Лекция
Привет, Вы узнаете о том , что такое перцептивное хеширование, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое перцептивное хеширование , настоятельно рекомендую прочитать все из категории Информационная безопасность- Криптография и криптоанализ, Стеганография и Стегоанализ.
перцептивное хеширование — это использование алгоритма снятия отпечатков пальцев , который создает фрагмент, хеш или отпечаток пальца различных форм мультимедиа . Перцептивный хэш — это тип хеша, чувствительного к местонахождению , который аналогичен, если характеристики мультимедиа схожи. В этом отличие от криптографического хеширования , которое основано на лавинном эффекте небольшого изменения входного значения, вызывающего резкое изменение выходного значения. Перцептивные хэш-функции широко используются при обнаружении случаев нарушения авторских прав в Интернете , а также в цифровой криминалистике из-за возможности корреляции между хэшами, позволяющей находить похожие данные (например, с другим водяным знаком ).
Перцептивные хэши — это другая концепция по сравнению с криптографическими хеш-функциями, такими как MD5 и SHA1. В случае криптографических хешей значения хеш-функции являются случайными. Данные, используемые для генерации хэша, действуют как случайное начальное число, поэтому одни и те же данные генерируют один и тот же результат, но разные данные создают разные результаты. Сравнение двух значений хеш-функции SHA1 на самом деле говорит вам только о двух вещах. Если хеши разные, то и данные разные. И если хеши одинаковые, то и данные, скорее всего, те же. Напротив, перцептивные хеши можно сравнивать, что дает вам ощущение сходства между двумя наборами данных.
Работа Марра и Хилдрет 1980 года является плодотворной работой в этой области.
Диссертация Кристофа Заунера, опубликованная в июле 2010 года, представляет собой хорошо написанное введение в эту тему.
В июне 2016 года Азаде Амир Асгари опубликовал работу по надежной подделке хеша изображений. Асгари отмечает, что перцептивная хеш-функция, как и любой другой алгоритм, подвержена ошибкам.
В декабре 2017 года исследователи отметили, что поиск изображений в Google основан на перцептивном хеше.
В исследовании, опубликованном в ноябре 2021 года, следователи сосредоточились на манипулируемом изображении Стейси Абрамс , которое было опубликовано в Интернете до ее поражения на выборах губернатора Джорджии в 2018 году . Они обнаружили, что алгоритм pHash уязвим для злоумышленников.
Исследование, опубликованное в январе 2019 года в Университете Нортумбрии, показало, что в отношении видео его можно использовать для одновременной идентификации аналогичного контента для обнаружения копий видео и обнаружения вредоносных манипуляций для аутентификации видео. Предлагаемая система работает лучше, чем существующие методы хеширования видео, как с точки зрения идентификации, так и с точки зрения аутентификации.
Исследование перцептивного хеширования звука на основе глубокого обучения, опубликованное в мае 2020 года Хьюстонским университетом, показало лучшую производительность, чем традиционные методы снятия отпечатков пальцев, для обнаружения похожего / скопированного звука, подверженного преобразованиям.
Помимо использования в цифровой криминалистике, исследование российской группы, опубликованное в 2019 году, показало, что перцептивное хеширование можно применять в самых разных ситуациях. Подобно сравнению изображений на предмет нарушения авторских прав, группа обнаружила, что его можно использовать для сравнения и сопоставления изображений в базе данных. Предложенный ими алгоритм оказался не только эффективным, но и более эффективным, чем стандартные средства поиска изображений в базе данных.
В июле 2019 года китайская группа сообщила, что они обнаружили перцепционный хэш для шифрования речи , который оказался эффективным. Им удалось создать систему, в которой шифрование было не только более точным, но и более компактным.
