Лекция
Сразу хочу сказать, что здесь никакой воды про использование видеокамеры для решения различных задач, и только нужная информация. Для того чтобы лучше понимать что такое использование видеокамеры для решения различных задач , настоятельно рекомендую прочитать все из категории Робототехника.
использование видеокамеры для решения различных задач
Автономное решение робота по линии - одна из популярных задач робототехники, которая является частой дисциплиной на соревнованиях. Обычно они проводятся на поле белого цвета с черной линией, которая может быть как непрерывной, так и прерывной. Целью участников является проехать роботом по линии, причем сделать это как можно быстрей и аккуратней. Традиционно эту задачу решают с помощью камеры, направленной строго вниз. Робот едет вперед и обрабатывает данные с камеры. Если линия смещается с центра полученного изображения, то робот поворачивает так, чтобы снова двигаться по центру линии. Иногда вместо камеры используют специальный датчик линий, но принцип его работы похож на описанный выше способ. При использовании данного решения приходится ограничивать скорость передвижения робота, так как при большой скорости он может не успеть повернуть вовремя, что влечет за собой потерю линии. Таким образом было предложено поместить камеру так, чтобы она смотрела вперед. Тогда робот будет собирать информацию о линии, находящейся впереди него и сможет использовать ее. Например, разгонятся по прямому участку, тормозить перед поворотами или срезать их, если это разрешено правилами. При таком положении камеры появляется необходимость распознавания линии впереди робота, так как существующие решения направлены на работу с линией, расположенной непосредственно под камерой. Данная работа направлена на решение описанной проблемы.
Для работы алгоритма необходимо заранее посчитать матрицу гомографии. Например, ее можно получить с помощью шахматной доски.
Получив изображение с камеры, нужно выбрать четыре точки на изображении, относящихся к доске, и сопоставить им подобранные точки в
координатах поля. Для упрощения подбора точек можно расположить
доску по нижней границе изображения. Далее, из полученных пар четырех точек можно легко получить матрицу гомографии.
Также необходимо выбрать порог бинаризации, который зависит от
освещения поля.
1 Гомография изображения

Рис. 1: Изображение с камеры робота\
На вход алгоритма поступает поток изображений (рис. 1). В первую
очередь мы переводим изображение из плоскости камеры в плоскость
поля. На этом этапе мы избавляемся от части внешних посторонних
объектов. Кроме того, теперь появляется возможность работать в координатах поля.

Рис. 2: После применения гомографии
Изображение с камеры имеет небольшое зашумление из-за качества
камеры. Для его подавления мы воспользуемся фильтром Гаусса . Выбор этого фильтра был обусловлен тем, что он учитывает расстояния
до соседних пикселей и при этом довольно эффективно подавляет шум.
В результате его применения мы получаем рис. 3
2. Размытие изображения

Рис. 3: Размытое фильтром Гаусса изображение
3. Бинаризация изображения
На этапе бинаризации мы выделяем линию. Для этого переводим
изображение в формат HSV и используем заданный порог (рис. 4). В
ходе экспериментов выяснилось, что данный способ бинаризации обладает невысокой мерой полноты (recall), но зато имеет высокую меру
точности (precision). Это является важным фактором, так как дополнительная фильтрация влечет лишние вычислительные затраты, что
критично для выполнения на платформе ТРИК.
Таким образом, можно предполагать, что белыми пикселями отмечена либо линия на поле, либо внешние объекты.

Рис. 4: Бинаризованное изображение
.4. Выделение контуров
Далее мы ищем контуры следующим образом: ищем объект, затем
идем по его границе, заполняя контур. Пройденные пиксели отмечаем
серым цветом, чтобы не искать контур у того же объекта. Необходимость в выделении конутров появилось ввиду того, что линия может
казаться прерывной из-за неровностей поля. Кроме того, как было сказано выше, сама линия бывает прерывистой.
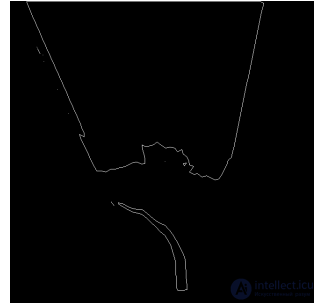
Рис. 5: Найденные контуры
.5. Фильтр контуров
После нахождения контуров ищем минимальные расстояния между ними. С помощью заданного параметра, обозначающего минимальное расстояние линии до границы поля, мы составляем матрицу смежности контуров. Далее отмечаем те контуры, которые находятся близко к верхней границе изображения. От них, с помощью поиска в глубину, по составленной матрице смежности убираем все оставшиеся ”плохие” контуры. Потом удаляем слишком маленькие контуры. Оставшиеся считаем искомыми. (рис. 6) Из предположения о том, что после бинаризации на изображении в области поля находятся только пиксели линии, мы получаем, что оставшиеся контуры - искомые. Исключения могут составить случайные контуры за пределами поля, но расстояния до них будут слишком велики.
.6. Выделение ломаных линий
Сначала мы сужаем контуры до ломаной. Для этого идем по контуру с двух параллельных сторон и дополняем ломаную точками, находящимися посередине прямой. Полученные ломаные имеют много звеньев, поэтому с помощью алгоритма Рамера — Дугласа — Пекера
аппроксимируем ее до ломаной с меньшим числом точек (рис. 7).

