Лекция
Привет, сегодня поговорим про прямой доступ в память, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое прямой доступ в память , настоятельно рекомендую прочитать все из категории Компьютерная схемотехника и архитектура компьютеров.
Программно-управляемый ВВ между ОП и ПУ во многих случаях является далеко не самым оптимальным, а иногда вообще невозможным. Причин тому несколько. Рассмотрим очень коротко основные из них.
· При программно-управляемом ВВ процессор "отвлекается" от выполнения основной программы решения задачи. Операции ВВ достаточно просты, чтобы эффективно загружать логически сложную быстродействующую аппаратуру процессора. В результате при использовании программно-управляемого ВВ снижается производительность ЭВМ в целом.
· При пересылке любой единицы данных (байт, слово) процессор выполняет достаточно много команд, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных единиц данных, формирование адресов памяти и регистров ПУ. В результате скорость передачи данных при программно-управляемом ВВ (т.е. через процессор) может оказаться недостаточной для работы с высокоскоростными ПУ, например с накопителями на жестких дисках, видеосистемами, быстродействующими аналого-цифровыми и цифро-аналоговыми преобразователями различного назначения, и т.д.
· Большинство современных сложных ПУ, таких как видеосистемы, сетевые карты, жесткие диски и т.д., осуществляют обмен с ОП целыми блоками информации. В этом случае перечисленные выше непроизводительные временные затраты процессора становятся особенно существенными.
· Обмен в режиме прерывания, несмотря на все свои достоинства, требует еще помимо перечисленных выше непроизводительных временных затрат время на сохранение вектора состояния текущей программы в стеке и его последующего восстановления. Кроме того, прерывание в большинстве случаев возможно только после завершения текущей команды.
Несмотря на широкое использование программно-управляемого ВВ, для ускорения операций обмена данными между ОП и ПУ и разгрузки процессора от управления этими операциями в современных ЭВМ используется специальный режим обмена, получивший название режим прямого доступа к памяти или просто прямой доступ к памяти (ПДП). В англоязычной литературе – Direct Memory Access (DMA). Ниже, в зависимости от контекста излагаемого материала, будут употребляться обе аббревиатуры – ПДП и DMA.
Прямым доступом к памяти называется режим, при котором обмен данными между ОП и регистрами ПУ осуществляется без участия центрального процессора за счет специальных, внешних по отношению к нему, электронных схем.
Введение режима ПДП (реализация каналов ПДП) всегда усложняет аппаратную часть ЭВМ, однако позволяет повысить скорость выполнения операций обмена ОП-ПУ, разгружает центральный процессор от обслуживания операций ВВ, повышает общую производительность ЭВМ. При наличии кэш-памяти достаточного объема режим ПДП в ряде случаев позволяет реализовать параллельное выполнение операций обмена и обработку команд текущей программы процессором, что также повышает общую производительность ЭВМ. Более того, наличие механизма прямого доступа к памяти позволяет поддерживать многопроцессорность вычислительной системы. На последнем моменте необходимо остановиться более подробно.
Дело в том, что термин ПДП (как и DMA), используемый при изложении материала настоящего раздела, в общем случае не совсем точно отражает суть процессов, происходящих в ЭВМ. Точнее, прямой доступ к памяти (к ОП) является только частным случаем организации процедур доступа к системной магистрали со стороны множества устройств, в том числе и процессоров. Под доступом к системной магистрали понимается возможность какого-либо устройства, имеющего соответствующее аппаратно-программное обеспечение (ведущее устройство, интеллектуальное устройство магистрали), занимать на какое-то время системную магистраль и полностью управлять ею, вырабатывая все необходимые управляющие сигналы. При этом могут осуществляться связи не только ОП-ПУ, но и ПУ-ПУ. Между тем смысл понятия "память" можно расширить и понимать под памятью не только ОП, но и адресуемые регистры ПУ. В этом случае использование термина ПДП (как и DMA) будет вполне корректно.
Следует иметь в виду, что термин "периферийное устройство (ПУ)" здесь используется достаточно условно. В англоязычной литературе ведущее устройство магистрали, инициирующее обмен, принято называть master. Устройство, к которому обращается master, является подчиненным, и его принято называть slave. Таким образом, более правильно говорить о реализации связей master-slave (M-S), а не ПУ-ПУ или ОП-ПУ. Мастером может быть только интеллектуальное устройство, имеющее средства управления магистралью (СУМ), которые, как минимум, должны "уметь" формировать и модифицировать адреса обращения, вести контроль за размером переданного блока информации и генерировать управляющие сигналы магистрали. Между тем в зависимости от текущего состояния вычислительного процесса одно и то же интеллектуальное устройство магистрали может выступать и как master, и как slave. Устройства магистрали, не имеющие СУМ, всегда являются подчиненными, т.е. slave.
Естественно, что предоставление магистрали в распоряжение того или иного устройства (захват магистрали) может происходить только на приоритетной основе. Эта процедура получила название арбитраж магистрали, а устройство, ее реализующее, – арбитр магистрали. В ряде случаев арбитр может строиться как отдельное устройство, размещенное на системной магистрали. В других случаях арбитраж магистрали выполняет сам процессор. Наличие процедуры арбитража позволяет размещать на системной магистрали несколько интеллектуальных устройств, в том числе и процессоров. В соответствии с принятой дисциплиной обслуживания (арбитража) каждое из них будет получать в свое распоряжение системную магистраль и устанавливать связи как с ОП, так и с регистрами других устройств магистрали. Следует отметить при этом, что в процедуре арбитража всегда предусматриваются средства, предотвращающие монопольный захват магистрали одним устройством. Часть этих средств может быть сосредоточена в арбитре, другая часть может быть распределена между устройствами магистрали, использующими режим ПДП.
Конкретные варианты процедур доступа ведущих устройств к магистрали (организации каналов ПДП) в различных ЭВМ очень разнообразны. Между тем существуют некоторые общие принципы их реализации. В общем случае для устройств, использующих ПДП (DMA), выделяют два основных принципа организации доступа, в соответствии с которыми выделяют два типа систем ПДП (DMA).
Пассивный доступ или slave DMA. При этом способе доступа все устройства, использующие режим DMA, являются slave и обслуживаются одним специальнымконтроллером DMA (ПДП), размещенным на системной магистрали, т.е. одним ведущим устройством, – master. Такой способ доступа позволяет реализовать только связи ПУ-ОП. Контроллер DMA включает в себя арбитр магистрали и соответствующие СУМ. В этом случае ПУ играют пассивную роль и осуществляют обмен с ОП по сигналам, формируемым контроллером DMA, т.е. аналогично тому, как это происходит при обмене через процессор.
