Лекция
Сразу хочу сказать, что здесь никакой воды про метод статистического моделирования на эвм, и только нужная информация. Для того чтобы лучше понимать что такое метод статистического моделирования на эвм , настоятельно рекомендую прочитать все из категории Теория надёжности.
На этапе исследования и проектирования систем при построении и реализации машинных моделей (аналитических и имитационных) широко используется метод статистических испытаний (Монте-Карло), который базируется на использовании случайных чисел, т. е. возможных значений некоторой случайной величины с заданным распределением вероятностей. Статистическое моделирование представляет собой метод получения с помощью ЭВМ статистических данных о процессах, происходящих в моделируемой системе. Для получения представляющих интерес оценок характеристик моделируемой системы S с учетом воздействий внешней среды Е статистические данные обрабатываются и классифицируются с использованием методов математической статистики.
Сущность метода статистического моделирования. Таким образом, сущность метода статистического моделирования сводится к построению для процесса функционирования исследуемой системы S некоторого моделирующего алгоритма, имитирующего поведение и взаимодействие элементов системы с учетом случайных
входных воздействий и воздействий внешней среды Е, и реализации этого алгоритма с использованием программно-технических средств ЭВМ.
Различают две области применения метода статистического моделирования:
1) для изучения стохастических систем;
2) для решения детерминированных задач.
Основной идеей, которая используется для решения детерминированных задач методом статистического моделирования, является замена детерминированной задачи эквивалентной схемой некоторой стохастической системы, выходные характеристики последней совпадают с результатом решения детерминированной задачи. Естественно, что при такой замене вместо точного решения задачи получается приближенное решение и погрешность уменьшается с увеличением числа испытаний (реализаций моделирующего алгоритма) N.
В результате статистического моделирования системы S получается серия частных значений искомых величин или функций, статистическая обработка которых позволяет получить сведения о поведении реального объекта или процесса в произвольные моменты времени. Если количество реализаций N достаточно велико, то полученные результаты моделирования системы приобретают статистическую устойчивость и с достаточной точностью могут быть приняты в качестве оценок искомых характеристик процесса функционирования системы S.
Пример детерминированной задачи – задача вычисления одномерного или многомерного интеграла методом статистических испытаний.
Теоретической основой метода статистического моделирования систем на ЭВМ являются предельные теоремы теории вероятностей. Множества случайных явлений (событий, величин) подчиняются определенным закономерностям, позволяющим не только прогнозировать их поведение, но и количественно оценить некоторые средние их характеристики, проявляющие определенную устойчивость. Характерные закономерности наблюдаются также в распределениях случайных величин, которые образуются при сложении множества воздействий. Выражением этих закономерностей и устойчивости средних показателей являются так называемые предельные теоремы теории вероятностей, часть из которых приводится ниже в пригодной для практического использования при статистическом моделировании формулировке. Принципиальное значение предельных теорем состоит в том, что они гарантируют высокое качество статистических оценок при весьма большом числе испытаний (реализаций) N. Практически приемлемые при статистическом моделировании количественные оценки характеристик систем часто могут быть получены уже при сравнительно небольших (при использовании ЭВМ) N.
1. Неравенство Чебышева.
Для неотрицательной функции 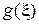 случайной величины
случайной величины 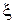 и любого К> 0 выполняется неравенство
и любого К> 0 выполняется неравенство
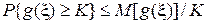
В частности, если  и
и 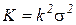 (где
(где 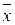 – среднее арифметическое;
– среднее арифметическое; 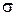 — среднеквадратическое отклонение), то
— среднеквадратическое отклонение), то
 .
.
2. Теорема Бернулли. Если проводится N независимых испытаний, в каждом из которых некоторое событие А осуществляется с вероятностью р, то относительная частота появления события m/N при  сходится по вероятности к р, т. е. при любом
сходится по вероятности к р, т. е. при любом 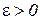
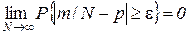 ,
,
где m — число положительных исходов испытания.
3. Теорема Пуассона. Если проводится N независимых испытаний и вероятность осуществления события А в i-м испытании равна 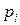 , то относительная частота появления события m/N при сходится по вероятности к среднему из вероятностей , т. е. при любом
, то относительная частота появления события m/N при сходится по вероятности к среднему из вероятностей , т. е. при любом
 .
.
4. Теорема Чебышева. Если в N независимых испытаниях наблюдаются значения 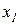 ,…,
,…,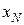 случайной величины , то при среднее арифметическое значений случайной величины сходится по вероятности к ее математическому ожиданию а, т. е. при любом
случайной величины , то при среднее арифметическое значений случайной величины сходится по вероятности к ее математическому ожиданию а, т. е. при любом
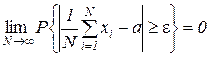 .
.
5. Обобщенная теорема Чебышева.Если 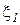 ,…,
,…, — независимые случайные величины с математическими ожиданиями
— независимые случайные величины с математическими ожиданиями 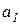 ,…,
,…, и дисперсиями
и дисперсиями 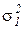 ,…,
,…,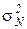 , ограниченными сверху одним и тем же числом, то при среднее арифметическое значений случайной величины сходится по вероятности к среднему арифметическому их
, ограниченными сверху одним и тем же числом, то при среднее арифметическое значений случайной величины сходится по вероятности к среднему арифметическому их
математических ожидании:
 (*)
(*)
6. Теорема Маркова. Выражение (*) справедливо и для зависимых случайных величин ,…,, если только
 .
.
Совокупность теорем, устанавливающих устойчивость средних показателей, принято называть законом больших чисел.
7. Центральная предельная теорема. Если ,…,— независимые одинаково распределенные случайные величины, имеющие математическое ожидание а и дисперсию 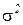 , то при закон распределения суммы
, то при закон распределения суммы  неограниченно приближается к нормальному:
неограниченно приближается к нормальному:
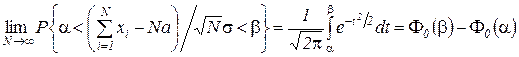 .
.
Здесь интеграл вероятностей
 .
.
8.Теорема Лапласа. Если в каждом из N независимых испытаний событие Апоявляется с вероятностью р, то
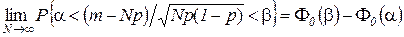
где m — число появлений события А в N испытаниях. Теорема Лапласа является частным случаем центральной предельной теоремы.
Идея метода моделирования, в основу которого положен метод статистических испытаний (метод Монте-Карло), заключается в том, что показатели качества функционирования исследуемого процесса, сложным образом зависящие от большого числа случайных факторов, вычисляют не по формулам (часто эти формулы получить невозможно), а с помощью так называемого розыгрыша.
При этом строится вероятностная модель исследуемого процесса функционирования АСУ и реализуется случайным образом с помощью ЭВМ. Полученные результаты являются приближенным решением задачи.
При построении модели (разработка моделирующего алгоритма) сложный стохастический процесс рассматривается как последовательность конечного числа взаимосвязанных элементарных стохастических актов. Реализация модели на ЭВМ (решение задачи) представляет собой последовательное поэлементное теоретическое воспроизведение процесса, моделирующее реальную физическую систему.
Особенностью метода является то, что получаемая в результате моделирования информация по своей природе аналогична той информации, которую можно было бы получить в процессе исследования реальной системы, однако объем ее значительно больший и на ее получение затрачивается меньше средств и времени. Отсюда следует эффективность использования метода моделирования, а также высокая точность и достоверность получаемых с его помощью результатов по сравнению с исследованием реальной системы.
Метод моделирования обычно используется для решения двух классов задач: детерминированных и вероятностных. Наибольший практический интерес представляет
применение метода к вероятностным задачам, что позволяет решать задачи, не сформулированные в виде уравнений или формул.
