за десять тактов.
PPE поддерживает обычную иерархию кэш-памяти; имеются кэши первого уровня для команд и данных емкостью по 32 Кбайт и кэш-память второго уровня емкостью 512 Кбайт. Кэш второго уровня и кэши преобразования адресов используют таблицы управления заменой, чтобы разрешить программе направлять данные из определенных диапазонов адресов в конкретное подмножество кэша. Такой механизм позволяет блокировать данные в кэше, если размер диапазона адресов равен размеру множества. Он может служить и для предотвращения перезаписи данных в кэше: данные, применяемые только один раз, направляются в определенное множество кэша. Все это повышает эффективность процессора и усиливает контроль над процессором, осуществляемый в масштабе реального времени.
Процессорный блок состоит из 3 блоков: IU (Instruction Unit); XU (eXecution Unit); VSU (Vector Scalar Unit) (рис.27.12). Узел команд IU (Instruction Unit) отвечает за выборку, дешифровку, выдачу и завершение команды, а также за выполнение команд перехода. Узел операций с фиксированной запятой XU (Fixed-Point eXecution Unit) выполняет все команды с фиксированной запятой и команды загрузки/сохранения. Узел векторно-скалярных команд VSU (Vector Scalar Unit) отвечает за векторные команды и команды с плавающей запятой.
Узел команд IU за один такт выбирает из каждого потока четыре команды в буфер команд и отправляет команды из этого буфера по назначению. После дешифровки и проверки зависимостей команды выдаются на узел выполнения по две за такт. Для прогнозирования результата команды перехода служит таблица истории переходов 4 Кбит х 2 бит с шестью битами глобальной истории на поток. Узел IU может выдавать до двух команд за такт.
При такой "сдвоенной" выдаче возможны любые комбинации, кроме двух команд к одному и тому же узлу, а также следующих исключений. Простая векторная, комплексная векторная, векторная с плавающей запятой и скалярная с плавающей запятой арифметические команды не могут быть сдвоены с командой того же типа (например, не допускается выдача простой векторной команды в одном такте с комплексной векторной). Однако эти команды могут быть сдвоены с любой формой команды загрузки/сохранения, перехода с фиксированной запятой или перестановки элементов вектора. Очередь готовых к выдаче команд в узле VSU отделяет конвейеры векторных команд и команд с плавающей запятой от остальных конвейеров. Это позволяет выдавать такие команды вне очереди других команд.
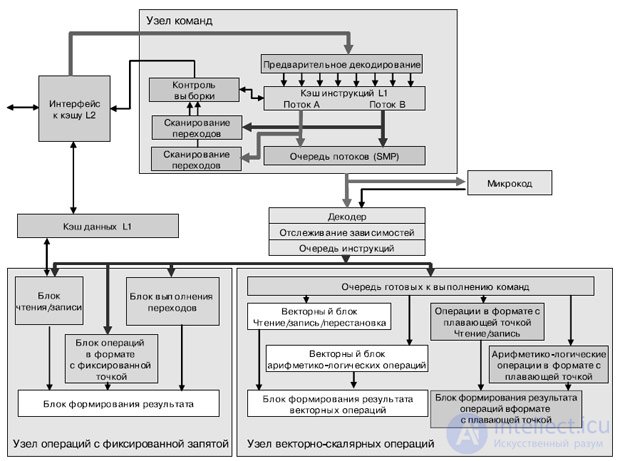
Рис.27.12. Структурная схема процессорного элемента PPE
Узел XU состоит из двух файлов регистров общего назначения 32x64 бит (по одному на поток), блока выполнения команд с фиксированной запятой и блока загрузки/сохранения. В последний входят кэш данных первого уровня, кэш преобразования адресов, 8-элементная очередь кэш-промахов и 16-элементная очередь хранения. Он поддерживает неблоки-руемый кэш данных первого уровня, который позволяет процессору обращаться к другой области кэш-памяти даже в процессе замены блока, вызвавшего кэш-промах (hit under miss cache).
