Лекция
Сразу хочу сказать, что здесь никакой воды про часть dsp, и только нужная информация. Для того чтобы лучше понимать что такое часть dsp, плис - как элементная база нейровычислителей , настоятельно рекомендую прочитать все из категории Компьютерная схемотехника и архитектура компьютеров.
Элементной базой нейровычислительных систем второго и третьего направлений (см. часть 1) являются соответственно заказные кристаллы (ASIC), встраиваемые микроконтроллеры (mС), процессоры общего назначения (GPP), программируемая логика (FPGA - ПЛИС), транспьютеры, цифровые сигнальные процессоры (DSP) и нейрочипы [1]. Причем использование, как тех, так и других, позволяет сегодня реализовывать нейровычислители, функционирующие в реальном масштабе времени, однако наибольшее использование при реализации нейровычислителей нашли ПЛИС, DSP и конечно нейрочипы.
Как отмечено в [2], транспьютеры (T414, T800, T9000) и в частности транспьютероподобные элементы являются важным для построения вычислительных систем с массовым параллелизмом, а их применение постепенно сдвигается в сторону коммутационных систем и сетей ЭВМ, хотя еще остаются примеры реализации на них слоев некоторых ЭВМ с массовым параллелизмом в виде решеток процессорных элементов. Подробнее о транспьютерных системах и их применении при построении вычислительных систем с массовым параллелизмом можно узнать в [3].
DSP (Digital Signal Processor-цифровой сигнальный процессор), обладая мощной вычислительной структурой, позволяют реализовать различные алгоритмы обработки информационных потоков. Сравнительно невысокая цена, а также развитые средства разработки программного обеспечения позволяют легко применять их при построении вычислительных систем с массовым параллелизмом.
Стремительный переход современных систем управления на цифровые стандарты, привел к необходимости обрабатывать с высокой скоростью достаточно большие объемы информации. Сложная обработка и фильтрация сигналов, например, распаковка сжатых аудио- и видеоданных, маршрутизация информационных потоков и т.п., требует применения достаточно производительных вычислительных систем. Подобные системы могут быть реализованы на различной элементной базе, но наибольшее распространение получили устройства с применением цифровых сигнальных процессоров и ПЛИС.
Программируемая логика способна работать на более высоких частотах, но поскольку управление реализовано аппаратно, то изменение алгоритмов работы требует перепрограммирования ИС. Низкая тактовая частота DSP пока ограничивает максимальную частоту обрабатываемого аналогового сигнала до уровня в 10-20 МГц, но программное управление позволяет достаточно легко изменять не только режимы обработки, но и функции, выполняемые DSP. Помимо обработки и фильтрации данных DSP могут осуществлять маршрутизацию цифровых потоков, выработку управляющих сигналов и даже формирование сигналов системных шин ISA, PCI и др.
Оценивать быстродействие тех или иных устройств на основе DSP и ПЛИС принято по времени выполнения типовых операций цифровой обработки сигналов (Фильтр Собеля, БПФ, преобразование Уолша-Адамара и др.). Однако оценки производительности нейровычислителей используют другие показатели:
Особенностью использования DSP и ПЛИС в качестве элементной базы нейровычислителей является то, что ориентация в выполнении нейросетевых операций обуславливает с одной стороны повышение скоростей обмена между памятью и параллельными арифметическими устройствами, а с другой стороны уменьшение времени весового суммирования (умножения и накопления) за счет применения фиксированного набора команд типа регистр-регистр [1-11].
Цифровые сигнальные процессоры (DSP) вот уже на протяжении нескольких десятилетий являются элементной базой для построения как нейроускорителей, так и контура логики общесистемного управления нейрокомпьютеров. Какие же DSP могут использоваться для реализации нейроускорителей? - Да практически любые, все зависит лишь от вашей фантазии и возможностей, мы проанализируем лишь МП трех видущих производителей: Analog Devices, Motorola и Texas Instruments, с позиций построения на их основе нейровычислительных систем.
Выбор того или иного процессора - многокритериальная задача, однако, следует отметить предпочтительность процессоров Analog Devices [7] для приложений, требующих выполнения больших объемов математических вычислений (таких как цифровая фильтрация сигнала, вычисление корреляционных функций и т.п.), поскольку их производительность на подобных задачах выше, чем у процессоров компаний Motorola и Texas Instruments. В то же время для задач, требующих выполнения интенсивного обмена с внешними устройствами (многопроцессорные системы, различного рода контроллеры), предпочтительнее использовать процессоры Texas Instruments [8], обладающие высокоскоростными интерфейсными подсистемами. Компания Motorola является лидером по объему производства сигнальных микропроцессоров, большую часть которых составляют дешевые и достаточно производительные 16- и 24-разрядные микропроцессоры с фиксированной точкой. Расширенные коммуникационные возможности, наличие достаточных объемов внутрикристалльной памяти для данных и программы, возможность защиты программы от несанкционированного доступа, поддержка режима энергосбережения делают эти микропроцессоры привлекательными для использования не только в качестве специализированных вычислителей, но и в качестве контроллеров, в бытовых электронных приборах, в системах адаптивной фильтрации и т.д.
