Лекция
Привет, сегодня поговорим про встраивание в плис блоков, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое встраивание в плис блоков , настоятельно рекомендую прочитать все из категории Компьютерная схемотехника и архитектура компьютеров.
Ключевой особенностью современных ПЛИС является то, что они содержат специальную логику и внутренние соединения, необходимые для реализации схем ускоренного переноса. Эта логика дополняется специальными внутренними соединениями между логическими ячейками в пределах каждой секции, между секциями в рамках каждого КЛБ и между КЛБ.
Специальная логика быстрого переноса и выделенная маршрутизация способствует выполнению логических функций, таких как счетчики, сумматоры и т.п. Возможности схем ускоренного переноса совместно с возможностями других средств, аналогичных сдвиговым регистрам на основе таблиц соответствия, встроенным умножителям и другим блокам обеспечивают необходимый набор средств для использования ПЛИС в приложениях цифровой обработки сигналов (ЦОС).
В процессе реализации большинства приложений возникает необходимость использовать ячейки памяти, поэтому современные ПЛИС содержат довольно большие блоки встроенной памяти, называемые блоками встроенного ОЗУ. В зависимости от архитектуры микросхемы эти блоки могут быть расположены по периметру кристалла, разбросаны по его поверхности и относительно изолированы друг от друга или организованы в столбцы, как показано на рис.8.1.
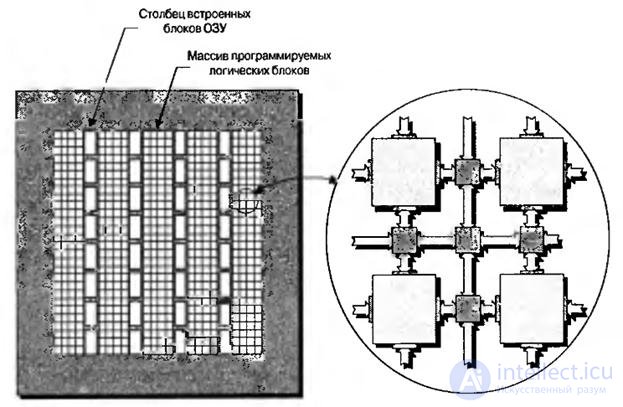
Рис.8.1. Вид на кристалл ПЛИС со столбцами встроенных блоков ОЗУ
В зависимости от устройства размер блоков ОЗУ может меняться от нескольких тысяч до нескольких десятков тысяч бит. Каждая микросхема может содержать от нескольких лесятков до нескольких сотен таких блоков. Таким образом, полная емкость простирается от нескольких сотен тысяч бит до нескольких миллионов бит.
Каждый блок ОЗУ может использоваться либо как независимое запоминающее устройство, либо находиться в связке с несколькими блоками для реализации массивов памяти большого объема. Блоки могут использоваться для различных целей, например, как стандартные одно- и двух-портовые ОЗУ, очереди FIFO (first-in first-out – первый пришел, первый вышел), конечные автоматы и так далее.
Некоторые типы функций, например умножители, по своей сути являются довольно медленными, если их реализовывать с помощью большого количества программируемых логических блоков, соединенных вместе. Поскольку эти блоки используются в многочисленных приложениях, многие ПЛИС содержат специальные аппаратные блоки умножения. Эти блоки обычно расположены в непосредственной близости от блоков встроенного ОЗУ, так как они часто используются вместе (рис.8.2).