Узел VSU состоит из двух файлов регистров 32x64 бит (по одному на поток) и конвейера двойной точности с десятью стадиями. Узел работает со 128-разрядным потоком данных. Он имеет четыре узла для выполнения простых и комплексных векторных операций, операций одинарной точности с плавающей запятой и операций перестановки. В нем имеются два 32-элементных 128-разрядных векторных файла регистров (по одному на поток), а все команды являются 128-разрядными SIMD-командами с изменяющейся шириной элементов (2x64, 4x32, 8x16, 16x8 и 128x1 разрядов).
SPE (Synergistic Processor Elements) представляет собой отдельный процессор, выполняющий отдельное приложение, но разделяемая когерентная память и большой набор команд для DMA позволяет организовать эффективных обмен данными между SPE (рис.27.13).
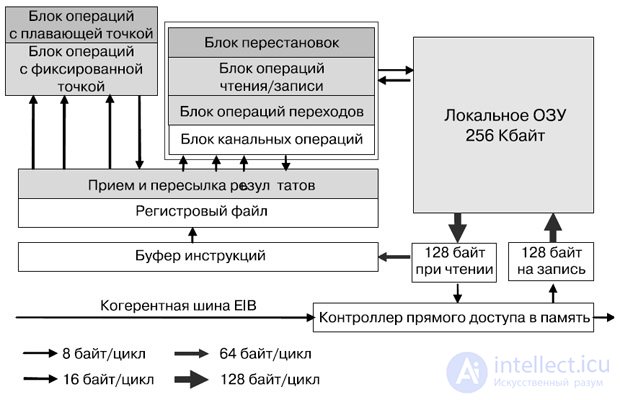
Рис.27.13. Структурная схема процессорного элемента SPE
Выборка инструкций, а также инструкции загрузки/сохранения работают только в пределах адресного пространства локальной памяти SPE. Большой объем регистрового файла служит более полному заполнению вычислительного конвейера. В каждом SPE есть контроллер потока данных памяти (Memory Flow Controller — MFC), в состав которого входит DMA-контроллер .
SPE может настроить DMA для обмена данными с локальной памятью другого SPE, а также для обмена данными с общей памятью.
В процессорном элементе SPE реализована новая архитектура системы команд, энергопотребление и производительность которой оптимизированы для вычислительных и мультимедийных приложений. SPE работает с локальной памятью объемом 256 Кбайт, которая хранит команды и данные. Они передаются между этой и системной памятью с помощью асинхронных когерентных команд прямого доступа, которые выполняются блоком управления потоком данных, входящим в состав любого SPE.
Каждый SPE поддерживает до 16 ожидающих выполнения команд прямого доступа к памяти (DMA). В этих когерентных командах применяются такие же, как в PPE, преобразование адресов и защита, управляемые таблицами страниц и сегментов из архитектуры Power Architecture, поэтому адреса можно передавать между PPE и SPE. Вследствие этого операционная система способна использовать общую память и согласованно управлять всеми системными ресурсами.
Блок DMA может быть запрограммирован одним из трех способов: при помощи команд SPE, которые вставляют в очереди команды прямого доступа к памяти; путем подготовки в локальной памяти списка команд для пересылки содержимого разрозненных участков памяти (scatter-gather DMA) и выдачи единого списка команд DMA; с помощью вставки команд в очередь DMA другого процессора (с соответствующими привилегиями) и применения команд сохранения или записи DMA. Для удобства программирования (чтобы разрешить транзакции DMA типа "локальная память — локальная память") локальная память отображается на карту памяти процессора. Однако при кэшировании эта память не является в системе когерентной.
Появление локальной памяти вводит новый уровень иерархии памяти — в дополнение к регистрам, которые обеспечивают локальное хранение данных в большинстве процессорных архитектур. Это обеспечивает механизм борьбы с проблемой "стена памяти" (memory wall), поскольку позволяет одновременно выполнять множество транзакций с памятью без глубокой спекуляции, которая сильно снижает эффективность других процессоров. Латентность основной памяти приближается к 1 тыс. тактов, поэтому те несколько тактов, которые нужны для настройки команды DMA при обращении к ней, становятся вполне приемлемой дополнительной нагрузкой. Очевидно, что такая организация процессора удобна для обработки мультимедийных потоков. А поскольку локальная память достаточно велика для хранения большего, чем просто ядро (streaming kernel) потока, возможна поддержка самых разных моделей программирования.
