Лекция
Привет, Вы узнаете о том , что такое метод ансамблей, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое метод ансамблей, бустинг , беггинг , стекинг , настоятельно рекомендую прочитать все из категории Машинное обучение.
Ансамбль методов в статистике и обучении машин использует несколько обучающих алгоритмов с целью получения лучшей эффективности прогнозирования[en], чем могли бы получить от каждого обучающего алгоритма по отдельности . В отличие от статистического ансамбля в статистической механике, который обычно бесконечен, ансамбль методов в обучении машин состоит из конкретного конечного множества альтернативных моделей, но, обычно, позволяет существовать существенно более гибким структурам.
Алгоритмы обучения с учителем наиболее часто описываются как осуществление задачи поиска в пространстве гипотез для нахождения подходящей гипотезы, которая делает хорошие предсказания для конкретной задачи. Даже если пространство гипотез содержит гипотезы, которые очень хорошо подходят для конкретной задачи, может оказаться трудной задачей найти хорошую гипотезу. Ансамбль методов комбинирует несколько гипотез в надежде образовать гипотезу лучше. Термин ансамбль обычно резервируется для методов, которые генерируют несколько гипотез с помощью одного и того же базового учителя. Более широкое понятие системы множественных классификаторов также использует несколько гипотез, но сгенерированных не с помощью одного и того же учителя.
Вычисление предсказания ансамбля обычно требует больше вычислений, чем предсказание одной модели, так что ансамбли можно рассматривать как способ компенсации плохого алгоритма обучения путем дополнительных вычислений. В ансамбле методов обычно используются быстрые алгоритмы, такие как деревья решений[en] (например, случайные леса), хотя медленные алгоритмы могут получить также преимущества от техники сборки в ансамбль.
По аналогии, техника сборки в ансамбль используется также и в сценариях обучения без учителя, например, в кластеризации на основе согласия[en] или в выявлении аномалий.
Ансамбль сам по себе является алгоритмом обучения с учителем, поскольку он может быть тренирован и затем использован для осуществления предсказания. Тренированный ансамбль, поэтому, представляет одну гипотезу. Эта гипотеза, однако, не обязательно лежит в пространстве гипотез моделей, из которых она построена. Таким образом, ансамбли могут иметь большую гибкость в функциях, которые они могут представлять. Эта гибкость может, в теории, быстрее привести их к переобучению по тренировочным данным, чем могло быть в случае отдельной модели, но, на практике, некоторые техники сборки в ансамбль (особенно бэггинг) склонны уменьшить проблемы, связанные с переобучением на тренировочных данных.
Эмпирически, ансамбли склонны давать результаты лучше, если имеется существенное отличие моделей . Многие ансамбли методов, поэтому, стараются повысить различие в моделях, которые они комбинируют . Хотя, возможно, неинтуитивные, более случайные алгоритмы (подобные случайным деревьям решений) могут быть использованы для получения более строгих ансамблей, чем продуманные алгоритмы (такие как деревья решений с уменьшением энтропии) . Использование различных алгоритмов строгого обучения, однако, как было показано, более эффективно, чем использование техник, которые пытаются упростить модели с целью обеспечить большее различие .
В то время как число классификаторов в ансамбле имеют большое влияние на точность предсказания, имеется лишь ограниченное число статей, изучающих эту проблему. Определение априори размера ансамбля и размеров скорости больших потоков данных делает этот фактор даже более критичным для онлайновых ансамблей классификаторов. Большинство статистических тестов были использованы для определения подходящего числа компонент. Относительно недавно теоретический фреймворк дал повод предположить, что имеется идеальное число классификаторов ансамбля, такое, что число классификаторов больше или меньше этого идеального числа приводит к ухудшению точности. Это называется «законом убывания отдачи в построении ансамбля». Этот теоретический фреймворк показывает, что использование числа независимых классификаторов, равного числу меток класса, дает наибольшую точность[10][11].
