Лекция
Привет, Вы узнаете о том , что такое рекуррентные нейронные сети, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое рекуррентные нейронные сети , настоятельно рекомендую прочитать все из категории Вычислительный интеллект.
рекуррентные нейронные сети (РНС, англ. Recurrent neural network; RNN) — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).
Джон Хопфилд в 1982 предложил Сеть Хопфилда. В 1993 нейронная система запоминания и сжатия исторических данных смогла решить задачу «очень глубокого обучения», в которой в рекуррентной сети разворачивалось более 1000 последовательных слоев.
Долгая краткосрочная память (LSTM)
Сеть с долговременной и кратковременной памятью (англ. Long short term memory, LSTM); LSTM). нашла применение в различных приложениях.
Начиная с 2007 года LSTM приобрела популярность и смогла вывести на новый уровень распознавание речи, показав существенное улучшение по сравнению с традиционными моделями. В 2009 году появился подход классификации по рейтингу (Connectionist Temporal Classification, (CTC)). Этот метод позволил рекуррентным сетям подключить анализ контекста при распознавании рукописного текста. В 2014 году китайская энциклопедия и поисковая система Baidu, используя рекуррентные сети с обучением по CTC смогли поднять на новый уровень показатели Switchboard Hub5’00, опередив традиционные методы.
LSTM привела также к улучшению распознавания речи с большими словарями и улучшения синтеза речи по тексту, и нашла также применение в операционной системе Google Android. В 2015 году распознавание речи у Google значительно повысило показатели вплоть до 49 %, причиной того стало использование специальной системы обучения LSTM на базе CTC в системе Google voice search.
LSTM вывело на новый уровень качество машинного перевода,, построения языковых моделей и обработки многоязычного текста. Сочетание LSTM со сверточными нейронными сетями (CNN) позволило усовершенствовать автоматическое описание изображений.
Существует много разновидностей, решений и конструктивных элементов рекуррентных нейронных сетей.
Трудность рекуррентной сети заключается в том, что если учитывать каждый шаг времени, то становится необходимым для каждого шага времени создавать свой слой нейронов, что вызывает серьезные вычислительные сложности. Кроме того, многослойные реализации оказываются вычислительно неустойчивыми, так как в них как правило исчезают или зашкаливают веса. Если ограничить расчет фиксированным временным окном, то полученные модели не будут отражать долгосрочных трендов. Различные подходы пытаются усовершенствовать модель исторической памяти и механизм запоминания и забывания.
Это базовая архитектура разработана в 1980-х. Сеть строится из узлов, каждый из которых соединен со всеми другими узлами. У каждого нейрона порог активации меняется со временем и является вещественным числом. Каждое соединение имеет переменный вещественный вес. Узлы разделяются на входные, выходные и скрытые.
Для обучения с учителем с дискретным временем, каждый (дискретный) шаг времени на входные узлы подаются данные, а прочие узлы завершают свою активацию, и выходные сигналы готовятся для передачи нейроном следующего уровня. Если например сеть отвечает за распознавание речи, в результате на выходные узлы поступают уже метки (распознанные слова).
В обучении с подкреплением (reinforcement learning) нет учителя, обеспечивающего целевые сигналы для сети, вместо этого иногда используется функция приспособленности (годности) или функция оценки (reward function), по которой проводится оценка качества работы сети, при этом значения на выходе оказывает влияние на поведение сети на входе. В частности, если сеть реализует игру, на выходе измеряется количество пунктов выигрыша или оценки позиции.
Каждая цепочка вычисляет ошибку как суммарную девиацию по выходным сигналам сети. Если имеется набор образцов обучения, ошибка вычисляется с учетом ошибок каждого отдельного образца.
Рекурсивные нейронные сети представляют собой более общий случай рекуррентных сетей, когда сигнал в сети проходит через структуру в виде дерева (обычно бинарные деревья).Те же самые матрицы весов используются рекурсивно по всему графу в соответствии с его топологией. Рекурсивные нейронные сети находят применение в задачах обработки естественного языка. Существуют также тензорные рекурсивные нейронные сети (RNTN, Recursive Neural Tensor Network), которые используют тензорные функции для всех узлов в дереве.
Сеть Хопфилда — это такой тип рекуррентной сети, когда все соединения симметричны. Изобретена Джоном Хопфилдом в 1982 году и гарантируется, что динамика такой сети сходится к одному из положений равновесия. Если при создании соединений используют обучение Хебба[en], то сеть Хопфилда может работать как надежная ассоциативная память, устойчивая к изменению подключений.
Вариацией сети Хопфилда является двунаправленная ассоциативная память (BAM). BAM имеет два слоя, каждый из которых может выступать в качестве входного, находить (вспоминать) ассоциацию и генерировать результат для другого слоя. Rául Rojas. [ в «Книгах Google» Neural networks: a systematic introduction] (англ.).