Локальная память — самый крупный компонент SPE, поэтому была очень важна ее эффективная реализация. Для минимизации площади использована однопортовая ячейка SRAM. Локальная память имеет узкий (128-разрядный) и широкий (128-байтовый) порты чтения и записи. Это обеспечивает высокую производительность, хотя она и должна выступать в роли арбитра по отношению к операциям чтения, записи, выборки команд, загрузки и сохранения с прямым доступом. Широкий порт служит для прямого чтения и записи в память, а также для упреждающей выборки команд.
Поскольку типичная 128-байтовая операция прямого чтения/записи требует 16 тактов процессора для пересылки данных по внутренней когерентной шине (даже когда операции прямого чтения/записи выполняются без ограничений на пропускную способность), семь из каждых восьми тактов остаются доступными для операций загрузки, сохранения и выборки команд. Аналогичным образом команды выбираются по 128 байтов за раз, и нагрузка на локальную память остается минимальной. Наивысший приоритет отдан командам DMA, за которыми следуют операции загрузки и сохранения, а операция упреждающей выборки команды выполняется, когда есть свободный такт. Существует специальная команда "без операции", позволяющая при необходимости принудительно обеспечить доступность слота для выборки команды.
Блоки выполнения операций в SPE работают со 128-разрядным потоком данных. Достаточно большой файл регистров из 128 элементов позволяет компилятору переупорядочить команды и компенсировать ла-тентность их выполнения. Имеется только один файл регистров, а все команды являются 128-разрядными SIMD-командами с изменяющейся шириной элемента (2x64, 4x32, 8x16, 16x8 и 128x1 разрядов).
За один такт может быть выдано до двух команд; один слот выдачи команды поддерживает операции с плавающей и фиксированной запятой, а другой обеспечивает загрузку/сохранение, операции перестановки байтов и перехода. Простые операции с фиксированной запятой занимают два такта, а команды одинарной точности с плавающей запятой и команды загрузки требуют шести тактов. Поддерживаются также двухпоточные SIMD-команды двойной точности с плавающей запятой, но максимальная скорость их выдачи составляет семь тактов на команду. Все остальные команды полностью конвейеризованы.
Для того чтобы ограничить дополнительную нагрузку на оборудование, вызванную прогнозированием ветвлений, программист или компилятор могут "подсказать" переход. Команда подсказки перехода уведомляет оборудование об адресе предстоящей команды перехода и его целевом адресе. Оборудование (в предположении, что доступны слоты локальной памяти) заранее выбирает по меньшей мере 17 команд по целевому адресу перехода. Для уменьшения числа ветвлений в коде можно использовать поразрядную команду выбора с тремя источниками.
Настройка DMA-контроллера, а также наличие очередей запросов позволяет SPE работать параллельно с работой DMA. Именно таким образом удается избежать простаивания SPE в результате задержки получения данных из основной памяти.
Несмотря на то, что PPE и SPE имеют общую память, между ними есть четкое разделение функций. PPE оптимизирован для решения задач управления и смены контекста, в то время как SPE — для решения вычислительных задач.
PPE получает доступ к общей памяти посредством инструкций загрузки/сохранения (через иерархию кэшей), перемещающих данные между регистровым файлом PPE и основной памятью.
SPE получает доступ к общей памяти посредством DMA-передач, перемещающих данные между локальной памятью SPE и общей памятью CELL.
Архитектура ATAC основывается на ячеистом принципе построения многоядерных процессоров, с тем отличием, что ячейками в данном случае выступают кластеры, которые состоят из нескольких вычислительных ядер, объединенных нанокристалльной сетью. Ячейки объединяются широковещательной оптической шиной. Интересным моментом является интеграция оптоэлектронных модулей и оптических каналов в рамках КМОП-технологии. Предусматривается возможность масштабирования количества ядер до нескольких тысяч.
Направление развития современных микропроцессоров вполне понятно — постепенный переход к многоядерным системам. Многие производители заявляют о достижении 1000 и более ядер на кристалле примерно к середине следующего десятилетия (∼2015). Но существует проблема: нынешние процессорные архитектуры, а особенно межъядерные коммуникационные механизмы, плохо приспособлены к масштабированию до тысячи вычислительных ядер. Это же касается и способов их программирования.