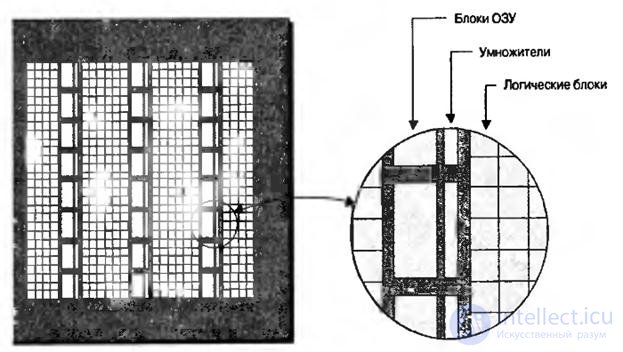
Рис.8.2. Вид на кристалл со столбцами встроенных умножителей и блоков ОЗУ
Некоторые производители ПЛИС также предлагают выделенные сумматоры. В то же время, одной из самых распространенных операций, применяемых в приложениях цифровой обработки сигналов, является умножение с накоплением (multiply-and-accumulate или MAC ), рис.8.3. Как подсказывает название, эта функция перемножает два числа и суммирует результат с текущим числом, сохраненным в аккумуляторе
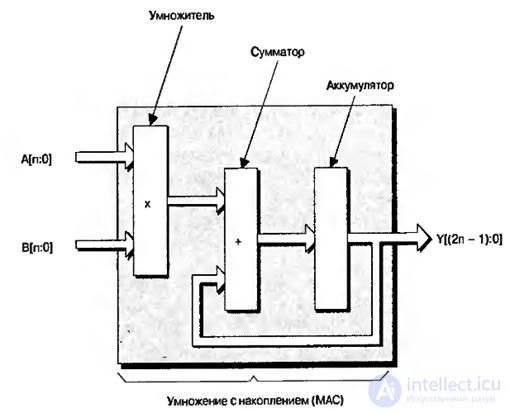
Рис.8.3. Функции, формирующие операцию умножения с накоплением
При работе с ПЛИС, которая содержит только встроенные умножители, для реализации этой функции необходимо соединить умножитель с сумматором, сформированным из нескольких программируемых логических блоков. Результат будет сохраняться в триггерах логических блоков, либо в блоках встроенного ОЗУ.
Важной особенностью ПЛИС является то, что в них почти все части электронного устройства могут быть реализованы аппаратно ( с использованием логических вентилей, регистрой и т.п.) или программно (в виде инструкций микропроцессора). Одним из главных частных критериев выбора между аппаратной и программной реализацией функции является время, за которое эта функция должна выполнить свои задачи:
· Пикосекундная или наносекундная логика – должна работать исключительно быстро и в структуре реализуется аппаратно.
· Микросекундная логика – умеренно быстрая и может реализовываться как аппаратно, так и программно.
· Миллисекундная логика – используется при реализации интерфейсов, таких как опрос состояний переключателей или зажигание светодиодов. Основные усилия направлены на замедление аппаратной части при реализации этих функций, например, используя громаднейшие счетчики для генерации задержек. Зачастую такие задачи лучше реализовывать на микропроцессоре.
Фактически большинство устройств в той или иной форме использует микропроцессоры. В настоящее время выпускаются ПЛИС, которые содержат один или несколько встроенных микропроцессоров, которые обычно называют микропроцессорными ядрами. При применении таких ПЛИС часто имеет смысл переложить все задачи, выполняемые внешним микропроцессором, на встроенное микропроцессорное ядро. Такой подход обеспечивает ряд преимуществ, не последними из которых будут снижение стоимости, устранение большого количества дорожек, посадочных мест и выводов на печатной плате, а также уменьшение размера и веса печатной платы.
Различают аппаратную и программную реализацию микропроцессорных ядер.
Аппаратные микропроцессорные ядра изготавливаются как отдельные предопределенные блоки. Существуют два способа интеграции таких ядер в ПЛИС. Первый предусматривает расположение ядра в виде полосы ( полоса – stripe) вдоль одной из сторон главной части, или главной структуры ПЛИС (рис.8.4). При таком подходе все компоненты обычно формируются на одном кремниевом кристалле. Главная часть ПЛИС также включает встроенные блоки ОЗУ, умножители и другие блоки.
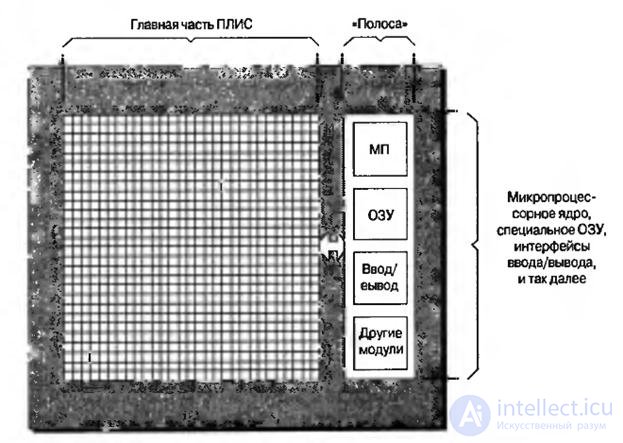
Рис.8.4. Вид на кристалл со встроенным ядром, находящимся за пределами главной части
Преимущество такой реализации проявляется в главной части ПЛИС, которая получается идентичной для устройств со встроенным и без встроенного микропроцессорного ядра. Это может существенно упростить работу инженеров со средствами разработки. Другое преимущество заключается в том, что поставщики ПЛИС могут связать все дополнительные функции, такие как память, устройства ввода-вывода и другие, в одну полосу для дополнения микропроцессорного ядра.