Сеть Элмана
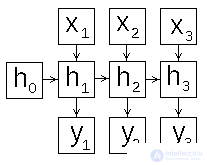
Нейронная сеть Элмана представляет из себя трехслойную нейронную сеть, слои которой называются на иллюстрации x, y, и z. Дополнительно к сети добавлен набор «контекстных блоков» (u на иллюстрации). Средний (скрытый) слой соединен с контекстными блоками с фиксированным весом, равным единице. С каждым шагом времени на вход поступает информация, которая проходит прямой ход к выходному слою в соответствии с правилами обучения. Фиксированные обратные связи сохраняют предыдущие значения скрытого слоя в контекстных блоках (до того как скрытый слой поменяет значение в процессе обучения). Таким способом сеть сохраняет свое состояние, что может использоваться в предсказании последовательностей, выходя за пределы мощности многослойного перцептрона.
Нейронная сеть Джордана подобна сети Элмана. Об этом говорит сайт https://intellect.icu . Однако контекстные блоки связаны не со скрытым слоем, а с выходным слоем. Контекстные блоки таким образом сохраняют свое состояние. Они обладают рекуррентной связью с собой.
Сети Элмана и Джордана называют также «простыми рекуррентными сетями» (SRN).
Сеть Элмана

Сеть Джордана

Обозначения переменных и функций:
 : вектор входного слоя
: вектор входного слоя : вектор скрытого слоя
: вектор скрытого слоя : вектор выходного слоя
: вектор выходного слоя ,
,  и
и  : Матрица и вектор параметров
: Матрица и вектор параметров и
и  : Функция активации
: Функция активацииЭхо-сеть (англ. echo state network; ESN) характеризуется одним скрытым слоем (который называется резервуаром) со случайными редкими связями между нейронами. При этом связи внутри резервуара фиксированы, но связи с выходным слоем подлежат обучению. Состояние резервуара (state) вычисляется через предыдущие состояния резервуара, а также предыдущие состояния входного и выходного сигналов. Так как эхо-сети обладают только одним скрытым слоем, они обладают достаточно низкой вычислительной сложностью, однако качество моделирования сильно зависит от начальных установок, которые грубо говоря случайны. Эхо-сети хорошо работают, воспроизводя временные ряды. Вариацией эхо-сетей являются импульсные (спайковые) нейронные сети, известные также как жидкие нейронные сети ("жидкие" сети названы с использование метафоры расходящихся кругов по воде от падения камешка, что характеризует кратковременную память от входного события).
Нейронный компрессор исторических данных - это блок, позволяющий в сжатом виде хранить существенные исторические особенности процесса, который является своего рода стеком рекуррентной нейронной сети, формируемым в процессе самообучения. На уровне входного сигнала, нейронный компрессор истории пытается предсказать следующий вход по историческим данным. На следующий уровень рекуррентной сети поступают только те входные сигналы, которые не смогли быть предсказаны, и которые при этом способствуют изменению состояния компрессора. Каждый следующий слой сети точно также изучает сжатую историческую информацию с предыдущих слоев. Таким образом входная последовательность может быть точно восстановлена по представлению последующих слоев.
Система пытается свести к минимуму размер описания, или же использует негативные логарифмы для оценки вероятностей данных. Используя обучаемую предсказуемость во входящей последовательности данных, сеть RNN следующего уровня, применяя уже обучение с учителем, может уже классифицировать даже глубокие последовательности с большими временными интервалами между ключевыми событиями.
Таким образом сеть RNN можно разделить на два уровня слоев: «сознательный» (более высокий уровень) и «подсознательный» автоматизатор (нижний уровень). После того, как верхний уровень научился прогнозировать и сжимать входы (которые непредсказуемы) с помощью автоматизатора, тогда автоматизатор может быть вынужден на следующей стадии обучения предсказывать сам или подражать через дополнительные или скрытые блоки более медленно меняющегося высшего уровня. Это упрощает работу автоматизатора, позволяя учесть долгосрочные, но редко меняющиеся воспоминания. В свою очередь, это помогает автоматизатору сделать многие из его некогда непредсказуемых входов предсказуемыми, так что высший уровень может сосредоточиться на оставшихся непредсказуемых событиях.
