Лекция
Сразу хочу сказать, что здесь никакой воды про обучение без учителя, и только нужная информация. Для того чтобы лучше понимать что такое обучение без учителя, алгоритм k-means, обучение с частичным привлечением учителя , настоятельно рекомендую прочитать все из категории Машинное обучение.
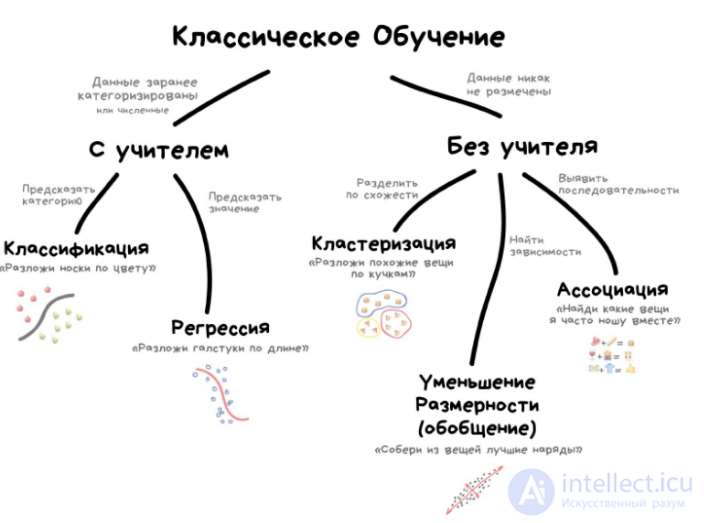
Обучение нейронных сетей можно разделить на два основных типа: обучение с учителем (supervised learning) и обучение без учителя (unsupervised learning). Давайте рассмотрим их отличия и назначения.
Обучение с учителем (Supervised Learning):
Обучение без учителя (Unsupervised Learning):
Таким образом, основное различие между обучением с учителем и без учителя заключается в наличии или отсутствии размеченных данных, и каждый из этих методов имеет свои собственные назначения и применения в машинном обучении.
Обучение без учителя (англ. Unsupervised learning, самообучение, спонтанное обучение) — один из способов машинного обучения, при решении которых испытуемая система спонтанно обучается выполнять поставленную задачу, без вмешательства со стороны экспериментатора. С точки зрения кибернетики, является одним из видов кибернетического эксперимента. Как правило, это пригодно только для задач, в которых известны описания множества объектов (обучающей выборки), и требуется обнаружить внутренние взаимосвязи, зависимости, закономерности, существующие между объектами.
Обучение без учителя часто противопоставляется обучению с учителем, когда для каждого обучающего объекта принудительно задается «правильный ответ», и требуется найти зависимость между стимулами и реакциями системы.
Обучить нейронную сеть можно разными способами: с учителем, без учителя, с подкреплением. Но как выбрать оптимальный алгоритм и чем они отличаются? Есть несколько способов собрать мебель из IKEA. Каждый из них приводит к собранному дивану или стулу. Но в зависимости от предмета мебели и его составляющих один способ будет более разумным, чем другие.
Есть руководство по эксплуатации и все нужные детали? Просто следуйте инструкции. Ну как, получается? Можно выбросить руководство и работать самостоятельно. Но стоит перепутать порядок действий, и уже вам решать, что делать с этой кучей деревянных болтов и досок.
Все то же самое с глубоким обучением (deep learning). Разработчик предпочтет алгоритм с конкретным способом обучения, учитывая вид данных и стоящую перед ним задачу.
Обучение без учителя (Unsupervised Learning) было изобретено позже, аж в 90-е, и на практике используется реже. Но бывают задачи, где у нас просто нет выбора.
Размеченные данные, как я сказал, дорогая редкость. Но что делать если я хочу, например, написать классификатор автобусов — идти на улицу руками фотографировать миллион сраных икарусов и подписывать где какой? Так и жизнь вся пройдет, а у меня еще игры в стиме не пройдены.