Байесовский оптимальный классификатор — это техника классификации. Он является ансамблем всех гипотез из пространства гипотез. В среднем ни один из ансамблей не может превосходить его[12]. Простой байесовский оптимальный классификатор — это версия, которая предполагает, что данные условно независимы от класса, и выполняет вычисления за более реальное время. Каждой гипотезе дается голос, пропорциональный вероятности того, что тренировочные данные будут выбраны из системы, если гипотеза была бы верна. Для получения тренировочных данных конечного размера голос каждой гипотезы умножается на априорную вероятность такой гипотезы. Байесовский оптимальный классификатор можно выразить следующим равенством:
 ,
,
где  предсказанный класс,
предсказанный класс,  является множеством всех возможных классов,
является множеством всех возможных классов,  является классом гипотез,
является классом гипотез,  относится к вероятности, а
относится к вероятности, а  является тренировочными данными. Как ансамбль байесовский оптимальный классификатор представляет гипотезу, которая не обязательно принадлежит в . Гипотеза, представленная байесовским оптимальным классификатором, однако, является оптимальной гипотезой в пространстве ансамблей (пространство всех возможных ансамблей, состоящих только из гипотез пространства ).
является тренировочными данными. Как ансамбль байесовский оптимальный классификатор представляет гипотезу, которая не обязательно принадлежит в . Гипотеза, представленная байесовским оптимальным классификатором, однако, является оптимальной гипотезой в пространстве ансамблей (пространство всех возможных ансамблей, состоящих только из гипотез пространства ).
Формулу можно переписать с помощью теоремы Байеса, которая гласит, что постериорная вероятность пропорциональна априорной вероятности:

откуда

Бутстрэп-агрегирование, часто сокращаемое до бэггинг, дает каждой модели в ансамбле одинаковый вес (голос). Чтобы поддерживать вариантность, бэггинг тренирует каждую модель в ансамбле с помощью случайно отобранного подмножества из тренировочного множества. Как пример, алгоритм «случайного леса» комбинирует случайные деревья решений с бэггингом, чтобы получить высокую точность классификации[13].
Бустинг строит ансамбль последовательными приращениями путем тренировки каждой новой модели, чтобы выделить тренировочные экземпляры, которые предыдущие модели классифицировали ошибочно. Об этом говорит сайт https://intellect.icu . В некоторых случаях бустинг, как было показано, дает лучшие результаты, чем бэггинг, но имеет тенденцию к переобучению на тренировочных данных. Наиболее частой реализацией бустинга является алгоритм AdaBoost, хотя есть утверждения, что некоторые более новые алгоритмы дают лучшие результаты.
Усреднение байесовских параметров (англ. Bayesian parameter averaging, BPA) — это техника сборки ансамбля, которая пытается аппроксимировать байесовский оптимальный классификатор путем семплинга из пространства гипотез и комбинирования их с помощью закона Байеса[14]. В отличие от байесовского оптимального классификатора, байесовская модель усреднения может быть практически реализована. Гипотезы обычно отбираются с помощью техники Монте-Карло, такой как MCMC[en]. Например, может быть использовано семплирование по Гиббсу для выборки гипотез, которые представляют распределение  . Было показано, что при некоторых обстоятельствах, если гипотезы выбираются таким образом и усредняются согласно закону Байеса, эта техника имеет ожидаемую ошибку, которая ограничена удвоенной ожидаемой ошибки байесовского оптимального классификатора[15]. Не смотря на теоретическую корректность этой техники, в ранних работах на основе экспериментальных данных было высказано предположение, что метод склонен к переобучению и ведет себя хуже, чем простые техники сборки ансамбля, такие как бэггинг[16]. Однако эти заключения были основаны на недопонимании цели байесовской модели усреднения для комбинации моделей[17]. Кроме того, есть существенные преимущества в теории и практике БМУ. Недавние строгие доказательства показывают точность БМУ для выбора переменных и оценке при многомерных условиях[18] и дают эмпирическое свидетельство существенной роли обеспечения разреженности в БМУ в смягчении переобучения[19].
. Было показано, что при некоторых обстоятельствах, если гипотезы выбираются таким образом и усредняются согласно закону Байеса, эта техника имеет ожидаемую ошибку, которая ограничена удвоенной ожидаемой ошибки байесовского оптимального классификатора[15]. Не смотря на теоретическую корректность этой техники, в ранних работах на основе экспериментальных данных было высказано предположение, что метод склонен к переобучению и ведет себя хуже, чем простые техники сборки ансамбля, такие как бэггинг[16]. Однако эти заключения были основаны на недопонимании цели байесовской модели усреднения для комбинации моделей[17]. Кроме того, есть существенные преимущества в теории и практике БМУ. Недавние строгие доказательства показывают точность БМУ для выбора переменных и оценке при многомерных условиях[18] и дают эмпирическое свидетельство существенной роли обеспечения разреженности в БМУ в смягчении переобучения[19].
