Лекция
Сразу хочу сказать, что здесь никакой воды про обучение с подкреплением, и только нужная информация. Для того чтобы лучше понимать что такое обучение с подкреплением , настоятельно рекомендую прочитать все из категории Машинное обучение.
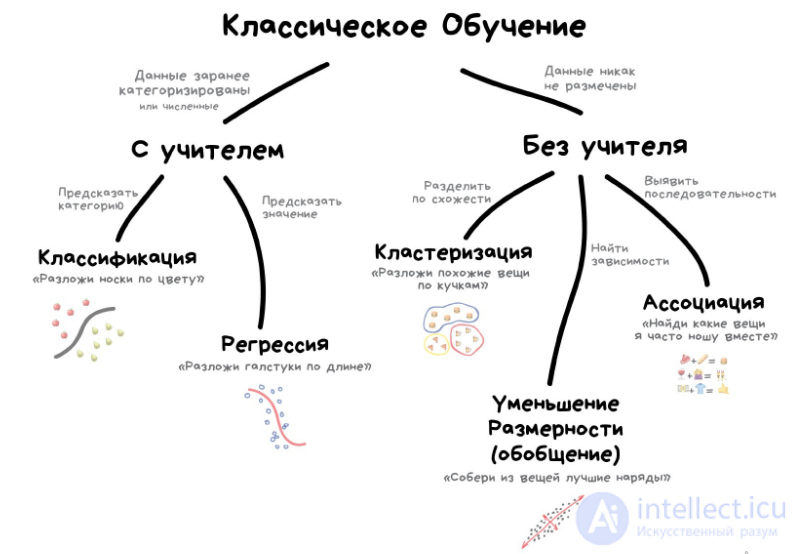
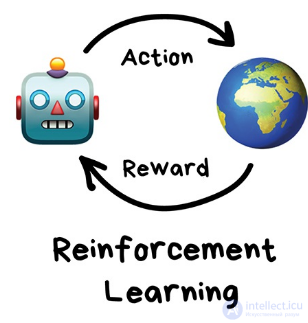
обучение с подкреплением (англ. reinforcement learning) — один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой. С точки зрения кибернетики, является одним из видовкибернетического эксперимента. Откликом среды (а не специальной системы управления подкреплением, как это происходит в обучении с учителем) на принятые решения являются сигналы подкрепления, поэтому такое обучение является частным случаем обучения с учителем, но учителем является среда или ее модель. Также нужно иметь в виду, что некоторые правила подкрепления базируются на неявных учителях, например, в случае искусственной нейронной среды, на одновременной активности формальных нейронов, из-за чего их можно отнести к обучению без учителя.

Агент воздействует на среду, а среда воздействует на агента. Об этом говорит сайт https://intellect.icu . О такой системе говорят, что она имеет обратную связь. Такую систему нужно рассматривать как единое целое, и поэтому линия раздела между средой и агентом достаточно условна. Конечно, с анатомической или физической точек зрения между средой и агентом (организмом) существует вполне определенная граница, но если эту систему рассматривать с функциональной точки зрения, то разделение становится нечетким. Например, резец в руке скульптора можно считать либо частью сложного биофизического механизма, придающего форму куску мрамора, либо частью материала, которым пытается управлять нервная система.
Розенблатт пытался классифицировать различные алгоритмы обучения, называя их системами подкрепления. Он дает следующее определение:
Системой подкрепления называется любой набор правил, на основании которых можно изменять с течением времени матрицу взаимодействия (или состояние памяти) перцептрона.
Кроме классического метода обучения перцептрона — метода коррекции ошибки, которого можно отнести к обучению с учителем, Розенблатт также ввел понятие об обучении без учителя, предложив несколько способов обучения:
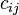 , которые ведут к элементу
, которые ведут к элементу 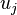 , изменяются на одинаковую величину r, а веса неактивных связей за это время не изменяются.
, изменяются на одинаковую величину r, а веса неактивных связей за это время не изменяются.
Сегодня используют для:
Популярные алгоритмы: Q-Learning, SARSA, DQN, A3C, Генетический Алгоритм
Наконец мы дошли до вещей, которые, вроде, выглядят как настоящий искусственный интеллект. Многие авторы почему-то ставят обучение с подкреплением где-то между обучением с учителем и без, но я не понимаю чем они похожи. Названием?
Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде.