В основе решения на ЭВМ вероятностных задач лежит моделирование случайных явлений. Об этом говорит сайт https://intellect.icu . Различные случайные величины, характеризующие отдельные стороны исследуемого процесса, воспроизводятся на ЭВМ с помощью случайных чисел в соответствии с заданными законами распределения.
Теоретической основой метода моделирования служит закон больших чисел. Следовательно, этот метод основан на самых общих теоремах теории вероятностей и принципиально не содержит никаких ограничений. Он может быть применен для исследования любой системы с известным алгоритмом функционирования, а при достаточно большом числе испытаний от него можно требовать любой точности. Метод моделирования позволяет полнее учесть особенности функционирования исследуемых систем, использовать любые законы распределения исходных случайных величин, имеет наглядную вероятностную трактовку, достаточно простую вычислительную схему и малую чувствительность к случайным сбоям машины в процессе решения. Все это достоинства метода.
Вместе с тем метод моделирования обладает рядом недостатков, наиболее существенными из которых являются большая трудоемкость и частный характер решения. Эффективными путями преодоления этих недостатков являются:
разработка обобщенных универсальных подходов к построению моделирующих алгоритмов для исследования процессов функционирования систем различных классов;
создание библиотеки стандартных подалгоритмов и подпрограмм, моделирующих все основные типовые операции, встречающиеся при решении различных задач, и используемых как готовые стандартные блоки (например, моделирование случайных величин с различными законами распределения, оценка точности результатов, построение гистограмм случайных величин и т. п.);
создание библиотеки стандартных алгоритмов и программ для решения основных типовых задач исследования систем;
дальнейшее развитие вопросов автоматизации программирования и отладки программ на основе совершенствования существующих и разработки новых эффективных алгоритмических языков;
синтез метода моделирования с аналитическими методами, позволяющий наилучшим образом использовать положительные стороны каждого из них.
Моделирование на ЭВМ процессов функционирования различных систем связано с выработкой большого количества случайных чисел с заданными законами распределения. Для этой цели используется обычно один из следующих способов:
генерирование случайных чисел специальной электронной приставкой к машине — датчиком случайных чисел;
получение случайных чисел в машине в соответствии с заданной программой формирования.
Принцип действия датчика случайных чисел основан на использовании некоторых свойств физических явлений (например, собственные шумы электронных ламп, излучение радиоактивных источников). Таким образом, можно получить равномерно распределенную последовательность, распределение Пуассона и ряд других.
Однако большинство универсальных ЭВМ не имеет датчиков случайных чисел, поэтому наибольшее распространение получил программный способ формирования случайных последовательностей, основанный на использовании некоторого рекуррентного соотношения.
При этом в качестве основного механизма генерирования случайных величин используется последовательность равномерно распределенных в интервале (0,1) случайных чисел , которые подвергаются дальнейшим преобразованиям для получения заданных законов распределения.
Рассмотрим некоторые из алгоритмических способов формирования равномерно распределенных случайных чисел.
Пусть F(х) и f(х) соответственно функция и плотность распределения некоторой случайной величины X, а i — случайное число с равномерным законом распределения в интервале (0,1). Тогда для получения случайного числа xi из совокупности случайных чисел, имеющих заданную функцию распределения F(х), необходимо решить относительно xi следующее интегральное уравнение:
 (6.1)
(6.1)
т. е. определить такое значение xi, при котором функция распределения F (х) равна i.
Для некоторых частных законов распределения уравнение (6.1) удается решить непосредственно. В большинстве же практически важных случаев уравнение (6.1) точно не решается. Тогда используют приближенные способы преобразования случайных чисел, которые можно условно разбить на две группы. К первой группе относятся способы, основанные при приближенном решении уравнения (6.1):
численное решение уравнения (6.1) в процессе преобразования случайных чисел;
предварительная аппроксимация подынтегральной функции в уравнении (6.1) полиномами или другими функциями, обеспечивающими простоту решения уравнения;
использование заранее составленных таблиц, содержащих решения уравнения (6.1).
Таблица 6.1
|
Наименование и параметры распределения |
Плотность распределения |
Математическое ожидание |
Дисперсия |
Формула для вычисления случайного числа |
|
Равномерное в интервале (a, b) |
|
|
|
|
|
Экспоненциальное с параметром |
|
|
|
|
|
Сдвинутое экспоненциальное с параметрами и b (параметр сдвига) |
|
|
|
|
|
Нормальное с параметрами а (математическое ожидание) и 2 (дисперсия) |
|
a |
2 |
|
|
Логарифмически нормальное с параметрами а и |
|
|
|
где |
|
Эрланга с параметрами k и |
|
|
|
|
|
2 с параметром n (число степеней свободы) |
|
n |
2n |
|
|
Вейбулла с параметрами (масштабный параметр) и k (параметр, определяющий асимметрию и эксцесс) |
|
|
|
|
|
Релея а параметром |
|
|
0,429 2 |
|
|
Стьюдента с параметром n (число степеней свободы) |
|
0 |
|
|
|
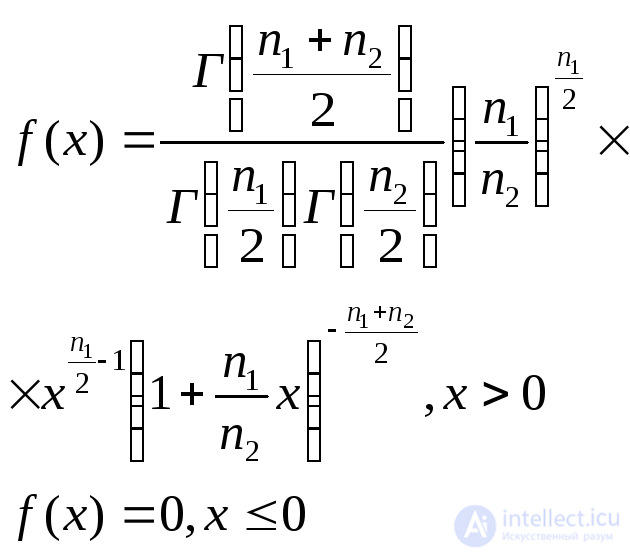
Фишера с параметрами n1 и n2 (число степеней свободы) |
|
|
|
|
|
Бета с параметрами n и m (число степеней свободы) |
|
|
|
|
Примечание. 
Ко второй группе относятся способы, не связанные с решением уравнения (6.1):
отбор случайных чисел с заданным законом распределения из исходной совокупности случайных чисел с равномерным распределением в интервале (0,1);
приближенное моделирование условий предельных теорем теории вероятностей.
В табл. 6.1 для различных непрерывных законов приведены формулы для вычисления случайных чисел xi, полученные с использованием указанных выше способов а также выражения, устанавливающие связи между параметрами каждого распределения и его
математическим ожиданием и дисперсией. Эти формулы обычно используются при исследовании влияния различных типов законов распределения исходных случайных величин на результаты моделирования.
Часто при решении задач на ЭЦВМ возникает необходимость моделирования случайных событий с известным распределением вероятностей. Покажем, как это делается. Предположим, что заданы численные значения вероятностей P1 , Р2,, ..., Рп для независимых событий A1 , А2 ,..., Аn , составляющих полную группу. Нужно определить в каждом испытании, какое из этих событий произошло.
Разобьем отрезок (0,1) на п отрезков так, чтобы длина i-го отрезка равнялась вероятности Pi. Выбирая из равномерного в интервале (0,1) распределения случайные числа i, будем определять, на какой участок отрезка попадает число i. Попадание случайного числа на i-й участок фиксируется как факт свершения события Ai.