Комбинация байесовских моделей (КБМ, англ. Bayesian model combination, BMC) — это алгоритмическое исправление байесовской модели усреднения (БМУ, англ. Bayesian model averaging, BMA). Вместо выбора каждой модели в ансамбль индивидуально, алгоритм отбирает из пространства возможных ансамблей (с весами моделей, выбранных случайно из распределения Дирихле с однородными параметрами). Эта модификация позволяет избежать тенденцию БМУ отдать полный вес одной модели. Хотя КБМ вычислительно несколько более расточителен по сравнению с БМУ, он дает существенно лучшие результаты. Результаты КБМ, как было показано, в среднем лучше, чем БМУ и бэггинг[20].
Использование закона Байеса для вычисления весов модели неизбежно влечет вычисление вероятности данных для каждой модели. Обычно ни одна из моделей в ансамбле не имеет точно такое же распределение, что и тренировочные данные, из которых они сгенерированы, так что все члены корректно получают значение, близкое к нулю. Это хорошо бы работало, если бы ансамбль был достаточно большим для выборки из полного пространства моделей, но такое редко случается возможным. Следовательно, каждый представитель тренировочного набора вызывает вес ансамбля сдвигаться к модели в ансамбле, которая наиболее близка к распределению тренировочных данных. Это существенно уменьшает необходимость чрезмерно сложного метода выбора модели.
Возможные веса для ансамбля можно представить как лежащие на симплексе. На каждой вершине симплекса все веса задаются отдельной моделью ансамбля. БМУ сходится к вершине, которая ближе по распределению с тренировочными данными. Для контраста, КБМ сходится к точке, где это распределение проектируется в симплекс. Другими словами, вместо выбора одной модели, которая ближе всего к распределению, метод ищет комбинацию моделей, наиболее близкой к распределению.
Результаты БМУ можно часто аппроксимировать с помощью перекрестной проверки для выбора модели из ведра моделей. Аналогично, результаты КБМ можно аппроксимировать с помощью перекрестной проверки для выбора лучшей комбинации ансамблей из случайной выборки возможных весов.
«Ведро моделей» (англ. bucket of models) является техникой сбора ансамбля, в которой используется алгоритм выбора модели для получения лучшей модели для каждой задачи. Когда тестируется только одна задача, ведро моделей не может дать результат лучше, чем лучшая модель в наборе, однако в случае прогона для нескольких задач, алгоритм обычно дает более хорошие результаты, чем любая модель в наборе.
Наиболее частый подход, используемый для выбора модели,— это перекрестная выборка. Он описывается следующим псевдокодом:
Для каждой модели в ведре:
Выполнить c раз: (где 'c' — некоторая константа)
Случайным образом делим тренировочные данные на два набора: A и B.
Тренируем m по A
Проверяем m по B
Выбираем модель, которая покажет высший средний результат
Перекрестная выборка может быть описана как: «прогони все на тренировочном множестве и выбери тот, что работает лучше»[21].
Выделение (англ. Gating) является обобщением перекрестной выборки. Метод вовлекает тренировку другой модели обучения для решения, какая из моделей в ведре больше подходит для решения задачи. Часто для выделения модели используется перцептрон. Он может быть использован для выбора «лучшей» модели, или он может быть использован для получения линейного веса для предсказаний из каждой модели в ведре.
Когда ведро моделей используется с большим набором задач, может быть желательным избежать тренировки некоторых моделей, которые требуют долгого времени тренировки. Ландмарк-обучение — это метаобучающий подход, который ищет решение этой задачи. Он вовлекает для тренировки только быстрые (но неточные) алгоритмы, а затем используется эффективность этих алгоритмов для определения, какой из медленных (но точных) алгоритмов выбрать как лучший[22].