Знания об окружающем мире такому роботу могут быть полезны, но чисто для справки. Не важно сколько данных он соберет, у него все равно не получится предусмотреть все ситуации. Потому его цель — минимизировать ошибки, а не рассчитать все ходы. Робот учится выживать в пространстве с максимальной выгодой: собранными монетками в Марио, временем поездки в Тесле или количеством убитых кожаных мешков хихихих.
Выживание в среде и есть идея обучения с подкреплением. Давайте бросим бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях норм работает, почему бы на и роботах не попробовать.
Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться никого там не убивать. Когда робот начинает хорошо себя чувствовать в искусственном GTA, его выпускают тестировать на реальные улицы.
Запоминать сам город машине не нужно — такой подход называется Model-Free. Конечно, тут есть и классический Model-Based, но в нем нашей машине пришлось бы запоминать модель всей планеты, всех возможных ситуаций на всех перекрестках мира. Такое просто не работает. В обучении с подкреплением машина не запоминает каждое движение, а пытается обобщить ситуации, чтобы выходить из них с максимальной выгодой.

Помните новость пару лет назад, когда машина обыграла человека в Го? Хотя незадолго до этого было доказано, что число комбинаций физически невозможно просчитать, ведь оно превышает количество атомов во вселенной. То есть если в шахматах машина реально просчитывала все будущие комбинации и побеждала, с Го так не прокатывало. Поэтому она просто выбирала наилучший выход из каждой ситуации и делала это достаточно точно, чтобы обыграть кожаного ублюдка.
Эта идея лежит в основе алгоритма Q-learning и его производных (SARSA и DQN). Буква Q в названии означает слово Quality, то есть робот учится поступать наиболее качественно в любой ситуации, а все ситуации он запоминает как простой марковский процесс.
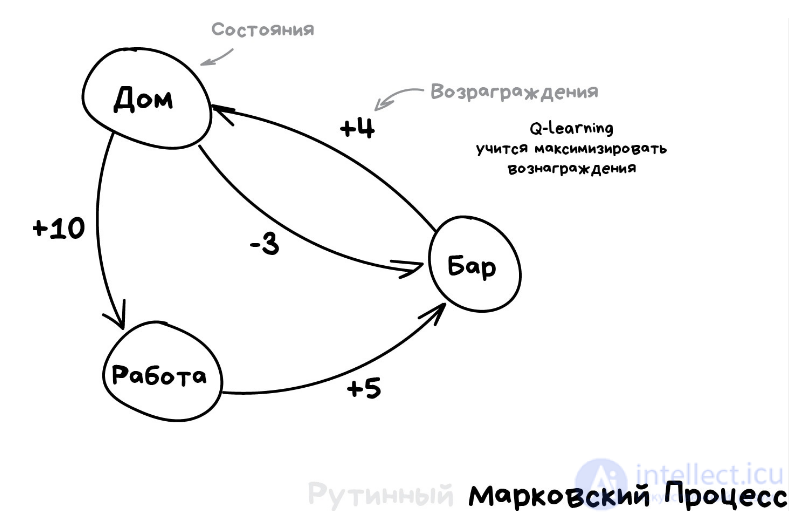
Машина прогоняет миллионы симуляций в среде, запоминая все сложившиеся ситуации и выходы из них, которые принесли максимальное вознаграждение. Но как понять, когда у нас сложилась известная ситуация, а когда абсолютно новая? Вот самоуправляемый автомобиль стоит у перекрестка и загорается зеленый — значит можно ехать? А если справа мчит скорая помощь с мигалками?
Ответ — хрен знает, никак, магии не бывает, исследователи постоянно этим занимаются, изобретая свои костыли. Одни прописывают все ситуации руками, что позволяет им обрабатывать исключительные случаи типа проблемы вагонетки. Другие идут глубже и отдают эту работу нейросетям, пусть сами все найдут. Так вместо Q-learning'а у нас появляется Deep Q-Network (DQN).
Reinforcement Learning для простого обывателя выглядит как настоящий интеллект. Потому что ух ты, машина сама принимает решения в реальных ситуациях! Он сейчас на хайпе, быстро прет вперед и активно пытается в нейросети, чтобы стать еще точнее (а не стукаться о ножку стула по двадцать раз).
Потому если вы любите наблюдать результаты своих трудов и хотите популярности — смело прыгайте в методы обучения с подкреплением (до чего ужасный русский термин, каждый раз передергивает) и заводите канал на ютюбе! Даже я бы смотрел.
