Лекция
Сразу хочу сказать, что здесь никакой воды про активное обучение, и только нужная информация. Для того чтобы лучше понимать что такое активное обучение, active learning, машинное обучение, сокращение дисперсии, variane redution, ожидаемое сокращение ошибки, expeted error redution , настоятельно рекомендую прочитать все из категории Машинное обучение.
активное обучение отличается тем, что обучаемый алгоритм имеет возможность самостоятельно назначать следующую исследуемую ситуацию, на которой станет известен верный ответ
Активное обучение - это особый случай машинного обучения, в котором алгоритм обучения может интерактивно запрашивать пользователя (или какой-либо другой источник информации), чтобы пометить новые точки данных желаемыми выходными данными. В статистической литературе это иногда также называют оптимальным экспериментальным планом . Источник информации также называют учителем или оракулом .
Бывают ситуации, когда немаркированных данных много, а ручная маркировка обходится дорого. В таком сценарии алгоритмы обучения могут активно запрашивать у пользователя / учителя ярлыки. Этот тип итеративного обучения с учителем называется активным обучением. Поскольку учащийся выбирает примеры, количество примеров для изучения концепции часто может быть намного меньше, чем количество, требуемое при обычном обучении с учителем. При таком подходе есть риск, что алгоритм перегружен неинформативными примерами. Последние разработки посвящены многокомпонентному активному обучению [ гибридному активному обучению и активному обучению в однопроходном (он-лайн) контексте , объединяющему концепции из области машинного обучения (например, конфликт и незнание) с адаптивным,Политика инкрементального обучения в области машинного обучения онлайн .
Активное обучение — представляет собой такую организацию и ведение учебного процесса, которая направлена на всемерную активизацию учебно-познавательной деятельности обучающихся посредством широкого, желательно комплексного, использования как педагогических (дидактических), так и организационно-управленческих средств .
В классической педагогике для естественого интеллекта выделяются следущие дидактические предпосылки
К дидактическим предпосылкам можно отнести педагогические технологии в той или иной мере реализующие и развивающие отдельные принципы активного обучения.
Содержание
Задача: обучение предсказательной модели a : X → Y по выборке (xi , yi), когда получение ответов yi стоит дорого.
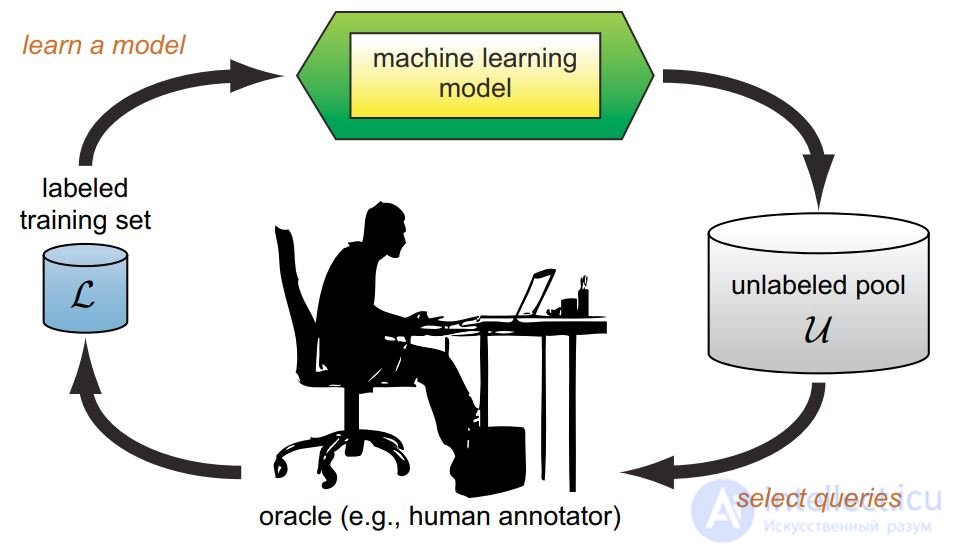
Задача: обучение предсказательной модели a : X → Y по выборке (xi , yi), когда получение ответов yi стоит дорого.