Большая производительность, требуемая при обработке сигналов в реальном времени, побудила Texas Instruments и Analog Devices выпустить транспьютероподобные семейства микропроцессоров TMS320C4x и ADSP2106x, ориентированные на использование в мультипроцессорных системах. На этом фоне первый российский сигнальный процессор (нейросигнальный процессор) фирмы Модуль - "Neuro Matrix" [6], выглядит весьма достойно среди DSP c фиксированной точкой. При тактовой частоте 50 Мгц "Neuro Matrix" практически не уступает по производительности изделиям мировых лидеров, а по некоторым задачам даже превосходит их (табл 1) ["Электроника: наука, технология, бизнес" №2, 1999 г.].
Табл. 1. Сравнительные тесты СISC процессоров, DSP TI и нейросигнального процессора NM6403 .
| Наименование теста | Intel Pentium II 300 Мгц | Intel PentiumMMX 200 Мгц | TI TMS320C40 50 Мгц | НТЦ"Модуль" NM6403 40 Мгц |
| Фильтр Собеля (размер кадра 384X288 байт), кадров/с. | - | 21 | 6,8 | 68 |
| Быстрое преобразование Фурье (256 точек, 32 разряда), мкс (тактов) | 200 | - | 464 (11588) | 102 (4070) |
| Преобразование Уолша-Адамара (21 шаг, вх. данные 5 бит), с | 2,58 | 2,80 | - | 0,45 |
При создании нейровычислительных систем на базе сигнальных процессоров необходимо помнить, что DSP обладают высокой степенью специализации. В них широко используются методы сокращения длительности командного цикла, характерные для универсальных RISC-процессоров, такие как конвейеризация на уровне отдельных микроинструкций и инструкций, размещение операндов большинства команд в регистрах, использование теневых регистров для сохранения состояния вычислений при переключении контекста, разделение шин команд и данных (Гарвардская архитектура). В то же время для сигнальных процессоров характерным является наличие аппаратного умножителя, позволяющего выполнять умножение как минимум двух чисел за один командный такт. Другой особенностью сигнальных процессоров является включение в систему команд таких операций, как умножение с накоплением MAC (C=AxB+C с указанным в команде числом выполнений в цикле и с правилом изменения индексов используемых элементов массивов A и B, т.е. уже реализованы прообразы базовых нейроопераций - взвешенное суммирование с накоплением), инверсия бит адреса, разнообразные битовые операции. В сигнальных процессорах реализуется аппаратная поддержка программных циклов, кольцевых буферов. Один или несколько операндов извлекаются из памяти в цикле исполнения команды.
Реализация однотактного умножения и команд, использующих в качестве операндов содержимое ячеек памяти, обуславливает сравнительно низкие тактовые частоты работы сигнальных процессоров. Специализация не позволяет поднимать производительность за счет быстрого выполнения коротких команд типа R,R->R, как это делается в универсальных процессорах. Этих команд просто нет в программах цифровой обработки сигналов.
Сигнальные процессоры различных компаний-производителей образуют два класса, существенно различающихся о цене: более дешевые микропроцессоры для обработки данных в формате с фиксированной точкой и более дорогие микропроцессоры, аппаратно поддерживающие операции над данными в формате с плавающей точкой.
Типичные DSP операции требуют выполнения множества простых сложений и умножений.