Сеть с долговременной и кратковременной памятью (англ. Long short term memory, LSTM) представляет собой систему глубинного обучения, при реализации которой удалось обойти проблему исчезновения или зашкаливания градиентов в процессе обучения методом обратного распространения ошибки. Сеть LSTM обычно модерируется с помощью рекуррентных вентилей, которые называются вентили (gates) «забывания». Ошибки распространяются назад по времени через потенциально неограниченное количество виртуальных слоев. Таким образом происходит обучение в LSTM , при этом сохраняя память о тысячах и даже миллионах временных интервалов в прошлом. Топологии сетей типа LSTM могут развиваться в соответствии со спецификой процесса. В сети LSTM даже большие задержки между значимыми событиями могут учитываться, и тем самым высокочастотные и низкочастотные компоненты могут смешиваться.
Многие рекуррентные сети используют стеки данных, присущие LSTM Сети могут обучаться с помощью "Классификации по времени и соединениям (CTC)" (англ. Connectionist Temporal Classification) чтобы найти такую матрицу весов, в которой вероятность последовательности меток в наборе образцов при соответствующем входном потоке сводится к максимуму. CTC позволяет добиться как упорядочивания так и распознавания.
LSTM может также обучаться для распознавания контекстно-чувствительных языков, в отличие от предыдущих моделей, базировавшихся на скрытой марковской модели (HMM) и подобных идеях.
Рекуррентные сети второго порядка
Рекуррентные сети второго порядка используют веса высших порядков  вместо обычных весов
вместо обычных весов  , при этом входные параметры и параметры состояния могут получать в виде произведения. В этом случае сеть трансформируется (mapping) в конечный автомат как в процессе обучения, так и при стабилизации и представлении. Долгая краткосрочная память в данном случае не имеет такой трансформации и проверки стабильности.
, при этом входные параметры и параметры состояния могут получать в виде произведения. В этом случае сеть трансформируется (mapping) в конечный автомат как в процессе обучения, так и при стабилизации и представлении. Долгая краткосрочная память в данном случае не имеет такой трансформации и проверки стабильности.
Управляемый рекуррентный блок (англ. Gated recurrent units; GRU) - механизм управления рекуррентной сети, предложенный в 2014 году. Производительность GRU в моделях речевого сигнала или полифонической музыки оказалась сопоставимой с долгой краткосрочной памятью (LSTM). У данной модели меньше параметров, чем у LSTM, и в ней отсутствует выходное управление.
Существуют актуальные задачи обработки данных, при решении которых мы сталкиваемся не с отдельными объектами но с их последовательностями, т.е. порядок следования объектов играет существенную роль в задаче. Например, это задача распознавания речи, где мы имеем дело с последовательностями звуков или некоторые задачи обработки текстов на естественном языке , где мы имеем дело с последовательностями слов.
Для решения такого рода задач можно применять рекуррентные нейронные сети, которые в процессе работы могут сохранять информацию о своих предыдущих состояниях. Далее мы рассмотрим принципы работы таких сетей на примере рекуррентной сети Элмана .
Искусственная нейронная сеть Элмана , известная так же как Simple Recurrent Neural Network, состоит из трех слоев - входного (распределительного) слоя, скрытого и выходного (обрабатывающих) слоев. При этом скрытый слой имеет обратную связь сам на себя. На рис.1 представлена схема нейронной сети Элмана.