Вход: начальная размеченная выборка 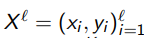
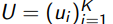 выборка(пул) неразмеченных объектов
выборка(пул) неразмеченных объектов
Выход: модель a и размеченная выборка 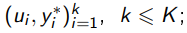
обучить модель a по начальной выборке 
пока
 ;
;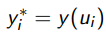 ;
;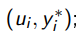
конецпока
Цель активного обучения:
достичь как можно лучшего качества модели a, использовав как можно меньше дополнительных примеров k
Примеры приложений активного обучения
Отбор объектов из выборки (pool-based sampling): какой следующий xi выбрать из множества 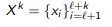
Синтез объектов (query synthesis):на каждом шаге построить оптимальный объект xi;
Отбор объектов из потока (selective sampling): для каждого приходящего xi решать, стоит ли узнавать yi
Функционал качества модели a(x, θ) с параметром θ:  где L функция потерь, Ci стоимость инормации yi для методов, чувствительных к стоимости (cost-sensitive)
где L функция потерь, Ci стоимость инормации yi для методов, чувствительных к стоимости (cost-sensitive)
Идея: выбирать xi с наибольшей неопределјнностью a(xi).
Задача многоклассовой классиикации: 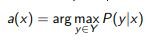
где pk (x), k = 1...|Y | ранжированные по убыванию P(y|x), y ∈Y .
Принцип наименьшей достоверности (least condence): 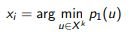
Принцип наименьшей разности отступов (margin sampling):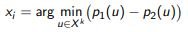
Принцип максимума энтропии (maximum entropy): 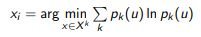
В случае двух классов эти три принципа эквивалентны.
В случае многих классов появляются различия.
Пример. Три класса, p1 + p2 + p3 = 1. Об этом говорит сайт https://intellect.icu . Показаны линии уровни трех критериев выбора объекта xi
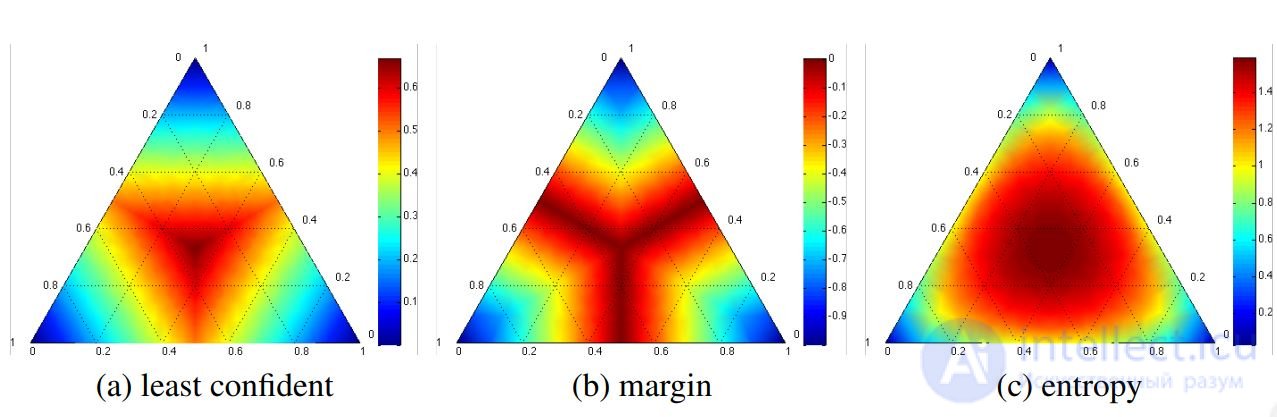
а) min p1
б) min(p1 − p2)
в) 
Пример 1. Синтетические данные: ℓ = 30, ℓ + k = 400;
(a) два гауссовских класса;
(b) логистическая регрессия по 30 случайным объектам;
(c) логистическая регрессия по 30 объектам, отобранным с помощью активного обучения.
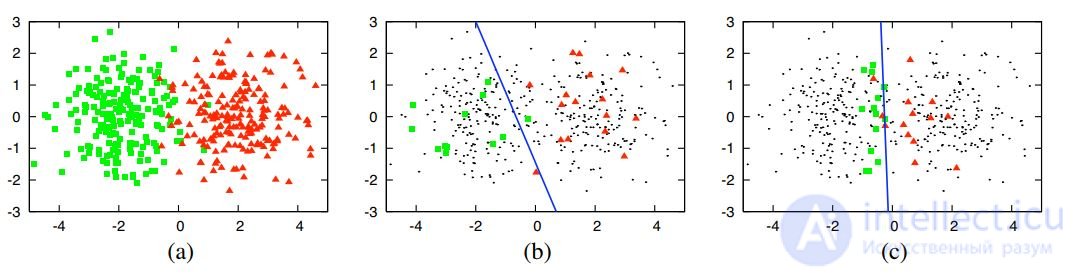
Обучение по смещенной неслучайной выборке требует меньше данных для построения алгоритма сопоставимого качества.