Когда нет разметки, есть надежда на капитализм, социальное расслоение и миллион китайцев из сервисов , которые готовы делать для вас что угодно за пять центов. Так обычно и поступают на практике.
Либо, можно попробовать обучение без учителя. Хотя, честно говоря, из своей практики я не помню чтобы где-то оно сработало хорошо.
Обучение без учителя, все же, чаще используют как метод анализа данных, а не как основной алгоритм. Специальный кожаный мешок с дипломом МГУ вбрасывает туда кучу мусора и наблюдает. Кластеры есть? Зависимости появились? Нет? Ну штош, продолжай, труд освобождает. Тыж хотел работать в датасаенсе.

Несмотря на многочисленные прикладные достижения, обучение с учителем критиковалось за свою биологическую неправдоподобность. Трудно вообразить обучающий механизм в мозге, который бы сравнивал желаемые и действительные значения выходов, выполняя коррекцию с помощью обратной связи. Если допустить подобный механизм в мозге, то откуда тогда возникают желаемые выходы? Обучение без учителя является намного более правдоподобной моделью обучения в биологической системе. Развитая Кохоненом и многими другими, она не нуждается в целевом векторе для выходов и, следовательно, не требует сравнения с предопределенными идеальными ответами .
Для построения теории и отхода от кибернетического эксперимента в различных теориях эксперимент с обучением без учителя пытаются формализовать математически. Существует много различных подвидов постановки и определения данной формализации. Одна из которых отражена в теории распознавания образов.
Такой отход от эксперимента и построение теории связаны с различным мнением специалистов во взглядах. Различия, в частности, заключаются при ответе на вопрос: «Возможны ли единые принципы адекватного описания образов различной природы, или же такое описание каждый раз есть задача для специалистов конкретных знаний?».
В первом случае постановка должна быть нацелена на выявление общих принципов использования априорной информации при составлении адекватного описания образов. Важно, что здесь априорные сведения об образах различной природы разные, а принцип их учета один и тот же. Во втором случае проблема получения описания выносится за рамки общей постановки, и теория обучения машин распознаванию образов с точки зрения статистической теории обучения распознаванию образов может быть сведена к проблеме минимизации среднего риска в специальном классе решающих правил .
В теории распознавания образов различают в основном три подхода к данной проблеме :
Идеально размеченные и чистые данные достать нелегко. Поэтому иногда перед алгоритмом стоит задача найти заранее не известные ответы. Вот где нужно обучение без учителя.
В обучении без учителя (unsupervised learning) у модели есть набор данных, и нет явных указаний, что с ним делать. Нейронная сеть пытается самостоятельно найти корелляции в данных, извлекая полезные признаки и анализируя их.

Кластеризация данных на основе общих признаков
В зависимости от задачи модель систематизирует данные по-разному.
В обучении без учителя сложно вычислить точность алгоритма, так как в данных отсутствуют «правильные ответы» или метки. Но размеченные данные часто ненадежные или их слишком дорого получить. В таких случаях, предоставляя модели свободу действий для поиска зависимостей, можно получить хорошие результаты.
Это золотая середина.
Обучение с частичным привлечением учителя (semi-supervised learning) характеризуется своим названием: обучающий датасет содержит как размеченные, так и неразмеченные данные. Об этом говорит сайт https://intellect.icu . Этот метод особенно полезен, когда трудно извлечь из данных важные признаки или разметить все объекты – трудоемкая задача.