Рис. 6: Контуры после фильтрации. Синим отмечены контуры, относящиеся к линии, зеленым - отброшенные.
Данный этап необходим, так как по ломаным можно будет легко
построить путь, а также они легко интерпретируются в команды для
робота.

Рис. 7: Ломаная линия по центру контура.
Первоначально алгоритм написан с помощью библиотеки компьютерного зрения OpenCV . Она хорошо подходит для составления и
тестирования алгоритма, так как в ней содержатся множество реализованных функций.
К сожалению, использование этой библиотеке в ТРИК для данной
задачи не является возможным, поэтому следующем этапом работы
стало переписывание выбранных функций без OpenCV.
Финальным этапом было внедрение в ТРИК. Типичной архитектурой для обработки видео является передача видеопотока на процессор
DSP, специализированный для обработки цифровых сигналов. затем
обработанные результаты передаются на ARM, процессор общего назначения. Так как гомография и фильтрация являются самыми вычислительно сложными задачами, было принято решение реализовать первые три этапа алгоритма на DSP, а остальные на ARM. Перед внедрением я решил оценить скорость алгоритма, воспользовавшись готовым
проектом. Выяснилось, что DSP в лучшем случае обрабатывал бы не
более двух кадров в секунду. Такая скорость неприемлема для робота,
который двигается быстро, так как он может пропустит часть линии.
В итоге я принял решение завершить работу на данном этапе.
Сразу начались проблемы с геометрией. У студентов на картинках полоса стрелой уходит в горизонт. И все равно на ней детектится множество линий, которые авторам пришлось комбинировать. Тем не менее, их линии были хорошо направлены, а на картинках не было мусора.
Совсем иная картина сложилась у меня. Об этом говорит сайт https://intellect.icu . Геометрия полосы изоленты была далека от прямой. Блики на полу генерили шумы.
После применения Canny получилось вот что:

А линии Хафа были такими:

Усилив критерии, удалось исключить мусор, однако исчезли почти все линии, найденные на полосе. Опираться на столь крохотные отрезки было бы глупо.

В общем, результаты были крайне неустойчивые, и мне пришло у голову попробовать другой подход.
Вместо линий я стал искать контуры. Сделав допущение, что самый большой контур — это и есть изолента, удалось избавиться от мусора. (Потом выяснилось, что большой белый плинтус занимал в кадре больше места чем изолента. Пришлось заслонить его диванной подушкой).
Если взять минимальный прямоугольник, ограничивающий контур, то средняя продольная линия очень хорошо подходит на роль вектора движения.

