Лекция
Это окончание невероятной информации про машина гельмгольца.
...
бодрствования и 25 000 фаз сна), в то время как нейронные сети обучаются в течение 5 000 с (500 фаз бодрствования и 500 фаз сна с 10 образцами на фазу). Чтобы проверить производительность вычислительной модели, она моделируется 50 раз (с отдельными экземплярами временной стохастичности). Для нейронной сети мы генерируем 50 сетей с различными реализациями случайной связности для каждого правила пластичности. Каждая сеть тестируется с использованием одного сеанса, как описано выше.
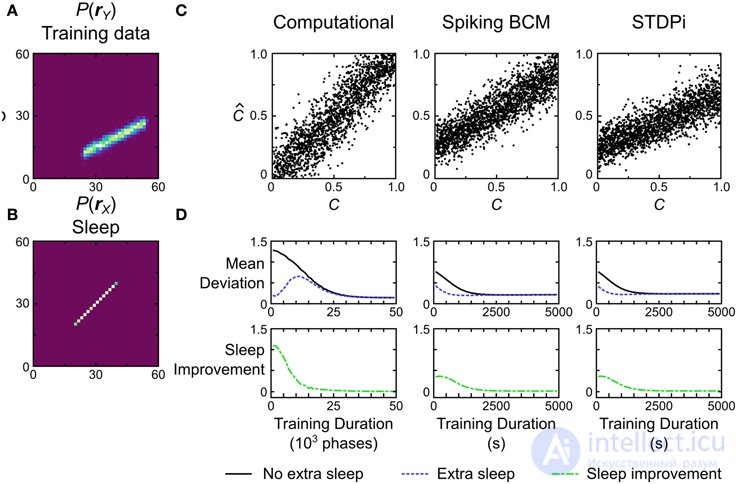
Рис. 13. Производительность вычислительной и нейронной сетевых моделей для задачи декодирования. (A) набор данных о том , что модели обучаются на для выполнения этой задачи. Каждая точка данных помечена меткой C, обозначающей ее положение на линии. Позиция находится в диапазоне [0, 1]. Модели должны восстановить это положение только по данным. (B) Предварительное распределение, используемое во время обучения. (C) Производительность декодирования трех примерных экземпляров модели. C - истинное значение, используемое для создания точки данных, аCˆC^- это значение, оцененное моделью на основе данных. (D) Если обучение остановлено до того, как веса сойдутся, дополнительные выборки в фазе сна без дальнейшего представления данных могут привести к повышению производительности. Планки погрешностей опущены для ясности.
На рисунке 13C показаны характеристики вычислительной модели и два экземпляра моделей нейронных сетей, в одном из которых используется правило пластичности Spiking BCM, а в другом - правило пластичности STDPi. Вычислительная модель выполняет декодирование без какой-либо заметной систематической ошибки, в то время как нейронные сети демонстрируют систематическую ошибку и неспособность декодировать весь динамический диапазон данных. Мы можем количественно оценить производительность, вычислив среднее отклонение (определяемое как квадратный корень из среднеквадратичной ошибки, усредненной по испытаниям) между истинными положениями точек данных и декодированными положениями. Вычислительная модель показывает наилучшие результаты при 0,15. Нейронные сети, использующие правило Spiking BCM, работают хуже со средним отклонением 0,22. Сети с правилом STDPi работают еще немного хуже - 0,24.
Этот тест декодирования - хороший способ проиллюстрировать предсказание, возникающее из средств, с помощью которых любая реализация Машины Гельмгольца узнает веса распознавания. Поскольку выполнение задачи зависит исключительно от весов распознавания, а веса распознавания изучаются во время фазы сна, мы можем наблюдать улучшение производительности во время фазы сна без представления каких-либо дополнительных данных обучения. Это тривиально верно для коротких фаз сна, используемых во время тренировки, потому что без каких-либо улучшений мы бы не наблюдали общего улучшения производительности на протяжении всей тренировки во сне и бодрствовании. Однако это не совсем так для более длительных фаз сна с большим количеством образцов. На ранних этапах обучения длительный сон приведет к созданию конвергентной модели распознавания, которая инвертирует неполностью конвергентную генеративную модель,
Чтобы изучить этот эффект, мы сначала отслеживаем среднее отклонение для моделей во время обучения (рис. 13D , черная кривая). Начальные веса для всех моделей были выбраны небольшими, поэтому начальное среднее отклонение соответственно велико. Мы используем относительно более низкие скорости обучения для всех моделей, чтобы визуализировать улучшение производительности с течением времени, поскольку этот тест очень прост, и в противном случае модели изучали бы его слишком быстро. Через определенные промежутки времени мы останавливаем представление данных и повторяем выборку в фазе сна до тех пор, пока веса распознавания не сойдутся. Изучение среднего отклонения моделей (рис. 13D , синяя кривая) показывает, что наблюдается явное уменьшение среднего отклонения, вызванное сном, без какого-либо нового представления данных. Зеленая кривая на рисунке 13Dпоказывает величину этого улучшения в разное время во время тренировки. Неудивительно, что наибольшее улучшение происходит в начале тренировки, в то время как в конце тренировки такие длительные фазы сна мало что дают.
Второй тест, который мы выполняем, - это задание с двумя вариантами принудительного выбора с неравными наградами за два варианта. Мы используем набор обучающих данных, который представляет собой набор однородных линейных данных (рисунок 14A , набор данных r ) и бимодальный априор (например, рисунок 14B показывает распределение, используемое для нейронных сетей, использующих правило STDPi). Мы называем позицию вдоль линии данных C (для согласованности; см. Обсуждение и рисунок 15 для интерпретации поведенческой задачи этого теста) в диапазоне от -1 до 1. Во время тестирования модели должны определить, меньше или больше C 0. Это достигается за счет того, что отмечается, какая из двух скрытых единиц имеет большую активность (например, является ли y 1 ≥y 2 или y 1 < y 2 ). Таким образом, модели могут сообщать только о том, было ли C больше или меньше 0. Когда модель правильно указывает, что C > 0, она получает вознаграждение со значением r 1 , тогда как если она правильно указывает, что C <0, она получает вознаграждение. с другим значением вознаграждения r 2. Сумма двух значений вознаграждения ограничена 1, поэтому идеальный бесшумный декодер, применяемый к бесшумным данным (как в данном случае), получит в среднем 0,5 вознаграждения. Вознаграждение не влияет на правила пластичности - машина Гельмгольца использует алгоритм обучения без учителя, - но оно влияет на априорное распределение (в мозгу априорное распределение в этом случае будет изменено пластичностью, зависящей от вознаграждения). Два усеченных гауссиана, которые смешиваются для получения предварительного распределения, смешиваются в пропорции r 1 / r 2 (Рисунок 14B показывает предварительное распределение с r 1 / r 2= 4). Таким образом, активность скрытых единиц представляет собой уровни вознаграждения, связанные с наблюдаемыми действиями единиц. Эта задача трудна для нейронных сетей, когда коэффициент вознаграждения высок (т. Е. Один режим намного больше, чем другой), поэтому мы обучаем сети в течение более длительных периодов времени (7500 с) и используем большие партии образцов (50 ) в каждой фазе бодрствования и сна. Как и раньше, мы моделируем вычислительную модель 50 раз. Для нейронной сети мы генерируем 50 сетей с различными экземплярами случайной связности, а затем тестируем каждую на всем наборе обучающих данных.

Рисунок 14. Производительность модели вычислительной и нейронной сети в задаче вознаграждения. (A) Набор данных r , на котором модели обучаются для этой задачи. Каждая точка данных помечена меткой C, обозначающей ее положение на линии. Положение находится в диапазоне [−1, 1]. Модели должны определить, является ли эта позиция положительной или нет, при этом два альтернативных варианта вознаграждаются разными суммами. (B) Бимодальный априор для этой задачи кодирует соотношение вознаграждения r 1 / r 2 из двух альтернативных вариантов путем модуляции весовых коэффициентов двух гауссовских блобов. Расположение и размеры гауссовских капель такие же, как на рисунках 9 , 10.. Изображен априор, использованный для нейронных сетей с использованием правила пластичности STDPi, когда r 1 / r 2 = 4. (C) Вероятность ответа трех примеров модели для r 1 / r 2 = 1. Данные вероятности (крестики) подходят с логистической функцией (красная линия) для определения внутреннего шума модели и порога принятия решения. Обратите внимание, что две нейронные сети показывают смещение порога принятия решения. (D) Порог решения модели (черный) по сравнению с оптимальным порогом (зеленый), учитывая уровень шума модели (оцененный по результатам испытаний, где r 1 / r 2= 1). Планки погрешностей представляют собой стандартное отклонение. N - количество моделей, использованных для построения графика. (E) Модель получила вознаграждение (черный) по сравнению с максимумом, который может получить оптимальный декодер с согласованным уровнем шума (зеленый), и минимально возможным с учетом процедуры подсчета баллов (синий). Оптимальный бесшумный декодер получит награду 0,5 во всех условиях. Планки погрешностей - SEM. N - количество моделей, которые использовались для построенных точек данных.
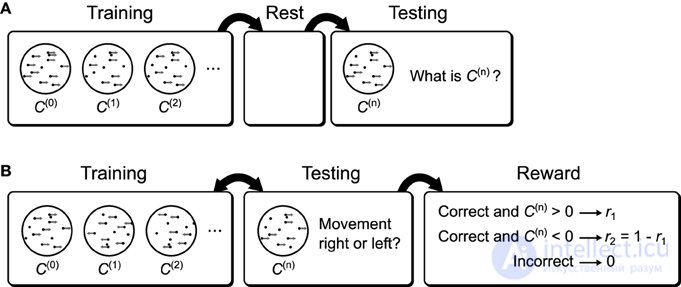
Рисунок 15. Возможные поведенческие задачи, реализующие тесты распознавания. (A) Возможная поведенческая задача для проверки прогноза улучшения сна. Сначала испытуемым показывают движущиеся точки различной степени согласованности. После тренировки испытуемым разрешается отдыхать. Во время последующего тестирования испытуемым снова показывают движущиеся точки с различной степенью согласованности, но теперь их просят сообщить о согласованности. Если мозг использует машину Гельмгольца для изучения весов распознавания, то отдых приведет к повышению производительности по сравнению с отсутствием периода отдыха между тренировкой и тестированием (рис. 13D ). (В)Возможная поведенческая задача для изучения влияния предвзятости вознаграждения на пороги принятия решений. Объектам показывают движущиеся точки разной степени согласованности и в одном из двух направлений. В то же время их спрашивают, в каком направлении они воспринимают движущиеся точки, и вознаграждают по-разному в зависимости от истинного направления движения. Если мозг использует машину Гельмгольца для изучения весов распознавания для этой задачи, то пороговые значения принятия решения субъектом будут смещены относительно оптимальных пороговых значений.
Сначала мы количественно оцениваем эффективность моделей, исследуя, как вероятность ответа [ P (CˆC^> 0 | С )] зависит от истинного значения C . На рисунке 14C показаны эти данные для одного прогона вычислительной модели и двух реализаций нейронных сетей, одна с использованием правила BCM Spiking, а другая с использованием правила STDPi. Для этих трех графиков коэффициент вознаграждения установлен равным единице. Мы подбираем данные с помощью логистической функции, которая параметризуется своим местоположением μ, которое мы называем порогом принятия решения, и его масштабом s, который измеряет внутренний шум системы:
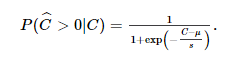
Первое наблюдение заключается в том, что как нейронные, так и вычислительные модели зашумлены и поэтому не могут достичь теоретической максимальной отдачи бесшумного декодера. Это также означает, что порог принятия решения будет варьироваться в зависимости от соотношения вознаграждения: оптимальный шумный декодер смещает порог принятия решения в сторону от выбора, имеющего большее вознаграждение (см. «Материалы и методы» для вывода этого факта). Другое наблюдение состоит в том, что пороги принятия решений нейронных сетей не равны нулю, даже когда вознаграждения за каждый из двух вариантов равны (в данном случае оптимальный порог равен 0). Это вызвано случайным подключением в нейронных сетях. Мы строим график, как этот порог решения изменяется в зависимости от соотношения вознаграждения (то есть14D ). Шум оценивается по испытаниям с коэффициентом вознаграждения, установленным на единицу. Вычислительная модель регулирует свой порог почти оптимально, но нейронные сети значительно превышают порог, т. Е. Более выгодный выбор выбирается даже чаще, чем это является оптимальным. Это явление наблюдалось в экспериментах с обезьянами ( Feng et al., 2009 ). Мы также смотрим на фактическое среднее общее вознаграждение, которое получают модели (рис. 14E , черные кривые). Мы можем сравнить полученное вознаграждение с теоретическим минимальным и максимальным вознаграждением (зеленая и синяя кривые на рисунке 14E., соответственно). Максимальное вознаграждение достигается при использовании оптимального порогового значения и, следовательно, зависит от модели. Минимальное вознаграждение получается, если мы выбираем порог так, чтобы модель всегда отвечала наиболее вознаграждаемым выбором. Вычислительная модель, по сути, получает максимально возможное вознаграждение с учетом уровня внутреннего шума. Нейронные сети также не работают. Низкая производительность нейронных сетей частично связана с тем, что чрезвычайно упрощенный декодер, который мы используем для извлечения решений из нейронных сетей, не принимает во внимание смещение, возникающее из-за случайной связи. Таким образом, эти результаты представляют собой нижнюю границу производительности. Эта нижняя граница может быть улучшена с помощью некоторых простых модификаций декодера (добавление гомеостатического синаптического масштабирования (Turrigiano and Nelson, 2004 ), например).
Мы представили сеть пиковых нейронов, которая реализует машину Гельмгольца и связанный с ней алгоритм неконтролируемого обучения, алгоритм бодрствования-сна. Чтобы создать такую модель, мы также разработали меньшую схему, которая реализует правило дельты, правило исправления ошибок, которое лежит в основе обучения в алгоритме бодрствования-сна. Мы показали, что эта модель может изучить генеративную модель, которая моделирует распределения вероятностей наборов данных, на которых была обучена сеть. Кроме того, мы показали, что он может выполнять приближенный вероятностный вывод в двух задачах распознавания. На протяжении всей этой работы мы противопоставляли два правила синаптической пластичности, Spiking BCM и STDPi, как предполагаемые механизмы для реализации правила дельты и получения необходимого обучения в машине Гельмгольца. Хотя STDPi основан на биологических наблюдениях,
Генеративные тесты, которые мы провели, могут быть использованы для объяснения данных, которые показывают сходство между нейронной активностью, вызванной стимулом, и спонтанной нейронной активностью ( Han et al., 2008 ; Berkes et al., 2011 ; Okun et al., 2012 ), поскольку а также дает нормативное объяснение воспроизведения нейронной активности во сне ( Sutherland and McNaughton, 2000 ). Два теста распознавания могут применяться к поведенческим экспериментам, в которых испытуемые должны наблюдать стимул, а затем принимать решения на основе своего предполагаемого восприятия. На рисунке 15 показаны два возможных эксперимента, в которых используются дисплеи с движущимися точками, которые будут отображать результаты тестов распознавания. Рисунок 15Aпоказывает эксперимент по декодированию, который исследует влияние отдыха (дополнительных образцов после тренировки в фазе сна) на производительность декодирования. На рисунке 15B показан эксперимент с предвзятым вознаграждением, в котором исследуются субоптимальные сдвиги пороговых значений решения, предсказанные нашей моделью. Примечательно, что эксперименты (с немного другой задачей), которые показывают субоптимальные сдвиги пороговых значений принятия решений у обезьян, уже существуют ( Feng et al., 2009 ).
Предлагаемая нами нейронная сеть - не первая, которая реализует правило дельты, хотя, насколько нам известно, она первая отвечает требованиям, предъявляемым нашей реализацией нейронной сети (с использованием пиковых нейронов со скоростью в качестве непрерывной переменной и избеганием временных причинность) Машины Гельмгольца. Тщательно контролируя постсинаптическую активность синаптической связи, сила которой в противном случае регулируется BCM-подобным правилом, Hancock et al. (1991) применили правило частичной дельты для двоичных единиц. Эта реализация неадекватна для этой машины Гельмгольца, потому что в ней используются единицы с непрерывным значением. Совсем недавно, сочетая адаптацию частоты спайков и пластичность, зависящую от времени спайков ( D'Souza et al., 2010) реализовано правило дельты для временно разделенных, но в остальном непрерывных единиц. Характер временного разделения требует, чтобы целевая активность появлялась после сетевой активности. Такое временное разделение потребовало бы нарушения причинности в любой нейронной реализации Машины Гельмгольца, потому что в действительности целевая активность появляется раньше, чем деятельность, производимая сетью. Например, во время фазы бодрствования целевая активность устанавливается стимулом, в то время как текущая активность сети возникает из соединений сверху вниз, которые возбуждаются стимулом. Возможно, что линии задержки или всплески отскока после подавления могут привести к необходимому упорядочиванию активности, но мы выбрали подход, который не требовал таких дополнительных осложнений.
В рамках выбора реализации машины Гельмгольца мы также одновременно решили представить распределения вероятностей с помощью выборок. Этот подход ранее исследовался другими ( Fiser et al., 2010 ; Buesing et al., 2011 ; Pecevski et al., 2011 ; Nessler et al., 2013 ) и обладает множеством интересных теоретических свойств (см. Fiser et al., 2010 ; Lochmann and Deneve, 2011 для обзора), а также напрямую поддаются реализации биологически правдоподобных алгоритмов обучения ( Nessler et al., 2013 и эта работа). Популярная альтернатива представляет распределения вероятностей с использованием кодов вероятностной совокупности ( Rao, 2005; Ma et al., 2006 , 2008 ). Эта структура имеет широкую экспериментальную поддержку, хотя биологически правдоподобный алгоритм обучения в ней еще не предложен. Еще одна альтернатива для кодирования распределения вероятностей - это кодирование с предсказанием спайков ( Deneve, 2008a , b ), которое поддерживает как вывод, так и обучение на уровне отдельных нейронов, но не распространяется естественным образом на представление непрерывных переменных.
Машина Гельмгольца, реализованная в этой статье, очень проста и состоит только из одного входного слоя и одного скрытого слоя с двумя линейными блоками каждый. В результате многие функции, достигаемые этим конкретным экземпляром и представленные в этой статье, могут быть выполнены с помощью более простых моделей без необходимости в сложных схемах и алгоритме пробуждения-сна. Сила машины Гельмгольца, однако, заключается в ее способности расширяться за счет использования нескольких уровней и нескольких единиц, а также различных условных распределений вероятностей ( Hinton and Dayan, 1996 ). Мы решили ограничиться очень бедной моделью, чтобы прояснить, как и почему на ее производительность влияет нейронная реализация. Кроме того, существуют более мощные расширения Машины Гельмгольца с внутриуровневой связью (Хинтон и Даян, 1996 ; Dayan, 1999 ), которые до сих пор используют алгоритм бодрствования-сна. Дальнейшая реализация этих идей позволит предполагаемому подключению нейронных сетей в большей степени соответствовать имеющимся нейрофизиологическим данным.
Связи между слоями в нашей сети реализуются с помощью возбуждающих и тормозных синапсов с прямой связью, из которых только тормозящие являются пластичными. Однако это не является обязательным требованием. Те же функции могут быть реализованы, даже если оба типа синапсов являются пластичными или только возбуждающие синапсы являются пластичными, по причинам, изложенным ниже. Ключевым ограничением правил синаптической пластичности в соединении является то, что чистый вес соединения (полученный в результате комбинации средней тормозной и возбуждающей проводимости в соединении) регулируется, как предсказывается правилом BCM на основе скорости (уравнение 23). В сети правил дельты это означает, что, когда постсинаптическая скорость близка к r θ (Рисунок 2B) и чистый вес соединения увеличивается, синаптические правила должны приводить к чистому уменьшению этого веса. Это не исключает возбуждающие синапсы от того усиливал, но это не означает , что тормозные синапсы должны быть усилено более . В этом смысле мы говорим, что пластичность сети будет антихеббийской. Мы ограничились использованием только одного типа пластиковых синапсов, чтобы минимизировать количество параметров. Доказательства антихеббовских правил немногочисленны для возбуждающих синапсов (хотя см. Sjöström and Häusser, 2006 и Letzkus et al., 2006 ), но имеются для тормозных синапсов ( Haas et al., 2006).). Кроме того, предшествующая теоретическая работа, касающаяся вероятностного вывода, также предполагает использование антихеббовской пластичности в возбуждающих и тормозных синапсах ( Rezende et al., 2011 ). Однако в отличие от этой работы наша модель предсказывает антихеббовскую пластичность как в нисходящих, так и в восходящих связях.
В соответствии с идеями, представленными в этой работе, ядра правила тормозной синаптической пластичности, обнаруженные в энторинальной коре крыс Haas et al. (2006) показывают выраженный провал для почти совпадающих пре- и постсинаптических спайков. Правило STDPi, предложенное в этой статье, выходит за рамки экспериментальных данных, поскольку оно предполагает квадратичную постсинаптическую зависимость скорости, подобную BCM (рис. 2B).), что не исследовалось в экспериментах. Правило экспериментальной пластичности также имеет временные константы, которые короче, чем требуется хорошо работающим ядрам STDPi, но это может быть объяснено биологическими нейронами в экспериментах с динамикой клеток, которые работают в более быстром масштабе времени, чем у наших модельных нейронов. Мы прогнозируем, что области мозга, которые реализуют алгоритм бодрствования-сна на основе скорости, который мы представили здесь, будут иметь адаптации (в форме формы ядра или времени изменения веса), чтобы уменьшить смещение, вносимое корреляциями всплесков.
Хотя наш формализм основан на связях с чистой антихеббийской пластичностью, наша модель не требует, чтобы все связи в мозгу были чистыми антихеббийскими. Неиерархические генеративные модели, такие как модели с боковыми связями внутри слоя, могут потребовать альтернативных правил пластичности для изучения этих весов связей ( Dayan, 1999 ). С другой стороны, не каждая часть мозга может требовать явной генеративной модели и, таким образом, лучше описывается другими, не связанными с машиной Гельмгольца, каркасами ( Brea et al., 2011 ; Nessler et al., 2013 ). В целом, наше предложение совместимо с изобилием известных правил пластичности Хебба в коре и гиппокампе.
Алгоритм пробуждения-сна реализован в нашей модели путем перенастройки сети для каждой фазы. Такая перестройка, однако, не обязательно должна осуществляться в головном мозге посредством явного подавления или шунтирования синапсов. Например, соединение между пулом O и выходным пулом X 1, изображенным на рисунке 4, может быть «отключено» путем строгого запрета ячеек в пуле O без какой-либо реконфигурации подключения. Это торможение может быть периодическим, что согласуется с обилием ритмов в коре ( Buzsáki and Draguhn, 2004 ), хотя такая периодичность, подобная часам, не требуется для функционирования алгоритма бодрствования-сна.
Фазы бодрствования и сна могут соответствовать фактическому бодрствованию и сну животного. Имеются данные о циркадных колебаниях модуляторов, влияющих на обучение ( Steriade, 2004 ; Welberg, 2013 ) и соответствующих изменениях наблюдаемых паттернов возбуждения нейронов ( Sherman, 2001 ) и общей функциональной связности ( Massimini et al., 2005 ). В качестве альтернативы, быстрое перцепционное обучение может происходить без прерывания сна ( Hawkey et al., 2004 ; Alain et al., 2007), что предполагает, что фазы бодрствования и сна могут соответствовать состоянию сети, когда соответствующий стимул присутствует (и к которому обращаются), в то время как фаза сна представляет спонтанное состояние сети (или состояние невнимательности). В этом случае требуемые переключатели связи будут вызваны разной динамикой сети в состояниях с разными уровнями внимания. Такая зависимая от внимания динамика наблюдалась в ряде сенсорных областей коры головного мозга ( Fontanini and Katz, 2006 , 2008 ).