Архитектура АТАС объединяет оптическую широковещательную сеть с ячеистой (плиточной) мультиядерной архитектурой для значительного увеличения производительности, энергетической масштабируемости и упрощения программирования.
Существующие многоядерные архитектуры не позволяют следовать закону Мура для некоторых важных классов параллельных приложений. Ограничения накладываются стоимостью взаимодействий ядер и скоростью обмена с внешней памятью. Целью проекта АТАС является решение этих проблем путем внедрения технологии оптической связи.
Вычислительный процесс можно представить как некий информационный поток, захватывающий ядра процессора, распространение инструкций и передачу значений между ядрами. По мере увеличения количества процессоров будет возрастать задержка передачи данных между отдаленными ядрами. Эффект может увеличиваться, если взаимодействие между парами ядер будет требовать уже занятых коммуникационных ресурсов. Это принципиально для приложений, работающих на глобальных взаимодействиях (широковещательная рассылка или синхронизация кэшей). Помимо потери производительности глобальные коммуникационные операции также ведут к значительным энергетическим затратам. Мультипроцессоры с небольшим количеством ядер используют для внутренних соединений шину. Это простое решение, как известно, не масштабируется на большое количество ядер. Системы с большим количеством ядер применяют связи типа "точка-точка", где управление коммуникациями осуществляется программно.
Как правило, для приложений с нерегулярной, не предсказуемой заранее или широковещательной структурой связей переход к процессорам с тысячами ядер на кристалле может быть крайне затруднен или невозможен. Масштабируемости приложений также мешают существующие программные техники. Программисты должны распределять вычисления по пространству и по времени, а также управлять взаимодействием ядер, если они хотят достичь высокой производительности для данной аппаратной архитектуры. В зависимости от используемой внутрикристальной сети скоординировать действия сотен и тысяч процессоров может быть крайне сложно.
Такие действия, как доставка инструкций ядрам, могут создать сложности даже для SIMD-архитектур. Существующие техники программирования не предусматривают оптимизации межпроцессорных коммуникаций для достижения высокой производительности. Широковещательные сообщения и сообщения "все-ко-всем", используемые в протоколах синхронизации, согласования или распределения инструкций, не имеют прямой аппаратной поддержки и эмулируются путем многократных передач типа "точка-точка".
Процессорная архитектура АТАС предусматривает решение этих проблем путем организации оптической сети вместо электрических каналов и шин. Проект нацелен на интеграцию оптоэлектронных компонент со стандартными КМОП-схемами. АТАС предусматривает частотное мультиплексирование — передачу сигналов на различных длинах волн — до 64 частотно разнесенных каналов. Оптические линии помимо прочего передают данные на более высоких скоростях, чем электрические линии (функция коэффициента преломления света в сравнении с задержками RC-цепей, диэлектрик, окружающий связи, и задержка, необходимая для ретрансляции электрического сигнала).
Оптические сигналы также могут требовать меньше мощности, чем электрические сигналы (особенно для длинных расстояний), за счет меньших потерь и отсутствия необходимости повторения сигналов.
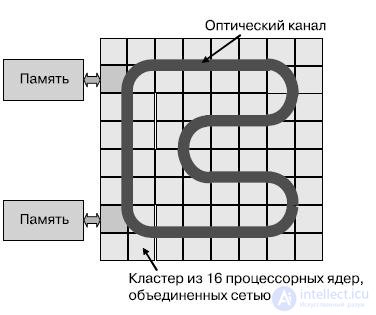
Рис.27.14 АТАС-архитектура
Архитектура АТАС (рис.27.14) базируется на возможности нанооптики создавать высокопроизводительные, глобальные накристальные сети с низкой задержкой распространения сигнала. Сеть состоит из оптического канала, охватывающего кристалл. Оптические хабы передают данные при помощи модуляции лазерного луча источника и направления его в сеть. Свет быстро распространяется по каналу и становится доступным для приема остальным хабам. Таким образом, любое сообщение в сети может быть эффективно передано всем ее участникам. Фильтрация на приемном хабе позволяет ограничить количество получателей сообщения.
АТАС допускает новую парадигму программирования многоядерных систем, с большим количеством разделяемых данных и простым механизмом распределения инструкций в рамках SIMD-модели. Механизм широковещания позволяет осуществлять массированное согласование кэшей многих ядер практически без ограничений.
