Лекция
Сразу хочу сказать, что здесь никакой воды про статистическое обучение, и только нужная информация. Для того чтобы лучше понимать что такое статистическое обучение , настоятельно рекомендую прочитать все из категории Машинное обучение.
Основными понятиями в данной главе, как и в главе 18, являются данные и гипотезы. Но в этой главе данные рассматриваются как свидетельства, т.е. конкретизации некоторых или всех случайных переменных, описывающих проблемную область, а гипотезы представляют собой вероятностные теории того, как функционирует проблемная область, включающие логические теории в качестве частного случая.
Рассмотрим очень простой пример. Наши любимые леденцы "Сюрприз" выпускаются в двух разновидностях: вишневые (сладкие) и лимонные (кислые). У изготовителя леденцов особое чувство юмора, поэтому он заворачивает каждую конфету в одинаковую непрозрачную бумагу, независимо от разновидности. Леденцы продаются в очень больших пакетах (также внешне не различимых), о которых известно, что они относятся к пяти следующим типам: h1: 100% вишневых леденцов h2: 75% вишневых + 25 % лимонных леденцов h3: 50% вишневых + 50 % лимонных леденцов h4: 25% вишневых + 75 % лимонных леденцов h5: 100 % лимонных леденцов
Получив новый пакет леденцов, любитель конфет пытается угадать, к какому типу он относится, и обозначает тип пакета случайной переменной я (сокращение от hypothesis — гипотеза), которая имеет возможные значения от h1 до h5. Безусловно, значение переменной я невозможно определить с помощью непосредственного наблюдения. По мере развертывания и осмотра конфет регистрируются данные о них, 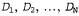 , где каждый элемент данных,
, где каждый элемент данных,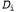 , представляет собой случайную переменную с возможными значениями cherry (вишневый леденец) и lime (лимонный леденец). Основная задача, стоящая перед агентом, состоит в том, что он должен предсказать, к какой разновидности относится следующая конфета1. Несмотря на кажущуюся простоту, постановка этой задачи позволяет ознакомиться с многими важными темами. В действительности агент должен вывести логическим путем теорию о мире, в котором он существует, хотя и очень простую.
, представляет собой случайную переменную с возможными значениями cherry (вишневый леденец) и lime (лимонный леденец). Основная задача, стоящая перед агентом, состоит в том, что он должен предсказать, к какой разновидности относится следующая конфета1. Несмотря на кажущуюся простоту, постановка этой задачи позволяет ознакомиться с многими важными темами. В действительности агент должен вывести логическим путем теорию о мире, в котором он существует, хотя и очень простую.
В байесовском обучении исходя из полученных данных просто вычисляется вероятность каждой гипотезы и на этой основе делаются предсказания. Это означает, что предсказания составляются с использованием всех гипотез, взвешенных по их вероятностям, а не с применением только одной "наилучшей" гипотезы. Таким образом, обучение сводится к вероятностному выводу. Допустим, что переменная D представляет все данные, с наблюдаемым значением d; в таком случае вероятность каждой гипотезы может быть определена с помощью правила Байеса:
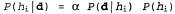 (20.1)
(20.1)
Теперь предположим, что необходимо сделать предсказание в отношении неизвестного количества X. В таком случае применяется следующее уравнение:
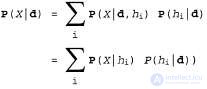 (20.2)
(20.2)
где предполагается, что каждая гипотеза определяет распределение вероятностей по X. Это уравнение показывает, что предсказания представляют собой взвешенные средние по предсказаниям отдельных гипотез. Сами гипотезы по сути являются "посредниками" между фактическими данными и предсказаниями. Основными количественными показателями в байесовском подходе являются распределение априорных вероятностей гипотезы,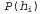 , и правдоподобие данных согласно каждой гипотезе,
, и правдоподобие данных согласно каждой гипотезе,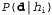
Применительно к рассматриваемому примеру с леденцами предположим, что изготовитель объявил о наличии распределения априорных вероятностей по значениям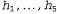 , которое задано вектором <0.1,0.2,0.4,0.2,0.1>. Правдоподобие данных рассчитывается в соответствии с предположением, что наблюдения характеризуются свойством i.i.d., т.е. являются независимыми и одинаково распределенными (i.i.d. — independently and identically distributed), поэтому соблюдается следующее уравнение:
, которое задано вектором <0.1,0.2,0.4,0.2,0.1>. Правдоподобие данных рассчитывается в соответствии с предположением, что наблюдения характеризуются свойством i.i.d., т.е. являются независимыми и одинаково распределенными (i.i.d. — independently and identically distributed), поэтому соблюдается следующее уравнение:
 (20.3)
(20.3)
Например, предположим, что пакет в действительности представляет собой пакет такого типа, который состоит из одних лимонных леденцов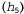 , и все первые 10 конфет являются лимонными леденцами; в таком случае значение
, и все первые 10 конфет являются лимонными леденцами; в таком случае значение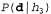 равно
равно
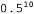 , поскольку в пакете типа h3 половина конфет— лимонные леденцы2. Об этом говорит сайт https://intellect.icu . На рис. 20.1, а показано, как изменяются апостериорные вероятности пяти гипотез по мере наблюдения последовательности из 10 лимонных леденцов. Обратите внимание на то, что кривые вероятностей начинаются с их априорных значений, поэтому первоначально наиболее вероятным вариантом является гипотеза h3 и остается таковой после развертывания 1 конфеты с лимонным леденцом. После развертывания 2 конфет с лимонными леденцами наиболее вероятной становится гипотеза h4, а после обнаружения 3 или больше лимонных леденцов наиболее вероятной становится гипотеза h5 (ненавистный пакет, состоящий из одних кислых лимонных леденцов). После обнаружения 10 подряд лимонных леденцов мы почти уверены в своей злосчастной судьбе. На рис. 20.1,6 приведена предсказанная вероятность того, что следующий леденец будет лимонным, согласно уравнению 20.2. Как и следовало ожидать, она монотонно увеличивается до 1.
, поскольку в пакете типа h3 половина конфет— лимонные леденцы2. Об этом говорит сайт https://intellect.icu . На рис. 20.1, а показано, как изменяются апостериорные вероятности пяти гипотез по мере наблюдения последовательности из 10 лимонных леденцов. Обратите внимание на то, что кривые вероятностей начинаются с их априорных значений, поэтому первоначально наиболее вероятным вариантом является гипотеза h3 и остается таковой после развертывания 1 конфеты с лимонным леденцом. После развертывания 2 конфет с лимонными леденцами наиболее вероятной становится гипотеза h4, а после обнаружения 3 или больше лимонных леденцов наиболее вероятной становится гипотеза h5 (ненавистный пакет, состоящий из одних кислых лимонных леденцов). После обнаружения 10 подряд лимонных леденцов мы почти уверены в своей злосчастной судьбе. На рис. 20.1,6 приведена предсказанная вероятность того, что следующий леденец будет лимонным, согласно уравнению 20.2. Как и следовало ожидать, она монотонно увеличивается до 1.

Рис. 20.1. Изменение вероятностей в зависимости от количества данных: апостериорные вероятности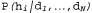 , полученные с помощью уравнения 20.1. Количество наблюдений N возрастает от 1 до 10, а в каждом наблюдении обнаруживается лимонный леденец (а); байесовские предсказания
, полученные с помощью уравнения 20.1. Количество наблюдений N возрастает от 1 до 10, а в каждом наблюдении обнаруживается лимонный леденец (а); байесовские предсказания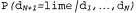 , полученные из уравнения 20.2 (б)
, полученные из уравнения 20.2 (б)
Этот пример показывает, что истинная гипотеза в конечном итоге будет доминировать над байесовским предсказанием. В этом состоит характерная особенность байесовского обучения. При любом заданном распределении априорных вероятностей, которое не исключает с самого начала истинную гипотезу, апостериорная вероятность любой ложной гипотезы в конечном итоге полностью исчезает просто потому, что вероятность неопределенно долгого формирования "нехарактерных" данных исчезающе мала (сравните это замечание с аналогичным замечанием, сделанным при обсуждении РАС-обучения в главе 18). Еще более важно то, что байесовское предсказание является оптимальным, независимо от того, применяется ли большой или малый набор данных. При наличии распределения априорных вероятностей гипотезы все другие предсказания будут правильными менее часто.
Но за оптимальность байесовского обучения, безусловно, приходится платить. В реальных задачах обучения пространство гипотез обычно является очень большим или бесконечным, как было показано в главе 18. В некоторых случаях операция вычисления суммы в уравнении 20.2 (или, в непрерывном случае, операция интегрирования) может быть выполнена успешно, но в большинстве случаев приходится прибегать к приближенным или упрощенным методам.