сложение и умножение требуют:
Для выборки двух операндов за один командный цикл необходимо осуществить два доступа к памяти одновременно. Но в действительности кроме выборки двух операндов необходимо еще сохранить результат и прочитать саму инструкцию. Поэтому число доступов в память за один командный цикл будет больше двух и следовательно DSP процессоры поддерживают множественный доступ к памяти за один и тот же командный цикл. Но невозможно осуществить доступ к двум различным адресам в памяти одновременно, используя для этого одну шину памяти. Существует два вида архитектур DSP процессоров позволяющих реализовать механизм множественного доступа к памяти:
Гарвардская архитектура имеет две физически разделенные шины данных. Это позволяет осуществить два доступа к памяти одновременно: Подлинная Гарвардская архитектура выделяет одну шину для выборки инструкций (шина адреса), а другую для выборки операндов (шина данных). Но для выполнения DSP операций этого недостаточно, так как в основном все они используют по два операнда. Поэтому Гарвардская архитектура применительно к цифровой обработке сигналов использует шину адреса и для доступа к данным. Важно отметить, что часто необходимо произвести выборку трех компонентов - инструкции с двумя операндами, на что собственно Гарвардская архитектура неспособна. В таком случае данная архитектура включает в себя кэш-память. Она может быть использована для хранения тех инструкций, которые будут использоваться вновь. При использовании кэш-памяти шина адреса и шина данных остаются свободными, что делает возможным выборку двух операндов. Такое расширение - Гарвардская архитектура плюс кэш - называют расширенной Гарвардской архитектурой или SHARC (Super Harvard ARChitecture).
Гарвардская архитектура требует наличия двух шин памяти. Это значительно повышает стоимость производства чипа. Так, например, DSP процессор работающий с 32-битными словами и в 32-битном адресном пространстве требует наличия по крайней мере 64 выводов для каждой шины памяти, а в сумме получается 128 выводов. Это приводит к увеличению размеров чипа и к трудностям при проектировании схемы.
Архитектура фон Неймана использует только одну шину памяти. Она обладает рядом положительных черт:
С точки зрения реализации нейроускорителей мы остановимся только на некоторых наиболее ярких представителях DSP, в основном относящихся к классу транспьютероподобных DSP с плавающей арифметикой.
Реализация нейровычислителей высокой пространственной размерности требует все более производительной элементной базы, для преодоления возникающих трудностей разработчики используют два возможных подхода: первый состоит в улучшении характеристик уже имеющихся процессоров, а второй - в увеличении производительности путем разработки новых архитектур. Первый способ ограничен увеличением производительности в 5-8 раз. Второй способ предполагает разработку архитектур, которые были бы наиболее удобны в конечном приложении и оптимизированы для конкретного языка программирования.
Компания Analog Devices [7] ведет разработки в обоих направлениях. Так ядро первого 32-разрядного процессора ADSP-21020 и производительностью 30 MFLOPS было усовершенствовано, что привело к созданию нового процессора ADSP-21065L с максимальной производительностью 198 MFLOPS, что соответствует ускорению в 6.6 раз. Работая над дальнейшим увеличением производительности, оптимизируя архитектуру существующих процессоров, был разработан новый сигнальный микропроцессор ADSP-2116x с тактовой частотой 100 МГц производительностью 600 MFLOPS.
Рис.1.DSP основа систем цифровой обработки сигналов.
Среди основных особенностей DSP семейства ADSP-2116x можно отметить:
Универсальное АЛУ процессора, устройство барабанного сдвига и универсальный умножитель функционируют независимо, обеспечивая высокую степень внутреннего параллелизма операций. Регистровый файл общего назначения служит для обмена данными между вычислительными модулями и внутренней шиной, а также для запоминания промежуточных результатов. Регистровый файл содержит 32 регистра (16 - первичных и 16 - вторичных), имеет 10 портов и, совместно с Гарвардской архитектурой процессора, позволяет организовывать эффективный обмен между вычислительными модулями и памятью. Расширенная Гарвардская архитектура процессора позволяет выбирать до двух операндов и команду из кэша команд за один цикл.
Процессоры ADSP-210xx содержат высокопроизводительный кэш команд. Кэш работает избирательно: кэшируются только те команды, выборка которых конфликтует с выборкой данных из памяти программ (Program Memory, PM).
Адресные генераторы (DAG1 и DAG2) обеспечивают аппаратную реализацию циклических(кольцевых) буферов, позволяющих эффективно выполнять фильтрацию и Фурье-преобразование, для которых требуется циклическое изменение адресов обрабатываемых данных. Физически циклический буфер может быть расположен начиная с любого адреса памяти, а для ссылки на его содержимое используются регистровые указатели. Два DAG содержат 16 первичных и 16 вторичных регистров, что позволяет работать одновременно с 32 циклическими буферами.
Современные требования рынка обусловили появление новой архитектуры -TigerSHARC, которая для получения высокого уровня производительности объединяет в себе множество особенностей ранее разработанных архитектур. Новый процессор должен объединить в себе достоинства, присущие существующим DSP технологиям, такие как быстрота и определенность времени выполнения команд, распознавание быстрых прерываний и высокая скорость обмена данными с периферийными устройствами.