При использовании новых оптических технологий АТАС процессор имеет потенциальную возможность уменьшить трудность программирования, повысить энергоэффективность, увеличить пропускную способность как внешних, так и внутренних шин данных и соответственно предусматривает масштабирование мощности .
Ключевыми элементами технологии, присутствующими на АТАС- кристалле, являются: так называемый "оптический источник питания" — источник света, волноводы для передачи света, модуляторы для помещения световых сигналов в волноводы, детекторы для приема сигналов. В АТАС источником света (оптическим питанием) служат внешние лазеры. Световой поток направляется в накристальные световоды. Энергопотребление внешнего лазера — примерно 1,5 Вт с выходом примерно 0,2 Вт в виде оптического излучения, попадающего в световод. Для использования схемы разделения частот предполагается наличие нескольких источников лазерного излучения. Световоды представляют собой встроенные каналы, по которым распространяется свет. Они направляют и распределяют при помощи комбинирования материала с большим коэффициентом преломления в центре и с меньшим по краям канала. Световоды могут быть изготовлены как из кремния, так и из полимера. С учетом того, что кремниевые световоды могут быть размещены на кристалле более компактно и что модуляторы для кремниевого световода намного более компактные, чем для полимерного, в АТАС предполагается создание кремниевых световодов. Тем более что кремниевые световоды могут быть изготовлены в стандартном КМОП-процессе.
Требуются световоды с потерями менее, чем 0,3 дБ/см и емкостью по мощности не менее 10мВт. И то и другое требование в кремнии достижимо. Для обмена информацией используются следующие компоненты: источник света, модулятор, оптический фильтр, электронный драйвер модулятора. Оптический фильтр представляет собой кольцевой резонатор(рис.27.15), настроенный на определенную длину волны, — определяется размерами резонатора (также им определяется расстояние между длинами волн для схемы WDM). Дальнейшая настройка может быть осуществлена путем изменения температуры резонатора или его заряда. Модулятор представляет собой оптическое устройство, которое формирует цифровой сигнал, изменяя коэффициент поглощения. Модуляторы применяются для преобразования электрического сигнала в оптический — своего рода оптический коммутатор, помещающий оптический сигнал в световод.
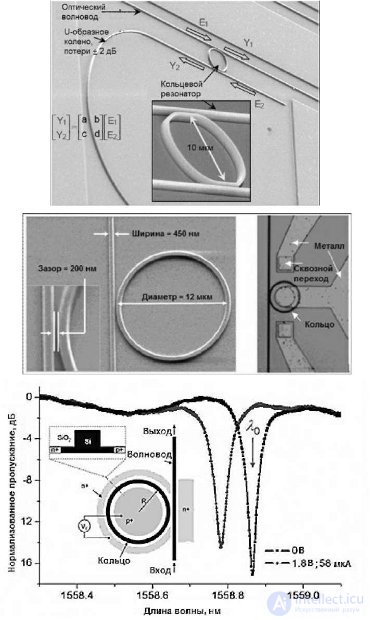
Рис. 27.15. Структура кольцевого оптического резонатора
Модуляторы, требуемые для архитектуры АТАС, должны иметь параметры, которые ориентировочно будут достигнуты в 2012 году: потери на включение — 1 дБ, площадь — менее 50 кв. мкм, скорость модуляции — 20 Гб/с, энергия, необходимая на переключение, — менее 25 фДж и общее потребление — порядка 25 мкВт/ГГц. На приемной стороне для приема сигнала используется дополнительный компонент — оптический фильтр для приема сигнала и преобразования его в электрический вид.
Оптический фильтр (кольцевой резонатор) используется для извлечения света нужной длины волны из световода и транспортировки его к фотодетектору. Так же как и модулятор, оптический фильтр должен быть настроен на конкретную длину волны. Фотодетектор в данном случае должен быть сверхчувствительным приемником. Для архитектуры АТАС требуются следующие параметры: для 11-нм технологичного процесса — чувствительность более 1 А/Вт, ширина полосы пропускания более 3 дБ на частотах более 20 ГГц, занимаемая площадь — менее 20 кв. мкм, паразитная емкость менее 1 фФ. При данной технологии выход детектора нуждается в усилении. Как правило, начиная с технологии 22 нм, меньшая емкость входа транзистора позволяет фотодетектору управлять цифровыми схемами. На рисунке 27.16 вышеперечисленные компоненты изображены вместе. Для одного ядра показана передающая часть, для другого — принимающая.