Стогование (иногда называемое стековое обобщение) вовлекает тренировку обучающего алгоритма для комбинирования предсказаний нескольких других обучающих алгоритмов. Сначала все другие алгоритмы тренируются с помощью допустимых данных, затем алгоритмы комбинирования тренируются с целью сделать конечное предсказание с помощью всех предсказаний других алгоритмов как дополнительный вход. Если используется произвольный алгоритм комбинирования, то стогование может теоретически представлять любую технику создания ансамблей, описанную в этой статье, хотя, на практике, модель логистической регрессии часто используется в качестве средства алгоритма комбинирования.
Стогование обычно дает лучшую эффективность, чем любая отдельная из тренировочных моделей[23]. Оно было успешно использовано как в задачах обучения с учителем (регрессии[24], классификации и дистанционного обучения[25]), так и задачах обучения без учителя (оценка плотности)[26]. Он использовался также для оценки ошибки бэггинга [27]. Утверждалось, что метод превзошел байесовскую модель усреднения[28]. Два призера конкурса Netflix используют смешивание, которое можно считать формой стогования[29].
В недавние годы, вследствие растущей вычислительной мощности, позволяющей тренировку больших тренировочных обучающих ансамблей в разумное время, число приложений росло все быстрее[35]. Некоторые из приложений ансамблей классификаторов приведены ниже.
Отражение растительного покрова
Отражение растительного покрова[en] является одним из главных приложений наблюдения за Землей[en], использующим дистанционное зондирование и географические данные[en] для распознавания объектов, которые расположены на поверхности целевых областей. Как правило, классы целевого материала включают дороги, здания, реки, озера и растительность[36]. Были предложены некоторые различные подходы обучения ансамблей, базирующихся на искусственных нейронных сетях[37], ядерном методе главных компонент[en] (англ. kernel principal component analysis, KPCA)[38], деревьях решений с бустингом[39], случайных лесах[36] и автоматическом создании нескольких систем классификаторов[40], для эффективного распознавания объектов растительного покрова.
Обнаружение изменени
Обнаружение изменений[en] является задачей анализа изображений[en], заключающейся в идентификации мест, где растительный покров изменился с течением времени. Обнаружение изменений[en] широко используется в таких областях, как рост городов[en], динамика изменений в лесах и растительности[en], землепользование и обнаружение стихийных бедствий[en][41]. Ранние приложения ансамблей классификаторов в определении изменений разрабатывались с помощью голосования большинством голосов[en], байесовского среднего[en] и оценки апостериорного максимума[42].
DoS-атака
Распределенная атака типа отказа в обслуживании является одной и самых угрожающих кибератак, которая может случаться с интернет-провайдером[35]. Путем комбинирования выхода отдельных классификаторов ансамбль классификаторов снижает общую ошибку детектирования и отделения таких атак от законных флешмобов[43].
Обнаружение вредоносных программ
Классификация кодов вредоносных программ, таких как компьютерные вирусы, сетевые черви, трояны, вирусы-вымогатели и программы-шпионы, с помощью техник обучения машин, навеяна задачей категоризации документов[44]. Системы обучения ансамблей показали надежную эффективность в этой области
Обнаружение вторжения
Система обнаружения вторжений отслеживает для идентификации кодов вторжения компьютерную сеть или компьютеры подобно процессу выявления аномалий. Обучение ансамблей успешно помогает таким системам сокращать общее число ошибок
Распознавание лиц
Распознавание лиц, которое недавно стало наиболее популярной областью исследований в распознавания образов, справляется с идентификацией или верификацией личности по его/ее цифровому изображению[49].