Обучение с частичным привлечением учителя часто используют для решения медицинских задач, где небольшое количество размеченных данных может привести к значительному повышению точности
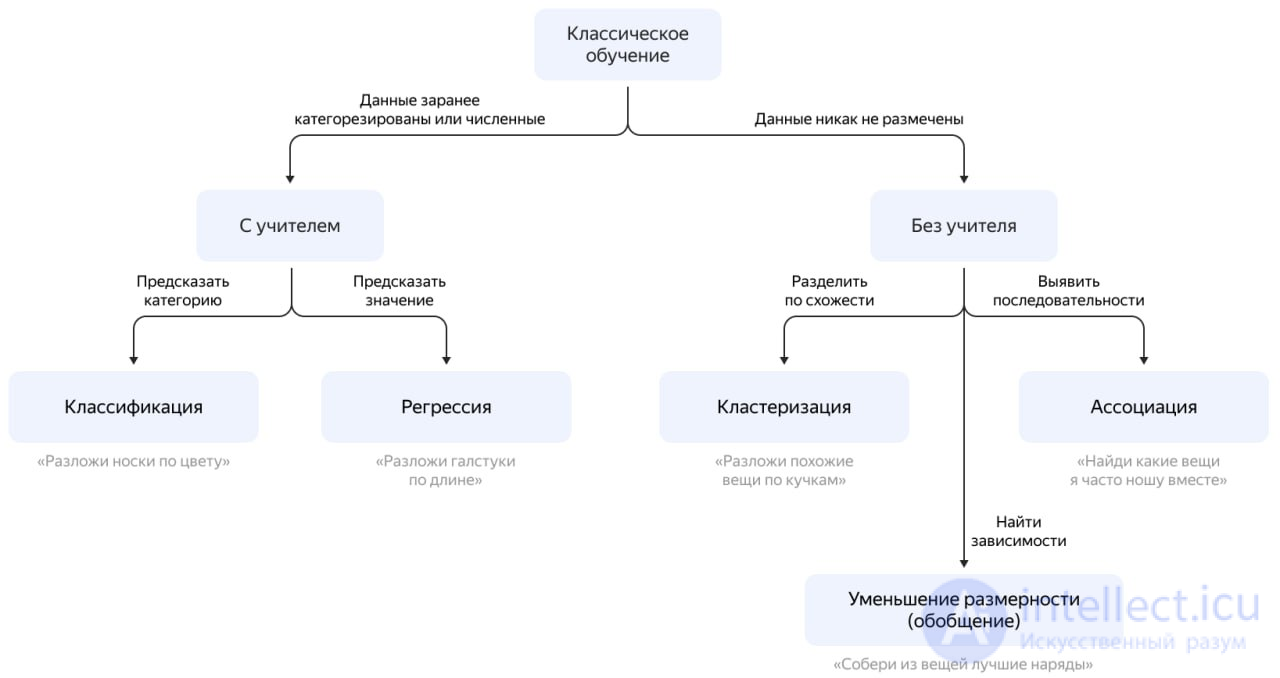
Этот метод машинного обучения распространен для анализа медицинских изображений, таких как сканы компьютерной томографии или МРТ. Опытный рентгенолог может разметить небольшое подмножество сканов, на которых выявлены опухоли и заболевания. Но вручную размечать все сканы — слишком трудоемкая и дорогостоящая задача. Тем не менее нейронная сеть может извлечь информацию из небольшой доли размеченных данных и улучшить точность предсказаний по сравнению с моделью, обучающейся исключительно на неразмеченных данных.
Популярный метод обучения, для которого требуется небольшой набор размеченных данных, заключается в использовании генеративно-состязательной сети или GAN.
Представьте себе соревнование двух нейронных сетей, где каждая пытается перехитрить другую. Это GAN. Одна из сетей, генератор, пытается создать новые объекты данных, которые имитируют обучающую выборку. Другая сеть, дискриминатор, оценивает, являются ли эти сгенерированные данные реальными или поддельными. Сети взаимодействуют и циклично совершенствуются, поскольку дискриминатор старается лучше отделять подделки от оригиналов, а генератор пытается создавать убедительные подделки.

Как работает GAN: дискриминатору «D» показывают исходные изображения и данные, созданные генератором «G». Дискриминатор должен определить, какие изображения являются реальными, а какие поддельными.