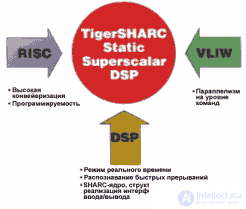
Рис.2. Принципы построения архитектуры TigerSHARC
Для достижения наивысшей производительности ядра использованы особенности RISC архитектуры, такие как структура хранения и обмена данными и командами, высоко конвейеризированный генератор адресов команд с возможностью предсказания переходов и объемным блокирующим файлом регистров. Также было решено взять в расчет особенности VLIW архитектуры для оптимизации построения команд. Полученная архитектура TigerSHARC достигает производительности 1.5 GFLOPS при 32-разрядных вычислениях с плавающей точкой и 6 GFLOPS при 16-разрядных с фиксированной точкой. Тактовая частота составляет на сегодня 250 МГц (рис.2.).
По данным компании Analog Devices [7] большинство нейросетевых реализаций на базе DSP схожи в использовании команд, но различаются набором данных. Особенно в многоканальных приложениях или в тех случаях, когда данные располагаются в виде прямоугольной матрицы, производительность может быть удвоена путем добавления второго набора математических модулей. Процессоры, содержащие второй вычислительный модуль, управляются также, как и небольшие SIMD-архитектуры. TigerSHARC позволяет использовать единственную команду для обработки данных в обоих вычислительных модулях - это уже элементы нейрочипа!
Более того, второй модуль может функционировать независимо от первого, для этой модели используются частично-множественные пути к данным. Для правильного выполнения команды в ней должно быть выделено дополнительное место, что приводит к очень длинным командным словам (VLIW - Very Long Instruction Word). Их использование приводит в большинстве случаев к быстрому заполнению небольшого объема внутрикристалльной памяти командами NOP (no operation), которые предназначены для тех устройств, которые не будут задействованы в текущем цикле. Для избежания размещения команды NOP в коде в существующих VLIW разработках был найден большой недостаток, который был устранен делением длинных слов на более мелкие, параллельно поступающие к каждому устройству. Обработка множества команд независимыми устройствами одновременно является главной особенностью суперскалярной процессорной архитектуры.
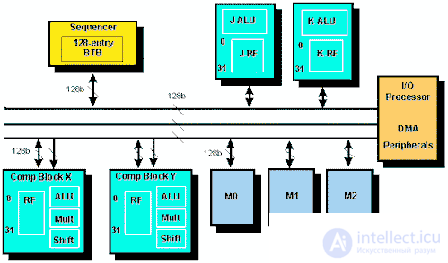
Рис.3. Архитектура TigerSHARC
Сердцем любого процессора является его вычислительная подсистема. Каждый из двух вычислительных модулей - Processing Element X (PEX) и Y (PEY) содержит 32-входовый по 32 бита в каждом входе блокировочный регистровый файл. При каждом вычислении, производимом ALU, MAC или Shifter, данные будут выбраны из этого регистрового файла, а затем в него будут помещены результаты вычислений, что является главной особенностью архитектуры считывания/записи (рис.3.). Использование большого числа регистров для хранения данных упрощает использование высокоуровневых языков программирования. Для достижения высокой внутренней пропускной способности каждый регистровый файл соединен с тремя 128-битовыми шинами посредством двух 128-битных шин. Обе шины могут использоваться одновременно для выполнения операций чтения из памяти и одна шина может быть использована для записи в память. Такая структура шин определяет типичные математические инструкции, требующие выполнения двух операций чтения данных и закачивающиеся записью результата в память.
Сравнительно большой объем внутрикристалльной памяти разделен на три независимых блока одинаковой величины. Каждый блок имеет ширину 128 бит, что соответствует четырехсловной структуре по четыре адреса в каждом ряду. Память может быть сконфигурирована по желанию пользователя без специальной сегментации на память программ и память данных. Для доступа к данным процессор может адресовать одно, два или четыре слова и передавать их в/из одно или оба вычислительных устройства за один такт. Кроме внутренней памяти архитектура TigerSHARC позволяет адресовать 4 ГСлов.
Одним из наиболее сложных устройств новой архитектуры является генератор адресов команд, определяющий порядок выполнения команд и отслеживающий правильность их выполнения в соответствующих модулях. Для снижения эффектов конвейеризации в нелинейном коде генератор адресов инструкций содержит буфер конечного перехода (Branch Target Buffer, BTB). Его механизм позволяет предсказывать переходы и сохранять их в буфере глубиной в 128-ячеек. С помощью предсказания переход может быть выполнен за один цикл вместо 3-6 без предсказания.