Вторым способом интеграции является встраивание одного или более микропроцессорных ядер прямо в главную часть ПЛИС (рис.8.5)
При использовании этого способа используемые средства проектирования должны учитывать присутствие микропроцессоров в структуре микросхемы. Память, используемая ядром, формируется из встроенных блоков ОЗУ, а любые функции сопряжения реализуются с помощью групп программируемых логических блоков общего назначения. Сторонники этой схемы утверждают, что размещение микропроцессорного ядра в непосредственной близости к главной части ПЛИС обеспечивает ей преимущество в скорости.

Рис.8.5. Вид на кристаллы с ядрами, встроенными в главную часть
Кроме физического встраивания микропроцессора в структуру кристалла, можно сконфигурировать группу программируемых логических блоков для работы в качестве микропроцессора. Такую группу обычно называют программным ядром. Программные ядра проще и медленнее, чем их аппаратные аналоги. Однако у них есть одно преимущество – при необходимости можно реализовать ядро или несколько ядер в том объеме, который можно достичь пока не будут исчерпаны все ресурсы в виде программируемых логических блоков.
Все синхронные элементы внутри ПЛИС, например, регистры внутри программируемого логического блока, сконфигурированные для работы в виде триггеров, необходимо синхронизировать с помощью тактового сигнала. Тактовые сигналы обычно вырабатываются за пределами микросхемы и поступают в нее через специальные входы синхронизации, а затем распределяются через специальные устройства и подаются на соответствующие регистры.
Рассмотрим упрощенное изображение дерева синхронизации (рис.8.6, программируемые логические блоки не показаны).
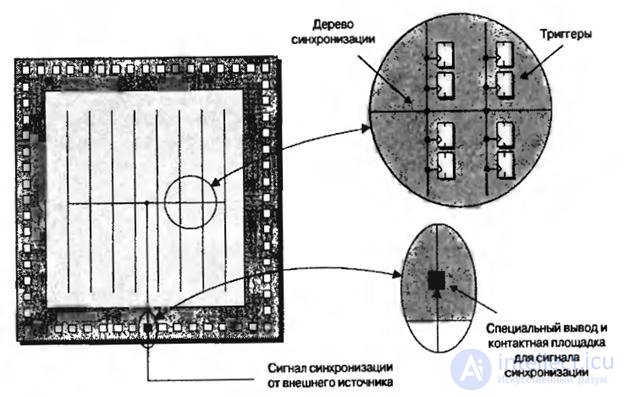
Рис.8.6. Об этом говорит сайт https://intellect.icu . Простое дерево синхронизации
Название ”дерево синхронизации”возникло потому, что главный синхросигнал разветвляется подобно ветвям дерева, при этом триггеры могут рассматриваться как “листья” на концах веток. Такая структура вселяет уверенность в том, что все триггеры увидят свои тактовые сигналы одновременно, на сколько это возможно. Если бы тактовые сигналы распространялись по одному длинному проводнику, синхронизируя все триггеры поочередно, триггер, расположенный ближе к выводу синхронизации микросхемы увидел бы синхроимпульс немного раньше, чем последние триггеры в этой цепочке. Подобная ситуация называется фазовым сдвигом, и она порождает целый ряд проблем. Даже при использовании дерева синхронизации может возникнуть некоторый сдвиг фаз между регистрами, находящимися на одной ветви, а также между ветвями.
Дерево синхронизации реализуется с помощью специальных проводников, которые отделены от внутренних соединений общего назначения. Принцип действия, рассмотренный выше, на самом деле сильно упрощен. На практике в микросхемах существует множество выводов синхронизации ( неиспользуемые выводы синхронизации могут быть использованы как выводы общего назначения), а внутри устройства имеются множественные домены синхронизации ( деревья синхронизации).