Иерархические ансамбли, основанные на классификаторе Габора Фишера и техниках предварительной обработки данных при анализе независимых компонентов[en], являются некоторыми ранними ансамблями, используемыми в этой области
В то время как распознавание речи главным образом основывается на глубоком обучении, поскольку большинство индустриальных игроков в этой области, такие как Google, Microsoft и IBM, используют его в качестве основы технологии распознавания речи, основанное на разговоре распознавание эмоций[en] может иметь удовлетворительные показатели с обучением ансамбля
Метод также успешно использовался в распознавании эмоций на лице
Выявление мошенничества имеет дело с идентификацией банковского мошенничества[en], такого как отмывание денег, мошенничество с платежными картами и телекоммуникационное мошенничество. Выявление мошенничества имеет широкие возможности для исследования и применения обучения машин. Поскольку обучение ансамбля улучшает устойчивость нормального поведения моделирования, оно было предложено в качестве эффективной техники определения таких случаев мошенничества и подозрительной активности в банковских операциях в системах кредитных карт
Точность предсказания коммерческого краха является важнейшим вопросом при принятии финансовых решений, поэтому были предложены различные ансамбли классификаторов для предсказания финансовых кризисов и финансовых крахов[en][60]. Также в задаче манипуляции на основе торгов[en], где трейдеры пытаются манипулировать ценами акций путем покупки или продажи, ансамблю классификаторов требуется проанализировать изменения в данных на рынке ценных бумаг и определить симптомы подозрительных манипуляций[en] с ценами акций[60].
Система классификаторов успешно применена в нейронауках, протеомике и медицинской диагностике. Подобно нейрокогнитивному расстройству[en] (то есть болезни Альцгеймера или миотонической дистрофии[en]) распознавание основывается на данных магнитно-резонансной томографии
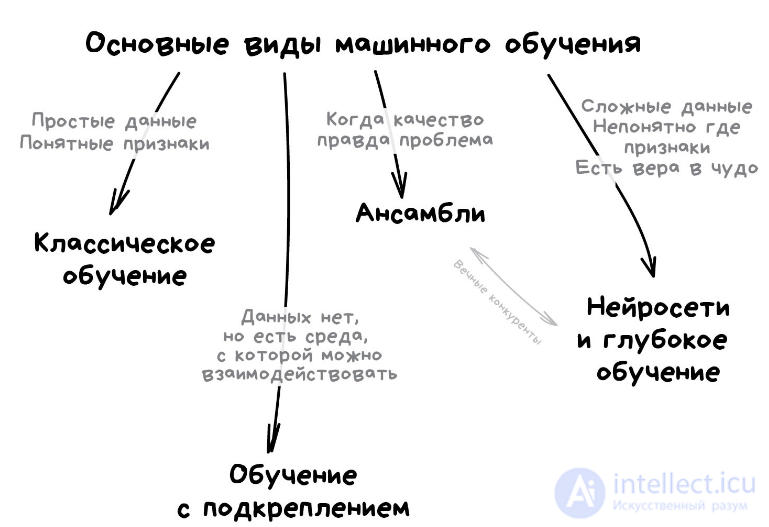
«Куча глупых деревьев учится исправлять ошибки друг друга»
Сегодня используют для:
Популярные алгоритмы: Random Forest, Gradient Boosting
Теперь к настоящим взрослым методам. Ансамбли и нейросети — наши главные бойцы на пути к неминуемой сингулярности. Сегодня они дают самые точные результаты и используются всеми крупными компаниями в продакшене. Только о нейросетях трещат на каждом углу, а слова «бустинг» и «бэггинг», наверное, пугают только хипстеров с теккранча.
При всей их эффективности, идея до издевательства проста. Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причем даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Ансамбль можно собрать как угодно, хоть случайно нарезать в тазик классификаторы и залить регрессией. За точность, правда, тогда никто не ручается. Потому есть три проверенных способа делать ансамбли.
стекинг Обучаем несколько разных алгоритмов и передаем их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.
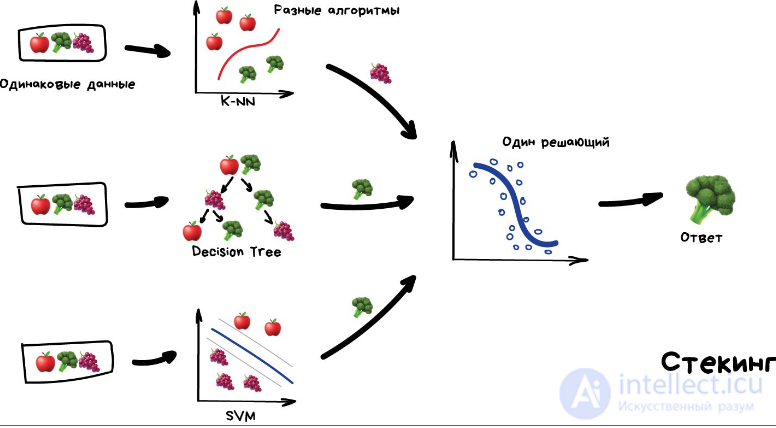
Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию.
