Лекция
Привет, Вы узнаете о том , что такое автокодировщик, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое автокодировщик, автоассоциатор , настоятельно рекомендую прочитать все из категории Вычислительный интеллект.
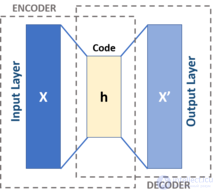
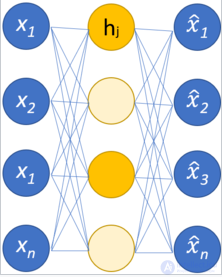
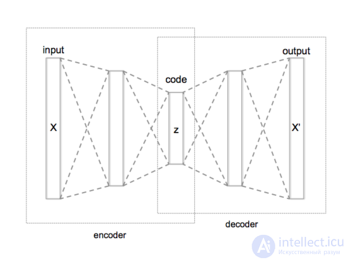
автокодировщик (англ. autoencoder, также — автоассоциатор ) — специальная архитектура искусственных нейронных сетей, позволяющая применять обучение без учителя при использовании метода обратного распространения ошибки. Простейшая архитектура автокодировщика — сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автокодировщика должен содержать столько же нейронов, сколько и входной слой.
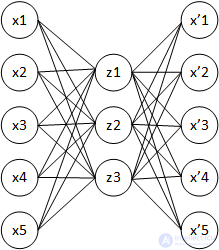
Основной принцип работы и обучения сети автокодировщика — получить на выходном слое отклик, наиболее близкий к входному. Чтобы решение не оказалось тривиальным, на промежуточный слой автокодировщика накладывают ограничения: промежуточный слой должен быть или меньшей размерности, чем входной и выходной слои, или искусственно ограничивается количество одновременно активных нейронов промежуточного слоя — разреженная активация. Эти ограничения заставляют нейросеть искать обобщения и корреляцию в поступающих на вход данных, выполнять их сжатие. Таким образом, нейросеть автоматически обучается выделять из входных данных общие признаки, которые кодируются в значениях весов искусственной нейронной сети. Так, при обучении сети на наборе различных входных изображений, нейросеть может самостоятельно обучиться распознавать линии и полосы под различными углами.
Чаще всего автокодировщики применяют каскадно для обучения глубоких (многослойных) сетей. Автокодировщики применяют для предварительного обучения глубокой сети без учителя. Для этого слои обучаются друг за другом, начиная с первых. К каждому новому необученному слою на время обучения подключается дополнительный выходной слой, дополняющий сеть до архитектуры автокодировщика, после чего на вход сети подается набор данных для обучения. Веса необученного слоя и дополнительного слоя автокодировщика обучаются при помощи метода обратного распространения ошибки. Затем слой автокодировщика отключается и создается новый, соответствующий следующему необученному слою сети. На вход сети снова подается тот же набор данных, обученные первые слои сети остаются без изменений и работают в качестве входных для очередного обучаемого автокодировщика слоя. Так обучение продолжается для всех слоев сети за исключением последних. Последние слои сети обычно обучаются без использования автокодировщика при помощи того же метода обратного распространения ошибки и на маркированных данных (обучение с учителем).
Самая простая форма автокодировщика - это непериодическая нейронная сеть с прямой связью , аналогичная однослойным перцептронам, которые участвуют в многослойных перцептронах (MLP), использующая входной слой и выходной слой, соединенные одним или несколькими скрытыми слоями. Выходной слой имеет такое же количество узлов (нейронов), что и входной слой. Его цель - восстановить входные данные (минимизируя разницу между входом и выходом) вместо прогнозирования целевого значения. данные входы
данные входы  . Следовательно, автокодировщикы - это модели обучения без учителя . (Для обучения им не требуются маркированные входные данные).
. Следовательно, автокодировщикы - это модели обучения без учителя . (Для обучения им не требуются маркированные входные данные).
автокодировщик состоит из двух частей: кодировщика и декодера, которые можно определить как переходы.  и
и  такой, что:
такой, что:



В простейшем случае, учитывая один скрытый слой, этап кодировщика автокодировщика принимает входные данные.  и сопоставляет его с
и сопоставляет его с  :
:

Это изображение  обычно называют кодом , скрытыми переменными или скрытым представлением . Здесь,
обычно называют кодом , скрытыми переменными или скрытым представлением . Здесь, представляет собой поэлементную функцию активации, такую как сигмовидная функция или выпрямленный линейный блок .
представляет собой поэлементную функцию активации, такую как сигмовидная функция или выпрямленный линейный блок .  - весовая матрица и
- весовая матрица и  вектор смещения. Веса и смещения обычно инициализируются случайным образом, а затем обновляются итеративно во время обучения посредством обратного распространения ошибки . После этого этап декодера автокодера отображает на реконструкцию
вектор смещения. Веса и смещения обычно инициализируются случайным образом, а затем обновляются итеративно во время обучения посредством обратного распространения ошибки . После этого этап декодера автокодера отображает на реконструкцию  такой же формы, как
такой же формы, как  :
:

где  для декодера может не иметь отношения к соответствующему
для декодера может не иметь отношения к соответствующему  для кодировщика.
для кодировщика.
автокодировщикы обучены минимизировать ошибки восстановления (такие как ошибки в квадрате ), часто называемые « потерями »:

где обычно усредняется по некоторой входной обучающей выборке.
Как упоминалось ранее, обучение автокодировщика выполняется путем обратного распространения ошибки, как и в обычной нейронной сети с прямой связью .
Если пространство функций  имеют меньшую размерность, чем входное пространство
имеют меньшую размерность, чем входное пространство  , вектор признаков
, вектор признаков  можно рассматривать как сжатое представление входных данных
можно рассматривать как сжатое представление входных данных . Это случай undercomplete автоассоциатор. Если скрытые слои больше, чем ( избыточные автокодировщикы) , или равны входному слою, или скрытым единицам дана достаточная емкость, автокодировщик потенциально может изучить функцию идентификации и стать бесполезным. Однако экспериментальные результаты показали, что в этих случаях автокодеры могут изучать полезные функции . [13] В идеальном случае нужно иметь возможность адаптировать размерность кода и емкость модели в зависимости от сложности моделируемого распределения данных. Один из способов сделать это - использовать варианты модели, известные как регулярные автокодировщикы.
. Это случай undercomplete автоассоциатор. Если скрытые слои больше, чем ( избыточные автокодировщикы) , или равны входному слою, или скрытым единицам дана достаточная емкость, автокодировщик потенциально может изучить функцию идентификации и стать бесполезным. Однако экспериментальные результаты показали, что в этих случаях автокодеры могут изучать полезные функции . [13] В идеальном случае нужно иметь возможность адаптировать размерность кода и емкость модели в зависимости от сложности моделируемого распределения данных. Один из способов сделать это - использовать варианты модели, известные как регулярные автокодировщикы.
Существуют различные методы для предотвращения обучения автокодировщикам функции идентификации и улучшения их способности захватывать важную информацию и изучать более богатые представления.
Когда представления изучаются таким образом, чтобы поощрять разреженность, повышается производительность при выполнении задач классификации. Об этом говорит сайт https://intellect.icu . Разреженный автокодировщик может включать больше (а не меньше) скрытых единиц, чем входов, но только небольшое количество скрытых единиц может быть активным одновременно. Это ограничение разреженности заставляет модель реагировать на уникальные статистические особенности обучающих данных.
В частности, разреженный автокодировщик - это автокодировщик, критерий обучения которого включает штраф за разреженность.  на уровне кода
на уровне кода  .
.

Напоминая, что  , штраф побуждает модель активировать (т. е. выходное значение, близкое к 1) определенные области сети на основе входных данных, при этом инактивируя все другие нейроны (т. е. иметь выходное значение, близкое к 0).
, штраф побуждает модель активировать (т. е. выходное значение, близкое к 1) определенные области сети на основе входных данных, при этом инактивируя все другие нейроны (т. е. иметь выходное значение, близкое к 0).
Этой разреженности можно добиться, сформулировав условия штрафа по-разному.