Вывод синхронизации микросхемы может быть подключен к дереву синхронизации. Однако, как правило, этот вывод подключают не напрямую к дереву синхронизации, а к входу устройства ( или блока) управления синхронизацией, называемого диспетчером синхронизации, который генерирует дочерние тактовые сигналы ( рис.8.7).
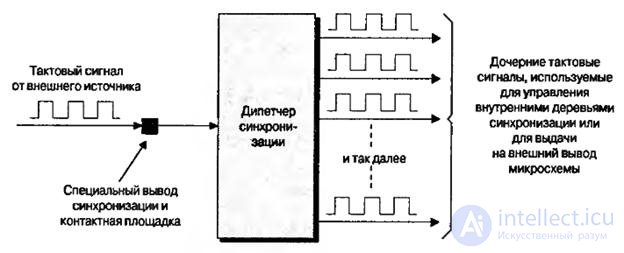
Рис.8.7. Диспетчер синхронизации, генерирующий дочерние тактовые сигналы
Дочерние тактовые сигналы могут использоваться для управления внутренними деревьями ( доменами) синхронизации или для выдачи сигналов на внешние выводы микросхемы, которые, в свою очередь, можно использовать для синхронизации других устройств, расположенных на печатной плате. Каждое семейство микросхем ПЛИС располагает собственным типом диспетчера синхронизации, и в одном устройстве могут находиться множество модулей диспетчера синхронизации. Различные диспетчеры синхронизации могут поддерживать все или только некоторые из следующих устройств, выполняющих функции:
– устранение флуктуаций,
– частотный синтез,
– фазовый сдвиг,
– автокоррекция сдвига фаз.
–
С развитием ПЛИС на основе ячеек статического ОЗУ в электронике появились новые возможности, связанные с динамически рекофигурируемой логикой. Имеются в виду устройства, которые могут реконфигурироваться на лету в процессе работы системы.
ПЛИС содержит большое количество программируемых логических элементов и регистров, которые могут быть соединены разными способами для реализации различных функций. Примечательно, что компоненты на базе ячеек статического ОЗУ позволяют системе загружать в устройство новые конфигурационные данные. Хотя все логические вентили, регистры и ячейки статической памяти, из которых состоит ПЛИС, созданы на поверхности одного кремниевого кристалла, иногда полезно рассматривать это устройство как состоящее из двух отдельных частей – логических вентилей ( и регистров) и программируемых конфигурационных ячеек статического ОЗУ (рис.8.8).
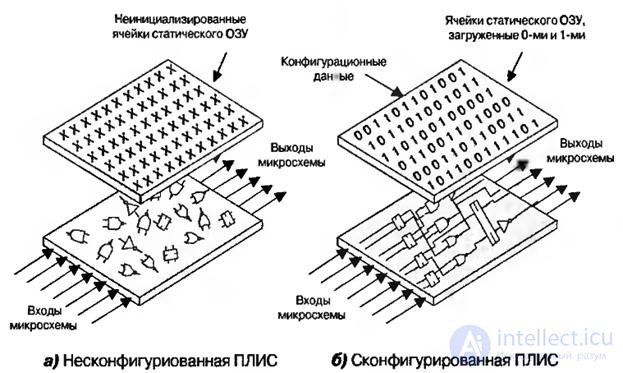
Рис.8.8. Динамически реконфигурируемая логика: ПЛИС на основе ячеек статического ОЗУ
Гибкость реконфигурируемых устройств открывает поистине широкие возможности. Например, при включении питания ПЛИС может быть сконфигурирована для тестирования системы или самотестирования. Как только система завершает тестирование, ПЛИС вновь может быть переконфигурирована для выполнения своих основных функций.
Безусловно, возможность переконфигурировать функции отдельных узлов на печатной плате предоставляет дополнительные удобства для инженеров, но иногда им необходимо создавать ыелые системы, которые могут быть переконфигурированы на уровне печатной платы для выполнения различных, радикально отличающихся функций.
Для решения этой задачи необходимо конфигурировать соединения между устройствами на уровне печатной платы. Справиться с такой задачей могут так называемые программируемые пользователем устройства внутренних соединений ( или FPID – field-programmable interconnect devices), которые также известны как программируемые пользователем кристаллы внутренних соединений ( или FPIC – field-programmable interconnect chips). Эти микросхемы, применяемые для для соединения логических устройств, могут быть динамически переконфигурированы таким же образом, как и стандартные ПЛИС на основе ячеек статического ОЗУ. Так как каждая микросхема FPID может содержать более 1000 контактов, для соединения компонентов на печатной плате может понадобиться всего лишь несколько таких микросхем (рис.8.9).