Вторая проблема была с освещением. Я очень удачно проложил одну сторону трассы в тени дивана и совершенно невозможно было обрабатывать фото всей трассы одними и теми же настройками. В итоге, пришлось реализовать динамическую отсечку на черно-белом фильтре. Алгоритм такой — если после применения фильтра на картинке слишком много белого (больше 10%) — то порог следует поднять. Если слишком мало (меньше 3%) — опустить. Практика показала, что в среднем за 3-4 итерации удается найти оптимальную отсечку.
Магические числа вынесены в отдельный конфиг (см ниже), можно с ними играться в поисках оптимума.
def balance_pic(image):
global T
ret = None
direction = 0
for i in range(0, tconf.th_iterations):
rc, gray = cv.threshold(image, T, 255, 0)
crop = Roi.crop_roi(gray)
nwh = cv.countNonZero(crop)
perc = int(100 * nwh / Roi.get_area())
logging.debug(("balance attempt", i, T, perc))
if perc > tconf.white_max:
if T > tconf.threshold_max:
break
if direction == -1:
ret = crop
break
T += 10
direction = 1
elif perc < tconf.white_min:
if T < tconf.threshold_min:
break
if direction == 1:
ret = crop
break
T -= 10
direction = -1
else:
ret = crop
break
return ret
Наладив машинное зрение, можно было переходить к собственно движению. Алгоритм был такой:
Сокращенный вариант кода (Полный — на Гитхабе):
https://github.com/tprlab/pitanq-dev/tree/master/selfdrive/follow_line
def check_shift_turn(angle, shift):
turn_state = 0
if angle < tconf.turn_angle or angle > 180 - tconf.turn_angle:
turn_state = np.sign(90 - angle)
shift_state = 0
if abs(shift) > tconf.shift_max:
shift_state = np.sign(shift)
return turn_state, shift_state
def get_turn(turn_state, shift_state):
turn_dir = 0
turn_val = 0
if shift_state != 0:
turn_dir = shift_state
turn_val = tconf.shift_step if shift_state != turn_state else tconf.turn_step
elif turn_state != 0:
turn_dir = turn_state
turn_val = tconf.turn_step
return turn_dir, turn_val
def follow(iterations):
tanq.set_motors("ff")
try:
last_turn = 0
last_angle = 0
for i in range(0, iterations):
a, shift = get_vector()
if a is None:
if last_turn != 0:
a, shift = find_line(last_turn)
if a is None:
break
elif last_angle != 0:
logging.debug(("Looking for line by angle", last_angle))
turn(np.sign(90 - last_angle), tconf.turn_step)
continue
else:
break
turn_state, shift_state = check_shift_turn(a, shift)
turn_dir, turn_val = get_turn(turn_state, shift_state)
if turn_dir != 0:
turn(turn_dir, turn_val)
last_turn = turn_dir
else:
time.sleep(tconf.straight_run)
last_turn = 0
last_angle = a
finally:
tanq.set_motors("ss")
Неровно, но уверенно танк ползет по траектории:

А вот собрал гифку из отладочной графики:

## Picture settings # initial grayscale threshold threshold = 120 # max grayscale threshold threshold_max = 180 #min grayscale threshold threshold_min = 40 # iterations to find balanced threshold th_iterations = 10 # min % of white in roi white_min=3 # max % of white in roi white_max=12 ## Driving settings # line angle to make a turn turn_angle = 45 # line shift to make an adjustment shift_max = 20 # turning time of shift adjustment shift_step = 0.125 # turning time of turn turn_step = 0.25 # time of straight run straight_run = 0.5 # attempts to find the line if lost find_turn_attempts = 5 # turn step to find the line if lost find_turn_step = 0.2 # max # of iterations of the whole tracking max_steps = 100
Последние несколько лет я занимался проектированием и изготовлением машины, которая сможет распознавать и сортировать детали LEGO. Важнейшая часть машины — это Capture Unit, небольшое, почти полностью закрытое отделение, в котором есть конвейерная лента, освещение и камера.

Освещение вы увидите чуть ниже.
Камера делает фотографии поступающих по конвейеру деталей LEGO, а затем передает изображения по беспроводному каналу на сервер, выполняющий алгоритм искусственного интеллекта для распознавания детали среди тысяч возможных элементов LEGO. Подробнее об ИИ-алгоритме я расскажу в будущих статьях, а эта статья будет посвящена обработке, которая выполняется между «сырым» выводом видео камеры и входом в нейросеть.
Основная проблема, которую мне нужно было решить — это преобразование видеопотока с конвейера в отдельные изображения деталей, которые бы могла использовать нейросеть.


Конечная цель: перейти от «сырого» видео (слева) к набору изображений одинакового размера (справа) для их передачи в нейросеть. (по сравнению с реальной работой gif замедлен примерно вдвое)
Это отличный пример задачи, которая на поверхности кажется простой, но на самом деле ставит множество уникальных и интересных препятствий, многие из которых уникальны для платформ машинного зрения.
Извлечение нужных частей изображения таким образом часто называют распознаванием объектов (object detection). Именно это мне и нужно сделать: распознать наличие объектов, их расположение и размер, чтобы можно было сгенерировать ограничивающие прямоугольники для каждой детали на каждом кадре.


Самое важное — найти хорошие ограничивающие прямоугольники (выше показаны зеленым цветом)
Я рассмотрю три аспекта решения задачи:
В случае подобных задач перед применением техник машинного зрения лучше всего устранить как можно больше переменных. Например, меня не должны волновать условия окружающей среды, разные положения камеры, потери информации из-за перекрытия одних деталей другими. Конечно, можно (хоть и очень сложно) разрешить все эти переменные программно, но к счастью для меня, эта машина создается с нуля. Я сам могу подготовиться к успешному решению, устранив все помехи еще до того, как начал писать код.
Первый шаг — это жесткая фиксация положения, угла и фокусировки камеры. С этим все просто — в системе камера закреплена над конвейером. Не нужно мне волноваться и о помехах от других деталей; нежелательные объекты почти не имеют шанса попасть в capture unit. Немного сложнее, но очень важно обеспечить постоянные условия освещенности. Мне не нужно, чтобы распознаватель объектов ошибочно интерпретировал тень от движущейся по ленте детали как физический объект. К счастью, capture unit очень мал (вся область обзора камеры меньше буханки хлеба), поэтому у меня был более чем достаточный контроль над окружающими условиями.

Capture unit, вид изнутри. Камера находится в верхней трети кадра.
Одно из решений — сделать отсек полностью замкнутым, чтобы никакое освещение снаружи не поступало. Я попробовал такой подход, использовав в качестве источника освещения светодиодные ленты. К сожалению, система оказалась очень капризной — достаточно одной небольшой дырочки в корпусе и свет проникает в отсек, делая невозможным распознавание объектов.
В конечном итоге наилучшим решением оказалось «забивание» всех других источников света при помощи заливки небольшого отсека сильным освещением. Оказалось, что источники света, которые можно использовать для освещения жилых помещений, очень дешевы и просты в использовании.

Получайте, тени!
При направлении источника в крошечный отсек он полностью забивает все потенциальные внешние световые помехи. У такой системы есть и удобный побочный эффект: благодаря большому количеству света в камере можно использовать очень высокую скорость затвора, получая идеально четкие изображения деталей даже при быстром перемещении по конвейеру.
Как же мне удалось превратить это красивое видео с равномерным освещением в нужные мне ограничивающие прямоугольники? Если вы работаете с ИИ, то могли бы предложить мне реализовать нейросеть для распознавания объектов наподобие YOLO или Faster R-CNN. Эти нейронные сети легко могут справиться с задачей. К сожалению, я выполняю код распознавания объектов на Raspberry pi. Даже у мощного компьютера возникали бы проблемы с выполнением этих сверточных нейросетей при нужной мне частоте около 90FPS. А уж Raspberry pi, у которой нет ИИ-совместимого GPU, не справилась бы и с очень урезанной версией одного из подобных ИИ-алгоритмов. Я могу выполнять потоковую передачу видео с Pi на другой компьютер, но передача видео в реальном времени — очень капризный процесс, а задержки и ограничения пропускной способности вызывают серьезные проблемы, особенно когда нужна высокая скорость передачи данных.

YOLO очень крута! Но мне не нужны все ее функции.
К счастью, я мог избежать сложного решения на основе ИИ, воспользовавшись «олдскульными» техниками машинного зрения. Первая техника — это вычитание фона (background subtraction), которое пытается выделить все изменившиеся части изображения. В моем случае единственное, что движется в поле зрения камеры — это детали LEGO. (Разумеется, лента тоже движется, но поскольку она имеет однородный цвет, камере она кажется неподвижной). Отделим эти детали LEGO от фона, и половина задачи решена.
Чтобы вычитание фона работало, объекты переднего плана должны значительно отличаться от фона. Детали LEGO имеют широкий диапазон цветов, поэтому мне нужно было очень тщательно выбирать цвет фона, чтобы он был как можно более далек от цветов LEGO. Именно поэтому лента под камерой изготовлена из бумаги — она не только должна быть очень однородной, но и не может состоять из LEGO, иначе будет иметь цвет одной из деталей, которые мне нужно распознавать! Я выбрал бледно-розовый, но подойдет и любой другой пастельный цвет, непохожий на обычные цвета LEGO.
В чудесной библиотеке OpenCV уже есть несколько алгоритмов для вычитания фона. Вычитатель фонов MOG2 — самый сложный из них, и при этом он работает невероятно быстро даже на raspberry pi. Однако подача кадров видео напрямую в MOG2 работает не совсем хорошо. Светло-серые и белые фигуры слишком близки к яркости бледного фона и теряются на нем. Мне нужно было придумать способ, чтобы отчетливей отделить ленту от находящихся на ней деталей, приказав вычитателю фона внимательнее смотреть на цвет, а не на яркость. Для этого мне достаточно было увеличить насыщенность изображений перед передачей его в вычитатель фонов. Результаты при этом значительно улучшились.
После вычитания фона мне нужно было использовать морфологические операции, чтобы избавиться от как можно большего количества шума. Для поиска контуров белых областей можно использовать функцию findContours() библиотеки OpenCV. Применив различные эвристики для отклонения контуров, содержащих шум, можно легко преобразовать эти контуры в готовые ограничивающие прямоугольники.