Очевидно, что при достаточно большом числе испытаний количество попаданий на i-й участок будет пропорционально его длине (т. е. значению Рi), а это означает, что случайные события Ai воспроизводятся в соответствии с распределением вероятностей Рi.В ЭВМ этот процесс сводится к выбору случайного числа i и последовательной проверке условия
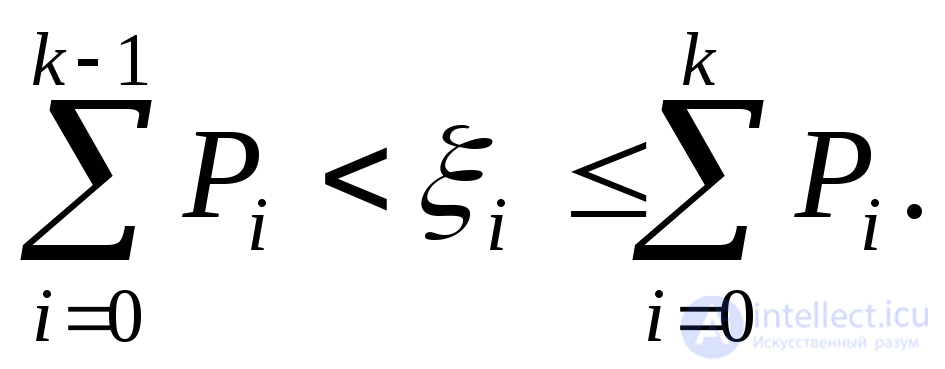 (6.2)
(6.2)
Для фиксированного i неравенство (6.2) выполняется лишь при каком-то одном значении k (k = l, 2, ..., п). Это значение k и определяет номер события Ап, которое произошло в данном опыте.
В простейшем случае число возможных исходов равнодвум, т.е. задана вероятность Р(А) события А и в каждом испытании требуется определить, произошло это событие или нет. Тогда процедура сводится к однократной проверке неравенства
i Р (А) (6.3)
Если это неравенство выполняется, то фиксируется факт свершения события А.
Моделирование дискретной случайной величины X фактически сводится к рассмотренной ранее схеме случайных событий, так как каждому из возможных значений случайной величины X ставится в соответствие определенное значение вероятности Р (X = т) того, что случайная величина примет значение, равное m. Алгоритмы для моделирования некоторых дискретных распределений (Пуассона, геометрического и др.) приведены в работе.
Результаты моделирования обладают определенной погрешностью, источниками которой могут быть: упрощение модели, неточность определения исходных данных, ограниченное число реализаций, сбои и т. п. Рассмотрим более подробно погрешность, обусловленную ограниченным числом реализаций, и приведем формулы для ее оценки.
Сточки зрения математической статистики, процесс моделирования сводится к выбору определенного объема из генеральной совокупности. В результате моделирования на основе полученного статистического материала дается количественное описание исследуемых случайных величин, т. е. определяются основные числовые характеристики (математическое ожидание, дисперсия, статистическая функция распределения и т. д.). При этом вследствие ограниченного числа испытаний вместо точных значений показателей мы получаем их приближенные значения, называемые оценками.
К оценкам искомых показателей следует подходить как к обычным случайным величинам. При этом необходимо учитывать, что закон распределения оценки зависит и от распределения самой случайной величины, и от числа опытов. При реализации метода моделирования на ЭВМ число испытаний обычно бывает достаточно большим (от нескольких сотен до десятков тысяч). Это позволяет сделать вывод о нормальном законе распределения оценок математического ожидания, дисперсии, вероятности события, что существенно упрощает анализ точности результатов моделирования.
На практике задача сводится к определению точности результатов по известному числу реализаций1 пp или наоборот— к выбору такого значения пp, которое обеспечивает получение результатов с заданной точностью . По существу, это одна задача, решение которой основывается на взаимосвязи трех величин: числа реализаций np, точности и достоверности результатов. Под достоверностью понимается доверительная вероятность
=P{a* - < a < a* + }, (6.4)
т. е. вероятность того, что интервал (a* - , a* + ) со случайными границами (доверительный интервал) накроет неизвестный параметр а.
В практике моделирования широкое применение получил метод автоматического контроля точности результатов моделирования с помощью ЭВМ. Сущность этого метода состоит в следующем: задают первоначальное число реализаций nр* (заведомо заниженное), а затем после каждой последующей реализации с помощью машины проверяется условие
< тр, (6.5)
где , тр — соответственно текущее и требуемое значение относительной погрешности результатов.
При выполнении условия (6.5) расчет прекращается, и машина выдает результаты моделирования на печать.
Для оценки относительной погрешности математического ожидания некоторой случайной величины X и вероятности Р события А используются формулы:
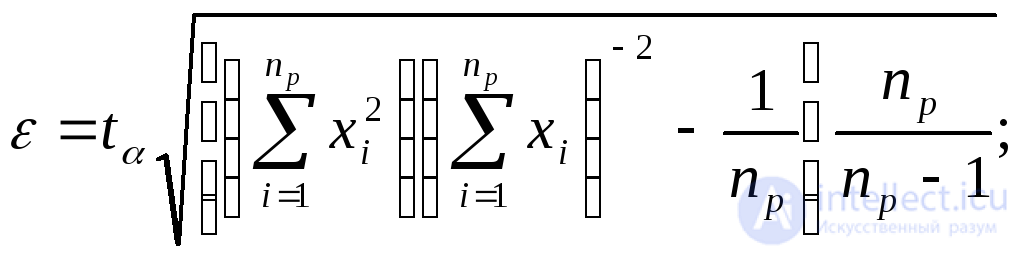 (6.6)
(6.6)
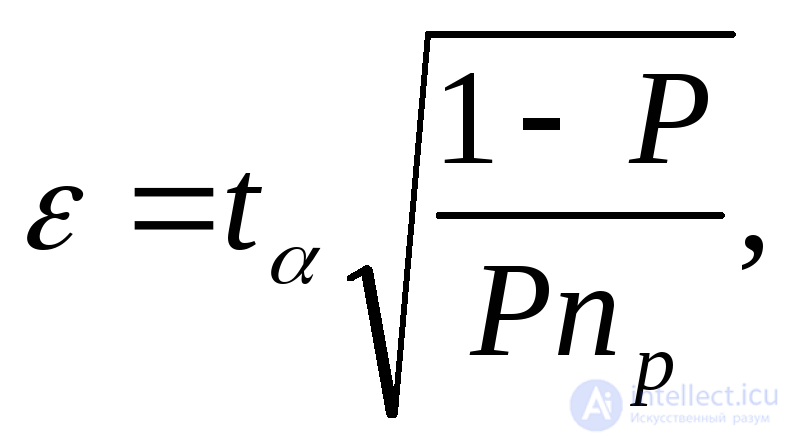 (6.7)
(6.7)
где  ;
; -функция, обратная функции Лапласа, т. е. такое значение аргумента, при котором функция Лапласа равна доверительной вероятности (значения t. табулированы и приведены в работе).
-функция, обратная функции Лапласа, т. е. такое значение аргумента, при котором функция Лапласа равна доверительной вероятности (значения t. табулированы и приведены в работе).
Для оценки относительной погрешности при вычислении дисперсии случайной величины X используется выражение
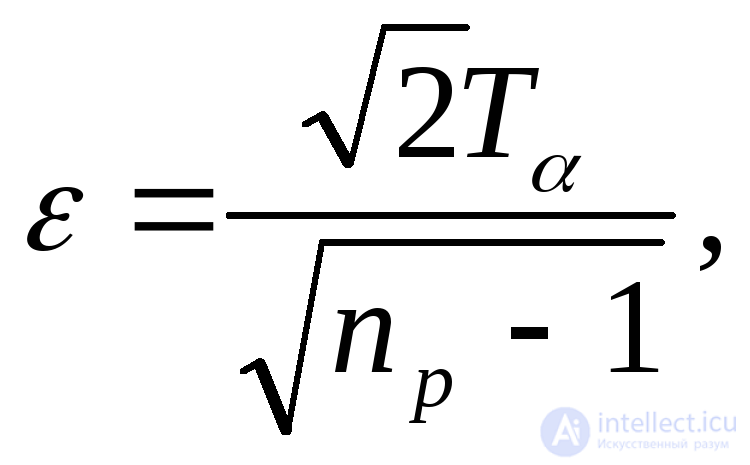 (6.8)
(6.8)
из которого при заданном значении t нетрудно определить число реализаций nр, обеспечивающее требуемую относительную погрешность е.
