Лекция
трансдуктивное обучение (transduction) в машинном обучении — это подход, при котором модель пытается напрямую предсказать метки (или значения) для конкретных тестовых данных, вместо создания общей функции для всех возможных данных. Этот метод фокусируется на решении задачи только для заданного набора тестовых данных, которые известны на этапе обучения, не стремясь построить универсальную гипотезу для новых, потенциально неизвестных данных. то есть это Обучение с частичным участием преподавателя, когда прогноз предполагается делать только по прецедентам из тестовой выборки.
in English Transductive learning: https://intellect.bond/transductive-learning-transduction-122 .
Трансдукция (машинное обучение)
В логике, статистическом выводе и контролируемом обучении трансдукция или трансдуктивный вывод — это рассуждение от наблюдаемых конкретных (тренировочных) случаев к конкретным (тестовым) случаям. Напротив, индукция — это рассуждение от наблюдаемых учебных случаев к общим правилам, которые затем применяются к тестовым случаям. Различие наиболее интересно в случаях, когда предсказания трансдуктивной модели недостижимы ни одной индуктивной моделью. Обратите внимание, что это вызвано трансдуктивным выводом на разных тестовых наборах, производящим взаимно несовместимые предсказания.
Трансдукция была введена Владимиром Вапником в 1990-х годах, мотивированным его мнением о том, что трансдукция предпочтительнее индукции, поскольку, по его мнению, индукция требует решения более общей проблемы (вывода функции) перед решением более конкретной проблемы (вычисления выходных данных для новых случаев): «При решении интересующей проблемы не решайте более общую проблему в качестве промежуточного шага. Постарайтесь получить ответ, который вам действительно нужен, а не более общий». Аналогичное наблюдение было сделано ранее Бертраном Расселом: «мы придем к выводу, что Сократ смертен, с большей степенью уверенности, если сделаем наш аргумент чисто индуктивным, чем если пойдем путем «все люди смертны», а затем используем дедукцию» (Рассел 1912, глава VII).
Примером обучения, которое не является индуктивным, может быть случай бинарной классификации, где входные данные имеют тенденцию группироваться в две группы. Большой набор тестовых входных данных может помочь в поиске кластеров, тем самым предоставляя полезную информацию о метках классификации. Те же прогнозы нельзя будет получить из модели, которая индуцирует функцию, основанную только на обучающих случаях. Некоторые люди могут назвать это примером тесно связанного полуконтролируемого обучения, поскольку мотивация Вапника совершенно иная. Примером алгоритма в этой категории является Transductive Support Vector Machine (TSVM).
Третья возможная мотивация, которая приводит к трансдукции, возникает из-за необходимости аппроксимации. Если точный вывод вычислительно невозможен, можно хотя бы попытаться убедиться, что приближения хороши для тестовых входов. В этом случае тестовые входы могут исходить из произвольного распределения (не обязательно связанного с распределением обучающих входов), что недопустимо в полуконтролируемом обучении. Примером алгоритма, попадающего в эту категорию, является Байесовский комитетный автомат (BCM).
Ограничение на тестовый набор:
Трансдукция работает исключительно с данным набором тестовых примеров. Это отличается от традиционного индуктивного подхода, где модель должна уметь обобщать на любые возможные данные.
Не строит универсальную функцию:
В отличие от индуктивного обучения, трансдукция не формулирует обобщающей функции (например, f(x)f(x)f(x)), которая будет применяться ко всем новым данным. Она работает только с известными входами.
Использует данные тестового набора на этапе обучения:
Знание тестовых данных позволяет модели подстроить свои предсказания под конкретные входы. Однако метки (ответы) тестовых данных остаются неизвестными.
Представим задачу классификации. Мы имеем:
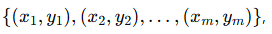 ,
,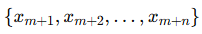 (метки ym+1,…,ym+n, неизвестны).
(метки ym+1,…,ym+n, неизвестны).В трансдуктивном обучении алгоритм пытается оптимально предсказать метки для 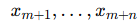 , используя как обучающие, так и тестовые данные.
, используя как обучающие, так и тестовые данные.
Следующий пример задачи противопоставляет некоторые уникальные свойства трансдукции индукции.

Дана коллекция точек, некоторые из которых помечены (A, B или C), но большинство точек не помечены (?). Цель состоит в том, чтобы предсказать соответствующие метки для всех не помеченных точек.