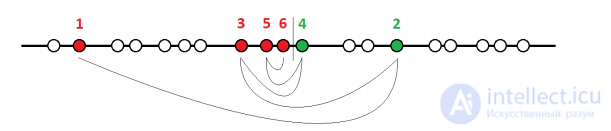
Пример 2. Одномерная задача с пороговым классиикатором:
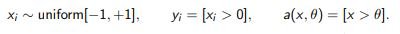
Оценим число шагов для определения θ с точностью 1/к.
Наивная стратегия: выбирать  число шагов О(к).
число шагов О(к).
Бинарный поиск: выбирать хi, ближайший к середине зазора между классами 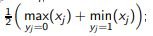
число шагов O(log k)
Идея: выбирать xi с наибольшей несогласованностью решений комитета моделей

Принцип максимума энтропии:выбираем xi, на котором at(xi) максимально различны:

Принцип максимума средней KL-дивергенции:выбираем xi , на котором Pt(y|xi) максимально различны:
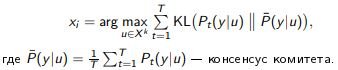
Идея: выбирать хi, максимально сужая множество решений.
Пример. Пространства допустимых решений для линейных и пороговых классиикаторов (двумерный случай):

Бустинг и бэггинг находят конечные подмножества решений.
Поэтому сэмплирование по несогласию в комитете это аппроксимация принципа сокращения пространства решений.
Идея: выбрать xi , который в методе стохастического градиента привел бы к наибольшему изменению модели.
Параметрическая модель многоклассовой классиикации:

Для каждого u ∈ Xk и y ∈ Y оценим длину градиентного шагав пространстве параметров θ при дообучении модели на (u, y);
пусть  вектор градиента функции потерь.
вектор градиента функции потерь.
Принцип максимума ожидаемой длины градиента:
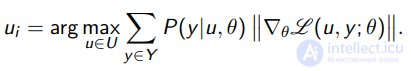
Идея: выбрать 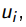 , который после обучения даст наиболее уверенную классиикацию неразмеченной выборки
, который после обучения даст наиболее уверенную классиикацию неразмеченной выборки 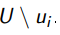
.
Для каждого u ∈ Xk и y ∈ Y обучим модель классиикации,добавив к размеченной обучающей выборке Xℓ пример (u, y):
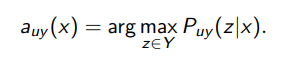
Принцип максимума уверенности на неразмеченных данных:
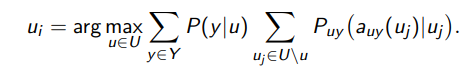
.
Принцип минимума энтропии неразмеченных данных:
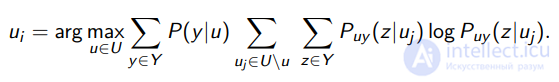
Идея: выбрать 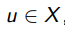 , который после дообучения модели a(x, θ) даст наименьшую оценку дисперсии σ2a(x).
, который после дообучения модели a(x, θ) даст наименьшую оценку дисперсии σ2a(x).
Задача регрессии, метод наименьших квадратов: 
Из теории оптимального планирования экспериментов
(OED, optimal experiment design):
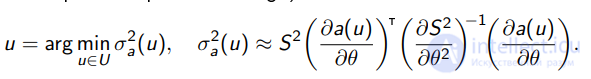
В частности, для линейной регрессии
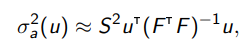
где F матрица объекты-признаки.
Идея: понижать вес нерепрезентативных объектов.
Пример. Объект A более пограничный, но менее репрезентативный, чем B.

Любой критерий сэмплирования объектов, имеющий вид
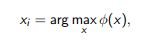
может быть уточнен локальной оценкой плотности:
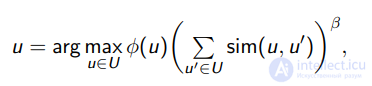
 оценка близости
оценка близости 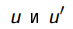 (чем ближе, тем больше).
(чем ближе, тем больше).
Кривая обучения (learning curve) зависимость точности классиикации на тесте от числа обучающих объектов.