Анализ показывает, что рассматриваемые процессы функционирования промышленных АСУ, как правило, обладают свойствами стационарности и эргодичности. Поэтому моделирующие алгоритмы для их исследования построены таким образом, что воспроизводят процессы функционирования систем в течение заданного длительного интервала времени мод (моделируется одна длинная реализация), обеспечивающего получение статистически устойчивых результатов решения. Обычно длина интервала моделирования мод задается ориентировочно с таким расчетом, чтобы в течение этого времени каждый из элементов исследуемой системы отказал несколько раз.
Подготовка и решение задач оценки надежности и эффективности АСУ с помощью ЭВМ — сложный и трудоемкий процесс, требующий совместной работы специалистов различного профиля. Можно условно разбить этот процесс на следующие этапы:
постановка задачи и изучение исследуемого процесса;
выбор и обоснование показателей качества исследуемого процесса;
определение характеристик случайного процесса (исходных данных) и диапазона их изменения;
обоснование требуемой точности получения результатов;
формализация процесса и выбор способа построения статистической модели;
разработка моделирующего алгоритма;
составление программы для решения на ЭВМ и ее отладка;
решение задачи на ЭВМ в соответствии с таблицей вариантов;
анализ полученных результатов, выводы по задаче и рекомендации
Из анализа перечисленных выше этапов видно, что значительная часть общего времени, необходимого для получения конечных результатов, расходуется на этапах предварительной подготовки. Трудоемкость и сложность этих этапов обусловили необходимость совместной работы инженеров, хорошо представляющих себе физическую сущность исследуемых процессов, и математиков-программистов, определяющих выбор наиболее эффективных методов решения и реализующих их в виде программ.
Таким образом, эффективность применения метода моделирования зависит не только от технических характеристик ЭВМ, а в значительной степени определяется спецификой задачи и трудовыми затратами на этапах предварительной подготовки ее к решению на машине. Поэтому большое внимание уделяется