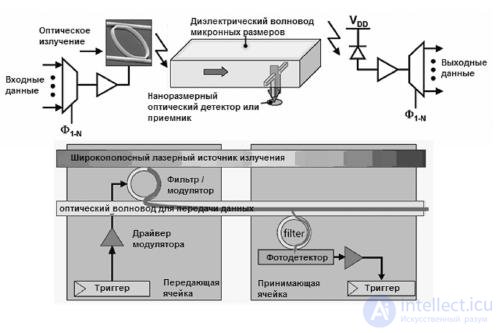
Рис.27.16 Схема оптической передачи между двумя ядрами
Для всех ядер, входящих в архитектуру, узлы приема-передачи оптических данных одинаковые. Сигналы модулятора используются для посылки 0 или 1 в сеть. Драйвер модулятора состоит из нескольких инверторов, которые управляют емкостной нагрузкой модулятора. Модулятор помещает свет на волне предварительно настроенной длины в световод, кодируя тем самым 0 или 1. Оптически кодированные данные распространяются по световоду на скорости, равной примерно одной трети скорости света, и принимаются фильтром, настроенным на ту же длину волны. Кванты света улавливаются приемником и передаются приемному регистру на приемной стороне.
Архитектура АТАС представляет собой "плиточную/ячеистую" многоядерную архитектуру, сочетающую технологию электрических соединений с оптической накристальной сетью. Применяется связанный двумерный массив простых вычислительных ядер, каждое из которых содержит одиночный или двойной RISC-процессор и кэш данных первого уровня. ATAC использует протокол распределенных директорий. Часть распределенной директории расположена в каждом узле.
Ядра в АТАС связаны двумя сетями — электрической EMesh и оптико-электрической ANet. ENet — обычная двумерная электрическая сеть типа "точка-точка", аналогичная существующим в обычных мультипроцессорах. EMesh идеальна для предсказуемых, близких взаимодействий. ANet предлагает технологию для организации оптической накристальной сети, основанную на технологии оптической памяти. Ядро сети ANet составляет ONet (рис.27.17). Сеть ANet содержит 64 оптически соединенных кластера, включающих в себя небольшие электрические структуры, служащие для взаимодействия с оптической сетью, — это сети ENet и BNet.
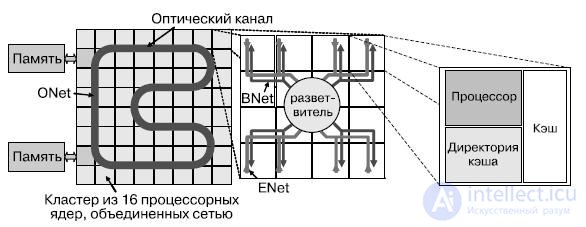
Рис.27.17. Организация связи между модулями АТАС архитектуры на различных уровнях
ANet используется обычно для осуществления передачи данных между удаленными ядрами или для глобальных передач в рамках сети (широковещательные передачи).