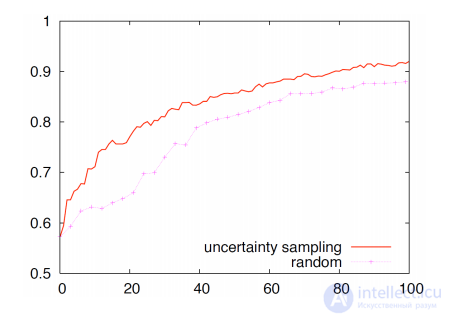
Кривые обучения для классификации текста: бейсбол против хоккея. Кривая графика точность в зависимости от количества документов, запрошенных для двух выборок стратегии: выборка неопределенности (активное обучение) и случайная выборка (пассивное обучение). Мы видим, что активный подход к обучению здесь выше, потому что его кривая обучения доминирует над кривой случайной выборки.
Недостатки стратегий активного обучения:
Идеи применения изучающих действий:
Djallel Bouneouf et al. Contextual bandit for ative learning: ative Thompsonsampling. 2014.
Djallel Bouneouf. Exponentiated Gradient Exploration for Active Learning. 2016.
Алгоритм обертка над любой стратегией активного обучения
Вход: начальная размеченная выборка 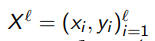 и пул
и пул 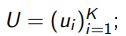 ;
;
Выход: модель a и размеченная выборка 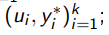 ;
;
обучить модель a по начальной выборке 
пока
остаются неразмеченные объекты
выбрать неразмеченный xi случайно с вероятностью ε,
либо  с вероятностью 1 − ε;
с вероятностью 1 − ε;
узнать 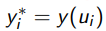 для объекта
для объекта 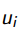 ;
;
дообучить модель a еще на одном примере 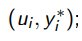 ;
;
Проблема:
как подбирать вероятность ε исследовательских действий?
как ее адаптировать (уменьшать) со временем?
ε1, . . . , εK сетка значений параметра ε;
p1, . . . , pK вероятности использовать значения ε1, . . . , εK ;
β , τ , κ параметры метода.
Идея алгоритма EG-active: аналогично алгоритму AdaBoost,
экспоненциально увеличивать ph в случае успеха εh :
экспоненциальное обновление весов wh по значению критерия φ(ui) на выбранном объекте ui
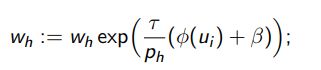
перенормировка вероятностей:
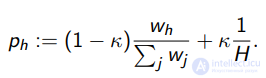
Алгоритм EG-active
Вход: 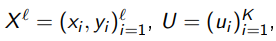 , параметры ε1, . . . , εh , β , τ , κ;
, параметры ε1, . . . , εh , β , τ , κ;
Выход: модель a и размеченная выборка 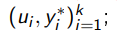
инициализация: 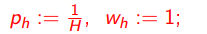
обучить модель a по начальной выборке 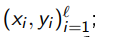
пока
остаются неразмеченные объекты и модель не обучалась выбрать h из дискретного распределения (p1, . . . , ph );
выбрать неразмеченный ui случайно с вероятностью εh ,
либо 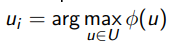 с вероятностью 1 − εh ;
с вероятностью 1 − εh ;
узнать yi * для объекта ui;
дообучить модель a еще на одном примере 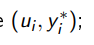

Недостатки стратегий активного обучения:
Идеи применения контекстного бандита (ontextual MAB):
C множество действий (ручек, кластеров объектов),
btc ∈ R
n вектор признаков кластера c ∈ C на шаге t ,
w ∈ R
n вектор коэициентов линейной модели.
Игра агента и среды (
ontextual bandit with linear payo ):
инициализация априорного распределения p1(w);
для всех t = 1, . . . ,T
среда сообщает агенту контексты btc для всех c ∈ C ;
агент сэмплирует вектор линейной модели wt ∼ pt(w);
агент выбирает действие ct = arg max
c∈C
hbtc ,wti;
среда генерирует премию rt
;
агент корректирует распределение по ормуле Байеса:
pt+1(w) ∝ p(rt
|w)pt(w);
Априорные и апостериорные распределения гауссовские.