разработке библиотек стандартных алгоритмов и программ для решения задач надежности и эффективности АСУ. При наличии таких алгоритмов и про грамм эффективность применения ЭВМ существенно повышается. Общее время получения требуемых результатов определяется при этом лишь временем подготовки таблиц вариантов исследования и «чистым» временем решения на машине, которое может быть сокращено путем максимальной
Вопросы для самоконтроля:
В чем заключается идея метода моделирования?
Какие существуют достоинства и недостатки метода моделирования на ЭВМ?
Какие законы распределения используются в данном методе.
Каким образом осуществляется оценка точности результатов моделирования.
Перечислите основные этапы подготовки и решения задачи оценки надежности и эффективности АСУ на ЭВМ.
Литература :
Надежность и эффективность АСУ. Заренин Ю.Г., Збырко М.Д., Креденцер Б.П и т.д. –Изд "Техника" 1975г. Киев
Л.И. Рыжов. Средства передачи данных в АСУ. Раздел "Методика расчета надежности трактов передачи данных с временной и аппаратурной избыточностями".
Г.В. Дружинин. Надежность автоматизированных систем. Москва,"Энергия",1977г
В. М. Журавлев Методы расчета надежности систем автоматики. Учебно-методическое пособие. Г. Фрунзе 1984г.
1Понятие реализации относится к случайному событию, случайной величине или случайной функции. Для случайного события реализацией будет конкретное событие, происходящее в данном опыте, для случайной величины — ее конкретное значение, а для случайной функции — конкретный вид функции. В таком же понимании употребляется понятие реализации и при моделировании АСУ.
А как ты думаешь, при улучшении метод статистического моделирования на эвм, будет лучше нам? Надеюсь, что теперь ты понял что такое метод статистического моделирования на эвм и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Теория надёжности
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

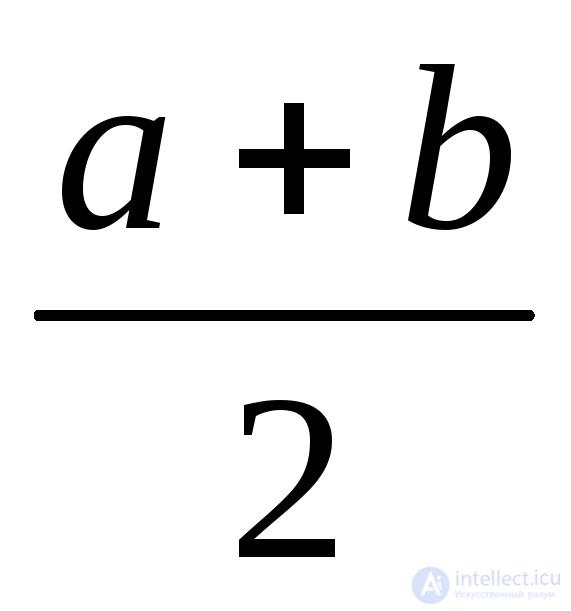


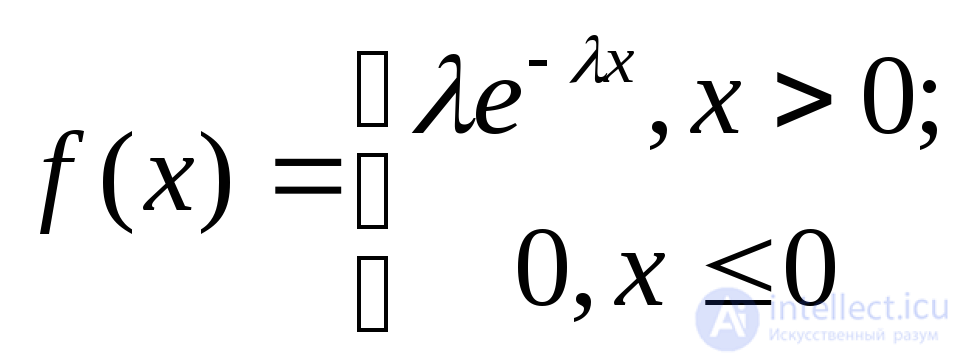

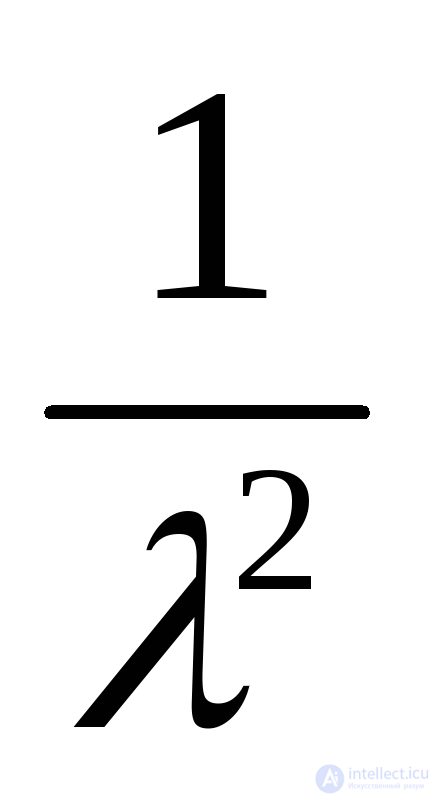
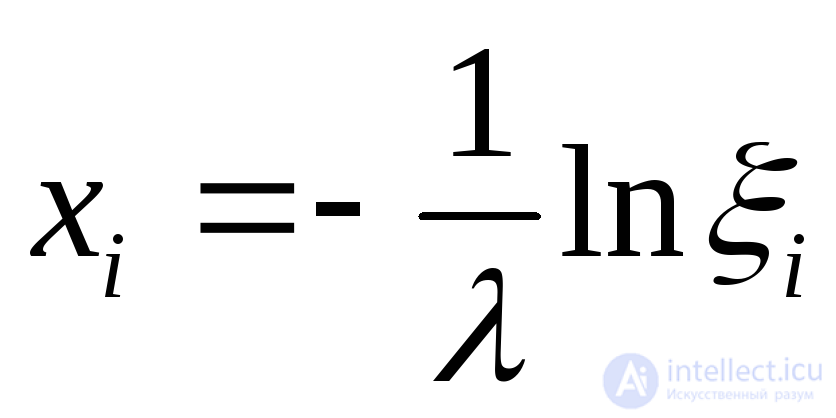
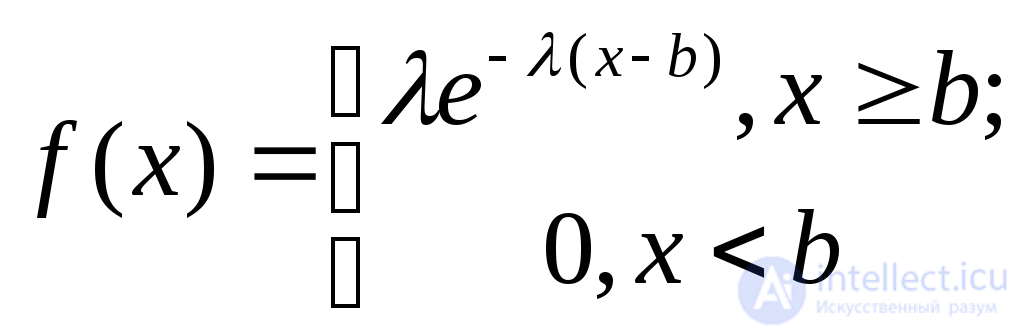
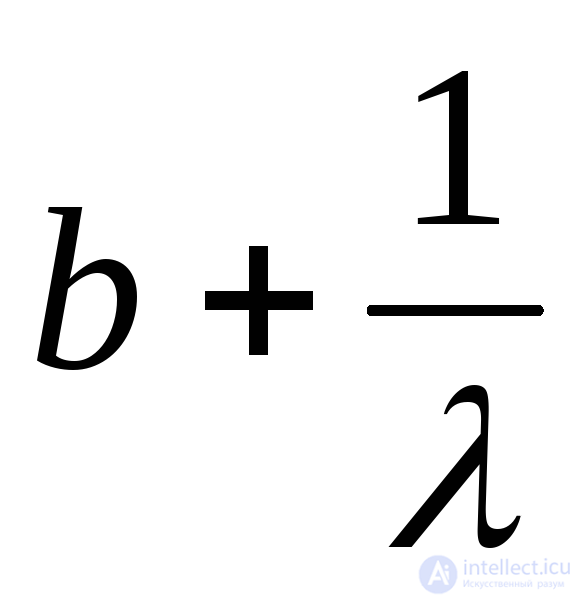