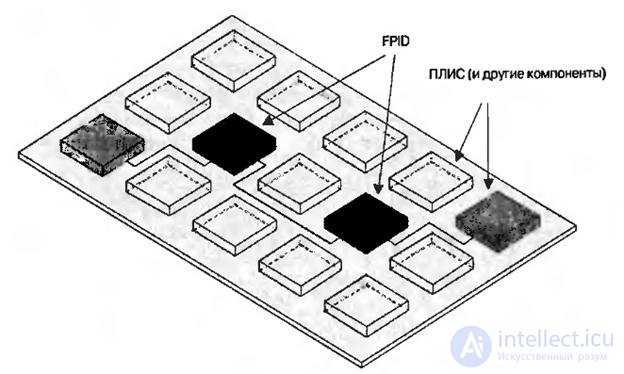
Рис.8.9. Динамически реконфигурируемые соединения: FPID на основе ячеек статического ОЗУ
Интересно, что описанный подход не ограничивается только применением на уровне печатных плат. Любой из вышеописанных подходов потенциально может быть использован и в гибридных микросхемах, и в многокристальных модулях, и в однокристальных устройствах.
Одним из ограничивающих факторов для большинства ПЛИС на основе ячеек статического ОЗУ является необходимость затрачивать определенное время на переконфигурацию. Эта особенность вызвана тем, что ПЛИС обычно программируется с помощью последовательной загрузки данных ( или параллельной загрузки данных шириной всего лишь 8 бит). Когда речь идет о высокотехнологичных устройствах с десятками миллионов конфигураций ячеек статической памяти, на перепрограммирование может уйти несколько секунд. Существуют некоторые типы ПЛИС, которые решают эту проблему путем использования большого количества контактов ввода/вывода общего назначения, которые в процессе программирования образуют широкую шину конфигурации ( скажем, 256 бит), а после конфигурирования возвращаются к выполнению своих основных функций.
Другой недостаток ПЛИС традиционной архитектуры состоит в том, что при необходимости внести самые незначительные изменения в конфигурацию приходится перепрограммировать целиком все устройство. Некоторые ПЛИС позволяют переконфигурировать их по столбцам, но и в этом случае обеспечивается весьма грубый уровень структурирования. Кроме того, на время конфигурирования обычно приходится приостанавливать работу всей печатной платы. Также при программировании безвозвратно теряется содержимое всех регистров ПЛИС.
Длярешения этих проблем, примерно в 1994 году компания Atmel Corporation (www.atmel.com) предложила ряд интересных ПЛИС. Кроме поддержки динамической реконфигурации выбранных элементов внутренней логики, эти устройства характеризуются тем, что:
– не нарушается работа входов и выходов устройства,
– не нарушается работа средств синхронизации системы,
– любые части устройства, не подверженные реконфигурации, могут продолжать свою работу,
– не теряется информация внутренних регистров, даже тех, которые находятся в области реконфигурирования.
Особенный интерес представляет последний пункт этого списка, так как позволяет одной реализации функции передавать данные для другой. Например, группа регистров изначально может быть запрограммирована для работы в качестве двоичного счетчика. Затем в какой-то момент времени, определяемый главной системой, те же регистры могут быть переконфигурированы для работы в качестве линейного сдвигового регистра, начальное значение которого определяется последним содержимым счетчика до реконфигурирования.
Хотя эти устройства стали очередным эволюционным шагом в технологическом плане, с точки зрения их потенциальных возможностей шаг оказался поистине революционным. Для оценки этих возможностей были введены такие новые термины, как виртуальное программное обеспечение и кэш-логика.
Понятие “виртуальное программное обеспечение” возникло по аналогии с его программным эквивалентом – “виртуальной памятью”. Оба этих термина используются для представления предметов, которых на самом деле не существует. В случае виртуальной памяти компьютерная операционная система делает вид, что ей доступно больше оперативной памяти, чем есть на самом деле. Каждый раз, когда программа пытается получить доступ к ячейкам памяти, которых физически не существует, операционная система хитрит и меняет часть данных, находящихся в памяти, с данными, рамположенными на жестком диске. Хотя эта процедура, известная, как ”свопинг”, замедляет процесс обработки данных, но в то же время позволяет программе выполнять свои задачи при меньшем объеме физичекой памяти.