Еще в августе 2021 года Apple Inc сообщила о системе материалов о сексуальном насилии над детьми (CSAM), известной как NeuralHash . В техническом сводном документе, который хорошо объясняет систему с многочисленными диаграммами и примерами фотографий, говорится: «Вместо сканирования изображений [на корпоративных] iCloud [серверах] система выполняет сопоставление на устройстве, используя базу данных известных хэшей изображений CSAM, предоставленную [ Национальный центр по делам пропавших и эксплуатируемых детей ] (NCMEC) и другие организации по обеспечению безопасности детей Apple дополнительно преобразует эту базу данных в нечитаемый набор хешей, который надежно хранится на устройствах пользователей».
В эссе, озаглавленном «Проблема перцептивных хэшей», Оливер Кудерле описывает поразительную коллизию, созданную частью коммерческого программного обеспечения для нейронных сетей типа NeuralHash. Фотопортрет реальной женщины (Adobe Stock) с помощью алгоритма теста сводится к тому же хешу, что и фотография произведения абстрактного искусства (из базы данных «deposit photos»). Оба образца изображений находятся в коммерческих базах данных. Кудерле обеспокоен подобными столкновениями. «Эти дела будут проверяться вручную. То есть, по словам Apple, сотрудник Apple затем будет просматривать ваши (отмеченные) фотографии…
Перцептивные хеши беспорядочны. Когда такие алгоритмы используются для обнаружения преступной деятельности, особенно в масштабах крупных компаний, многие невинные люди потенциально могут столкнуться с серьезными проблемами... Излишне говорить, что меня это очень беспокоит».
Исследователи продолжают публиковать комплексный анализ под названием «Обучение взлому глубокого перцептивного хеширования: пример использования NeuralHash», в котором они исследуют уязвимость NeuralHash как представителя алгоритмов глубокого перцептивного хеширования к различным атакам. Их результаты показывают, что хеш-коллизии между различными изображениями могут быть достигнуты с помощью небольших изменений, внесенных в изображения. По мнению авторов, эти результаты демонстрируют реальную вероятность подобных атак и позволяют выявить и возможно привлечь к ответственности невиновных пользователей. Они также заявляют, что обнаружения незаконных материалов можно легко избежать и перехитрить систему с помощью простых преобразований изображений, например, предоставляемых бесплатными редакторами изображений. Авторы предполагают, что их результаты применимы и к другим алгоритмам глубокого перцептивного хеширования, ставя под сомнение их общую эффективность и функциональность в таких приложениях, как сканирование на стороне клиента и управление чатом.
перцептивный хэш-алгоритмы описывают класс функций для генерации сравнимых хэшей. Они используют различные свойства изображения для построения индивидуального «отпечатка». В дальнейшем эти «отпечатки» можно сравнивать друг с другом.
Если хэши отличаются, значит, данные разные. Если хэши совпадают, то данные, скорее всего, одинаковые (поскольку существует вероятность коллизий, то одинаковые хэши не гарантируют совпадения данных). Об этом говорит сайт https://intellect.icu . В этой статье речь пойдет о нескольких популярных методах построения перцептивный хешей изображения, а также о простом способе борьбы с коллизиями. Всем кому интересно, прошу под кат.
Существует много различных подходов к формированию перцептивный хеша изображения. Всех их объединяет 3 основных этапа:
В данной публикации мы не будем касаться реализации приведенных алгоритмов. Она носит обзорный характер и рассказывает о различных подходах к построению хэшей.
Рассмотрим различные хеш алгоритмы: Simple Hash , DCT Based Hash ,[11], Radial Variance Based Hash , и Marr- Hildreth Operator Based Hash , .
Суть данного алгоритма заключается в отображении среднего значения низких частот. В изображениях высокие частоты обеспечивают детализацию, а низкие – показывают структуру. Поэтому для построения такой хеш-функции, которая для похожих изображений будет выдавать близкий хеш, нужно избавиться от высоких частот. Принцип работы:
Полученный хеш устойчив к масштабированию, сжатию или растягиванию изображения, изменению яркости, контраста, манипуляциями с цветами. Но главное достоинство алгоритма – скорость работы. Для сравнения хешей этого типа используется функция нормированного расстояния Хэмминга.