Один из широко распространенных приближенных подходов (из числа тех, которые обычно применяются в научных исследованиях) состоит в том, чтобы делать предсказания на основе единственной наиболее вероятной гипотезы, т.е. той гипотезы , которая максимизирует значение
, которая максимизирует значение . Такую гипотезу часто называют максимальной апостериорной гипотезой, или сокращенно MAP (Maximum A Posteriori; произносится "эм-эй-пи"). Предсказания
. Такую гипотезу часто называют максимальной апостериорной гипотезой, или сокращенно MAP (Maximum A Posteriori; произносится "эм-эй-пи"). Предсказания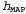 , сделанные на основе МАР-гипотезы, являются приближенно байесовскими до такой степени, что
, сделанные на основе МАР-гипотезы, являются приближенно байесовскими до такой степени, что 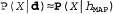 . В рассматриваемом примере с конфетами
. В рассматриваемом примере с конфетами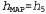 после обнаружения трех лимонных леденцов подряд, поэтому агент, обучающийся с помощью МАР-гипотезы, после этого предсказывает, что четвертая конфета представляет собой лимонный леденец, с вероятностью 1. 0, а это — гораздо более радикальное предсказание, чем байесовское предсказание вероятности 0.8, приведенное на рис. 20.1.
после обнаружения трех лимонных леденцов подряд, поэтому агент, обучающийся с помощью МАР-гипотезы, после этого предсказывает, что четвертая конфета представляет собой лимонный леденец, с вероятностью 1. 0, а это — гораздо более радикальное предсказание, чем байесовское предсказание вероятности 0.8, приведенное на рис. 20.1.
По мере поступления дополнительных данных предсказания с помощью МАР-гипотезы и байесовские предсказания сближаются, поскольку появление гипотез, конкурирующих с MAP-гипотезой, становится все менее и менее вероятным. Хотя в рассматриваемом примере это не показано, поиск МАР-гипотез часто бывает намного проще по сравнению с байесовским обучением, поскольку требует решения задачи оптимизации, а не задачи вычисления большой суммы (или интегрирования). Примеры, подтверждающие это замечание, будут приведены ниже в данной главе.
И в байесовском обучении, и в обучении с помощью МАР-гипотез важную роль играет распределение априорных вероятностей гипотезы . Как было показано в главе 18, если пространство гипотез является слишком выразительным, в том смысле, что содержит много гипотез, хорошо согласующихся с набором данных, то может происходить чрезмерно тщательная подгонка. С другой стороны, байесовские методы обучения и методы обучения на основе МАР-гипотез не налагают произвольный предел на количество подлежащих рассмотрению гипотез, а позволяют использовать распределение априорных вероятностей для наложения штрафа за сложность. Как правило, более сложные гипотезы имеют более низкую априорную вероятность, отчасти потому, что сложных гипотез обычно бывает намного больше, чем простых. С другой стороны, более сложные гипотезы имеют большую способность согласовываться с данными (в крайнем случае какая-то поисковая таблица может оказаться способной точно воспроизводить данные с вероятностью 1). Поэтому в распределении априорных вероятностей гипотезы воплощен компромисс между сложностью гипотезы и степенью ее согласования с данными.
. Как было показано в главе 18, если пространство гипотез является слишком выразительным, в том смысле, что содержит много гипотез, хорошо согласующихся с набором данных, то может происходить чрезмерно тщательная подгонка. С другой стороны, байесовские методы обучения и методы обучения на основе МАР-гипотез не налагают произвольный предел на количество подлежащих рассмотрению гипотез, а позволяют использовать распределение априорных вероятностей для наложения штрафа за сложность. Как правило, более сложные гипотезы имеют более низкую априорную вероятность, отчасти потому, что сложных гипотез обычно бывает намного больше, чем простых. С другой стороны, более сложные гипотезы имеют большую способность согласовываться с данными (в крайнем случае какая-то поисковая таблица может оказаться способной точно воспроизводить данные с вероятностью 1). Поэтому в распределении априорных вероятностей гипотезы воплощен компромисс между сложностью гипотезы и степенью ее согласования с данными.
Влияние такого компромисса можно наблюдать наиболее наглядно в случае использования логических гипотез, когда переменная Я содержит только детерминированные гипотезы. В таком случае значение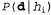 равно 1, если гипотезасо
равно 1, если гипотезасо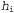 гласуется с данными, и 0 — в противном случае. Рассматривая уравнение 20.1, можно определить, что
гласуется с данными, и 0 — в противном случае. Рассматривая уравнение 20.1, можно определить, что 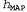 в таких условиях представляет собой простейшую логическую теорию, согласованную с данными. Поэтому обучение с помощью максимальной апостериорной гипотезы представляет собой естественное воплощение принципа бритвы Оккама.