Ключ к эффективной организации глобальных коммуникаций в пределах кристалла — оптическая сеть ONet. Она обеспечивает связь между отдельными конечными точками, называемыми хабами. Хабы соединены между собой световодом, проходящим через весь кристалл, формируя замкнутое кольцо (рис.18.33). При помощи модулятора, оптических фильтров и приемника хаб имеет возможность передавать и принимать данные из световодов. Сигнал, посланный одним из хабов, быстро достигает остальных. Таким образом, любая передача в сети может быть широковещательной. Для передачи независимых данных применяется частотное мультиплексирование каналов. Каждый хаб имеет фильтры, настроенные на уникальную длину волны, и фильтры, позволяющие ему принимать сигналы на всех длинах волн. Эта возможность используется при организации глобальных передач, синхронизации ядер, управлении сетью. В дополнение к этому повышенная скорость передачи исключает разнородную задержку распространения сигнала, зависящую от расстояния между ядрами, — в любой паре хабы взаимодействуют между собой с малой фиксированной задержкой, вместо задержки на один цикл на узел в связях типа "точка-точка". В общем, функциональность сети ONet можно сравнить с полносвязной сетью с двунаправленными связями между узлами и с дополнительной функцией широковещания. Частотное разделение каналов позволяет задействовать один световод для нескольких перекрывающихся передач в различных направлениях (для сравнения, электрическая связь обычно используется для передачи одного бита). Для многих сетевых операций, трудно реализуемых в электрических сетях, применение АТАС существенно увеличивает эффективность. ONet может масштабироваться до как минимум 64 хабов (возможно до 100). Количество длин волн, на которые могут быть настроены фильтры, ограничено минимально необходимым расстоянием, спектральной шириной канала и общей шириной полосы излучения в питающем световоде. Также существуют ограничения по общему количеству энергии, которое может передать световод в отношении к количеству энергии, требуемому детектором для приема сигнала, и по максимальной длине волновода, зависящей от потерь распространения.
Указанные ограничения могут быть обойдены использованием нескольких волноводов и распределением каналов передачи данных между ними. Как правило, при этом площадь, необходимая для реализации световода, может также стать ограничением. Оптические компоненты сети и сама сеть могут быть вынесены на отдельный уровень КМОП-стека и накладываться на электронные компоненты, к которым они подключаются. К примеру, на кристалле площадью 400 мм2 может разместиться оптическая сеть с 384 хабами. Для рассматриваемого случая ONet соединяет 64 одинаковых кластера при помощи 64-битной оптической шины, проложенной по всему кристаллу. Каждый кластер содержит 16 вычислительных ядер и хаб сети ONet. Внутри кластера ядра связаны между собой и с оптическим хабом двумя сетями — ENet и BNet. ENet используется только для передачи данных от ядер кластера к хабу ONet. BNet — широковещательная электрическая сеть для передачи данных от оптической сети вычислителям.
Более детально процесс передачи данных с применением сети ANet показан на рис. 27.18.
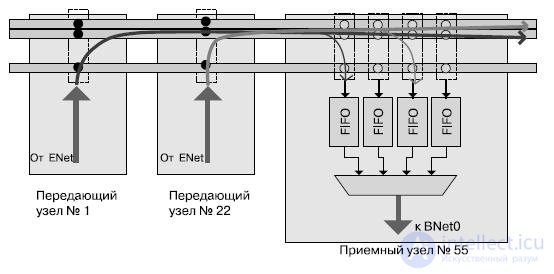
Рис.27.18. Процесс передачи данных с использованием сети ANet
Сообщения ядер достигают хаба, который, в свою очередь, пересылает их в сеть ONet на своей уникальной длине волны. Это позволяет двум хабам передавать данные одновременно без интерференции. ONet состоит из нескольких световодов: 64 для данных, 1 для управления и несколько для метаданных. Световоды метаданных служат для указания типа передаваемого сообщения (чтение памяти, данные и пр.) или как тэг сообщения (для устранения двусмысленности при нескольких сообщениях от одного источника). Хаб приемника принимает оба значения последовательно в FIFO-буфер, связанный с конкретным отправителем. Затем данные пересылаются вычислительным ядрам через BNet. Оптическая часть позволяет эффективно реализовывать широковещательную передачу с большей скоростью и меньшими затратами на регенерацию сигнала.
Ядра в АТАС — простые процессоры с кэшем данных и команд первого уровня. Когерентность кэшей поддерживается при помощи протокола, известного как ACKwise. Кэши поддерживают когерентность при помощи протокола распределенных директорий MOESI.