Нейронная сеть — прожорливое существо. Для получения наилучших результатов при классификации ей требуются изображения максимального разрешения и в как можно больших количествах. Это значит, что мне нужно снимать их с очень высокой частотой кадров, сохраняя при этом качество и разрешение изображения. Я должен выжать из камеры и GPU Raspberry PI максимум возможного.
В очень подробной документации к picamera написано, что чип камеры V2 может выдавать изображения размером 1280x720 пикселей с максимальной частотой 90 кадров в секунду. Это невероятный объем данных, и хотя камера может его генерировать, это не означает, что с ним справится компьютер. Если бы я обрабатывал сырые 24-битные RGB-изображения, то мне пришлось бы передавать данные со скоростью примерно 237 МБ/с, а это слишком много и для бедного GPU компьютера Pi, и для SDRAM. Даже при использовании ускоренной с помощью GPU компрессии в JPEG частоты 90fps достичь невозможно.
Камера Raspberry Pi способна выводить сырое неотфильтрованное YUV-изображение. Хотя с ним работать сложнее, чем с RGB, у YUV на самом деле есть множество удобных свойств. Самое важное из них заключается в том, что оно хранит всего 12 бит на пиксель (у RGB это 24 бита).
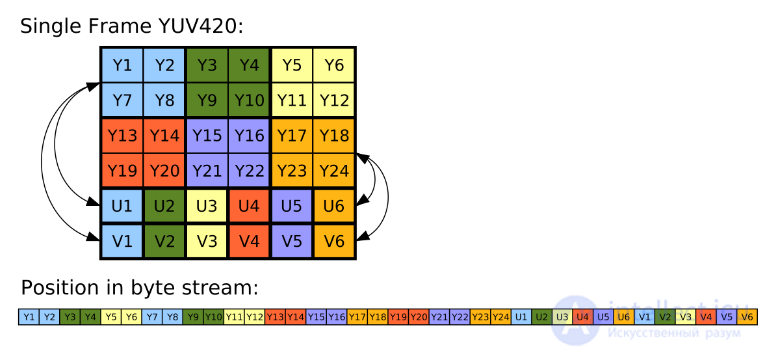
Каждые четыре байта Y имеют один байт U и один байт V, то есть на пиксель приходится 1,5 байта.
Это означает, что по сравнению с RGB-кадрами я могу обрабатывать в два раза больше YUV-кадров, и это еще не считая дополнительного времени, которое GPU экономит на преобразовании в RGB-изображение.
Однако такой подход накладывает уникальные ограничения на процесс обработки. На большинство операций с полноразмерным кадром видео будет тратиться чрезвычайно много памяти и ресурсов ЦП. В пределах моих строгих временных ограничений невозможно даже декодировать полноэкранный YUV-кадр.
К счастью, мне и не нужно обрабатывать кадр целиком! Для распознавания объектов ограничивающие прямоугольники не обязаны быть точными, достаточно приблизительной точности, поэтому весь процесс распознавания объектов можно выполнять с гораздо меньшим кадром. Операция уменьшения масштаба не обязана учитывать все пиксели полноразмерного кадра, поэтому кадры можно уменьшать очень быстро и без затрат. Затем масштаб получившихся ограничивающих прямоугольников снова увеличивается и используется для вырезания объектов из полноразмерного YUV-кадра. Благодаря этому мне не нужно декодировать или иным образом обрабатывать весь кадр высокого разрешения.

К счастью, благодаря способу хранения этого формата YUV (см. выше) очень легко реализовать быстрые операции обрезки и уменьшения масштаба, работающие непосредственно с форматом YUV. Кроме того, весь процесс без особых проблем можно распараллелить на четыре ядра Pi. Однако я выяснил, что не все ядра используются в полную силу, и это говорит нам, что «бутылочным горлышком» по-прежнему остается пропускная способность памяти. Но даже при этом мне удалось на практике достичь 70-80FPS. Более глубокий анализ использования памяти возможно помог бы еще больше ускорить работу.

Список литературы
OpenCV. Collection of algorithms for image processing. –– URL: http://docs.opencv.org/3.0.0/.
Ramer Urs. An iterative procedure for the polygonal approximation ofplane curves. –– 1972.
Szeliski Richard. Computer Vision: Algorithms and Applications. ––2010.
ТРИК Робототехнический контроллер. –– URL: http://www.trikset.com/ (дата обращения: 23.05.2016).
А как ты думаешь, при улучшении использование видеокамеры для решения различных задач, будет лучше нам? Надеюсь, что теперь ты понял что такое использование видеокамеры для решения различных задач и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Робототехника
Комментарии
Оставить комментарий
Робототехника
Термины: Робототехника