в таких условиях представляет собой простейшую логическую теорию, согласованную с данными. Поэтому обучение с помощью максимальной апостериорной гипотезы представляет собой естественное воплощение принципа бритвы Оккама.
Еще один способ анализа компромисса между сложностью и степенью согласованности состоит в том, что можно исследовать уравнение 20.1, взяв его логарифм. Применение значения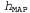 для максимизации выражения
для максимизации выражения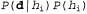 эквивалентно минимизации следующего выражения:
эквивалентно минимизации следующего выражения:

Используя связь между информационным содержанием и вероятностью, которая была описана в главе 18, можно определить, что терм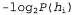 определяет количество битов, требуемых для задания гипотезы
определяет количество битов, требуемых для задания гипотезы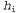 . Кроме того, терм
. Кроме того, терм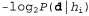 представляет собой дополнительное количество битов, требуемых для задания данных, если дана рассматриваемая гипотеза (чтобы убедиться в этом, достаточно отметить, что если гипотеза точно предсказывает данные, как в случае гипотезы
представляет собой дополнительное количество битов, требуемых для задания данных, если дана рассматриваемая гипотеза (чтобы убедиться в этом, достаточно отметить, что если гипотеза точно предсказывает данные, как в случае гипотезы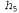 и сплошного ряда конфет с лимонными леденцами, не требуется ни одного бита, поскольку
и сплошного ряда конфет с лимонными леденцами, не требуется ни одного бита, поскольку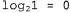 ). Таким образом, обучение с помощью МАР-гипотезы равносильно выбору гипотезы, которая обеспечивает максимальное сжатие данных. Такую же задачу можно решить более прямо с помощью метода обучения на основе минимальной длины описания, или сокращенно MDL (Minimum Description
). Таким образом, обучение с помощью МАР-гипотезы равносильно выбору гипотезы, которая обеспечивает максимальное сжатие данных. Такую же задачу можно решить более прямо с помощью метода обучения на основе минимальной длины описания, или сокращенно MDL (Minimum Description
Length), в котором вместо манипуляций с вероятностями предпринимаются попытки минимизировать размер гипотезы и закодированного представления данных.
Окончательное упрощение может быть достигнуто путем принятия предположения о равномерном распределении априорных вероятностей по пространству гипотез. В этом случае обучение с помощью МАР-гипотезы сводится в выбору гипотезы 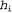 , которая максимизирует значение
, которая максимизирует значение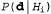 . Такая гипотеза называется гипотезой с максимальным правдоподобием (Maximum Likelihood — ML) и сокращенно обозначается
. Такая гипотеза называется гипотезой с максимальным правдоподобием (Maximum Likelihood — ML) и сокращенно обозначается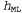 . Обучение на основе гипотезы с максимальным правдоподобием очень широко применяется в статистике, поскольку в этой научной области многие исследователи не доверяют распределениям априорных вероятностей гипотезы, считая, что они имеют субъективный характер. Это — приемлемый подход, применяемый в тех обстоятельствах, когда нет оснований априорно отдавать предпочтение одной гипотезе перед другой, например, в тех условиях, когда все гипотезы являются в равной степени сложными. Такой метод обучения становится хорошей аппроксимацией байесовского обучения и обучения с помощью МАР-гипотезы, когда набор данных имеет большие размеры, поскольку данные сами исправляют распределение априорных вероятностей по гипотезам, но связан с возникновением определенных проблем (как будет показано ниже) при использовании небольших наборов данных.
. Обучение на основе гипотезы с максимальным правдоподобием очень широко применяется в статистике, поскольку в этой научной области многие исследователи не доверяют распределениям априорных вероятностей гипотезы, считая, что они имеют субъективный характер. Это — приемлемый подход, применяемый в тех обстоятельствах, когда нет оснований априорно отдавать предпочтение одной гипотезе перед другой, например, в тех условиях, когда все гипотезы являются в равной степени сложными. Такой метод обучения становится хорошей аппроксимацией байесовского обучения и обучения с помощью МАР-гипотезы, когда набор данных имеет большие размеры, поскольку данные сами исправляют распределение априорных вероятностей по гипотезам, но связан с возникновением определенных проблем (как будет показано ниже) при использовании небольших наборов данных.
А как ты думаешь, при улучшении статистическое обучение, будет лучше нам? Надеюсь, что теперь ты понял что такое статистическое обучение и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение

Комментарии