Чисто из опыта — стекинг на практике применяется редко, потому что два других метода обычно точнее.
беггинг Он же Bootstrap AGGregatING. Обучаем один алгоритм много раз на случайных выборках из исходных данных. В самом конце усредняем ответы.
Данные в случайных выборках могут повторяться. То есть из набора 1-2-3 мы можем делать выборки 2-2-3, 1-2-2, 3-1-2 и так пока не надоест. На них мы обучаем один и тот же алгоритм несколько раз, а в конце вычисляем ответ простым голосованием.
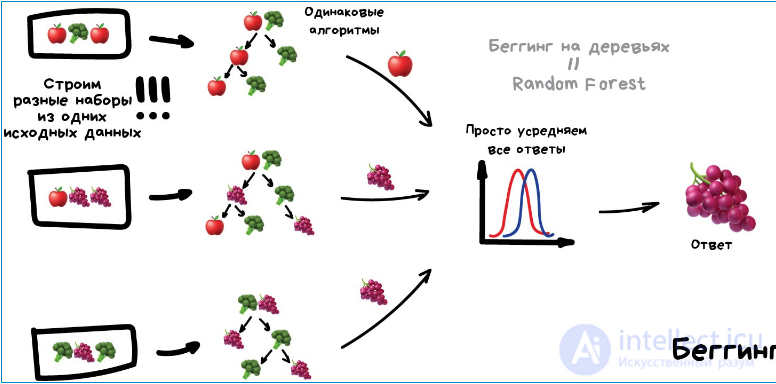
Самый популярный пример беггинга — алгоритм Random Forest, беггинг на деревьях, который и нарисован на картинке. Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Дикая способность параллелиться дает беггингу преимущество даже над следующим методом, который работает точнее, но только в один поток. Хотя можно разбить на сегменты, запустить несколько... ах кого я учу, сами не маленькие.

Бустинг Обучаем алгоритмы последовательно, каждый следующий уделяет особое внимание тем случаям, на которых ошибся предыдущий.
Как в беггинге, мы делаем выборки из исходных данных, но теперь не совсем случайно. В каждую новую выборку мы берем часть тех данных, на которых предыдущий алгоритм отработал неправильно. То есть как бы доучиваем новый алгоритм на ошибках предыдущего.
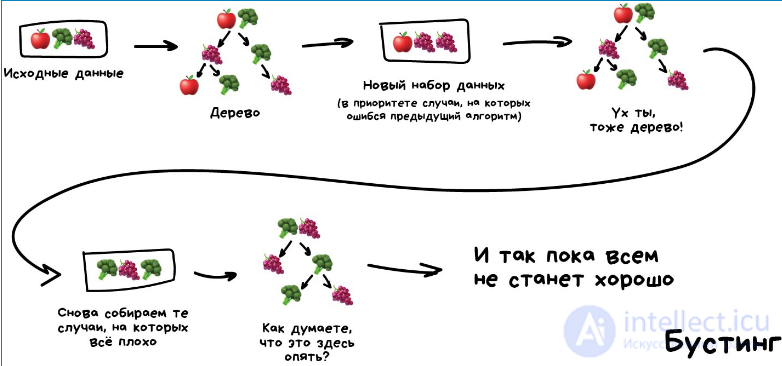
Плюсы — неистовая, даже нелегальная в некоторых странах, точность классификации, которой позавидуют все бабушки у подъезда. Минусы уже названы — не параллелится. Хотя все равно работает быстрее нейросетей, которые как груженые камазы с песком по сравнению с шустрым бустингом.
Нужен реальный пример работы бустинга — откройте Яндекс и введите запрос. Слышите, как Матрикснет грохочет деревьями и ранжирует вам результаты? Вот это как раз оно, Яндекс сейчас весь на бустинге. Про Google не знаю.
Сегодня есть три популярных метода бустинга, отличия которых хорошо донесены в статье CatBoost vs. LightGBM vs. XGBoost
Исследование, описанное в статье про метод ансамблей, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое метод ансамблей, бустинг , беггинг , стекинг и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение

Комментарии