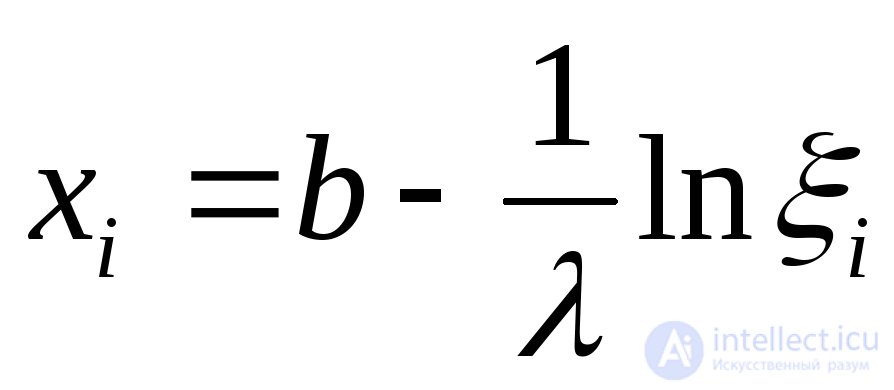
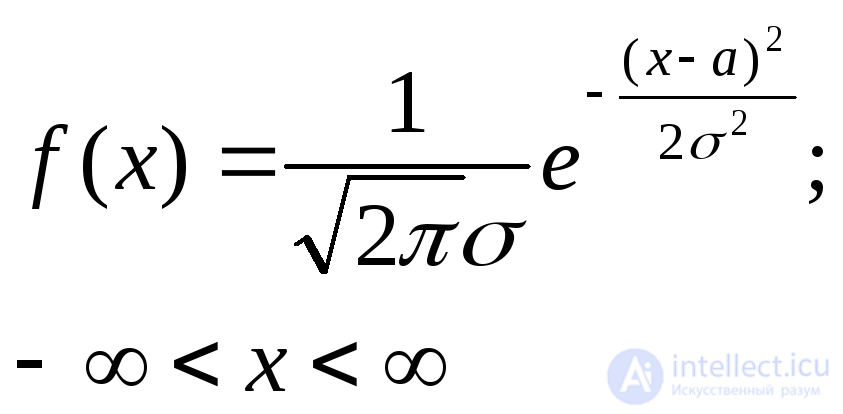
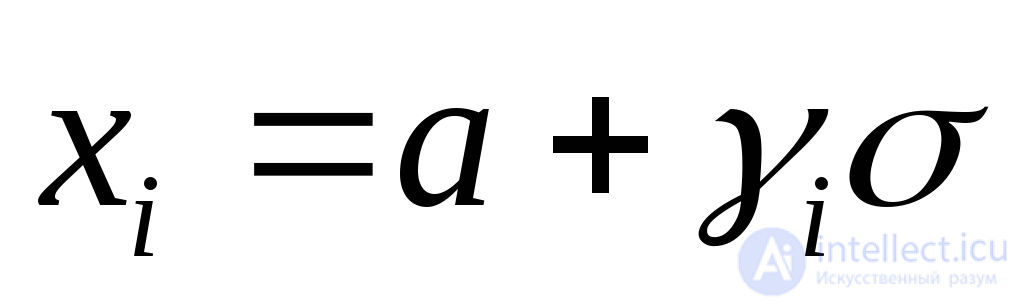
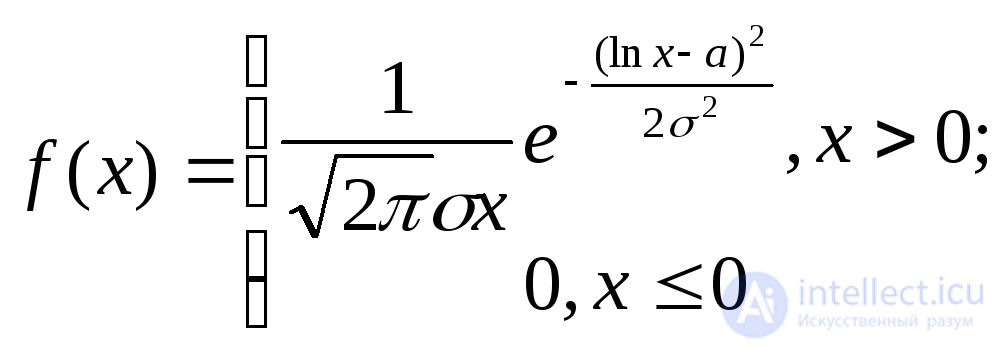
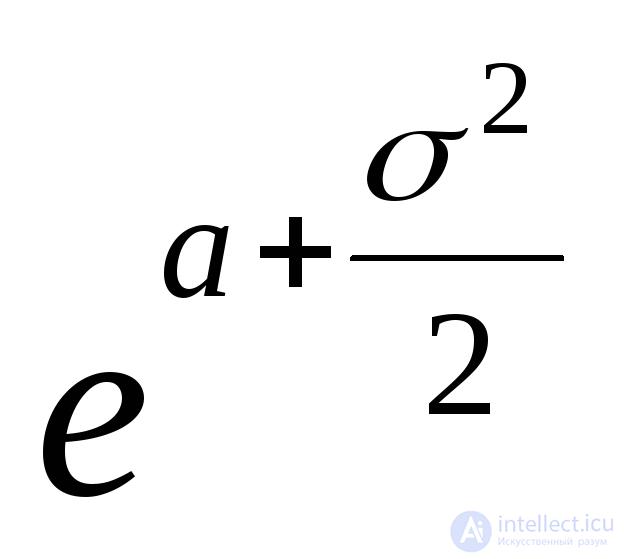

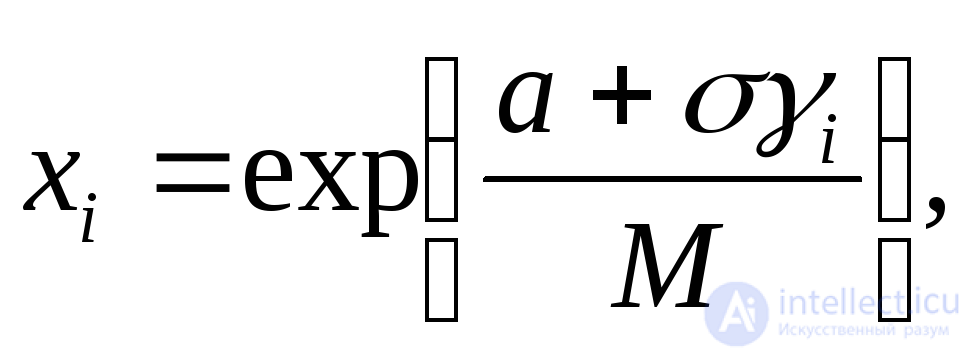
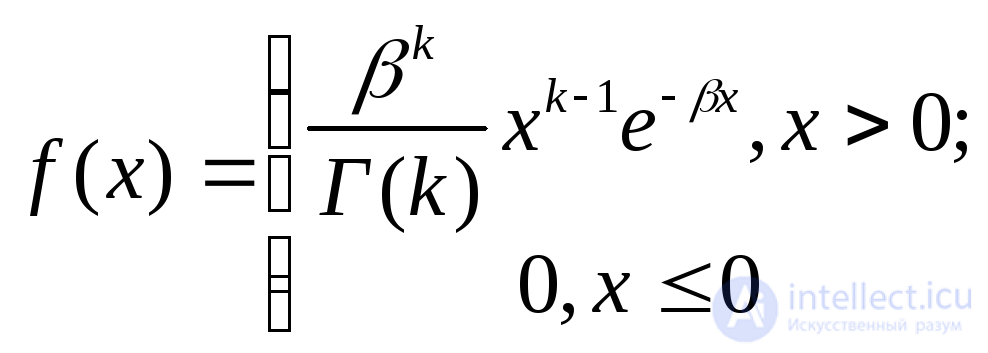
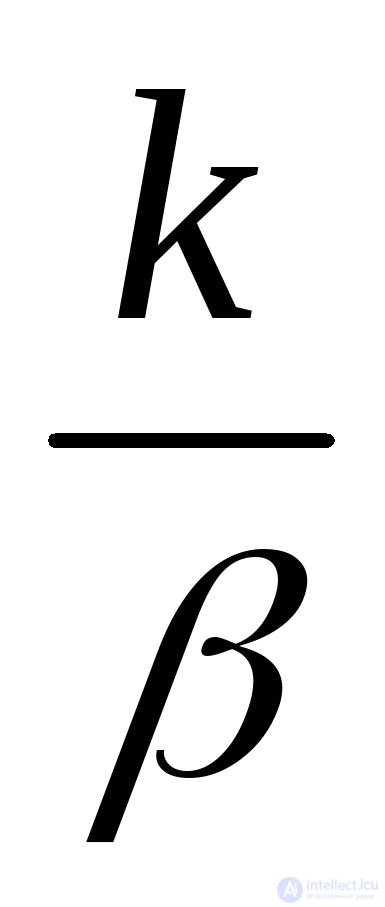
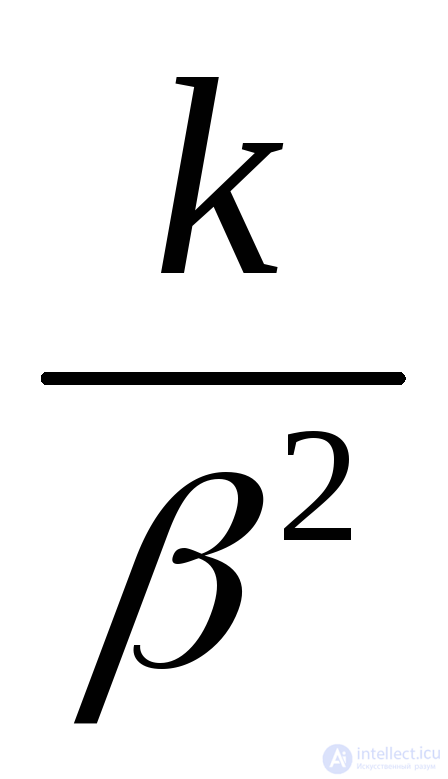


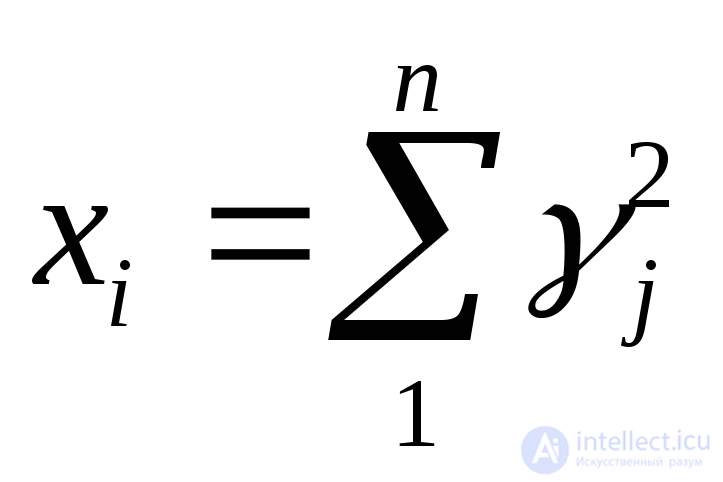
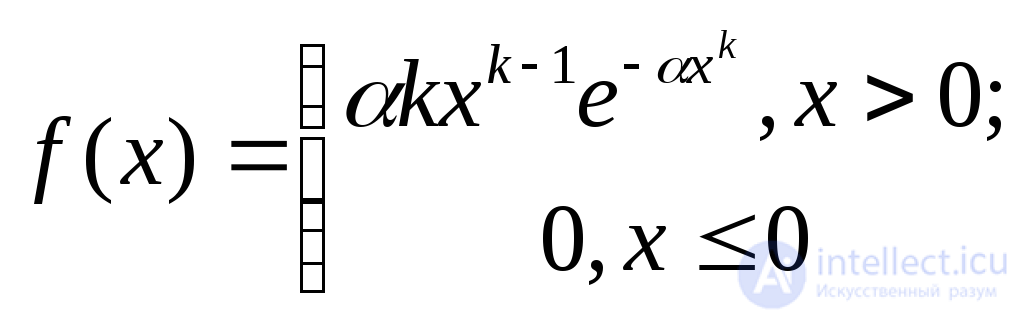

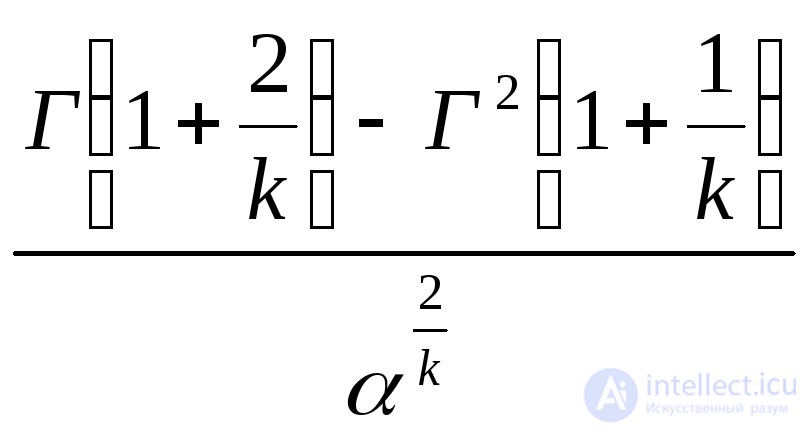
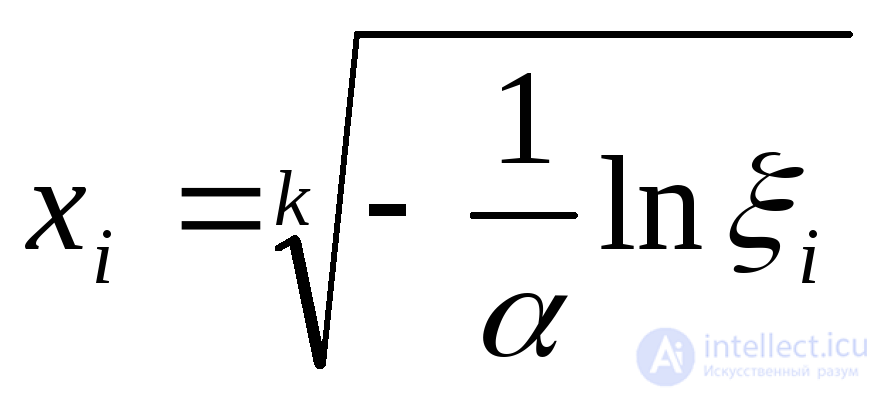
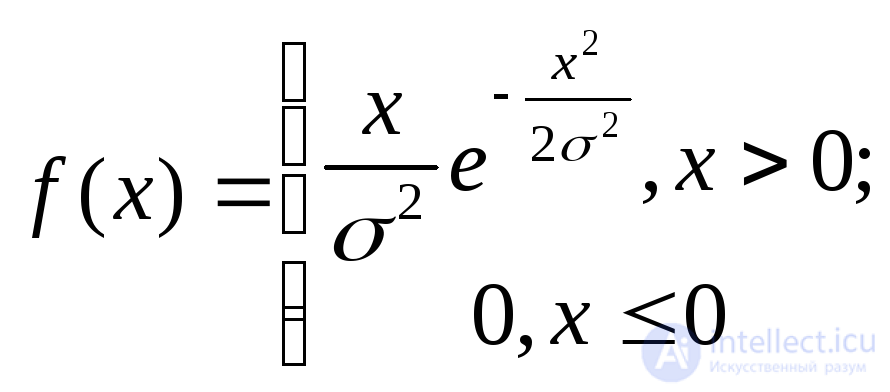

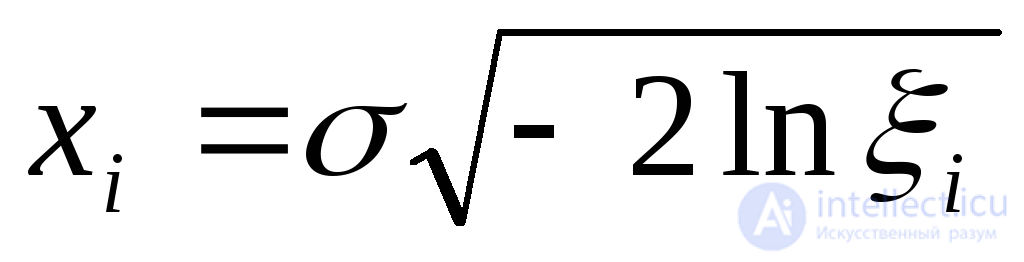
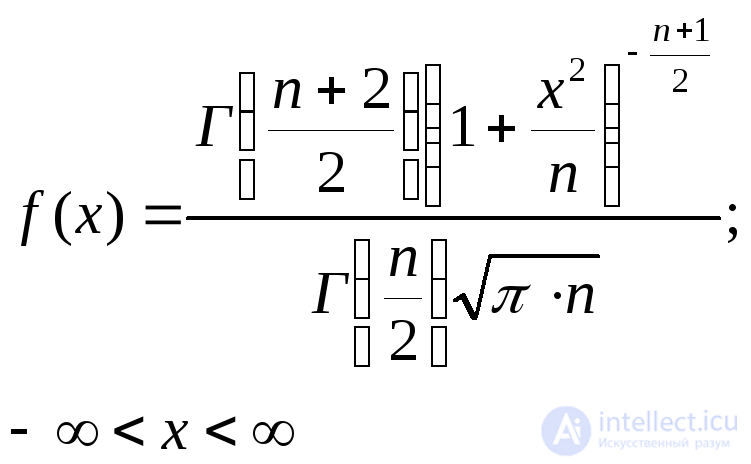
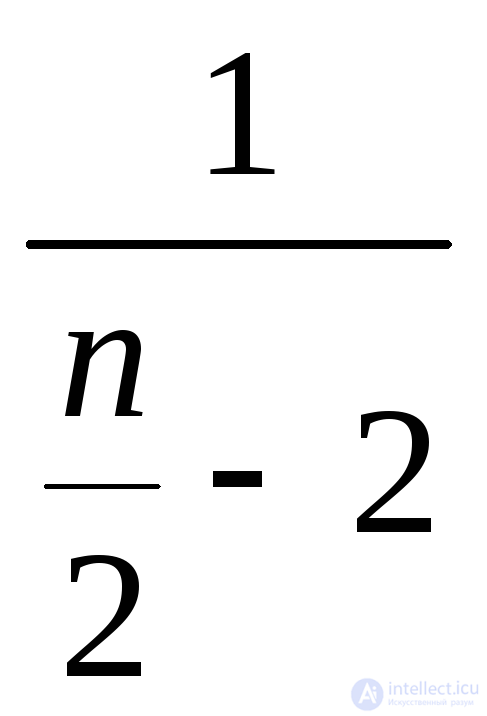
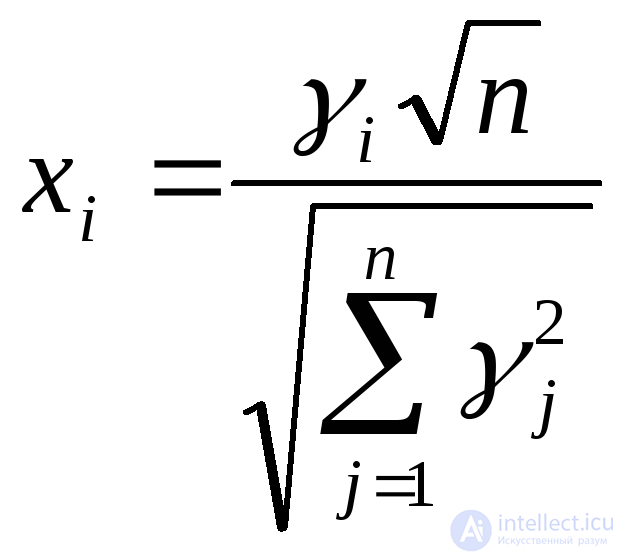

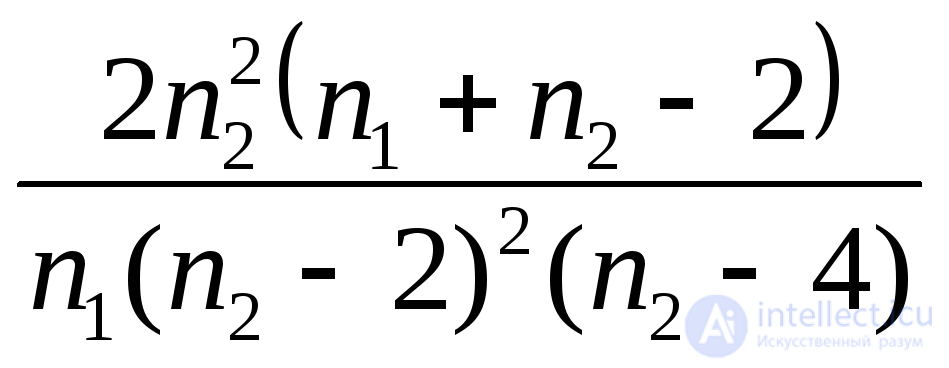
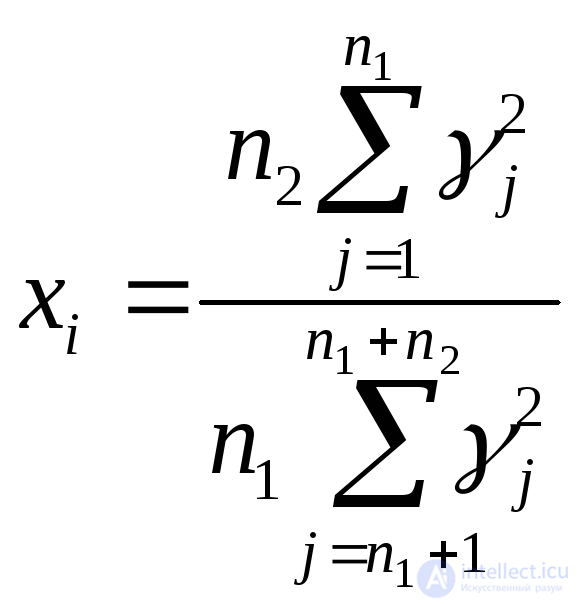
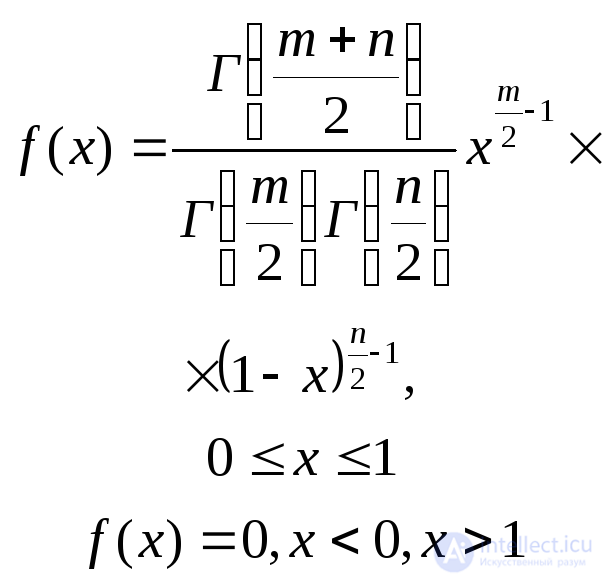
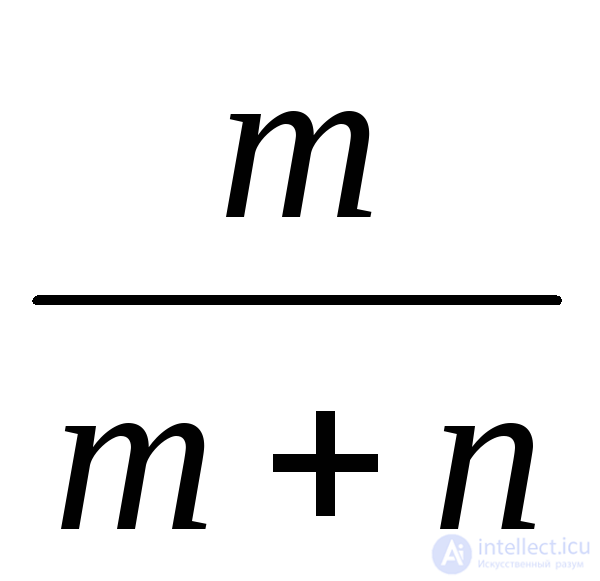
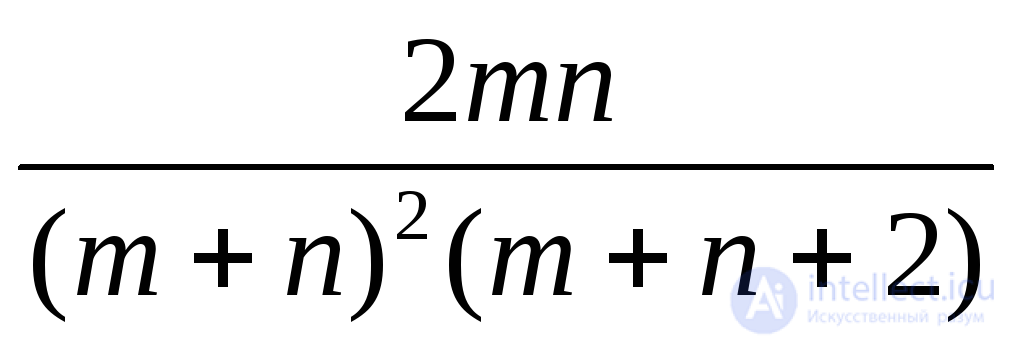
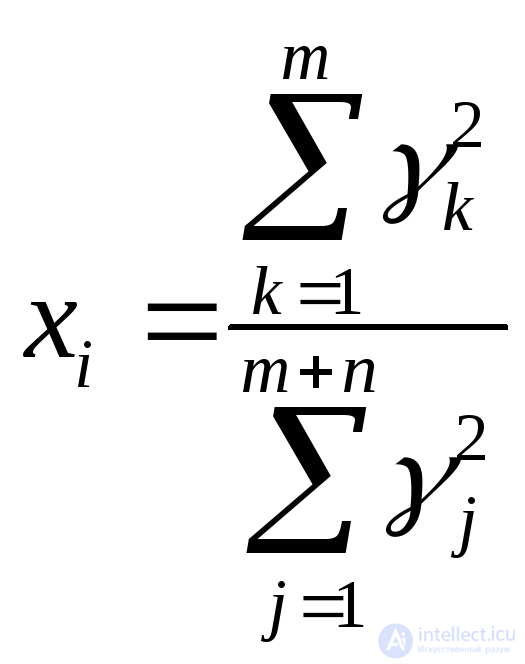
Комментарии
Оставить комментарий
Теория надёжности
Термины: Теория надёжности