быть средней активацией скрытого блока  (в среднем по
(в среднем по  обучающие примеры). Обозначение
обучающие примеры). Обозначение определяет входное значение, вызвавшее активацию. Чтобы стимулировать бездействие большинства нейронов,
определяет входное значение, вызвавшее активацию. Чтобы стимулировать бездействие большинства нейронов, должно быть близко к 0. Следовательно, этот метод применяет ограничение
должно быть близко к 0. Следовательно, этот метод применяет ограничение  где
где  - параметр разреженности, значение, близкое к нулю. Срок штрафа принимает форму, которая наказывает за значительное отклонение от , используя дивергенцию KL:
- параметр разреженности, значение, близкое к нулю. Срок штрафа принимает форму, которая наказывает за значительное отклонение от , используя дивергенцию KL:
 где подводит итоги
где подводит итоги  скрытые узлы в скрытом слое и
скрытые узлы в скрытом слое и  KL-дивергенция между случайной величиной Бернулли со средним и случайная величина Бернулли со средним .
KL-дивергенция между случайной величиной Бернулли со средним и случайная величина Бернулли со средним .
 . [18] Например, в случае L1 функция потерь принимает вид
. [18] Например, в случае L1 функция потерь принимает вид
автокодировщикы с шумоподавлением (DAE) пытаются добиться хорошего представления, изменяя критерий восстановления .
Действительно, DAE принимают частично поврежденный ввод и обучаются восстанавливать исходный неискаженный ввод . На практике целью шумоподавления автокодеров является очистка искаженного ввода или уменьшение шума . Этому подходу присущи два допущения:
Другими словами, шумоподавление рекомендуется в качестве критерия обучения для обучения извлечению полезных функций, которые будут лучше представлять входные данные на более высоком уровне.
Тренировочный процесс DAE работает следующим образом:
поврежден в  через стохастическое отображение
через стохастическое отображение  . затем сопоставляется со скрытым представлением с помощью того же процесса стандартного автокодировщика,
. затем сопоставляется со скрытым представлением с помощью того же процесса стандартного автокодировщика,  .
. .
.Параметры модели  и
и  обучаются минимизировать среднюю ошибку реконструкции по обучающим данным, в частности, минимизировать разницу между
обучаются минимизировать среднюю ошибку реконструкции по обучающим данным, в частности, минимизировать разницу между  и исходный неповрежденный ввод
и исходный неповрежденный ввод  . Обратите внимание, что каждый раз случайный пример представлена в модель, новая поврежденная версия генерируется стохастически на основе
. Обратите внимание, что каждый раз случайный пример представлена в модель, новая поврежденная версия генерируется стохастически на основе  .
.
Вышеупомянутый учебный процесс может применяться к любому коррупционному процессу. Некоторыми примерами могут быть аддитивный изотропный гауссовский шум, маскирующий шум (часть входного сигнала, выбранная случайным образом для каждого примера, принудительно равна 0) или шум соли и перца (часть входного сигнала, выбранного случайным образом для каждого примера, устанавливается равным 0). его минимальное или максимальное значение с равномерной вероятностью).
Искажение ввода выполняется только во время обучения. После того, как модель изучила оптимальные параметры, чтобы извлечь представления из исходных данных, никакие повреждения не добавляются.
Сжимающий автокодировщик добавляет явный регуляризатор в свою целевую функцию, который заставляет модель изучать кодирование, устойчивое к небольшим изменениям входных значений. Это регуляризатор соответствует фробениусовой норме от матрицы Якоби из активаций датчика по отношению к входу. Поскольку штраф применяется только к обучающим примерам, этот термин заставляет модель узнавать полезную информацию о обучающем распределении. Конечная целевая функция имеет следующий вид:

Автокодировщик называется сжимающим, потому что CAE рекомендуется отображать окрестность входных точек в меньшую окрестность выходных точек.
DAE подключается к CAE: в пределе небольшого гауссовского входного шума DAE заставляют функцию восстановления сопротивляться небольшим, но конечным входным возмущениям, в то время как CAE заставляют извлеченные функции сопротивляться бесконечно малым входным возмущениям.
Конкретный автокодировщик - это вариант стандартной архитектуры автокодировщика, предназначенный для выбора дискретных функций. [20] В отличие от стандартного автокодировщика, который изучает скрытое представление, которое является комбинацией потенциально всех входных функций, конкретный автокодировщик заставляет скрытое пространство состоять только из ряда функций, указанных пользователем. Автоассоциатор бетона использует непрерывную релаксацию от категоричных распределения , чтобы градиенты , чтобы пройти через слой селектора особенности, что делает возможным использование стандартного обратного распространения , чтобы узнать оптимальное подмножество ввода функции , которые свести к минимуму потери реконструкции.
Вариационные автокодеры (VAE) - это генеративные модели , похожие на генеративные состязательные сети . [21] Их связь с этой группой моделей проистекает в основном из архитектурного сходства с базовым автокодировщиком (конечная цель обучения включает кодировщик и декодер), но их математическая формулировка значительно отличается. VAE представляют собой направленные вероятностные графические модели (DPGM), апостериорные данные которых аппроксимируются нейронной сетью , образуя архитектуру, подобную автокодировщику. В отличие от дискриминативного моделирования, которое направлено на изучение предиктора на основе наблюдения, генеративное моделированиепытается узнать, как генерируются данные, и отразить лежащие в основе причинно-следственные связи. Причинно-следственные связи обладают потенциалом обобщения.
Модели вариационного автокодировщика делают сильные предположения относительно распределения скрытых переменных . Они используют вариационный подход для обучения скрытому представлению, что приводит к дополнительному компоненту потерь и специальной оценке для алгоритма обучения, называемой стохастическим градиентно-вариационным байесовским оценщиком (SGVB).Предполагается, что данные генерируются направленной графической моделью. и что кодировщик изучает приближение
и что кодировщик изучает приближение  к апостериорному распределению
к апостериорному распределению  где
где  и
и  обозначают параметры кодера (модель распознавания) и декодера (генеративная модель) соответственно. Распределение вероятностей скрытого вектора VAE обычно соответствует таковому для обучающих данных намного ближе, чем у стандартного автокодировщика. Задача VAE имеет следующий вид:
обозначают параметры кодера (модель распознавания) и декодера (генеративная модель) соответственно. Распределение вероятностей скрытого вектора VAE обычно соответствует таковому для обучающих данных намного ближе, чем у стандартного автокодировщика. Задача VAE имеет следующий вид:

Здесь,  означает расхождение Кульбака – Лейблера . Априорность перед скрытыми переменными обычно устанавливается как центрированная изотропная многомерная гауссова
означает расхождение Кульбака – Лейблера . Априорность перед скрытыми переменными обычно устанавливается как центрированная изотропная многомерная гауссова  ; однако были рассмотрены альтернативные конфигурации. [24]
; однако были рассмотрены альтернативные конфигурации. [24]
Обычно форма вариационного распределения и распределения правдоподобия выбирается так, чтобы они были факторизованы гауссианами:

где  и
и  выходы энкодера, а
выходы энкодера, а  и
и  выходы декодера. Этот выбор оправдан упрощениями [10], которые он производит при оценке как дивергенции KL, так и члена правдоподобия в вариационной цели, определенной выше.
выходы декодера. Этот выбор оправдан упрощениями [10], которые он производит при оценке как дивергенции KL, так и члена правдоподобия в вариационной цели, определенной выше.
VAE подвергались критике за то, что они создают размытые изображения. [25] Однако исследователи, использующие эту модель, показали только среднее значение распределений,, а не образец изученного гауссовского распределения
 .
.
Было показано, что эти образцы слишком зашумлены из-за выбора факторизованного распределения Гаусса. [25] [26] Используя распределение Гаусса с полной ковариационной матрицей,