Аналогично термин ”кэш-логика” произошел от родственного ему понятия кэш-памяти, которая представляет собой высокоскоростную дорогостоящую статическую память для хранения текущих активных данных, в то время как основная часть данных помещается в более медленную недорогую память, например, в динамическую (DRAM).
Отслеживая местоположение и обращение к каждой микрофункции, а также объединяя функциональность и исключаяизбыточность, устройства с виртуальной аппаратной частью могут выполнять гораздо более сложные задачи, чем устройства, построенные по классической схеме. Например, в сложных функциях, требующих 100000 эквивалентных вентилей, в отдельный момент времени из них могут быть активными только 10000. Следовательно, с помощью сокращения или кэширования можно реализовать еще функций на 90000 логических элементов. Тем самым небольшое и недорогое устройство с 10000 логическими элементами может заменить большое и дорогое со 100000 элементами (рис.8.10).
Таким образом возможно в реальном масштабе времени компилировать новые варианты устройств, которые могут быть использованы как динамически создаваемые аппаратные подпрограммы.
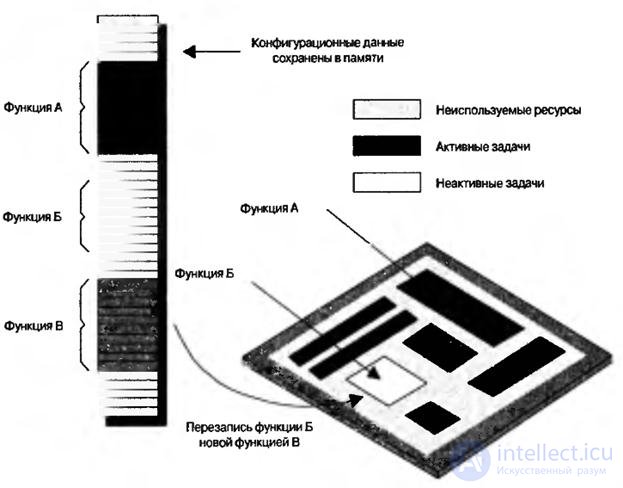
Рис.8.10. Виртуальное программное обеспечение
ПЛИС, классифицируемые как программируемые пользователем массивы узлов ( или FNPA – field-programmable node array), построены по крупномодульной архитектуре. Основополагающая концепция этих устройств состоит в том, что они сформированы из массива ”узлов”, каждый из которых является сложным элементом обработки данных (рис.8.11).
На рис.8.11 показано довольно упрощенное представление FPNA-устройства не только потому, что на нем не приведены элементы ввода/вывода и показано небольшое количество узлов обработки, хотя такое устройство может содержать сотни и тысячи подобных устройств. В зависимости от поставщика FPNA каждый узел может представлять собой арифметико-логическое устройство (АЛУ), микропроцессор или элемент алгоритмической обработки.
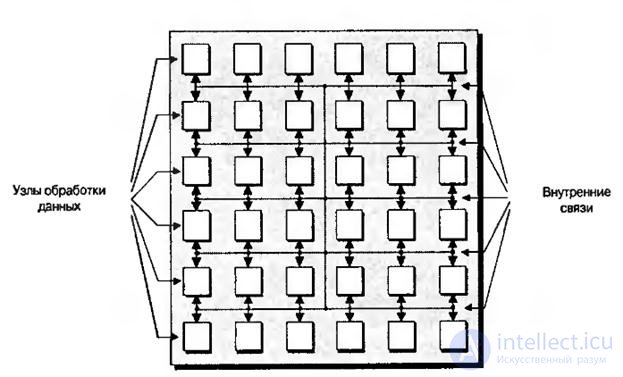
Рис.8.11. Общее представление устройства FPNA
Разработками в этом направлении занимается большое количество компаний. Далее будет рассмотрена продукция только двух копаний – PicoChip и QuickSilver, чьи концепции диаметрально противоположны.
Устройства picoArray компании picoChip формируются из массива процессоров и, в основном, предназначены для больших, не критичных к величине энергопотребления, стационарным системам, к которым относятся, например, базовые станции для беспроводных сетей. Кроме того, эти устройства при необходимости в любой момент могут быть реконфигурированы ( ежечасно или подобно тому).