Как уже отмечалось выше, контроллер DMA обслуживает несколько ПУ, т.е. поддерживает несколько каналов ПДП. Перед началом обмена контроллер должен быть инициализирован. Для этого в его регистры необходимо загрузить начальный адрес области ОП, с которой ведется обмен, размер передаваемого блока информации для каждого канала, направление и режим передачи, дисциплину арбитража. В общем случае инициализация контроллера может осуществляться по мере необходимости (многократно) в процессе обработки текущей программы. Однако установка дисциплины арбитража в абсолютном большинстве случаев осуществляется один раз, при запуске вычислительной системы на решение конкретной задачи.
Таким образом, slave DMA не требует существенного усложнения аппаратуры устройств магистрали, а следовательно, и увеличения их стоимости. Каждое устройство, использующее такой режим обмена, должно иметь только аппаратуру формирования сигнала запроса ПДП (запросчик). При этом контроллер DMA является достаточно сложным и дорогим устройством, которое можно считать сопроцессором ввода/вывода, разгружающим центральный процессор от рутинных операций обмена (т.е. контроллер ПДП является очень упрощенным вариантом канальных процессоров мэйнфреймов).
Исторически системы slave DMA появились первыми. В частности, система ПДП такого типа использовалась первоначально на магистрали ISA в компьютерах PC/XT фирмы IBM. Многочисленные варианты систем slave DMA используются и в настоящее время в универсальных и управляющих ЭВМ самой разной архитектуры, назначения и производительности.
Активный доступ, или bus master DMA. При этом способе доступа предполагается, что устройства, использующие режим DMA, имеют программно-аппаратные средства, способные управлять магистралью (осуществлять прямое управление магистралью, илиbus mastering), а следовательно, и реализовывать любые связи типа master-slave (M-S). Такие устройства магистрали могут выступать как master, поэтому единый контроллер DMA отсутствует. Остается только арбитр магистрали, который по определенной дисциплине предоставляет магистраль в распоряжение того или иного устройства. Арбитр может быть выполнен как отдельное устройство, размещенное на магистрали, либо арбитражем магистрали может заниматься процессор. В современных IBM PC процедуры арбитража магистрали включены в функции чипсета. При наличии нескольких процессоров арбитром может быть назначен один из них.
Следует иметь в виду, что любое современное интеллектуальное устройство управляется процессором (процессорами), находящимся на системной магистрали и имеющим собственную шину расширения. Такое устройство фактически является специализированной микро-ЭВМ, функционирующей по программе, обычно хранящейся в собственном ПЗУ. Этим оно, в сущности, только и отличается от "центрального процессора (ЦП)", также находящегося на системной магистрали и обрабатывающего команды текущей программы, хранящейся в ОП или системном ПЗУ. Такой подход позволяет рассматривать "ЦП" как одно из интеллектуальных устройств магистрали, причем "ЦП" может быть несколько. Исходя из этого, в вычислительных системах, использующих bus mastering, можно говорить о множестве интеллектуальных устройств, приоритеты которых на использование системной магистрали для обмена (захват магистрали) определяются только дисциплиной обслуживания, загруженной в арбитр при инициализации, т.е. можно говорить о многопроцессорных вычислительных системах.
Таким образом, bus master DMA требует существенного усложнения устройств магистрали (наличие СУМ, более сложный запросчик), а следовательно, и увеличения их стоимости. Однако он дает возможность ускорить процессы обмена, особенно в многозадачном режиме, и реализовать многопроцессорные варианты вычислительных систем, имеющих магистрально-модульную архитектуру.
Примером устройств с активным DMA являются контроллеры АТА (AT Attachment for Disk Drivers), расположенные в современных IBM PC на магистрали PCI, в частном случае контроллеры IDE. Активный DMA использует хост-адаптер шины SCSI (Small Computer System Interface), связывающий шину с какой-либо внутренней магистралью компьютера, а также контроллеры графических систем и средства их подключения, например порт AGP (Accelerated Graphic Port) и ряд других устройств. Примером устройств, использующих только bus master DMA (bus mastering), являются устройства вычислительных систем, построенных на базе магистрали VME (Versa Module Eurocard).
Следует отметить, что в реальных вычислительных системах иногда используют оба варианта систем DMA одновременно (для разных устройств магистрали). При этом контроллер может поддерживать несколько каналов DMA и работать в комбинированном режиме. Для одних устройств магистрали (slave) он может выполнять функции контроллера DMA, а для других устройств (master) он являются только арбитром магистрали. Именно такой вариант функционирования системы DMA был реализован в PC/AT фирмы IBM.
Конкретные технические реализации систем ПДП имеют множество вариантов. Они зависят от типа системной магистрали, архитектуры ЭВМ в целом, типа используемого процессора, целевого назначения ЭВМ, количества устройств на магистрали и т.д. В то же время они являются сложными комбинациями небольшого количества базовых структур систем ПДП. Ниже рассматриваются две основные базовые структуры – радиальная и цепочечная.
Радиальная структура
Упрощенные варианты обобщенных структур систем ПДП радиального типа представлены на рис. 20.1.
Характерной особенностью радиальной структуры является то, что каждый ИЗПД (в частном случае ПУ) подключен к отдельному входу контроллера ПДП (рис. 20.1, а) или арбитра (рис. 20.1, б). Отличие двух структур состоит в том, что в случае slave DMA для подключения ИЗПД достаточно одной линии ЛЗПД, по которой устройство выставляет запрос на обслуживание. В системе bus master DMA для подключения устройства к арбитру необходимы, как минимум, три линии – ЛЗПД, ЛПЗ и ЛРПД, которые можно назвать шиной арбитража (ШАр), имеющей собственный вход в арбитр. Каждый вход (в контроллер, в арбитр) обладает определенным уровнем приоритета. Число подключаемых ИЗПД определяется числом входов в контроллер или арбитр.
При обслуживании устройств, использующих slave DMA (рис. 20.1, а), всем обменом управляет контроллер ПДП, обязательными компонентами которого являются блок СУМ и арбитр магистрали. Устройства магистрали пассивны и должны содержать только запросчик.
При обслуживании устройств, использующих bus master DMA (рис. 20.1, б), контроллер ПДП, как таковой, отсутствует и централизованно выполняется только арбитраж магистрали. Устройства магистрали активны, поэтому их обязательными компонентами являются запросчик и блок СУМ (как уже отмечалось, "ЦП" в системах bus mastering рассматривается как одно из ИЗПД). После захвата магистраль управляется блоком СУМ конкретного устройства, ведущего обмен (master). В качестве арбитра магистрали используется либо специализированное устройство, либо контроллер ПДП, в котором функции блока СУМ отключены. Линии ЛРПД, присутствующие в системе bus master DMA, предназначены для передачи сигнала РПД, позволяющего активному устройству захватить магистраль. Кроме того, в системе bus master DMA обязательно присутствуют линии ЛПЗ, сигналы которых информируют арбитр о захвате магистрали тем или иным устройством. Сигнал ПЗ всегда выставляет master и удерживает его на линии все время, пока осуществляет обмен (управляет магистралью), поэтому сигнал всегда представлен потенциалом.