Экспериментальная схема обучения без учителя часто используется в теории распознавания образов, машинном обучении. При этом в зависимости от подхода формализуется в ту или иную математическую концепцию. И только в теории искусственных нейронных сетей задача решается экспериментально, применяя тот или иной вид нейросетей. При этом, как правило, полученная модель может не иметь интерпретации, что иногда относят к минусам нейросетей. Но тем не менее, результаты получаются ничем не хуже, и при желании могут быть интерпретированы при применении специальных методов.
Кластерный анализ
Эксперимент обучения без учителя при решении задачи распознавания образов можно сформулировать как задачу кластерного анализа. Выборка объектов разбивается на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Исходная информация представляется в виде матрицы расстояний.
Методы решения
Кластеризация может играть вспомогательную роль при решении задач классификации и регрессии. Для этого нужно сначала разбить выборку на кластеры, затем к каждому кластеру применить какой-нибудь совсем простой метод, например, приблизить целевую зависимость константой.
Методы решения
Обобщение понятий
Так же как и в случае экспериментов по различению, что математически может быть сформулированно как кластеризация, при обобщении понятий можно исследовать спонтанное обобщение, при котором критерии подобия не вводятся извне или не навязываются экспериментатором.
При этом в эксперименте по «чистому обобщению» от модели мозга или перцептрона требуется перейти от избирательной реакции на один стимул (допустим, квадрат, находящийся в левой части сетчатки) к подобному ему стимулу, который не активизирует ни одного из тех же сенсорных окончаний (квадрат в правой части сетчатки). К обобщению более слабого вида относится, например, требование, чтобы реакции системы распространялись на элементы класса подобных стимулов, которые не обязательно отделены от уже показанного ранее (или услышанного, или воспринятого на ощупь) стимула.
Задачи сокращения размерности Исходная информация представляется в виде признаковых описаний. Задача состоит в том, чтобы найти такие наборы признаков, и такие значения этих признаков, которые особенно часто (неслучайно часто) встречаются в признаковых описаниях объектов.
Исходная информация представляется в виде признаковых описаний, причем число признаков может быть достаточно большим. Задача состоит в том, чтобы представить эти данные в пространстве меньшей размерности, по возможности, минимизировав потери информации.
Методы решения
Некоторые методы кластеризации и снижения размерности строят представления выборки в пространстве размерности два. Это позволяет отображать многомерные данные в виде плоских графиков и анализировать их визуально, что способствует лучшему пониманию данных и самой сути решаемой задачи.
Методы решения
«Разделяет объекты по неизвестному признаку. Машина сама решает как лучше»
Сегодня используют для:
Популярные алгоритмы: Метод K-средних, Mean-Shift, DBSCAN
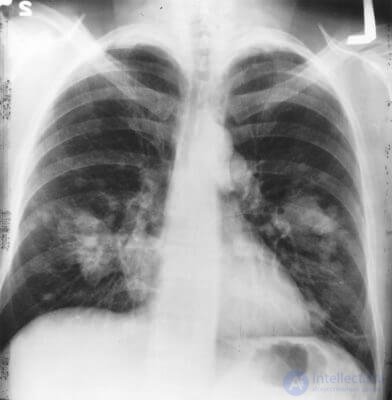
Кластеризация — это классификация, но без заранее известных классов. Она сама ищет похожие объекты и объединяет их в кластеры. Количество кластеров можно задать заранее или доверить это машине. Похожесть объектов машина определяет по тем признакам, которые мы ей разметили — у кого много схожих характеристик, тех давай в один класс.
Отличный пример кластеризации — маркеры на картах в вебе. Когда вы ищете все крафтовые бары в Москве, движку приходится группировать их в кружочки с циферкой, иначе браузер зависнет в потугах нарисовать миллион маркеров.
Более сложные примеры кластеризации можно вспомнить в приложениях iPhoto или Google Photos, которые находят лица людей на фотографиях и группируют их в альбомы. Приложение не знает как зовут ваших друзей, но может отличить их по характерным чертам лица. Типичная кластеризация.
Правда для начала им приходится найти эти самые «характерные черты», а это уже только с учителем.
