Лекция
Это продолжение увлекательной статьи про свёрточная нейронная сеть.
...
Многосменного логистическая потеря ( англ. Softmax ) применяется для предсказания единого класса с K взаимоисключающих классов. Сигмоидна перекрестно-энтропическая потеря применяется для предсказания K независимых значений вероятности в промежутке 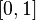 . Евклидова потеря применяется к регрессии диейсвительзначних меток
. Евклидова потеря применяется к регрессии диейсвительзначних меток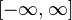 .
.
Самая распространенная форма ОНР состоит из несколько сверточно-ректифицированных(обрезанных) ( англ. Conv-ReLU ) слоев, за ними идут слои подвыборки ( англ. POOL ) , и повторяется эту слои, пока вход не сольется пространственно к небольшому размера. В какой-то момент будет переход к полносвязным ( англ. FC ) слоям. Последний полносвязный слой содержит выход, такой как равные отношения к классам. Вот некоторые распространенные архитектуры CNN, следующих этой схеме:

Типичная архитектура ОНР
Составление сверточных слоев с меньшими фильтрами, в противовес владение одним сверточных слоем с большим фильтром, позволяет выражать мощные признаки входа, с меньшим количеством параметров. Как практический недостаток, может быть необходимо больше памяти для хранения всех результатов промежуточных сверточных слоев для шага обратного распространения .
CNN использует больше гиперпараметрив , чем стандартный БШП . В то время как обычные правила для темпов обучения и постоянных регуляризации все еще применяются при оптимизации сверточных сетей нужно иметь в виду следующее.
Поскольку карта признаков уменьшается с глубиной, слои рядом с входным слоем, как правило, будет меньше фильтров, тогда как высшие слои могут иметь больше. Для выравнивания вычислений на каждом слое обычно берется произведение количества признаков и количества пиксельных положений, чтобы поддерживать его грубо постоянным по всем слоям. Сохранение информации о входе потребует обеспечения, чтобы общее число активаций (количество карт признаков на количество пиксельных положений) не убывало от одного слоя к следующему.
Количество карт признаков направления контролирует емкость, и зависит от количества доступных примеров и сложности задачи.
Распространены в литературе формы поля фильтров сильно различаются, и обычно выбираются в зависимости от набора данных. Лучшие результаты на изображениях размера MNIST (28 × 28) является обычно в диапазоне 5 × 5 на первом слое, тогда как наборы данных природных изображений (часто с сотнями точек по каждому из измерений) склонны к использованию больших фильтров первого слоя формы 12 × 12 или 15 × 15.
Таким образом, сложность заключается в нахождении правильного уровня зернистости, чтобы создавать абстракции в правильном масштабе для определенного набора данных.
Типичными значениями являются 2 × 2. Очень большие входные объемы могут оправдывать на низших слоях подвыборку 4 × 4. Однако выбор больших форм разно снижать размерность сигнала, и может приводить к отказу слишком большого количества информации.
суть переобучения (overfitting) - Грубо говоря, если вы будете слишком интенсивно обучать модель, то в конечном счете получите весовые значения, чрезвычайно точно подходящие к обучающим данным, но, когда вы примените полученную модель к новым данным, точность прогноза окажется весьма скверной.
Переобучение проиллюстрировано двумя графиками на рис. 3. На первом графике показана гипотетическая ситуация, где цель заключается в классификации двух типов элементов, обозначенных черными и серыми точками. Плавная светло-серая кривая представляет истинное разделение двух классов с черными точками над кривой и серыми точками под кривой. Заметьте: из-за случайных ошибок в данных две из черных точек находятся под кривой, а две серых — над ней. При хорошем обучении (без переобучения) вы получили бы весовые значения, которые соответствуют плавной светло-серой кривой. Допустим, что были вставлены новые данные в (3, 7). Элемент данных окажется над кривой и будет правильно спрогнозирован как относящийся к черному классу.
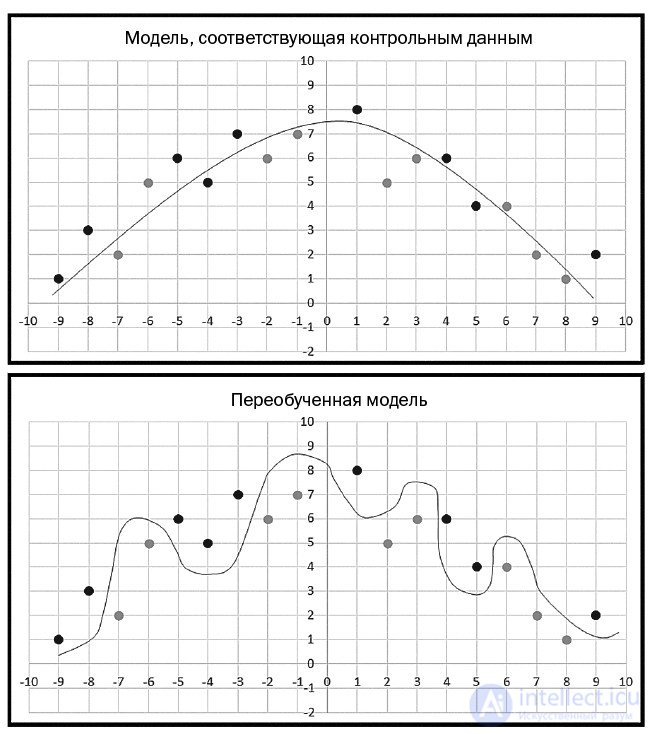
Рис. 3. Переобучение модели
| Ground truth fit model | Модель, соответствующая контрольным данным |
| Overfitted model | Переобученная модель |
На втором графике рис. 3 мы видим те же точки, но другую кривую, которая является результатом переобучения. На этот раз все черные точки находятся над кривой, а все зеленые — под ней. Но кривая слишком сложна. Новый элемент данных в (3, 7) оказался бы под кривой и был бы неправильно спрогнозирован как серый класс.
Переобучение дает неплавные кривые прогнозирования, т. е. «нерегулярные». Такие плохие сложные кривые прогнозирования обычно характеризуются весовыми значениями, которые имеют очень большие или очень малые величины. Поэтому один из способов уменьшить степень переобучения состоит в том, чтобы не допускать очень малых или больших весовых значений для модели. В этом и заключается суть регуляризации.
При обучении ML-модели вы должны использовать некую меру ошибки, чтобы определять хорошие весовые значения. Есть несколько способов измерения ошибок.
Исключение
Поскольку полносвязный слой имеет больше всего параметров, он склонен к переобучению . Для предотвращения переобучению введено метод исключения (англ. Dropout ). На каждом этапе тренировки отдельные узлы или «исключаются» из сети с вероятностью 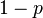 , или остаются с вероятностью
, или остаются с вероятностью 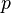 , так что остается уменьшена сеть; входные и выходные ребра исключенных узлов также устраняются. На следующем этапе на данных тренируется уже только уменьшена сеть. После этого устранены узлы повторно вставляются в сети с их первичными весовыми коэффициентами.
, так что остается уменьшена сеть; входные и выходные ребра исключенных узлов также устраняются. На следующем этапе на данных тренируется уже только уменьшена сеть. После этого устранены узлы повторно вставляются в сети с их первичными весовыми коэффициентами.
На этапах тренировки вероятностью оставление (то есть, не исключение) скрытого узла обычно 0.5; для входных узлов вероятность оставления должна быть намного выше, интуитивно том, что при игнорировании входных узлов происходит непосредственная потеря информации.
Во время проверки после завершения тренировки мы в идеале хотели бы найти выборочное среднее всех возможных 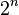 сетей с исключениями; к сожалению, это невыполнимой для больших значений
сетей с исключениями; к сожалению, это невыполнимой для больших значений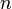 .Тем не менее, мы можем найти приближения, используя полную сеть, в которой выход каждого узла взвешенно на коэффициент , так что математическое ожидание значения выхода любого узла будет таким же, как и на этапах тренировки. Это самым большим вкладом метода исключения: хотя он эффективно порождает нейронных сетей, и таким образом делает сочетание моделей, при проверке проверять нужно только одну сеть.
.Тем не менее, мы можем найти приближения, используя полную сеть, в которой выход каждого узла взвешенно на коэффициент , так что математическое ожидание значения выхода любого узла будет таким же, как и на этапах тренировки. Это самым большим вкладом метода исключения: хотя он эффективно порождает нейронных сетей, и таким образом делает сочетание моделей, при проверке проверять нужно только одну сеть.
Избегая обучение всех узлов на всех тренировочных данных, исключения снижает переобучение нейронных сетей. Этот метод также значительно улучшает скорость обучения. Это делает сочетание моделей практичным, даже для глубинных нейронных сетей. Похоже, что эта методика ослабляет сложные, тесно подогнаны взаимодействия между узлами, ведя их к обучению надежных признаков, лучше обобщаются на новые данные. Было показано, что исключение улучшает производительность нейронных сетей в задачах в видении, распознавании речи, классификации документов и в вычислительной биологии .
Исключение соединений
Исключение соединений ( англ. DropConnect ) является обобщением исключения ( англ. Dropout ), в котором каждое соединение, а не каждый выходной узел, может быть исключен из вероятностью . Таким образом, каждый узел получает вход со случайной подмножества узлов предыдущего слоя.
Исключение соединений подобен исключения тем, что оно вводит в модели динамическую разреженность, но отличается тем, что вероятность есть на весовых коэффициентах, а не на выходных векторах слоя. Иными словами, полносвязный слой с исключением соединений становится разреженно соединенным слоем, в котором соединение избираются случайно во время этапа тренировки.
Стохастическая подвыборка
Главным недостатком исключения является то, что оно не имеет таких же преимуществ для сверточных слоев, где нейроны не является полносвязным.
В стохастической пидвибирци ( англ. Stochastic pooling ) обычные детерминированы действия подвыборки заменяются стохастической процедурой, в которой активация в пределах каждой области подвыборки выбирается случайно, в соответствии с полиномиального распределения , заданного показателям в пределах области подвыборки. Этот подход является свободным от гиперпараметрив, и может сочетаться с другими подходами к регуляризации, такими как исключение, и наращивание данных.
Альтернативным взглядом на стохастической подвыборку является то, что она является равнозначной стандартной максимизацийний пидвибирци, но со многими копиями входного изображения, каждая из которых имеет небольшие локальные деформации. Это подобным явных эластичных деформаций входных изображений, которые обеспечивают отличную производительность в MNIST. Применение стохастической подвыборки в многослойной модели дает экспоненциальное число деформаций, поскольку выборы в высших слоях зависят от выборов в низших.
Искусственные данные
Поскольку степень переобучения модели определяется как ее мощности, так и количеством получаемого ею тренировки, обеспечение сверточной сети дополнительными тренировочными примерами может снизить переобучение. Поскольку эти сети обычно уже натренированно всеми имеющимся данным, одним из подходов является или порождать новые примеры с нуля (если это возможно), или будоражить имеющиеся тренировочные образцы для создания новых. Например, входные изображение может быть асимметрично обрезаемая на несколько процентов для создания новых примеров с таким же маркером, как и первичный.
Размер сети
Самым простым способом предотвратить переобучению сети просто ограничить количество скрытых узлов и свободных параметров (соединений) в ней. Это непосредственно ограничивает предсказательную мощность сети, снижая сложность функции, которую она выполняет в данных, и поэтому ограничивает размер переобучение. Это равнозначно «нулевой норме» .
Ослабление веса
Простым видом добавленного регуляризатора является ослабление веса ( англ. Weight decay ), которое просто добавляет к погрешности каждого узла дополнительную погрешность, пропорциональную сумме весовых коэффициентов ( норма L1 ) или квадратном ступенчатые ( норма L2 ) вектора весовых коэффициентов. Уровень приемлемой сложности модели может быть снижена увеличением постоянной пропорциональности, тем самым увеличивает штраф за большие векторы весовых коэффициентов.
L2 -регуляризация ( англ. L2 regularization ) является, возможно, самым распространенным видом регуляризации. Она может быть реализовано штрафованием квадратного степени всех параметров непосредственно в цели. L2 -регуляризация имеет интуитивную интерпретацию в сильном штрафовании пиковых весовых векторов, и отдаче преимущества рассеянным весовым векторам. В связи с многократными взаимодействиями между весами и входами, это имеет привлекательную свойство поощрения сети использовать все ее входы понемногу, вместо сильного использования только некоторых из них.
L1 -регуляризация ( англ. L1 regularization ) является другим относительно распространенным видом регуляризации. L1 -регуляризацию возможно сочетать с L2 -регуляризациею (это называется эластично-сетевым регуляризации , англ. Elastic net regularization ). L1 -регуляризация имеет такую увлекательную свойство , что она ведет весовые векторы до вступления разреженности течение оптимизации. Иными словами, нейроны с L1 -регуляризациею заканчивают использованием только разреженной подмножества их важнейших входов, и становятся почти инвариантными относительно зашумленных входов.
Ограничения максимума нормы
Другим видом регуляризации является навязывание абсолютной верхней границы величине весового вектора для каждого нейрона, и применение метода проекционного наискорейшего спуска для обеспечения этого ограничения. На практике это соответствует выполнению уточнения параметров как обычно, а потом обеспечению ограничения зажатием весового вектора 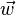 каждого нейрона, чтобы он удовлетворял
каждого нейрона, чтобы он удовлетворял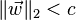 .Типичные значения
.Типичные значения  является порядке 3 или 4. Некоторые труды сообщают об улучшении при применении этого вида регуляризации.
является порядке 3 или 4. Некоторые труды сообщают об улучшении при применении этого вида регуляризации.
Наиболее простым и популярным способом обучения является метод обучения с учителем (на маркированных данных) — метод обратного распространения ошибки и его модификации. Но существует также ряд техник обучения сверточной сети без учителя. Например, фильтры операции свертки можно обучить отдельно и автономно, подавая на них вырезанные случайным образом кусочки исходных изображений обучающей выборки и применяя для них любой известный алгоритм обучения без учителя (например, автоассоциатор или даже метод k-средних) — такая техника известна под названием patch-based training. Соответственно, следующий слой свертки сети будет обучаться на кусочках от уже обученного первого слоя сети. Также можно скомбинировать сверточную нейросеть с другими технологиями глубокого обучения. Например, сделать сверточный авто-ассоциатор , сверточную версию каскадных ограниченных машин Больцмана, обучающихся за счет вероятностного математического аппарата , сверточную версию разреженного кодирования (англ. sparse coding), названную deconvolutional networks («развертывающими» сетями) .
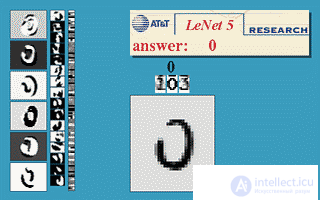
LeNet-5 является последней сверточного сеть ,предназначенная для рукописного и машинной печатью распознавания символов.
Ниже приведен пример LeNet-5 в действии.
Для обучения сверточной сети применяются градиентные методы .
6.1 Вычисление ошибки
Для выходного (MLP) слоя ошибка рассчитывается следующим образом.
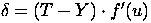
Здесь T - ожидаемый (учебный) выход , Y - реальный выход, f′(u) - производная функции активации по ее аргументу
Для скрытых слоев MLP ошибка имеет следующий вид.
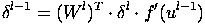
Здесь δl - ошибка слоя l, f′(ul) - производная функции активации, ul - состояние (не активированное) нейронов слоя l, Wl - матрица весовых коэффициентов слоя l.
Ошибка на выходе сверточного слоя формируется путем простого увеличения размера матриц ошибки следующего за ним субдискретизирующего слоя.
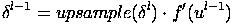
Здесь δl - ошибка слоя l, f′(ul) - производная функции активации, ul - состояние (не активированное) нейронов слоя l, upsample() - операция увеличения размера матриц.
Ошибка на выходе субдискретизирующего слоя рассчитывается путем выполнения ”обратной свертки” карт признаков следующего за ним сверточного слоя, т.е. над каждой картой признаков выполняется свертка с соответствующим ”перевернутым” ядром, при этом за счет краевых эффектов размер исходных матриц увеличивается. Далее над получившимися картами вычисляются несколько частичных сумм по числу ядер свертки, в соответствии с матрицей смежности субдискретизирующего и сверточного слоев.
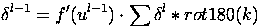
Здесь δl - ошибка слоя l, f′(ul) - производная функции активации, ul - состояние (не активированное) нейронов слоя l, k - ядра свертки.
6.2 Вычисление градиента
В этом разделе описана процедура вычисления градиента функции потери сети, т.е. направления максимального роста функции потери. Обучение сводиться к ее минимизации в пространстве параметров (весов) сети.
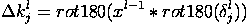
Здесь δl - ошибка слоя l, xl - вход слоя l, k - ядра свертки.
Градиент для сдвига для сверточного слоя вычисляется как сумма значений соответствующей матрицы ошибки.

Здесь δl - ошибка слоя l

Здесь xl - выход слоя l, δl - ошибка слоя l, subsample() - операция выборки локальных максимальных значений.
Градиент для коэффициента сдвига для субдискретизирующего слоя вычисляется как сумма значений соответствующей матрицы ошибки.
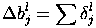
Здесь δl - ошибка слоя l
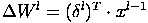
Здесь δl - ошибка слоя l, xl - вход слоя l, Wl - матрица весовых коэффициентов слоя l.
Подвыборка в сверточных сетях приводит к потерям точных пространственных взаимоотношений между высокоуровневыми частями (такими как нос и рот в изображении лица). А точные пространственные взаимоотношения нужны для распознавания идентичности. Сохранению информации о положении признаки помогает прекратить подвыборок, такое, что каждый признак встречается в различных подвыборкам. Но сверточные сети, просто используют сдвиг, не могут экстраполировать свое понимание геометрических взаимоотношений на корне новую точку обзора, такую как другая ориентация, или другой масштаб. С другой стороны, люди очень умелыми в экстраполяции; увидев новую фигуру один раз, они могут распознать ее с другой точки обзора.
Сейчас распространенным способом преодоления этой проблемы является тренировка сверточных сетей на преобразованных данных в различных ориентациях, масштабах, освещении и т.д., чтобы сеть могла справляться с этими вариантами, что крайне вычислительно напряженным для больших наборов данных. Альтернативой является применение иерархии координатных сеток ( англ. Coordinate frames ) и использования группы нейронов для представления связи формы фигуры и ее положения с сетчаткой . Положение относительно сетчатки является взаимоотношением между координатной сеткой сетчатки и собственной координатной сеткой признаки.
Таким образом, одним из способов представления чего является встраивание координатной сетки в этом. Как только это сделано, великие знамения могут распознаваться применением согласованности положений их частей (например, положение носа и рта делают согласованное предсказания положения всего лица).Применяя этот подход, можно сказать, что чем выше уровень сущности (например, лицо) присутствует, когда визуальные сущности низшего уровня (например, нос и рот) имеют согласованные предсказания его положения. Векторы нейронной активности, представляющие положение ( «векторы положения», англ. «Pose vectors» ), позволяют моделирования пространственных преобразований как линейных операций, упрощает сети обучения иерархии визуальных сущностей и обобщения по точкам обзора. Это подобным тому, как человеческий зрительный анализатор накладывает координатные сетки для представления фигур.
Сверточные нейронные сети представляют собой особый вид многослойных нейронных сетей. Как ипочти во всех других нейронных сетей они обучаются с версией алгоритма обратного распространения. Где они отличаются в архитектуре.
Сверточных нейронных сетей предназначено для распознавания визуальных образов непосредственно из пиксельных изображений с минимальной предварительной обработки.
Они могут распознавать образы с крайней изменчивостью (например, рукописных символов), а также с устойчивостью к искажениям и простых геометрических преобразований.
Сверточные нейронные сети часто применяют в системах распознавания изображений. Они достигли 0.23-процентного уровня погрешности на базе данных MNIST , который по состоянию на февраль 2012 года является самым низким с достигнутых на ней. Еще одна работа о применении CNN для классификации изображений сообщила, что процесс обучения был « удивительно быстрым »; в той же труда было достигнуто лучших из опубликованных к тому времени результатов на базах данных MNIST и NORB.
При применении к распознавания лиц им удалось привнести большое снижение уровня погрешности. В другой работе им удалось достичь 97.6-процентного уровня распознавания на «5600 неподвижных изображениях более 10 субъектов». CNN были использованы для оценки качества видео объективным образом, после ручного тренировки; полученная в результате система имела очень низкую корневую среднеквадратичную погрешность .
Широкомасштабное испытания с визуального распознавания ImageNet ( англ. ImageNet Large Scale Visual Recognition Challenge ) является эталоном в классификации и выявлении объектов, с миллионами изображений и сотнями классов объектов. В ILSVRC 2014 , что является крупномасштабным соревнованием с визуального распознавания, почти каждая команда, которая достигла высокого уровня, использовала CNN как свою основную схему. Победитель, GoogLeNet (основа DeepDream ), увеличил ожидаемую среднюю точность обнаружения объектов 0.439 , и снизил погрешность классификации к 0.067, лучшего результата на тот момент. Его сеть применяла более 30 слоев. Производительность сверточных нейронных сетей в задачах ImageNet уже близка к человеческой. Самые алгоритмы все еще сражаются с объектами, являются маленькими или тонкими, такими как маленький муравей на стебле цветка, или лицо, держит перо в руке. Они также имеют проблемы с изображениями, было искажено фильтрами, все более распространенным явлением с современными цифровыми камерами. Напротив, такие типы изображений редко вызывают затруднения у людей. Люди, однако, склонны иметь проблемы с другими вопросами. Например, они не очень опытны в классификации объектов на тонкие категории, такие как отдельные породы собак или виды птиц, в то время как сверточные нейронные сети справляются с этим с легкостью.
2015 многослойная CNN продемонстрировала способность с конкурентоспособной производительностью замечать лицо из большого диапазона углов, включая перевернутыми, даже частично закрытыми. Эта сеть тренировалась на базе данных с 200 000 изображений, включающих лицо под разными углами и в разных ориентациях, и еще 20000000 изображений без лиц. Они использовали пакеты из 128 изображений в 50000 итераций.
По сравнению с отраслями данных изображений, является относительно мало работы по применению CNN классификации видео. Видео является сложнее изображение, поскольку оно имеет еще один (временной) измерение. Тем не менее, было исследовано некоторые расширения CNN в область видео. Одним из подходов является трактовать пространство и время как равноценные измерения входа, и выполнять свертку как по времени, так и по пространству. Другим подходом является слияние особенностей различных сверточных нейронных сетей, ответственных за пространственное и временной поток. Также были представлены схемы спонтанного обучения для тренировки пространственно-временных признаков на основе сверточных вентильных ограниченных машин Больцмана ( англ. Convolutional Gated Restricted Boltzmann Machine ) и метода независимых подпространств ( англ. Independent Subspace Analysis ).
Сверточные нейронные сети также видели применение и в области обработки естественного языка . Затем была показана эффективность моделей CNN для различных задач ОПМ, и они достигли отличных результатов в семантическом разборе, получении результатов поисковых запросов, моделировании предложений, классификации, предвидении и других традиционных задачах ОПМ.
Сверточные нейронные сети применялись в поиске новых лекарств . Предсказания взаимодействия между молекулами и биологическими протеинами может применяться для идентификации потенциальных лекарств, которые вероятно будут действенными и безопасными. 2015 Atomwise представила AtomNet, первые нейронные сети глубинного обучения для рациональной разработки лекарств на основе структуры. Эта система тренируется непосредственно в режиме 3D-представлениях химических взаимодействий. Подобно тому, как сеть распознавания изображений учится составлять меньше, пространственно близкие признаки в большие, сложные структуры, AtomNet открывает новые химические признаки, такие как ароматичность , sp3-углероде и водородное связывание . Впоследствии AtomNet было использовано для предсказания новых кандидатур биомолекул для целей некоторых болезней, прежде всего для лечения вируса Эбола ирассеянного склероза .
Сверточные нейронные сети применялись в компьютерное Го . В декабре 2014 года Кристофер Кларк и Эймос Сторк опубликовали работу, которая показала сверточную сеть, тренированную управляемым обучением из базы данных человеческих профессиональных игр, которая может превосходить GNU Go и выигрывать некоторые игры против Fuego 1.1 древесного поиска Монте-Карло по только долю времени, что требовалось для игры Fuego. [58] Вскоре после этого было объявлено, что большая 12-слойная сверточная нейронная сеть правильно предсказала профессиональный шаг в 55% положений, сравнив точность с 6-м даном [en ]человеческих игроков. Когда тренированная сверточная сеть применялась непосредственно для игры в Го, без всякого поиска, она поборола традиционную поисковую программу GNU Go в 97% игр, и достигла уровня производительности программы древесного поиска Монте-Карло Fuego, которая имитирует десять тысяч розыгрышей (около миллиона позиций) за ход.
Для многих приложений доступна только небольшое количество тренировочных данных. А сверточные нейронные сети обычно требуют большого количества тренировочных данных, чтобы предотвратить переобучению . Распространенной методикой является тренировать сеть на широком наборе данных с связанной области определения. Только параметры сети сошлись, выполняется дополнительный этап тренировки с применением данных из области определения для тонкой настройки весовых коэффициентов сети. Это позволяет сверточным сетям успешно применяться к задачам с небольшими тренировочными наборами.

Но классический, и, возможно, самый популярный вариант использования сетей это обработка изображений. Давайте посмотрим, как СНС используются для классификации изображений.
Задача классификации изображений — это прием начального изображения и вывод его класса (кошка, собака и т.д.)
продолжение следует...
Часть 1 Сверточная нейронная сеть (convolutional neural network -CNN )
Часть 2 Схемы слоев - Сверточная нейронная сеть (convolutional neural network -CNN
Часть 3 Вводы и выводы - Сверточная нейронная сеть (convolutional neural network
В заключение, эта статья об свёрточная нейронная сеть подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое свёрточная нейронная сеть, сверточная нейронная сеть, convolutional neural network, cnn и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Распознавание образов
Комментарии
Оставить комментарий
Распознавание образов
Термины: Распознавание образов