В отличии от них ”адаптивные вычислительные машины” компании QuickSilver сформированы из кластеров узлов алгоритмических элементов. Применяются эти устройства в основном в небольших, неэнергоемких портативных ихделиях, например, в фотоаппаратах и сотовых телефонах.Кроме того, эти устройства могут быть реконфигурированы сотни тысяч раз в секунду.
Устройства FPNA, главным образом, предназначены для реализации сложных алгоритмов, требующих значительных вычислительных ресурсов.
С одной стороны, существуют технологии, использующие алгоритмы пословной обработки, к числу которых, например, относится метод множественного доступа с разделением по времени ( или TDMA – time division multiple access), применяемый в системах беспроводной связи. С другой стороны, существуют технологии, использующие алгоритмы побитовой обработки, такие как метод широкополосного множественного доступа с кодовым разделением каналов ( или W-CDMA – Wideband Code Division Multiple Access) и его подвиды CDMA2000, IS-95A и другие. Существуют также технологии, использующие алгоритмы, представляющие смесь пословной и побитовой обработки данных, например, различные виды MPEG, сжатие речи, музыки и так далее.
То есть сложные алгоритмы могут быть существенно гетерогенными (разнородными) по своей природе. Исходя из этого, очевидно, что для реализации гетерогенных технологий необходимо использовать и гетерогенные структуры.
Для удовлетворения требований к обработке описанных выше алгоритмов, компания picoChip использует устройство под названием picoArray. Его гетерогенная узловая архитектура представляет собой матрицу различных 16-битных RISC (Reduced Instruction Set Computing – технология вычислений с сокращенным набором команд) микроконтроллеров, каждый тип которых оптимизирован для реализации определенных вычислений. Например, один из них может содержать много памяти, а другой будет поддерживать специальные алгоритмические команды типа ”расширение” и “сужение” для беспроводного стандарта CDMA, используя для этого один такт ( в отличии от 40 тактов при использовании универсального процессора).
Операторы сотовой связи тратят миллиарды долларовежгодно на развитие своих беспроводных инфраструктур, причем, большая часть этих сумм уходит на разработку новых модулей цифровой обработки, устанавливаемых на базовых станциях. В зависимости от расположения каждая базовая станция должна предусматривать обработку десятков или сотен каналов одновременно.
Поэтому неудивительно, что у всех заинтересованных лиц есть огромное желание уменьшить стоимость реализации каждого канала. Так как один picoArray может заменить несколько традиционных заказных микросхем, ПЛИС и процессоров ЦОС, его использование как раз и позволяет существенно снизить цену канала базовой станции.
При обычном подходе заказные микросхемы позволяют достичь очень высокой производительности, но они отличаются высокой стоимостью и длительными сроками разработки. К тому же алгоритмы, реализованные в заказных микросхемах, жестко прошиваются в схему. Это, пожалуй, самая главная проблема заказных микросхем, так как стандарты беспроводной связи меняются настолько быстро, что к моменту завершения разработки заказной микросхемы она уже может устареть.
В отличие от заказных микросхем у picoArray каждый микропроцессорный узел может быть легко реконфигурирован для адаптации к ежечасным изменениям пользовательских профилей, к еженедельным расширениям и исправлениям ошибок, и к ежемесячным этапам развития беспроводных протоколов. Следовательно, базовые станции, построенные по технологии picoArray, имеют более долгий срок эксплуатации, что позволяет снизить затраты на работу системы связи.
Архитектура адаптивной вычислительной машины (АВМ) в обощенном виде представлена на рис.8.12. На самом нижнем уровне находится узел алгоритмических элементов. Четыре таких узла, составляющих квадрант, соединенный матрицей внутренних соединений, формируют структуру, которую можно назвать кластером первого уровня. Четыре таких кластера первого уровня могут быть сгруппированы в кластер второго уровня и так далее.
Каждый из алгоритмических узлов выполняет задачи на уровне целых алгоритмических элементов, типа фильтров с конечной импульсной характеристикой, дискретного косинусного преобразования и т.д. Кроме того, узел может применяться для реализации нелинейных арифметических функций, таких как (1/sinA)·(1/x) и полученное произведение возвести в 13-ю степень.
Аналогично узел обработки битов может применяться для реализации различных функций побитной обработки, например, линейного сдвигового регистра, кодового генератора Уолша, дешифратора TCP/IP –пакетов и т.п.