Исходное изображение

Полученный «отпечаток»
Дискретное косинусное преобразование (ДКП, DCT) – одно из ортогональных преобразований, тесно связанное с дискретным преобразованием Фурье (ДПФ) и являющееся гомоморфизмом его векторного пространства. ДКП, как и любое Фурье-ориентированное преобразование, выражает функцию или сигнал (последовательность из конечного числа точек данных) в виде суммы синусоид с различными частотами и амплитудами. ДКП использует только косинусные функции, в отличие от ДПФ, использующего и косинусные, и синусные функции. Существует 8 типов ДКП . Самый распространенный – второй тип. Его мы и будем использовать для построения хеш-функции.
Давайте разберемся, что такое второй тип ДКП:
Пусть x[m], где m = 0,…, N — 1 — последовательность сигнала длин N. Определим второй тип ДКП, как
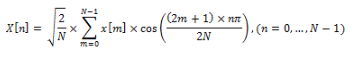
Это выражение можно переписать как:
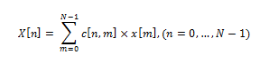
где c[n,m] – элемент матрицы ДКП на пересечении строки с номером n и столбца с номером m.
ДКП матрица определяется как:
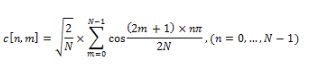
Данная матрица очень удобна, для вычисления ДКП. ДКП может быть вычислена заранее, для любой необходимой длины. Таким образом ДКП может быть представлена в виде:
ДКП=M×I×M'
Где M – ДКП матрица, I – изображение квадратного размера, M’ – обратная матрица.
Идея алгоритма Radial Variance Based Hash состоит в построении лучевого вектора дисперсии (ЛВД) на основе преобразования Радона . Затем к ЛВД применяется ДКП и вычисляется хеш. Преобразование Радона — это интегральное преобразование функции многих переменных вдоль прямой. Оно устойчиво к обработке изображений с помощью различных манипуляций (например, сжатия) и геометрических преобразований (например, поворотов). В двумерном случае преобразование Радона для функции f(x,y) выглядит так:

Преобразование Радона имеет простой геометрический смысл – это интеграл от функции вдоль прямой, перпендикулярной вектору n = (cos a,sin a) и проходящей на расстоянии s (измеренного вдоль вектора n, с соответствующим знаком) от начала координат.
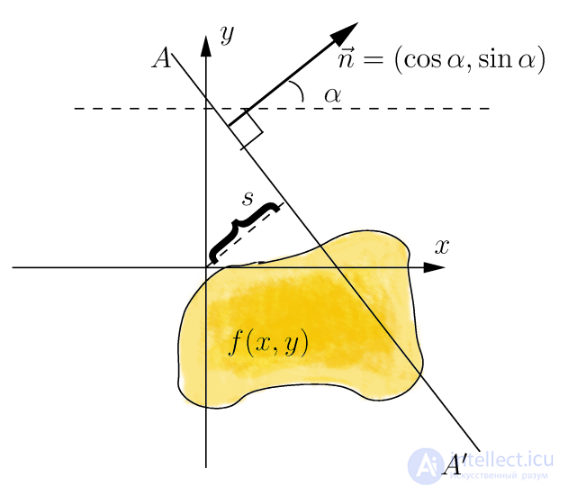
Чтобы преобразование Радона расширить для дискретных изображений, линейный интеграл по прямой d = x ∙ cos α + y ∙ sin α может быть аппроксимирован путем суммирования значений всех пикселей, лежащих в линии шириной один пиксель:
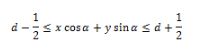
Позже было обнаружено, что лучше использовать дисперсию вместо суммы значений пикселей вдоль линии проекции . Дисперсия намного лучше обрабатывает яркостные разрывы вдоль линии проекции. Такие яркостные разрывы появляются из-за краев, которые ортогональны линии проекции.
Теперь определим лучевой вектор дисперсии. Пусть Г(α) – набор пикселей на линии проекции, соответствующей данному углу. Пусть (x′, y′) – координаты центрального пикселя на изображении. x, y принадлежат Г(α) тогда и только тогда, когда
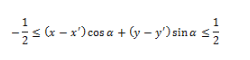
Теперь определим лучевой вектор дисперсии (radial variance vector):
Пусть I(x,y) обозначает яркость пикселя (x,y), #Г(α) – мощность множества, тогда лучевой вектор дисперсии R[α], где α = 0,1, … ,179 определим как
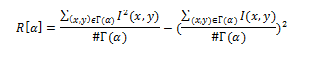
Достаточно построить вектор по 180 значениям угла, так как преобразование Радона является симметричным. Полученный вектор можно использовать для построения хеша, но в этом алгоритме предлагается еще некоторое улучшение — применить ДКП к полученному вектору. В результате получится вектор, наследующий все важные свойства ДКП. В качестве хеша берутся первые 40 коэффициентов полученного вектора, которые соответствуют низким частотам. Таким образом, размер полученного хеша — 40 байт.
Оператор Марра-Хилдрета позволяет определять края на изображении. Вообще говоря, границу на изображении можно определить как край или контур, отделяющий соседние части изображения, которые имеют сравнительно отличные характеристики в соответствии с некоторыми особенностями. Этими особенностями могут быть цвет или текстура, но чаще всего используется серая градация цвета изображения (яркость). Результатом определения границ является карта границ. Карта границ описывает классификацию границ для каждого пикселя изображения. Если границы определять как резкое изменение яркости, то для их нахождения можно использовать производные или градиент.
Пусть функция обозначает уровень яркости для линии (одномерный массив пикселей). Первый подход определения границ заключается в нахождении локальных экстремумов функции, то есть первых производных. Второй подход (метод Лапласа) заключается в нахождении вторых производных .
Оба подхода могут быть адаптированы для случая двумерных дискретных изображений, но с некоторыми проблемами. Для нахождения производных в дискретном случае требуется аппроксимация. Кроме того, шум на изображении может значительно ухудшить процесс поиска границ. Поэтому перед определением границ к изображению нужно применить какой-либо фильтр, подавляющий шумы. Для построения хеша можно выбрать алгоритм, использующий оператор Лапласа (2 подход) и фильтр Гаусса.
Определим непрерывный Лапласиан (оператор Лапласа):
Пусть определяет яркость на изображении. Тогда непрерывный Лапласиан определим как:
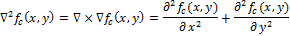
Обращения в ноль и есть точки, соответствующие границе функции , так как это точки, при которых вторая производная обращается в ноль. Различные фильтры (дискретные операторы Лапласа) могут быть получены из непрерывного Лапласиана. Такой фильтр , может быть применен к дискретному изображению с помощью использования свертки функций. Оператор Лапласа для изображения можно переписать как:
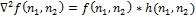
где * обозначает свертку функций. Чтобы построить карту границ, нужно найти обращения в ноль дискретного оператора .
Теперь рассмотрим оператор Марра-Хилдрета. Он также называется Лапласиан от фильтра Гаусса (LoG) – это особенный тип дискретного оператора Лапласа. LoG конструируется с помощью применения оператора Лапласа к фильтру (функции) Гаусса. Особенность этого оператора в том, что он может выделять границы в определенном масштабе. Переменную масштаба можно варьировать для того, чтобы лучше выявить границы.
Фильтр Гаусса определим как:
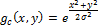
Свертку с операцией Лапласа можно поменять местами, потому что производная и свертка – линейные операторы:
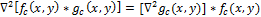
Это свойство позволяет заранее вычислить оператор , потому что он никак не зависит от изображения ().
(оператор Марра-Хилдрета, Лапласиан от фильтра Гаусса, LoG). LoG hc(x, y) определим как:
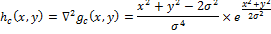
Чтобы использовать LoG в дискретной форме, сделаем дискретизацию данного уравнения, подставив нужную переменную масштаба. По умолчанию ее значение принимается как 1.0. Затем фильтр можно применить к изображению, используя дискретную свертку.
Определим дискретную свертку:
Пусть x,y,z — пиксельная ширина, длина и глубина изображения I.
Результат R свертки изображения I c маской M определим как:
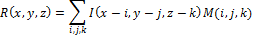
Расстояние Хэмминга определяет количество различных позиций между двумя бинарными последовательностями.
Определение:
Пусть А – алфавит конечной длины. 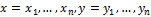 – бинарные последовательности (векторы). Расстояние Хэмминга Δ между x и y определим как:
– бинарные последовательности (векторы). Расстояние Хэмминга Δ между x и y определим как:
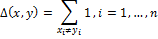
Этот способ сравнения хеш-значений используется в методе DCT Based Hash. Хеш занимает размер 8 байт, поэтому расстояние Хэмминга лежит в отрезке [0, 64]. Чем меньше значение Δ, тем более похожи изображения.
Для облегчения сравнения расстояние Хэмминга можно нормировать с помощью длины векторов:
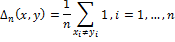
Нормированное расстояние Хэмминга используется в алгоритмах Simple Hash и Marr-Hildreth Operator Based Hash. Расстояние Хэмминга лежит в промежутке [0,1] и чем ближе Δ к 0, тем более похожи изображения.
Корреляцию между двумя сигналами определим как:
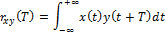
где x(t) и y(t) — две непрерывные функции вещественных чисел. Функция rxy(t) описывает смещение этих двух сигналов относительно времени T. Переменная T определяет насколько сигнал смещен слева. Если сигналы x(t) и y(t) различны, функция rxy T называется взаимнокорреляционной.
Определим Нормированную взаимнокорреляционную функцию:
Пусть xi и yi, где i = 0, … N − 1 – две последовательности вещественных чисел, а N – длина обеих последовательностей.
НВФ с задержкой d определим как:
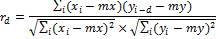
где mx и my обозначают среднее значение для соответствующей последовательности.
Пик взаимнокорреляционной функции (PCC) – максимальное значение функции rd, которое может быть достигнуто на промежутке d = 0, N.
PCC используется для сравнения хеш-значений в алгоритме Radial Variance Based Hash. PCC ∈ [0,1], чем больше его значение, тем более похожи изображения.
Виды редакционных расстояний
Есть несколько основных редакционных расстояний. Основное отличие между ними — набор операций, который разрешено использовать.
В таблице ниже перечислены наиболее используемые редакционные расстояния и операции, разрешенные для каждого из них.
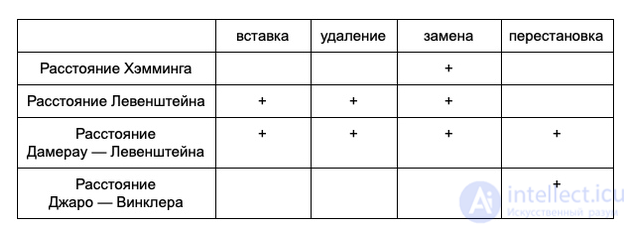
Расстояние Хэмминга разрешает только замены, так что с помощью него можно сравнивать только строки одинаковой длины: мы не можем удлинить строку с помощью вставки или укоротить ее с помощью удаления.
Расстояние Дамерау—Левенштейна разрешает все четыре операции: замену, вставку, удаление и перестановку соседних символов. Федерик Демерау показал, что эти четыре операции покрывают порядка 80% ошибок при письме.
Исследование, описанное в статье про перцептивное хеширование, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое перцептивное хеширование и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Информационная безопасность- Криптография и криптоанализ, Стеганография и Стегоанализ

Комментарии