Объединение данных процессоров по любой из архитектур (кольцо, гиперкуб и т.п.), позволяет создавать полнофункциональные нейроускорители. Так, нейровычислительная сеть может быть выполнена в виде двумерного массива (в общем случае 4 ряда по высоте и n колонн) процессоров, подключенных к интерфейсным платам и с помощью хост-интерфейса к процессору общего управления. Каждый процессор в сети соединен с соседними, расположенными сверху и снизу относительно него, посредством четырех из шести имеющихся SHARC линков. Остальные линки процессоров используются для обеспечения частичного приема данных, необходимых в процессе вычислений. Архитектура обеспечивает масштабируемую сетевую процессорную модель с общей средой вычислений для каждого узла сети. Эта сеть подсоединяется посредством стандартного интерфейса разделяемой памяти к хост-процессору, который выполняет роль контрольного пункта системы.
Сигнальные процессоры компании Texas Instruments [8] разделяются на два класса: это процессоры для обработки чисел с фиксированной точкой и процессоры для обработки чисел с плавающей точкой (рис.4.). Первый класс представлен тремя семействами процессоров, базовыми моделями которых являются соответственно TMS320C10, TMS320C20, TMS320C50. Второй класс включает процессоры TMS320C30, TMS320C40, TMS320C80, которые поддерживают операции с плавающей точкой и представляют собой мультипроцессорную систему выполненную на одном кристалле, а семейство TMS320C6x включает как процессоры с фиксированной, так и с плавающей точкой.
Процессоры старших поколений одного семейства наследуют основные архитектурные особенности и совместимы "снизу вверх" по системе команд (чего нельзя сказать о процессорах, входящих в разные семейства). Процессоры компании Texas Instruments обладают высокоскоростными интерфейсными подсистемами и поэтому их предпочтительнее использовать для тех задач, в которых требуется выполнение интенсивного обмена с внешними устройствами (микропроцессорные системы, различного рода контроллеры).
Рис.4. Иерархическое дерево микропроцессоров фирмы Texas Instruments [8].
Процессор TMS320C80 фирмы Texas Instruments с производительностью в 2 млрд. операций в секунду представляет собой комбинацию из пяти процессоров, реализованных по MIMD (multiple-instruction, multiple-data) архитектуре (рис.5.). На одном кристалле реализованы одновременно две технологии - DSP и RISC, расположены один управляющий RISC процессор и четыре 32-х разрядных цифровых сигнальных процессора усовершенствованной архитектуры с фиксированной точкой (ADSP0-ADSP-3), обладающие высокой степенью конвейеризации и повышенной до 64 бит длиной слова инструкций, а это в свою очередь позволяет описывать сразу несколько параллельно выполняемых команд. Каждый из процессоров работает независимо друг от друга и может программироваться отдельно друг от друга и выполнять различные или одинаковые задачи, обмениваясь данными через общую внутрикристалльную кеш-память.

Рис.5. Размещение функциональных элементов TMS320C80 на кристалле.
Суммарная производительность TMS320C80 на регистровых операциях составляет 2 млрд. RISС-подобных команд в секунду. Благодаря столь высокой производительности TMS320C80 может заменить при реализации приложений более 10 высокопроизводительных ЦСП или ЦП общего назначения. Пропускная способность шины TMS320C80 достигает 2.4 Гбайт/с - в потоке данных и 1.8 Гбайт/с в потоке инструкций.
TMS320C80 обеспечивает высокую степень гибкости и адаптивности системы, построенной на его базе, которая достигается за счет наличия на кристалле параллельно функционирующих DSP процессоров и главного RISC-процессора. Архитектура процессора TMS320C80 относится к классу MIMD (Multiple-Instruction, Multiple-Data) - множественный поток команд, множественный поток данных. Входящие в состав TMS320C80 процессоры программируются независимо один от другого и могут выполнять как разные, так и одну общую задачу. Обмен данными между процессорами осуществляется через общую внутрикристалльную память. Доступ к разделяемой внутрикристалльной памяти обеспечивает матричный коммутатор (Crossbar), выполняющий также функции монитора при обращении к одному сегменту памяти нескольких процессоров.
Основные технические характеристики процессоров семейства 'C8x':
Главный процессор (MP) - это вычислительное устройство с RISC-архитектурой и встроенным сопроцессором для выполнения операций с плавающей точкой. Подобно другим процессорам с RISC-архитектурой, MP использует команды загрузки/сохранения для доступа к данным в памяти, а также выполняет большинство целочисленных, битовых и логических команд над операндами в регистрах в течение одного такта.