Директории распределены равномерно между ядрами, более того, каждое ядро является "домом" для определенного пула адресов (распределяется статически). Рис 27.19 представляет три ядра, находящиеся в различных кластерах. Каждое ядро содержит процессор, кэш данных и директории кэша. Для примера (рис. 27.19) предположим, что обращение к директории кэша всегда приводит к промаху (необходимости синхронизации кэша). Стрелками на рисунке обозначены типовые операции по согласованию кэшей: промах по записи по адресу А ядром а. В данном примере ядро б является "домом" адреса А, и начальное состояние адреса А в кэше — "занято" (O-state) ядром с. Трафик по согласованию кэшей передается по сети ANet. Последовательность действий для согласования кэшей для данного случая будет следующей:
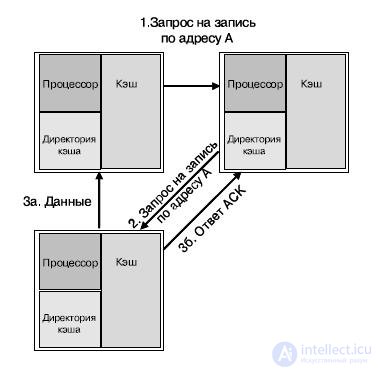
Рис.27.19. Пример согласования кэшей различных ядер
1. процессор в ядре а пытается осуществить запись по адресу А и получает ошибку записи;
2. ядро а посылает запрос на запись ядру б, к которому относится адрес А;
3. ядро б не имеет данных в кэше, но указывается, что этот адрес занят ядром с. Ядро б посылает запрос на запись по этому адресу от имени ядра а;
4.
o ядро с пересылает данные адреса А ядру а и обновляет состояние кэша для этого адреса до "недействительный";
o ядро с посылает ACK-сигнал в директорию ядра б;
5. линия кэша, содержащая адрес А, обновляется на ядре а, и линия получает статус "модифицирована";
6. процессор ядра а производит запись по адресу А.
Когда ядрам необходимо обратиться к внешней памяти, они делают это при помощи нескольких встроенных в кристалл контроллеров памяти. Каждый контроллер памяти замещает кластер ядер и, таким образом, имеет свой выделенный оптический хаб. После получения запроса по оптической сети он обращается к внешним DRAM-модулям посредством стандартных линий ввода-вывода. Результаты передаются в оптическую сеть. Изменяя количество контроллеров памяти и количество кластеров, можно на различных АТАС-процессорах достигать различных значений показателей пропускной способности подсистемы памяти и вычислительной мощности. Основная задача контроллера памяти — преобразовать запросы от процессорных ядер в транзакции на шине памяти. Выбор технологии шины, таким образом, не зависит от архитектуры накристальной сети.
Вполне допустим вариант использования оптических интерфейсов как на ввод-вывод, так и для шины памяти. Это даст преимущество в пропускной способности и потребляемой мощности.
Каждый оптический вывод может поддерживать до 64 длин волн со скоростями до 20 ГГц. Скорость передачи данных будет ограничена скоростью работы электронных компонент, управляющих оптическим потоком. Предполагается, что скорость в 5 ГГц вполне может быть достигнута. При этом полоса пропускания оптического вывода может достигать 320 Гб/с (40 Гб/с). Для сравнения, 64-битная DDR3 имеет пиковую пропускную способность 12,8 Гб/с. Поскольку оптическая шина памяти состоит только из одного световода, уменьшается количество выводов, и это при увеличении пропускной способности практически в три раза. Все это де- лает применение оптического ввода-вывода востребованным для АТАС- процессоров с несколькими контроллерами памяти.
Архитектура ориентируется на 11-нм техпроцесс, который, по мнению ее разработчиков, может быть реализован к середине десятилетия (ориентировочно 2012-2016 гг.).
1. Структура процессора Tile64.
2. Организация кэш-памяти в процессоре Tile64.
3. Коммутатор сети iMesh.
4. Структура процессора CSX700.
5. Структура MTAP-блока в процессоре CSX700.
6. 167-ядерная вычислительная платформа — AsAP-II.
7. Общая структура процессора Cell.
8. Структурная схема процессорного элемента PPE в Cell.
9. Структурная схема процессорного элемента SPE в Cell.
10. Альтернативная технология построения многоядерных систем на кристалле — ATAC.
11. Основные идеи архитектуры ATAC.
12. Ключевые элементы технологии АТАС.
13. Структура межъядерных связей в архитектуре АТАС.
14. Передача данных и согласование кэш-памяти в архитектуре АТАС.
Надеюсь, эта статья про многоядерные процессоры для встраиваемых приложений, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое многоядерные процессоры для встраиваемых приложений и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Компьютерная схемотехника и архитектура компьютеров
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Компьютерная схемотехника и архитектура компьютеров
Термины: Компьютерная схемотехника и архитектура компьютеров