Игра агента и среды (
ontextual bandit with linear payo ):
инициализация: B = InЧn ; w = 0n ; f = 0n ;
для всех t = 1, . . . ,T
среда сообщает агенту контексты btc для всех c ∈ C ;
агент сэмплирует вектор линейной модели
wt ∼ N (w, σ2B
−1
);
агент выбирает действие ct = arg max
c∈C
hbtc ,wti;
среда генерирует премию rt
;
агент корректирует распределение по ормуле Байеса:
B := B + btcb
т
tc ; f := f + btc rt
; w := B
−1
f ;
екомендуемое значение константы σ
2 = 0.25.
Игра агента и среды (встраиваем активное обучение)
C := кластеризация неразмеченной выборки X
k
;
инициализация: B = InЧn ; w = 0n ; f = 0n ;
для всех t = 1, . . . ,T , пока остаются неразмеченные объекты
вычислить контексты btc для всех кластеров c ∈ C ;
сэмплировать вектор линейной модели wt ∼ N (w, σ2B
−1
);
выбрать кластер ct = arg max
c∈C
hbtc ,wti;
выбрать случайный неразмеченный xi из кластера ct
;
узнать для него yi
;
дообучить модель a ещј на одном примере (xi
, yi);
вычислить премию rt (ормула на следующем слайде);
скорректировать распределение по ормуле Байеса:
B := B + btcb
т
tc ; f := f + btc rt
; w := B
−1
f ;
Идея: премия поощряет изменение модели a(x, θ).
Ht =
a(xi
, θt)
ℓ+k
i=1 вектор ответов на выборке X
ℓ ∪ X
k
Премия угол между векторами Ht и Ht−1:
rt
:= e
βt
arccos
hHt
, Ht−1i
kHtk kHt−1k
,
где экспоненциальный множитель компенсирует убывание расстояний;
β = 0.121 эмпирически подобранный параметр.
Djallel Bouneouf et al. Contextual bandit for active learning: active Thompson sampling. 2014.
btc =
Mdisc ,Vdisc , |c|, plbtc , MixRatetcy
Mdisc среднее внутрикластерное расстояние;
Vdisc дисперсия внутрикластерных расстояний;
|c| число объектов в кластере;
plbtc доля размеченных объектов в кластере;
MixRatetcy доля объектов класса y ∈ Y в кластере.
Всего признаков: 4 + |
R(T) = P
T
t=1
hbtc∗
t
,wti − hbtc ,wti
,
c
∗
t оптимальное действие (R = 0, если все действия оптимальны)
Сравнение накопленных потерь для различных алгоритмов
Пассивный обучающийся агент руководствуется постоянно заданной стратегией, которая определяет его поведение, а активный агент должен сам принимать решение о том, какие действия следует предпринять. Начнем с описания агента, действующего с помощью адаптивного динамического программирования, и рассмотрим, какие изменения необходимо внести в его проект, чтобы он мог функционировать с учетом этой новой степени свободы.
Прежде всего агенту потребуется определить с помощью обучения полную модель с вероятностями результатов для всех действий, а не просто модель для заданной стратегии. Для этой цели превосходно подходит простой механизм обучения, используемый в алгоритме Passive-ADP-Agent. Затем необходимо принять в расчет тот факт, что агент должен осуществлять выбор из целого ряда действий. Полезности, которые ему потребуются для обучения, определяются оптимальной стратегией; они подчиняются уравнениям Беллмана, приведенным на с. 824, которые мы еще раз приведем ниже для удобства.
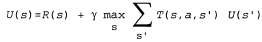 (21.4)
(21.4)
Эти уравнения могут быть решены для получения функции полезности U с помощью алгоритмов итерации по значениям или итерации по стратегиям, приведенных в других статьях (гл17). Последняя задача состоит в определении того, что делать на каждом этапе. Получив функцию полезности U, оптимальную для модели, определяемой с помощью обучения, агент может извлечь информацию об оптимальном действии, составляя одношаговый прогноз для максимизации ожидаемой полезности; еще один вариант состоит в том, что если используется итерация по стратегиям, то оптимальная стратегия уже известна, поэтому агент должен просто выполнить действие, рекомендуемое согласно оптимальной стратегии. Но действительно ли он должен выполнять именно это действие?
Djallel Bouneouf et al. Contextual bandit for active learning: active Thompson sampling. 2014.
William R. Thompson. On the likelihood that one unknown probability exeeds another in view of the evidene of two samples. 1933.
А как ты думаешь, при улучшении активное обучение, будет лучше нам? Надеюсь, что теперь ты понял что такое активное обучение, active learning, машинное обучение, сокращение дисперсии, variane redution, ожидаемое сокращение ошибки, expeted error redution и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение

Комментарии