Вычислитель с плавающей точкой (Floating-Point Unit, FPU) конвейеризирован и позволяет одновременно выполнять операции над данными как с одинарной, так и с двойной точностью. Производительность устройства составляет около 100 MFLOPS при внутренней тактовой частоте 50 МГц. FPU использует тот же регистровый файл, что и устройство целочисленной и логической обработки. Специальный механизм отметок (Scoreboard) фиксирует занятость регистров и обеспечивает их бесконфликтное использование.
Основными компонентами MP являются:
Архитектура ADSP-процессоров TMS320C80 ориентирована для применений, связанных с графикой и обработкой изображений (где использование нейропарадигм даем наибольший на сегодня эффект). Она обеспечивает эффективное выполнение операций фильтрации и частотного преобразования, типичных для данных приложений. ADSP может выполнять за один такт одновременно операцию умножения, арифметико-логическую операцию (например, сдвиг-суммирование) и два обращения к памяти. Внутренний параллелизм ADSP позволяет обеспечить быстродействие свыше 500 млн. операций в секунду на некоторых алгоритмах.
ADSP манипулирует 32-разрядными словами, а разрядность команд составляет 64 бита. Процессор использует прямую, непосредственную и 12 видов косвенной адресации.
Архитектура ADSP характеризуется следующими параметрами:
Контроллер обмена (TC) управляет операциями обмена процессоров и памяти как внутри кристалла (через коммутатор), так и вне кристалла, с использованием входящих в его состав интерфейсных схем, поддерживающих все распространенные стандарты памяти (DRAM, VRAM, SRAM) и обеспечивающих возможность динамического изменения разрядности шины от 8 до 64. Используя приоритетную дисциплину обслуживания запросов к памяти в режиме DMA, TC позволяет выполнить обмен данными, не прерывая вычислений со скоростью до 400 Мбайт/c. Контроллер обмена поддерживает линейную и координатную адресацию памяти для эффективного выполнения обмена при работе с 2- и 3-мерными графическими изображениями.
Большинство известных на сегодня нейровычислителей на базе DSP строятся на основе микропроцессоров семейства TMS320C4х. Благодаря своей уникальной структуре эти DSP получили широкое распространение в мультипроцессорных системах и практически вытеснили ранее господствующее в этой области семейство транспьютеров, производимых рядом европейских компаний. Процессоры TMS320C4x совместимы по системе команд с TMS320C3x, однако обладают большей производительностью и лучшими коммуникационными возможностями.
Центральный процессор TMS320C4x имеет конвейерную регистро-ориентированную архитектуру. Компонентами ЦП являются:
Умножитель выполняет операции над 32-разрядными данными в формате с фиксированной точкой и 40-разрядными данными в формате с плавающей точкой, причем умножение производится за один такт (25 нс), независимо от типа данных и параллельно с обработкой данных в других функциональных блоках микропроцессора (например, ALU).
АЛУ выполняет за один такт операции над 32-разрядными целыми и логическими и 40-разрядными данными в формате с плавающей точкой, в том числе и операции преобразования форматов представления данных. Микропроцессор аппаратно поддерживает операции деления и извлечения квадратного корня. Устройство барабанного сдвига позволяет за один такт выполнить сдвиг данных влево или вправо на число позиций от 1 до 32. Два дополнительных модуля регистровой арифметики (Address Generation 0 и Address Generation 1) функционируют параллельно с умножителем и АЛУ и могут генерировать два адреса в одном такте. В процессоре поддерживается относительная базовая, базово-индексная, циклическая и бит-реверсная адресации.
Первичный регистровый файл представляет собой многовходовый файл из 32 регистров. Все регистры первичного регистрового файла могут использоваться умножителем, АЛУ и в качестве регистров общего назначения. Регистры имеют некоторые специальные функции. 8 дополнительных регистров могут использоваться для некоторых косвенных способов адресации, а также как целочисленные и логические регистры общего назначения. Остальные регистры обеспечивают функции системы такие, как адресация, управление стеком, прерывания, отображение статуса процессора, блочные повторы.
Регистры повышенной точности предназначены для хранения и обработки 32-разрядных целых чисел и 40-разрядных чисел с плавающей точкой. Дополнительные регистры доступны как для АЛУ, так и для двух модулей регистровой арифметики. Основная функция этих регистров - генерация 32-разрядных адресов. Они также могут использоваться как счетчик циклов или как регистры общего назначения.
Адресуемое процессором пространство составляет 4Г 32-разрядных слов. На кристалле расположены два двухвходовых блока оперативной памяти RAM0 и RAM1, размером 4 Кбайт каждый, а также двухвходовой блок ROM, содержащий программу начальной загрузки.