Рис.20.1. Радиальная структура системы: а – Slave DMA, б – Bus Master
В системах радиальной структуры контроллер ПДП может работать, как было отмечено выше, и в комбинированном режиме, т.е. поддерживать как систему slave DMA, так и систему bus master DMA. Запросы от ИЗПД в обеих системах DMA могут быть представлены как уровнем потенциала, так и его перепадом, поскольку поступают в контроллер или арбитр по отдельным линиям. Однако представление запроса потенциалом более предпочтительно, поскольку система DMA становится более устойчивой как к помехам, так и к сбоям аппаратуры. Это существенно снижает вероятность пропуска запроса от ИЗПД.
Основным преимуществом радиальной структуры является то, что упрощается аппаратура арбитра магистрали, поскольку каждый ИЗПД имеет собственную ЛЗПД. Кроме того, несколько упрощается аппаратура ИЗПД и конструкция слота даже в случае bus master DMA, поскольку все активные устройства магистрали имеют отдельную шину арбитража (ШАр). Все это удешевляет радиальную систему по сравнению с цепочечной, рассматриваемой ниже.
Цепочечная структура
Упрощенный вариант обобщенной структуры системы ПДП цепочечного типа представлен на рис. 20.2.

Рис.20.2. Обобщенная цепочечная структура системы Bus Master DMA
Характерной особенностью цепочечной структуры является то, что множество активных устройств магистрали (ИЗПД), обязательными компонентами которых являются блок СУМ и запросчик, подключены к одной или нескольким шинам арбитража (ШАр). На рис. 20.2 присутствуют две ШАр. После захвата магистраль управляется блоком СУМ конкретного устройства, ведущего обмен (master). Контроллер ПДП отсутствует, и централизованно выполняется только арбитраж магистрали. На рис. 20.2 арбитр изображен как отдельное устройство магистрали, хотя, как отмечено выше, арбитраж может осуществлять и процессор (один из процессоров). Каждая ШАр соответствует одному входу в арбитр и обладает собственным уровнем приоритета. Таким образом, ИЗПД, подключенные к разным ШАр, обладают различным приоритетом. Пассивные устройства магистрали (slave) к ШАр не подключены. Кроме того, приоритет устройств, подключенных к одной ШАр, определяется также их положением в цепи распространения сигнала разрешения прямого доступа (РПД).
Рассмотрим этот момент более подробно на примере одной ШАрn системы bus master DMA, упрощенная структура которой приведена на
рис. Об этом говорит сайт https://intellect.icu . 20.3.
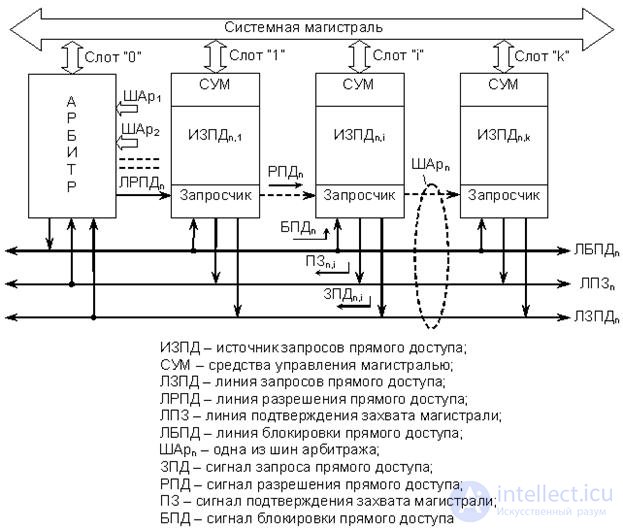
Рис.20.3. Структура шины арбитража ”n” системы bus master DMA цепочечного типа
Из рисунка следует, что ШАр (для упрощения обозначений здесь и ниже индекс "n" опущен) в такой системе содержит, как минимум, четыре линии – ЛЗПД, ЛРПД, ЛПЗ и ЛБПД. В отличие от радиальной структуры, ИЗПД магистрали подключены к трем линиям ШАр (ЛЗПД, ЛПЗ и ЛБПД) параллельно, поэтому запросы от ИЗПД (сигналы ЗПД) всегда представлены уровнем потенциала. Выходные каскады аппаратных средств формирования запросов в каждом ИЗПД представляют собой ключи с открытым коллектором, объединенные по схеме монтажного "или". Это позволяет исключить потерю запросов, одновременно выставленных запросчиками разных ИЗПД на одну ЛЗПД.
Сигнал РПД распространяется последовательно через все устройства, пока его распространение не будет заблокировано запросчиком ИЗПДi, выставившим запрос прямого доступа (сигнал ЗПДi). Таким образом, приоритет ведущего устройства магистрали определяется его положением в цепи распространения сигнала РПД. Пусть арбитр расположен в слоте с номером "0". Тогда приоритет устройств, расположенных в последующих слотах, будет убывать с ростом номера слота. При отсутствии устройства в слоте необходимо принять меры для того, чтобы цепь распространения сигнала РПД не разрывалась. Это обеспечивается либо специальной конструкцией контактов слота, либо установкой перемычки на системной плате.
Сигнал линии ЛПЗ, как и в радиальной системе bus master DMA, информирует арбитр о захвате магистрали тем или иным устройством. Этот сигнал всегда выставляет master и удерживает его на линии все время, пока осуществляет обмен (управляет магистралью), поэтому сигнал всегда представлен потенциалом.
Линия ЛБПД – общая для всех ШАр и предназначена для передачи от арбитра сигнала блокировки прямого доступа (БПД), который запрещает bus mastering всем интеллектуальным устройствам магистрали. Необходимость в этом может возникнуть, например, при появлении запроса на линии ЛЗПД ШАр более высокого приоритета (при наличии нескольких ШАр) или в случае удержания магистрали одним устройством недопустимо долгое время.
Следует иметь в виду, что системы цепочечной структуры практически работают только в режиме bus master DMA, поскольку арбитр магистрали может идентифицировать только ЛЗПД, с которой поступил запрос, и определить его приоритет. При реализации режима slave DMA контроллеру DMA необходимо будет идентифицировать конкретное ИЗПД на данной линии. Такую операцию контроллер может выполнить только путем последовательного опроса устройств линии, что существенно увеличит время арбитража и усложнит аппаратуру устройств. Между тем техническая реализация таких систем возможна.
Основным преимуществом цепочечной структуры является практически неограниченное количество ИЗПД, подключаемых к одному входу арбитра (одной ШАр) без снижения быстродействия. Однако сложность и объем аппаратуры поддержки системы bus mastering в каждом ИЗПД увеличиваются, что ведет к увеличению стоимости системы.