Помню, у меня в студенчестве были очень популярны генетические алгоритмы (по ссылке прикольная визуализация). Это когда мы бросаем кучу роботов в среду и заставляем их идти к цели, пока не сдохнут. Затем выбираем лучших, скрещиваем, добавляем мутации и бросаем еще раз. Через пару миллиардов лет должно получиться разумное существо. Теория эволюции в действии.
Так вот, генетические алгоритмы тоже относятся к обучению с подкреплением, и у них есть важнейшая особенность, подтвержденная многолетней практикой — они нахер никому не нужны.
Человечеству еще не удалось придумать задачу, где они были бы реально эффективнее других. Зато отлично заходят как студенческие эксперименты и позволяют кадрить научруков «достижениями» особо не заморачиваясь. На ютюбе тоже зайдет.
Видеоигры основаны на системе стимулов. Завершите уровень и получите награду. Победите всех монстров и заработаете бонус. Попали в ловушку – конец игры, не попадайте. Эти стимулы помогают игрокам понять, как лучше действовать в следующем раунде игры. Без обратной связи люди бы просто принимали случайные решения и надеялись перейти на следующий игровой уровень.
Обучение с подкреплением (reinforcement learning) действует по тому же принципу. Видеоигры — популярная тестовая среда для исследований.
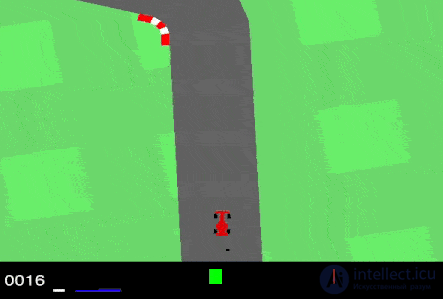
Результат обучения с подкреплением — «агент» проходит трассу, не выезжая за ее пределы. Далее можно добивиться повышения скорости прохождения трассы.
Агенты ИИ пытаются найти оптимальный способ достижения цели или улучшения производительности для конкретной среды. Когда агент предпринимает действия, способствующие достижению цели, он получает награду. Глобальная цель — предсказывать следующие шаги, чтобы заработать максимальную награду в конечном итоге.
При принятии решения агент изучает обратную связь, новые тактики и решения способные привести к большему выигрышу. Этот подход использует долгосрочную стратегию — так же как в шахматах: следующий наилучший ход может не помочь выиграть в конечном счете. Поэтому агент пытается максимизировать суммарную награду.
Это итеративный процесс. Чем больше уровней с обратной связи, тем лучше становится стратегия агента. Такой подход особенно полезен для обучения роботов, которые управляют автономными транспортными средствами или инвентарем на складе.
Так же, как и ученики в школе, каждый алгоритм учится по-разному. Но благодаря разнообразию доступных методов, вопрос в том, чтобы выбрать подходящий и научить вашу нейронную сеть разбираться в среде.
В обучении с подкреплением ключевым моментом является функции Q(s,a), которая является субъективной оценкой действия a в состоянии s. На основании этой функции агент принимает решение. В тоже время в результате игры агент постоянно модифицирует эту функции, что и является обучением.
Опишем алгоритм SARSA обучения с подкреплением
1. Инициализировать Q(s, a)
2. Повторять для каждой игры
3. Инициализировать s
4. Выбрать a по s (ε-жадную)
5. Повторять для каждого шага
6. Выполнить a, найти r, s’
7. Найти a’ по s’, используя (ε-жадную)
8. Q(s, a) = Q(s, a) + α[r + γQ(s’,a’)-Q(s,a)]
9. s = s’, a = a’
10. Пока s не станет финальным
Рассмотрим теперь алгоритм обучения с подкреплением Q-learning.
1. Инициализировать Q(s, a)
2. Повторять для каждой игры
3. Инициализировать s
4. Повторять для каждого шага
5. Выбрать a по s (ε-жадную)
6. Выполнить a, найти r, s’
7. Q(s, a) = Q(s, a) + α[r + γmaxa’Q(s’,a’)-Q(s,a)]
8. s = s’
9. Пока s не станет финальным
А как ты думаешь, при улучшении обучение с подкреплением, будет лучше нам? Надеюсь, что теперь ты понял что такое обучение с подкреплением и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение
Комментарии
Оставить комментарий
Машинное обучение
Термины: Машинное обучение