может решить эту проблему, но является трудноразрешимым с вычислительной точки зрения и численно нестабильным, так как требует оценки ковариационной матрицы по единственной выборке данных . Однако более поздние исследования показали, что ограниченный подход, когда обратная матрица редко может создавать изображения с высокочастотными деталями.
редко может создавать изображения с высокочастотными деталями.
Крупномасштабные модели VAE были разработаны в различных областях для представления данных в компактном вероятностном скрытом пространстве. Например, VQ-VAE [27] для генерации изображений и Optimus для языкового моделирования.
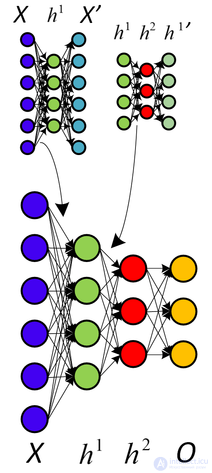
автокодировщикы часто обучаются с помощью однослойного кодировщика и однослойного декодера, но использование глубоких (многоуровневых) кодировщиков и декодеров дает много преимуществ.
Джеффри Хинтон разработал методику обучения многослойных глубоких автокодировщиков. Его метод включает в себя обработку каждого соседнего набора из двух слоев как ограниченной машины Больцмана, так что предварительное обучение приближает хорошее решение, а затем использование обратного распространения ошибки для точной настройки результатов. Эта модель получила название сети глубоких убеждений .
Исследователи обсуждали, будет ли совместное обучение (т.е. обучение всей архитектуры вместе с единственной целью глобальной реконструкции для оптимизации) лучше для глубинных автокодировщиков. Исследование 2015 года показало, что при совместном обучении изучаются лучшие модели данных, а также более репрезентативные функции для классификации по сравнению с послойным методом. [30] Однако их эксперименты показали, что успех совместного обучения сильно зависит от принятых стратегий регуляризации.
В последнее время автокодировщики мало используются для описанного «жадного» послойного предобучения глубоких нейронных сетей. После того, как этот метод был предложен в 2006 г Джеффри Хинтоном и Русланом Салахутдиновым, достаточно быстро оказалось, что новых методов инициализации случайными весами оказывается достаточно для дальнейшего обучения глубоких сетей. Предложенная в 2014 г. пакетная нормализация позволила обучать еще более глубокие сети, предложенный же в конце 2015 г. метод остаточного обучения позволил обучать сети произвольной глубины.
Основными практическими приложениями автокодировщиков остаются уменьшение шума в данных, а также уменьшение размерности многомерных данных для визуализации. С определенными оговорками, касающимися размерности и разреженности данных, автокодировщики могут позволять получать проекции многомерных данных, которые оказываются лучше тех, что дает метод главных компонент либо какой-либо другой классический метод.
Двумя основными приложениями автокодировщиков являются уменьшение размерности и поиск информации , но современные варианты оказались успешными при применении к различным задачам.
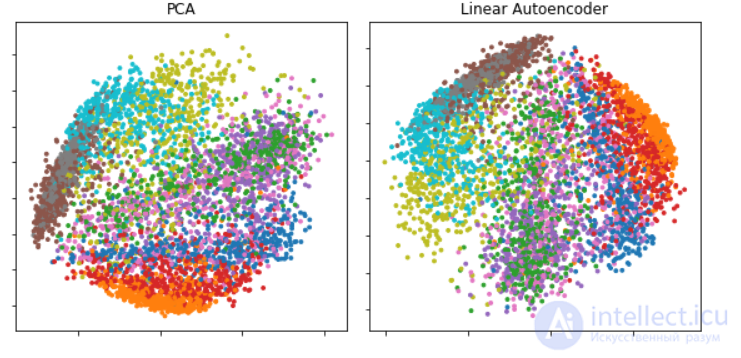
Снижение размерности было одним из первых приложений глубокого обучения и одним из первых мотивов изучения автокодировщиков. Задача состоит в том, чтобы найти подходящий метод проецирования, который отображает данные из пространства высоких признаков в пространство низких признаков.
Одной из важных статей по этому вопросу была статья Хинтона 2006 г .: [29] в этом исследовании он предварительно обучил многослойный автокодировщик со стеком RBM, а затем использовал их веса для инициализации глубокого автокодировщика с постепенно уменьшающимися скрытыми слоями, пока не столкнулся с узким местом 30 нейронов. Полученные 30 измерений кода дали меньшую ошибку реконструкции по сравнению с первыми 30 компонентами анализа главных компонентов (PCA) и получили представление, которое было качественно легче интерпретировать, четко разделяя кластеры данных.
Представление данных в пространстве меньшей размерности может повысить производительность таких задач, как классификация. Действительно, многие формы уменьшения размерности помещают семантически связанные примеры рядом друг с другом , способствуя обобщению.