Сжатие изображений — еще одна популярная проблема. Сохраняя картинку в PNG, вы можете установить палитру, скажем, в 32 цвета. Тогда кластеризация найдет все «примерно красные» пиксели изображения, высчитает из них «средний красный по больнице» и заменит все красные на него. Меньше цветов — меньше файл.
Проблема только, как быть с цветами типа Cyan  — вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.
— вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.

Искать центроиды удобно и просто, но в реальных задачах кластеры могут быть совсем не круглой формы. Вот вы геолог, которому нужно найти на карте схожие по структуре горные породы — ваши кластеры не только будут вложены друг в друга, но вы еще и не знаете сколько их вообще получится.
Хитрым задачам — хитрые методы. DBSCAN, например. Он сам находит скопления точек и строит вокруг кластеры. Его легко понять, если представить, что точки — это люди на площади. Находим трех любых близко стоящих человека и говорим им взяться за руки. Затем они начинают брать за руку тех, до кого могут дотянуться. Так по цепочке, пока никто больше не сможет взять кого-то за руку — это и будет первый кластер. Повторяем, пока не поделим всех. Те, кому вообще некого брать за руку — это выбросы, аномалии. В динамике выглядит довольно красиво:
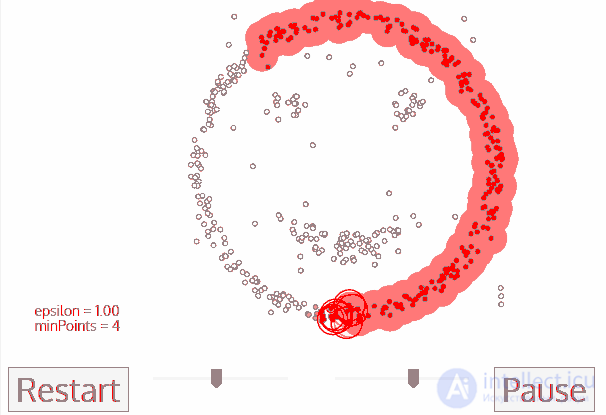
Как и классификация, кластеризация тоже может использоваться как детектор аномалий. Поведение пользователя после регистрации резко отличается от нормального? Заблокировать его и создать тикет саппорту, чтобы проверили бот это или нет. При этом нам даже не надо знать, что есть «нормальное поведение» — мы просто выгружаем все действия пользователей в модель, и пусть машина сама разбирается кто тут нормальный.
Работает такой подход, по сравнению с классификацией, не очень. Но за спрос не бьют, вдруг получится.
Сегодня используют для:«Собирает конкретные признаки в абстракции более высокого уровня»
Популярные алгоритмы: Метод главных компонент (PCA), Сингулярное разложение (SVD), Латентное размещение Дирихле (LDA), Латентно-семантический анализ (LSA, pLSA, GLSA), t-SNE (для визуализации)
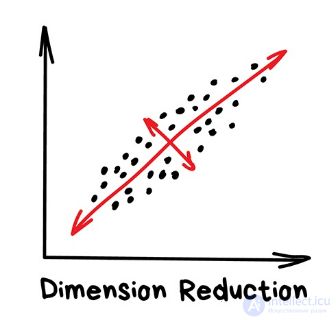
Изначально это были методы хардкорных Data Scientist'ов, которым сгружали две фуры цифр и говорили найти там что-нибудь интересное. Когда просто строить графики в экселе уже не помогало, они придумали напрячь машины искать закономерности вместо них. Так у них появились методы, которые назвали Dimension Reduction или Feature Learning.
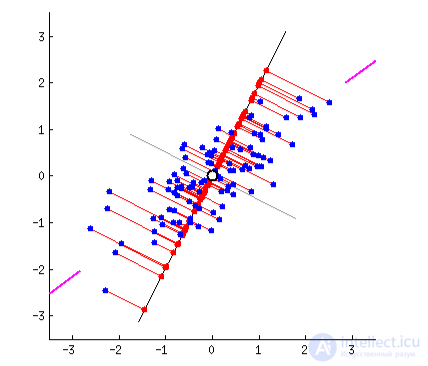
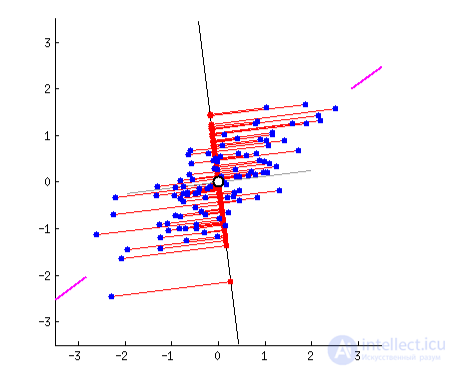
Для нас практическая польза их методов в том, что мы можем объединить несколько признаков в один и получить абстракцию. Например, собаки с треугольными ушами, длинными носами и большими хвостами соединяются в полезную абстракцию «овчарки». Да, мы теряем информацию о конкретных овчарках, но новая абстракция всяко полезнее этих лишних деталей. Плюс, обучение на меньшем количестве размерностей идет сильно быстрее.
Инструмент на удивление хорошо подошел для определения тематик текстов (Topic Modelling). Мы смогли абстрагироваться от конкретных слов до уровня смыслов даже без привлечения учителя со списком категорий. Алгоритм назвали Латентно-семантический анализ (LSA), и его идея была в том, что частота появления слова в тексте зависит от его тематики: в научных статьях больше технических терминов, в новостях о политике — имен политиков. Да, мы могли бы просто взять все слова из статей и кластеризовать, как мы делали с ларьками выше, но тогда мы бы потеряли все полезные связи между словами, например, что батарейка и аккумулятор, означают одно и то же в разных документах.
Точность такой системы — полное дно, даже не пытайтесь.
Нужно как-то объединить слова и документы в один признак, чтобы не терять эти скрытые (латентные) связи. Отсюда и появилось название метода. Оказалось, что Сингулярное разложение (SVD) легко справляется с этой задачей, выявляя для нас полезные тематические кластеры из слов, которые встречаются вместе.

Другое мега-популярное применение метода уменьшения размерности нашли в рекомендательных системах и коллаборативной фильтрации (у меня был пост про их виды). Оказалось, если абстрагировать ими оценки пользователей фильмам, получается неплохая система рекомендаций кино, музыки, игр и чего угодно вообще.
Полученная абстракция будет с трудом понимаема мозгом, но когда исследователи начали пристально рассматривать новые признаки, они обнаружили, что какие-то из них явно коррелируют с возрастом пользователя (дети чаще играли в Майнкрафт и смотрели мультфильмы), другие с определенными жанрами кино, а третьи вообще с синдромом поиска глубокого смысла.
Машина, не знавшая ничего кроме оценок пользователей, смогла добраться до таких высоких материй, даже не понимая их. Достойно. Дальше можно проводить соцопросы и писать дипломные работы о том, почему бородатые мужики любят дегенеративные мультики.

«Ищет закономерности в потоке заказов»
Сегодня используют для:
Популярные алгоритмы: Apriori, Euclat, FP-growth
Сюда входят все методы анализа продуктовых корзин, стратегий маркетинга и других последовательностей.
Предположим, покупатель берет в дальнем углу магазина пиво и идет на кассу. Стоит ли ставить на его пути орешки? Часто ли люди берут их вместе? Орешки с пивом, наверное да, но какие еще товары покупают вместе? Когда вы владелец сети гипермаркетов, ответ для вас не всегда очевиден, но одно тактическое улучшение в расстановке товаров может принести хорошую прибыль.
То же касается интернет-магазинов, где задача еще интереснее — за каким товаром покупатель вернется в следующий раз?
По непонятным мне причинам, поиск правил — самая хреново продуманная категория среди всех методов обучения. Классические способы заключаются в тупом переборе пар всех купленных товаров с помощью деревьев или множеств. Сами алгоритмы работают наполовину — могут искать закономерности, но не умеют обобщать или воспроизводить их на новых примерах.
В реальности каждый крупный ритейлер пилит свой велосипед, и никаких особых прорывов в этой области я не встречал. Максимальный уровень технологий здесь — запилить систему рекомендаций, как в пункте выше. Хотя может я просто далек от этой области, расскажите в комментах, кто шарит?
А́льфа-систе́ма подкрепле́ния — система подкрепления, при которой веса всех активных связей  , которые оканчиваются на некотором элементе
, которые оканчиваются на некотором элементе 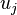 , изменяются на одинаковую величину
, изменяются на одинаковую величину  , или с постоянной скоростью в течение всего времени действия подкрепления, причем веса неактивных связей за это время не изменяются. Перцептрон, в котором используется α-система подкрепления, называется α-перцептроном. Подкрепление называется дискретным, если величина изменения веса является фиксированной, и непрерывным, если эта величина может принимать произвольное значение.
, или с постоянной скоростью в течение всего времени действия подкрепления, причем веса неактивных связей за это время не изменяются. Перцептрон, в котором используется α-система подкрепления, называется α-перцептроном. Подкрепление называется дискретным, если величина изменения веса является фиксированной, и непрерывным, если эта величина может принимать произвольное значение.
k-means (метод k-средних) — наиболее популярный метод кластеризации. Был изобретен в 1950-х годах математиком Гуго Штейнгаузом и почти одновременно Стюартом Ллойдом . Особую популярность приобрел после работы Маккуина .
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
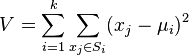
где 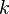 — число кластеров,
— число кластеров, 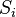 — полученные кластеры,
— полученные кластеры, 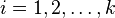 и
и 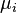 — центры масс векторов
— центры масс векторов 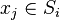 .
.
По аналогии с методом главных компонент центры кластеров называются также главными точками, а сам метод называется методом главных точек и включается в общую теорию главных объектов, обеспечивающих наилучшую аппроксимациюданных .
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения центра масс кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечно, а на каждом шаге суммарное квадратичное отклонение V не увеличивается, поэтому зацикливание невозможно.
Как показали Дэвид Артур и Сергей Васильвицкий, на некоторых классах множеств сложность алгоритма по времени, нужному для сходимости, равна 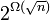 .
.
Действие алгоритма в двумерном случае. Начальные точки выбраны случайно.


Типичный пример сходимости метода k средних к локальному минимуму. В этом примере результат «кластеризации» методом k средних противоречит очевидной кластерной структуре множества данных. Маленькими кружками обозначены точки данных, четырехлучевые звезды — центроиды. Принадлежащие им точки данных окрашены в тот же цвет. Иллюстрация подготовлена с помощью апплета Миркеса .
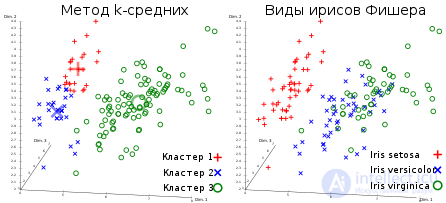
Результат кластеризации методом k-средних для ирисов Фишера и реальные виды ирисов, визуализированные с помощью ELKI. Центры кластеров отмечены с помощью крупных, полупрозрачных маркеров.
Широко известна и используется нейросетевая реализация K-means — сети векторного квантования сигналов (одна из версий нейронных сетей Кохонена).
Существует расширение k-means++, которое направлено на оптимальный выбор начальных значений центров кластеров.
А как ты думаешь, при улучшении обучение без учителя, будет лучше нам? Надеюсь, что теперь ты понял что такое обучение без учителя, алгоритм k-means, обучение с частичным привлечением учителя и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение
Комментарии
Оставить комментарий
Машинное обучение
Термины: Машинное обучение