Использование любого варианта ПДП порождает ряд проблем, связанных с использованием общей магистрали несколькими устройствами. Даже при использовании простейшего варианта ПДП (slave DMA), который и рассматривается ниже, возникает проблема совместного использования магистрали двумя устройствами – процессором и контроллером ПДП. Для получения максимальной скорости обмена желательно, чтобы ПУ через контроллер ПДП имело непосредственную связь с ОП ЭВМ, т.е. имело бы специальную магистраль, как это и делается в ряде случаев. Однако такое решение существенно усложняет и удорожает ЭВМ, особенно при подключении нескольких ПУ, поэтому в большинстве простейших микро-ЭВМ для реализации обмена в режиме ПДП (организации каналов ПДП) используются шины системной магистрали. Именно этот вариант и рассматривается ниже. Кроме того, предполагается, что кэш-память отсутствует и данные (как и команды) поступают в процессор непосредственно из ОП. Последнее означает, что в течение всего периода обмена, т.е. пока магистралью управляет контроллер ПДП (master), процессор вынужден простаивать, поскольку не имеет доступа к ОП.
Несмотря на то что такой способ организации обмена в режиме ПДП характерен только для самых простейших микроЭВМ, на его примере можно достаточно наглядно проиллюстрировать основные принципы прямого управления магистралью со стороны ведущего устройства. Изучение механизма функционирования средств bas mastering более сложных вычислительных систем всегда требует достаточно детального рассмотрения сигналов конкретной системной магистрали, используемого процессора, особенностей архитектуры ведущих устройств и т.д.
Проблема совместного использования шин системного интерфейса процессором и контроллером ПДП в общем случае имеет два основных способа решения – ПДП с захватом цикла и ПДП с блокировкой процессора.
ПДП с захватом цикла
Этот способ ПДП предназначен для обмена короткими блоками информации в виде байта или слова и имеет два варианта.
Вариант 1. Для обмена используются те интервалы времени машинного цикла процессора, в которые он не обменивается данными с памятью или регистрами ПУ. В этом варианте контроллер ПДП никак не мешает работе процессора. Однако возникает необходимость выделения таких интервалов для исключения временного перекрытия обмена контроллера ПДП и процессора. В некоторых случаях процессоры формируют специальные сигналы, указывающие такты, в которых процессор не ведет операций обмена. В других случаях применяют специальные схемы, внешние по отношению к процессору, которые идентифицируют такие "свободные" интервалы времени.
Применение подобного варианта организации ПДП не снижает производительность процессора, но передача данных происходит только в случайные моменты времени. Это понижает общую скорость обмена. Кроме того, для некоторых ПУ, такой режим обмена вообще неприемлем.
Вариант 2. На время, необходимое для обмена одним байтом или словом данных (что составляет несколько тактов), процессор принудительно отключается от шин системной магистрали. Такой способ организации ПДП с захватом цикла является наиболее распространенным.
Когда ПУ готово к обмену, оно формирует сигнал ЗПД, который поступает в контроллер ПДП. Он, в свою очередь, вырабатывает аналогичный управляющий сигнал (ОЗПД), который поступает в процессор. Сигнал ОЗПД формируется контроллером при появлении сигнала (сигналов) ЗПД на любой линии (линиях) ЛЗПД и заставляет процессор на несколько тактов отключиться от системной магистрали. Получив этот сигнал, процессор заканчивает операции обмена на магистрали. Затем, не дожидаясь завершения текущей команды (или машинного цикла), выдает в контроллер ПДП сигнал РПД и отключается от шин системной магистрали. При этом внутренние операции в процессоре по завершению текущей команды (или машинного цикла) продолжаются и могут быть совмещены по времени с операциями ПДП.
С этого момента времени всеми шинами системной магистрали управляет контроллер ПДП. Используя системную магистраль, он осуществляет обмен между ПУ и ОП одним байтом или словом, а затем, сняв сигнал ОЗПД, возвращает управление системной магистралью процессору. Как только ПУ вновь будет готово к обмену, оно формирует сигнал ЗПД, контроллер ПДП захватывает магистраль, и цикл обмена повторяется. В промежутках между сигналами ЗПД процессор продолжает выполнять команды текущей программы.
Таким образом, в отличие от режима прерывания, который вводится только после завершения текущей команды, режим ПДП вводится, не дожидаясь ее завершения. Это связано с тем, что в режиме ПДП внутренние регистры процессора не используются, их содержимое не модифицируется, а следовательно, и не требует запоминания в стеке.
Естественно, что применение такого способа организации ПДП замедляет выполнение программы, но в меньшей степени, чем при обмене в режиме прерывания. Кроме того, в отличие от варианта 1 обмен происходит в те моменты времени, в которые это требует ПУ, что особенно важно при работе микроЭВМ в режиме реального времени.
Следует отметить, что такой вариант ПДП используется только тогда, когда интервалы времени между моментами готовности ПУ к обмену достаточно велики и позволяют выполнить процессору несколько операций.
ПДП с блокировкой процессора
Этот режим отличается от ПДП с "захватом цикла" тем, что управление системным интерфейсом передается контроллеру ПДП не на время обмена одним байтом или словом, а на все время обмена блоком данных. В этом случае все вопросы, связанные с синхронизацией работы ПУ и ОП, также решаются контроллером ПДП (в режиме "захвата цикла" их фактически решал процессор). Такой режим ПДП особенно необходим в тех случаях, когда процессор не успевает выполнить хотя бы одну команду между очередными операциями обмена в режиме ПДП.
Режим ПДП с блокировкой процессора в современных ЭВМ является основным, поскольку современные ПУ, такие как жесткие и оптические диски, видеосистемы, принтеры, сканеры и т.д., всегда ведут обмен блоками информации существенного объема. Однако для их передачи контроллер ПДП должен удерживать магистраль достаточно продолжительное время, в течение которого процессор будет простаивать. Это существенно понизит производительность рассматриваемой простейшей микроЭВМ в целом.
Между тем, как уже отмечалось, процессоры большинства современных ЭВМ работают с ОП через кэш-память. При наличии кэш-памяти достаточного объема (особенно многоуровневой) процессор может продолжать некоторое время обработку команд текущей программы – до тех пор, пока необходимая информация присутствует в кэш и не требует обновления. Это время достаточно ограничено, поэтому арбитр должен следить за тем, чтобы время удержания магистрали контроллером ПДП не превышало некоторой, наперед заданной величины и простои процессора были сведены к минимуму.
Следует отметить, что реальные контроллеры ПДП, как правило, могут работать в различных режимах организации ПДП, зачастую комбинированных, поэтому рассмотренная выше классификация способов организации ПДП является весьма условной (особенно ПДП с блокировкой процессора и вариант 2 ПДП с захватом цикла).