Реконструкция изображений 28x28 пикселей с помощью автокодировщика с размером кода два (двухуровневый скрытый слой) и реконструкция из первых двух основных компонентов PCA. Изображения взяты из набора данных Fashion MNIST . [32]
Если используются линейные активации или только один скрытый сигмовидный слой, то оптимальное решение для автокодировщика сильно связано с анализом главных компонентов (PCA). Веса автокодировщика с одним скрытым слоем размера. (где меньше размера ввода) охватывает то же векторное подпространство, что и первое, главные компоненты, и выход автокодировщика является ортогональной проекцией на это подпространство. Веса автокодера не равны основным компонентам и, как правило, не ортогональны, но главные компоненты могут быть восстановлены из них с использованием разложения по сингулярным значениям .
(где меньше размера ввода) охватывает то же векторное подпространство, что и первое, главные компоненты, и выход автокодировщика является ортогональной проекцией на это подпространство. Веса автокодера не равны основным компонентам и, как правило, не ортогональны, но главные компоненты могут быть восстановлены из них с использованием разложения по сингулярным значениям .
Однако потенциал автокодировщиков заключается в их нелинейности, что позволяет модели изучать более мощные обобщения по сравнению с PCA и восстанавливать входные данные со значительно меньшими потерями информации.
Информационный поиск выигрывает, в частности, от уменьшения размерности, поскольку поиск может стать более эффективным в определенных типах низкоразмерных пространств. автокодировщикы действительно были применены к семантическому хешированию, предложенному Салахутдиновым и Хинтоном в 2007 году. Обучая алгоритм для создания низкоразмерного двоичного кода, все записи базы данных могут храниться в хэш-таблице, отображающей двоичные кодовые векторы на записи. Эта таблица затем будет поддерживать поиск информации, возвращая все записи с тем же двоичным кодом, что и запрос, или немного менее похожие записи, перевернув некоторые биты из кодировки запроса.
Еще одно применение автокодировщиков - обнаружение аномалий . Научившись воспроизводить наиболее важные особенности обучающих данных при некоторых из описанных ранее ограничений, модель поощряется к тому, чтобы научиться точно воспроизводить наиболее часто наблюдаемые характеристики. При столкновении с аномалиями модель должна ухудшить свои характеристики восстановления. В большинстве случаев для обучения автокодировщика используются только данные с обычными экземплярами; в других случаях частота аномалий мала по сравнению с набором наблюдений, так что их вклад в изученное представление можно игнорировать. После обучения автокодировщик будет точно реконструировать «нормальные» данные, но не сможет сделать это с незнакомыми аномальными данными. Ошибка реконструкции (ошибка между исходными данными и их реконструкцией малой размерности) используется в качестве оценки аномалии для обнаружения аномалий.
Однако недавняя литература показала, что некоторые модели автокодирования могут, как ни странно, очень хорошо восстанавливать аномальные примеры и, следовательно, не могут надежно выполнять обнаружение аномалий.
Характеристики автокодировщиков полезны при обработке изображений.
Один из примеров можно найти в сжатии изображений с потерями , когда автокодеры превзошли другие подходы и оказались конкурентоспособными по сравнению с JPEG 2000 .
Еще одно полезное применение автокодировщиков при предварительной обработке изображений - это шумоподавление .
автокодировщикы нашли применение в более сложных контекстах, таких как медицинская визуализация, где они использовались для шумоподавления изображения , а также для сверхвысокого разрешения В диагностике с использованием изображений в экспериментах автокодировщикы применялись для обнаружения рака груди и для моделирования связи между когнитивным снижением болезни Альцгеймера и скрытыми функциями автокодировщика, обученного с помощью МРТ .
В 2019 году молекулы, созданные с помощью вариационных автокодировщиков, были проверены экспериментально на мышах.
Недавно составная структура автокодировщика дала многообещающие результаты в прогнозировании популярности сообщений в социальных сетях , что полезно для стратегий онлайн-рекламы.
автокодировщик был применен для машинного перевода , который обычно называют нейронным машинным переводом (NMT). В NMT тексты обрабатываются как последовательности, которые должны быть закодированы в процедуру обучения, в то время как на стороне декодера генерируются целевые языки. Специфичные для языка автокодировщикы включают лингвистические функции в процедуру обучения, такие как функции разложения китайского языка.
Данная статья про автокодировщик подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое автокодировщик, автоассоциатор и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Вычислительный интеллект

Комментарии