Каждый узел окружен оболочкой, которая позволяет со стороны внешнего мира рассматривать все узлы совершенно одинаковыми. Эта оболочка принимает входящие пакеты информации ( команды, необработанные данные, конфигурационные данные и т.д.) из внешнего мира, распаковывает их, рапределяет по узлу, управляет задачами обработки, собирает результаты и возвращает их во внешний мир.
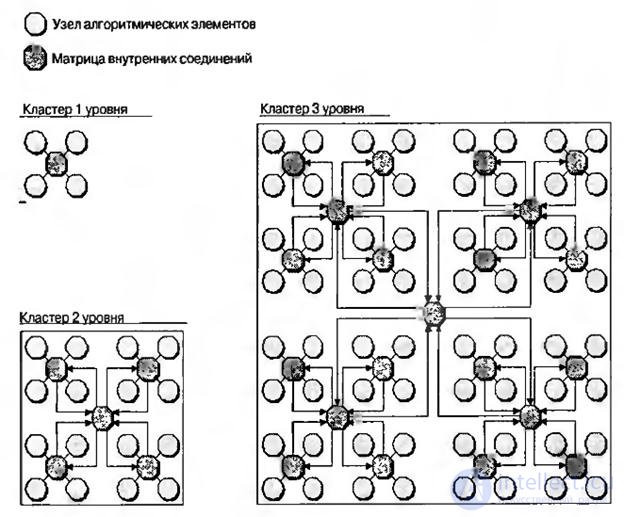
Рис.8.12. Архитектура адаптивной вычислительной машины.
Один из ключевых моментов технологии АВМ заключается в том, что любая часть устройства, от нескольких узлов до целой микросхемы, может быть быстро адаптирована для решения определенной задачи в большинстве случаев за один такт. Также любопытно, что 75% каждого узла реализуется в локальной памяти. Эти особенности позволяют вносить радикальные изменения в методы реализации алгоритмов. В отличие от обычного способа передачи данных от функции к функции, при таком подходе данные могут оставаться в узле, в то время как функция узла может меняться с каждым тактом. Это также значит, что в отличии от заказных микросхем, в которых для каждого алгоритма требуется отдельный кристалл, возможность адаптировать АВМ десятки или сотни тысяч раз в секунду подразумевает, что только те части алгоритма, которые действительно выполняются, должны оставаться в устройстве в текущий момент времени. Этот подход позволяет существенно снизить величину потребляемой мощности и занимаемое на кристалле место.
В дополнение к структуре, изображенной на рис.6.37, любая адаптивная вычислительная машина включает в себя группу узлов специального назначения, таких как системный конроллер, контроллер внешней и внутренней памяти, а также узлы ввода/вывода. Каждый узел ввода/вывода может использоваться для реализации задач ввода/вывода данных в форме универсального асинхронного приемопередатчика (УАПП) или в виде шинного интерфейса, например, PCI, USB, Firewire и им подобных (как и алгоритмические узлы, узлы ввода/вывода при необходимости могут быть реконфигурированы в течении одного такта). Кроме того, эти узлы используются для импорта конфигурационных данных, так как у каждой АВМ ширина шины конфигурации может быть равна количеству входных контактов.
Каждая АВМ содержит встроенную операционную систему (ОС), которая распределена по узлу системного контроллера и оболочкам, связанных с каждым алгоритмическим узлом. Алгоритмические узлы также планируют свои задачи и все межузловые соединения. Это позволяет разгрузить работу узла системного контроллера, основная обязанность которого заключается в отслеживании свободных в текущий момент узлов и распределение между ними новых заданий.
Из рис.8.12 следует, что ядро архитектуры АВМ может легко масштабироваться. При этом желательно, чтобы установленные на печатной плате микросхемы различных АВМ взаимодействовали между собой и с остальной частью схемы на уровне операционных систем. В этом случае их работу можно рассматривать как работу отдельных устройств.
1. Опишите варианты встраивания в ПЛИС блоков ОЗУ, умножителей, сумматоров и микропроцессорных ядер.
2. Особенности синхронизации в ПЛИС.
3. Понятие программируемого пользователем массива узлов.
4. Архитектура адаптивной вычислительной машины.
Надеюсь, эта статья про встраивание в плис блоков, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое встраивание в плис блоков и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Компьютерная схемотехника и архитектура компьютеров
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии