Лекция
Привет, Вы узнаете о том , что такое двоичная нейронная сеть, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое двоичная нейронная сеть, би-реальная сеть , настоятельно рекомендую прочитать все из категории Вычислительный интеллект.
« би-реальная сеть ( двоичная нейронная сеть ,): повышение производительности 1-битных CNN с улучшенной репрезентативной способностью и расширенным алгоритмом обучения» В этой статье сделан ряд улучшений и улучшений в структуре сети и обучении оптимизации в ответ на дефекты XNOR-сети, включая введение из одного Быстрое соединение в виде слоя на блок, использование квадратичной функции для соответствия знаковой операции активации действительного числа, введение величины веса действительного числа при обновлении веса действительного числа и предварительное обучение модель, использующая функцию отсечения вместо ReLU для обучения, тем самым достигая сетевого веса и активации. Хотя выходные данные бинаризованы, это обеспечивает высокую точность вывода, особенно для больших наборов данных (ILSVRC ImageNet).
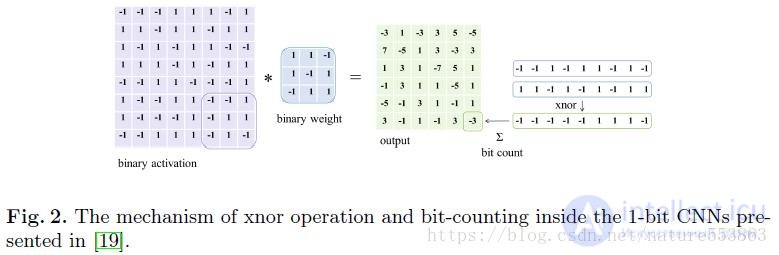
Как показано на рисунке выше, после бинаризации веса и активации глубокой сети объем памяти параметров и активаций может быть значительно сокращен. Во-вторых, вычисление свертки также упрощается до операций XNOR и подсчета битов, поэтому очень Это способствует развертыванию глубоких сетей с логическим выводом, особенно на мобильных устройствах с ограниченными ресурсами и чрезвычайно высокими требованиями к энергоэффективности. XNOR-net, ABC-net и т. Д. В настоящее время являются ведущими бинарными сетями. Bi-Real Net, предложенная в статье, является последующим развитием и улучшением XNOR-сети. Во-первых, реализован ярлык в виде одного слоя на блок в структуре сети. Соединение, то есть результат действительного числа текущей 1-битной свертки или вывода BN, напрямую добавляется к результату действительного числа следующей 1-битной свертки или вывода BN, тем самым увеличивая диапазон значений сети. структура следующая:
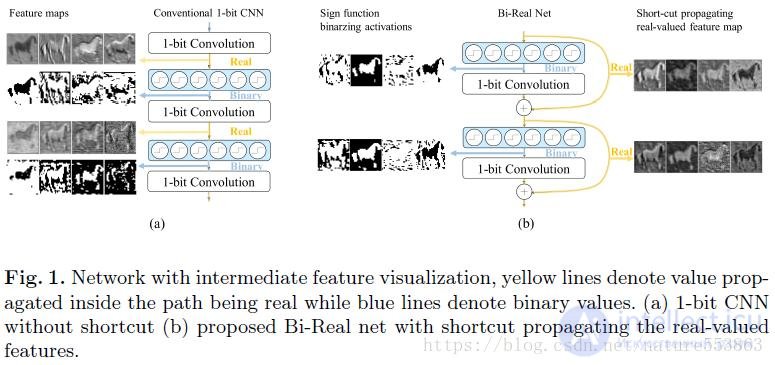

В бинарной сети бинаризация активации A и веса W обычно реализуется с помощью операции Знака:
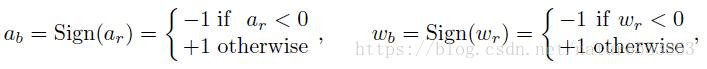
Схема обучения бинарной сети, предложенная в статье, показана на рисунке ниже, включая прямой процесс (знаковая операция, активируемая действительными числами, знаковая операция с учетом величины с действительными весами, 1 бит Conv, BN и т. Об этом говорит сайт https://intellect.icu . Д.) И обратные процессы. (двоичные веса, двоичные веса и т. д.) Вывод веса и обновление веса действительных чисел и т. д.):

На этапе обучения действительные числовые веса сети обновляются напрямую, и градиент потерь по отношению к действительным числовым весам может быть расширен в соответствии с правилом цепочки (условия произведения - это градиент потерь относительно двоичного веса и градиента двоичного веса относительно реального веса):

Среди них градиент потерь по отношению к двоичному весу может быть расширен в соответствии с правилом цепочки следующим образом (термины произведения - это градиент потерь по отношению к активации действительного числа, гамма-коэффициент слоя BN и бинарная активация):
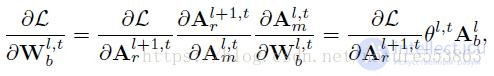
В это время сначала необходимо решить градиент потери относительно активации действительного числа (он может быть выражен как произведение градиента потери относительно двоичной активации и градиента двоичной активации относительно активация действительного числа в соответствии с цепным правилом), но поскольку функция Знака не дифференцируема (производная - это единичный импульс) Шоковая реакция), необходимо разработать функцию аппроксимации F (дифференцируемую) функции Знака как прямое приближение:
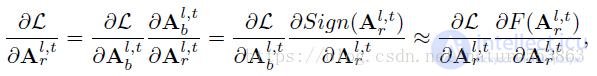
Аппроксимация функции Знака вызовет несоответствие между приблизительным градиентом, полученным в фазе обратного распространения ошибки, и реальной активацией, поэтому степень приближения между функцией аппроксимации и функцией Знака влияет на производительность модели. XNOR-net выбирает кусочно-линейную функцию clip (-1, x, 1) в качестве приближения функции Sign, которая имеет большое отклонение. В статье строится квадратичная функция как прямая аппроксимация функции Знака, которая может дополнительно уменьшить отклонение и повысить производительность модели, а соответствующая производная кривая имеет треугольную форму, которая больше подходит для моделирования импульсных сигналов:


На этапе обучения, поскольку градиент потерь по отношению к двоичным весам обычно невелик, трудно вызвать изменения реальных весов. В этой статье представлена информация об амплитуде реальных весов, то есть операция знака реальных весов заменяется операцией знака с учетом величины во время обучения, которая может увеличить градиент двоичных весов относительно реальных весов, тем самым увеличение размера шага обновления реального веса. Помогите ускорить скорость сходимости модели:

Последняя рекурсивная формула, используемая для обновления весов действительных чисел, выглядит следующим образом:

Термин продукта на этапе обновления - это градиент потерь относительно активации действительного числа, гамма-коэффициент слоя BN, двоичная активация и градиент операции Знака с учетом величины. Градиент операции Знака с учетом величины, то есть градиент двоичного веса относительно реального веса, выражается как (вывод функции Знака по-прежнему аппроксимируется функцией Клипа):

Поскольку модель находится на стадии развертывания логического вывода, бинаризация реальных весов по-прежнему использует обычную операцию Знака, поэтому после того, как операция Знака с учетом величины используется для обучения модели и сходится, необходимо использовать операцию Знак для обучения нескольких эпох для обновления параметров перемещения уровня BN (в это время скорость обучения установлена на ноль) для удовлетворения потребностей фактического развертывания.
Кроме того, поскольку выход бинаризации бинарной сети равен {-1,1} и не содержит нулевых элементов, при обновлении параметров модели предварительного обучения выбор функции отсечения вместо ReLU, поскольку функция нелинейной активации может получить лучший эффект инициализации. В то же время на этапе обучения двоичной сети убывание веса устанавливается на ноль, то есть нет необходимости вводить ограничения регуляризации L1 или L2 на веса действительных чисел. И сокращенная структура из двух слоев по одному на блок лучше, чем сокращенная структура из двух слоев на блок, подробности см. В экспериментальном анализе.
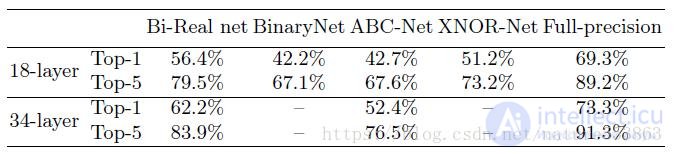
Экспериментальные результаты показывают, что Bi-Real Net работает лучше, чем XNOR-net, ABC-net и т. Д., С такими наборами данных, как CIFAR10 / 100 и ImageNet, и имеет меньше параметров. Он очень подходит для развертывания мобильных терминалов и ускоряется с помощью помощь набора инструкций NEON:

Исследование, описанное в статье про двоичная нейронная сеть, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое двоичная нейронная сеть, би-реальная сеть и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Вычислительный интеллект
Из статьи мы узнали кратко, но содержательно про двоичная нейронная сеть
Комментарии