Кэш команд процессора емкостью 128 32-разрядных слов содержит наиболее часто используемые участки кода, что позволяет сократить среднее время выборки команд. Высокая производительность TMS320C40 достигается благодаря внутреннему параллелизму процессов и многошинной организации процессора. Раздельные шины позволяют одновременно выполнять выборку команды, данных и прямой доступ в память.
Все больше завоевывающее популярность, в том числе и для нейро приложений, семейство процессоров TMS320C6x обладает рекордной производительностью 1600 MIPS. Благодаря этому возможен принципиально новый взгляд на существующие системы связи и телекоммуникаций. Высокая производительность микропроцессоров обеспечивается благодаря новой архитектуре VelociTIT с очень длинным командным словом (VLIW, Very Long Instruction Word). Архитектура VelociTI образована множеством параллельно работающих процессоров, которые позволяют выполнять несколько инструкций за один командный цикл. Именно такой параллелизм архитектуры процессора обеспечивает высокую производительность.
Сравнительная оценка производительности наиболее используемых сегодня в нейроприложениях DSP Analog Devices и TI приведена в таблице 2.
Таблица 2. Сравнительные характеристики [7].
| Характеристика\процессор | ADSP21061 | TMS320C40/TMS320C44 |
| Instruction Execution Time | 20 ns | 33 ns |
| Peak MFLOPS | 150 Peak MFLOPS | 60 Peak MFLOPS |
| Price (10,000 pcs) | $49 | $176 ($99 w/C44) |
| Price/performance | 3.1 MFLOPS/$ | 0.34 MFLOPS/$ (.6 w/C44) |
| Benchmark: | ||
| 1K pt Complex FFT | .37 ms | .97 ms |
| Core Features: | ||
| Data Registers | 32 | 12 |
| Circular Buffers | 32 | 1 (Fixed Length) |
| I/O Capabilities: | ||
| DMA Channels | 6 | 6 |
| Serial Ports | 2 with TDM mode | None |
| Max throughput | 300 Mbytes/sec | 60 Mbytes/sec |
| On-Chip Memory | 32K x 32 Bit Words | 2K x 32 Bit Words |
| Total On-Chip Memory Size | 1,024 Kbit (1Mbit) | 64 Kbits |
| Multiprocessing Support | 6 processors through cluster bus | 6 processors through COMM ports (4 processors w/C44) |
| Host Interface | Parallel | None |
Сигнальные процессоры компании Motorola на сегодня в меньшей степени, чем рассмотренные выше, используются для реализации нейропарадигм. Они подразделяются на семейства 16- и 24-разрядных микропроцессоров с фиксированной точкой - DSP560xx, DSP561xx, DSP563xx, DSP566xx, DSP568xx и микропроцессоры с плавающей точкой - DSP960xx. Линия 24-разрядных микропроцессоров компании Motorola включает два семейства: DSP560xx и DSP563xx. Основные принципы, положенные в основу архитектуры сигнальных микропроцессоров Motorola были разработаны и воплощены в семействе DSP560xx. Дальнейшие работы по совершенствованию сигнальных процессоров проводились по трем направленим:
Компания Motorola является лидером по объему производства сигнальных микропроцессоров, однако, большую часть которых составляют дешевые и достаточно высокопроизводительные 16- и 24-разрядные микропроцессоры с фиксированной точкой. Расширенные коммуникационные возможности, наличие достаточных объемов внутрикристалльной памяти для данных и программы, возможности защиты программы от несанкционированного доступа, поддержка режима энергосбережения делают эти микропроцессоры привлекательными для использования в основном в качестве специализированных вычислителей, контроллеров в промышленных роботах, бытовых электронных приборах, системах управления оружием, средствах беспроводной связи и др. Примеры построения нейровычислителей на их основе нам не известны.
Отдельно следует рассмотреть возможность создания параллельных вычислителей (в том числе и нейро) на базе ПЛИС (программируемых логических интегральных схем). На ПЛИС можно реализовывать системы, как второго, так и третьего типа (см. часть 1), также в последнее время широко распространены гибридные нейровычислители, когда блок обработки данных реализуется на DSP, а логика управления на ПЛИС. В настоящее время множество фирм в мире занимается разработкой и выпуском различных ПЛИС, однако, лидерство делят две фирмы Xilinx и ALTERA. Выделить продукцию какой-либо одной из этих фирм невозможно, так как по техническим характеристикам они различаются очень мало.
В настоящее время фирма ALTERA выпускает семь семейств СБИС ПЛИС. Основные характеристики наиболее популярных из них приведены в таблице 3.
Таблица 3. Характеристики ПЛИС фирмы ALTERA
| Характеристики | Семейства СБИС | |||
| MAX 7000E(S) | MAX 9000 | FLEX 8000A | FLEX 10K | |
| Архитектура | Матрицы И-ИЛИ | матрицы И-ИЛИ | Таблицы перекодировки | таблицы перекодировки |
| Логическая емкость | 600-5000 | 6000-12000 | 2500-16000 | 10000-100000 |
| Внутренняя память | нет | Нет | Нет | 6-24 Кбит |
| Число пользовательских выводов | 36-164 | 60-216 | 68-208 | 59-406 |
Компания Xilinx выпускает семь серий ПЛИС двух типов:
Каждая серия содержит от одного до нескольких семейств, в свою очередь состоящих из ряда кристаллов различной емкости, быстродействия, типов корпуса.
Основные особенности ПЛИС Xilinx:
При изготовлении ПЛИС фирмой Xilinx используются три основные технологии:
Реализация нейровычислителей на основе ПЛИС требует участия эксперта на топологической стадии проектирования. Это обусловлено тем, что автоматизированный режим разводки пока не позволяет достигать 60-100% использования ресурсов кристала по разводке, а это является принципиальным для сильносвязанных схем, к которым относятся и нейросетевые вычислители. Характеристики ПЛИС с точки зрения реализации нейросетевых парадигм представлены в таблице 4 [10]:
Таблица 4. Особенности реализации нейровычислителей на ПЛИС.
| № | Тип ПЛИС | Производитель | Сложность кристалла, макроячеек (CLB) | Максимальное число нейронов |
| 1 | XC4005E/XL | XILINX | 196 (14x14) | 6 |
| 2 | XC4013XLA | XILINX | 576 (24x24) | 18 |
| 3 | XC4020XLA | XILINX | 784 (28x28) | 24 |
| 4 | XC4044XLA | XILINX | 1600 (40x40) | 50 |
| 5 | XC4062XLA | XILINX | 2304 (42x42) | 72 |
| 6 | XC4085XL | XILINX | 3136 (56x56) | 97 |
| 7 | XC40250XV | XILINX | 8000 | 200 |
| 8 | EPF10K2 | 0ALTERA | 144 | 4 |
| 9 | EPF10K50E | ALTERA | 360 | 11 |
| 10 | EPF10K100E | ALTERA | 624 | 19 |
| 11 | EPF10K250E | ALTERA | 1520 | 50 |
| 12 | M4LV-96/48 | AMD | 966 | 3 |
| 13 | M4LV-192/96 | AMD | 192 | 6 |
| 14 | M5LV-256 | AMD | 256 | 8 |
| 15 | M5LV-512 | AMD | 512 | 16 |
Построение нейровычислителей на их основе хотя и дает высокую гибкость создаваемых структур, но пока еще проигрывает по производительности, по сравнению с другими решениями.
Реализация нейровычислительных систем и специализированных вычислителей с массовым параллелизмом на базе DSP и ПЛИС является эффективным при решении задач цифровой обработки сигналов, обработки видео- и аудиоданных и построения технических систем управления. Сравнительные данные по выполнению БПФ для DSP, RISC и CISC процессоров приведены в таблице 5 [9].
Таблица.5. Время выполнения преобразования Фурье.
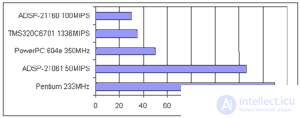
При реализации нейровычислителей сегодня, как правило приоритетно используется гибридная схема, когда блок матричных вычислений реализуется на базе кластерного соединения DSP процессоров, а логика управления на основе ПЛИС. В качестве элементной базы матричного кластера используются ADSP21060 и TMS320C44, в ближайшее время им на смену придут ADSP2106х и TMS320C67хх. В дальнейшем матричное ядро будет реализовываться на базе нейрочипов (обзору которых будет посвящена третья часть работы), а сигнальные процессоры и ПЛИС останутся основой для построения логики управления, что уже явно прослеживается на известных сегодня нейровычислителях, например Synaps 3, обзору которых будет посвящена четвертая часть статьи.
Пожалуйста, пиши комментарии, если ты обнаружил что-то неправильное или если ты желаешь поделиться дополнительной информацией про часть dsp Надеюсь, что теперь ты понял что такое часть dsp, плис - как элементная база нейровычислителей и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Компьютерная схемотехника и архитектура компьютеров
Комментарии
Оставить комментарий
Компьютерная схемотехника и архитектура компьютеров
Термины: Компьютерная схемотехника и архитектура компьютеров