Любой способ организации обмена в режиме slave DMA предполагает инициализацию контроллера со стороны процессора. Для этого, как уже отмечалось, перед началом обмена с ПУ в режиме ПДП процессор должен загрузить в регистры контроллера для каждого канала ПДП начальные адреса выделенных областей памяти и их размер в байтах или в словах в зависимости от того, какими единицами информации ведется обмен, направление и режим передачи. Кроме того, если конкретный контроллер это позволяет, программа инициализации должна установить дисциплину обслуживания каналов ПДП (арбитража), а также запрограммировать внутренний таймер, контролирующий время удержания магистрали.
Все изложенное выше справедливо для простейшего варианта обмена – slave DMA, при котором всеми операциями обмена управляет контроллер ПДП. При использовании режима bus master DMA в системах как радиальной, так и цепочечной структуры контроллер ПДП отсутствует. Остается только арбитр магистрали, который также требует инициализации. В зависимости от "интеллектуальности" арбитра его инициализация осуществляется либо вручную с помощью переключателей (перемычек), либо программным путем. В последнем случае инициализация осуществляется либо из встроенного ПЗУ, либо одним из ведущих устройств магистрали при запуске вычислительной системы. Дисциплина арбитража в этом случае остается неизменной на все время функционирования вычислительной системы. Однако если предусмотрена возможность изменения дисциплины арбитража, повторная инициализация арбитра может выполняться в процессе обработки текущей программы процессором одного из ведущих устройств магистрали.
В общем случае СУМ интеллектуальных устройств магистрали, которые могут выступать как master, также требуют инициализации, т.е. загрузки адресов и режимов обмена, размеров передаваемых блоков информации и т.д. Однако во многих случаях master ведет обмен, руководствуясь только потребностями собственного программного обеспечения, записанного в локальное ПЗУ.
Рассмотрим упрощенные алгоритмы организации обмена (захвата магистрали) для обеих структур систем ПДП – радиальной и цепочечной.
В соответствии с рис. 20.1,а все запросы от ИЗПД поступают в арбитр магистрали контроллера ПДП и в общем случае фиксируются там каким-либо образом. Последовательность операций по предоставлению магистрали в распоряжение контроллера ПДП при передаче блока данных в общем случае следующая:
1. Перед началом обмена происходит инициализация контроллера ПДП со стороны процессора. Эта процедура описана выше и здесь не конкретизируется.
2. Процессор продолжает выполнять команды текущей программы до поступления запроса от какого-либо ИЗПД.
3. При возникновении готовности какого-либо из инициализированных ПУ его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр контроллера ПДП.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по любой ЛЗПД) арбитр контроллера ПДП формирует сигнал ОЗПД, который транслируется в процессор. При этом в контроллере инициализируется процедура поиска запроса с максимальным приоритетом, если одновременно поступило несколько запросов. Эта процедура выполняется обычно аппаратным способом, например с помощью дейзи-цепочек или логических схем.
5. Процессор заканчивает операции обмена на магистрали, посылает в контроллер сигнал РПД и отключается от шин системной магистрали. С этого момента шинами системной магистрали управляет контроллер ПДП (master). Кроме того, в контроллере запускается внутренний таймер, контролирующий время удержания магистрали.
6. Блок СУМ контроллера ПДП выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен между ОП и наиболее приоритетным ПУ одним байтом или словом.
7. Блок СУМ контроллера ПДП производит модификацию адреса обмена и счетчика байт.
8. Блок СУМ контролирует размер переданного блока данных. Контроль может происходить как по количеству переданных байтов (слов), так и по конечному адресу области обмена.
9. Блок СУМ контролирует время удержания магистрали контроллером ПДП по внутреннему таймеру.
10. Дальнейшие действия зависят от результатов операций в п. 8 и 9, а именно:
· Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с п. 6.
· Если блок информации передан полностью (обмен закончен), то контроллер ПДП снимает сигнал ОЗПД и освобождает системную магистраль.
· Если время удержания магистрали истекло (хотя обмен и не закончен), то контроллер ПДП освобождает магистраль и снимает сигнал ОЗПД.
11. Процессор продолжает выполнение текущей программы, либо, если запрос уже поступил, начинается процесс обслуживания канала ПДП с меньшим приоритетом (см. операции, начиная с п. 4).
Возможна ситуация, при которой в процессе обслуживания одного из устройств магистрали в арбитр контроллера ПДП поступит запрос от устройства с большим приоритетом. В этом случае контроллер ПДП, не снимая сигнал ОЗПД, прекращает обслуживание устройства с меньшим приоритетом и переключается на обслуживание более приоритетного устройства.
В соответствии с рис. 20.1,б все запросы от ИЗПД поступают в арбитр магистрали (контроллер ПДП отсутствует) и в общем случае фиксируются там каким-либо образом. Следует помнить, что в системе bus master DMA "ЦП" рассматривается как одно из ведущих устройств магистрали со своим приоритетом, т.е. как одно из ИЗПД. Последовательность операций по предоставлению магистрали в распоряжение одного из ведущих устройств (master) для передачи блока информации в общем случае следующая:
1. В начале функционирования вычислительной системы происходит инициализация арбитра и, если это необходимо, СУМ ведущих устройств магистрали. Эта процедура описана выше и здесь не конкретизируется.
2. Полагаем, что вычислительная система функционирует. Процессоры ведущих устройств выполняют команды соответствующих программ и периодически захватывают магистраль для реализации обмена M-S.
3. При возникновении готовности какого-либо из ведущих устройств магистрали его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по любой ЛЗПД) в арбитре магистрали происходит анализ сигналов линий ЛПЗ. Наличие сигнала на любой линии означает, что в текущий момент магистраль занята другим устройством, ведущим обмен. Одновременно выполняется процедура установления приоритета поступившего запроса (или запросов, если их поступило несколько). Пусть наиболее приоритетным оказался запрос от ИЗПДi.
5. Дальнейшие операции зависят от результата анализа линий ЛПЗ (сигналов ПЗ), а именно:
· При отсутствии сигналов ПЗ на линиях ЛПЗ (т.е. свободной магистрали) арбитр выставляет сигнал РПДi на линию ЛРПДi наиболее приоритетного устройства ИЗПДi.
· При наличии сигнала ПЗ на какой-либо из линий ЛПЗ (т.е. занятой магистрали) арбитр сравнивает приоритет устройства, занимающего магистраль, с приоритетом выделенного запроса (т.е. приоритетом ШАрi).
- Если приоритет поступившего запроса ниже, то арбитр ожидает окончание текущего обмена и снятия сигнала ПЗ. После этого арбитр выставляет сигнал РПДi на линию ЛРПДiнаиболее приоритетного устройства ИЗПДi.
- Если приоритет поступившего запроса выше, то арбитр снимает сигнал РПД с линии ЛРПД устройства, ведущего обмен, т.е. запрещает ему bus mastering. Устройство прекращает операции обмена, освобождает магистраль и снимает сигнал ПЗ. Только после этого арбитр выставляет сигнал РПДi на линию ЛРПДi наиболее приоритетного устройства ИЗПДi.
6. Поступление сигнала РПД разрешает устройству bus mastering, т.е. захват магистрали. С этого момента шинами системной магистрали управляет блок СУМ выбранного устройства ИЗПДi (master), который выставляет также сигнал ПЗi. Кроме того, в арбитре или самом ИЗПДi запускается внутренний таймер, контролирующий время удержания магистрали.
7. Блок СУМ устройства ИЗПДi (master) выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен M-S одним байтом или словом.
8. Блок СУМ активного устройства производит модификацию адреса и счетчика байтов.
9. Блок СУМ активного устройства контролирует размер переданного блока данных. Размер блока контролируется обычно по количеству переданных байтов (слов).
10. Контролируется время удержания магистрали устройством, ведущим обмен. Этот контроль может осуществляться как арбитром, так и самим устройством ИЗПДi по встроенному таймеру.
11. Дальнейшие действия зависят от результатов операций в п. 9 и 10, а
именно:
· Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с п. 7.
· Если блок информации передан полностью (обмен закончен), то master освобождает системную магистраль и снимает сигнал ПЗi.
· Если время удержания магистрали истекло (хотя обмен и не закончен), то master освобождает магистраль либо сам, либо после снятия арбитром сигнала РПДi.
12. Начинается процедура захвата магистрали ведущим устройством с меньшим приоритетом (организация канала M-S), если запрос в арбитр уже поступил (см. операции, начиная с пункта 4).
Следует отметить, что в общем случае возможны системы bus master DMA радиальной структуры, в которых арбитр выступает как подчиненное устройство по отношению к ЦП. В этом случае перед предоставлением магистрали в распоряжение какого-либо ИЗПД арбитр запрашивает ЦП, монопольно использующий магистраль, т.е. как в случае slave DMA. Однако этот вариант DMA в настоящем разделе не рассматривается.
В соответствии с рис. 20.2 к каждой ШАр (входу арбитра) может быть подключено множество запросчиков ИЗПД. Сигнал РПД распространяется по цепочке ИЗПД, подключенных к одной ЛЗПД (к одной ШАр). Распространение этого сигнала блокируется ИЗПД, выставившим запрос. Пусть это будет ИЗПДi, подключенный к ЩАрn (см. рис. 20.3). Получив сигнал РПД, блок СУМ ИЗПДn,i захватывает магистраль и начинает ею управлять. Таким образом, приоритет подключенных к одной ЛЗПД устройств определяется положением ИЗПД в цепочке распространения сигнала РПД. Это исключает необходимость выполнения процедуры поиска запроса с максимальным приоритетом среди ИЗПД, подключенных к одной ЛЗПД.
Если ШАр несколько, что обычно имеет место в реальных системах bus master DMA цепочечной структуры, в арбитре выполняется процедура поиска возбужденной ЛЗПД с максимальным приоритетом, которая аналогична процедуре поиска запроса с максимальным приоритетом в системе радиальной структуры.
На основании вышеизложенного можно записать обобщенную последовательность основных операций по предоставлению магистрали в распоряжение ведущего устройства (master) для передачи блока информации:
1. В начале функционирования вычислительной системы происходит инициализация арбитра и, если это необходимо, СУМ ведущих устройств магистрали. Эта процедура описана выше и здесь не конкретизируется.
2. Полагаем, что вычислительная система функционирует. Процессоры ведущих устройств выполняют команды соответствующих программ и периодически захватывают магистраль для реализации обмена M-S.
3. При возникновении готовности какого-либо из ведущих устройств магистрали его запросчик вырабатывает сигнал ЗПД, поступающий по соответствующей ЛЗПД в арбитр.
4. При поступлении запроса от любого ИЗПД (т.е. сигнала ЗПД по ЛЗПД любой ШАр) в арбитре магистрали происходит анализ сигналов линий ЛПЗ. Наличие сигнала на любой линии означает, что в текущий момент магистраль занята другим устройством, ведущим обмен. Одновременно выполняется процедура установления приоритета ШАр, с которой поступил запрос (или запросы, если их поступило несколько). Пусть наиболее приоритетным оказался запрос по ШАрn.
5. Дальнейшие операции зависят от результата анализа линий ЛПЗ (сигналов ПЗ), а именно:
· При отсутствии сигналов ПЗ на линиях ЛПЗ (т.е. свободной магистрали) арбитр выставляет сигнал РПДn на линию ЛРПДn наиболее приоритетной ШАр.
· При наличии сигнала ПЗ на какой-либо из линий ЛПЗ (т.е. занятой магистрали) арбитр сравнивает приоритет устройства, занимающего магистраль, с приоритетом выделенного запроса (т.е. приоритетом ШАрn):
- Если приоритет поступившего запроса ниже, то арбитр ожидает окончание текущего обмена и снятия сигнала ПЗ. После этого арбитр выставляет сигнал РПДn на линию ЛРПДn наиболее приоритетной ШАрn.
- Если приоритет поступившего запроса выше, то арбитр выставляет сигнал БПД на линии ЛБПД ШАр, т.е. запрещает активным устройствам магистрали bus mastering. Устройство прекращает операции обмена, освобождает магистраль и снимает сигнал ПЗ. Только после этого арбитр выставляет сигнал РПДn на линию ЛРПДn наиболее приоритетной ШАрn.
6. Поступление сигнала РПДn разрешает устройствам ШАрn bus mastering, т.е. захват магистрали. Распространение сигнала РПДn блокируется устройством ИЗПДn,i, выставившим запрос. С этого момента шинами системной магистрали управляет блок СУМ выбранного устройства ИЗПДn,i (master), который выставляет также сигнал ПЗn,i. Кроме того, в арбитре или самом ИЗПДn,i запускается внутренний таймер, контролирующий время удержания магистрали.
7. Блок СУМ активного устройства магистрали (master) выставляет адрес обмена и управляющие сигналы, инициализирующие обмен. Результатом этой операции является обмен M-S одним байтом или словом.
8. Блок СУМ активного устройства производит модификацию адреса и счетчика байт.
9. Блок СУМ активного устройства контролирует размер переданного блока данных. Размер блока контролируется обычно по количеству переданных байтов (слов).
10. Контролируется время удержания магистрали устройством, ведущим обмен. Этот контроль может осуществляться как арбитром, так и самим устройством ИЗПДn,i по встроенному таймеру.
11. Дальнейшие действия зависят от результатов операций в п. 9 и 10, а
именно:
· Если обмен не закончен и время удержания магистрали не истекло, то происходит повторение операций, начиная с п. 7.