Рис 1: схема нейронной сети Элмана
В отличии от обычной сети прямого распространения , входной образ рекуррентной сети это не один вектор но последовательность векторов {x(1),…x(n)}{x(1),…x(n)} , векторы входного образа в заданном порядке подаются на вход, при этом новое состояние скрытого слоя зависит от его предыдущих состояний. Сеть Элмана можно описать следующими соотношениями.

здесь
x(t) - входной вектор номер t ,
h(t) - состояние скрытого слоя для входа x(t) ( h(0)=0 ),
y(t) - выход сети для входа x(t) ,
U - весовая матрица распределительного слоя,
W - весовая (квадратная) матрица обратных связей скрытого слоя,
bh - вектор сдвигов скрытого слоя,
V - весовая матрица выходного слоя,
by - вектор сдвигов выходного слоя
f - функция активации скрытого слоя
g - функция активации выходного слоя
При этом возможны различные схемы работы сети, о которых мы поговорим в следующем разделе.
В зависимости от того как сформировать вход и выход рекуррентной сети, можно разными способами задать схему ее работы. Рассмотрим этот вопрос подробнее, для этого развернем схему рекуррентной сети во времени (рис.2).
 |
 |
 |
| a) | b) | c) |
 |
| d) |
Рис 2: схемы работы рекуррентной нейронной сети
Перечислим возможные способы организации работы рекуррентной сети [4,5].
Далее мы рассмотрим метод обучения сети Элмана.
В этом разделе мы опишем метод обучения рекуррентной сети Элмана по схеме many-to-one (рис.2a), для реализации классификатора объектов, заданных последовательностями векторов. Для обучения сети Элмана применяются те же градиентные методы , что и для обычных сетей прямого распространения, но с определенными модификациями для корректного вычисления градиента функции ошибки. Он вычисляется с помощью модифицированного метода обратного распространения , который носит название Backpropagation through time (метод обратного распространения с разворачиванием сети во времени, BPTT) . Идея метода - развернуть последовательность, превратив рекуррентную сеть в "обычную" (рис.2a). Как и в методе обратного распространения для сетей прямого распространения , процесс вычисления градиента (изменения весов) происходит в три следующих этапа.
Рассмотрим эти этапы подробнее.
1. Прямой проход: для каждого вектора последовательности  :
:
вычисляем состояния скрытого слоя  и выходы скрытого слоя
и выходы скрытого слоя 

вычисляем выход сети y

2. Обратный проход: вычисляем ошибку выходного слоя δo

вычисляем ошибку скрытого слоя в конечном состоянии δh(n)

вычисляем ошибки скрытого слоя в промежуточных состояниях 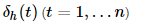

3. Вычисляем изменение весов:
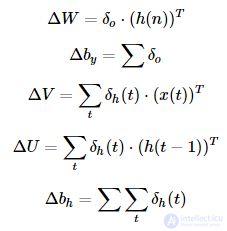
Найдя способ вычисления градиента функции ошибки, далее мы можем применить одну из модификаций метода градиентного спуска, которые подробно описаны в .
В этом разделе представлена реализация рекуррентной сети Элмана по схеме many-to-one (рис.2a), активация скрытого слоя - гиберболический тангенс (tanh), активация выходного слоя (softmax), функция ошибки - средняя кросс-энтропия. Учебные данные генерируются случайным образом.


Рис 3:история изменения ошибки обучения
исходный код нрекурентно неросети https://intellect.icu/uploads/docx/rnn.tar
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области рекуррентные нейронные сети имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое рекуррентные нейронные сети и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Вычислительный интеллект

Комментарии