Индуктивный подход к решению этой задачи заключается в использовании помеченных точек для обучения контролируемого алгоритма обучения, а затем в том, чтобы он предсказал метки для всех не помеченных точек. Однако в этой задаче контролируемый алгоритм обучения будет иметь только пять помеченных точек для использования в качестве основы для построения предиктивной модели. Он, безусловно, будет бороться за построение модели, которая фиксирует структуру этих данных. Например, если используется алгоритм ближайшего соседа, то точки около середины будут помечены «A» или «C», хотя очевидно, что они принадлежат к тому же кластеру, что и точка с меткой «B».
Преобразование имеет преимущество в том, что может учитывать все точки, а не только помеченные, при выполнении задачи по маркировке. В этом случае трансдуктивные алгоритмы будут маркировать немаркированные точки в соответствии с кластерами, к которым они естественным образом принадлежат. Таким образом, точки в середине, скорее всего, будут помечены как «B», поскольку они упакованы очень близко к этому кластеру.
Преимущество преобразования заключается в том, что оно может делать лучшие прогнозы с меньшим количеством помеченных точек, поскольку оно использует естественные разрывы, обнаруженные в немаркированных точках. Один из недостатков преобразования заключается в том, что оно не строит предиктивную модель. Если ранее неизвестная точка добавляется в набор, весь трансдуктивный алгоритм должен быть повторен со всеми точками, чтобы предсказать метку. Это может быть вычислительно затратным, если данные предоставляются постепенно в потоке. Кроме того, это может привести к изменению прогнозов некоторых старых точек (что может быть хорошо или плохо, в зависимости от приложения). С другой стороны, контролируемый алгоритм обучения может мгновенно маркировать новые точки с очень небольшими вычислительными затратами.
| Характеристика | Индуктивное обучение | Трансдуктивное обучение |
|---|---|---|
| Цель | Найти универсальную функцию f(x) для любых данных. | Предсказать метки для данного тестового набора. |
| Обобщение | Стремится обобщать на любые новые данные. | Фокусируется только на известных тестовых данных. |
| Примеры | Классическое обучение нейросетей, SVM. | Semi-Supervised Learning, Graph-Based Methods. |
Трансдуктивная поддерживающая векторная машина (Transductive SVM):
Этот метод использует информацию о тестовых данных для нахождения разделяющей гиперплоскости, которая лучше разделяет классы с учетом известных тестовых примеров.
Алгоритмы на графах:
Semi-Supervised Learning:
Комбинирует малый объем размеченных данных с большим количеством неразмеченных данных, включая тестовые.
Трансдукция — это гибкий подход, особенно полезный в условиях, когда тестовые данные известны заранее и требуется максимальная точность на ограниченном наборе.
Алгоритмы трансдукции можно в целом разделить на две категории: те, которые стремятся назначать дискретные метки немаркированным точкам, и те, которые стремятся регрессировать непрерывные метки для немаркированных точек. Алгоритмы, которые стремятся предсказывать дискретные метки, как правило, выводятся путем добавления частичного надзора к алгоритму кластеризации. Их можно далее подразделить на две категории: те, которые кластеризуются путем разбиения, и те, которые кластеризуются путем агломерации. Алгоритмы, которые стремятся предсказывать непрерывные метки, как правило, выводятся путем добавления частичного надзора к алгоритму обучения многообразия.
Разделительная трансдукция
Разделительная трансдукция может рассматриваться как нисходящая трансдукция. Это полуконтролируемое расширение кластеризации на основе разделов. Обычно выполняется следующим образом:
Consider the set of all points to be one large partition. While any partition P contains two points with conflicting labels: Partition P into smaller partitions. For each partition P: Assign the same label to all of the points in P.
Конечно, с этим алгоритмом можно использовать любую разумную технику разбиения. Схемы разбиения Max flow min cut очень популярны для этой цели.
Агломеративная трансдукция
Агломеративную трансдукцию можно рассматривать как трансдукцию снизу вверх. Это полуконтролируемое расширение агломеративной кластеризации. Обычно она выполняется следующим образом:
Compute the pair-wise distances, D, between all the points.
Sort D in ascending order.
Consider each point to be a cluster of size 1.
For each pair of points {a,b} in D:
If (a is unlabeled) or (b is unlabeled) or (a and b have the same label)
Merge the two clusters that contain a and b.
Label all points in the merged cluster with the same label.
Трансдукция на основе многообразного обучения
Трансдукция на основе многообразного обучения все еще является очень молодой областью исследований.

Комментарии