· Если блок информации передан полностью (обмен закончен), то master освобождает системную магистраль и снимает сигнал ПЗn,i.
· Если время удержания магистрали истекло (хотя обмен и не закончен), то master освобождает магистраль либо сам, либо после выставления арбитром сигнала БПД, который запрещает активным устройствам магистрали bus mastering.
12. Начинается процедура захвата магистрали ведущим устройством с меньшим приоритетом (организация канала M-S), если запрос в арбитр уже поступил (см. операции, начиная с п. 4).
В простых системах bus master DMA цепочечной структуры может присутствовать только одна ЛЗПД. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали. Такие системы bus master DMA являются наиболее динамичными, даже при достаточно большом количестве ИЗПД.
Нормальное функционирование системы ПДП любой структуры очень во многом зависит от правильного выбора дисциплины обслуживания устройств магистрали, т.е. от правильного выбора системы приоритетных соотношений. Особенно остро эта проблема стоит в вычислительных системах, использующих bus mastering, поскольку общая производительность системы существенно зависит от равномерности загрузки всех ведущих устройств магистрали. Последнее можно обеспечить только рациональным выбором дисциплины арбитража (в дальнейшем просто арбитража). Существуют многочисленные варианты арбитража, каждый из которых имеет свои преимущества и недостатки, причем ни один из них не может быть назван идеальным для любых вычислительных систем. Оптимальный вариант арбитража всегда зависит от конкретной конфигурации вычислительной системы и ее целевого назначения, типа используемых процессоров, конфигурации и назначения ведущих устройств магистрали, способов взаимодействия с системой прерывания и многих других факторов. Способ арбитража определяет и название арбитра, используемого в конкретной вычислительной системе.
Наиболее популярными вариантами арбитров в настоящее время являются: одноуровневый, с фиксированными приоритетами, с циклическим изменением приоритетов, круговой. Рассмотрим их более подробно.
Одноуровневый арбитр
Это простейший вариант арбитра, который используется в простых системах bus master DMA цепочечной структуры, изображенной на рис. 20.3. В соответствии со своим названием он обслуживает только один уровень запроса и предоставляет магистраль, используя одну линию ЛРПД, т.е. в системе используется только одна ШАр. В этом случае отпадает необходимость выполнения процедуры поиска возбужденной ЛЗПД с максимальным приоритетом. Отпадает необходимость и в отдельном арбитре магистрали, поэтому термин "одноуровневый арбитр" не совсем уместен, так как реальным арбитражем он не занимается. Каждое ИЗПД само принимает решение принимать или пропускать сигнал РПД. Такие системы bus master DMA, как уже отмечалось, являются наиболее динамичными, даже при достаточно большом количестве ИЗПД, и могут быть построены с минимальной аппаратной поддержкой.
Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, расположенные в слотах с малыми номерами, т.е. близкие к слоту "0".
Арбитр с фиксированными приоритетами
Это также достаточно простой вариант арбитра, который предполагает, что за каждым входом ШАр (система bus master DMA) или ЛЗПД (система slave DMA) закреплен определенный уровень приоритета, который не может быть изменен в процессе обслуживания устройств магистрали. В большинстве случаев количество входов в арбитр или контроллер ПДП не превышает 4-8. Для увеличения количества входов, особенно в контроллерах систем slave DMA, обычно допускается их каскадное включение. Основной недостаток такого арбитра состоит в том, что постоянное преимущество в использовании магистрали имеют устройства, использующие вход арбитра с максимальным приоритетом.
Арбитр с циклическим изменением приоритета
Этот вариант арбитра является развитием варианта арбитра с фиксированными приоритетами. Алгоритм функционирования такого арбитра состоит в следующем. Пусть арбитр имеет четыре входа, к которым подключены четыре ШАр – ШАр0, ШАр1, ШАр2, ШАр3. После инициализации входам арбитра присваиваются фиксированные приоритеты (например, ШАр0 – высший, а ШАр3 – низший). Однако после обслуживания устройств одной из ШАр ей автоматически назначают низший приоритет, а приоритеты остальных ШАр изменяются в круговой последовательности. Например, после обслуживания ШАр2приоритеты остальных ШАр убывают в таком порядке: ШАр3, ШАр0, ШАр1, ШАр2. Такой режим позволяет выровнять приоритеты всех ШАр и не допустить преимущественное использование магистрали устройствами одной ШАр. Возможны и другие схемы выравнивания приоритетов.
Основной недостаток такого арбитра состоит в том, что невозможно жестко зафиксировать наивысший приоритет какой-либо ШАр или устройства.
Круговой арбитр
Этот вариант арбитра предоставляет равный приоритет всем ШАр, подключенным к его входам. Пусть, как и в предыдущем случае, к арбитру подключены четыре ШАр. Тогда арбитр предоставляет магистраль в распоряжение устройств каждой ШАр на основе круговой диспетчеризации подобно круговому переключателю на четыре позиции. После запуска вычислительной системы "переключатель" может установиться либо на фиксированную, либо на случайную позицию (вход ШАр). Все зависит от конкретной технической реализации арбитра. Пусть это будет вход ШАр0. Когда одно из ведущих устройств ШАр0 осуществит обмен и освободит магистраль, "переключатель" повернется на следующую позицию и предоставит возможность захвата магистрали ведущим устройствам ШАр1. Если на входе ШАр1 его не ожидает запрос, арбитр пропустит этот вход и переключится на следующий, т.е. на вход ШАр2. Таким образом, ведущие устройства всех ШАр обеспечиваются равными правами на захват магистрали.
Основной недостаток такого арбитра аналогичен предыдущему.
Рассмотренные выше варианты, как уже отмечалось, не исчерпывают всего многообразия арбитров, используемых в реальных вычислительных системах. Кроме того, следует помнить, что многие арбитры являются сложными перепрограммируемыми устройствами и могут, после соответствующей инициализации, поддерживать не только различные варианты арбитража, но и использовать комбинированные варианты, наиболее оптимальные для конкретной вычислительной системы.
Упрощенная структурная схема вычислительного устройства на базе МП I8080 (КР580ВМ80А) представлена на рис. 20.4. Это простейшая микро-ЭВМ минимальной конфигурации, структура которой является частным случаем обобщенной (см. рис. 18.1).
Представленная схема включает все основные функциональные блоки, за исключением источника питания. ПЗУ может быть использовано для хранения программы, а ОП для хранения данных, поступающих от ПУ (через ППУ), а также результатов работы программы. Предполагается, что ОП и ПЗУ охвачены единым полем адресов.
К шинам адреса и данных системной магистрали, даже в простейшей микро-ЭВМ, подключено достаточно много устройств: ОП, ПЗУ, несколько ППУ. Однако нагрузочная способность выходов МП КР580, в силу технологических особенностей, весьма мала. К любому выходу МП допускается подключать не более одного входа микросхемы ТТЛ, поэтому в шины адреса и данных включаются специальные буферы, причем ШД требует двунаправленного буфера. Для построения таких буферов предусмотрены микросхемышинных формирователей КР580ВА86 и КР580ВА87.
Общие принципы функционирования микропроцессорной системы следующие. Из МП на ША (16 разрядов) выдается адрес очередной команды. В этот момент МП еще «не знает», сколько байт занимает данная команда. Первый байт команды, выбранный из памяти (в частном случае из ПЗУ), пересылается по внутренней ШД в РгК. Выход РгК связан с дешифратором команд, который определяет тип выполняемой операции. При этом к содержимому СчК добавляется 1, т.е. формируется адрес следующего байта, а УУ вырабатывает ряд сигналов, позволяющих выполнить те или иные микрооперации. После этого возможны два варианта дальнейших действий:
· Если команда однобайтовая, то она выполняется, а содержимое счетчика адреса (РС) = (РС) + 1 является адресом следующей команды.
· Если команда содержит более одного байта (2 или 3) и для ее выполнения требуется вызов дополнительных байтов, то содержимое счетчика адреса команд (РС) = (РС) + 1 является адресом следующего байта той же команды.

Рис.20.4. Упрощенная структурная схема микропроцессорной системы на базе МП КР580ВМ80
Рассмотрим более подробно процесс выполнения команды. Этот процесс разбивается намашинные циклы, которые обозначаются M1...M5. Число циклов в одной команде может быть от одного до пяти. В свою очередь, каждый машинный цикл состоит из тактов, обозначаемых T1...T5. В одном машинном цикле может быть от трех до пяти тактов. Имеется в виду 5 типов тактов, поскольку в каждом такте выполняется определенное действие по реализации машинного цикла. При этом количество тактов как временных интервалов может быть значительно больше за счет тактов Т2, о чем речь пойдет ниже. В каждом машинном цикле производится одно обращение к памяти или ППУ в разных вариантах. Каждый такой вариант обращения называется состоянием цикла. Всего в МП КР580 возможно 10 состояний машинного цикла. Это выборка первого байта команды, чтение из памяти, запись в память, чтение из стека, запись в стек, ввод из ППУ, вывод через ППУ, подтверждение прерывания, подтверждение останова, подтверждение прерывания при останове. При этом первым машинным циклом любой команды всегда является выборка первого байта команды.
Во всех машинных циклах первые три такта (T1,T2,T3) используются для организации обмена с памятью и ППУ. Такты T4 и T5 (если они есть) – для выполнения внутренних операций в МП. Таким образом, процесс выполнения команд состоит из стольких машинных циклов, сколько обращений к памяти или ППУ требуется для ее исполнения.

Рис.20.5. Временная диаграмма цикла М1
На рис. 20.5 представлена временная диаграмма цикла М1 из пяти тактов (первый машинный цикл любой команды). Отсчет тактов производится от положительных фронтов импульса F1. Действия процессора по реализации машинного цикла М1 состоят в следующем:
T1 – содержимое РС выдается на ША, адрес принимается памятью, где начинается чтение байта команды из ячейки.
T2 – проверяется наличие сигнала на входе READY (уровень логической 1). Этот сигнал подается на вход МП через интервал времени, достаточный для завершения процесса чтения из памяти. Если на входе READY сигнал отсутствует (действует логический 0), то МП устанавливается в режим ожидания, в котором каждый следующий такт рассматривается как T2 до тех пор, пока не появится сигнал READY. С приходом этого сигнала МП выходит из режима ожидания и переходит в такт T3.
T3 – байт с ШД принимается в МП и помещается в регистр команд (РгК).
T4 – происходит анализ принятого байта и выяснение потребности в дополнительном обращении к памяти. Если дополнительных обращений не требуется (команда однобайтовая и операнды находятся в регистрах процессора), то в этом же такте или с использованием дополнительного такта T5 выполняются предусмотренные командой микрооперации.
T5 – дополнительный такт.
Если требуется дополнительное обращение к памяти, то после T4 цикл M1 завершается и происходит переход к циклу M2.
Отметим, что КОП всегда находится в первом байте команды. Если команда двух- или трехбайтовая, то в остальных байтах находятся данные или адрес. Содержимое этих байтов помещается в аккумулятор или буферные регистры. Так, например, в команде MOV (запись аккумулятора в ячейку памяти) двухбайтовый адрес, который следует за КОП, помещается в регистровую пару WZ, а затем, при исполнении, он передается через мультиплексор непосредственно в РА и далее через буфер на ША.
В каждом машинном цикле в такте T1 по переднему фронту F2 МП выдает сигнал синхронизации SYNC, т.е. на выходе SYNC появляется уровень логической 1. Одновременно с этим сигналом в такте T1 МП выставляет на ШД 8-разрядноеуправляющее слово, которое несет в себе полную информацию о микрооперациях в текущем машинном цикле. Так, например, 1 в разряде D0 управляющего слова является сигналом подтверждения прерывания INTA. Наличие 1 в разряде D2 означает, что в данном машинном цикле на ША установлено содержимое указателя стека (регистр SP). Наличие 1 в разряде D3 означает, что МП в состоянии останова. В момент прихода импульса F1, означающего начало такта T2, на схеме "&" (рис. 14.6) вырабатывается импульс, называемый строб состояния. Этот строб разрешает запись управляющего слова с ШД во внешний регистр, названный на схеме фиксатор состояния.
Используя это слово или его часть, специальные логические схемы вырабатывают системные управляющие сигналы для обращения к памяти и ППУ. В общем случае фиксатор состояния и блок логических схем называются системным контроллером. Эти, а также некоторые другие вспомогательные схемы, в частности шинный формирователь, оформлены в виде специальной БИС КР580ВК28. Однако в простейших микроЭВМ часто требуются только 4 управляющих сигнала – R, W, IN, OUT. В связи с этим необходимость в БИС ВК28 отпадает, а используют какой-либо управляемый регистр и 2-3 логические схемы.
1. Принципы организации систем прямого доступа в память.
2. Способы организации доступа к системной магистрали при ПДП.
3. Возможные структуры систем ПДП.
4. Обобщенная цепочечная структура системы Bus Master DMA.
5. Структура шины арбитража ”n” системы bus master DMA цепочечного типа.
6. Организация обмена в режиме ПДП.
7. Принципы организации арбитража магистрали.
8. Упрощенная структурная схема микропроцессорной системы на базе МП КР580ВМ80.
Надеюсь, эта статья про прямой доступ в память, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое прямой доступ в память и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Компьютерная схемотехника и архитектура компьютеров
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Компьютерная схемотехника и архитектура компьютеров
Термины: Компьютерная схемотехника и архитектура компьютеров