Наши сети используют редкие случайные связи между пулами, но не включают механизмы гомеостатической и структурной пластичности для настройки непластических связей, чтобы противодействовать неблагоприятным реализациям случайной связности. В худшем случае нейрон может быть полностью отключен от вышестоящих нейронов или быть тонически активным. Это способствует большой вариативности производительности между различными реализациями сети и общей неоптимальной производительности по сравнению с вычислительной машиной Гемлгольца. Мы полагаем, что, напротив, почти оптимальное поведение животных проистекает из мозга, использующего такие механизмы ( Holtmaat and Svoboda, 2009 ; Vitureira et al., 2012), который, если его добавить к нашим моделям, вероятно, поможет закрыть очевидный разрыв в средней производительности наших сетей и экспериментов.
Наша модель использует очень упрощенную стратегию кодирования для представления непрерывных переменных, при этом средняя скорость популяции нейронов точно интерпретируется как значение переменной. Одним из следствий этого является то, что дисперсия закодированного распределения вероятностей переменной обратно пропорциональна количеству нейронов, используемых для ее кодирования. Используя относительно небольшие пулы нейронов, мы обеспечиваем высокую дисперсию. Когда это наносит ущерб задаче (например, рис. 13 ), мы ожидаем, что мозг объединит действия нескольких единичных сетей, чтобы уменьшить дисперсию в результатах решения.
Еще одна проблема, которая возникает из нашей стратегии кодирования, - это сложность представления отрицательных весов, из-за чего нейронные сети испытывали проблемы с моделированием вероятностных распределений с отрицательными корреляциями. Вместо однозначного соответствия между частотой активации и переменными стимулов, использование более сложной стратегии кодирования (например, с использованием идей Элиасмита и Андерсона, 2003 ) в рамках машины Гельмгольца является естественным продолжением нашей работы, которая могла бы решить такие вопросы.
На протяжении всей статьи мы представляли образцы из распределения вероятностей как среднюю скорость пула нейронов за 500 мс. Это несовместимо с данными, которые показывают, что корреляция между активностью разных нейронов затухает в течение 20-40 мс ( Berkes et al., 2011 ) и что решения о восприятии могут приниматься в столь же короткие сроки ( Stanford et al., 2010).). Продолжительность каждой выборки, необходимой для успешного обучения в нашей реализации, критически зависит от шкалы времени, которую правила синаптической пластичности используют для оценки соответствующих показателей. В нашем предварительном моделировании мы наблюдали (данные не показаны), что производительность обучения сетей заметно падает, когда выборки сокращаются по продолжительности (самая короткая длительность выборки, которую мы тестировали, составляла 100 мс). Снижение было более выраженным для правила STDPi, чем для правила Spiking BCM, что согласуется с общим снижением производительности первого, показанного в этой статье. Однако эти проблемы должны возникать только во время тренировки. Вне обучения можно использовать более короткие выборки, что позволяет фреймворку моделировать быстрые выводы.
В целом, мы думаем, что подход, принятый в этой статье для реализации машины Гельмгольца в нейронной сети, является многообещающим, и улучшения модели в возможных направлениях, обсужденных выше, могут дать единое объяснение того, как вероятностный вывод выполняется в мозге.
Данная статья про машина гельмгольца подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое машина гельмгольца, алгоритм бодрствования-сна и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Вычислительный интеллект
Часть 1 Машина Гельмгольца и генеративная модель
Часть 2 3. Результаты - Машина Гельмгольца и генеративная модель
Часть 3 3.2. Результаты сети правил дельты - Машина Гельмгольца и генеративная
Часть 4 4. Дискуссия - Машина Гельмгольца и генеративная модель
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии